 電子發燒友App
電子發燒友App


英特爾加速器架構實驗室的Eriko Nurvitadhi 博士以最新的 GPU 為參照,對兩代 Intel FPGA 上新興的DNN算法進行了評估,認為新興的低精度和稀疏DNN算法效率較之傳統的密集FP32 DNN有巨大改進,但是它們引入了GPU難以處理的不規則并行度和定制數據類型。相比之下,FPGA正是設計用于在運行不規則并行度和自定義數據類型時實現極端的可定制性的。這樣的趨勢使未來FPGA成為運行DNN、AI和ML應用的可行平臺。
來自社交媒體和互聯網的圖像、視頻和語音數字數據的持續指數增長推動了分析的需要,以使得數據可以理解和處理。
數據分析通常依賴于機器學習(ML)算法。在ML算法中,深度卷積神經網絡(DNN)為重要的圖像分類任務提供了最先進的精度,并被廣泛采用。
在最近的 International Symposium onField Programmable Gate Arrays (ISFPGA) 上,Intel Accelerator Architecture Lab (AAL) 的 Eriko Nurvitadhi 博士提出了一篇名為 Can FPGAs beat GPUs in AcceleratingNext-Generation Deep Neural Networks 的論文。他們的研究以最新的高性能的 NVIDIA Titan X Pascal * Graphics Processing Unit (GPU) 為參照,對兩代 Intel FPGA(Intel Arria10 和Intel Stratix 10)的新興DNN算法進行了評估。
Intel Programmable SolutionsGroup 的 FPGA 架構師 Randy Huang 博士,論文的合著者之一,說:“深度學習是AI中最令人興奮的領域,因為我們已經看到了深入學習帶來的巨大進步和大量應用。雖然AI 和DNN 研究傾向于使用 GPU,但我們發現應用領域和英特爾下一代FPGA 架構之間是完美契合的。我們考察了接下來FPGA 的技術進展,以及DNN 創新算法的快速增長,并思考了對于下一代 DNN 來說,未來的高性能 FPGA 是否會優于GPU。我們的研究發現,FPGA 在DNN 研究中表現非常出色,可用于需要分析大量數據的AI、大數據或機器學習等研究領域。使用經修剪或壓縮的數據(相對于全32位浮點數據(FP32)),被測試的 Intel Stratix10 FPGA 的性能優于GPU。除了性能外,FPGA 的強大還源于它們具有適應性,通過重用現有的芯片可以輕松實現更改,從而讓團隊在六個月內從想法進展到原型(和用18個月構建一個 ASIC 相比)。”
測試中使用的神經網絡機器學習
神經網絡可以被表現為通過加權邊互連的神經元的圖形。每個神經元和邊分別與激活值和權重相關聯。該圖形被構造為神經元層。如圖1所示。

