 電子發(fā)燒友App
電子發(fā)燒友App


汽車革命的上半場是電動化,下半場是智能化,電動化只是改變了汽車的動力供給方式,并沒有改變汽車的性質(zhì),而智能化才是這場革命的主菜,將對汽車帶來顛覆性變化,汽車將由傳統(tǒng)的機械體,變?yōu)閾碛袕姶笥嬎隳芰Φ闹悄荏w。
在汽車智能化的道路上,有一個擁有絕對實力的引領(lǐng)者,那就是Elon Musk領(lǐng)導下的特斯拉,其打造的自動駕駛體系是全球關(guān)注的焦點,馬斯克曾在微博上發(fā)文稱特斯拉打造的人工智能是世界上最為先進的。
特斯拉是截止目前全球唯一一家實現(xiàn)了自動駕駛核心領(lǐng)域全棧自研自產(chǎn)的科技公司,在數(shù)據(jù)、算法、算力等各個層面打造了一套包含感知、規(guī)控、執(zhí)行在內(nèi)的全鏈路自動駕駛軟硬件架構(gòu)。
整體而言,特斯拉的自動駕駛架構(gòu)是采用純視覺方案實現(xiàn)對世界的感知,并基于原始視頻數(shù)據(jù)通過神經(jīng)網(wǎng)絡構(gòu)建出真實世界的三維向量空間,在向量空間中通過傳統(tǒng)規(guī)控方法與神經(jīng)網(wǎng)絡相結(jié)合的混合規(guī)劃系統(tǒng)實現(xiàn)汽車的行為與路徑規(guī)劃,生成控制信號傳遞給執(zhí)行機構(gòu),同時通過完善的數(shù)據(jù)閉環(huán)體系和仿真平臺實現(xiàn)自動駕駛能力的持續(xù)迭代。
下面將分別按照感知、規(guī)劃與控制、數(shù)據(jù)與仿真、算力四個部分對特斯拉實現(xiàn)FSD(Full Self-Drive,完全自動駕駛)的核心體系進行全面解析。
01 感知
根據(jù)2021年8月Tesla AI Day上的展示,特斯拉最新的感知方案采用純視覺感知方案,完全摒棄掉激光雷達、毫米波雷達等非攝像頭傳感器,僅采用攝像頭進行感知,在自動駕駛領(lǐng)域獨樹一幟。
人類通過眼睛感知世界的原理為:光線通過眼睛被視網(wǎng)膜采集信息,經(jīng)過傳遞與預處理,信息抵達大腦視覺皮層,神經(jīng)元從視網(wǎng)膜傳遞的信息中提取出顏色、方向、邊緣等特征結(jié)構(gòu),再傳遞給下顳葉皮層,然后經(jīng)過認知神經(jīng)網(wǎng)絡的復雜處理最終輸出感知結(jié)果。
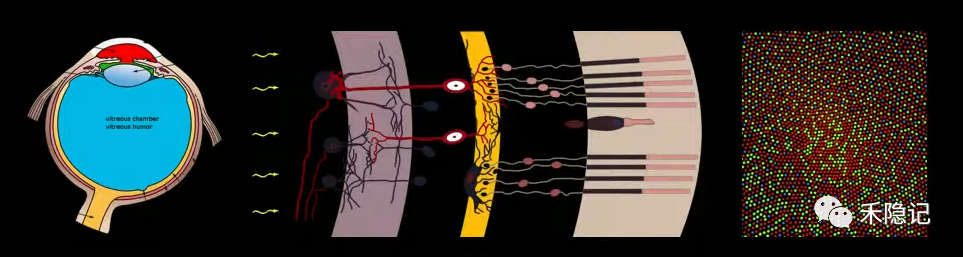
人類視覺感知原理
自動駕駛視覺感知方案是效仿人類視覺系統(tǒng)原理,攝像頭便是“汽車之眼”,特斯拉汽車共計采用八個攝像頭分布在車體四周,車身前部有三個攝像頭,分別為前視主視野攝像頭、前視寬視野攝像頭(魚眼鏡頭)以及前視窄視野攝像頭(長聚焦鏡頭),左右兩側(cè)各有兩個攝像頭,分別為側(cè)方前視攝像頭和側(cè)方后視攝像頭,車身后部有一個后視攝像頭,整體實現(xiàn)360度全局環(huán)視視野,最大監(jiān)測距離可以達到250米。

特斯拉車身攝像頭環(huán)視視野
通過“汽車之眼”采集到的真實世界圖像數(shù)據(jù),經(jīng)過復雜的感知神經(jīng)網(wǎng)絡架構(gòu)進行處理,構(gòu)建真實世界的三維向量空間,其中包含汽車、行人等動態(tài)交通參與物,道路線、交通標識、紅綠燈、建筑物等靜態(tài)環(huán)境物,以及各元素的坐標位置、方向角、距離、速度、加速度等屬性參數(shù),這個向量空間不需要和真實世界的模樣完全保持一致,更傾向于是供機器理解的數(shù)學表達。

