 電子發燒友App
電子發燒友App


隨著計算機技術的發展,人們開始把它應用到越來越多的領域,例如金融分析、科學計算、網絡服務應用、醫療成像等等。雖然這些不同領域有著各異的應用程序和算法,但對于高性能的計算機而言,它們共同的需求就是,對程序要有強大的執行效率,并且能夠實現較快的計算速度。
為了提高HPC的計算能力,在最近的幾年中,人們開始把其他各種高性能架構開始向機群系統轉移。然而,目前的機群系統大多還是傳統的CPU,為了追求計算能力,僅僅是不停的增加計算節點,最終服務器會堆到機房外面。
如果在HPC系統中的計算節點上加入FPGA(現場可編程門陣列)作為協處理器,通過對FPGA進行特定程序算法優化,可以大大提高對特定應用程序的執行效率,同時還可以大大降低系統的功耗,并降低系統TCO。
隨著主流服務器芯片廠商中AMD和Intel先后開放了CPU接口總線IP核,使得FPGA同CPU總線直接接口變得更加容易,而不需要再采用IO接口進行設計專門的協處理IO卡。目前已經有大量的廠商開始提供相關的協處理器。
HPC變遷趨勢和機群架構的新問題
對于高性能計算(HPC),其特點是計算能力強,一般為特別設計的超級計算機。之前的超級計算機架構多是SMP、MPP、SMD等,圖1所示為TOP500中HPC的架構變遷。
集群(Cluster)技術是近幾年興起的發展高性能計算機的一項技術,采用Cluster體系結構集群系統,具有可自由伸縮、高度可管理、高可用、高性能價格比等諸多優點,從圖1中我們可以看到機群系統逐漸在HPC應用上取代MPP開始占據主流位置。
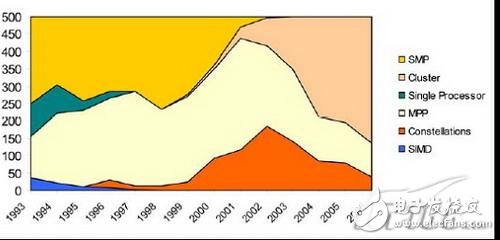
圖1 TOP500中系統架構發展情況
雖然機群系統有著上述種種優勢,但由于使用了通用的處理器,隨著應用對計算能力需求的日益增加,人們不得不被動增加計算結點數目,增加CPU數目來應對計算能力需求的提升。目前的機群系統從原來的幾十個計算結點,到現在的成百上千個結點,甚至到不遠的將來上萬個計算結點,機群系統的不足也隨之日趨明顯。主要體現在:第一、受機柜高度和傳統1U機箱的限制,計算密度比較疏松,而且密度無法突破;第二、安裝維護工作量和成本過大;第三、對于大規模機群,功耗日趨成為瓶頸;第四、智能而有效的管理監控成為大規模機群系統新的挑戰。所有這些問題都會導致數據中心的整體擁有成本的增加(TCO),這對于長期運營的數據中心而言,是最不想看到的。
而最大的問題在于,對于所有的應用而言,都采用同樣的CPU進行運算處理,而像金融分析、生物計算、科學計算,對CPU資源的需求是不同的,因此采用同樣的系統,就不能夠實際獲得機群系統所標稱的性能。
目前,人們開始尋找一種替代方式,可以看到的是采用基于FPGA的協處理器來加速應用軟件的關鍵算法執行。這種方式類似于以前提出過的在C++代碼中的內層循環采用匯編語言來直接編寫,以優化關鍵程序運行。
相對于目前的X86處理器而言,FPGA一般都運行在比較低的時鐘頻率下,優勢在于有著較高的內存帶寬、突出的并行處理能力和出色的根據應用環境的硬件定制化能力。如果同在服務器上增加一顆處理器/內核比較,僅僅在服務器上增加一顆FPGA的協處理器,一般情況下性能可以提高2至3倍,而功耗則可以降低40%,根據應用情況進行算法優化的話,最大可以提高性能達10倍。
FPGA協處理器為HPC加速
正如上文所言,目前HPC應用涵蓋了多個領域,有著不同的計算需求。例如在商業數據分析和基因測序中,要進行大量的數組運算、線形數據匹配、邏輯測試等等,而對于醫療成像、計算化學而言,其主要工作是同步映射、過濾等等。這些不同的應用需要不同的數學邏輯操作以及有效的內存連接讀取等。
通用的CPU、專用的圖像處理CPU(目前稱之為GPU)或網絡處理CPU,都無法為HPC應用提供一個可選的通用解決方案。而FPGA作為一個可重構計算引擎,可以在軟件控制下進行硬件單元優化工作,來滿足不同HPC應用需求,從而提供計算效率。從某種程度上說,采用基于FPGA協處理器的可重構計算硬件平臺,可以有可能讓HPC在各種應用軟件下達到很高的效率。
