 電子發(fā)燒友App
電子發(fā)燒友App


作者:匡吉
自動(dòng)駕駛技術(shù)在20世紀(jì)初的概念和實(shí)驗(yàn)主要集中在車(chē)輛自動(dòng)化和遙控方面。到了20世紀(jì)80年代和90年代,隨著計(jì)算機(jī)技術(shù)和人工智能的發(fā)展,自動(dòng)駕駛技術(shù)開(kāi)始取得顯著進(jìn)展。這一時(shí)期,一些大學(xué)和研究機(jī)構(gòu)開(kāi)始開(kāi)發(fā)原型車(chē)輛,能夠在特定條件下實(shí)現(xiàn)自動(dòng)駕駛。
進(jìn)入21世紀(jì),自動(dòng)駕駛技術(shù)迎來(lái)了快速發(fā)展期。隨著傳感器、算法、計(jì)算能力和大數(shù)據(jù)技術(shù)的進(jìn)步,多家科技公司和汽車(chē)制造商開(kāi)始投入巨資研發(fā)自動(dòng)駕駛車(chē)輛。 目前,自動(dòng)駕駛技術(shù)正處于逐步成熟階段,雖然還面臨著技術(shù)、法律、倫理和安全等多方面的挑戰(zhàn),但其發(fā)展?jié)摿θ匀徊豢尚∮U,將對(duì)交通安全、效率、環(huán)境保護(hù)等產(chǎn)生深遠(yuǎn)影響。 本文,我們將梳理自動(dòng)駕駛技術(shù)的進(jìn)化與發(fā)展。
如圖1是自動(dòng)駕駛的經(jīng)典框架,其中,最為重要的任務(wù)是場(chǎng)景理解任務(wù),這一任務(wù)在學(xué)術(shù)文章中常常稱(chēng)之為感知任務(wù),伴隨AI技術(shù)蓬勃發(fā)展,感知任務(wù)也在不斷刷新其性能上限。為輔助車(chē)輛控制系統(tǒng),以及理解周?chē)h(huán)境,自動(dòng)駕駛系統(tǒng)使用了各種感知技術(shù),最為重要且廣為人知的就是:SLAM(同步定位與建圖)和BEV(鳥(niǎo)瞰視圖)技術(shù)。這些技術(shù)賦予車(chē)輛無(wú)論在靜止還是移動(dòng)的狀態(tài)下,理解自身位置、檢測(cè)周?chē)系K物、以及估計(jì)障礙物方向和距離的能力,這些能力為后續(xù)駕駛決策提供信息。

▲圖1|經(jīng)典的自動(dòng)駕駛框架
SLAM+DL:第一代自動(dòng)駕駛技術(shù)
■2.1 簡(jiǎn)介
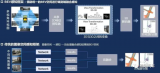
開(kāi)門(mén)見(jiàn)山,第一代自動(dòng)駕駛感知技術(shù),是以SLAM算法結(jié)合深度學(xué)習(xí)技術(shù)相結(jié)合為代表的。第一代自動(dòng)駕駛感知技術(shù)框架中的多種任務(wù),例如:目標(biāo)檢測(cè)和語(yǔ)義分割任務(wù),都必須和輸入數(shù)據(jù)處于相同坐標(biāo)系統(tǒng)下實(shí)施。如下圖2所示,唯一例外的是相機(jī)感知任務(wù),它是在2D圖像的透視空間中運(yùn)行的。但是,為了從2D空間升級(jí)到3D空間,2D檢測(cè)任務(wù)需要很多關(guān)于傳感器融合的手動(dòng)規(guī)則,例如使用雷達(dá)或者激光雷達(dá)等傳感器進(jìn)行3D測(cè)量。因此,傳統(tǒng)感知系統(tǒng)通常需要在與車(chē)載攝像機(jī)圖像相同的空間內(nèi)進(jìn)行處理。為了將2D空間中的位置信息更新到3D空間,后續(xù)的預(yù)測(cè)和規(guī)劃任務(wù)常常用于多傳感器融合,如借助毫米波雷達(dá)或激光雷達(dá)等有源傳感器。
