 電子發(fā)燒友App
電子發(fā)燒友App


導(dǎo)讀
地平線在智東西公開課開設(shè)的「地平線自動駕駛技術(shù)專場」第3講順利完結(jié),地平線智能駕駛應(yīng)用軟件部負責(zé)人宋巍圍繞《面向規(guī)模化量產(chǎn)的智能駕駛系統(tǒng)和軟件開發(fā)》這一主題進行了直播講解。
宋巍老師首先結(jié)合以往智能駕駛應(yīng)用軟件開發(fā)過程中的痛點和實踐經(jīng)驗,對智能駕駛應(yīng)用軟件技術(shù)進行了詳細分析。之后,他從軟件視角闡述了“軟硬結(jié)合”和“軟硬解耦”的意義與價值,并對智能駕駛軟件開發(fā)平臺Horizon TogetherOS Bole進行了深度講解。最后,還展望了智能駕駛應(yīng)用軟件的開發(fā)趨勢。
本次課程內(nèi)容分為4個部分:
1、智能駕駛應(yīng)用軟件技術(shù)拆解2、軟件視角的“軟硬結(jié)合”與“軟硬解耦”3、智能駕駛軟件開發(fā)平臺Horizon TogetherOS Bole4、智能駕駛應(yīng)用軟件開發(fā)趨勢展望
01 智能駕駛應(yīng)用軟件技術(shù)拆解
談到軟件,那什么是軟件呢?維基百科上的解釋是:Software is a set of instructions and documentation that tells a computer what to do or how to perform a task。在百度百科上也給了軟件中文解釋,是指一系列按照特定順序組織的計算機數(shù)據(jù)和指令的集合。對于軟件來說,它就是在執(zhí)行單元上執(zhí)行指令和數(shù)據(jù),也就是在硬件之上,所有事情都是軟件。
?
整個智能駕駛中,如果從大的領(lǐng)域劃分,可以看到有廣義感知、地圖融合、規(guī)劃和控制幾個大領(lǐng)域。如果是根據(jù)算法時代來劃分,可以劃分成軟件1.0和軟件2.0。
軟件1.0是傳統(tǒng)的CV,或者是在端到端的深度學(xué)習(xí)落地之前,基于規(guī)則實現(xiàn)的一些面向自動駕駛的軟件和算法。軟件2.0是未來可以通過深度學(xué)習(xí)和數(shù)據(jù)驅(qū)動,端到端的把整個軟件算法性能迭代起來。但描述它時都是用軟件1.0和軟件2.0,這其實是一個廣義的軟件定義。那對于一個智能駕駛的軟件工程師來說,這時就要承載上面所有領(lǐng)域的研發(fā)工作。
一個軟件研發(fā)工程師,他的能力要求該如何被定義呢?簡單來看,因為要做嵌入式開發(fā),懂C++就可以。但如果是面向智能駕駛業(yè)務(wù)開發(fā)的工作,那既要有豐富的軟件工程能力;還要有完備的智能駕駛業(yè)務(wù)知識體系,知道智能駕駛的業(yè)務(wù)在做什么;又要對硬件有一定理解,因為在嵌入式上開發(fā),資源和在服務(wù)器上開發(fā)是非常不一樣的;且要有一定的算法實現(xiàn)能力,因為在開發(fā)過程中,如果對算法一無所知,整個開發(fā)過程會遇到非常多的困難。
?
我們可以把智能駕駛的環(huán)境感知做一些拆解。從地平線征程5 SoC芯片的系統(tǒng)框圖上,可以看到有OS部分,即基礎(chǔ)操作系統(tǒng);再往上有中間件和軟件開發(fā)平臺,整個通訊的組件,基礎(chǔ)中間件和應(yīng)用中間件;再往上就是面向自動駕駛和智能交互的上層應(yīng)用。
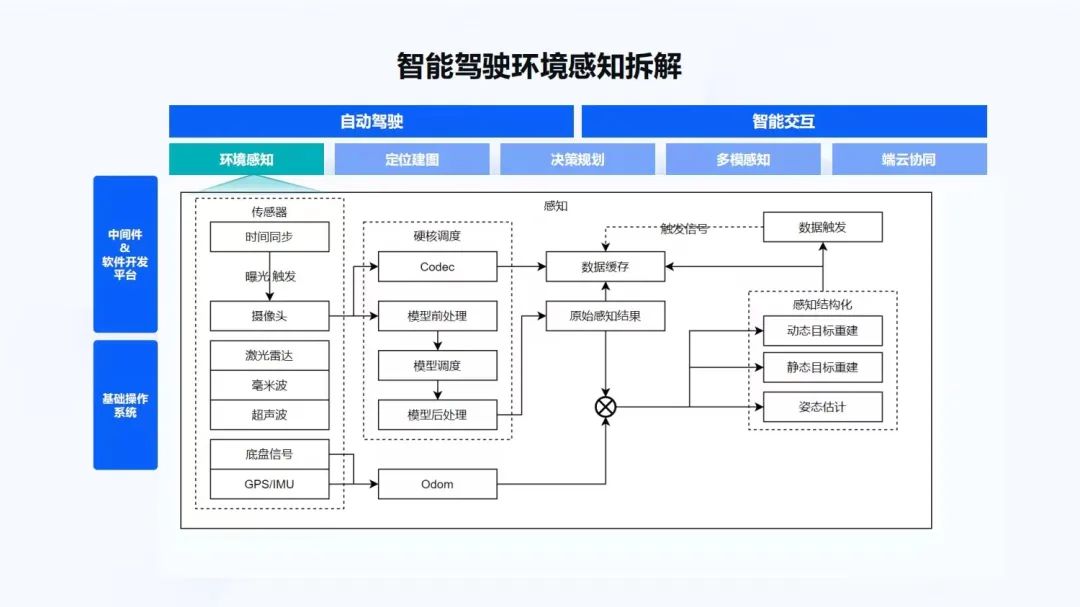
主要看下環(huán)境感知部分。我們把它做一些簡單的拆解,如果做環(huán)境感知,首先要有一系列的傳感器,有時間同步,有攝像頭、激光雷達、毫米波、超聲波、車身的底盤信號、GPS/IMU等。然后,在一個嵌入式SoC上有很多的硬核,需要對硬核做一些調(diào)度,來執(zhí)行模型。對模型也要做調(diào)度,比如模型的前處理、后處理。基于底盤信號,要做自測里程計,用到Odom。有了感知結(jié)果和Odom之后,會做感知結(jié)構(gòu)化,進而可以做動/靜態(tài)的目標重建、自車的位姿估計。
同時,為了做軟件2.0,整個的數(shù)據(jù)閉環(huán)能夠以數(shù)據(jù)驅(qū)動迭代算法,還要在端上做數(shù)據(jù)緩存。對于一些特定的數(shù)據(jù)做數(shù)據(jù)觸發(fā),把緩存信號再發(fā)出去。這個過程都是需要軟件來做的,后面也會逐一的進行拆解:先是傳感器的部分,后面講硬核調(diào)度,然后是偏算法的Odom和感知結(jié)構(gòu)化。
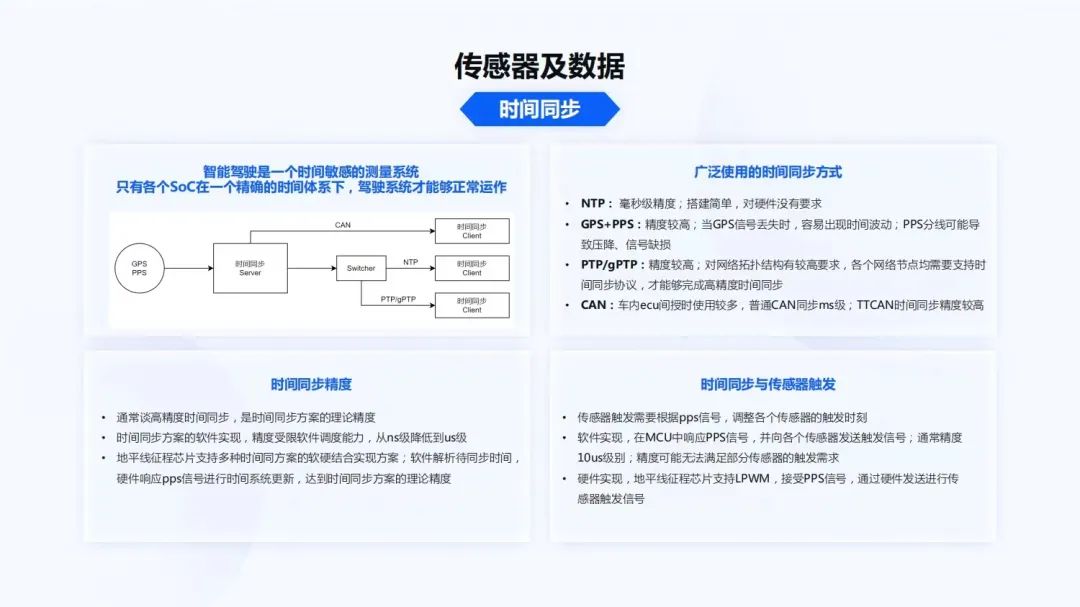
首先是傳感器和數(shù)據(jù)。第一點要看的是時間同步。智能駕駛是一個時間敏感的測量系統(tǒng)。這里有兩個詞,一個是“時間敏感”,一個是“測量”。因為對于智能駕駛來說,如果時間錯了50毫秒、100毫秒,整個計算結(jié)果就會有非常大的誤差。同時,環(huán)境感知也是測量環(huán)境中不同目標距離自車的相對位置、速度、加速度等信息,它們對于時間都有一個非常重要的定義。只有各個SoC都在一個精確的時間體系下,智能駕駛才能夠正常運作。
廣泛使用的時間同步方式,有NTP。NTP通常在毫秒級精度搭建比較簡單,對硬件也沒有要求,但NTP通常會受網(wǎng)絡(luò)環(huán)境波動的影響,時間調(diào)整會比較大。GPS+PPS用到的也比較多,雖然精度比較高,但是當(dāng)GPS信號丟失時,非常容易出現(xiàn)時間的波動。比如在山里面經(jīng)常有隧道,有的隧道比較長,過一個隧道有可能GPS信號會丟失,當(dāng)GPS信號再次獲取時,時間就很容易出現(xiàn)波動。同時,PPS信號也是時間同步非常重要的一個描述發(fā)源。如果一個系統(tǒng)里只有GPS和PPS,給多個觸發(fā),PPS分線也會導(dǎo)致一些壓降、信號缺損。PTP/gPTP精度比較高,但對網(wǎng)絡(luò)拓撲結(jié)構(gòu)要求也會比較高,各個網(wǎng)絡(luò)節(jié)點均需要支持時間同步協(xié)議,才能夠完成高精度的時間同步。在CAN系統(tǒng)里面,車內(nèi)ECU間授時使用較多,普通CAN時間同步在ms級,TTCAN也會把時間同步的精度提高到微秒級精度。
