 電子發燒友App
電子發燒友App


2023年12月23日,NIO DAY上,蔚來推出了新旗艦車型ET9,同時也介紹了蔚來自主研發的自動駕駛芯片神璣NX9031,并宣布2025年ET9將量產,搭載這款NX9031。
目前對于這款芯片,蔚來僅公布了如上圖中的信息,不過這已經足夠做深度分析了。關鍵點包括5納米工藝,超過500億晶體管,使用LPDDR5X存儲,32核心CPU配置,且是大小核配置,高動態ISP,位寬26比特,像素處理能力6.5GPixel/s,支持ASIL-D級安全。
現在芯片行業是IP時代,只要舍得花錢,自動駕駛SoC需要的IP都可以買得到,蔚來能做出來5納米芯片并不令人驚訝。能做5納米芯片代工的只有臺積電和三星,蔚來找三星代工的可能性更高,一來臺積電代工價格至少是三星的兩倍,二來三星的5納米客戶稀缺,車規級更是稀缺,臺積電有大量高通5納米車規芯片訂單,產能可能還比較緊張,三星僅有安霸一家,產能肯定非常充裕。
智能駕駛芯片排名并不簡單只看AI算力,存儲帶寬和AI算力數值一樣重要,CPU算力也很重要,智能駕駛系統軟件異常復雜,會消耗大量的CPU運算資源,軟件系統包含眾多中間件諸如SOME/IP、自適應AUTOSAR、DDS、ROS等,基礎軟件包括訂制的Linux BSP、OS抽象層、虛擬機,還有與底層硬件關聯的內存管理、各種驅動、各種通訊協議等等。除此之外,應用層中的路徑規劃、高精度地圖、行為決策等也大量消耗CPU資源,同時CPU也管理AI運算時的任務調度、存儲搬運指令等,整體的任務調度,決策自然也是CPU的任務。CPU是絕對的核心,AI是CPU的附屬功能,只是在做圖像特征提取、分類、BEV變換、矢量地圖映射或空間分布占有時才用到AI。
排名的權重依次是AI算力、存儲帶寬、CPU算力、GPU算力、制造工藝。存儲帶寬和AI算力同等權重,GPU也是錦上添花,大部分車載AI處理部分只能對應INT8位數據,而GPU可以對應FP32數據,有些時候可能有很大作用。實際AI算力數字完全是個黑箱,有些廠家寫的是等效于多少算力,這里面操作空間極大,參考意義不大。