 電子發(fā)燒友App
電子發(fā)燒友App


上篇文章NVIDIA ADAS-英偉達(dá)DriveOS入門,介紹了英偉達(dá)的軟件,本篇文章來說明下現(xiàn)在英偉達(dá)在智能駕駛上已商用最新的硬件芯片Orin。
目前Orin訂單火爆,上汽的R和智己,理想L9、蔚來ET7、小鵬新一代P7,威馬M7、比亞迪、沃爾沃XC90,還有自動(dòng)駕駛卡車公司智加科技,Robotaxi等眾多明星企業(yè)Cruise、Zoox、滴滴、小馬智行、AutoX、軟件公司Momonta等等,都搭載Orin平臺(tái)進(jìn)行開發(fā),看陣容就不可小覷,可謂地表最強(qiáng)算力芯片。
1. 英偉達(dá)智駕SoC芯片發(fā)展史
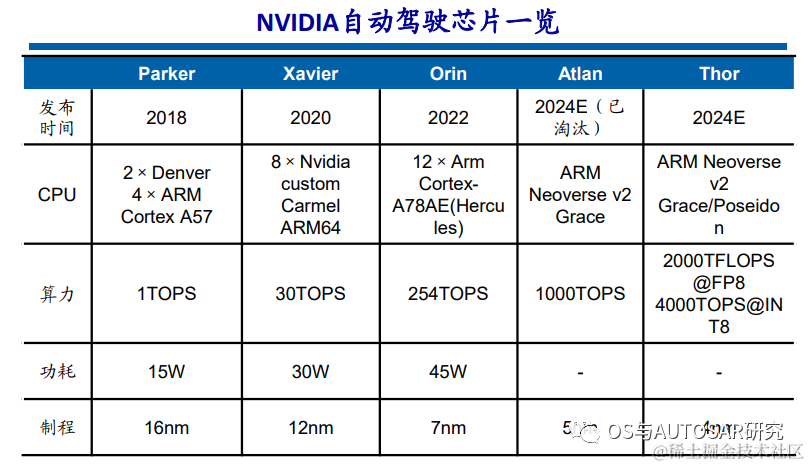
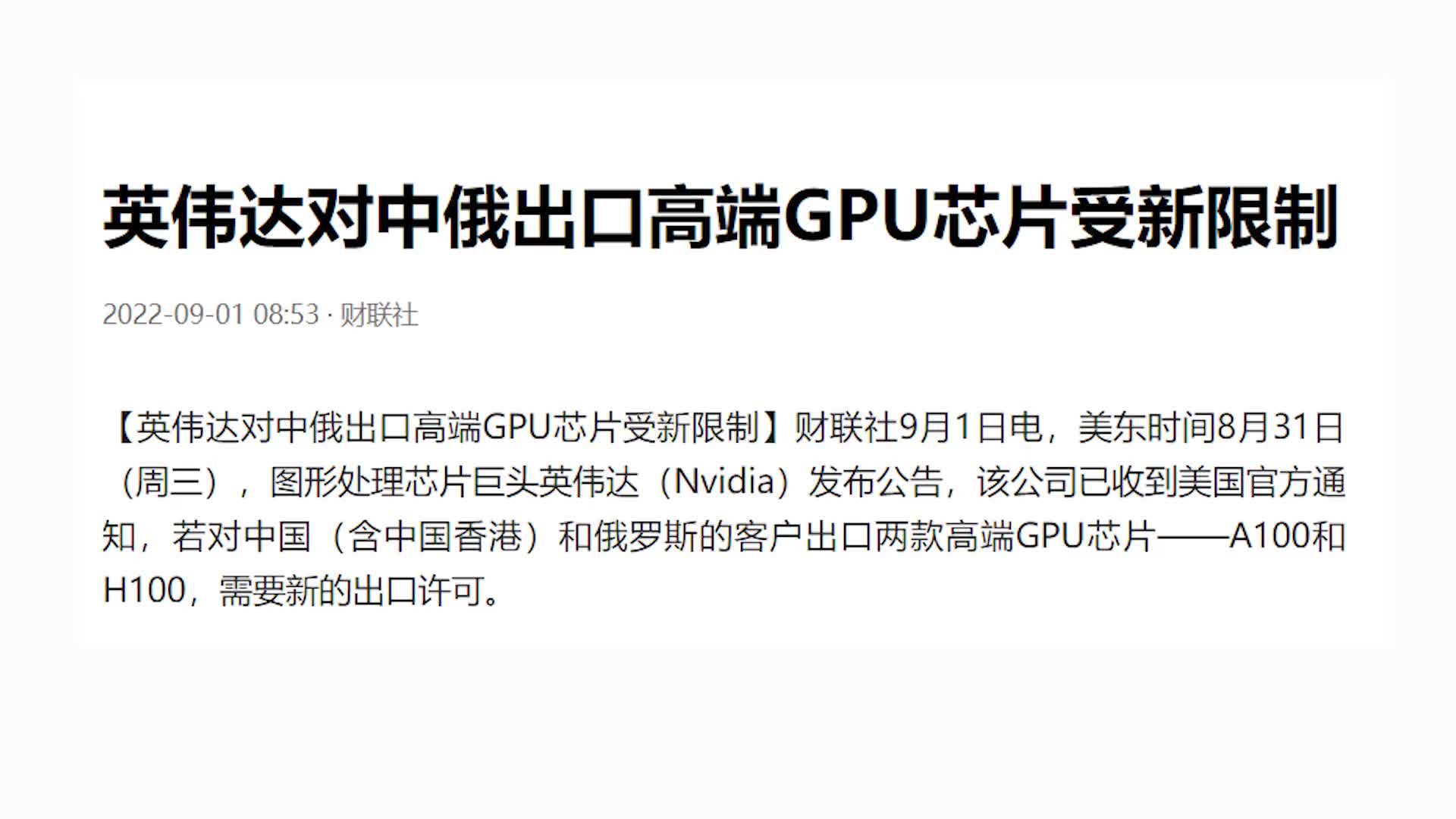
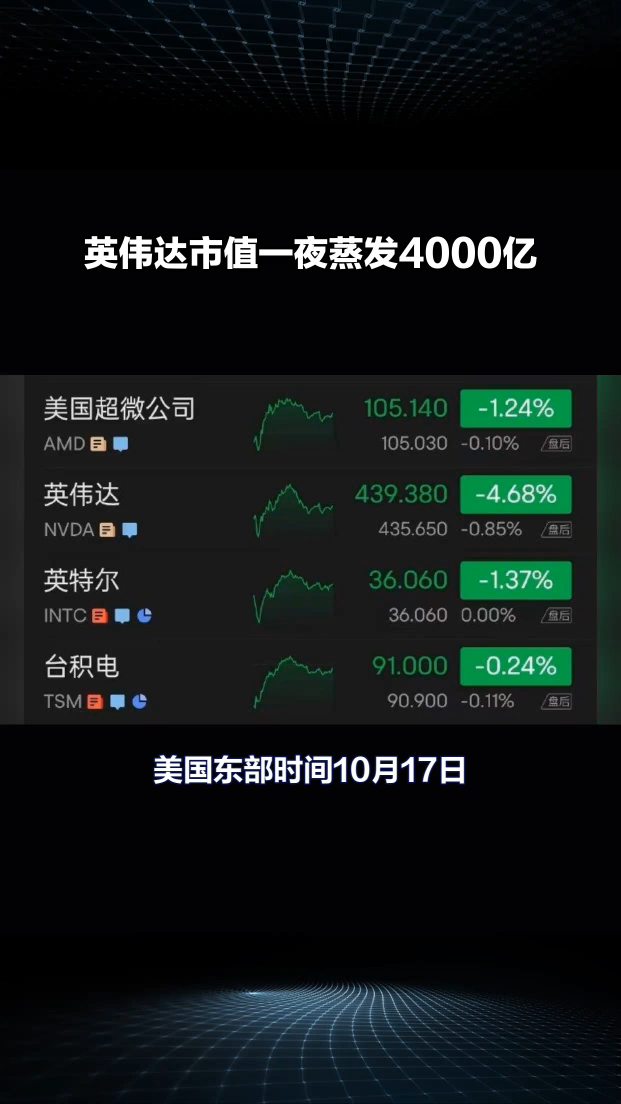
從2015年開始,英偉達(dá)開始進(jìn)入車載SoC和車載計(jì)算平臺(tái)領(lǐng)域,為自動(dòng)駕駛提供基礎(chǔ)計(jì)算能力。此后英偉達(dá)幾乎每隔兩年發(fā)布一款車規(guī)級(jí)SoC芯片,且不斷拉升算力水平。2020年,Xavier芯片算力為30 TOPS,2022年發(fā)布的Orin算力為254 TOPS,2022秋季GTC大會(huì)上發(fā)布了新自動(dòng)駕駛芯片Thor,算力為2000TFLOPS@FP8、4000TOPS@INT8,取代了之 前發(fā)布的算力達(dá)1000TOPS的Altan。
也就是說目前商用最新的芯片就是Orin。英偉達(dá)使用的車企陣容強(qiáng)大,如下圖:

1.1 Xavier平臺(tái)
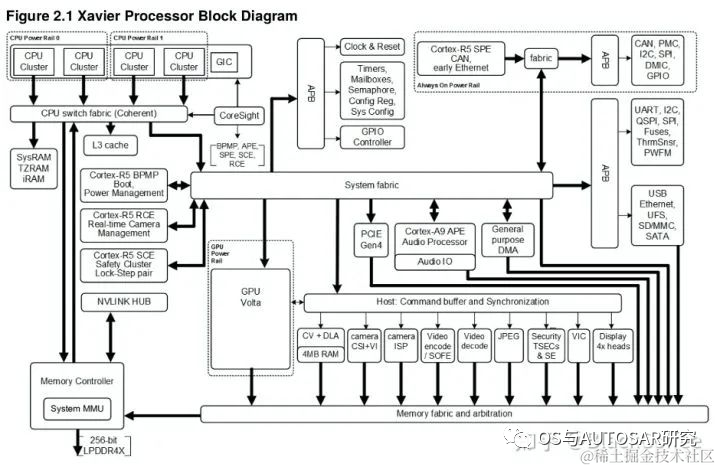
NVIDIA在2018年CES上推出了Xavier平臺(tái),作為Driver PX2 的進(jìn)化版本。NVIDIA稱Xavier 是“世界上最強(qiáng)大的SoC(片上系統(tǒng))”,Xavier可處理來自車輛雷達(dá)、攝像頭、激光雷達(dá)和超聲波等傳感器的自主駕駛感知數(shù)據(jù),能效比市場(chǎng)上同類產(chǎn)品更高,體積更小。“NVIDIA Jetson AGX Xavier 為邊緣設(shè)備的計(jì)算密度、能效和 AI 推理能力樹立了新的標(biāo)桿。”
2020年4月上市的小鵬汽車P7,成為首款搭載 NVIDIA DRIVE AGX Xavier 自動(dòng)駕駛平臺(tái)的量產(chǎn)車型,小鵬 P7 配備了13 個(gè)攝像頭、5 個(gè)毫米波雷達(dá)、12 個(gè)超聲波雷達(dá),集成開放式的 NVIDIA DRIVE OS 操作系統(tǒng)。