如上圖左上角所示,通常一個系統(tǒng)都會是GPS+PPS作為一個獨立的時間源,之后會有一個時間同步的Server,然后作為一個Master,經(jīng)過一些Switcher,然后給各個Slave節(jié)點或者Client做時間授時。
對于時間同步的精度,通常談到的高精度時間同步是一個理論的精度。GPS理論的時間同步精度很高。如果是純軟件實現(xiàn),接收一個PPS的脈沖信號時,就會受限于軟件的調(diào)度能力,精度也會從ns級降低到us級。而在地平線的征程芯片中,為了能夠讓整個系統(tǒng)有更高的時間同步精度,會以軟硬結(jié)合的方式實現(xiàn)。對于軟件來說,會解析一個待同步的時間,硬件響應(yīng)PPS信號,然后在硬件的方案下,直接對整個啟動時間進行更新,達到時間同步方案的理論精度。
同時,由于時間同步有一個PPS,所以時間同步往往也和傳感器觸發(fā)相關(guān)。很多的傳感器都依賴于PPS信號調(diào)整傳感器的一些相位差,來達到時間同步的精度和傳感器的對齊精度。
這個部分也會涉及到一些軟件和硬件的差別。對于軟件實現(xiàn)來說,通常需要在周期比較穩(wěn)定的MCU中響應(yīng)PPS信號,然后向各個傳感器發(fā)送觸發(fā)信號。而這種觸發(fā)信號對于MCU來說,達到10us級就已經(jīng)比較高了。但這個精度仍然無法滿足部分傳感器的觸發(fā)要求,因為有的傳感器在曝光觸發(fā)時,觸發(fā)條件非常高,要求觸發(fā)信號在幾us級別內(nèi)。如果觸發(fā)信號沒有達到精度,有可能圖像會出現(xiàn)一些缺損,或者圖像出現(xiàn)一些重曝光,對后續(xù)的影響比較大。
在硬件實現(xiàn)方面,地平線征程芯片支持LPWM,可以接收PPS信號。通過硬件轉(zhuǎn)發(fā)觸發(fā)信號,也可以設(shè)置不同觸發(fā)信號的相位差,達到整車傳感器的時間同步對齊作用。
當(dāng)把所有的SoC和傳感器都做到一個時間同步精度下,下一步就看傳感器。
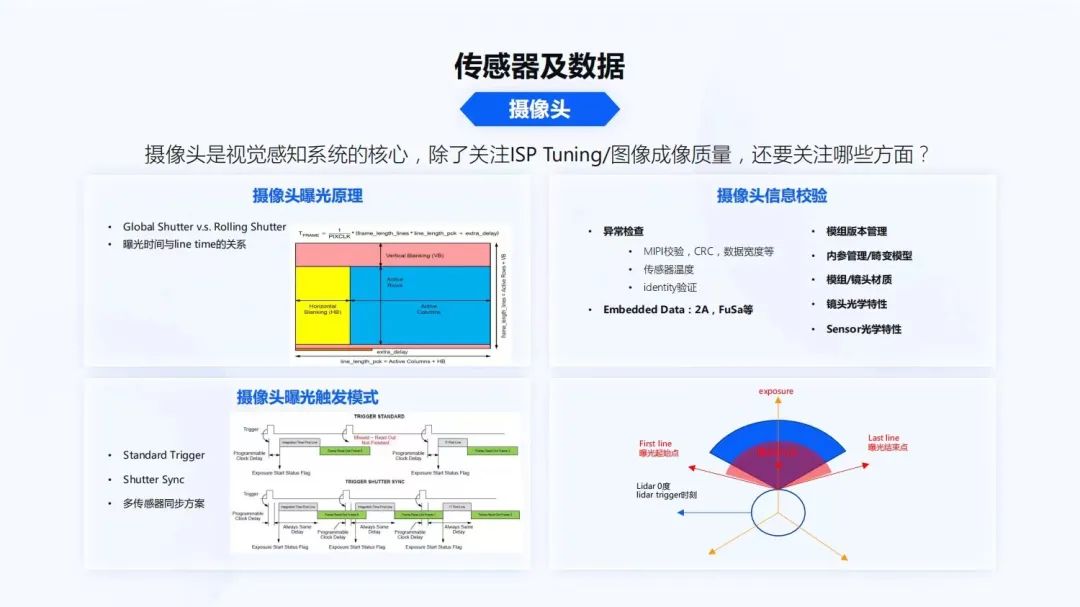
首先看攝像頭,攝像頭是視覺感知系統(tǒng)的核心。對于算法的同學(xué),可能只關(guān)注ISP Tuning和圖像的成像質(zhì)量,那除此之外還需要關(guān)注哪些方面呢?
在做一些高等級的自動駕駛算法時,目前已經(jīng)和過去的時代不太一樣。在過去傳統(tǒng)的視覺感知過程中,經(jīng)常是由人工標記2D的bounding box,然后做模型訓(xùn)練。而對于未來一些3D算法,像特斯拉最近開放了很多的BEV算法,地平線也實現(xiàn)了BEV算法,這些算法中對攝像頭的同步,及其對于時間系統(tǒng)的要求是非常高的。所以軟件工程師和算法工程師,都需要理解攝像頭的曝光原理。
Global Shutter和Rolling Shutter大家可能都會知道,但是Rolling Shutter的曝光原理到底是什么?曝光時間是我們經(jīng)常提到的ISP曝光控制時間,它和每行傳感器的數(shù)據(jù)生成時間到底是什么關(guān)系?一幀數(shù)據(jù)生成,比如曝光時間是10毫秒和一幀數(shù)據(jù)生成的30毫秒,關(guān)系到底是什么?傳感器中間的時序到底是如何設(shè)置的?這些是后續(xù)整個算法設(shè)計,視覺和其他傳感器對齊中非常重要的一點。
同時攝像頭的曝光觸發(fā)模式,也會是多種多樣的。比如一些標準的觸發(fā)模式,像Shutter Sync。剛才談到時間同步時有PPS信號,標準觸發(fā)模式一般都是接收到PPS信號,攝像頭立刻曝光觸發(fā)。Shutter Sync會有一個確定性的延遲,然后讓數(shù)據(jù)開始往外傳輸。這兩種模式得到的傳感器時間是不一樣的,它的物理的意義也是不一樣的。
在做多傳感器對齊時,不同的曝光模式對后續(xù)的算法和軟件實現(xiàn)差別都會非常大。對于軟件來說,一個攝像頭,除了曝光原理、觸發(fā)模式,還有很多其他的信息需要了解,因為對于攝像頭這種高頻的數(shù)據(jù),還有很多的異常需要做檢查。像高速接口MIPI很容易受到外部電磁的干擾;MIPI校驗,CRC校驗,每一行數(shù)據(jù)寬度的校驗;有了傳感器,它會有一些復(fù)雜的功能,傳感器內(nèi)部溫度是否過高,也需要做校驗。傳感器是否會被人調(diào)包,算法適配的傳感器是不是裝錯了,裝成了別的型號,這時還有一些傳感器的identity驗證。每幀數(shù)據(jù)在效應(yīng)區(qū),如上圖左上角的效應(yīng)區(qū),Embedded Data里有單幀的2A,F(xiàn)uSa等信息,這些都是軟件開發(fā)者需要關(guān)注的事情。
對于模組來說,還要做很多管理相關(guān)的事情,像模組的版本管理。因為在量產(chǎn)過程中,模組也會有很多的版本,它是AA對焦的?模組的對焦是什么狀態(tài)?模組的材質(zhì)、Lens內(nèi)參存儲在什么位置?機電模型到底用的是什么?模組材質(zhì)在不同的溫度下,鏡頭內(nèi)會不會起霧?Lens的光學(xué)特性,Lens會不會出現(xiàn)一些鬼影和擦散光?以上這些都是在自動駕駛開發(fā)過程中,軟件工程師需要關(guān)注的一些點,通過這些才能夠把整個系統(tǒng)串起來。
同時,多傳感器曝光在曝光原理部分就能很好地體現(xiàn)出來。如上圖右下角所示,一個傳統(tǒng)的機械激光雷達,處于一個360度掃描的狀態(tài)。Lidar在0時刻掃描時,攝像頭到底從哪個時刻要觸發(fā)曝光,到底是選擇用Standard trigger還是Shutter Sync,這都是整個系統(tǒng)中軟件工程師需要明確討論的內(nèi)容。
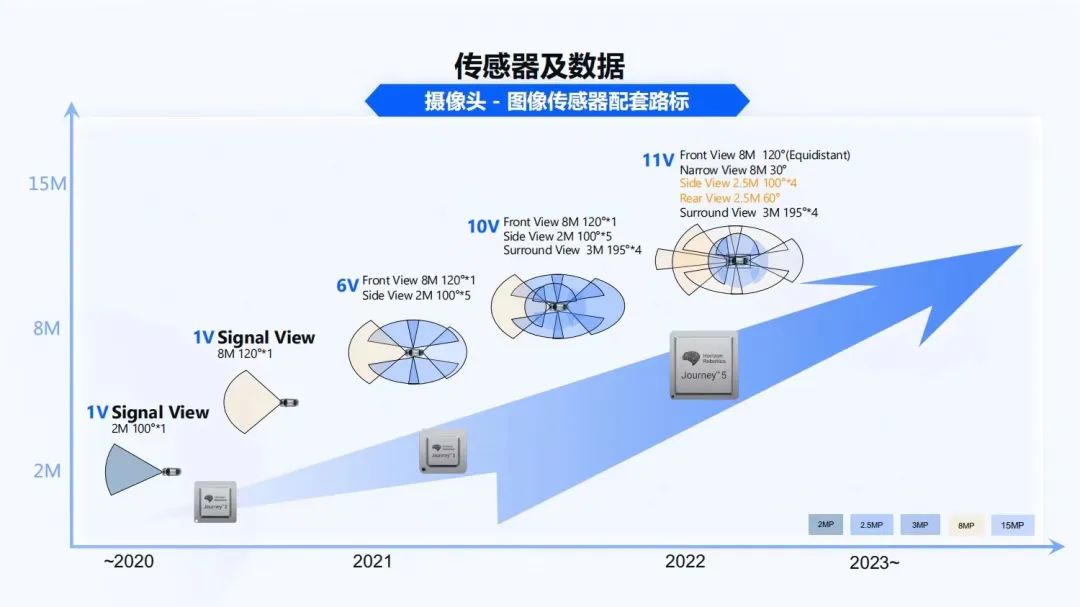
不同的方案對于地平線來說,從征程2、征程3到征程5,它們在逐漸覆蓋越來越復(fù)雜的智能駕駛系統(tǒng)。從1V的2M攝像頭、到1V的8M攝像頭,到6V,再到后面10V、11V,最終能夠做一個完整的自動駕駛產(chǎn)品。從上圖可以看出,攝像頭在這里扮演著非常重要的角色,而且攝像頭的復(fù)雜程度也會越來越高。對于不同的攝像頭,都要理解不同攝像頭的曝光原理、觸發(fā)模式,各種安全校驗,這是非常復(fù)雜的。