利用攝像頭采集數(shù)據(jù)通過神經(jīng)網(wǎng)絡輸出三維向量空間
根據(jù)特斯拉在AI DAY的公開信息,經(jīng)過多輪升級迭代,特斯拉目前所采用的視覺感知框架如下圖所示,這是一套基于視頻流數(shù)據(jù)的共享特征多任務型神經(jīng)網(wǎng)絡架構(gòu),擁有物體深度識別能力和短時記憶能力。
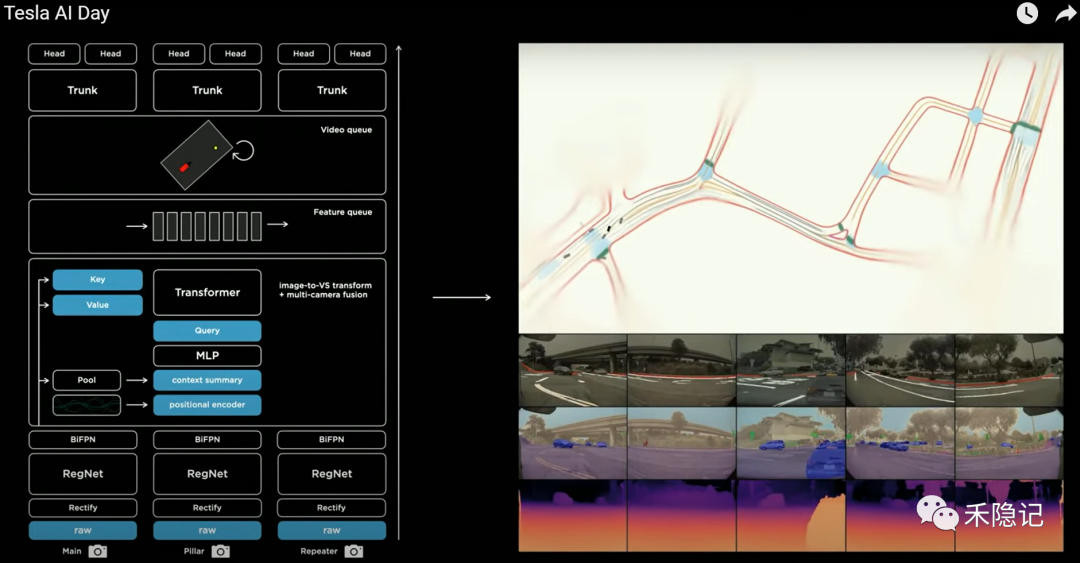
特斯拉視覺感知網(wǎng)絡架構(gòu)
網(wǎng)絡基礎(chǔ)結(jié)構(gòu):HydraNet多頭網(wǎng)絡
特斯拉視覺感知網(wǎng)絡的基礎(chǔ)結(jié)構(gòu)是由主干(Backbone)、頸部(Neck)與多個分支頭部(Head)共同組成,特斯拉取名為“HydraNet”,取意自古希臘神話中的九頭蛇。
主干層將原始視頻數(shù)據(jù)通過殘差神經(jīng)網(wǎng)絡(RegNet)及BiFPN多尺度特征融合結(jié)構(gòu)完成端到端訓練,提取出頸部層的多尺度視覺特征空間(feature map),最后在頭部層根據(jù)不同任務類型完成子網(wǎng)絡訓練并輸出感知結(jié)果,共計支持包括物體檢測、交通信號燈識別、車道線識別在內(nèi)的1000多個任務。
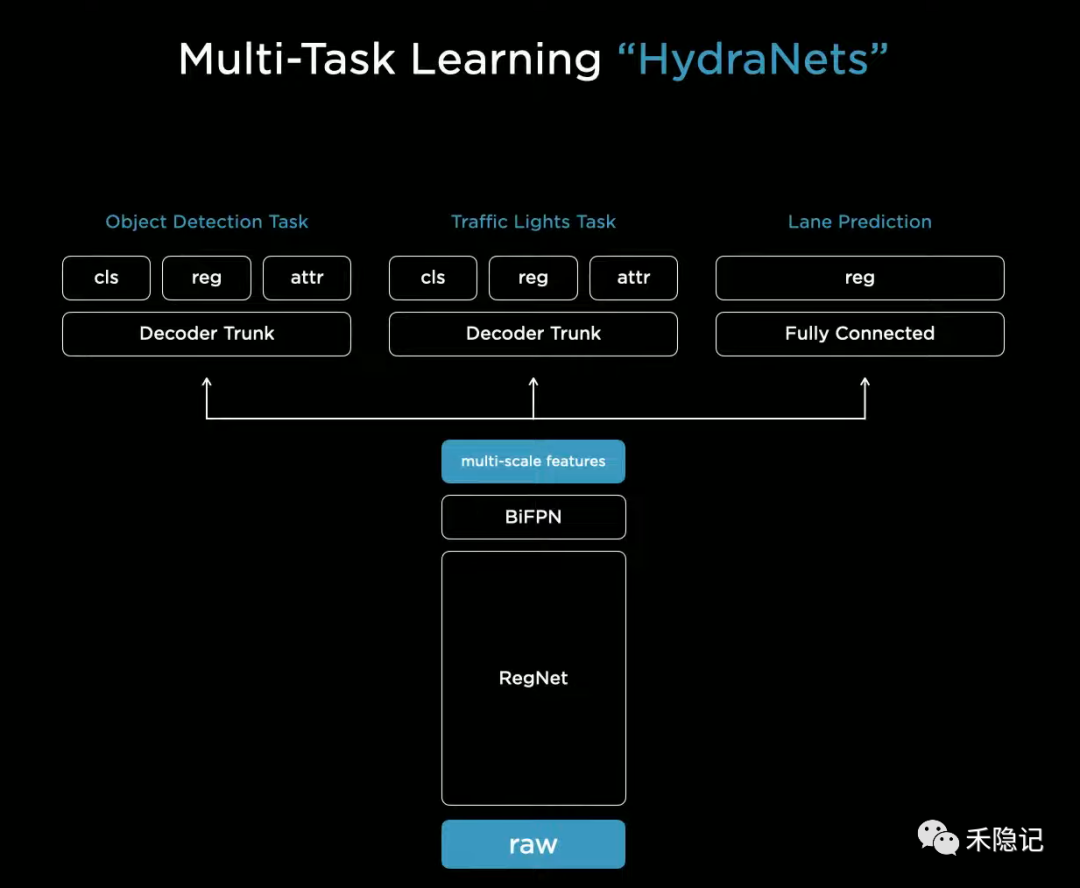
HydraNet多任務網(wǎng)絡結(jié)構(gòu)
HydraNet網(wǎng)絡的核心特點是多個子任務分支共享同一個特征空間,相比單一任務使用獨立的神經(jīng)網(wǎng)絡,具有如下優(yōu)勢:
1)使用同一主干統(tǒng)一提取特征并共享給各任務頭部使用,可以避免不同任務之間重復計算現(xiàn)象,有效提升網(wǎng)絡整體運行效率;
2)不同子任務類型之間可以實現(xiàn)解耦,每項任務獨立運行不會影響到其他任務,因此對單項任務的升級可以不必同時驗證其他任務是否正常,升級成本更低;
3)生成的特征空間可以進行緩存,便于各任務需求隨時調(diào)用,具有很強的可擴展性。
數(shù)據(jù)校準層:虛擬相機構(gòu)建標準化數(shù)據(jù)
特斯拉通過不同的汽車采集到的數(shù)據(jù)共同構(gòu)建一個通用的感知網(wǎng)絡架構(gòu),然而不同汽車由于攝像頭安裝外參的差異,可能導致采集的數(shù)據(jù)存在微小偏差,為此特斯拉在感知框架中加入了一層“虛擬標準相機”,引入攝像頭標定外參將每輛車采集到的圖像數(shù)據(jù)通過去畸變、旋轉(zhuǎn)等方式處理后,統(tǒng)一映射到同一套虛擬標準攝像頭坐標中,從而實現(xiàn)各攝像頭原始數(shù)據(jù)的“校準(Rectify)”,消除外參誤差,確保數(shù)據(jù)一致性,將校準后的數(shù)據(jù)喂養(yǎng)給主干神經(jīng)網(wǎng)絡進行訓練。
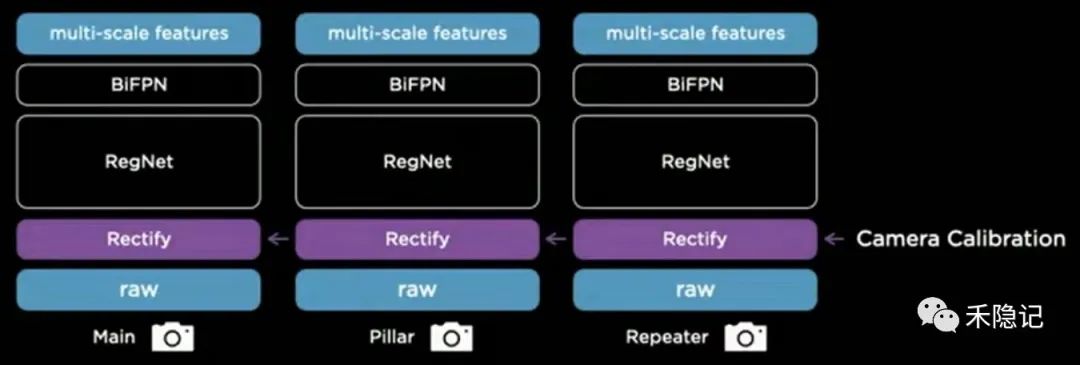
在原始數(shù)據(jù)進入神經(jīng)網(wǎng)絡前插入虛擬攝像頭層
空間理解層:Transformer實現(xiàn)三維變換
由于攝像頭采集到的數(shù)據(jù)為2D圖像級,與現(xiàn)實世界的三維空間不在一個維度上,因此要實現(xiàn)完全自動駕駛能力,需要將二維數(shù)據(jù)變換至三維空間。
為了構(gòu)建出三維向量空間,需要網(wǎng)絡能夠輸出物體深度信息,大部分自動駕駛公司采用的方案是使用激光雷達、毫米波雷達等傳感器來獲取深度信息,并與視覺感知結(jié)果進行融合,而特斯拉堅持使用純視覺方案獲取的視頻數(shù)據(jù)來計算深度信息,其思路是在網(wǎng)絡結(jié)構(gòu)中引入一層BEV空間轉(zhuǎn)換層,用以構(gòu)建網(wǎng)絡的空間理解能力,BEV坐標系即鳥瞰俯視圖坐標系,是一種忽略高程信息的自車坐標系。