Xavier SoC基于臺(tái)積電12nm FinFET工藝,集成90億顆晶體管,芯片面積350平方毫米,CPU采用NVIDIA自研8核ARM64架構(gòu)(代號(hào)Carmel), 集成了Volta架構(gòu)的GPU(512個(gè)CUDA核心),支持FP32/FP16/INT8,20W功耗下單精度浮點(diǎn)性能1.3TFLOPS,Tensor核心性能20TOPs,解鎖到30W后可達(dá)30TOPs。
Xavier是一顆高度異構(gòu)的SoC處理器,集成多達(dá)八種不同的處理器核心或者硬件加速單元。使得它能同時(shí)、且實(shí)時(shí)地處理數(shù)十種算法,以用于傳感器處理、測(cè)距、定位和繪圖、視覺和感知以及路徑規(guī)劃等任務(wù)負(fù)載。
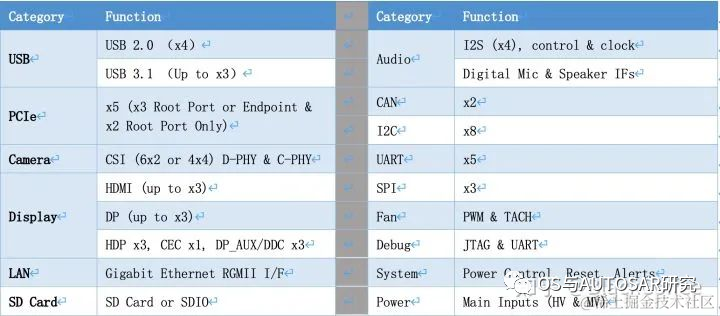
除了強(qiáng)大的計(jì)算資源外,Xavier SoC擁有豐富的IO接口資源:
Xavier的主處理器可以達(dá)到ASIL-B級(jí)別的功能安全等級(jí)需求。Ecotron公司基于NVIDIA Xavier SoC和Infineon TC297 MCU打造、面向L3/L4級(jí)別自動(dòng)駕駛領(lǐng)域的高性能中央計(jì)算平臺(tái)。按照設(shè)計(jì)方案考慮,Xavier智能處理器用于環(huán)境感知、圖像融合、路徑規(guī)劃等,TC297 MCU用于滿足ISO26262功能安全需求(ASIL-C/D級(jí)別)的控制應(yīng)用場(chǎng)景(也即作為Safety Core)?,比如安全監(jiān)控、冗余控制、網(wǎng)關(guān)通訊及整車控制。
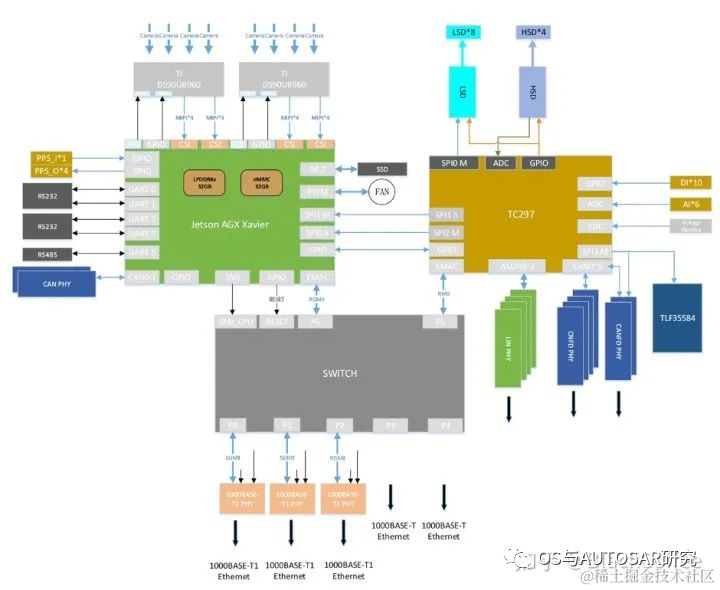
雙Xavier+TC297 MCU的方案結(jié)構(gòu)圖:
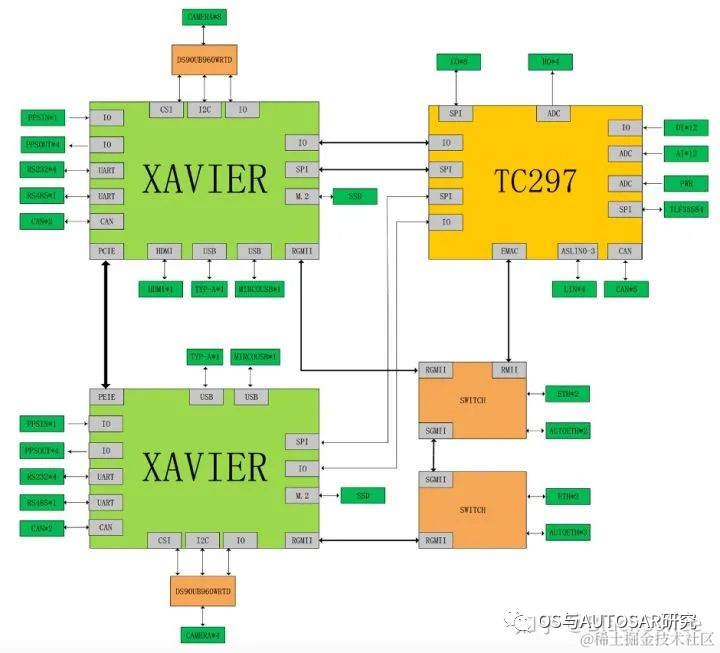
此用法雖然是舊平臺(tái)的,但是其方案之后也是一直繼承的,即TCXXX的車控芯片獨(dú)立運(yùn)行AUTOSAR,這里畫出了兩個(gè)域:智駕域(NVIDIA)+車控域(TC),座艙一般直接使用成熟便宜的手機(jī)安卓技術(shù)了。就看未來是否有中央式架構(gòu)實(shí)現(xiàn)的可能了,目前還是三域架構(gòu)。
1.2 Orin平臺(tái)

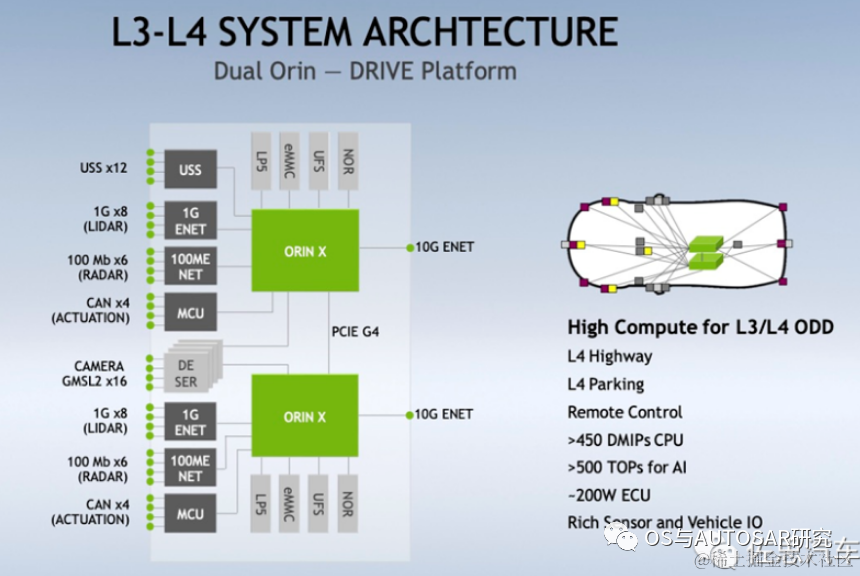
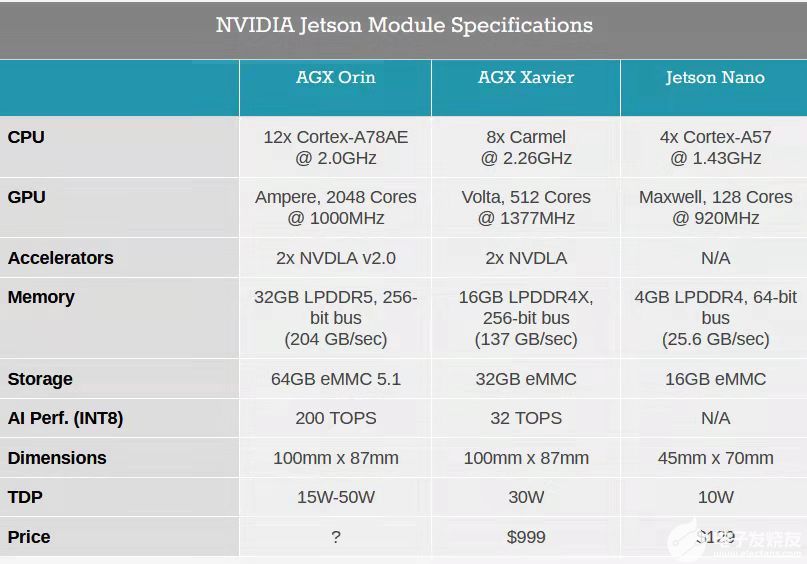
2019年12月英偉達(dá)發(fā)布了新一代面向自動(dòng)駕駛和機(jī)器人領(lǐng)域Orin芯片和計(jì)算平臺(tái)。具有ARM Hercules CPU內(nèi)核和英偉達(dá)下一代GPU架構(gòu)。Orin SoC包含170億晶體管,晶體管的數(shù)量幾乎是Xavier SoC的兩倍,具有12個(gè)ARM Hercules內(nèi)核,將集成Nvidia下一代Ampere架構(gòu)的GPU,提供200 TOPS@INT8性能,接近Xavier SoC的7倍,Orin SOC將在2021年提供樣片,2022年正式面向車廠量產(chǎn)。
