 電子發燒友App
電子發燒友App


如何利用車載環視相機采集到的多張圖像實現精準的 3D 目標檢測,是自動駕駛感知領域的重要課題之一。針對這個問題,傳統的檢測方案可以概括為:先利用一個 2D 模型在各自的相機視角獲取 3D 檢測結果,再通過后處理算法將各個視角的 3D 檢測框投影到 ego frame 再組合在一起。
這樣的做法簡單有效,但是由于將多視角融合的步驟排除在模型學習之外,導致其難以檢測相鄰環視相機重疊部分中被截斷的物體,也難以實現與 3D 點云傳感器 (LiDAR) 的數據級/特征級融合。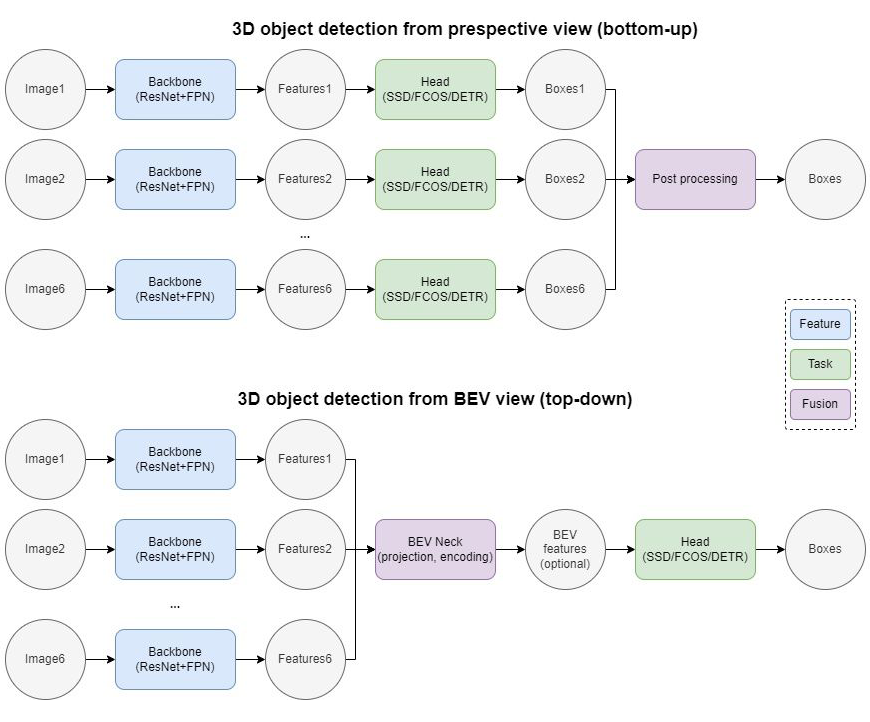
Perspective view VS BEV view 3D object detection 隨著 Attention 機制在 Vision 領域的成功應用,大家開始關注如何將多個 Perspective view 的圖片表征 (image representation) 轉化為一個統一的BEV view (Bird's Eye View, 鳥瞰圖) 的場景表征 (scene representation),從而實現完整統一的 3D 目標檢測。具體而言,傳統的 2D 網絡包含 Backbone 和 Head 兩個模塊,分別用于特征提取和目標檢測。
BEV 網絡則在二者之間增加一個 BEV Neck,用于 2D 到 3D 的 BEV 投影以及 BEV 視角下的特征提取。本文嘗試盤點一下目前市面上幾種主流的 Transformer-based BEV 3D object detection 的方法,重點著眼于如何高效的從環視相機視角提取 BEV 特征。?