那如何簡化這個過程呢?地平線有一些傳感器認證的方案,經(jīng)過認證方案的傳感器,它們都經(jīng)過前面提到的模式驗證,能夠很好的和地平線軟件、算法、以及芯片做匹配,能夠幫我們的用戶,盡可能把多個 攝像頭、多類型傳感器更好的搭建起來。

對于激光雷達來說,有哪方面的應(yīng)用呢?高階自動駕駛可能會選擇激光雷達作為感知傳感器,低階自動駕駛會使用激光雷達作為一個真值系統(tǒng)。而現(xiàn)有的2.5D/3D算法方案,都會使用激光雷達真值做自動化的數(shù)據(jù)標注方案。
激光雷達有很多不同的種類,比如有機械激光雷達,如上圖左下角所示,是一個360度旋轉(zhuǎn)的激光雷達。激光雷達可以接收時間同步的PPS信號來調(diào)整馬達轉(zhuǎn)速,讓激光雷達在它的坐標系定義的0度上,和0時刻對齊。還有一些固態(tài)/半固態(tài)激光雷達,比如MEMS,在MEMS內(nèi)會把它劃分成多區(qū),然后進行掃描。MEMS的好處是多區(qū)可以同時掃描,但區(qū)塊之間會有一些overlap和重影。旋轉(zhuǎn)鏡跟機械激光雷達的精度差不多,也是旋轉(zhuǎn)的形式,從左至右掃描過去。也有一些非重復(fù)的、非規(guī)則的掃描,而得到的點云對于人來說,直觀理解會比較困難。也有純固態(tài)的Flash激光雷達,激光點陣模擬camera曝光方式進行掃描。
對于激光雷達的掃描方式,也都需要時間同步。通過PPS調(diào)整激光雷達和不同攝像頭曝光時刻的角度去對齊,達到右下角圖所示的情況。每一個點經(jīng)過時間對齊、傳感器之間的標定,能夠讓激光雷達的點云與視覺實現(xiàn)一個完全對齊的方案。
激光雷達在部署過程中,也會經(jīng)常會遇到很多問題。激光雷達目前主要使用UDP協(xié)議,UDP協(xié)議網(wǎng)絡(luò)帶寬的負載會比較高,使用時也需要設(shè)置網(wǎng)絡(luò)環(huán)境/VLAN隔離;Lidar網(wǎng)絡(luò)包比較小,一般是一個MTU發(fā)一包數(shù)據(jù),這就會導(dǎo)致網(wǎng)絡(luò)包非常多,網(wǎng)絡(luò)中斷響應(yīng)也會非常多,影響整個系統(tǒng)的響應(yīng)能力;未來征程芯片也會支持硬件網(wǎng)絡(luò)拆包來解決這些的問題。
激光雷達在使用的過程中,也會遇到非常多的問題。雖然激光雷達的精度是比較高的,但使用過程中會碰到各種的鏡面反射,你將會得到一些預(yù)期不到的點。比如地面反射到其他的地方,或者通過車窗直接反射到遠處,或更遠的一些相鄰車,到雨、雪、霧、柳絮、臟污等。激光雷達在高速上比較不幸時,有些小蟲子可能會撞上激光雷達,導(dǎo)致傳感器出現(xiàn)一些故障;以及激光雷達對不同的物體,反射值也是不一樣的。通常我們也會設(shè)置不同反射值的映射,對于不了解激光雷達的開發(fā)者來說,有時拿到一些反射值可能會覺得比較奇怪,為什么有的反射值這么高,有的反射值這么低。
對于非純固態(tài)激光雷達,供電穩(wěn)定性也會是一個很大的問題,在實車環(huán)境的供電系統(tǒng)不是特別好。如果做不到穩(wěn)定的激光雷達供電,有可能也會導(dǎo)致光頭或者機械元件出現(xiàn)異常,從而導(dǎo)致點云出現(xiàn)異常。同時,也需要關(guān)注多傳感器對齊,這些對于軟件開發(fā)來者來說,都是非常重要的工作。
激光雷達在高頻的UDP數(shù)據(jù)包情況下,協(xié)議解析如何做到非常低的延遲,盡可能地降低CPU負載,都是軟件開發(fā)者需要關(guān)注的事情。同時,傳感器和算法之間達成一致,也是在整個自動駕駛系統(tǒng)軟件開發(fā)過程中,需要上下游不停拉通、對齊的事情。
對于激光雷達,地平線也有很多合作伙伴,都能夠比較好的支持地平線的感知系統(tǒng)構(gòu)建及真值數(shù)據(jù)構(gòu)建。

自動駕駛系統(tǒng)里還有很多其他的傳感器。
首先,車身底盤信號從CAN或CANFD,能夠拿到很多車身上其他傳感器的數(shù)據(jù)。對于CAN和CANFD來說,也有很多接入方式,比如征程5代芯片上有CAN收發(fā)器,直接使用SocketCAN,來接收CAN數(shù)據(jù)。通常車上也會引入一個MCU作為網(wǎng)關(guān),MCU和SoC之間,通過SPI進行CAN協(xié)議轉(zhuǎn)發(fā)。這時就會出現(xiàn)數(shù)據(jù)鏈路長的問題,經(jīng)過網(wǎng)關(guān),SPI、OS到HAL、USER才能進行解析。
在協(xié)議中的時間敏感系統(tǒng),不同的SoC之間需要保證時間同步,以及數(shù)據(jù)的時刻到底是什么,所以協(xié)議中需要對時間有非常明確的定義。然后對于CAN大小端數(shù)據(jù)的校驗,Rolling Counter和CRC,各種信號的校驗數(shù)據(jù)有效位、閾值、數(shù)據(jù)頻率、數(shù)據(jù)更新。對于軟件開發(fā)者來說,信號的校驗是功能安全處理中非常重要的一點。
毫米波雷達和4D Image Radar。它們的數(shù)據(jù)鏈路比較多,有可能會使用CANFD,有的4D Image Radar用以太網(wǎng),也有4D Image Radar用MIPI,來降低數(shù)據(jù)傳輸延遲。數(shù)據(jù)類型也會比較多,目前大部分Radar都是目標級的,即通常輸出了跟蹤之后的目標數(shù)據(jù)。也有一些Radar能夠輸出一些原始的雷達回波信號,從廠商獲取有一定難度。4D Image Radar目前合作廠商都會得到一些點云數(shù)據(jù),信息量與比較傳統(tǒng)的Radar相比,有明顯的提高。時間同步方面,對于不同傳感器,可以通過CAN或以太網(wǎng)進行時間同步。
對于GPS和IMU,GPS的時間同步是授時和定位系統(tǒng)必備的。不同的GPS精度差異也比較大;不同型號的RTK,定位精度在5厘米、10厘米、20厘米級別;不同的IMU精度差異也比較大,有溫飄。數(shù)據(jù)接口通常為UART、SPI和I2C,這些接口都是相對比較低速的,特別UART在查詢時,整個數(shù)據(jù)鏈路都會比較慢,穩(wěn)定性相對較差;而且對于IMU來說,通常不具備授時能力,IMU基于內(nèi)部時鐘進行數(shù)據(jù)處理;對于一個數(shù)據(jù)敏感系統(tǒng)不穩(wěn)定的數(shù)據(jù)鏈路來說,需要使用IMU內(nèi)部時間進行數(shù)據(jù)的時間校驗和優(yōu)化。