2020年5月GTC上,英偉達(dá)介紹了即將發(fā)布的新一代自動(dòng)駕駛Drive AGX Orin平臺(tái),它可以搭載兩個(gè)Orin SoC和兩塊NVIDIA Ampere GPU,可以實(shí)現(xiàn)從入門級(jí)ADAS解決方案到L5級(jí)自動(dòng)駕駛出租車(Robotaxi)系統(tǒng)的全方位性能提升,平臺(tái)最高可提供2000TOPS算力。未來L4/L5級(jí)別的自動(dòng)駕駛系統(tǒng)將需要更復(fù)雜、更強(qiáng)大的自動(dòng)駕駛軟件框架和算法,借助強(qiáng)勁的計(jì)算性能,Orin計(jì)算平臺(tái)將有助于并發(fā)運(yùn)行多個(gè)自動(dòng)駕駛應(yīng)用和深度神經(jīng)網(wǎng)絡(luò)模型算法。
作為一顆專為自動(dòng)駕駛而設(shè)計(jì)的車載智能計(jì)算平臺(tái),Orin可以達(dá)到ISO 26262 ASIL-D 等級(jí)的功能安全標(biāo)準(zhǔn)。
借助于先進(jìn)的7nm制程工藝,Orin擁有非常出色的功耗水平。在擁有200TOPS的巨大算力時(shí),TDP僅為50W。NVIDIA Orin處理器功能模塊圖
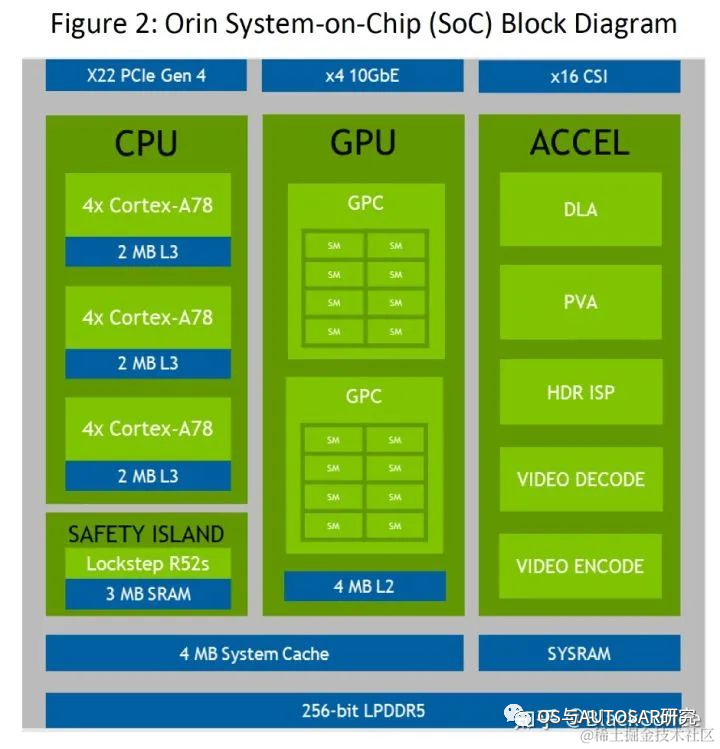
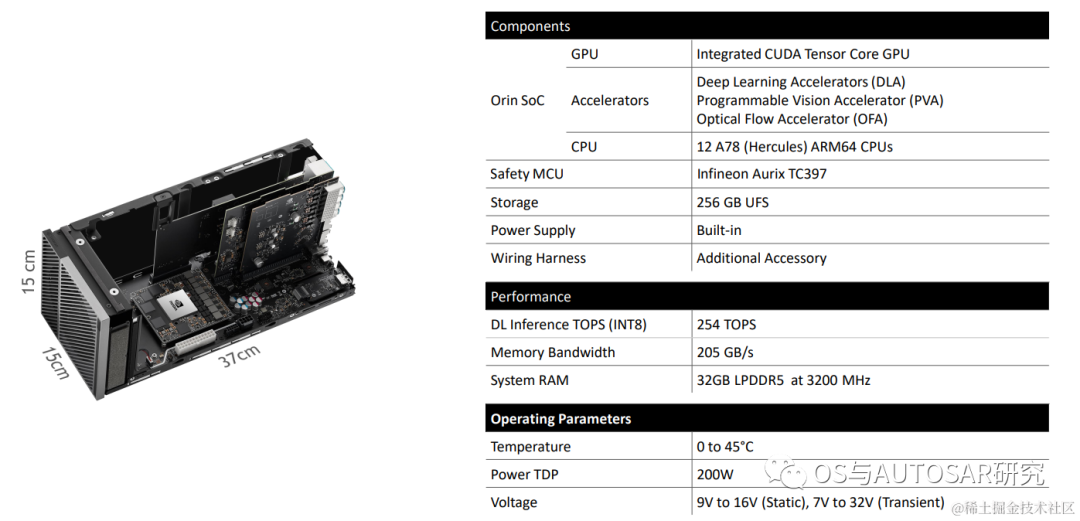
下表是Jetson AGX Orin的片上系統(tǒng)的性能參數(shù):
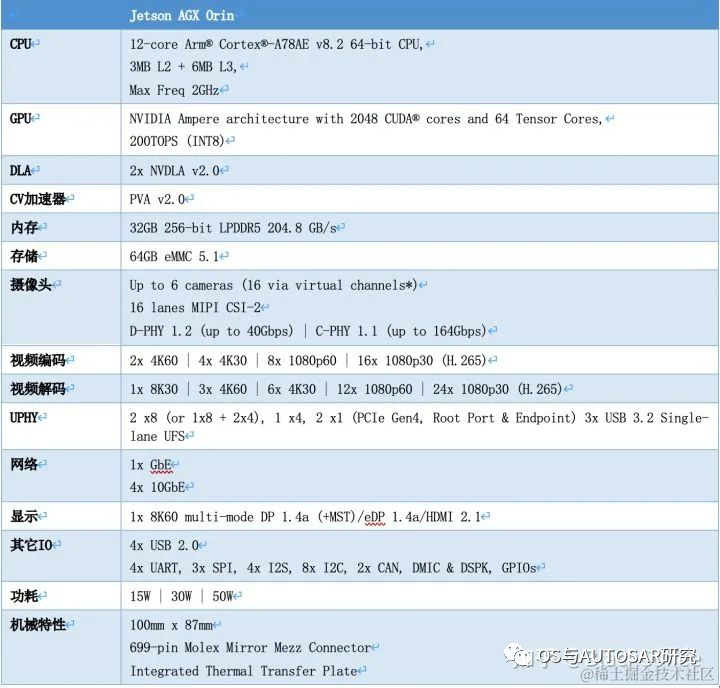
image.png
1.3 Thor平臺(tái)
NVIDIA DRIVE Thor 是NVIDIA新一代集中式車載計(jì)算平臺(tái),可在單個(gè)安全、可靠的系統(tǒng)上運(yùn)行高級(jí)駕駛員輔助應(yīng)用和車載信息娛樂應(yīng)用。DRIVE Thor 超級(jí)芯片借助我們新的 CPU 和 GPU 突破,可提供出色的 2000 萬億次浮點(diǎn)運(yùn)算性能,同時(shí)降低總體系統(tǒng)成本,計(jì)劃于2025年開始量產(chǎn)。
可以看到三域開始變兩域了,智駕和座艙統(tǒng)一了,一統(tǒng)天下看來指日可待了,就需要利用安全技術(shù)解決最后一個(gè)車控MCU就可以了。
DRIVE Thor 還在深度神經(jīng)網(wǎng)絡(luò)準(zhǔn)確性方面實(shí)現(xiàn)了令人難以置信的飛躍。Transformer 引擎是NVIDIA GPU Tensor Core的新組件。Transformer 網(wǎng)絡(luò)將視頻數(shù)據(jù)作為單個(gè)感知幀進(jìn)行處理,使計(jì)算平臺(tái)能夠隨著時(shí)間的推移處理更多數(shù)據(jù)。
