 電子發燒友App
電子發燒友App


ASICvsGPU+FPGA
GPU適用于單一指令的并行計算,而FPGA與之相反,適用于多指令,單數據流,常用于云端的“訓練”階段。
此外與GPU對比,FPGA沒有存取功能,因此速度更快,功耗低,但同時運算量不大。結合兩者優勢,形成GPU+FPGA的解決方案。
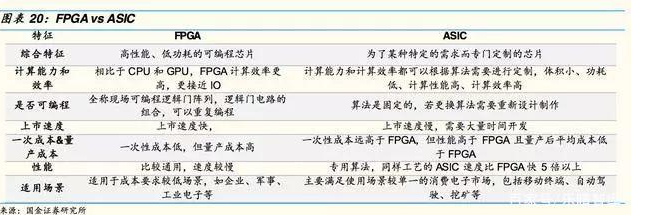
FPGA和ASIC的區別主要在是否可以編程。FPGA客戶可根據需求編程,改變用途,但量產成本較高,適用于應用場景較多的企業、軍事等用戶;而ASIC已經制作完成并且只搭載一種算法和形成一種用途,首次“開模”成本高,但量產成本低,適用于場景單一的消費電子、“挖礦”等客戶。
目前自動駕駛算法仍在快速更迭和進化,因此大多自動駕駛芯片使用GPU+FPGA的解決方案。未來算法穩定后,ASIC將成為主流。
計算能耗比,ASIC>FPGA>GPU>CPU,究其原因,ASIC和FPGA更接近底層IO,同時FPGA有冗余晶體管和連線用于編程,而ASIC是固定算法最優化設計,因此ASIC能耗比最高。
相比前兩者,GPU和CPU屏蔽底層IO,降低了數據的遷移和運算效率,能耗比較高。同時GPU的邏輯和緩存功能簡單,以并行計算為主,因此GPU能耗比又高于CPU。
▌ASIC是未來自動駕駛芯片的核心和趨勢
結合ASIC的優勢,我們認為長遠看自動駕駛的AI芯片會以ASIC為解決方案,主要有以下幾個原因:

綜上ASIC專用芯片幾乎是自動駕駛量產芯片唯一的解決方案。由于這種芯片僅支持單一算法,對芯片設計者在算法、IC設計上都提出很高要求。
以上并非下定論目前ASIC為核心的芯片一定比GPU+FPGA的芯片強,由于目前自動駕駛算法還在快速迭代和升級過程中,過早以固有算法生產ASIC芯片長期來看不一定是最優選擇。
▌相關公司
Mobileye
Intel在ADAS處理器上的布局已經完善,包括Mobileye的ADAS視覺處理,利用Altera的FPGA處理,以及英特爾自身的至強等型號的處理器,可以形成自動駕駛整個硬件超級中央控制的解決方案。
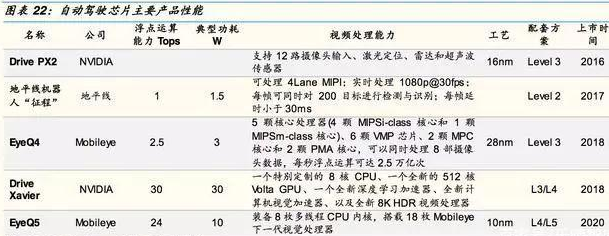
Mobileye具有自主研發設計的芯片EyeQ系列,由意法半導體公司生產供應。現在已經量產的芯片型號有EyeQ1至EyeQ4,EyeQ5正在開發進行中,計劃2020年面世,對標英偉達DrivePXXavier,并透露EyeQ5的計算性能達到了24TOPS,功耗為10瓦,芯片節能效率是DriveXavier的2.4倍。
英特爾自動駕駛系統將采用攝像頭為先的方法設計,搭載兩塊EyeQ5系統芯片、一個英特爾凌動C3xx4處理器以及Mobileye軟件,大規模應用于可擴展的L4/L5自動駕駛汽車。該系列已被奧迪、寶馬、菲亞特、福特、通用等多家汽車制造商使用。
從硬件架構來看,該芯片包括了一組工業級四核MIPS處理器,以支持多線程技術能更好的進行數據的控制和管理(下圖左上)。
多個專用的向量微碼處理器(VMP),用來應對ADAS相關的圖像處理任務(如:縮放和預處理、翹曲、跟蹤、車道標記檢測、道路幾何檢測、濾波和直方圖等,下圖右上)。