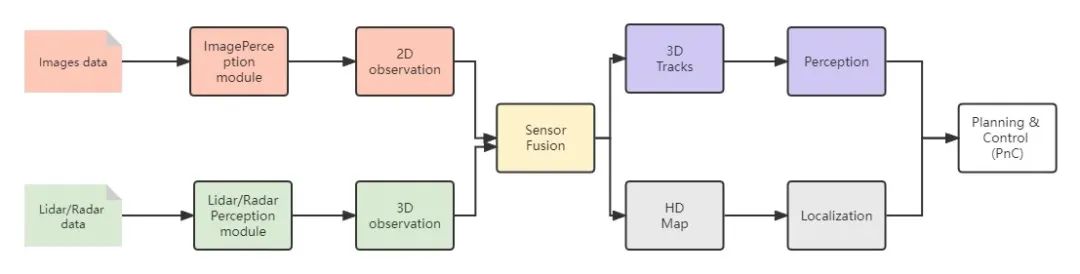
▲圖2?SLAM+DL的自動(dòng)駕駛技術(shù)框架
■2.2問(wèn)題和挑戰(zhàn)
但是,上述基于SLAM+DL的第一代自動(dòng)駕駛技術(shù)暴露出越來(lái)越多的問(wèn)題: 1)整個(gè)自動(dòng)駕駛系統(tǒng)最上游的是感知模塊,尤其當(dāng)傳感器的類(lèi)型和數(shù)量變的越來(lái)越復(fù)雜,如何融合持續(xù)輸入的多模態(tài)和不同視圖數(shù)據(jù),并實(shí)時(shí)輸出下游所需的一系列任務(wù)結(jié)果,成為自動(dòng)駕駛的核心挑戰(zhàn)。 2)感知環(huán)節(jié)通常會(huì)消耗車(chē)輛的大部分算力。在感知過(guò)程中,系統(tǒng)需要融合不同視角攝像頭的視覺(jué)數(shù)據(jù)以及毫米波雷達(dá)、激光雷達(dá)等傳感器的數(shù)據(jù),這給模型設(shè)計(jì)和工程實(shí)現(xiàn)帶來(lái)了挑戰(zhàn)。在傳統(tǒng)的融合后處理方法中,每個(gè)傳感器對(duì)應(yīng)一個(gè)神經(jīng)網(wǎng)絡(luò),無(wú)法充分發(fā)揮多傳感器融合的優(yōu)勢(shì),而且計(jì)算量大、耗時(shí)長(zhǎng)。此外,如果多個(gè)任務(wù)簡(jiǎn)單地共享一個(gè)骨干網(wǎng)絡(luò),很容易導(dǎo)致每個(gè)任務(wù)難以同時(shí)獲得優(yōu)異的性能,如圖3所示。
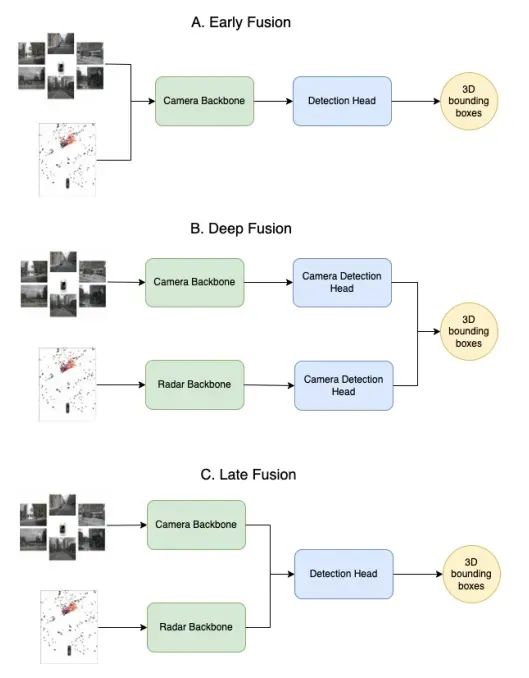
▲圖3|一種多模態(tài)融合算法示意圖
■3.1 BEV方案基本流程 ·簡(jiǎn)介 BEV(鳥(niǎo)瞰視圖)模型
基于多個(gè)攝像頭甚至不同傳感器,可以被視為解決上述SLAM+DL第一代自動(dòng)駕駛技術(shù)問(wèn)題的潛在技術(shù)方案,本文將BEV+Transformer結(jié)合技術(shù)成為自動(dòng)駕駛感知2.0時(shí)代。如圖4所示,BEV以鳥(niǎo)瞰圖視角呈現(xiàn)車(chē)輛信息,是自動(dòng)駕駛系統(tǒng)中跨攝像頭和多模態(tài)融合的體現(xiàn)。其核心思想是將傳統(tǒng)的2D圖像感知轉(zhuǎn)為3D感知。對(duì)于BEV感知來(lái)說(shuō),關(guān)鍵在于將2D圖像作為輸入并輸出3D感知幀,而如何在多攝像頭視角下高效優(yōu)雅地獲得最佳特征表示仍是一個(gè)難題。
目前,基于多視角相機(jī)的BEV3D物體檢測(cè)感知任務(wù),受到越來(lái)越多的關(guān)注。如圖5所示,在BEV視圖下,統(tǒng)一和描述不同視角的信息是非常直觀自然的,這為后續(xù)規(guī)劃和控制模塊的任務(wù)提供了便利。此外,BEV視圖下的物體在2D視角下不存在遮擋和比例問(wèn)題,有助于提高檢測(cè)性能。BEV模型還有助于提高感知融合的性能,并通過(guò)統(tǒng)一的模型實(shí)現(xiàn)從純視覺(jué)感知到多傳感器融合解決方案的邏輯一致性,從而降低額外的開(kāi)發(fā)成本。
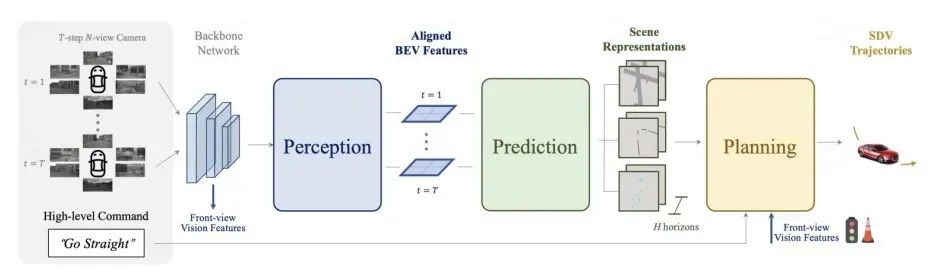