該SoC能夠進(jìn)行多域計(jì)算,這意味著它可以劃分自動(dòng)駕駛和車載信息娛樂的任務(wù)。這種多計(jì)算域隔離可以讓并發(fā)的時(shí)間關(guān)鍵進(jìn)程不間斷地運(yùn)行。在一臺(tái)計(jì)算機(jī)上,車輛可以同時(shí)運(yùn)行Linux、QNX和Android。通常,這些類型的功能由分布在車輛各處的數(shù)十個(gè)電子控制單元控制。制造商現(xiàn)在可以利用 DRIVE Thor 隔離特定任務(wù)的能力來整合車輛功能,而不是依賴這些分布式ECU。

所有車輛顯示器、傳感器等都可以連接到這個(gè)單一SoC,從而簡(jiǎn)化了汽車制造商極其復(fù)雜的供應(yīng)鏈。
參考:https://blogs.nvidia.com/blog/drive-thor/
2. Orin架構(gòu)介紹
以 Orin-x 為例,其中的 CPU 包括基于 Arm Cortex-A78AE 的主CPU 復(fù)合體,它提供通用高速計(jì)算能力;以及基于 Arm Cortex-R52 的功能安全島(FSI),它提供了隔離的片上計(jì)算資源, 減少了對(duì)外部 ASIL D 功能安全 CPU 處理的需求。
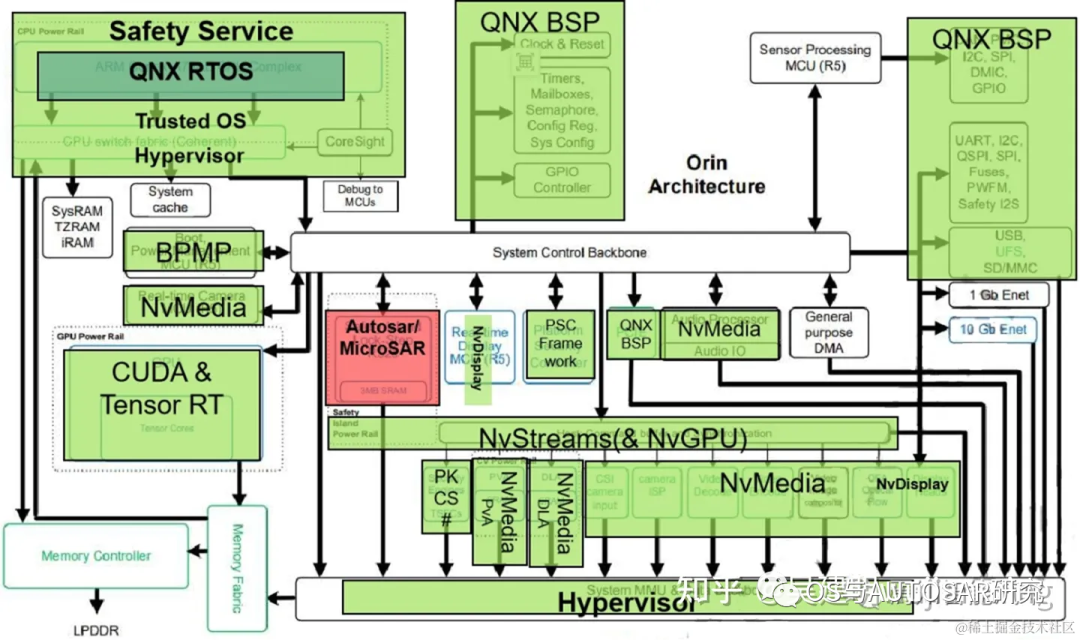
GPU 則是 NVIDIAAmpere GPU,為 CUDA 語言提供高級(jí)并行處理計(jì)算能力,并支持多種工具, 如 TensorRT,一種深度學(xué)習(xí)推理優(yōu)化器和運(yùn)行時(shí),可提供低延遲和高吞吐量。Ampere 還提供最先進(jìn)的圖形功能,包括實(shí)時(shí)光線跟蹤。域特定硬件加速器(DSA)是一組專用硬件引擎,旨在從計(jì)算引擎中卸載各種計(jì)算任務(wù),并以高吞吐量和高能效執(zhí)行這些任務(wù)。
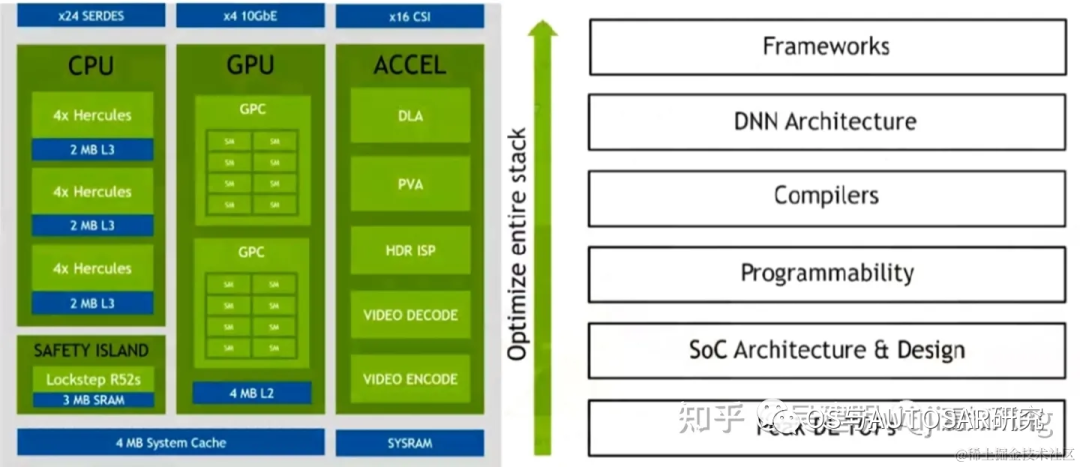
整個(gè)芯片內(nèi)部架構(gòu)設(shè)計(jì)主要是按分塊進(jìn)行功能設(shè)計(jì)區(qū)分。包括操作系統(tǒng)底層軟件QNX BSP(時(shí)鐘Clock源&系統(tǒng)重啟、CAN/SPI/I2C/GPIO/UART控制器、配置寄存器、系統(tǒng)配置)、實(shí)時(shí)運(yùn)行系統(tǒng)QNX RTOS、Nv多媒體處理模塊(傳感器處理模塊MCU(R5)、PVA、DLA、Audio Processor、MCU R5配置實(shí)時(shí)相機(jī)輸入)、經(jīng)典Autosar處理模塊(用于Safety Island Lock-Step R52s)、安全服務(wù)Safety Service(ARM Cotex-A78AE CPU Complex、CPU Switch fabric Coherent、信息安全PSC)、神經(jīng)網(wǎng)絡(luò)處理模塊(CUDA & TensorRT)。
下圖顯示了 SoC 的高級(jí)架構(gòu),分為三個(gè)主要處理復(fù)合體:CPU、GPU 和硬件加速器。
?