01??Feature point sampling
DETR3D [2] 將原本的 DETR 模型拓展到 3D 空間。具體而言:在 2D Image feature extraction 部分,利用共享權重的 ResNet+FPN (output stride = 1/8, 1/16, 1/32, 1/64) 提取環視相機所采集到的 6 張圖片的特征。
在 3D Transformer decoder 部分,每個 object query 先通過一個子網絡預測所查詢物體在真實世界的 3D 坐標 (reference point),再利用由相機的內參外參所構造的坐標變換矩陣 (camera transformation matrices, 3x4) 將真實世界的 3D 坐標投影至環視相機的 2D 像素坐標,并應用雙線性插值采樣各個相機視角、各個 PFN 層級同一位置的特征點(投影在圖像外的特征點用 0 填充),最后利用所采樣到的 6x4=24 個特征點的均值作為物體特征更新 object query。? Feature point sampling有很多優點:
1)計算量小(畢竟只采樣 24 個特征點);
2)兼容 FPN(應該對檢測不同距離的物體有幫助);
3)避免了 dense depth prediction(只需要預測 sparse object query 的 3D 坐標,不需要預測每張圖片、每個像素的深度信息)。
02??Global cross-attention
無法直接用 3D object query 在 2D spatial features 上實現查詢匹配的原因之一,是二者空間上的不一致:在 2D 圖片上兩個點之間的坐標距離難以表述 3D 世界中這兩個點的實際距離。
為了將 2D 的圖像特征擴展到 3D 檢測空間(以方便 3D object query 查詢匹配),PETR [3] 選擇在 Positional embedding 方面做改進:為 2D 特征圖上的每個像素生成一個對應真實世界中的 3D 坐標列表(2D 圖片上的一個點對應 3D 真實世界中以相機鏡頭為起始點的一條射線 (camera ray),列表即是在這條射線上采樣的 N 個點的 3D 坐標集合),再通過 MLP 將這個坐標列表轉化為 3D Positional embedding。
下圖展示了前視相機的左中右三個點與其他所有相機視角的 3D Positional embedding 的相似度比較,可以發現與這三個點所對應真實世界的三條射線夾角較小的區域相似度較高,證明這種 2D 到 3D 的轉換是有效的。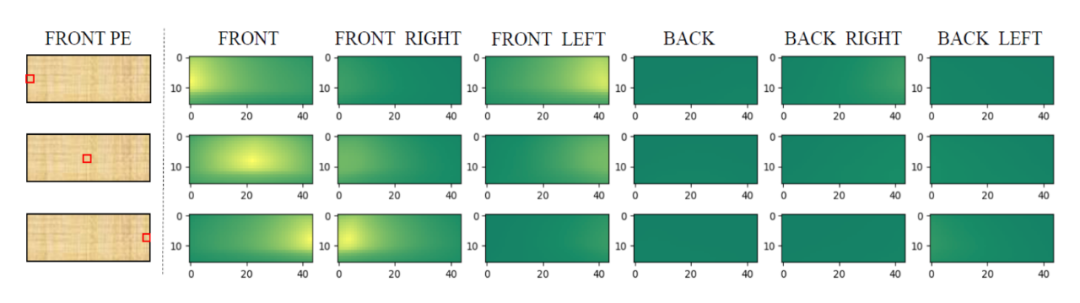
圖片來自PETR 有了 3D Positional embedding 的修飾,原本的 2D 圖像特征便可以升級成 3D 空間特征,直接與 3D object query 做查詢匹配。
PETR [3] 最大程度上保留了 Anchor DETR [4] 的網絡結構和檢測邏輯,在 Transformer decoder 階段使用了原本的 Global cross-attention,即每個 3D object query 要和 6 張環視圖片的所有特征點做一遍相似度匹配。 值得注意的是:
1)可能是出于計算量考慮,PETR [3] 并沒有采用多尺度 FPN,而是僅僅使用固定大小(stride=16)的特征圖;
2)根據作者的實驗,BEV query(3D anchor points)需要在高度上(z 軸)做出細分,這與目前許多 pillar-based 檢測方法有所不同。?
03??Deformable cross-attention
BEVFormer [5] 繼承自 Deformable DETR [6],與上述兩個工作的主要區別在于:
1)顯式得構建 BEV features(200x200 分辨率,覆蓋以車為中心邊長 102.4 米的正方形區域);
2)利用 Deformable cross-attention 從 image space aggregate spatial information 到 BEV query 中;
3)引入多幀時序信息。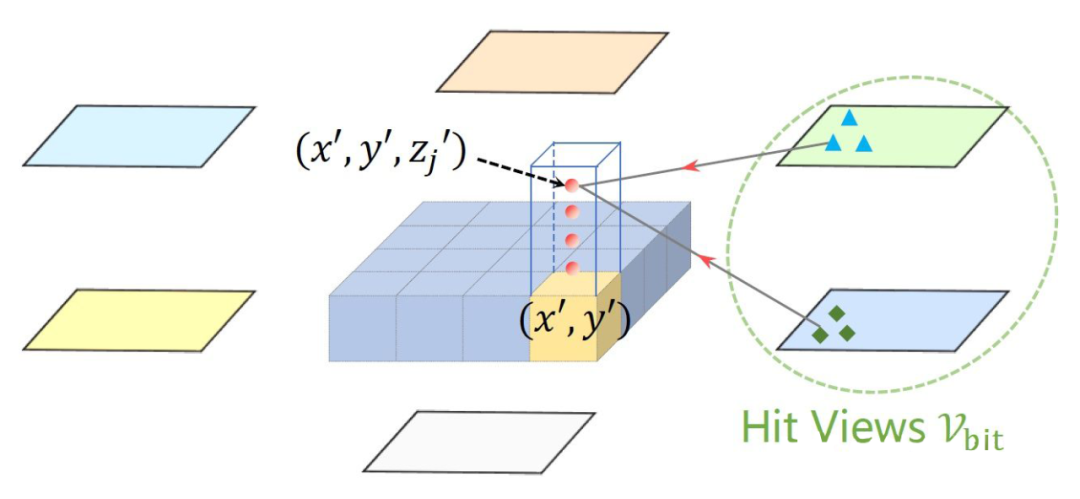
圖片來自BEVFormer 其具體做法是:為 BEV space 的每個 feature point 定義一組 anchor heights(pillar-like query, four 3D reference points from -5 meters to 3 meters),將這 4 個點投影回 2D image space 進行特征點采樣(sampling 4 points around this reference point),再用采樣得到的特征點與 BEV query 做 deformable attention。