▲圖5|純視覺(jué)的端到端規(guī)劃框架
· BEV技術(shù)方法 目前為止,BEV研究主要基于深度學(xué)習(xí)方法。根據(jù)BEV特征信息的組織方式,主流方法可分為不同架構(gòu)的模式。
■3.2 自底向上?vs.?自頂向下
· 自底向上方法 自底向上法采用了從2D到3D的模式:
1)首先,在2D視圖下估計(jì)每個(gè)像素的深度信息,然后基于相機(jī)內(nèi)外參數(shù)將圖像映射到BEV空間。 ?
2)然后,通過(guò)融合多個(gè)視圖生成BEV特征。
這種方法的早期代表方法是LSS(Lift、Splat、Shoot),如圖6所示,它構(gòu)建了一個(gè)簡(jiǎn)單而有效的處理過(guò)程:
1)將2D相機(jī)圖像投射到3D場(chǎng)景中;
2)然后從上帝視角把得到的3D場(chǎng)景“壓扁”,形成BEV視圖。
平面場(chǎng)景符合人們對(duì)地圖的直觀感覺(jué),雖然已經(jīng)獲得了三維場(chǎng)景數(shù)據(jù),但并不是完整的三維數(shù)據(jù),因?yàn)閺?BEV 的角度來(lái)看,無(wú)法獲得準(zhǔn)確的三維高度信息,所以需要將其扁平化。自下而上法的核心步驟是:
1)拉升----在對(duì)每幅相機(jī)圖像進(jìn)行圖像平面下采樣后,準(zhǔn)確估計(jì)特征點(diǎn)的深度分布,并獲得包含圖像特征的視錐(點(diǎn)云);
2)拍打----結(jié)合攝像機(jī)的內(nèi)部和外部參數(shù),將所有攝像機(jī)的視錐(點(diǎn)云)分布到 BEV 網(wǎng)格中,并對(duì)每個(gè)網(wǎng)格中的多個(gè)視錐點(diǎn)進(jìn)行求和匯集計(jì)算,形成BEV 特征圖;
3)拍攝----使用任務(wù)頭處理 BEV 特征圖,輸出感知結(jié)果。
LSS 和 BEVDepth等算法基于 LSS 框架進(jìn)行了優(yōu)化,是 BEV 算法的經(jīng)典之作。 · 自頂向下方法 自頂向下法采用了從3D到2D的模式:
1)這類(lèi)方法首先初始化BEV空間中的特征;
2)然后通過(guò)一個(gè)多層的Transformer與每個(gè)圖像特征進(jìn)行交互,得到與之對(duì)應(yīng)的BEV特征。
Transformer 是谷歌在 2017 年提出的一種基于注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)模型。與傳統(tǒng)的 RNN 和 CNN 不同,Transformer 通過(guò)注意力機(jī)制挖掘序列中不同元素之間的聯(lián)系和關(guān)聯(lián),從而適應(yīng)不同長(zhǎng)度和結(jié)構(gòu)的輸入。Transformer 首先在自然語(yǔ)言處理(NLP)領(lǐng)域取得了巨大成功,隨后被應(yīng)用于計(jì)算機(jī)視覺(jué)(CV)任務(wù),并取得了顯著效果。 這種自頂向下的方法逆轉(zhuǎn)了 BEV 的構(gòu)建過(guò)程,利用 Transformer 的全局感知能力從多個(gè)透視圖像的特征中查詢(xún)相應(yīng)信息,并將這些信息融合和更新到BEV 特征圖中。特斯拉在其 FSD Beta 軟件視覺(jué)感知模塊中采用了這種自上而下的方法,并在特斯拉 AI-Day上展示了有關(guān) BEVFormer的更多技術(shù)理念。
■3.3?純視覺(jué)還是多傳感器融合?