2.1 CPU相關(guān)
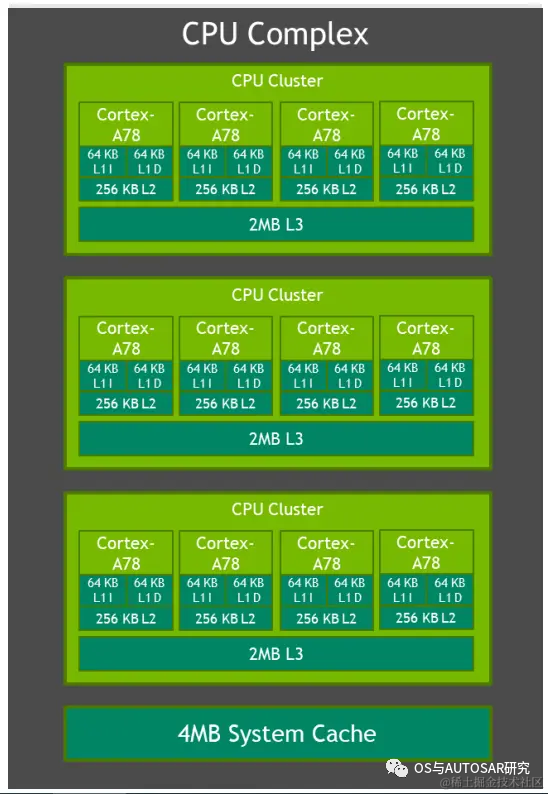
Orin系統(tǒng)架構(gòu)中,CPU從之前自研的Carmel架構(gòu)回到了到5納米工藝的ARM Cortex-A78上。Orin-x中CPU包括 12個(gè) Cortex-A78,可以提供通用的目標(biāo)高速計(jì)算兼容性。同時(shí),Arm Cortex R52 基于功能安全設(shè)計(jì)(FSI),可以提供獨(dú)立的片上計(jì)算資源,這樣就可以不用增加額外的 CPU(ASIL D)芯片用來提供功能安全等級(jí)。
CPU 族群所支持的特性包括 Debug 調(diào)試,電源管理,Arm CoreLink 中斷控制器,錯(cuò)誤檢測(cè)與報(bào)告。CPU需要對(duì)芯片進(jìn)行整體性能監(jiān)控,每個(gè)核中的性能監(jiān)控單元提供了六個(gè)計(jì)算單元,每個(gè)單元可以計(jì)算處理器中的任何事件。基于 PMUv3 架構(gòu)上,在每個(gè) Runtime 期間這些計(jì)算單元會(huì)收集不同的統(tǒng)計(jì)值并運(yùn)行在處理器和存儲(chǔ)系統(tǒng)上。
2.2 GPU

Orin采用了新一代的Ampere架構(gòu)GPU,由2個(gè)GPC(Graphics Processing Clusters,圖形處理簇)組成。每個(gè)GPC又包含4個(gè)TPC(Texture Processing Clusters, 紋理處理簇),每個(gè)TPC由2個(gè)SM(Streaming Multiprocesor,流處理器)組成,下圖為Orin的GPU架構(gòu)。每個(gè)SM有192KB的L1緩存和4MB的L2緩存,包含128個(gè)CUDA Core和4個(gè)Tensor Core。因此Orin總計(jì)2048個(gè)CUDA Core和64個(gè)Tensor Core,INT8稀疏算力為170 TOPS(Tensor Core提供),INT8稠密算力為54TOPS,F(xiàn)P32算力為5.3TFLOP(由Cuda Core提供)。
NVIDIA Ampere GPU 可以提供先進(jìn)的并行處理計(jì)算架構(gòu)。開發(fā)者可以使用 CUDA 語言進(jìn)行開發(fā)(后續(xù)將對(duì)CUDA架構(gòu)進(jìn)行詳細(xì)說明),并支持 NVIDIA 中各種不同的工具鏈(如開發(fā) Tensor Core 和 RT Core 的應(yīng)用程序接口)。一個(gè)深度學(xué)習(xí)接口優(yōu)化器和實(shí)時(shí)運(yùn)行系統(tǒng)可以傳遞低延遲和高效輸出。Ampere GPU 同時(shí)可以提供如下一些的特性來實(shí)現(xiàn)對(duì)高分辨率、高復(fù)雜度的圖像處理能力(如實(shí)時(shí)光流追蹤)。
稀疏化::細(xì)粒度結(jié)構(gòu)化稀疏性使吞吐量翻倍,減少對(duì)內(nèi)存消耗。浮點(diǎn)處理能力:每個(gè)時(shí)鐘周期內(nèi)可實(shí)現(xiàn) 2 倍 CUDA 浮點(diǎn)性能。
緩存::流處理器架構(gòu)可以增加 L1 高速緩存帶寬和共享內(nèi)存,減少緩存未命中延遲。提升異步計(jì)算能力,后 L2 緩存壓縮。
2.3 加速器
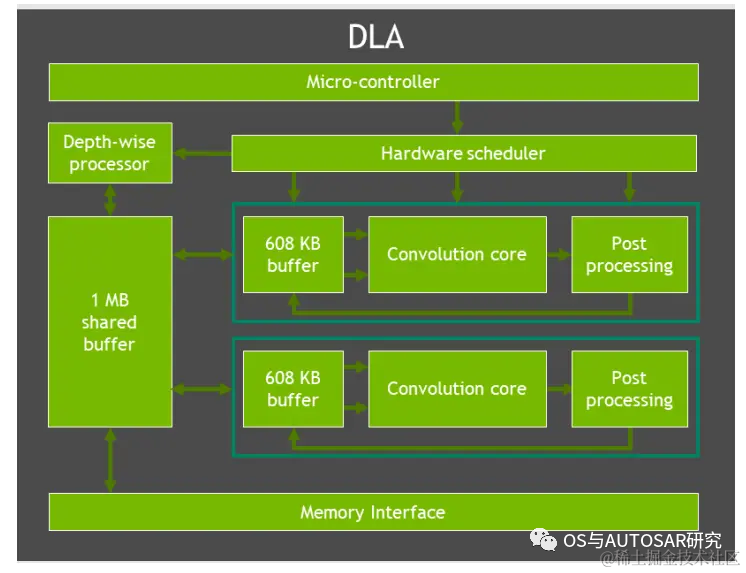
特定域硬件加速器(DSAs、DLA、PVA)是一組特殊目的硬件引擎,實(shí)現(xiàn)計(jì)算引擎多任務(wù)、高效、低功率等特性。計(jì)算機(jī)視覺和深度學(xué)習(xí)簇包括兩個(gè)主要的引擎:可編程視覺加速器 PVA 和深度學(xué)習(xí)加速器 DLA(而在最新的中級(jí)算力 Orin n 芯片則取消了 DLA 處理器)。
PVA 是第二代 NVIDIA 視覺DSP架構(gòu),它是一種特殊應(yīng)用指令矢量處理器,這種處理器是專門針對(duì)計(jì)算機(jī)視覺、ADAS、ADS、虛擬現(xiàn)實(shí)系統(tǒng)。PVA 有一些關(guān)鍵的要素可以很好的適配預(yù)測(cè)算法領(lǐng)域,且功耗和延遲性都很低。Orin-x需要通過內(nèi)部的R核(Cortex-R5)子系統(tǒng)可以用于 PVA 控制和任務(wù)監(jiān)控。一個(gè) PVA 簇可以完成如下任務(wù):雙向量處理單元(VPU)帶有向量核,指令緩存和 3 矢量數(shù)據(jù)存儲(chǔ)單元。每個(gè)單元有 7 個(gè)可見的插槽,包含可標(biāo)量和向量指令。此外,每個(gè) VPU 還含有 384 KBytes的3端口存儲(chǔ)容量。
DLA 是一個(gè)固定的函數(shù)引擎,可用于加速卷積神經(jīng)網(wǎng)絡(luò)中的推理操作。Orin-x 單獨(dú)設(shè)置了 DLA 用于實(shí)現(xiàn)第二代 NVIDIA 的 DLA架構(gòu)。DLA支持加速 CNN 層的卷積、去卷積、激活、池化、局部歸一化、全連接層。最終支持優(yōu)化結(jié)構(gòu)化稀疏、深度卷積、一個(gè)專用的硬件調(diào)度器,以最大限度地提高效率。
2.4 第二代視覺加速器PVA和VIC
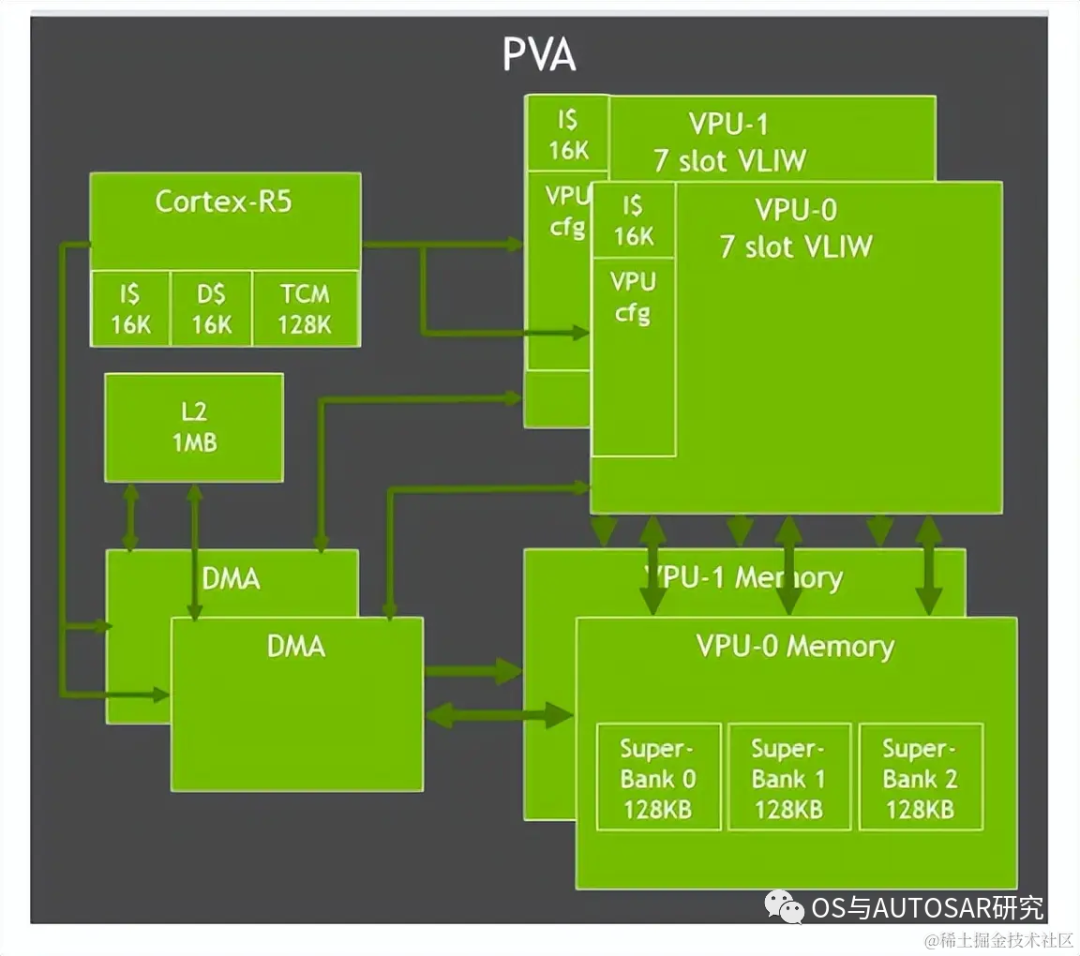
Orin中對(duì)PVA進(jìn)行了升級(jí),包括雙7路VLIW(超長(zhǎng)指令字)矢量處理單元、雙DMA和Cortex-R5,支持計(jì)算機(jī)視覺中過濾、變形、圖像金字塔、特征檢測(cè)和FFT等功能。
Orin還包含一個(gè)Gen 4.2視頻成像合成器 (Video Imaging Compositor,VIC) 2D 引擎,支持鏡頭畸變校正和增強(qiáng)、時(shí)間降噪、視頻清晰度增強(qiáng)、像素處理(色彩空間轉(zhuǎn)換、縮放、混合和合成)等圖像處理功能。