早期特斯拉采取的方案是先在二維圖像空間實現(xiàn)感知,然后將其映射至三維向量空間,再將所有攝像頭的結(jié)果進行融合,但圖像層面感知是基于地面平面假說,即把地面想象成為無限大的平面,而實際世界中的地面會有坡度,因此會導致深度信息預測不準確,這也是基于攝像頭的純視覺方案面臨的最大困難,同時也會存在單個攝像頭無法看見完整目標導致“后融合”難以實現(xiàn)的問題。
為了應對這一問題,使感知結(jié)果更準確,特斯拉采用“前融合”的思路,將車身四周的多個攝像頭獲得的不同視頻數(shù)據(jù)直接進行融合,然后用同一套神經(jīng)網(wǎng)絡進行訓練實現(xiàn)特征從二維圖像空間到三維向量空間的變換。
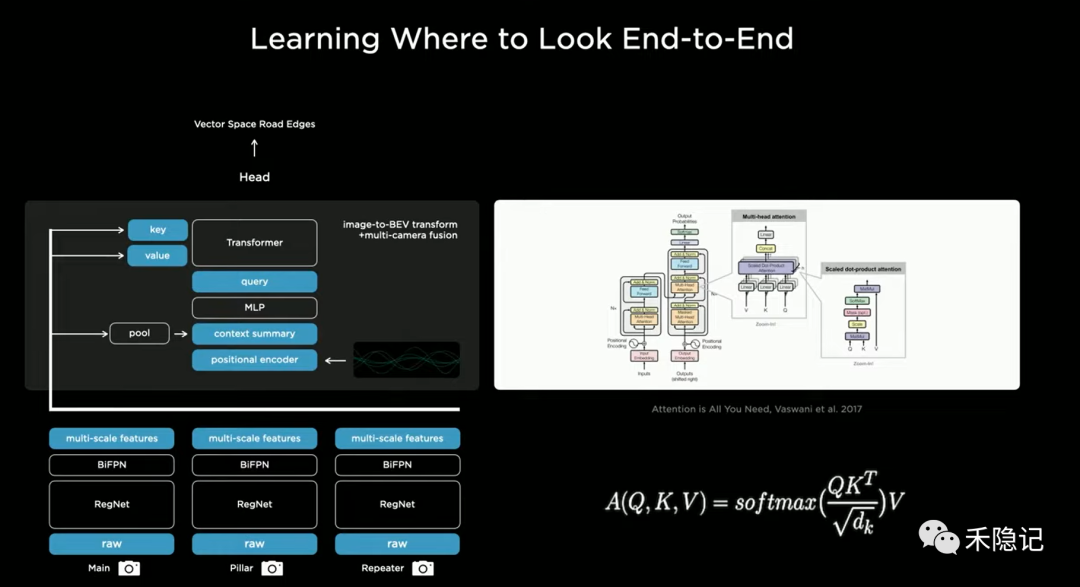
引入BEV三維空間轉(zhuǎn)化層
實現(xiàn)三維變換的核心模塊是Transformer神經(jīng)網(wǎng)絡,這是一種基于注意力機制的深度學習模型,源自于人腦對信息處理的機制,在面對外界大量信息時,人腦會過濾掉不重要的信息,僅將注意力集中在關(guān)鍵信息,可以大大提升信息處理效率,Transformer在應對大規(guī)模數(shù)據(jù)量級的學習任務時具有相當出色的表現(xiàn)。
Transformer模型需要的三個核心參數(shù)為Query、Key和Value,其中Key和Value由HydraNet主干部分生成的多尺度特征空間經(jīng)過一層MLP(多層感知機網(wǎng)絡)訓練得到,而通過對特征空間進行池化處理得到全局描述向量(context summary),同時對輸出的BEV空間各柵格進行位置編碼(positional encoder),合成描述向量和位置編碼后再通過一層MLP可以得到Query。
特斯拉通過這種方法,可以將地面坡度、曲率等幾何形狀的變化情況內(nèi)化進神經(jīng)網(wǎng)絡的訓練參數(shù)中,實現(xiàn)對物體深度信息準確感知和預測,這也是特斯拉敢于放棄雷達融合路線走純視覺路線的底氣。
短時記憶層:視頻時空序列特征提取
引入空間理解層后,感知網(wǎng)絡已經(jīng)具備對現(xiàn)實世界的三維向量空間描述能力,但仍然是對瞬時的圖像片段進行感知,缺乏時空記憶力,也就是說汽車只能根據(jù)當前時刻感知到的信息進行判斷,這會導致世界空間內(nèi)部分特征感知不到。
例如在行車過程中,如果有行人正在穿過馬路,過程中被靜止的障礙物遮擋,而汽車僅有瞬時感知能力的話,由于在感知時刻行人正好被汽車遮擋了,則無法識別到行人,導致很大的安全風險。而人類司機在面對類似場景時,則會根據(jù)之前時刻看到行人在穿越馬路的記憶,預測其當前時刻有很大概率被汽車遮擋,且有繼續(xù)穿越馬路的意圖,從而選擇減速或者剎車避讓。
因此自動駕駛感知網(wǎng)絡也需要擁有類似的記憶能力,能夠記住之前某一時間段的數(shù)據(jù)特征,從而推演目前場景下可能性最大的結(jié)果,而不僅僅是基于當前時刻看到的場景進行判斷。
為了解決這一問題,特斯拉感知網(wǎng)絡架構(gòu)引入了時空序列特征層,通過使用具有時間維度的視頻片段而非靜態(tài)的圖像來訓練神經(jīng)網(wǎng)絡,為自動駕駛增添了短時記憶能力。
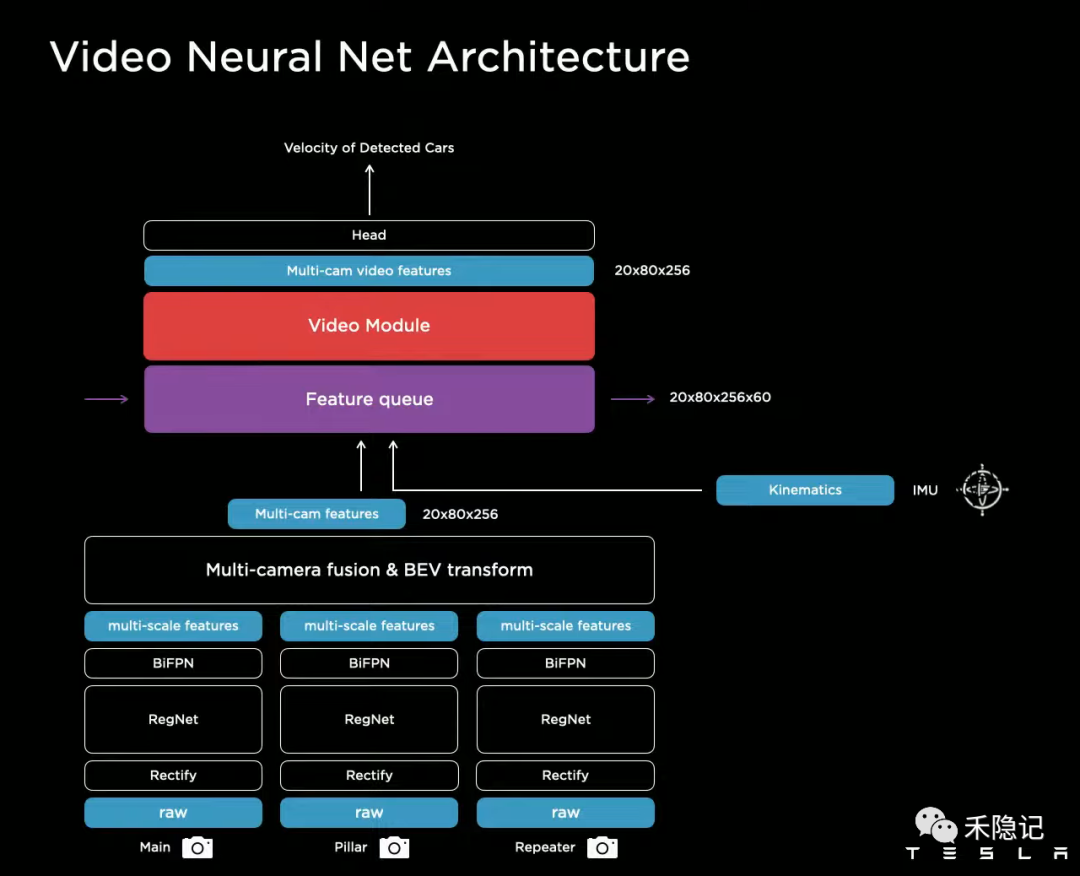
引入時空序列特征提取層以實現(xiàn)短時記憶能力
特斯拉同時還引入了IMU傳感器獲取到的包含速度和加速度在內(nèi)的自車運動信息,結(jié)合三維向量空間特征,分別生成基于時間維度和基于空間維度的特征隊列,其中時間維度的特征隊列提供了感知在時間上的連續(xù)性,而空間特征隊列的意義是防止由于部分場景等待時間過長導致的時序信息丟失,并利用三維卷積、Transfomer、RNN等方法實現(xiàn)時序信息融合,進而得到多傳感器融合的視頻流時空特征空間。
此外特斯拉還嘗試了一種新的時序信息融合方法——Spatial RNN,可以省略BEV層的位置編碼,直接將視覺特征喂給RNN網(wǎng)絡,通過隱藏層保留多個時刻的狀態(tài)編碼,指導應對當前環(huán)境需要選取哪些記憶片段使用。