一顆軍工級MIPSWarriorCPU位于次級傳輸管理中心,用于處理片內片外的通用數據。
此外通過行業訪談調研等途徑了解到,Mobileye在L1-L3智能駕駛領域具有極大的話語權,對Tire1和OEM非常強勢,其算法和芯片綁定,不允許更改。
5月3日,寒武紀科技在2018產品發布會上發布了多個IP產品——采用7nm工藝的終端芯片Cambricon1M、云端智能芯片MLU100等。
其中寒武紀1M芯片是公司第三代IP產品,在TSMC7nm工藝下8位運算的效能比達5Tops/w(每瓦5萬億次運算),同時提供2Tops、4Tops、8Tops三種尺寸的處理器內核,以滿足不同需求。
1M還將支持CNN、RNN、SVM、k-NN等多種深度學習模型與機器學習算法的加速,能夠完成視覺、語音、自然語言處理等任務。通過靈活配置1M處理器,可以實現多線和復雜自動駕駛任務的資源最大化利用。它還支持終端的訓練,以此避免敏感數據的傳輸和實現更快的響應。
寒武紀首款云端智能芯片CambriconMLU100同期發布,同時公布了在R-CNN算法下MLU100與英偉達TeslaV100(2017)和英偉達TeslaP4(2016)的對比,從參數上看,主要對標TeslaP4。最后說明芯片從設計到落地應用面臨的潛在風險:
地平線
2017年地平線發布了新一代自動駕駛芯片“征程”和配套軟件平臺方案“雨果”,同時還發布了應用于智能攝像頭的“旭日”處理器。
“征程”是一款專用AI芯片,采用地平線的第一代BPU架構,可實時處理1080p@30視頻,每幀中可同時對200個目標進行檢測、跟蹤、識別,典型功耗1.5W,每幀延時小于30ms。CEO余凱介紹,地平線的芯片更聚焦在針對不同場景下的具體應用,相比于英偉達的方案,在功耗上低一個數量級,價格也會有更大的競爭力。
2018年亞洲CES,地平線宣布推出從L2到L4級別全系列的自動駕駛計算平臺。
地平線星云,基于征程1.0芯片,能夠以車規級標準滿足L1和L2級別的自動駕駛的需求,能同時對行人、機動車、非機動車、車道線、交通標志牌、紅綠燈等多類目標進行精準的實時監測與識別;并可滿足車載設備嚴苛的環境要求,以及復雜環境下的視覺感知需求,支持L2級別ADAS功能。
地平線Matrix1.0,內置地平線征程2.0處理器架構,最大化嵌入式AI計算性能,是面向L3/L4的自動駕駛解決方案,可滿足自動駕駛場景下高性能和低功耗的需求。
依托地平線公司自主研發的工具鏈,開發者和研究人員可以基于Matrix平臺部署神經網絡模型,實現開發、驗證、優化和部署。
百度“昆侖”
7月4日百度AI開發者大會上,李彥宏發布了由百度自主研發的中國首款云端全功能AI芯片——“昆侖”。“昆侖”基于百度8年的AI加速器經驗的研發,預計將于明年流片。
“昆侖”采用14nm三星工藝,是業內設計算力最高的AI芯片(100+瓦功耗下提供260Tops性能);512GB/s內存帶寬,由幾萬個小核心構成。
“昆侖”可高效地同時滿足訓練和推斷的需求,除了常用深度學習算法等云端需求,還能適配諸如自然語言處理,大規模語音識別,自動駕駛,大規模推薦等具體終端場景的計算需求。
此外可以支持paddle等多個深度學習框架,編程靈活度高。同時也有媒體對該產品提出疑義,主要有以下兩點:
GoogleTPU