為了調(diào)用Orin SoC上的多個(gè)硬件組件(PVA、VIC、CPU、GPU、 ENC等),英偉達(dá)開發(fā)了視覺編程接口?( Vision Programming Interface,VPI)?。作為一個(gè)軟件庫,VPI附帶了多種圖像處理算法(如框過濾、卷積、圖像重縮放和重映射)和計(jì)算機(jī)視覺算法(如哈里斯角檢測(cè)、KLT 特征跟蹤器、光流、背景減法等)。
2.5 內(nèi)存和通訊
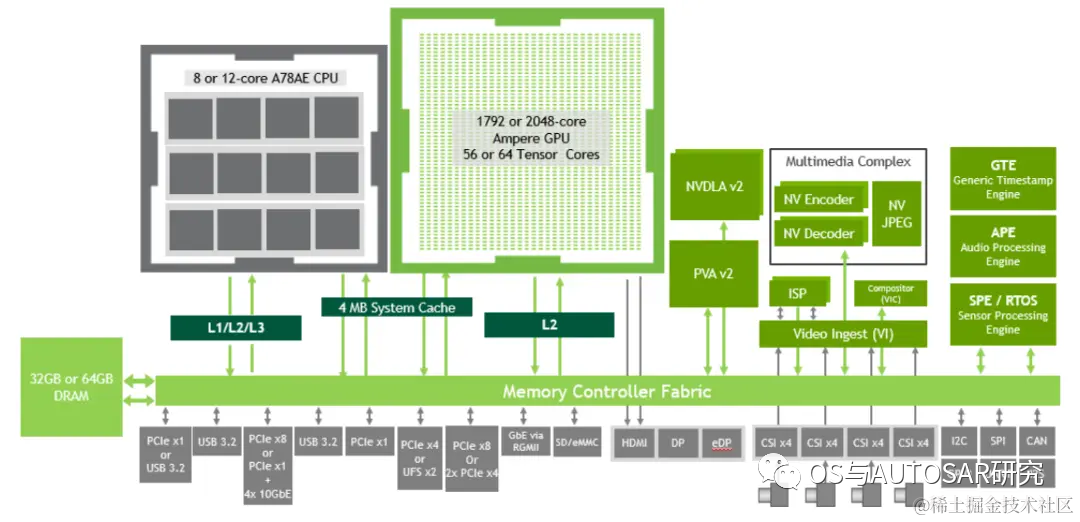
image.png
上圖顯示了Orin各組件中,通過內(nèi)存控制器結(jié)構(gòu)(Fabric)和DRAM如何通訊和數(shù)據(jù)交互。
Orin最高支持64GB的256位LPDDR5和64GB的eMMC。DRAM支持3200MHz的最大時(shí)鐘速度,每個(gè)引腳6400Gbps,支持204.8GB/s的內(nèi)存帶寬,是Xavier內(nèi)存帶寬 memory bandwidth 的1.4倍、存儲(chǔ)storage的2倍。
3. 基于Orin的自動(dòng)駕駛平臺(tái)架構(gòu)設(shè)計(jì)

常規(guī)的 SOC 系統(tǒng)架構(gòu)通常是包含有常規(guī)的 SOC+MCU 雙芯片甚至三芯片的方式進(jìn)行設(shè)計(jì)的。SOC 由于計(jì)算性能上的優(yōu)勢(shì),一般在前端感知、規(guī)劃中的計(jì)算應(yīng)用場(chǎng)景比 MCU 更好。
MCU 由于具備較高的功能安全等級(jí),可以作為控制執(zhí)行的校驗(yàn)輸出。業(yè)界對(duì)于英偉達(dá)芯片是否可以單純作為類似 TDA4 一樣的超異構(gòu)芯片而獨(dú)立承擔(dān)任務(wù), 一直都是褒貶不一的。原則上,從無論 Xavier 還是 Orin 系列,英偉達(dá)系列芯片設(shè)計(jì)都兼具豐富的 AI 和 CPU 算力能力。考慮 L2+級(jí)別以上的自動(dòng)駕駛系統(tǒng)開發(fā)而言,這種能力都是可以完全適配整個(gè)方案設(shè)計(jì)的。可能是對(duì)于安全要求較高的車控MCU不光是技術(shù)上先進(jìn)就可以替代,主要還是裝機(jī)量,需要用起來安全才可以。
3.1 安全考慮

可以看到基本R52核實(shí)現(xiàn)的安全島達(dá)到了ASIL-D,其他基本還是只滿足ISO 26262。所以需要一個(gè)SMCU作為輔助實(shí)現(xiàn)車控域。如英飛凌 Aurix TC系 列,瑞薩的 RH850 系列都可以充當(dāng) MCU 實(shí)現(xiàn)對(duì) Orin 的 SMCU 接入。這樣的 SMCU 實(shí)際是可以充當(dāng)整個(gè)系統(tǒng)開發(fā)的電源控制和嚴(yán)重失效故障規(guī)避的。在英偉達(dá)賣的開發(fā)平臺(tái)上就可以看到SMCU TC397的身影,如下圖:
通過可信安全加載技術(shù),ATF中BL1存入ROM,里面有BL2的安全校驗(yàn),然后形成鏈?zhǔn)桨踩虞d。包括 u-boot 在內(nèi)的所有低級(jí)引導(dǎo)步驟都可以通過簽名的二進(jìn)制文件來確保安全。它們的密鑰可以存儲(chǔ)在 CPU 中的一次性可編程保險(xiǎn)絲中。U-boot 本身可以配置為使用簽名的FIT 映像,從而提供一個(gè)安全的引導(dǎo)鏈,一直到 Linux 內(nèi)核。初始 ROM 引導(dǎo)加載程序和 TegraBoot 也都支持完全冗余的引導(dǎo)路徑。
3.2 FSI介紹

上圖顯示了如何在英偉達(dá)系列芯片中加載 FSI 及底層相關(guān)模塊驅(qū)動(dòng)引導(dǎo)程序。英偉達(dá)系列芯片在功能安全設(shè)計(jì)上,Orin 系列通過制定目標(biāo)實(shí)現(xiàn) ASIL D 系統(tǒng)能力設(shè)計(jì)和ASIL B/D 隨機(jī)錯(cuò)誤管理能力設(shè)計(jì)。包括基于 SOC 芯片硬件的 ASIL 分解需求到各個(gè)核,確保核間設(shè)計(jì)一致性可以滿足 ASIL D 需求,并應(yīng)用標(biāo)準(zhǔn)的 ASIL D 開發(fā)流程到整個(gè)功能安全設(shè)計(jì)中,從底之上分別對(duì)安全流程、Drive AGX、操作系統(tǒng) Drive OS、Drive Work、傳感器、冗余架構(gòu)設(shè)計(jì)、安全策略幾個(gè)方面分別進(jìn)行相應(yīng)的安全設(shè)計(jì)。
英偉達(dá)系列芯片的功能安全島(FSI)是一個(gè)包含 Cortex-R52 和 Cortex-R5F real 的處理器集群,并具有專用 I/O 控制器的時(shí)間處理器的核心。例如,Orin-X 中的 FSI 模塊具有自己的電壓軌、振蕩器和PLL、SRAM,以確保與 SOC 內(nèi)部的其他模塊相互作用最小,并實(shí)現(xiàn)如上模塊相互之間無干擾。
Cortex-R52 處理器,也稱為安全CPU,具有 DCLS(雙核鎖步)模式下的 4 個(gè)內(nèi)核(共 8 個(gè)物理內(nèi)核),可運(yùn)行經(jīng)典 AUTOSAR 操作系統(tǒng),實(shí)現(xiàn)錯(cuò)誤處理、系統(tǒng)故障處理和其他客戶工作負(fù)載,綜合性能約為 10KDMIPs。
Cortex-R5F 處理器,也稱為加密硬件安全模塊(CHSM),用于通過 CAN 接口運(yùn)行加密 和安全用例,如安全車載通信(SecOC)。
整個(gè)FSI機(jī)制上總體包含有如下的一些安全指令和控制接口信息:
1、安全和 CHSM CPU 每個(gè)核心的緊密耦合內(nèi)存、指令和數(shù)據(jù)緩存。
2、安全島上總共有 5MB 的片上專用 RAM,以確保代碼執(zhí)行和數(shù)據(jù)存儲(chǔ)可以保持在 FSI 內(nèi)。
3、島上有專門用于與外部組件通信的專用 I/O 接口。包含1個(gè) UART,4 個(gè) GPIO 口。
4、硬件安全機(jī)制,如 FSI 內(nèi)所有 IP 的 DLS、CRC、ECC、奇偶校驗(yàn)、超時(shí)等。專用熱、電壓和頻率監(jiān)測(cè)器。
5、邏輯隔離,確保與 SoC 的其他部分有足夠的錯(cuò)誤恢復(fù)時(shí)間FFI。