短時記憶層無疑增加了特斯拉感知網(wǎng)絡的魯棒性,針對惡劣天氣、突發(fā)事件、遮擋場景等,都能保持良好的感知能力。
以上便構(gòu)成了特斯拉的感知網(wǎng)絡架構(gòu),通過端到端的訓練模型,從視頻數(shù)據(jù)輸入到向量空間輸出。
據(jù)特斯拉AI技術(shù)總監(jiān)Karpathy介紹,基于以上架構(gòu)的特斯拉視覺感知體系,對于深度信息的感知能力甚至可以超過雷達,同時由于具備短時記憶,特斯拉可以實現(xiàn)局部地圖的實時構(gòu)建,通過融合多個局部地圖,理論上可以得到任何一個區(qū)域的高精地圖,這也是特斯拉目前沒有采用高精地圖作為輸入原因。
02 規(guī)劃與控制
人體在感知到周圍世界的信息后,會基于對這些信息的認知做出相應的判斷,來規(guī)劃自己的軀體應該作何反應并下發(fā)控制指令,汽車也是如此,在完成感知任務后下一步便是對感知到的信息做出決策方案,指導汽車完成相應執(zhí)行動作,這便是自動駕駛的規(guī)劃與控制部分。
特斯拉自動駕駛規(guī)控的核心目標是基于感知網(wǎng)絡輸出的三維向量空間,通過規(guī)劃汽車行為和行車路徑使汽車到達指定目的地,同時最大化確保行車安全性、效率性及舒適性。
規(guī)控是一個非常復雜的問題,一方面汽車的行為空間具有典型的非凸性,同一個目標任務可能對應非常多個解決方案,同時全局最優(yōu)解難以獲得,具體表現(xiàn)就是汽車可能由于陷入局部最優(yōu),無法快速做出準確決策;另一方面行為空間具有多維性,要制定針對目標任務的規(guī)劃方案需要在短時間內(nèi)快速產(chǎn)生速度、加速度等多個維度的參數(shù)。
特斯拉采用的解決方案是將傳統(tǒng)規(guī)劃控制方法與神經(jīng)網(wǎng)絡算法相結(jié)合,構(gòu)建一套混合規(guī)劃系統(tǒng),以任務分解的方式分別解決上述兩大難題,其規(guī)劃控制邏輯如下圖所示。
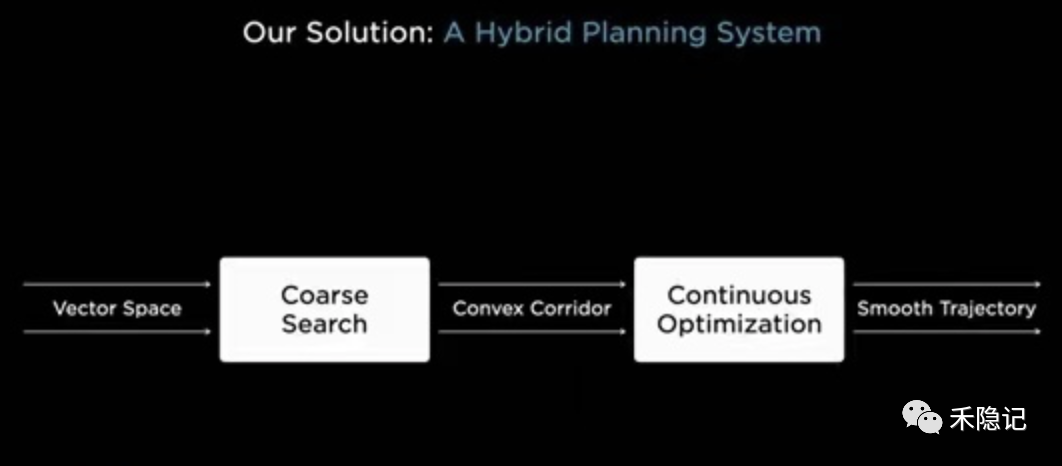
混合規(guī)劃系統(tǒng)解決方案
在感知獲得的三維向量空間中,基于既定的目標位置,先采用粗搜索的方式找到一條初步的路徑,然后根據(jù)安全性、舒適性等指標,圍繞初步路徑進行優(yōu)化,對與障礙物間距、加速度等參數(shù)做持續(xù)微調(diào),最終獲得一條最優(yōu)的時空軌跡。
在大部分結(jié)構(gòu)化場景下,例如高速公路等,粗搜索選取的是經(jīng)典的A-Star算法(啟發(fā)式搜索方法),但針對一些復雜的場景,例如鬧市中心、停車場等,由于場景中非結(jié)構(gòu)化元素比較多,搜索空間大,采用傳統(tǒng)A-Star算法消耗運算節(jié)點過多,導致決策速度緩慢。
由此特斯拉引入強化學習方法,強化學習的機制類似于人類學習模式,通過獎賞正確的行為來引導人類習得某項能力,首先利用神經(jīng)網(wǎng)絡學習全場景特點獲得價值函數(shù),然后通過MCTS算法(蒙特卡洛樹搜索)引導搜索路徑不斷靠攏價值函數(shù),這種方法可以大幅度減少搜索空間,有效提高決策實時性。
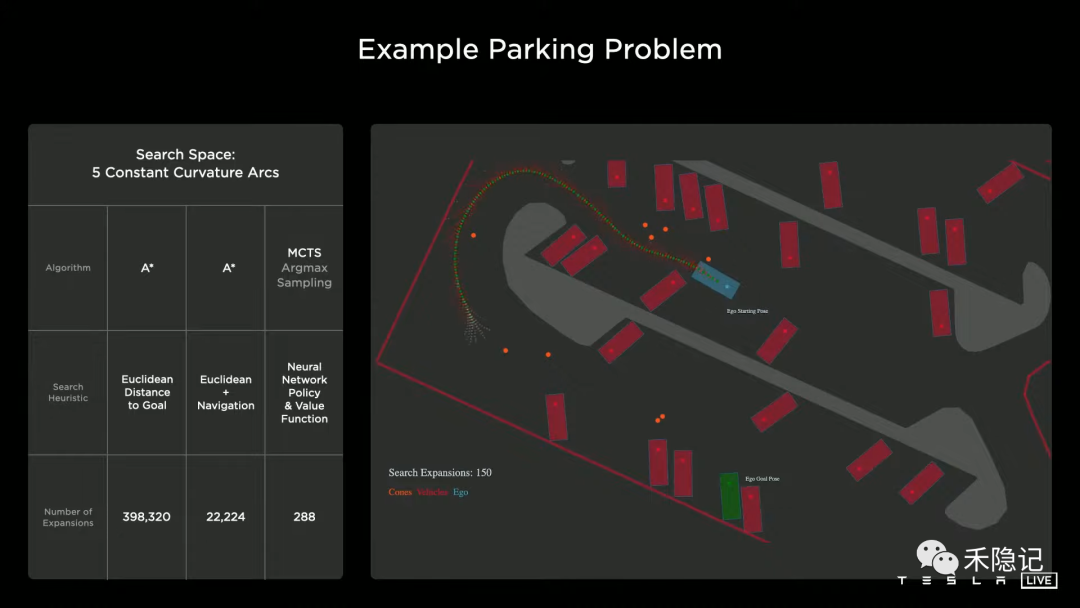
MCTS算法規(guī)劃停車場行車路線
而在行車過程中,會涉及與其他車輛的博弈問題,例如變道過程、在狹窄路口錯車場景,類似場景下一般需要根據(jù)對方車輛的反應變化隨時調(diào)整自車的決策方案。
因此除了單車規(guī)劃外,特斯拉還做了交通參與者聯(lián)合軌跡規(guī)劃,根據(jù)其他車的狀態(tài)參數(shù)(速度、加速度、角速度等)規(guī)劃其路徑,進而選擇合適的自車方案,待其他車狀態(tài)發(fā)生變化后,隨時調(diào)整自車方案,盡量避免出現(xiàn)自車愣在原地不做反應的情況,提升自車的smart性。

