 電子發燒友App
電子發燒友App


CVPR 2023 落下帷幕,Best Paper 之一花落上海人工智能實驗室 OpenDriveLab 團隊和武漢大學聯合團隊的工作 UniAD。
UniAD 獲得了多個首次:
CVPR 首次將最佳論文授予純自動駕駛領域。
自動駕駛界首個開源具備全棧關鍵任務的端到端自動駕駛模型,統一了多個自動駕駛子任務。
十年來首次中國本土團隊獲得 CVPR Best Paper。
UniAD 統一自動駕駛關鍵任務,但是端到端的訓練難度極大,對數據的要求和工程能力的要求比常規的技術棧要高,但是由此帶來的全局一致性讓整個系統變得更加簡潔,也能夠防止某個模塊進入局部最優,而不是全局最優。
雖然整體稱為端到端,但是各個模塊直接確實有著明顯的界限和區隔,并非一個整體黑盒網絡。
各個模塊間有了相當的可解釋性,也有利于訓練和 Debug,為自動駕駛端到端的設計提供了一個很好的范本,也期待在工業界的應用。
在正式討論這篇論文前,其實有一個問題,端到端自動駕駛到底是什么?
01
端到端自動駕駛到底是什么?
經典的自動駕駛系統有著相對統一的系統架構:
探測(detection)
跟蹤(tracking)
靜態環境建圖(mapping)
高精地圖定位
目標物軌跡預測
本車軌跡規劃
運動控制
幾乎所有的自動駕駛系統都離不開這些子系統,在常規的技術開發中,這些模塊分別由不同的團隊分擔,各自負責自己模塊的結果輸出。
這樣的好處是,每一個子系統都能夠有足夠好的可解釋性,在開發時能夠獨立優化。
與此同時,為了保證整體自動駕駛的性能,每一個模塊都需要保證給出穩定的表現。
所以事實上在一個 Bug 出現時,需要巨大的 Triage 團隊對 Bug 進行分析,然后將具體的 Bug 來源分配給責任團隊。
據說在 Waymo,甚至有超過 200 人的團隊,對 Bug 進行分析和責任分配。
那找 Bug 來源和 Bug 優化的任務就不能自動化嗎?
當然可以, 如果我們能將各個模塊用可微分的方式連接起來。類似于傳統深度學習,出現誤差時,深度自動回傳進行權重更新。
某種程度上,這就是端到端自動駕駛的概念。
02
理想化的端到端自動駕駛
事實上,從自動駕駛開始發展,就一直伴隨一個看似幼稚但是非常復雜的疑問:
為什么我們不能開發一個系統,輸入時是傳感器信號(攝像頭,激光雷達),輸出是控制指令(轉向,剎車,加速)?
這個問題,實際上,業界也一直有人在探討,甚至于國內 2018 年還有一家公司給出了這樣計劃:
其方案
輸入為視覺信號,輸出為 Steering,Brake,Accelerate,而真值為真實人類司機的上述動作。
輸入輸出都有了,真值數據也有了,接下來就是塞進看不太懂的膠囊神經網絡里進行全局優化訓練,最后就能給出結果。
這個方案好在沒有吸引到什么大手筆投資,很快就銷聲匿跡了。
不過這兩天,大模型出來之后,我甚至也看到了一模一樣的計劃,只不過網絡換成了大模型。
03
為什么完全端到端目前不可行?
神經網絡的黑盒效應讓完全端到端自動駕駛無法找到正確優化方向。
本質上又回到了最初的問題,模塊解耦讓多模塊單獨優化成為可能,讓每一個模塊擁有獨立的可解釋性。
而如果變成一個巨大的神經網絡模塊,這種基于統計學的神經網絡是無法保證在正確的道路上持續優化的,因為無法保證對未見過的物體的魯棒性,也無法對某一個具體的 Bug 進行定向改進。
可能會有人會問,那語言大模型表現可以遷移嗎?