3.3 TESC
Tegra是英偉達(dá)芯片中特有的信息安全芯片內(nèi)核,Tegra Security Controller(TESC)是一種信息安全子系統(tǒng),他有自己的可信任根ROM、IMEM、DMEM,Crypto 加速器(AES、SHA、RNG、PKA),關(guān)鍵鏈路和關(guān)鍵存儲(chǔ)。TSEC 提供了一個(gè)片上TEE(可信任執(zhí)行環(huán)境)可以運(yùn)行NVIDIA-標(biāo)記的為處理代碼。TSEC是一種典型的安全視頻回放解決方案,下載信息安全運(yùn)行所需的HDCP1.x 和2.x連接授權(quán)和完整的線端連接檢測(cè)。
1)線端HDMI 1.4上的HDCP 1.4和 線端HDMI 2.3上的HDCP 2.0 2.1;?HDCP連接管理沒有暴露受保護(hù)的內(nèi)容,也無需運(yùn)行在CPU上的軟件鑰匙。用于 HDCP 鏈路管理的兩個(gè)軟件可編程獨(dú)立指令隊(duì)列(最多可容納 16 條指令);整個(gè)芯片能夠獨(dú)立于播放器在 HDCP 狀態(tài)檢查失敗時(shí)禁用 HDMI 輸出。
2)平臺(tái)安全控制器;?他是一個(gè)高安全子系統(tǒng),他可以保護(hù)和管理SOC中的資產(chǎn)(鑰匙、保險(xiǎn)絲、功能、特性),并提供可信任的服務(wù),提升自由的抵御對(duì) SOC 的攻擊,并可以提高對(duì)子系統(tǒng)本身的軟件和硬件攻擊的保護(hù)水平。
3)鑰匙管理和保護(hù);?PSC 將是唯一可以訪問芯片中最關(guān)鍵秘鑰的機(jī)制。該子系統(tǒng)代表了 Orin-x 中最高級(jí)別的保護(hù),并且該子系統(tǒng)本身對(duì)各種軟件和硬件攻擊具有高度的彈性。
4)授信服務(wù);?例如,在 SOC 安全啟動(dòng)期間,主要的 PSC 服務(wù)可以完成有效的安全身份驗(yàn)證、提供額外的密鑰/ID/數(shù)據(jù)、密鑰訪問和管理、隨機(jī)數(shù)生成和授信的時(shí)間報(bào)告。
5)信息安全監(jiān)控。?PSC 將負(fù)責(zé)定期的安全管理任務(wù),包括持續(xù)評(píng)估 SOC 的安全狀態(tài),主動(dòng)監(jiān)控已知或潛在的攻擊模式(例如,電壓故障或熱攻擊),降低硬件攻擊風(fēng)險(xiǎn),并在檢測(cè)到有攻擊的情況下采取有效的措施。PSC 將能夠接受各種軟件更新來作為解決方法,以提高現(xiàn)場(chǎng)系統(tǒng)的穩(wěn)健性。
3.4 安全引擎(SE)
安全引擎SE中有兩種情況針對(duì)軟件使用是有用的。其一,TZ-SE只能被可信任區(qū)域軟件所訪問。其二,NS/TZ-SE可配置用來被可信任的軟件區(qū)域或非安全軟件所訪問。安全引擎SE可以為各種加密算法提供硬件加速以及硬件支撐密鑰保護(hù)。SE提供的加密算法可以被軟件用來建立加密協(xié)議和安全特性。所有加密運(yùn)算都是基于國(guó)際標(biāo)準(zhǔn)技術(shù)協(xié)會(huì)NIST批準(zhǔn)的加密算法。
英偉達(dá)的安全引擎SE可支持包含如下的所有信息安全保障能力:
NIST合規(guī)的對(duì)稱以及非對(duì)稱加密和哈希算法、側(cè)信道對(duì)策(AES/RSA/ECC)、獨(dú)立并行信道、硬件鑰匙訪問控制(KAC)(基于規(guī)則,增強(qiáng)硬件訪問控制的對(duì)稱鑰匙)、16xAES,4xRSA/ECC鑰匙孔、硬件密鑰隔離(僅針對(duì)AES鑰匙孔)、讀保護(hù)(僅針對(duì)AES鑰匙孔)、硬件鑰匙孔函數(shù)、密鑰包裝/解包功能(AES->AES鑰匙孔)、鑰匙從鑰匙孔分離(KDF->AES鑰匙孔)、隨機(jī)鑰匙生成(RNG->AES鑰匙孔)。
4. GPU編程CUDA
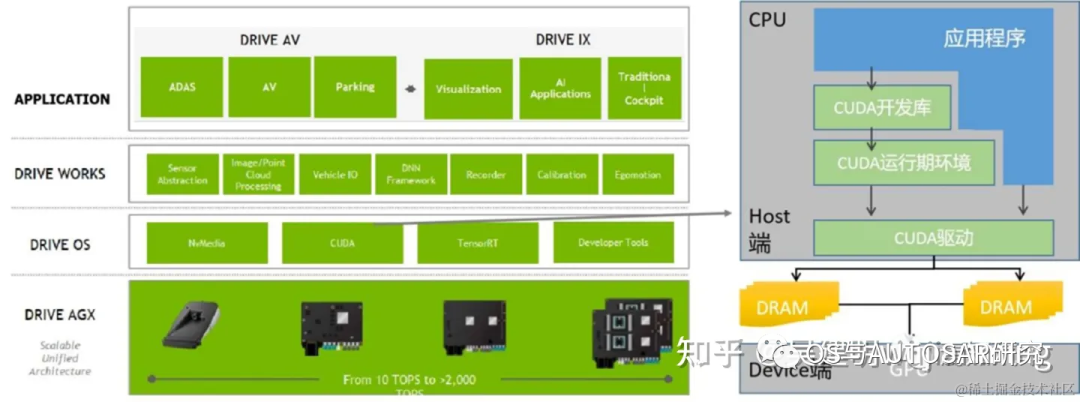
image.png
上圖表示了 CUDA 架構(gòu)示意圖,表示了CPU,GPU,應(yīng)用程序,CUDA 開發(fā)庫,運(yùn)行環(huán)境,驅(qū)動(dòng)之間的關(guān)系
4.1 GPU軟件架構(gòu)
自動(dòng)駕駛領(lǐng)域使用的 AI 算法多為并行結(jié)構(gòu)。AI 領(lǐng)域中用于圖像識(shí)別的深度學(xué)習(xí)、用于決策和推理的機(jī)器學(xué)習(xí)以及超級(jí)計(jì)算都需要大規(guī)模的并行計(jì)算,更適合采用 GPU 架構(gòu)。由于神經(jīng)網(wǎng)絡(luò)的分層級(jí)數(shù)(通常隱藏層的數(shù)量越多,神經(jīng)網(wǎng)絡(luò)模擬的結(jié)果越精確)會(huì)很大程度的影響其在預(yù)測(cè)結(jié)果。擅長(zhǎng)并行處理的 GPU 可以很好的對(duì)神經(jīng)網(wǎng)絡(luò)算法進(jìn)行處理和優(yōu)化。因?yàn)椋窠?jīng)網(wǎng)絡(luò)中的每個(gè)計(jì)算都是獨(dú)立于其他計(jì)算的,這意味著任何計(jì)算都不依賴于任何其他計(jì)算的結(jié)果,所有這些獨(dú)立的計(jì)算都可以在 GPU 上并行進(jìn)行。通常 GPU 上進(jìn)行的單個(gè)卷積計(jì)算要比 CPU 慢,但是對(duì)于整個(gè)任務(wù)來說,CPU 幾乎是串行處理方式,需要要逐個(gè)依次完成,因此,其速度要大大慢于 GPU。因此,卷積運(yùn)算可以通過使用并行編程方法和GPU來加速。
英偉達(dá)通過 CPU+GPU+DPU 形成產(chǎn)品矩陣,全面發(fā)力數(shù)據(jù)中心市場(chǎng)。利用 GPU 在AI 領(lǐng)域的先天優(yōu)勢(shì),英偉達(dá)借此切入數(shù)據(jù)中心市場(chǎng)。針對(duì)芯片內(nèi)部帶寬以及系統(tǒng)級(jí)互聯(lián)等諸多問題,英偉達(dá)推出了 Bluefield DPU 和 Grace CPU,提升了整體硬件性能。
對(duì)于英偉達(dá)的GPU而言,一個(gè) GPC 中有一個(gè)光柵引擎(ROP)和 4 個(gè)紋理處理集群(TPC),每個(gè)引擎可以訪問所有的存儲(chǔ)。
