 電子發燒友App
電子發燒友App


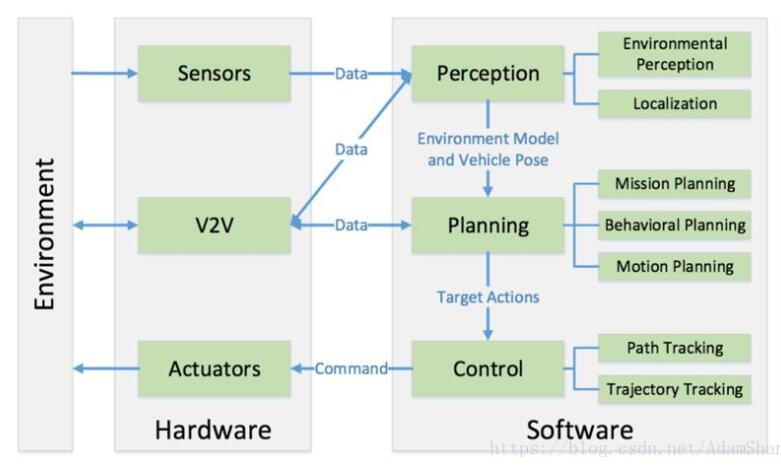
深度學習在無人駕駛領域主要用于圖像處理,也就是攝像頭上面。當然也可以用于雷達的數據處理,但是基于圖像極大豐富的信息以及難以手工建模的特性,深度學習能最大限度的發揮其優勢。
現在介紹一下全球攝像頭領域的巨擘,以色列的mobileye公司是怎么在他們的產品中運用深度學習的。 深度學習可以用于感知,識別周圍環境,各種對車輛有用的信息;也可以用于決策,比如AlphaGo的走子網絡(Policy Network),就是直接用DNN訓練, 如何基于當前狀態作出決策。
環境識別方面,mobileye把他們識別方面的工作主要分為三部分,物體識別,可行駛區域檢測,行駛路徑識別。
物體識別
一般的物體識別是這樣子的:
有一個長方形框框能識別出來車在哪里,很好,很不錯,但是Mobileye出來的是這樣子的:
以及這樣子的:
很明顯的區別就是Mobileye可以實現非常準確的車的正面以及側面的檢測,以及完全正確的區分左邊側面以及右邊側面(黃色和藍色)。

這兩種檢測結果的信息量是完全不同的,左邊這個檢測結果告訴我們什么位置大概有一輛車,但是他的具體位置,車的朝向信息完全沒有。但是從右邊的檢測結果,就可以相對精確的估算出來車的位置,行駛方向等重要信息,跟我們人看到后可以推測的信息差不多了。
這樣出眾的結果,對于較近距離的車,用其他基于幾何的方法,多跟蹤幾幀,可能可以做到接近的效果,但是留意遠處很小的車,結果也完全正確,這就只可能是深度學習的威力了。可惜 Mobileye 創始人兼 CTO 總愛四處顯擺他們技術怎么怎么牛,之前也常發論文共享一些技術,但是在車輛識別怎么建模神經網絡可以輸出這么精確帶 orientation 的 bounding box,他只是微微一笑,說這里面有很多 tricks ……
如果誰知道學術界有類似的工作,請私信告訴我, 拜謝
可行駛區域(free space)檢測
深度學習以前的可行駛區域檢測,有兩種方法,一是基于雙目攝像頭立體視覺或者 Structure from motion, 二是基于局部特征,馬爾科夫場之類的圖像分割。結果是這樣的:

綠色部分是可行駛區域檢測,看著還不錯對不對? 但是注意左邊的綠色部分涵蓋了馬路 “ 倒鴨子 ”(雷鋒網按:路邊石)以及人行道部分,因為 “ 倒鴨子 ” 也就比路面高十厘米左右, 靠立體視覺是很難跟馬路區分開來的。而傳統的圖像分割也很困難,因為局部特征上,“ 倒鴨子 ” 上和路面的顏色極其接近。區分二者需要對環境整個 context 的綜合理解。
自從有了深度學習可以做 scene understanding 之后,這個問題終于被攻克了:
綠色部分還是可行駛區域,馬路右邊的路肩跟路面的高度相差無幾,顏色 texture 也是一模一樣,用立體視覺的方法不可能區分開來。
而且不僅僅可行駛區域的邊界準確檢測出來了,連為什么是邊界的原因也可以檢測出來:

紅色表示是物體跟道路的邊界,鼠標位置那里表示的是 Guard rail ( 護欄 ) ,而上一張圖應該是 Flat。這樣在正常情況下知道哪些區域是可以行駛的,而在緊急情況下,也可以知道哪里是可以沖過去的。
當然,相較于第一部分,這一部分的原理是比較清楚的,就是基于深度學習的 scene understanding。學術界也有蠻不錯的結果了,比如下圖 ( Cambridge 的工作 ) ,路面跟倒鴨子就分的很好 ( 藍色跟紫色 ) :

行駛路徑檢測
這一部分工作要解決的問題主要是在沒有車輛線或者車輛線狀況很差的情況下,車怎么開的問題。如果所有的路況都如下:
那當然很完美,但是由于路況或者天氣,有些時候車輛線是很難檢測到的。
深度學習為此提供了一個解決辦法。我們可以用人在沒有車道線的路況下開車的數據來訓練神經網絡,訓練好之后,神經網絡在沒有車道線的時候也能大概判斷未來車可以怎么開。這一部分原理也是比較清楚的,找一個人開車,把整個開車的過程攝像頭的錄像保存下來,把人開車的策略車輛的行駛路徑也保存下來。用每一幀圖片作為輸入,車輛未來一段時間(很短的時間)的路徑作為輸出訓練神經網絡。之前很火的 Comma 公司,黑蘋果手機那個創立的,做的無人駕駛就是這種思路,因為其可靠性以及原創性還被 LeCun 鄙視了。
結果如下,可以看到神經網絡提供的行駛路徑基本上符合人類的判斷:
更極端的情況:
綠色是預測的行駛路徑。沒有深度學習,這種場景也是完全不可能的。當然,我在最近的另外一個答案里面提到了,不能完全依靠神經網絡來做路徑規劃,Mobileye 也是綜合傳統的車道線檢測,上面提到的場景分割檢測到的護欄等,這一部分的神經網絡輸出等等,做信息融合最后得到一個穩定的完美的行駛路徑。


































 工商網監
工商網監
評論