狹窄路口聯(lián)合軌跡規(guī)劃
至此,特斯拉FSD的最終架構(gòu)浮出水面,首先通過視覺感知網(wǎng)絡生成三維向量空間,對于僅有唯一解的問題,可直接生成明確的規(guī)控方案,而對于有多個可選方案的復雜問題,使用向量空間和感知網(wǎng)絡提取的中間層特征訓練神經(jīng)網(wǎng)絡規(guī)劃器,得到軌跡分布,再融入成本函數(shù)、人工干預數(shù)據(jù)或其他仿真模擬數(shù)據(jù),獲得最優(yōu)的規(guī)控方案,最終生成汽車轉(zhuǎn)向、加速、剎車等控制指令,由汽車執(zhí)行模塊接受控制指令實現(xiàn)汽車自動駕駛。
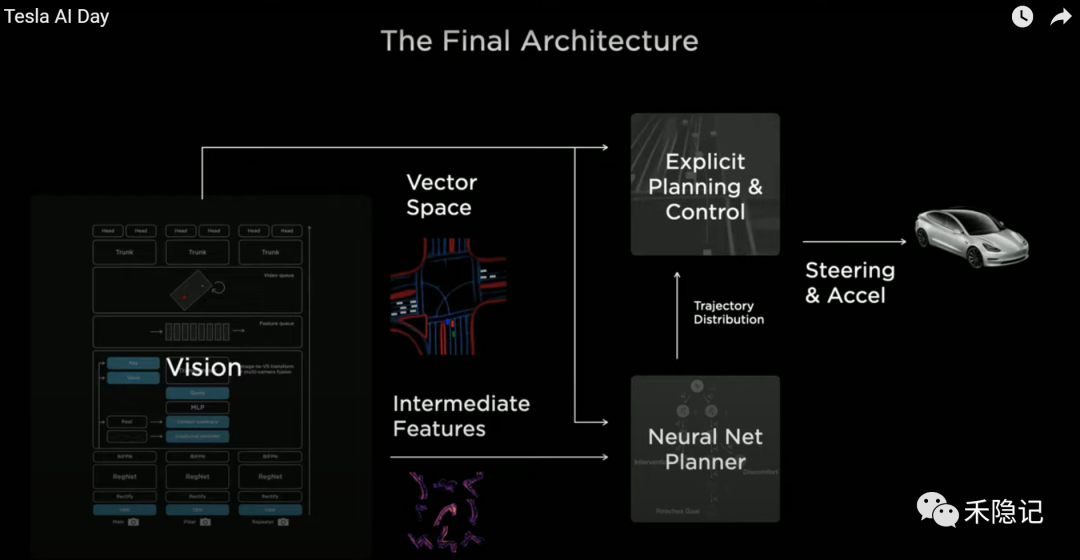
特斯拉FSD 感知-規(guī)劃-控制整體架構(gòu)
03 數(shù)據(jù)標注與仿真
可以看到在特斯拉的自動駕駛方案中,無論是在感知層面還是規(guī)控層面,核心算法基本都是由數(shù)據(jù)驅(qū)動的,數(shù)據(jù)的數(shù)量和質(zhì)量決定了算法的性能,因此構(gòu)建一套高效獲取、標注及仿真訓練數(shù)據(jù)的閉環(huán)至關(guān)重要。
數(shù)據(jù)標注
特斯拉每年售出近百萬輛汽車,通過這些汽車日常運行,可以采集到超大規(guī)模的原始數(shù)據(jù)集,對這些數(shù)據(jù)集的標注工作特斯拉最早是外包給合作方,后來發(fā)現(xiàn)存在交付延遲和質(zhì)量不高的情況,因此便在內(nèi)部發(fā)展了上千人的標注團隊并獨立開發(fā)標注基礎(chǔ)設(shè)施。
特斯拉的標注最初是在二維圖像中進行的,后來發(fā)展為四維實現(xiàn),除了標注三維空間外還有對時間維度的標注,直接在向量空間中完成標注后再反向投影到攝像頭對應的圖像空間中。
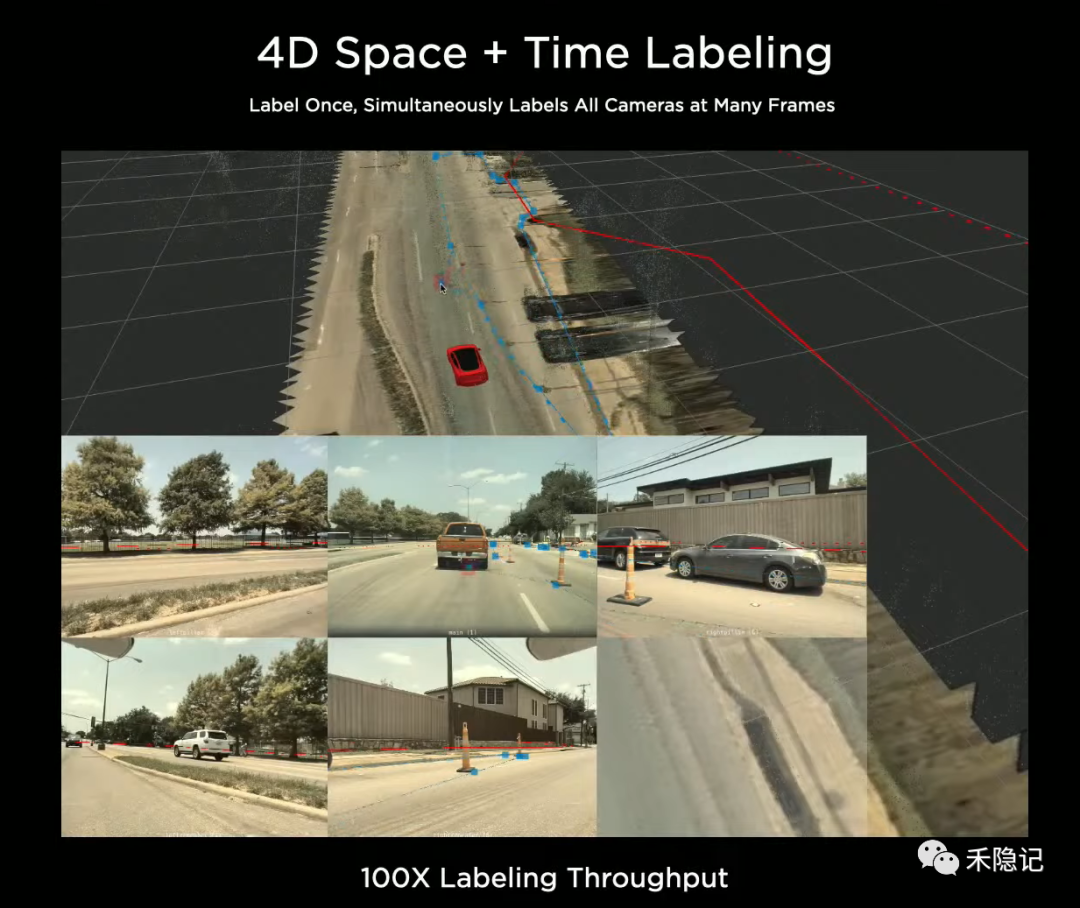
特斯拉的四維標注
隨著數(shù)據(jù)規(guī)模的逐漸擴大,人工標注的方式需要消耗大量人力成本,同時人類相對更擅長語義分割之類的標注任務,對于幾何圖形的標注,反倒是機器更擅長,因此特斯拉引入了自動標注的方法,實現(xiàn)人工與機器相結(jié)合的數(shù)據(jù)標注模式。
特斯拉實現(xiàn)自動標注的方案是通過汽車在一段時間內(nèi)采集到的視頻、IMU、GPS、里程表等數(shù)據(jù)構(gòu)成最小標注單元(Clip),由離線神經(jīng)網(wǎng)絡系統(tǒng)訓練得到中間層結(jié)果,如目標物、語義分割、深度、光流等,再通過大量機器算法生成最終用以訓練的標簽集,包括行車軌跡、靜態(tài)環(huán)境重建、動態(tài)物、運動學參數(shù)等,人工可以對自動生成的標簽集進行調(diào)整干預。