超聲波雷達通常會用于一些低速的避障場景,與感知進行融合,但超聲波都不具備時間同步的能力,對于低速場景來說還是可以接受的。
前面更多的是講到傳感器自身以及傳感器的時間同步。多傳感器以及多類型的傳感器,就需要做好傳感器標定。

單傳感器標定方面有產(chǎn)線標定,通常在一輛汽車下線時,在產(chǎn)線中會有一個產(chǎn)線標定房,如上圖左上角所示,這張圖片是地平線的一個早期的標定間,它更多是校驗自己的算法。售后標定是車可能會出現(xiàn)一些問題,進行一些換件,在4S店進行的標定;對于在線標定,車輛可能會有一些胎壓變化,或經(jīng)過長時間的熱脹冷縮帶來的傳感器的姿態(tài)發(fā)生變化。車輛的負載變化,都需要對傳感器進行在線標定以及動態(tài)標定。
多傳感器標定對系統(tǒng)的時間精度要求非常高,如果所有的傳感器不在一個時間系統(tǒng)下,很難獲得比較精確的時間;同時,攝像頭、激光雷達的掃描方式不同,需要理解多傳感器數(shù)據(jù)的生產(chǎn)原理,保障多傳感器的時間是對齊的;也要理解應(yīng)該如何做傳感器數(shù)據(jù)的時間補償,如何讓多傳感器達到對齊的效果;最后,還需要多傳感器的聯(lián)合標定算法。
在這個過程中,一方面是標定算法的精度,另一方面,工程化是非常重要的,特別是在產(chǎn)線標定過程中,如果工程化出現(xiàn)了問題,產(chǎn)線會被block,非常影響效率。
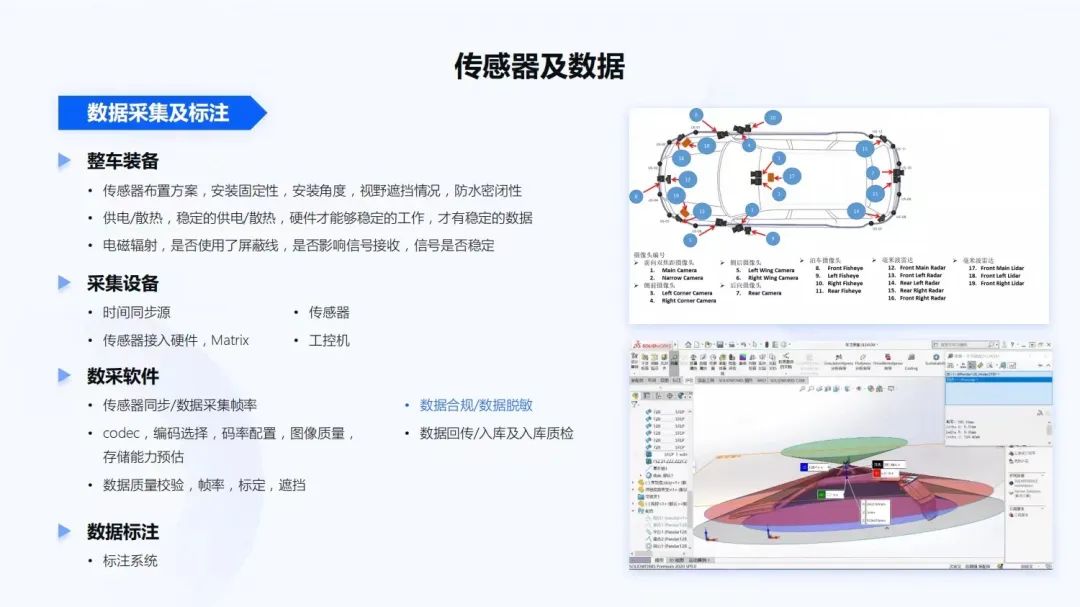
前面提到的軟件和一些基礎(chǔ)性算法都準備好之后,可以開始準備數(shù)據(jù)采集或標注,進一步打造自動駕駛系統(tǒng)。
在安裝傳感器方面,首先需要整車裝備。在傳感器的布置方案中,檢查安裝不同傳感器是否足夠的固定,會不會天氣一熱膠就軟了;安裝的角度和系統(tǒng)的需求是否一致的,是否都能夠達到我們的期望。還有在安裝過程中,視野是否有遮擋,比如此前經(jīng)常要做一些數(shù)模方案,看傳感器的感知范圍內(nèi),是否會被車身所遮擋。整個安裝方案是否防水密閉,像最近北京下暴雨,如果有一輛車在這種情況下開出去,傳感器是否會進水。
在整車的供電和散熱方面,在供電不穩(wěn)定的情況下,有些傳感器不能夠正常工作。電磁輻射,比如整車傳感器比較多,線材也比較多,是否使用一些屏蔽線,是否影響了接收信號的穩(wěn)定性。
在整車的采集設(shè)備部署過程中,整車的時間同步源精度是否足夠。當(dāng)時間發(fā)生跳變時,時間同步方案是否能夠保障整個系統(tǒng)仍然能夠穩(wěn)定的運行。傳感器是否都正常的部署。對于傳感器接入了硬件,像地平線Matrix自動駕駛計算平臺,包括工控機也要錄制所有采集到的數(shù)據(jù)。
數(shù)采軟件,需要校驗傳感器同步以及數(shù)據(jù)采集幀率是否滿足算法的要求,即數(shù)據(jù)是否滿幀率。對于視覺系統(tǒng)來說,還要看codec編解碼,究竟是選擇264、265還JEPG。碼率的配置、圖像的質(zhì)量是否滿足算法的要求。不同的碼率配置、不同的數(shù)據(jù)格式,對整個存儲帶寬的影響都特別大。未來可能經(jīng)常會看到一個11V、3L、5R的智能駕駛系統(tǒng),它一秒的數(shù)據(jù)量可能都會達到GB級,存儲能力、磁盤寫入能力是否足夠,如果不足夠,應(yīng)該如何改造。甚至軟件開發(fā)者要關(guān)注IO系統(tǒng)應(yīng)該如何做優(yōu)化,如通過數(shù)據(jù)緩存優(yōu)化IO效率。
對于數(shù)據(jù)質(zhì)量,即圖像的質(zhì)量、激光雷達的質(zhì)量、傳感器的時鐘,標定是否對齊。如果采集回來的數(shù)據(jù)達不到這些質(zhì)量,需要判定這些數(shù)據(jù)對后續(xù)算法到底是否可用。同時,對于數(shù)據(jù)來說,有一個非常重要的點,要符合法律法規(guī),要使用合規(guī)的數(shù)據(jù)庫,采集時也要做數(shù)據(jù)脫敏,不要有任何法律上的問題。以及在數(shù)據(jù)回傳之后,也要有一些回傳入庫和入庫質(zhì)檢的步驟。數(shù)據(jù)入庫之后,批量數(shù)據(jù)才能夠進行標注。對于標注系統(tǒng),如果能夠全自動化的標注,效率肯定是最高的,另外人工校驗也是非常重要的。

那有了數(shù)據(jù)文件之后,該怎么把它用起來呢?這時還需要很多的數(shù)據(jù)工具,需要開發(fā)各種數(shù)據(jù)訪存SDK,像視覺數(shù)據(jù)、雷達數(shù)據(jù),它們的文件size都是非常大的,在數(shù)據(jù)的訪問、查詢、跳轉(zhuǎn)、反序列化過程中,或解碼過程中,效率是否足夠高。對于數(shù)據(jù)的統(tǒng)計能力,數(shù)據(jù)幀率、延遲、關(guān)鍵信號的穩(wěn)定性,底盤數(shù)據(jù)是否丟失,數(shù)據(jù)轉(zhuǎn)碼效率是否會很高,是否能夠很明確的給這些數(shù)據(jù)一些label,讓下游真正的把數(shù)據(jù)用起來。
對于數(shù)據(jù)調(diào)試和profile工具,當(dāng)拿到一個數(shù)據(jù)時,可以構(gòu)成各種信號的topic,是否能夠很好的關(guān)注這些topic的波形圖。對于數(shù)據(jù)來說,是否能夠分析實際運行過程中的WCET,進而分析執(zhí)行時間。由于數(shù)據(jù)都是在后臺運行,所以也需要展示工具,展示圖像、感知結(jié)果、3D信息、點云。在車內(nèi)也需要有HMI,如上圖右半部分所示,是點云數(shù)據(jù)和HMI的展示狀態(tài)。
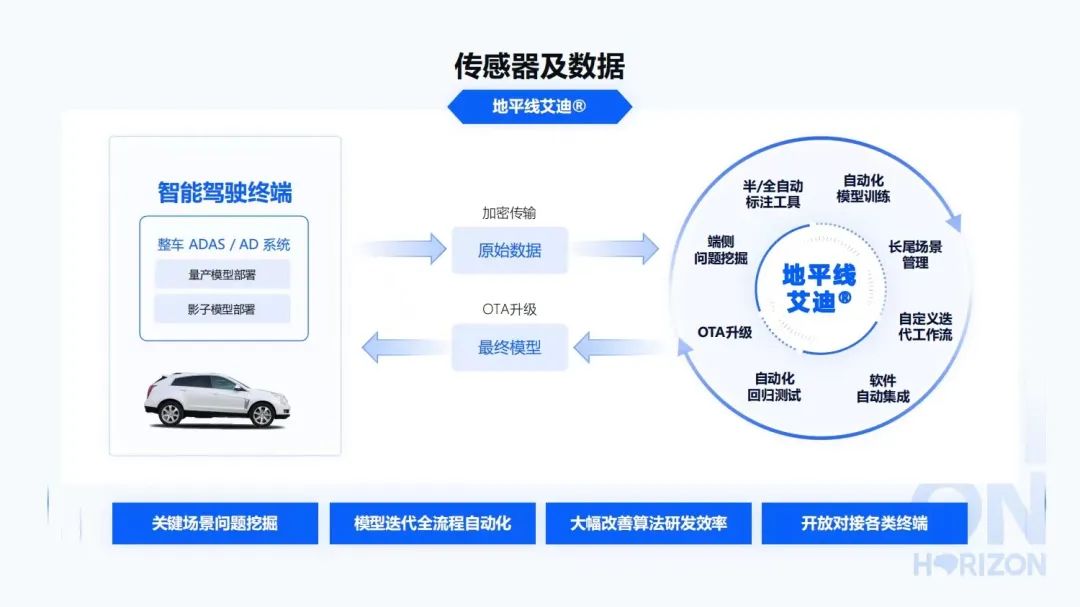