圖1 深度神經網絡概述
神經網絡計算會通過網絡中的每個層。對于給定層,每個神經元的值通過相乘和累加上一層的神經元值和邊權重來計算。計算非常依賴于多重累積運算。DNN計算包括正向和反向傳遞。正向傳遞在輸入層采樣,遍歷所有隱藏層,并在輸出層產生預測。對于推理,只需要正向傳遞以獲得給定樣本的預測。對于訓練,來自正向傳遞的預測錯誤在反向傳遞中被反饋以更新網絡權重。這被稱為反向傳播算法。訓練迭代地進行向前和向后傳遞以調整網絡權重,直到達到期望的精度。
FPGA成為可行的替代方案
硬件:與高端GPU 相比,FPGA 具有卓越的能效(性能/瓦特),但它們不具有高峰值浮點性能。FPGA技術正在迅速發展,即將推出的Intel Stratix10 FPGA提供超過5,000個硬件浮點單元(DSP),超過28MB的芯片上RAM(M20Ks),與高帶寬內存(up to 4x250GB/s/stack or 1TB/s)的集成,并來自新HyperFlex技術的改進頻率。英特爾FPGA 提供了一個全面的軟件生態系統,從低級HardwareDescription 語言到具有OpenCL、C和C ++的更高級別的軟件開發環境。英特爾將進一步利用MKL-DNN庫,針對Intel的機器學習生態系統和傳統框架(如今天提供的Caffe)以及其他不久后會出現的框架對 FPGA進行調整。基于14nm工藝的英特爾Stratix 10在FP32吞吐量方面達到峰值9.2TFLOP/s。相比之下,最新的Titan X Pascal GPU的FP32吞吐量為11TFLOP/s。
新興的DNN算法:更深入的網絡提高了精度,但是大大增加了參數和模型大小。這增加了對計算、帶寬和存儲的要求。因此,使用更為有效的DNN已成趨勢。新興趨勢是采用遠低于32位的緊湊型低精度數據類型, 16位和8位數據類型正在成為新的標準,因為它們得到了DNN軟件框架(例如TensorFlow )支持。此外,研究人員已經對極低精度的2位三進制和1位二進制 DNN 進行了持續的精度改進,其中值分別約束為(0,+ 1,-1)或(+ 1,-1)。Nurvitadhi 博士最近合著的另一篇論文首次證明了,ternary DNN可以在最著名的ImageNet數據集上實現目前最高的準確性。另一個新興趨勢是通過諸如修剪、ReLU 和ternarization 等技術在DNN神經元和權重中引入稀疏性(零存在),這可以導致DNN帶有?50%至?90%的零存在。由于不需要在這樣的零值上進行計算,因此如果執行這種稀疏DNN 的硬件可以有效地跳過零計算,性能提升就可以實現。 新興的低精度和稀疏DNN算法效率較之傳統的密集FP32 DNN有巨大改進,但是它們引入了GPU難以處理的不規則并行度和定制數據類型。相比之下,FPGA正是設計用于在運行不規則并行度和自定義數據類型時實現極端的可定制性的。這樣的趨勢使未來FPGA成為運行DNN、AI和ML應用的可行平臺。黃先生說:“FPGA專用機器學習算法有更多的余量。圖2說明了FPGA的極端可定制性(2A),可以有效實施新興的DNN(2B)。
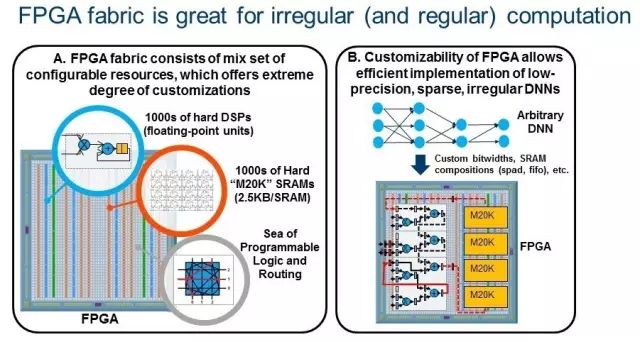
圖2
研究所用的硬件和方法