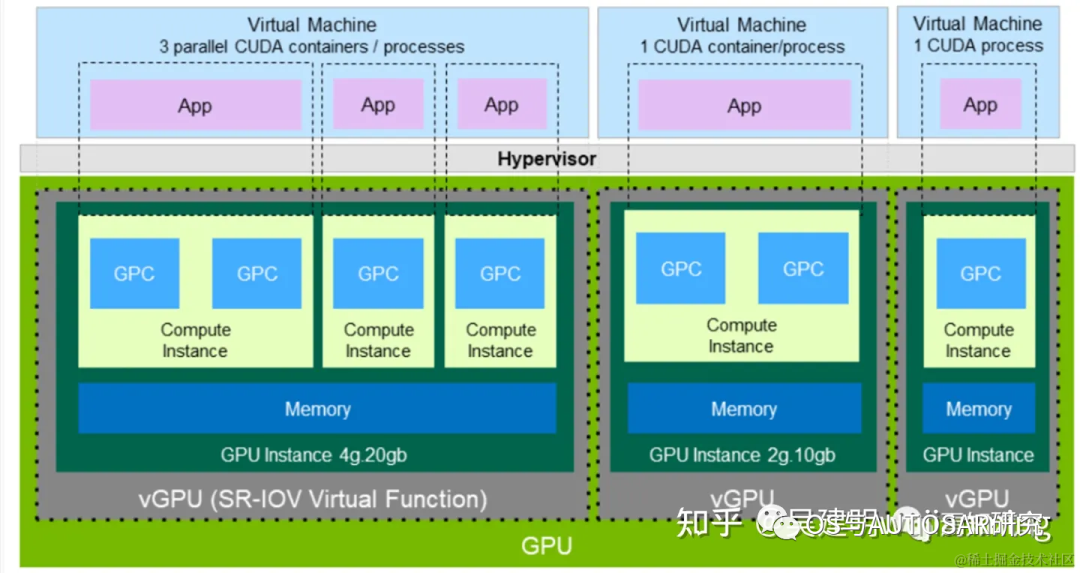
4.2 CUDA編程
CUDA(Compute Unified Device Architecture,統(tǒng)一計(jì)算架構(gòu)) 作為連接 AI 的中心節(jié)點(diǎn),CUDA+GPU 系統(tǒng)極大推動(dòng)了 AI 領(lǐng)域的發(fā)展。搭載英偉達(dá) GPU 硬件的工作站(Workstation)、服務(wù)器(Server)和云(Cloud)通過 CUDA軟件系統(tǒng)以及開發(fā)的 CUDA-XAI 庫,為自動(dòng)駕駛系統(tǒng) AI 計(jì)算所需要的機(jī)器學(xué)習(xí)、深度學(xué)習(xí)的訓(xùn)練(Train)和推理(Inference)提供了對(duì)應(yīng)的軟件工具鏈,來服務(wù)眾多的框架、云服務(wù)等等,是整個(gè)英偉達(dá)系列芯片軟件開發(fā)中必不可少的一環(huán)。
CUDA 是一個(gè)基于英偉達(dá) GPU 平臺(tái)上面定制的特殊計(jì)算體系/算法,一般只能在英偉達(dá)的 GPU 系統(tǒng)上使用。這里從開發(fā)者角度我們講講在英偉達(dá) Orin 系列芯片中如何在 CUDA架構(gòu)上進(jìn)行不同軟件級(jí)別開發(fā)。
從CUDA 體系結(jié)構(gòu)的組成來說,它包含了三個(gè)部分:開發(fā)庫、運(yùn)行期環(huán)境和驅(qū)動(dòng)。
“Developer Lib 開發(fā)庫”?是基于 CUDA 技術(shù)所提供的應(yīng)用開發(fā)庫。例如高度優(yōu)化的通用數(shù)學(xué)庫,即cuBLAS、cuSolver 和 cuFFT。核心庫,例如 Thrust 和 libcu++;通信庫, 例如 NCCL 和 NVSHMEM,以及其他可以在其上構(gòu)建應(yīng)用程序的包和框架。
“Runtime 運(yùn)行期環(huán)境”?提供了應(yīng)用開發(fā)接口和運(yùn)行期組件,包括基本數(shù)據(jù)類型的定義和各類計(jì)算、類型轉(zhuǎn)換、內(nèi)存管理、設(shè)備訪問和執(zhí)行調(diào)度等函數(shù)。
“Driver 驅(qū)動(dòng)部分”?是 CUDA使能GPU的設(shè)備抽象層,提供硬件設(shè)備的抽象訪問接口。CUDA 提供運(yùn)行期環(huán)境也是通過這一層來實(shí)現(xiàn)各種功能的。
在 CUDA 架構(gòu)下,一個(gè)程序分為兩個(gè)部份:host端和 device端。Host端是指在 CPU 上執(zhí)行的部份,而 device端則是在顯示芯片(GPU)上執(zhí)行的部份。Device 端的程序又稱為 "kernel"。通常 host 端程序會(huì)將數(shù)據(jù)準(zhǔn)備好后,復(fù)制到顯卡的內(nèi)存中,再由顯示芯片執(zhí)行 device 端程序,完成后再由 host 端程序?qū)⒔Y(jié)果從顯卡的內(nèi)存中取回。這里需要注意的是,由于 CPU 存取顯存時(shí)只能透過 PCI Express 接口,因此速度較慢 (PCI Express x16 的理論帶寬是雙向各 4GB/s),因此不能經(jīng)常進(jìn)行,以免降低效率。
基于以上分析可知,針對(duì)大量并行化問題,采用 CUDA 來進(jìn)行問題處理,可以有效隱藏內(nèi)存的延遲性 latency,且可以有效利用顯示芯片上的大量執(zhí)行單元,同時(shí)處理上千個(gè)線程 thread 。因此,如果不能處理大量并行化的問題,使用 CUDA 就沒辦法達(dá)到最好的效率了。
對(duì)于這一應(yīng)用瓶頸來說,英偉達(dá)也在數(shù)據(jù)存取上做出了較大的努力提升。一方面,優(yōu)化的CUDA 改進(jìn)了 DRAM 的讀寫靈活性,使得GPU與CPU的機(jī)制相吻合。另一方面,CUDA提供了片上(on-chip)共享內(nèi)存,使得線程之間可以共享數(shù)據(jù)。應(yīng)用程序可以利用共享內(nèi)存來減少 DRAM 的數(shù)據(jù)傳送,更少的依賴 DRAM 的內(nèi)存帶寬。
此外,CUDA 還可以在程序開始時(shí)將數(shù)據(jù)復(fù)制進(jìn) GPU 顯存,然后在 GPU 內(nèi)進(jìn)行計(jì)算,直到獲得需要的數(shù)據(jù),再將其復(fù)制到系統(tǒng)內(nèi)存中。為了讓研發(fā)人員方便使用 GPU 的算力,英偉達(dá)不斷優(yōu)化 CUDA 的開發(fā)庫及驅(qū)動(dòng)系統(tǒng)。操作系統(tǒng)的多任務(wù)機(jī)制可以同時(shí)管理 CUDA 訪問 GPU 和圖形程序的運(yùn)行庫,其計(jì)算特性支持利用 CUDA 直觀地編寫 GPU 核心程序。
后記:
對(duì)于軟件開發(fā)人員學(xué)習(xí)SoC架構(gòu)也是非常有用的,在制定軟件方案的時(shí)候需要參考硬件上有那些通路,性能是否可以滿足,有那些硬件可以利用來支撐功能實(shí)現(xiàn)。在驅(qū)動(dòng)開發(fā)的時(shí)候,需要羅列那些硬件模塊的需求需要開發(fā),驅(qū)動(dòng)對(duì)上層提供的服務(wù)要達(dá)到什么程度形成封裝API接口。
本篇文章為了更加全面準(zhǔn)確的介紹Orin,除了參考官網(wǎng)的資料外,參考了大量他人的文章,見參考資料章節(jié),對(duì)于芯片更細(xì)節(jié)的東西需要注冊(cè)英偉達(dá)官網(wǎng)賬號(hào),甚至購買后有芯片的data sheet和FAE支持,這里不涉及。芯片研發(fā)和使用需要大量人力物力,這里雖只是冰山一角都這么多,也寫的比較流水賬,大家多多擔(dān)待。
審核編輯:黃飛
?

































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論