相比于前兩種方法,Deformable cross-attention 更加靈活:它并不只采樣一個點,也不是跟 6 張圖片的所有位置挨個匹配,而是查詢 reference point 周圍的感興趣區域(RoI, region of interest)。
細算一下,一個 pillar-like BEV query 對應 4 個不同高度的 reference points,每個 reference point 采樣 4 個特征點,deformable attention 還涉及 8 個 heads,再加上 3 層 FPN(output stride=1/16, 1/32, 1/64)的特征輸出,最終一個 BEV query 實際上考察了 4x4x8x3=384 個特征點。
04??Lift-Splat
嚴格來說 Lift-Splat [7] 并不是基于 Attention 實現的,而是根據(預測的)深度信息加權來實現特征從 perspective view 到 BEV 的轉換(值得注意的是,每張圖片的每個特征點都需要預測其深度信息)。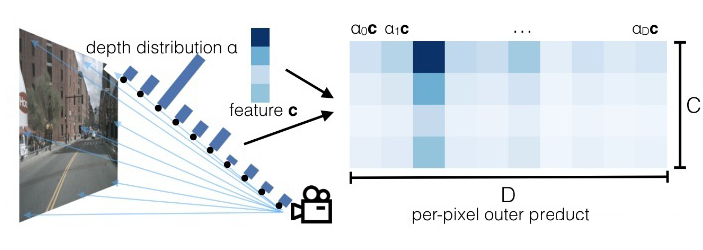
圖片來自Lift, Splat, Shoot 具體來說,在 Lift 步驟:與 PETR [3] 類似,考慮 2D 圖片上的一個點對應 3D 世界的一條射線,故可以在這條直線上采樣 N 個點(例圖用了 10 個,實際用了 41 個);之后網絡需要預測這個特征點的深度信息 (distribution over depth,參考直線上的直方圖),利用深度信息加權 (scale) 同一位置的圖像特征 C(參考例圖右側,由于網絡預測的深度在第三個 bin 較高,所以當深度 D=3 時特征與圖片特征 C 最接近,而其余深度處特征較弱)。 對一張圖片每個 2D 特征點做相同的操作,就可以生成一個形狀類似平頭金字塔 (frustum) 的點云。
在 Splat 步驟:首先構建一個 pillar-based BEV 視角的特征圖(200x200 分辨率,覆蓋以車為中心邊長 100 米的正方形區域),然后將上一步驟得到的 6 個平頭金字塔點云中的每個點匹配 (assign) 給距離最近的 pillar,最終 BEV space 上每個 pillar 的特征就是所有匹配到的特征點的和 (sum pooling)。 基于此方法的后續改進包括:
1. 通過添加顯式的深度預測監督 (explicit depth estimation supervision) 實現更精確的 camera to BEV 特征轉換 [8];
2. 通過添加坐標轉換預計算 (precomputation) 與 GPU 多線程并行池化 (specialized GPU kernel that parallelizes directly over BEV grids) 實現更快速的 camera to BEV 特征轉換 [9];
3. 由于 Splat 步驟所采用的 sum pooling 會粗暴地壓縮一個BEV grid 的高度(Z軸)信息,故可以先將 Lift 步驟得到的點云渲染成立體特征 (pseudo voxel, feature shape = XYZC),再 reshape 成 XY(ZC),最后通過 3x3 卷積降低特征通道數至 C [10]。
05??Future directions
仿照 Sparse RCNN [11] 的思路,在 BEV space 通過 RoIAlign 的方式抽取環視相機 perspective view 的 2D 特征(每個視角一個 RoI,投影到圖片外的 proposal 用 0 填充)是否可行?目前還沒有讀到類似的工作,有待進一步驗證。? 上面介紹的方法都是基于 query-based detection,出于計算量考慮 query 的數量一般比較少(大約 500-1500 左右),復雜場景下模型的 recall 表現還有待調研。?
Transformer-based BEV 3D object detection 模型是否必須依賴 perspective view 的預訓練模型 (e.g., FCOS3D [12])?能否設計一種時間+空間、2D 到 3D、單任務到多任務、單傳感器到多傳感器的大規模自監督預訓練?能否利用大規模仿真產生的數據???
審核編輯:劉清













 工商網監
工商網監
評論