泛化性的遷移是可行的, 根據 Google 的研究結果,他們基于語言大模型的抓取機器人,已經可以做到對沒有見過的物體有直接的泛化能力,例如他們要求從未見過烏龜的機器人抓取一只烏龜,任務能夠被很好地完成。
因為很好地使用了大語言模型的泛化能力,但是這件事情在自動駕駛上,尚未得到驗證。
但是如何對一個具體的 Bug 進行改進?
假設出現了一次誤剎,經典的自動駕駛技術棧會分析:
剎車指令的來源,是前方動態障礙物,還是靜態物體?
或者是規劃模塊的速度規劃出現問題?
或者是控制模塊在輸出正確的情況下,控制指令出現了問題?
根據這些然后再進行定向優化。
但是,完全端到端,就失去了這種定向優化的能力,甚至都無法知道,具體應該提供哪種數據進行定向優化。
而理想在上周提到的紅綠燈意圖網絡(TIN)也同樣是一個視覺輸入到轉向意圖的整體設計創新,令人印象深刻。
但是對于具體如何應用到量產中我其實并不樂觀,一個這樣的網絡硬件部署難度和實際效用的收益比尚且不論,而優化過程是一個更加大的命題。
如果答案是加上所有的量產數據,顯然不能說服工程界,期待之后有更加深入的介紹。
當然,Elon Musk 在上個月的 Twitter 中,畫了一個巨大的視覺到控制指令的餅,但是我也絕不認為他們正在研究的模型內部是一個完全黑盒的網絡。
04
工程派的端到端自動駕駛 UniAD
整體自動優化,可解釋性我統統都要
為了解決整體優化問題,UniAD 使用了一個巨大的 Transformer 網絡,但是為了保證每個模塊有足夠的可解釋性并能夠被獨立優化,這個網絡被分割成多個共享 BEV 特征的 Transformer 網絡。
首次將跟蹤、建圖、軌跡預測、占據柵格預測統一到一起,并且使用不依賴高精地圖的 Planner 作為一個最終的目標輸出,同時使用 Plan 結果作為整體訓練的 loss 來源。
也就是說,UniAD 并沒有完全拋棄原有的自動駕駛技術棧,而是改變了子模塊連接的方式,傳統可能是靠規則和顯式連接,例如先從檢測網絡拿到目標物體的位置和速度,再喂給下一個模塊。
這種規則和顯式連接的方式無法完成梯度傳播(神經網絡的自我迭代方式),只能靠人工優化。
但是 UniAD 共享了 BEV 特征,將子模塊用神經網絡的方式連接起來。這樣就保證了整體網絡的一致性,能夠完成梯度的前向傳播,也就有了自動優化的能力。
整體流程
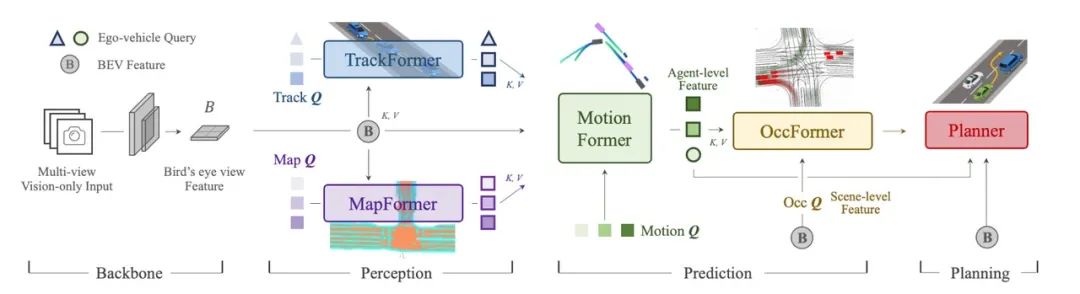
從流程上看,首先將環視的圖片以 Transformer 映射到 BEV 空間供后續模塊使用。
TrackFormer 根據 BEV 信息進行推理,融合了檢測和跟蹤任務,輸出為目標檢測和跟蹤的信息;