自動標注方案實現(xiàn)過程
對于靜態(tài)標注物,例如對于某一段道路的標注,以攝像頭采集到的路面每個點的平面坐標作為輸入,通過神經(jīng)網(wǎng)絡預測出這個點的高度及相關(guān)的語義分割、道路線邊界等三維中間結(jié)果,然后將這個三維點反向投影至各個攝像頭的二維空間,并將其與原本在二維圖像空間內(nèi)直接做語義分割的結(jié)果進行對比,再基于各個攝像頭的對比結(jié)果進行跨時空維度的聯(lián)合優(yōu)化實現(xiàn)重建,最終得到整個道路在各攝像機畫面內(nèi)及視頻前后幀時間序列中的一致性標注結(jié)果。
通過不同輛車不同時間經(jīng)過同一路段采集到的視頻數(shù)據(jù),按照上述方法進行自動標注,再將所有標注結(jié)果進行融合后優(yōu)化,得到該路段的精確標注結(jié)果,實現(xiàn)道路重建。

自動標注實現(xiàn)道路重建
通過這種方式,不僅可以重建道路,還可以重建墻體、屏障、建筑物等所有靜態(tài)環(huán)境物。
對于動態(tài)標注物,核心是要標注其運動學參數(shù)及行為軌跡預測,通過不同車輛在同一路段采集的含時間序列的視頻標注單元,我們不僅可以知道每個標注物過去時刻的信息,還可以知道未來時刻的信息,因此可以輕易獲取每個動態(tài)標注物運動軌跡和參數(shù)的“真值”,即使被遮擋的運動物體也可以標注出來。
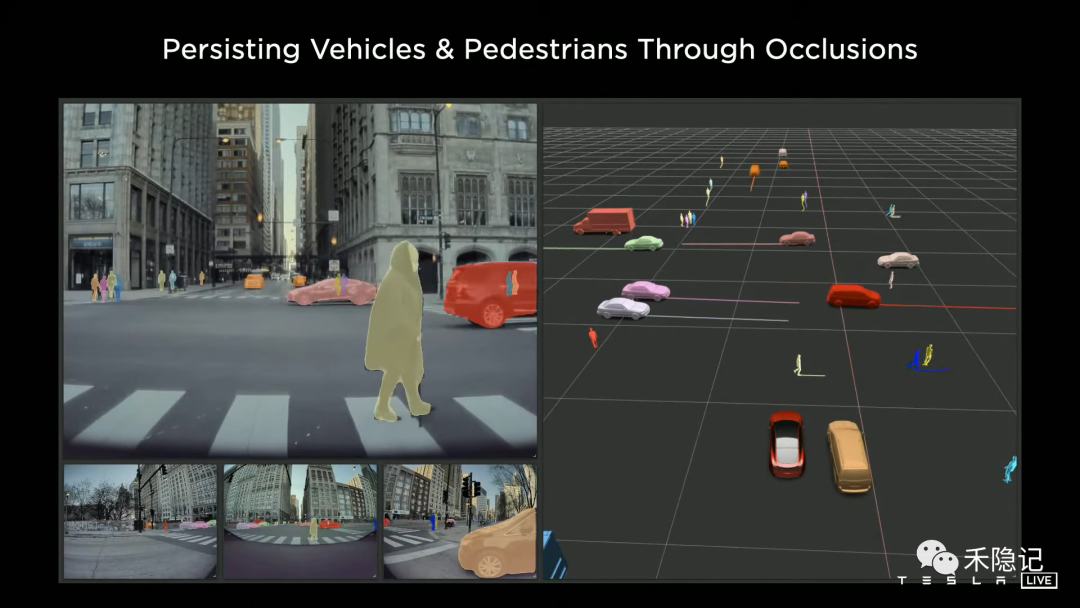
動態(tài)物體自動標注
通過對靜態(tài)物體和動態(tài)物體分別標注,最終得到一個最小標注單元的完整標注結(jié)果,如下圖所示。