FPGA通過把高性能計算算法中固有的并行運算部分硬件化來實現HPC應用加速。其實這種并行可分為多個等級,在機群計算中在多個CPU上進行任務的多線程分配我們可以稱之為“任務級并行”。第二級并行我們稱之為“指令并行”,傳統的CPU支持數量有限的指令并發處理,就是CPU指令流水線的管道數或者發射數比較有限。而FPGA則可以提供很多管道,也就是說可以同時并行執行大量的指令。“數據并行”是FPGA很容易實現的第三級并行處理能力,FPGA的結構非常容易實現并行操作。因而,通過配置,它可以同時執行大量的數據吞吐操作,在這種情況下,該設備相當于多個傳統CPU在同時工作。
如果實現上述三種級別的并行處理,一個200Mhz的FPGA處理能力將遠遠超過一個3Ghz的通用CPU,然而功耗僅僅是后者的1/4。例如在生物計算中,FPGA在處理DNA基因排序上能往往能夠比通用CPU加速50倍到100倍;而在醫療CT的2D/3D圖像處理上能夠加速10倍左右;而對與一些通用的算法如FFT,一般情況下FPGA的加速至少可以達到10倍以上。
一個標準FPGA協處理器的例子
本文以XtremeData公司的協處理器產品為例,介紹其應用環境及工作流程。圖二是XtremeData 公司的x86 FPGA 協處理器實物以及應用平臺情況。從圖中可以看出,該協處理器產品可以直接放置在普通的4路或者兩路Opteron系統上,該系統可以是機架式服務器或刀片產品。
該協處理器模塊同CPU管教兼容,同時可以直接使用板上連接在協處理器上的內存條,或者通過HT總線使用其他CPU上連接的內存條。這種結構有很大的優勢,主板可以不用作任何改動,也就是說在普通的服務器上可以即插即用,同時還可以直接利用主板資源,并獲取很大的HT總線帶寬和低延遲。
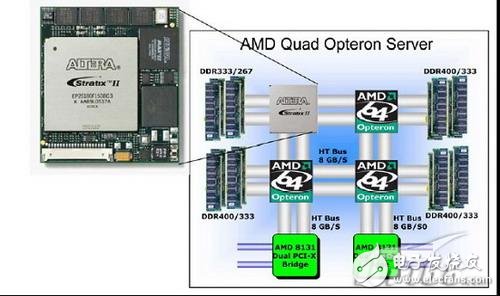
圖2 典型協處理器應用架構
其工作原理把適用于該芯片的算法庫安裝在主機上,根據應用不同,主機上的GUI可以在線配置和更改FPGA內硬件進行不用算法的優化。當然,前提是對于各種HPC應用都要實現完成算法庫的編寫,并轉換成FGPA可以識別的硬件描述語言庫,通過加載該語言庫,可更改FPGA內部硬件結構,實現應用程序的硬件加速。圖3為系統工作流程。
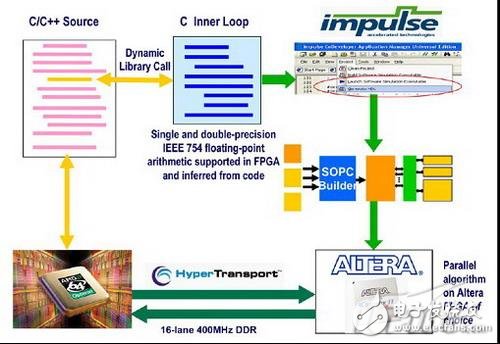
圖3 協處理器配置和實現過程
在執行過程中,對于并行性較強、浮點運算需求較高的計算可以通過后HT總線丟給協處理器進行計算,并持續獲取計算結果,主CPU主要負責IO處理以及程序調度工作,從而實現協處理器的加速工作。
CPU 廠商持開放態度
CPU廠商目前對協處理器的出現并沒有持抵制態度,而是比較支持協處理器的開發。
AMD率先提出Torenza協處理平臺,允許第三方處理器與Opteron合作,開放相關接口。之后,Intel在IDF上也提出了自己的系統架構開放計劃。Intel高級副總裁Pat Gelsinger宣布,Intel將向Xilinx等第三方FPGA生產商開放前端總線(FSB)授權,以便他們的芯片能通過前端總線和內存控制器 (MCH)的直連與Intel處理器協同工作。如同AMD的HyperTransport總線,Intel的前端總線授權也能讓各種加速單元加入一個高帶寬、低延遲的總線,從而在Intel系統中與MCH直接相連。
至此,兩個通用處理器的巨人對協處理器都抱著支持和看好的態度,大大方便了第三方廠商進行協處理器同通用處理器的接口的開發工作。
總之,從市場來看,目前IBM 的cell、美國的Cleaspeed、DRC、Mitrionics和Celoxic等公司都有相應產品提供。在目前的應用中,Sun公司在為東京理工大學制造的超級計算機就采用了ClearSpeed的協處理器卡進行了加速,Cray公司目前在超級計算機上也有應用。
不過,該技術從目前的情況來看還不是很成熟,距離大規模商業應用還有一定的距離。主要問題在于:不同的HPC領域應用算法各異。而作為可重構計算的 FPGA協處理器,對于不同的算法都需要通過硬件描述語言解釋和實現,需要進行大量的算法庫的工作。而目前沒有公司能夠提供足夠多的IP核供使用,只能在少數應用上進行FPGA協處理器的加速。當然,由于Linepacke是HPC的主要測試軟件,而各家公司的產品都可以加速Linpake的性能測試。
從長遠看來,由于FPGA可重構的協處理器有著上文描述的種種優勢,所以在將來的HPC應用中,解決的不同算法的硬件描述轉化的問題后,將會得到大量的應用。









 工商網監
工商網監
評論