地平線艾迪平臺,能夠支撐完整的數(shù)據(jù)閉環(huán)鏈路。在智能駕駛終端上部署整個地平線的智能駕駛軟件,然后通過數(shù)據(jù)觸發(fā)、關(guān)鍵場景的問題挖掘,能夠把這些經(jīng)過脫敏之后的原始數(shù)據(jù)加密傳輸。之后在云端能夠進行端側(cè)的問題挖掘,半自動或者全自動的標注工具進行數(shù)據(jù)標注,自動化的模型訓(xùn)練,長尾場景的管理,自定義迭代工作流,軟件自動集成,自動化回歸測試,OTA升級等。最后,再回歸到車上,這也是一個軟件2.0非常重要的概念。
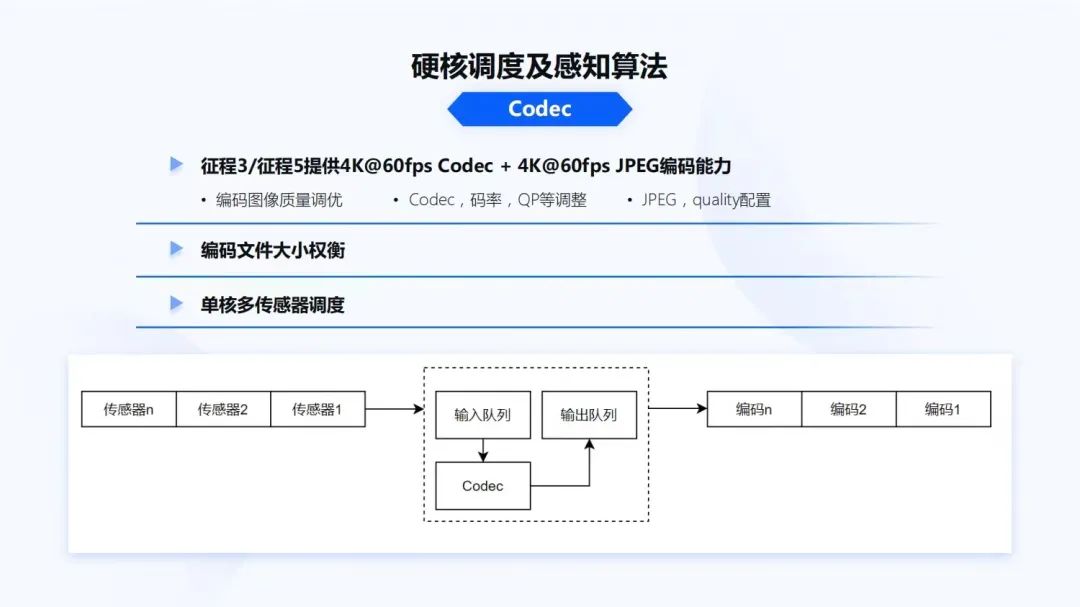
接下來講解硬核調(diào)度和感知算法部分的內(nèi)容。
硬核調(diào)度如上圖所示,今天簡單講解兩個部分,首先是Codec。
征程3和征程5提供4K@60fps Codec + 4K@60fps JPEG編碼能力。對于Codec,如果只是使用它,不會有什么問題,我們的軟件工程師需要看Codec編碼到底是做什么用的。對于數(shù)據(jù)采集來說,Codec要盡可能的調(diào)高圖像效果。
Codec碼率應(yīng)該如何設(shè)置,QP值該如何調(diào)整。如果是JPEG,quality配置究竟調(diào)成什么質(zhì)量,才能夠滿足后續(xù)算法的迭代過程。除了給算法進行訓(xùn)練,Codec還有一些DVR數(shù)據(jù)回傳的需求,當(dāng)帶寬不足時,又要權(quán)衡究竟設(shè)置什么樣的碼率和圖像質(zhì)量,能夠滿足數(shù)據(jù)傳輸?shù)膕ize要求。
通常Codec在單SoC只有一個加速硬核。但單SoC有6V、10V、11V的系統(tǒng),雖然Codec能力很強,但Codec也需要一個比較好的調(diào)度器。如上圖下半部分所示,是一個簡單的調(diào)度器,它主要是在硬件響應(yīng)過程中,與硬件交互,讓中斷更加及時響應(yīng)到用戶層。
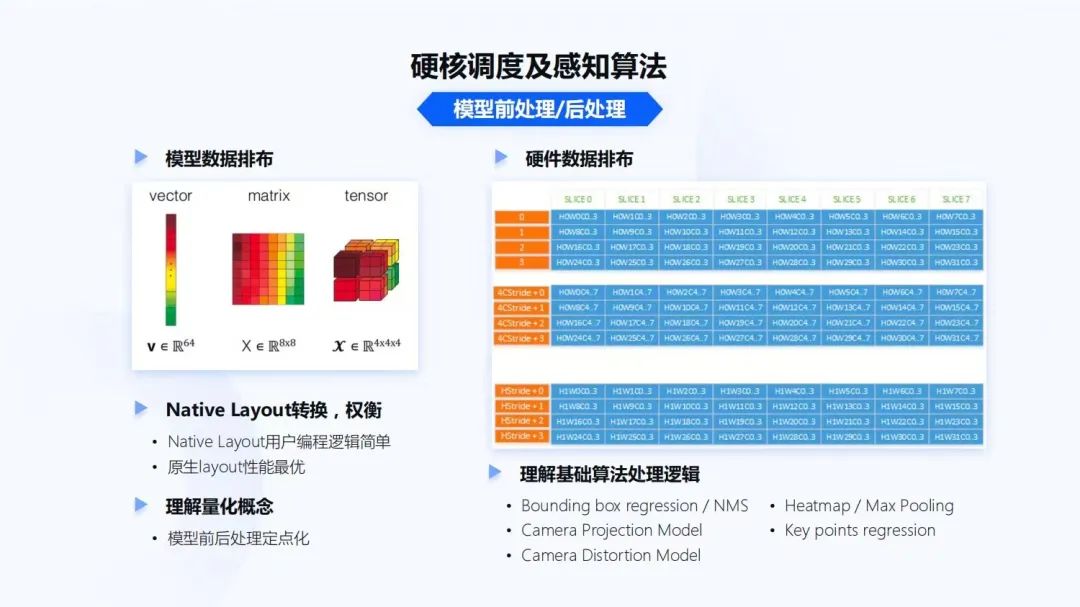
更重要的還有模型前處理、后處理以及BPU調(diào)度。通常算法開發(fā)者更多的是在云端工作,拿到一些標注好的數(shù)據(jù),訓(xùn)練模型,并通過地平線的編譯器,轉(zhuǎn)換成地平線芯片可以運行的模型文件在BPU上去運行。
對于軟件開發(fā)者來說,要調(diào)度一個模型,和調(diào)度CPU不會有本質(zhì)的差別,那差別是什么呢?是要理解算法的一些數(shù)據(jù)排布。要理解地平線芯片,在實現(xiàn)計算時這些數(shù)據(jù)排布到底是如何實現(xiàn)高效率。對于深度學(xué)習(xí)來說,數(shù)據(jù)排布通常有vector、matrix和tensor。如果對于軟件開發(fā)者來說,通常習(xí)慣將數(shù)據(jù)轉(zhuǎn)換為Native Layout(NHWC)。但對于硬件來說,硬件在輸出時,數(shù)據(jù)排布往往也不Native,轉(zhuǎn)換Native Layout往往不是最高效的。這時就要做權(quán)衡。Native Layout用戶的編程邏輯會比較簡單。但不同芯片的原生Layout,性能往往是最優(yōu)的,所以這對軟件開發(fā)者的要求也會更高,因為數(shù)據(jù)不會經(jīng)常是連續(xù)的一個數(shù)據(jù)塊會存在一個區(qū)域,另外一個數(shù)據(jù)塊會存在另外一個區(qū)域;開發(fā)者需要理解硬件原生數(shù)據(jù)存儲格式。
開發(fā)者也需要理解定點化的概念。在模型的前處理和后處理過程中,算法往往會做定點化,定點化會讓模型的效率運行的更高。對于軟件工程師來說,如果不理解這個模型本身數(shù)據(jù)輸出的含義,通常在實現(xiàn)的過程會出現(xiàn)一些代碼效率上的問題,即把定點直接轉(zhuǎn)成浮點。在模型計算過程中使用定點計算,而結(jié)果解析使用浮點計算,造成了性能上的損失。
這就要求軟件工程師理解一些基礎(chǔ)算法處理的邏輯。像Bounding box regression究竟是怎么做的,它的原理是什么?NMS是怎么做的?軟件實現(xiàn)為什么可以把整個計算過程實現(xiàn)成定點而不是浮點?即便是不同模型,也需要理解攝像頭的一些 projection model,distortion model。因為未來更多的是2.5D和3D的算法,模型inference出來后,可能會是不同坐標系下的數(shù)據(jù),需要進行坐標系轉(zhuǎn)換。
對于軟件工程師來說,如果不理解projection model和distortion model,這些數(shù)據(jù)很難轉(zhuǎn)換成駕駛系統(tǒng)里面真正上下游需要的一些數(shù)據(jù),包括一些Heatmap、Max Pooling如何實現(xiàn)?代碼的效率如何才是最高的?一些關(guān)鍵點回歸的原理是什么?這些都是對軟件工程師提的更高要求。
BPU調(diào)度,和SoC中CPU是比較類似的。CPU會有非常多復(fù)雜的任務(wù)調(diào)度。地平線征程芯片擁有雙核高性能BPU。如果一個系統(tǒng)中有11路攝像頭,通常會面臨著50~100個模型的調(diào)度。這時整個模型管理、調(diào)度編排非常重要;哪些模型是重要的?到底能不能搶占?通過軟件方案做一些模型的搶占,還是硬件方案做模型搶占?模型搶占是否會對DDR帶寬帶來一些沖擊?整個體系架構(gòu)從DDR到SRAM,再到BPU的執(zhí)行,如何才是最優(yōu)的?這些都是軟件工程師需要關(guān)注的一些點。在地平線Bole開發(fā)平臺發(fā)布EasyDNN,它可以幫用戶更好的面向復(fù)雜的模型調(diào)度、調(diào)度編排和搶占,解決相關(guān)調(diào)度上的問題。
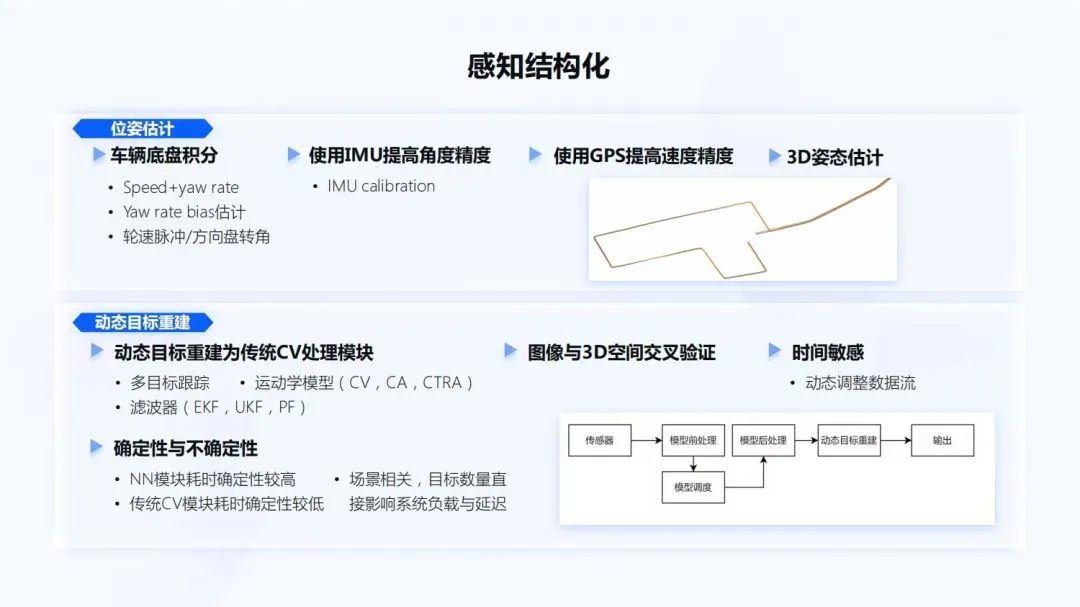
在傳統(tǒng)的感知方案中都是一些2D的方案,而現(xiàn)代的一些算法方案,不管是3D方案,還是未來的BEV的方案,都需要在模型后期,再增添一些傳統(tǒng)的CV算法。在感知模型基礎(chǔ)上,進行感知結(jié)構(gòu)化處理。
首先,要有一個自車的位姿估計。位姿估計可以使用車輛底盤積分,對于簡單的行車模式下,Speed+yaw rate就足夠了。而對于一些低速場景,還需要引入輪脈沖輪速、方向轉(zhuǎn)角等方法。對于每輛車的yaw rate,即橫擺角速度,也會存在一些bias。當(dāng)車輛處于靜態(tài)時,就會有一個靜態(tài)偏置,動態(tài)時也可能會有一個動態(tài)偏置。把 bias估計好才能夠得到一個更好的自車里程計。