最能準確衡量算力的是MAC陣列數量,谷歌的TPU V1是65000個FP16 MAC,運行頻率0.7GHz,那么算力就是65000*0.7G*2=91TOPS。特斯拉第一代FSD兩個NPU,每個NPU是9216個INT8 MAC,運行頻率是2GHz,算力就是2*2*2G*9216=73.7TOPS。制造工藝方面,自然還是越先進,功耗越低。
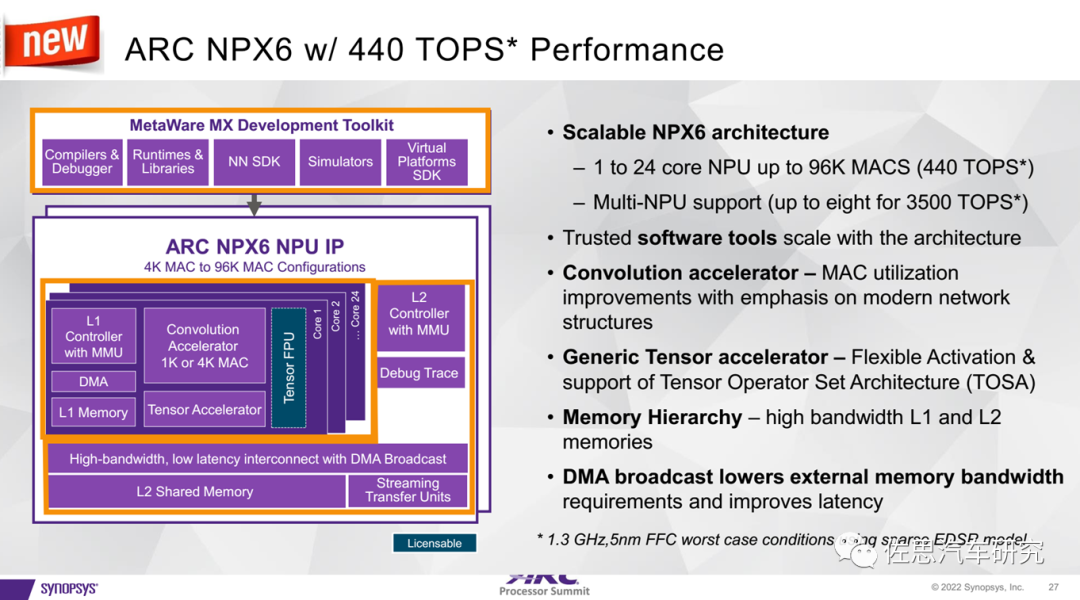
圖片來源:Synopsys
上圖是SYNOPSYS推出的一款IP,最高支持8個NPU,達到3500TOPS的算力,單個NPU有高達96000個MAC,運行頻率1.3GHz,2*1.3G*96000=249.6TOPS的算力,這個顯然是稠密值,如果是稀疏EDSR模式,那么算力會增加大約76%,即440TOPS。
蔚來NX9031未公布算力,有人認為NX9031是代替4片英偉達Orin的,算力自然是4*254=1008TOPS。這就大錯特錯了,4片英偉達Orin如果是用以太網交換機連接,那么算力頂多增加20%,4片也就是大約300TOPS。想要算力增加4倍付出的成本遠超4片Orin。
通過英偉達DGX級聯8個GPU的例子來看看如何級聯芯片。
英偉達DGX系統的示意圖
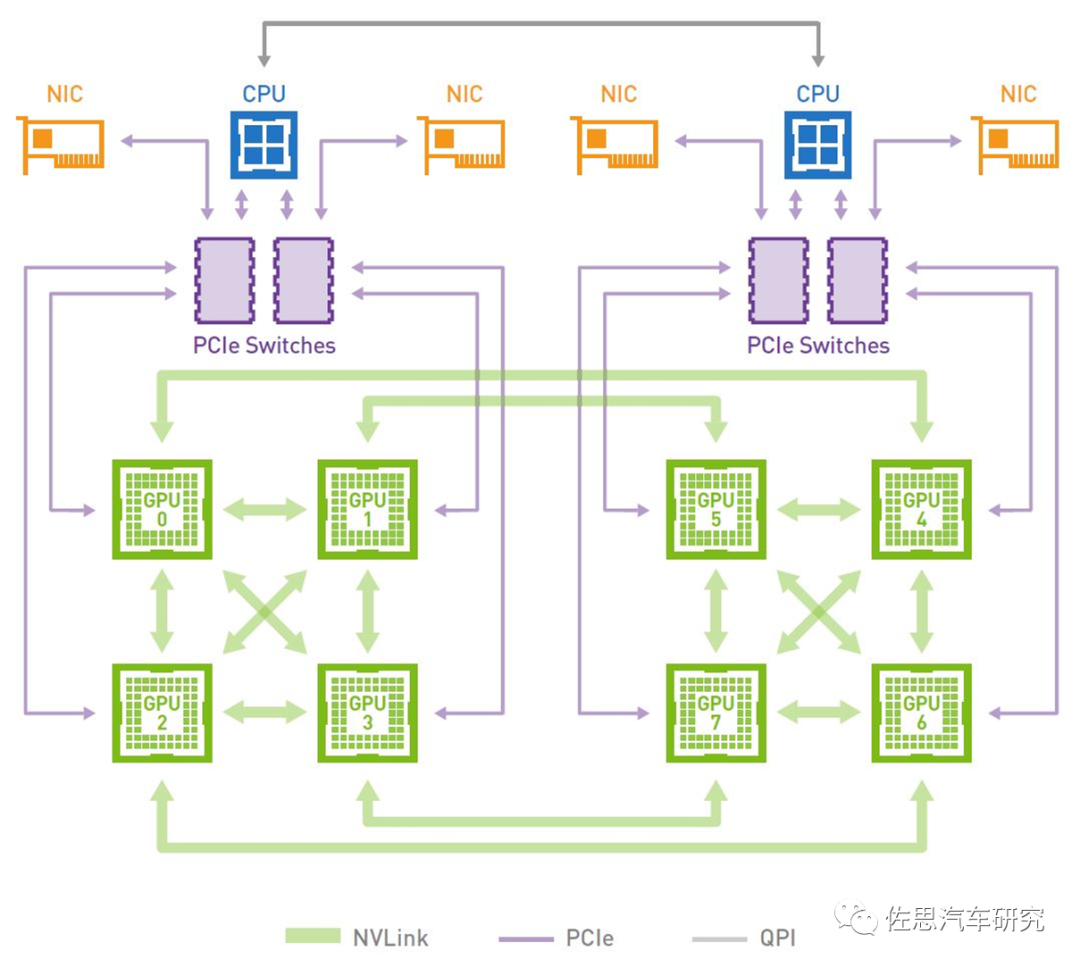
圖片來源:NVIDIA
英偉達DGX系統有8個GPU也就是8張顯卡級聯,首先GPU是無法單獨工作的,必須配合CPU才能工作。GPU之間是通過NVLink連接的,CPU與GPU之間是通過PCIe交換機連接的。

圖片來源:NVIDIA
目前第四代NVLink的帶寬是900GB/s,那么以太網交換機帶寬是多少?以目前量產最頂級以太網交換機88Q5192來說,下行端口帶寬一般是1Gb/s,也就是0.125GB/s,與NVLink有天壤之別,即便不看上行或下行,目前主流的以太網交換最高也就1.25GB/s,通常這種帶寬的端口不超過兩個。
想要媲美NVLink,讓4個Orin就是4倍算力,可以考慮博通的Qumran3D的路由交換芯片,它的上行帶寬高達3200GB/s,也就是25.6Tb/s,價格驚人,超過1萬美元。不過Orin芯片最高也只支持1.25GB/s的以太網,Qumran3D是無法使用的。