GoogleTPU于2016年在GoogleI/O上宣布,當時該公司表示TPU已在其數據中心內使用了一年以上。該芯片專為Google的TensorFlow(一個符號數學庫,用于神經網絡等機器學習應用)框架而設計。
GoogleTPU是專用的,并不面向市場,谷歌僅表示“將允許其他公司通過其云計算服務購買這些芯片。”
今年2月,谷歌在其云平臺博客上宣布的TPU服務開放價格大約為每cloudTPU(180TFLOPS和64GB內存)每小時6.50美元。
Google使用TPU開發圍棋系統AlphaGo和AlphaZero以及進行Google街景視頻文字處理等,能夠在不到五天的時間內找到街景數據庫中的所有文字,此外TPU也用于提供Google搜索結果的排序。
TPU與同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。
Xilinx&深鑒科技
Xilinx賽靈思是FPGA的先行者和領導者,1984年,賽靈思發明了現場可編程門陣列FPGA,作為半定制化的ASIC,順應了計算機需求更專業的趨勢。
FPGA的好處是可編程以及帶來的靈活配置,同時還可以提高整體系統性能,比單獨開發芯片整個開發周期大為縮短,但缺點是價格、尺寸等因素。
在汽車ADAS和自動駕駛解決方案上,賽靈思的FPGA和SOC產品家族衍生出三個模塊:
前置攝像頭Zynq-7000/ZynqUltraScale+MPSoC
多傳感器融合系統ZynqUltraScale+MPSoC
Zynq采用單一芯片即可完成ADAS解決方案的開發,SOC平臺大幅提升了性能,便于各種捆綁式應用,能實現不同產品系列間的可擴展性,可幫助系統廠商加快在環繞視覺、3D環繞視覺、后視攝像頭、動態校準、行人檢測、后視車道偏離警告和盲區檢測等ADAS應用的開發時間。并且可以讓OEM和Tier1在平臺上添加自己的IP以及賽靈思自己的擴展。
深鑒科技成立于2016年,其創始團隊有著深厚的清華背景,專注于神經網絡剪枝、深度壓縮技術及系統級優化。2018年7月17日,賽靈思宣布收購深鑒科技。
自成立以來,深鑒科技就一直基于賽靈思的技術平臺開發機器學習解決方案,推出的兩個用于深度學習處理器的底層架構—亞里士多德架構和笛卡爾架構的DPU產品,都是基于賽靈思FPGA器件。
對于賽靈思來說,看好深鑒科技基于機器學習的軟件、算法,以及面向云側和端側硬件架構的優勢;對于深鑒科技,后期發展高昂的研發費用、高成本的芯片設計、流片、試制、認證、投片量產,投靠賽靈思能夠降低隨之而來的風險,進入芯片戰爭的持久戰。
2018年6月,深鑒科技宣布進軍自動駕駛領域,自主研發的ADAS輔助駕駛系統——DPhiAuto,目前已獲得日本與歐洲一線車企廠商和Tier1的訂單,即將實現量產。
DPhiAuto,基于FPGA,是面向高級輔助駕駛和自動駕駛的嵌入式AI計算平臺,可提供車輛檢測、行人檢測、車道線檢測、語義分割、交通標志識別、可行駛區域檢測等深度學習算法功能,是一套針對計算機視覺環境感知的軟硬件協同產品。
功耗方面,可以在10-20W的功耗范圍內,實現等效性能,能效比指標高于目前主流的CPU、GPU方案。(國金證券:張帥)百度搜索“樂晴智庫”獲得更多行業報告。









 工商網監
工商網監
評論