同時,也可以使用IMU和GPS來提高里程計的精度。上圖右上角是一個行車的軌跡圖,它有兩種顏色,一個藍色和一個橙色,通過Odom的提高,展示出了兩種不同方法的實現(xiàn)結(jié)果。
使用IMU,還能夠進行3D姿態(tài)估計,特別是在跨層輔助泊車的場景。在這個過程中,也會遇到很多工程上的問題,對于CAN數(shù)據(jù)、底盤數(shù)據(jù)到SoC系統(tǒng)里,它的鏈路是比較長的,如何更好的提高系統(tǒng)的響應(yīng),保障Odom延遲在一個可接受的范圍內(nèi),這也是軟件工程師需要解決的一些問題。
在動態(tài)目標建模方面,要處理的是一些多目標跟蹤、運動學(xué)的建模,(CV、CA、CTRA等),以及不同的濾波器(EKF、UKF、PF等)。在處理過程中,也需要圖像空間與3D空間進行交叉驗證。同時,動態(tài)目標建模也是一個時間敏感的系統(tǒng)。對于場景的不同,會有一些不確定性。因為傳統(tǒng)CV和多目標跟蹤,它的耗時是隨著目標數(shù)量而增長的。而對于深度學(xué)習(xí),耗時的確定性是比較高的。對于軟件工程師來說,一方面需要用數(shù)據(jù)工具,profiling整個系統(tǒng),能夠動態(tài)的調(diào)整數(shù)據(jù)流,讓整個系統(tǒng)盡可能壓低負載和延遲。
同時,也要去考慮對于確定性和不確定性,后面應(yīng)該如何解決它。對于軟件2.0的系統(tǒng),或端到端的系統(tǒng)來說,需要把更多的傳統(tǒng)CV部分,轉(zhuǎn)移到深度學(xué)習(xí)模型或BPU模型,能夠被硬件確定性執(zhí)行的部分,來提高整個系統(tǒng)的確定性、穩(wěn)定性和延遲優(yōu)化。
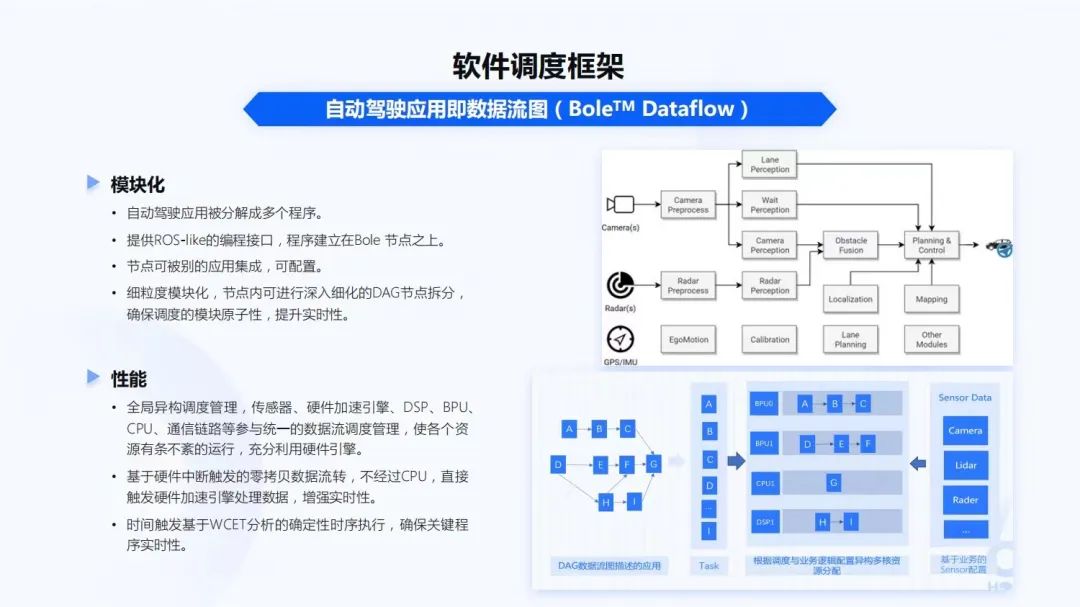
講到調(diào)度,Bole Dataflow調(diào)度框架,能夠幫助開發(fā)者快速構(gòu)建自動駕駛應(yīng)用數(shù)據(jù)流圖。整個系統(tǒng)里會有各種的傳感器、硬核調(diào)度、傳統(tǒng)CV的處理模塊。各個的模塊都會有自己的執(zhí)行單元,整個自動駕駛應(yīng)用也被分解成很多的程序。
Bole Dataflow調(diào)度框架,也提供ROS-like的編程接口。為什么是ROS-like?因為對于很多自動駕駛算法開發(fā)者,特別是學(xué)校里的一些同學(xué),他們在學(xué)校上學(xué)時都是用ROS,所以ROS-like能夠讓這些算法開發(fā)者更容易的在嵌入式上進行開發(fā)。程序整個建立在Bole Dataflow的節(jié)點之上,節(jié)點可以被應(yīng)用集成、被配置。同時,也會在細粒度的模塊化節(jié)點內(nèi),進行深入細化的DAG節(jié)點拆分,確保調(diào)度模塊的原子性,提升實時性。像上圖右下角,就是DAG數(shù)據(jù)流圖描述的應(yīng)用。
在SoC上,也有很多的硬核,不同的硬核都有不同的計算能力和性能。全局異構(gòu)調(diào)度管理,傳感器、硬件加速引擎、DSP、BPU、CPU、通信鏈路等參與統(tǒng)一的數(shù)據(jù)流調(diào)度管理。只有把所有的調(diào)度管理統(tǒng)一起來,才能使各個資源有條不紊的運行,充分利用硬件引擎。這樣基于硬件中斷觸發(fā)的零拷貝數(shù)據(jù)流轉(zhuǎn),不經(jīng)過CPU,直接觸發(fā)硬件加速引擎處理數(shù)據(jù),來增強實時性。而時間觸發(fā)基于WCET分析的確定性時序執(zhí)行,確保關(guān)鍵程序的實時性。

在多個模塊、多個進程,甚至多個SoC的過程中,除了調(diào)度,通訊也是非常重要的。Bole Communication通訊框架,支持集成多種消息中間件DDS、ZeroMQ、AutoSAR ARA::COM、PCIe等。關(guān)于PCIe,由于未來還有跨SoC、多SoC這種非常大量的數(shù)據(jù)傳輸。面向未來的架構(gòu),在多SoC時,數(shù)據(jù)傳輸通常是在幾十兆每幀級的feature map,而傳統(tǒng)的以太網(wǎng)肯定不能很好的承載。PCIe在未來會是一個非常重要的數(shù)據(jù)通訊鏈路。
Bole也會提供Zero-Copy共享內(nèi)存通信機制,同時也會內(nèi)置一些自適應(yīng)通信策略,來保障節(jié)點部署是一個最佳通訊的模式。Bole提供多平臺的支持。開發(fā)者除了在地平線的芯片上開發(fā),還會在不同設(shè)備上進行開發(fā)。很多的算法開發(fā)者在做算法開發(fā)時,不管是調(diào)度框架還是通訊框架,在個人的電腦集群上都需要提供編譯、調(diào)試能力。同時,對于通訊來說,算法在集群上做模型訓(xùn)練,也可以通過Python接口,讓算法簡單的替換嵌入式模塊的一個程序,這樣也能夠快速的進行算法原型驗證。
調(diào)度和通訊是大的框架級別,再深入是每一個Node。如果一個Node的運行時間過長,什么樣的調(diào)度框架和通訊框架都很難進一步的提升性能,所以軟件性能優(yōu)化也是整個軟件團隊非常重要的一部分,這一塊也需要非常深入的了解才能夠完成。
做軟件的性能優(yōu)化,需要理解芯片的一些架構(gòu)設(shè)計。首先,需要理解整個Memory Hierarchy,即整個內(nèi)存的層級系統(tǒng),也需要理解總線帶寬、DDR帶寬、DDR控制器到底是如何運作的,還有DDR工作模式。因為現(xiàn)在大算力的SoC,DDR通常是雙通道和多通道,DDR到底是運行在并發(fā)模式,還是在其他的模式下運行,DDR的QoS到底給哪個硬核才能讓它的響應(yīng)最高,這些都需要考慮到。
對于CPU來說,CPU L2 Cache,L1 Cache工作模式是什么,各級Cache Size對系統(tǒng)性能影響是什么?系統(tǒng)中什么樣的數(shù)據(jù)需要自動去刷新,什么樣的數(shù)據(jù)不需要?對于BPU來說,一個模型有多級的SRAM,它的工作機制、模型調(diào)度與IO之間的overhead到底是什么樣子的?