再來看存儲,蔚來把LPDDR5X特別點出來,但沒說芯片存儲位寬,也就無法得知存儲帶寬了。
歷代LPDDR的參數
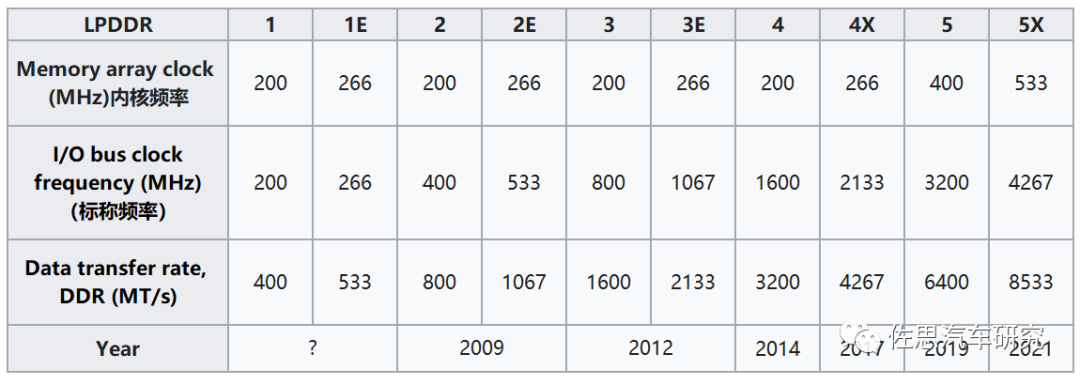
圖片來源:公開資料整理
目前業內大多數是采用LPDDR5或LPDDR4,LPDDR5X畢竟是2021年才有標準的(實際2020年就有產品了),最高帶寬8533MT/s,不過比LPDDR5X高的GDDR6已經有百度和特斯拉在用了,還有更高的HBM。
蔚來未給出位寬,估計位寬是128-256比特,存儲帶寬也就是136-273GB/s。那廠家為何不把位寬做高一點,很簡單,會增加成本,芯片的成本就是die size,位寬越高,對應的內存控制器die size就增加越多,成本就增加越多。
蘋果M3系列芯片
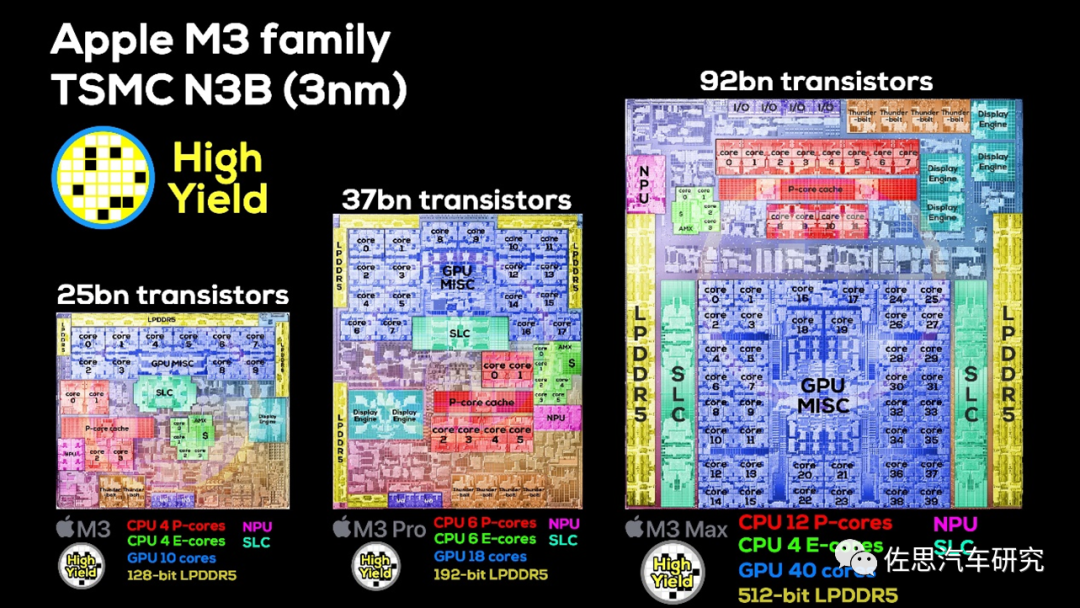
圖片來源:Twitter
蘋果M3的位寬僅128比特,M3 Pro是192比特,M3 Max是512比特,從上圖不難看出M3 Max的內存控制器占的die size遠比M3和M3 Pro大十幾倍乃至幾十倍以上,也就是存儲位寬的增加會導致成本暴增,也是大多數廠家寧肯多放一些cache,也不愿意增加存儲位寬的原因。
2023年初LPDDR進一步升級,出現了LPDDR5T,聯發科的天璣9300第一個使用。
接下來看ISP(Image Signal Processor),早期有不少獨立的外置ISP芯片,近期大多集成在SoC內,因為隨著AI應用的大量出現和像素的飛速增加,外置ISP芯片延遲會比較明顯。典型的ISP通常會對攝像頭輸出的RAW數據先做黑電平矯正(BLC)、壞點矯正(DPC)、數字增益(Dgain)、鏡頭陰影矯正(LSC)等必要處理。然后通過去馬賽克(DM)插值恢復出全彩色圖像,在RGB域完成色彩矩陣矯正(CMC)、伽馬矯正(GMA)。最后轉到YUV域,進行銳度(SHP)、對比度(CON)、顏色飽和度(SAT)等調整后輸出。在整個ISP pipeline中間會插入若干降噪(NR)模塊。