BEV 目前已經(jīng)是自動(dòng)駕駛領(lǐng)域一個(gè)龐大的算法家族,包括不同方向的算法選擇。其中,以視覺(jué)感知為主的流派由特斯拉主導(dǎo),核心算法建立在多個(gè)攝像頭上。另一大流派是融合派,利用激光雷達(dá)、毫米波雷達(dá)和多個(gè)攝像頭進(jìn)行感知。許多自動(dòng)駕駛公司都采用了融合式算法,谷歌的 Waymo 也是如此。從輸入信號(hào)的角度來(lái)看,BEV 可分為視覺(jué)流派和激光雷達(dá)流派。
· BEV相機(jī)
BEV 相機(jī)指的是基于多個(gè)視角的圖像序列,算法需要將這些視角轉(zhuǎn)換為 BEV 特征并對(duì)其進(jìn)行感知,例如輸出物體的三維檢測(cè)幀或在俯視圖下進(jìn)行語(yǔ)義分割。與激光雷達(dá)相比,視覺(jué)感知具有更豐富的語(yǔ)義信息,但缺乏精確的深度測(cè)量。此外,BEV 的 DNN 模型需要在訓(xùn)練階段指出照片中的每個(gè)物體是什么,并在標(biāo)注數(shù)據(jù)上標(biāo)注各種物體。如果遇到訓(xùn)練集中沒(méi)有的物體類(lèi)型,或者模型表現(xiàn)不佳,就會(huì)出現(xiàn)問(wèn)題。 為了解決這個(gè)問(wèn)題,Occupancy Network改變了感知策略,不再?gòu)?qiáng)調(diào)分類(lèi),而是關(guān)注道路上是否有障礙物。這種障礙物可以用三維積木來(lái)表示,有些地方稱(chēng)之為體素(voxel)。這種方法更為貼切,無(wú)論障礙物的具體類(lèi)型如何,都能保證不撞擊障礙物。 特斯拉正在經(jīng)歷從 BEV 技術(shù)(鳥(niǎo)瞰圖)到新技術(shù)--occupancy network(占用網(wǎng)絡(luò))的過(guò)渡,從二維到三維。無(wú)論是二維還是三維,它們都致力于描述車(chē)輛周?chē)臻g的占用情況,但使用的表示方法不同。在二維 BEV 中,我們使用類(lèi)似棋盤(pán)的方法來(lái)表達(dá)環(huán)境中的占用情況;而在三維占用網(wǎng)絡(luò)中,它們使用類(lèi)似積木的體素來(lái)表達(dá)。 具體來(lái)說(shuō),在 BEV 技術(shù)中,深度學(xué)習(xí)模型(DNN)通過(guò)概率來(lái)衡量不同位置的占用率,通常將物體分為兩類(lèi):
1)不經(jīng)常變化的物體,如車(chē)輛可通過(guò)區(qū)域(Driveable)、路面(Road )、車(chē)道(Lane)、建筑物(Building)、植被(Foliage/Vegetation)、停車(chē)區(qū)域(Parking)、信號(hào)燈(TrafficLight)以及一些未分類(lèi)的靜態(tài)物體(Static),這些類(lèi)別可以相互包含。
2)另一類(lèi)是可變物體,即會(huì)移動(dòng)的物體,如行人(Pedestrian)、汽車(chē)(Car)、卡車(chē)(Truck)、錐形交通標(biāo)志/安全桶(TrafficCone)等。