MapFormer 根據 BEV 信息給出實時地圖構建結果;
之后 Motion Former 將 TrackerFormer 的結果和 MapFormer 的結果和 BEV 結果進行融合,最后得出周圍物體整體軌跡和預測。
這些信息會作為 OccFormer 的輸入,再次與 BEV 特征融合作為占據柵格網絡預測的輸入。Planner 的目標是防止本車與占據柵格碰撞,作為整個大模塊的最終輸出。
前景
面對一個巨大的,并且分模塊的任務,訓練過程一定是非常不穩定的。
文章中提到,根據他們的經驗,他們會先訓練 6 次 Percecption(Track 和 Map )部分,再訓練 20 次整體,最后得到比較好的結果。
這種訓練方式也是得益于整體設計的相對解耦,感知模塊可以被單獨訓練。能夠在獲得一個相對已經穩定的感知結果的基礎上,進行后續模塊的訓練,同時也對感知模塊進行優化。
這種設計為工業界使用提供了一定的便利,多個模塊之間的輸出可以被單獨 debug,也能被統一優化。
而在工業界相對比較多的本車 Plan 相關數據也為整個網絡的訓練提供了保證。
UniAD 的輸出到了Planning 就截止了,確實因為后面控制的內容就不屬于計算機視覺領域了,并且其實控制模塊用 Learning 的方式其實并沒有的得到承認 期待一些公司的部署結果。
寫在最后
關于自動駕駛的未來,各個模塊之間的界限越來越模糊,與此同時,配套的開發工具鏈也需要從模塊解耦轉換到模塊融合。
有意思的是,恰逢其時,來自 Waabi 創始人,著名研究學者 Raquel 的一篇文章 CVPR Highlight UniSim 也非常值得一讀。
使用 NeRF 相關技術,統一了場景編輯、Camera 仿真、Lidar 仿真、交通仿真多個任務。
這篇文章為高效端到端的仿真訓練提供了可能性。
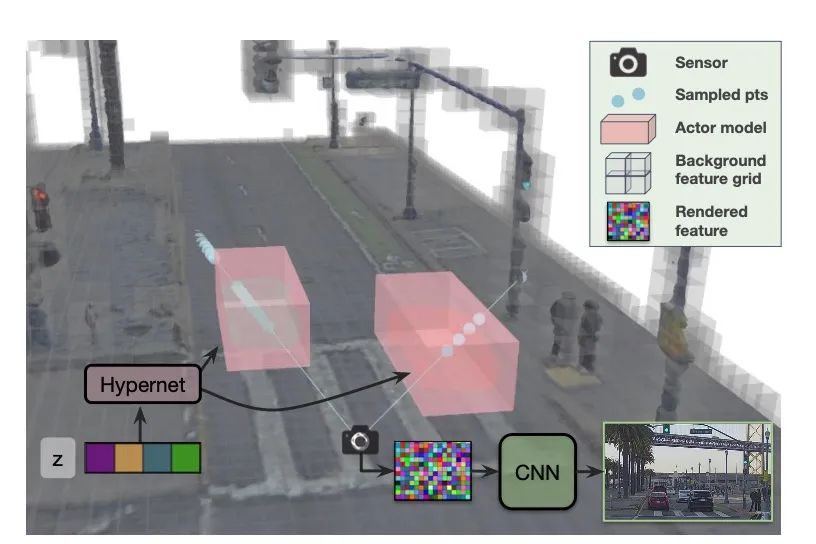
雖然從算法創新的角度看,太陽底下沒有什么新鮮事,UniAD 是 Tranformer 的工程化創新,UniSim 是 NeRF 的工程化創新。
但是自動駕駛本身就是一個工程問題,工程化和快速迭代的能力會越來越重要。
學術界已經有了非常明顯的轉變,國內工業界某些公司卻似乎還在每天宣傳自家算法的巨大創新。
甚至在這次 Best Paper 發布之后, 知乎上很多人詬病 UniAD 算法不夠創新。
可是自動駕駛作為一個巨大的工程問題,為了創新而創新是無法帶來真正量產可用的系統的。
這種反差倒也是一件非常有意思的事情。
編輯:黃飛









 工商網監
工商網監
評論