自動標注實現(xiàn)Clip的完整標注
可以看到,只需要汽車在路上行駛采集到的數(shù)據(jù)作為輸入,然后運行標注模型,再將結(jié)果進行融合優(yōu)化,便可以得到任意場景的標注結(jié)果,全過程自動實現(xiàn),無人工參與。
一萬個標注單元在一周內(nèi)即可完成自動化標注,而純?nèi)斯俗t需要幾個月的時間,自動標注大大提升了標注效率。
仿真
由于路測條件的限制,導致積累數(shù)據(jù)和訓練算法的效率偏低且成本高昂,為了更高效的實現(xiàn)數(shù)據(jù)訓練,特斯拉構(gòu)建了一個真實世界的虛擬仿真空間,來加速FSD能力的訓練,仿真對于實現(xiàn)完全自動駕駛的價值如今在行業(yè)內(nèi)已經(jīng)普遍被認可。
自動駕駛的仿真是在模擬環(huán)境中,通過調(diào)整各類交通參與物及環(huán)境的模型參數(shù)以構(gòu)建各種虛擬場景,以訓練算法應對不同場景的性能。

特斯拉仿真場景
其價值主要體現(xiàn)在以下幾個方面:
1、通過仿真可以建立在現(xiàn)實世界中難以遇到的極端場景(corner case),例如高速公路上一家三口在跑步的場景,類似的場景雖然在現(xiàn)實世界中存在的可能性極低,但考慮到自動駕駛的安全性,必須掌握應對此種極端場景的能力,因此可以在仿真環(huán)境下進行模擬訓練;
2、針對部分復雜場景難以直接標注的情況,可以通過仿真進行快速標注,例如在一個路況復雜的十字路口有各種川流不息的汽車、行人,由于元素眾多,要直接進行標注難度很大,而在仿真場景中,由于所有的元素的初始參數(shù)都是自行設(shè)定的,因此在模擬復雜的運動狀態(tài)時,所需要標注的參數(shù)很容易就可以通過計算得到,以此實現(xiàn)快速標注;
3、仿真為規(guī)控算法的訓練和驗證提供了一個安全的環(huán)境,考慮汽車駕駛安全問題的重要性,自動駕駛規(guī)控算法訓練和優(yōu)化過程難以通過實際路測實現(xiàn),在仿真場景中便具有非常高的自由度;
4、可以用以某些閉環(huán)場景算法的長期持續(xù)訓練,例如泊車場景,這個場景下空間是閉環(huán)的,參與者有限,因此通過仿真持續(xù)模擬各種工況,可以有效地對自動駕駛泊車能力進行訓練;
5、對于現(xiàn)實世界中FSD失敗的場景,可以通過仿真重現(xiàn)失敗場景,在仿真環(huán)境中尋找失敗原因并進行算法訓練和優(yōu)化。
一套完整的仿真體系需要包括仿真場景、仿真系統(tǒng)和仿真評估三大部分,這里僅介紹特斯拉在仿真場景層面所做的工作。
自動駕駛的實現(xiàn)首先是基于感知能力,因此對感知系統(tǒng)的準確仿真非常關(guān)鍵,特斯拉的感知系統(tǒng)是基于純攝像頭,因此對攝像頭的各種屬性進行軟硬件建模,如傳感器噪聲、曝光時間、光圈大小、運動模糊、光學畸變等,甚至對于擋風玻璃上的衍射斑這種細節(jié),特斯拉也考慮在內(nèi),這套準確的傳感器仿真系統(tǒng)不僅可以用以FSD的訓練和驗證,還可以指導攝像頭的硬件選型和設(shè)計。

準確的傳感器仿真
為了真實的模擬現(xiàn)實世界場景,要求仿真渲染要盡可能做到逼真,特斯拉利用神經(jīng)網(wǎng)絡渲染技術(shù)來提升視覺渲染效果,同時用光線追蹤的方法來模擬逼真的光照效果。

逼真的視覺渲染
為了避免仿真環(huán)境過于單一,導致感知系統(tǒng)過擬合的問題,特斯拉對仿真環(huán)境參與物進行了充分的建模,包括多元交通參與者(例如車、行人等)和靜態(tài)環(huán)境物(例如建筑、樹、道路等)等,截至最新Tesla AI Day公開的信息,特斯拉總共已經(jīng)繪制了2000+公里的道路環(huán)境。

多元交通參與者與地理位置
針對自動駕駛可能遇到的各種場景,構(gòu)建了大規(guī)模的可擴展場景庫,由計算機通過調(diào)整參數(shù)生成不同的場景形態(tài),例如道路曲度等,同時由于大量的仿真場景可能是無用的,例如實際該場景下汽車的決策已經(jīng)正確,為了避免計算資源的浪費,特斯拉還引入了MLB等神經(jīng)網(wǎng)絡用來尋找故障點,重點圍繞故障點進行仿真數(shù)據(jù)創(chuàng)建,反哺實際規(guī)劃網(wǎng)絡,形成閉環(huán)。