這種分類(lèi)的目的是幫助自動(dòng)駕駛系統(tǒng)進(jìn)行后續(xù)的駕駛規(guī)劃和控制。在BEV的感知階段,算法根據(jù)物體出現(xiàn)在網(wǎng)格上的概率進(jìn)行打分,并通過(guò)Softmax函數(shù)對(duì)概率進(jìn)行歸一化處理,最后選擇概率最高的物體類(lèi)型對(duì)應(yīng)的網(wǎng)格作為占據(jù)網(wǎng)格的預(yù)測(cè)結(jié)果。
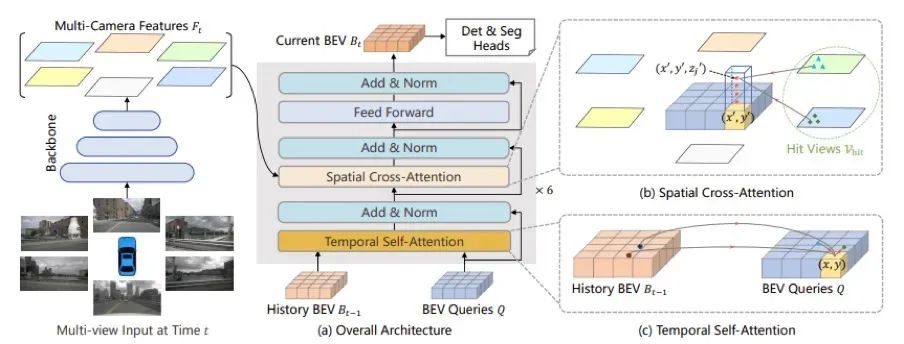
▲圖7|BEVFormer流程
BEVFormer的詳細(xì)流程如下:
1)使用基干和脖頸模塊(使用 ResNet-101-DCN + FPN)從環(huán)視圖像中提取多尺度特征。
2)編碼器模塊(包括時(shí)間自注意力模塊和空間交叉注意力模塊)使用本文提出的方法將環(huán)視圖像特征轉(zhuǎn)換為 BEV 特征。
3)與可變形 DETR 的解碼器模塊類(lèi)似,它完成三維物體檢測(cè)的分類(lèi)和定位任務(wù)。
4)使用匈牙利匹配算法定義正負(fù)樣本,并使用 Focal Loss + L1 Loss 作為總損失來(lái)優(yōu)化網(wǎng)絡(luò)參數(shù)。
5)計(jì)算損失時(shí)使用 Focal Loss 分類(lèi)損失和 L1 Loss 回歸損失,然后執(zhí)行反向傳播并更新網(wǎng)絡(luò)模型參數(shù)。
在算法創(chuàng)新方面,BEVFormer 采用 Transformer 和時(shí)間結(jié)構(gòu)來(lái)聚合時(shí)空信息。它利用預(yù)定義的網(wǎng)格狀 BEV 查詢(xún)與空間/時(shí)間特征進(jìn)行交互,以查找和聚合時(shí)空信息。這種方法能有效捕捉三維場(chǎng)景中物體的時(shí)空關(guān)系,并生成更強(qiáng)大的表征。這些創(chuàng)新使 BEVFormer 能夠更好地處理環(huán)境中的物體檢測(cè)和場(chǎng)景理解任務(wù)。 · BEV融合
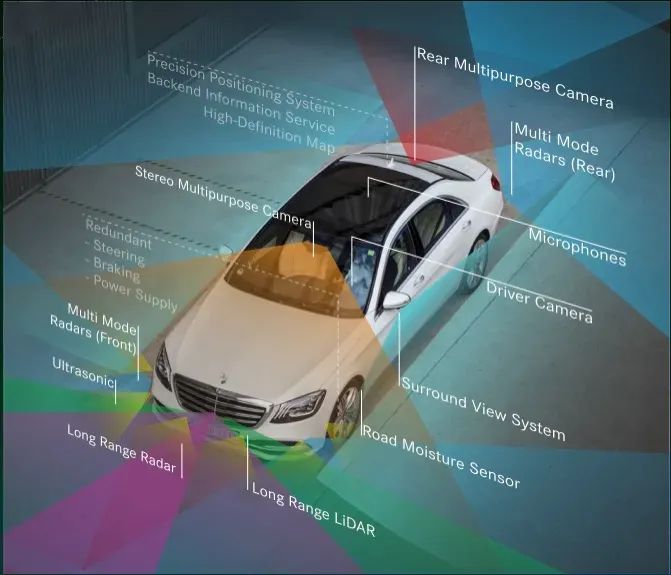
▲圖8|奔馳智能駕駛配備的傳感器套件
BEV 融合學(xué)派在自動(dòng)駕駛領(lǐng)域的主要任務(wù)是融合各種傳感器的數(shù)據(jù),如圖 8所示,包括攝像頭、激光雷達(dá)、GNSS(全球?qū)Ш叫l(wèi)星系統(tǒng))、里程表、高精度地圖(HD-Map)、CAN總線等。這種融合機(jī)制可以充分利用各個(gè)傳感器的優(yōu)勢(shì),提高自動(dòng)駕駛系統(tǒng)對(duì)周?chē)h(huán)境的感知和理解能力。 除了攝像頭,融合學(xué)派還關(guān)注激光雷達(dá)的數(shù)據(jù)。與毫米波雷達(dá)相比,激光雷達(dá)的數(shù)據(jù)質(zhì)量更高,因此毫米波雷達(dá)逐漸退出了主要用途,在一些車(chē)輛中繼續(xù)充當(dāng)停車(chē)?yán)走_(dá)。