對于DSP來說,又會出現(xiàn)一個TCM,TCM和DDR之間使用DMA。對于TCM的使用,到底是使用什么樣子代碼固化在TCM上,什么樣的代碼固化到DSP的cache上。
以上這些對整個的系統(tǒng),整個Memory帶寬、軟件性能有非常大的影響。
同時,要理解整個芯片設(shè)計的Interrupt Hierarchy。當(dāng)一個系統(tǒng)里有十幾個攝像頭、幾個激光雷達,整個系統(tǒng)的中斷是非常多的。我們的軟件究竟如何配置中斷,中斷和CPU之間中斷響應(yīng)是如何綁定的?
也需要在純計算優(yōu)化的方式上,深入理解向量化編程。向量化編程一般都稱它為SIMD,在ARM上有NEON,在PC上有SSE以及DSP這種SIMD指令,這都是非常重要的軟件優(yōu)化手段。
內(nèi)存訪問需要靜態(tài)化。因為現(xiàn)在大家開發(fā)都在 OS以上,不管是Linux也好,QNX也好,對內(nèi)存的靜態(tài)化非常重要。特別是在QNX系統(tǒng)上開發(fā),QNX對內(nèi)存每次申請釋放都會有很多的安全性校驗,如果是太多的碎面化內(nèi)存,整個系統(tǒng)的overhead會非常重。
CPU計算的定點化。定點運算肯定比浮點運算要快,什么樣的算法能夠定點化,這也是軟件工程師和算法工程師需要去深入溝通的。系統(tǒng)里到底哪一部分算法是非常重的overhead,能否把它定點化實現(xiàn)。
對于整個復(fù)雜的自動駕駛系統(tǒng),像11V、3L的系統(tǒng),它的線程/進程非常多。線程和進程的優(yōu)先級到底是什么樣子?在一個實時系統(tǒng)里面,不同的功能模塊的實時優(yōu)先級配置,線程是否能夠合并、綁定。
在系統(tǒng)整個的通訊優(yōu)化方面,因為系統(tǒng)里面會有各種各樣的信號,可能會有非常高的高頻信號,也有一些低頻信號,哪些信號是可以合并的,哪些高頻信號可以做一些打包。例如可以把一些高頻信號,比如每個信號都是100赫茲,有幾十個信號能否把它們?nèi)看虬梢粋€100赫茲,減少通訊的開銷。
更高要求是一些算法復(fù)雜度的優(yōu)化。算法復(fù)雜度的優(yōu)化,通常有可能把一個算法耗時降低一個數(shù)量級。
最痛苦的有可能就是純代碼級的優(yōu)化。因為需要在代碼中一個點一個點去check,發(fā)現(xiàn)到底有哪些點可以再進一步的優(yōu)化,能夠把系統(tǒng)的性能進一步的提升。特別是量產(chǎn)的最后階段,有可能花很長的時間都是零點幾個點的CPU降低,但這也是非常值得的。
綜上所述,在地平線各代的征程芯片上,上面講到的各種軟件相關(guān)的開發(fā)事項,遇到的各種問題,以及問題的解決,它們在地平線的量產(chǎn)落地的項目中都有體現(xiàn)。
過去地平線已經(jīng)完成了從0到1的突破,現(xiàn)在也準備和行業(yè)伙伴一起實現(xiàn)從1到N的開放共贏。大規(guī)模量產(chǎn)是驗證智能駕駛產(chǎn)品技術(shù)領(lǐng)先性的首要標準,剛剛講到了很多在量產(chǎn)過程中遇到的問題和解決這些問題的經(jīng)驗。而把這些問題和經(jīng)驗分享出來,也是希望能夠幫助大家在后續(xù)量產(chǎn)的過程中更好地應(yīng)對這些問題。
02 軟件視角的“軟硬結(jié)合”與“軟硬解耦”
新一代汽車智能芯片領(lǐng)導(dǎo)者,必須也是世界級 AI 算法公司。地平線是在2015年成立,而我是在2016年加入地平線,當(dāng)時還是處于芯片開發(fā)的初期階段。我個人也非常幸運能夠在早期加入地平線,經(jīng)歷芯片軟硬結(jié)合,協(xié)同設(shè)計的整個過程。
對于一個軟件開發(fā)者來說,當(dāng)你從市面上拿到一款芯片,芯片可能有各個不同的硬件設(shè)置,它的DDR、各個硬核的IP,深度學(xué)習(xí)芯片的一些算子,到底是不是工程上需要的,這些都無法改變。
地平線在每一代芯片的設(shè)計、BPU設(shè)計、整個SoC的設(shè)計過程中,都和我們的軟件開發(fā)者、算法開發(fā)者進行了非常深入的討論,以軟硬結(jié)合的方式,讓芯片真的是為后續(xù)的應(yīng)用場景、為軟件去服務(wù)的,即我們的芯片設(shè)計,真正的從實際場景出發(fā),從軟件中來,到軟件中去。
地平線的芯片DDR帶寬到底需要多少,BPU算力需要多少,CPU、SP、Codec等,是否真的是一個極具性價比,極具能耗比的設(shè)計?是不是能夠把AI芯片的能力在自動駕駛的系統(tǒng)里充分展示出來,這個都是在開發(fā)過程中軟硬結(jié)合的體現(xiàn)。
芯片設(shè)計出來后,面向芯片,需要在軟件層級上,從OS到基礎(chǔ)中間件,再到應(yīng)用中間件,打造不同的模塊單元,讓不同的開發(fā)者使用不同的、已經(jīng)封裝的、比較成熟的模塊。像剛才介紹在自動駕駛系統(tǒng)設(shè)計中遇到的各種各樣問題,這些模塊都能很好地解決,并提供給開發(fā)者去使用,讓開發(fā)者能夠自定義的完成他們的應(yīng)用開發(fā)。

因而,從芯片到上層的操作系統(tǒng),基礎(chǔ)中間件、應(yīng)用中間件的軟硬結(jié)合,再向上提供給我們的應(yīng)用開發(fā)者,去開發(fā)各種各樣的智能汽車應(yīng)用,達到軟硬解耦。
03 智能駕駛軟件開發(fā)平臺Horizon TogetherOS Bole
在征程5芯片發(fā)布時,也發(fā)布了TogetherOS,Bole是TogetherOS中的應(yīng)用中間件部分,即軟件開發(fā)平臺。Horizon TogetherOS Bole是面向高等級自動駕駛的軟件開發(fā)平臺及中間件。
首先,介紹下高等級自動駕駛系統(tǒng)面臨的難點與挑戰(zhàn)。第一,自動駕駛車載軟件的架構(gòu)復(fù)雜度是陡增的。在過去的兩三年,L2級別單目的視覺系統(tǒng)比較主流。而從2021年開始,一輛車裝載多個攝像頭,完成NOA(領(lǐng)航輔助駕駛)等功能,已經(jīng)逐漸開始是一個標準化的過程。未來到城區(qū)自動駕駛,傳感器會越來越多,整個自動駕駛的車載軟件架構(gòu)設(shè)計,復(fù)雜度也是陡增的。在快速迭代過程中,如何能夠提高開發(fā)效率,實現(xiàn)快速的復(fù)制,加速量產(chǎn)開發(fā)的進程,都是會變得非常重要。