大規(guī)模場景生成
除了直接在虛擬場景中進行仿真訓練,特斯拉還希望可以在仿真環(huán)境中重現(xiàn)真實世界場景,以便可以復現(xiàn)FSD失敗的場景,實現(xiàn)在仿真環(huán)境下的優(yōu)化迭代后再反哺汽車算法模型,實現(xiàn)“數(shù)據(jù)閉環(huán)”,因此在完成真實世界片段的自動標注重建后,再疊加視覺圖像信息,生成與真實世界“孿生”的虛擬世界。

場景重現(xiàn)
特斯拉通過仿真獲得的虛擬數(shù)據(jù)規(guī)模已達到37.1億張圖片及4.8億標注,且已實際融入車端模型中,用以提升FSD性能。
04 算力
上面對特斯拉自動駕駛所采用的算法架構(gòu)和數(shù)據(jù)閉環(huán)進行了介紹,而超大規(guī)模的數(shù)據(jù)和高性能的算法均需要強大的算力支撐,特斯拉為此自研打造了服務于自動駕駛的全球最強超級計算機——Dojo。
Dojo是一種通過網(wǎng)絡結(jié)構(gòu)連接的分布式計算架構(gòu),具有大型計算平面、極高帶寬、低延遲、可擴展性極強等特點,去年8月的AI Day,特斯拉公布了為Dojo超算打造的自研AI訓練芯片D1。
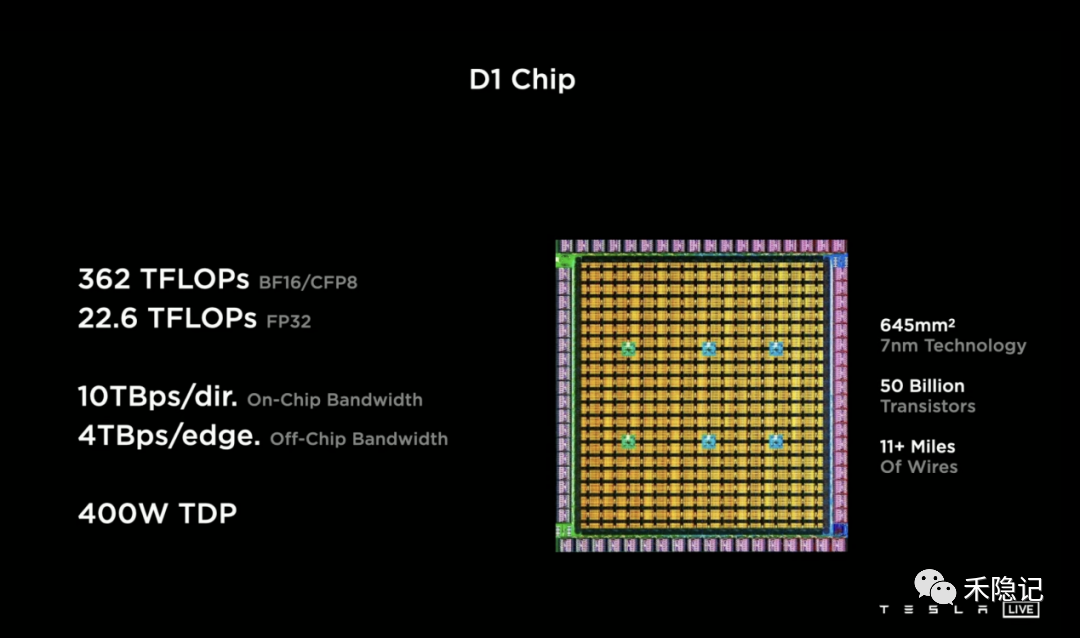
Dojo?D1芯片
D1芯片采用分布式結(jié)構(gòu)和7納米制造工藝,單片面積僅645平方毫米,具有500億個晶體管和354個訓練節(jié)點,內(nèi)部電路長達17.7公里,單片F(xiàn)P32算力可達22.6 TOPs,BF16 算力可達362 TOPs,1TOPS代表處理器每秒鐘可進行一萬億次(10^12)操作,同時具有GPU級的計算能力和CPU的連接能力,I/O帶寬是最先進的網(wǎng)絡芯片的2倍。
同時D1芯片之間可以實現(xiàn)無縫連接,特斯拉將25個D1芯片連接起來組成了獨立的訓練模塊,模塊算力高達9 PFLOPs(每秒處理9千萬億次),I/O帶寬最大達每秒36TB。

D1組成的訓練模塊
那么將120個訓練模塊(包含3000顆D1芯片)集成在一塊,就組成了AI訓練計算機柜——Dojo ExaPOD,其包含超過100萬個訓練節(jié)點,BF16/CFP8算力高達1.1 EFLOPs(每秒110京次的浮點運算,1京=10^18),超越了當時排名全球第一的日本富士通0.415 EFLOPs,且在相同成本下,ExaPOD具有4倍性能和1.3倍能耗節(jié)約,碳排放僅占1/5。

Dojo?ExaPOD 超級計算機
而且由于DI芯片的無限連接特性,理論上由其組成的Dojo計算機性能拓展無上限,因此目前的算力不是終點,特斯拉預計下一代Dojo還會有10倍性能提升。
超強算力將持續(xù)服務于特斯拉大規(guī)模數(shù)據(jù)訓練、自動駕駛算法、云計算能力和其他AI方向。
05 寫在最后
特斯拉全棧自研自動駕駛體系在全球已經(jīng)處于領(lǐng)先地位,卻也仍然有非常大的提升空間,例如:
1、感知層面進一步逼近人類甚至超越人類,馬斯克曾在采訪中提到過特斯拉已經(jīng)在使用攝像頭采集可見光的光子信息,跳過圖像信號處理階段,直接將最原始的光子數(shù)據(jù)輸入給神經(jīng)網(wǎng)絡訓練,這將使純視覺方案獲得遠超人類的夜間視距。
2、規(guī)控層面提升自動駕駛的“老司機”屬性,特斯拉目前公開的決策規(guī)劃的技術(shù)方案并不多,從已公開的部分可以看到整體比較中規(guī)中矩,如何進一步發(fā)展規(guī)控能力,讓人類對自動駕駛擁有更多信任感,是一個非常重要的課題。
3、仿真層面打造自動駕駛“數(shù)字孿生”,仿真是實現(xiàn)完全自動駕駛的關(guān)鍵一環(huán),主要由于仿真的試錯成本非常低,可以加速自動駕駛能力訓練,促進L4級以上自動駕駛提早到來。
自動駕駛作為人工智能技術(shù)的“皇冠”,可以說是智能時代的“核彈”,是全球高科技企業(yè)競相追逐的科技高地,自動駕駛的持續(xù)發(fā)展最終很有可能將引發(fā)汽車交通行業(yè)乃至整個人類社會運行方式的巨大變革。
數(shù)據(jù)、算法、算力是驅(qū)動自動駕駛的三駕馬車,特斯拉通過大規(guī)模汽車生產(chǎn)獲取數(shù)據(jù)、持續(xù)迭代FSD算法反哺汽車性能、自研超級算力服務AI訓練的模式成功打造了實現(xiàn)完全自動駕駛的良性飛輪。
特斯拉正在并將持續(xù)引領(lǐng)智能汽車革命。
編輯:黃飛
?












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論