然而,毫米波雷達(dá)仍有其獨(dú)特的價(jià)值,尤其是在自動(dòng)駕駛領(lǐng)域技術(shù)日新月異的背景下。新算法可能會(huì)讓毫米波雷達(dá)重新發(fā)揮作用。 激光雷達(dá)的優(yōu)勢(shì)在于可以直接測(cè)量物體的距離,其精度遠(yuǎn)高于視覺(jué)推測(cè)的場(chǎng)景深度。激光雷達(dá)通常將測(cè)量結(jié)果轉(zhuǎn)化為深度數(shù)據(jù)或點(diǎn)云,這兩種數(shù)據(jù)形式的應(yīng)用歷史悠久,成熟的算法可以直接借鑒,從而減少開(kāi)發(fā)工作量。此外,激光雷達(dá)在夜間或惡劣天氣條件下仍能正常工作,而相機(jī)在這種情況下可能會(huì)受到很大影響,導(dǎo)致無(wú)法準(zhǔn)確感知周?chē)h(huán)境。 總之,融合學(xué)派的目標(biāo)是有效整合多傳感器數(shù)據(jù),使自動(dòng)駕駛系統(tǒng)在各種復(fù)雜條件下獲得更全面、更準(zhǔn)確的環(huán)境感知,從而提高駕駛的安全性和可靠性。融合技術(shù)在自動(dòng)駕駛領(lǐng)域發(fā)揮著關(guān)鍵作用。它融合了來(lái)自不同傳感器的信息,使整個(gè)系統(tǒng)能更好地感知和理解周?chē)h(huán)境,做出更準(zhǔn)確的決策和計(jì)劃。
■4.1 為什么是BEV感知?
首先,自動(dòng)駕駛是一個(gè) 3D 或 BEV 感知問(wèn)題。使用 BEV 視角可以提供更全面的場(chǎng)景信息,幫助車(chē)輛感知周?chē)h(huán)境并做出準(zhǔn)確決策。在傳統(tǒng)的二維視角中,由于透視效應(yīng),物體可能會(huì)出現(xiàn)遮擋和比例問(wèn)題,而 BEV 視角可以有效解決這些問(wèn)題。 與以往自動(dòng)駕駛領(lǐng)域基于正視圖或透視圖進(jìn)行檢測(cè)、分割、跟蹤等任務(wù)的大多數(shù)模型相比,BEV 表示法能使模型更好地識(shí)別遮擋的車(chē)輛,有利于后續(xù)模塊(如預(yù)測(cè)、規(guī)劃控制)的開(kāi)發(fā)和部署。同時(shí),它還能將二維圖像特征精確轉(zhuǎn)換為三維特征,并能將提取的 BEV 特征應(yīng)用于不同的探測(cè)頭。 另一個(gè)重要原因是促進(jìn)多模態(tài)融合。自動(dòng)駕駛系統(tǒng)通常使用多種傳感器,如攝像頭、激光雷達(dá)、毫米波雷達(dá)等。BEV視角可以將不同傳感器的數(shù)據(jù)統(tǒng)一表達(dá)在同一平面上,這使得傳感器數(shù)據(jù)的融合和處理更加方便。在現(xiàn)有技術(shù)中,將單視角檢測(cè)擴(kuò)展到多視角檢測(cè)是不可行的。 這是因?yàn)閱我暯菣z測(cè)器只能處理單個(gè)攝像頭的圖像數(shù)據(jù),而在多視角的情況下,檢測(cè)結(jié)果需要根據(jù)相應(yīng)攝像頭的內(nèi)外部參數(shù)進(jìn)行轉(zhuǎn)換,才能完成多視角檢測(cè)。然而,這種簡(jiǎn)單的后處理方法無(wú)法用于數(shù)據(jù)驅(qū)動(dòng)訓(xùn)練,因?yàn)樽儞Q是單向的,無(wú)法反向區(qū)分不同特征的坐標(biāo)系原點(diǎn)。這使得我們無(wú)法輕松地使用端到端訓(xùn)練模型來(lái)改進(jìn)自動(dòng)感知系統(tǒng)。為了解決這些問(wèn)題,基于變換器的 BEV 感知技術(shù)應(yīng)運(yùn)而生。 總之,對(duì)于攝像頭的感知而言,轉(zhuǎn)向 BEV 將大有裨益:
1)直接在 BEV 中執(zhí)行攝像頭感知可直接與雷達(dá)或激光雷達(dá)等其他模式的感知結(jié)果相結(jié)合,因?yàn)樗鼈円言?BEV中表示和使用。BEV 空間中的感知結(jié)果也很容易被預(yù)測(cè)和規(guī)劃等下游組件使用。
2)純粹通過(guò)手工創(chuàng)建的規(guī)則將 2D 觀察結(jié)果提升到 3D 是不可擴(kuò)展的。BEV 表示法有助于向早期融合管道過(guò)渡,使融合過(guò)程完全由數(shù)據(jù)驅(qū)動(dòng)。
3)在沒(méi)有雷達(dá)或激光雷達(dá)的純視覺(jué)系統(tǒng)中,通過(guò)BEV 執(zhí)行感知任務(wù)幾乎是強(qiáng)制的,因?yàn)樵趥鞲衅魅诤现袥](méi)有其他三維線索可用于執(zhí)行這種視圖轉(zhuǎn)換。之所以選擇從 BEV 的角度進(jìn)行感知,是為了提高感知的準(zhǔn)確性和穩(wěn)定性,并為多模態(tài)融合和端到端優(yōu)化創(chuàng)造條件,從而推動(dòng)自動(dòng)駕駛技術(shù)的發(fā)展。
■4.2 為什么是BEV+Transformer?
為什么?"BEV+Transformer "會(huì)成為主流模式?其背后的關(guān)鍵在于?"第一原則",即智能駕駛應(yīng)該越來(lái)越接近?"像人一樣駕駛",而映射到感知模型本身,BEV 是一種更自然的表達(dá)方式,由于全局注意力機(jī)制,變形器更適合進(jìn)行視圖轉(zhuǎn)換。目標(biāo)域中的每個(gè)位置訪問(wèn)源域中任何位置的距離都是相同的,克服了 CNN 中卷積層感受野的局部局限性。此外,與傳統(tǒng)的 CNN 相比,視覺(jué)轉(zhuǎn)換器還有幾個(gè)優(yōu)勢(shì):更好的可解釋性和更好的靈活性。隨著產(chǎn)學(xué)研的推進(jìn),BEV+Transformer 最近已從普及走向量產(chǎn),這在當(dāng)前智能駕駛的商業(yè)顛覆背景下或許是一個(gè)難得的亮點(diǎn)。
1. 數(shù)據(jù)采集和預(yù)處理 BEV 透視需要進(jìn)行大量的數(shù)據(jù)采集和預(yù)處理,這對(duì)場(chǎng)景感知的性能和效果有著重要影響。其中,需要解決多相機(jī)圖像融合、數(shù)據(jù)對(duì)齊、畸變校正等問(wèn)題。同時(shí),變換器需要海量數(shù)據(jù),如何獲取高質(zhì)量的海量數(shù)據(jù)也是一個(gè)重要的研究課題。 2. Transformer是暴力美學(xué),模型體積驚人,其計(jì)算會(huì)消耗大量的存儲(chǔ)和帶寬空間。對(duì)于芯片而言,除了相應(yīng)的運(yùn)算器適配和底層軟件優(yōu)化外,還需要對(duì)緩存和帶寬進(jìn)行優(yōu)化,要求也隨之提高。與此同時(shí),還需要對(duì)模型進(jìn)行優(yōu)化。
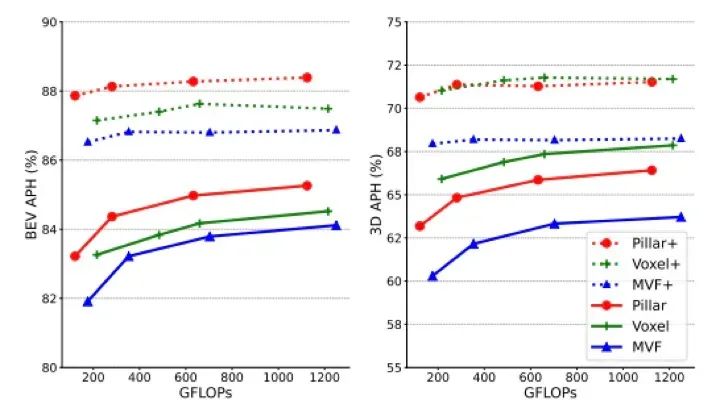