第二,自動駕駛平臺軟件關(guān)鍵技術(shù)還沒有標準化。傳統(tǒng)車載應(yīng)用軟件的開發(fā)范式,很難做到以數(shù)據(jù)為中心的數(shù)據(jù)閉環(huán)。整個數(shù)據(jù)閉環(huán)過程中,傳統(tǒng)的軟件開發(fā)方式會顯得比較困難。AutoSAR AP、ROS等高等級自動駕駛場景還處在初期摸索階段。在落地過程中,各有千秋,目前行業(yè)中還沒有形成統(tǒng)一的面向高等級自動駕駛的軟件開發(fā)平臺及中間件。
第三,高等級自動駕駛也需要更高的安全性保障。關(guān)于功能安全部分,此前也有同事有過相關(guān)的分享。
最后,高等級自動駕駛也需要高算力的支撐。L3+自動駕駛算法復(fù)雜度及功能安全的冗余設(shè)計,隨著自動駕駛等級的提高,其所需算力呈指數(shù)提升,需要BPU/DSP等異構(gòu)執(zhí)行單元對算法進行加速。同時,當(dāng)前單芯片的很難滿足算力要求,多個異構(gòu)芯片混合,軟件與計算平臺協(xié)同也變得越來越困難,自動駕駛計算平臺的有效算力很難得到充分發(fā)揮。以上這些都是高級自動駕駛系統(tǒng)面臨的一些難點和挑戰(zhàn)。
總結(jié)一下,需要安全可靠、極致效能,簡單易用,而且也要面向下一代智能駕駛,是一個能夠很好達成軟件開發(fā)的系統(tǒng),而且也需要是一個開放且兼容的系統(tǒng)。
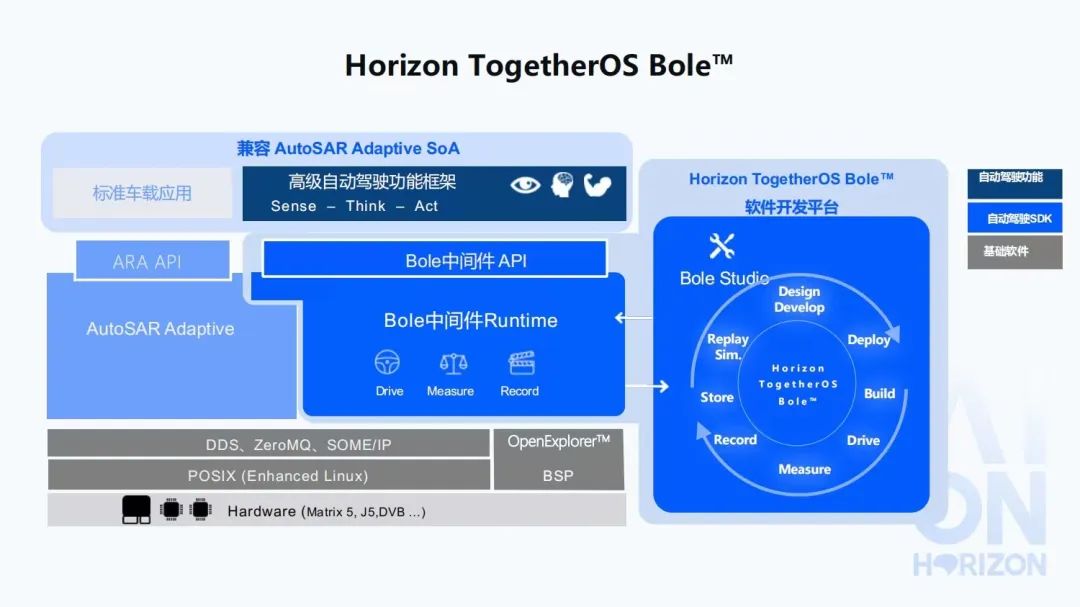
Bole,希望能夠解決自動駕駛量產(chǎn)軟件開發(fā)中的難題,面向高等級自動駕駛,完成上圖右半部分所示的數(shù)據(jù)閉環(huán)、軟件2.0的開發(fā)方式,能夠做到數(shù)據(jù)的錄制、實際的開發(fā),然后部署。我們將Design、Develop、Deploy、Build、Drive,Measure,Record,Store等等,把它整個閉環(huán)起來,和艾迪平臺一起,配合著完成數(shù)據(jù)閉環(huán)。

Bole會產(chǎn)出一套面向高等級自動駕駛的開發(fā)范式;BoleStudio IDE,能夠把不同的模塊、不同的node,以DAG的形式展現(xiàn)出來;BoleViewer,能夠完成數(shù)據(jù)可視化;還有一些數(shù)據(jù)工具,像Recorder、Repaly、SensorCenter;包括車身的一些通訊VehicleIO;也有之前談到的Bole Dataflow調(diào)度框架,通訊框架Communication,BPU調(diào)度框架EasyDNN等,它們都是為了能夠快速的開發(fā)和集成。同時,HobotCV也是面向征程芯片不同的硬核計算單元,提供高效的接口抽象。
數(shù)據(jù)閉環(huán),也是以數(shù)據(jù)驅(qū)動開發(fā),助力自動駕駛應(yīng)用快速落地。在實車的環(huán)境下,要實時抓取傳感器的數(shù)據(jù),在實車的應(yīng)用軟件下,能夠把傳感數(shù)據(jù)與日志進行錄制,包括傳感器的標定、常規(guī)數(shù)據(jù)采集。數(shù)據(jù)回來之后,剛才也提到數(shù)據(jù)工具也會非常重要。在云端要有數(shù)據(jù)回灌的能力,特別是在云端和艾迪的配合,對于批量的數(shù)據(jù)、批量的設(shè)備來說,艾迪平臺和Bole一起協(xié)同,能夠把數(shù)據(jù)的開發(fā)、回灌、回歸、數(shù)據(jù)可視化總體整合起來。同時,也提供一個BoleStudio的AI應(yīng)用開發(fā)集成環(huán)境,能夠做到持續(xù)的改進與開發(fā)。
04 智能駕駛應(yīng)用軟件開發(fā)趨勢展望

對于自動駕駛的應(yīng)用開發(fā),未來會是什么形態(tài)呢?
在Bole之上,剛才也談到會有各種各樣不同的模塊。在Dataflow框架中也會把各種各樣的模塊,抽象成不同的一些module,或者node,可能會執(zhí)行在不同的計算單元上。有多模傳感器、攝像頭、激光雷達、毫米波雷達、超聲波雷達等。感知要在一個大的感知模塊下,要執(zhí)行BPU、傳感器,執(zhí)行傳統(tǒng)的CV算法。然后在定位地圖上,還要與做地圖的一些localization或者自身的定位信息,組成整個動靜態(tài)環(huán)境模型。在融合與規(guī)劃部分,得到自車的軌跡規(guī)劃。之后到整車控制,所有的數(shù)據(jù)可視化,包括整個的車身通訊,各種各樣的信號,這些都會是自動駕駛開發(fā)系統(tǒng)中需要實現(xiàn)的一些模塊。
如果要去做一個自動駕駛系統(tǒng),從零開始實現(xiàn)這些內(nèi)容,是非常困難的。如果能夠有一個很好的baseline,地平線也是很希望把這樣的一個baseline開放出來,能夠把我們在量產(chǎn)過程中積累的軟件開發(fā)經(jīng)驗,以這種module,或以node的形式,和各個合作伙伴一起把它作為一種開發(fā)的基礎(chǔ)模板,加速合作伙伴的量產(chǎn)過程,這樣會是一個更快的開發(fā)方式。
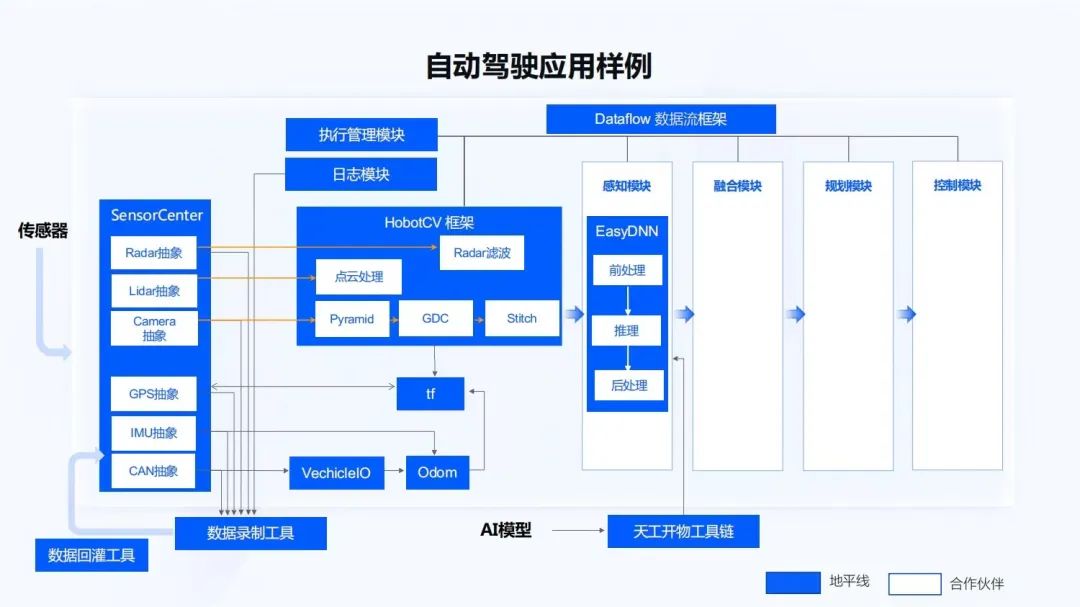
基于整個開發(fā)框架,會有各種各樣不同的模塊。上圖所示藍色的部分是地平線所做的開放框架,把在軟件框架以及量產(chǎn)工程實現(xiàn)過程中,遇到的一些經(jīng)驗和問題抽象出來,作為一些開放的框架。同時,用戶也可以自定義的完成各種不同模塊,包括一些新傳感器的接入,一些新的傳統(tǒng)CV算法的實現(xiàn),以及不同模型的前處理、后處理,都可以在我們的調(diào)度框架下完成。
同時,在整套框架的定義下,也能夠把這些感知模塊、融合模塊、規(guī)劃模塊、控制模塊的接口很好的定義抽象出來,幫助開發(fā)者快速實現(xiàn)全棧的自動駕駛開發(fā)過程。一方面,能夠在一個相對比較成熟的軟件baseline下,完成自動駕駛量產(chǎn)的開發(fā);另一方面,把我們實現(xiàn)規(guī)模化量產(chǎn)過程中的一些經(jīng)驗也分享出來,通過協(xié)同開發(fā),大幅提升開發(fā)效率,從而達到一個開放共贏的狀態(tài),加速智能駕駛應(yīng)用落地。
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論