ISP流程
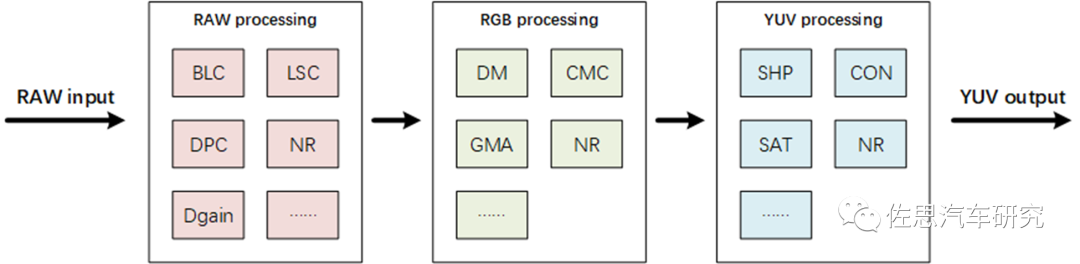
圖片來源:網絡
Orin內部也是有ISP的,處理像素的速度是1.85Gpixel/s,蔚來的NX9031達到了6.5Gpixel/s,是Orin的3倍還多。不過這不算什么,手機領域的ISP更高。
聯發科天璣9000的ISP
上圖是聯發科天璣9000的ISP,高達9Gpixel/s,高通的一般會低一點。pixel/s越高意味著對應的攝像頭像素可以越高,基本上1.3Gpixel/s就可對應1億像素攝像頭,但圖像會有壓縮,完全不壓縮的話,3.2Gpixel/s可以對應1億像素。蔚來可以對應2億像素。
至于ISP的位寬,很少人提及,天璣9000的位寬是18比特,蔚來是26比特,高出不少,不過大部分圖像傳感器的位寬也只有10或12比特。位寬主要是ADC的動態范圍決定,以索尼IMX490為例,當ADC是10比特時,幀率40fps,12比特時,幀率30fps。ISP的位寬越高意味著幀率可以越高。
最后來看CPU,CPU被蔚來重點標明,高達615kDMIPS的算力的確是無敵的。Orin的CPU算力是228kDMIPS,Orin是用了12個ARM Cortex-A78AE核心,ARM目前為汽車行業設計的大核心只有Cortex-A78AE,蔚來極有可能也是用Cortex-A78AE,Orin的L2緩存是3MB,L3緩存是6MB,運行頻率是2.0-2.2GHz之間,也就是每個核心貢獻19kDMIPS的算力。蔚來是5納米工藝,運行頻率和緩存都可以更高一點,估計最高可以達到每核心24kDMIPS的算力,估計大核心是20個,小核心還是常見的Cortex-A55,有12個。合起來算力就是615kDMIPS。
至于ASIL-D級功能安全,添加一個MCU核心島即可,一般是2到4個Cortex-R52做鎖步,高通SA8255、SA8755就是這種設計。 ? 蔚來第一次做芯片就達到全球第三的水平,難能可貴。
審核編輯:黃飛
?









 工商網監
工商網監
評論