▲圖9|模型優(yōu)化性能對(duì)比圖
3. 更多傳感器融合:?目前,BEV 透視技術(shù)主要使用激光雷達(dá)和攝像頭等傳感器進(jìn)行數(shù)據(jù)采集和處理,但仍需要更多傳感器的融合,如圖10所示的毫米波雷達(dá)、GPS等,以提高數(shù)據(jù)的準(zhǔn)確性和全面性。
▲圖10|更多的傳感器數(shù)據(jù)融合
4. 穩(wěn)健優(yōu)化:BEV 在復(fù)雜環(huán)境中的應(yīng)用面臨諸多挑戰(zhàn),如天氣變化、光照變化、目標(biāo)遮擋、對(duì)抗性攻擊等。未來(lái)有必要加強(qiáng)算法的魯棒優(yōu)化,以提高系統(tǒng)的穩(wěn)定性和可靠性。
5. 應(yīng)用場(chǎng)景更多:BEV 技術(shù)的應(yīng)用場(chǎng)景非常廣泛,包括自動(dòng)駕駛、智能交通、物流配送、城市規(guī)劃等領(lǐng)域,如圖12中的機(jī)器人。自動(dòng)駕駛與 BEV 的融合可以提供全方位的場(chǎng)景信息,有利于車(chē)輛準(zhǔn)確感知周?chē)奈矬w和環(huán)境,實(shí)現(xiàn)高效、安全的自動(dòng)駕駛。BEV視角下的智能交通可以提供更直觀、更全面的路況信息,有利于實(shí)現(xiàn)高效的路況監(jiān)測(cè)和交通管理,提高城市交通的效率和安全性。物流配送與 BEV 的結(jié)合可以提供更準(zhǔn)確、更全面的貨物位置和空間信息,有利于實(shí)現(xiàn)高效的物流配送,提高物流效率和服務(wù)質(zhì)量。未來(lái),應(yīng)用領(lǐng)域還可以進(jìn)一步拓展,如農(nóng)業(yè)、礦業(yè)等領(lǐng)域,滿(mǎn)足不同領(lǐng)域的需求。
▲圖12|BEV在機(jī)器人領(lǐng)域中的應(yīng)用
總結(jié)
從行業(yè)發(fā)展趨勢(shì)來(lái)看,BEV 模式及其應(yīng)用或?qū)⒊蔀橹髁髭厔?shì)。這意味著從芯片開(kāi)始,傳感器芯片、攝像頭、軟件算法等都需要快速適應(yīng),快速實(shí)現(xiàn)解決方案。 綜上所述,BEV 是繼深度學(xué)習(xí)之后的又一新高度,它解決了以往多傳感器變化和異構(gòu)帶來(lái)的各種融合感知算法的發(fā)展難題。從原理上講,與傳統(tǒng)的感知算法相比,BEV 的輸入相同,都是多通道傳感器信息,最后直接輸出三維空間規(guī)劃和控制所需的輸出形式。BEV 基于二維數(shù)據(jù),提供鳥(niǎo)瞰視角,與 SLAM 相輔相成,為自動(dòng)駕駛的發(fā)展和實(shí)現(xiàn)帶來(lái)了更多可能。隨著技術(shù)的不斷進(jìn)步,感知模塊也將不斷發(fā)展,更高效、更精準(zhǔn)的感知技術(shù)將推動(dòng)自動(dòng)駕駛技術(shù)走向更廣闊的未來(lái),為人類(lèi)社會(huì)的進(jìn)步貢獻(xiàn)更多價(jià)值。
審核編輯:黃飛














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論