GPU:使用已知的庫(cuBLAS)或框架(Torch with cuDNN)FPGA:使用Quartus Early Beta版本和PowerPlay

圖3 GEMM測試結果、GEMM是DNN中的關鍵操作
在低精度和稀疏DNN中,Stratix 10 FPGA 比 Titan X GPU的性能更好,甚至性能功耗比要更好。未來這類DNN可能會成為趨勢。
研究1:GEMM測試
DNN 嚴重依賴GEMM。常規DNN依靠FP32密集GEMM。然而,較低的精度和稀疏的新興DNN 依賴于低精度和/或稀疏的GEMM 。Intel 團隊對這些GEMM進行了評估。
FP32 密集GEMM:由于FP32密集GEMM得到了很好的研究,該團隊比較了FPGA和GPU數據表上的峰值。Titan X Pascal 的最高理論性能是Stratix 10 的11 TFLOP和9.2 TFLOP。圖3A顯示,帶有多得多的DSP 數量的Intle Stratix 10 將提供比Intel Arria 10 更強大的FP32性能,和Titan X 的性能表現接近。
低精度INT6 GEMM:為了顯示FPGA的可定制性優勢,該團隊通過將四個int6打包到一個DSP模塊中,研究了FPGA的Int6 GEMM。對于本來不支持Int6 的GPU,他們使用了Int8 GPU 的峰值性能進行了比較。圖3B顯示,Intel Stratix 10 的性能優于GPU。FPGA比GPU提供了更引人注目的性能/功耗比。
非常低精度的1位二進制GEMM :最近的二進制DNN 提出了非常緊湊的1bit數據類型,允許用xnor 和位計數操作替換乘法,非常適合FPGA。圖3C顯示了團隊的二進制GEMM 測試結果,其中FPGA 基本上執行得比GPU 好(即,根據頻率目標的不同,為~2x 到 ~10x)。
稀疏GEMM:新出現的稀疏DNN包含許多零值。該團隊在帶有85%零值的矩陣上測試了一個稀疏的GEMM(基于已修剪的AlexNet)。該團隊測試了使用FPGA的靈活性以細粒度的方式來跳過零計算的 GEMM 設計。該團隊還在 GPU 上測試了稀疏的 GEMM,但發現性能比在GPU 上執行密集的 GEMM 更差(相同的矩陣大小)。該團隊的稀疏 GEMM 測試(圖3D)顯示,FPGA 可以比 GPU 表現更好,具體取決于目標 FPGA 的頻率。
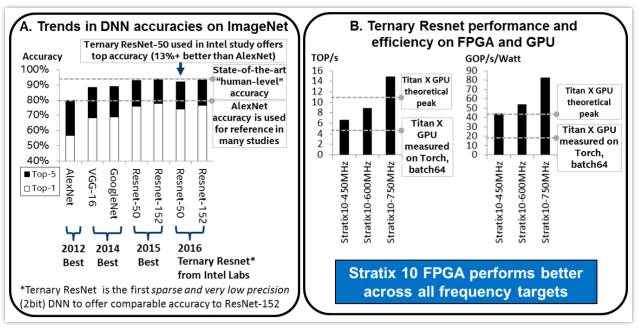
圖4 DNN精度的趨勢,以及FPGA和GPU在Ternary ResNet DNN上的測試結果
研究2:使用三進制 ResNet DNN 測試
三進制DNN最近提出神經網絡權重約束值為+1,0或-1。這允許稀疏的2位權重,并用符號位操作代替乘法。在本次測試中,該團隊使用了為零跳躍、2位權重定制的FPGA設計,同時沒有乘法器來優化運行Ternary-ResNet DNN 。
與許多其他低精度和稀疏的DNN 不同,三進制DNN可以為最先進的DNN(即ResNet)提供可供比較的精度,如圖4A所示。“許多現有的GPU和FPGA研究僅針對基于AlexNet(2012年提出)的ImageNet的”足夠好“的準確性。最先進的Resnet(在2015年提出)提供比AlexNet高出10%以上的準確性。在2016年底,在另一篇論文中,我們首先指出,Resnet上的低精度和稀疏三進制DNN 算法可以在全精度ResNet 的±1%的精度范圍內實現。這個三進制ResNet 是我們在FPGA研究中的目標。因此,我們首先論證,FPGA可以提供一流的(ResNet)ImageNet精度,并且可以比GPU更好地實現。““Nurvitadhi說。
圖4B顯示了 Intel Stratix 10 FPGA 和 Titan X GPU 在 ResNet-50上的性能和性能/功耗比。即使保守估計,Intel Stratix 10 FPGA 也比 Titan X GPU 性能提高了約60%。中度和激進的估計會更好(2.1x和3.5x的加速)。有趣的是,Intel Stratix 10 750MHz的激進預估可以比 Titan X 的理論峰值性能還高35%。在性能/功耗比方面,從保守估計到激進估計,Intel Stratix 10 比 Titan X 要好2.3倍到4.3倍, FPGA如何在研究測試中堆疊
結果表明,Intel Stratix 10 FPGA的性能(TOP /秒)比稀疏的、Int6 和二進制DNN的GEMM上的 Titan X Pascal GPU分別提高了10%、50%和5.4倍。在三進制 ResNet 上,Stratix 10 FPGA 的性能比Titan X Pascal GPU 提高了60%,而性能/功耗比好2.3倍。結果表明,FPGA 可能成為下一代DNN 加速的首選平臺。 深層神經網絡中FPGA的未來
FPGA 能否在下一代 DNN 的性能上擊敗 GPU ?Intel 對兩代 FPGA(Intel Arria 10和 Intel Stratix 10)以及最新的 Titan X GPU 的各種新興DNN的評估顯示,目前DNN算法的趨勢可能有利于FPGA,而且FPGA甚至可以提供卓越的性能。雖然這些結論源于2016年完成的工作,Intel 團隊在繼續測試 Intel FPGA 的現代 DNN 算法和優化(例如,FFT / winograd 數學變換,量化,壓縮)。
該團隊還指出,除了DNN之外,FPGA在其他不規則應用以及延遲敏感(如ADAS和工業用途)等領域也有機會。
“目前使用32位密集矩陣乘法的機器學習是GPU體現優勢的領域”,黃表示:“我們鼓勵其他開發人員和研究人員與我們一起重新表述機器學習問題,以充分發揮 FPGA 更小位數處理能力的優勢,因為 FPGA 可以很好地適應向低精度的轉變。”
編輯:黃飛















 工商網監
工商網監
評論