 電子發燒友App
電子發燒友App


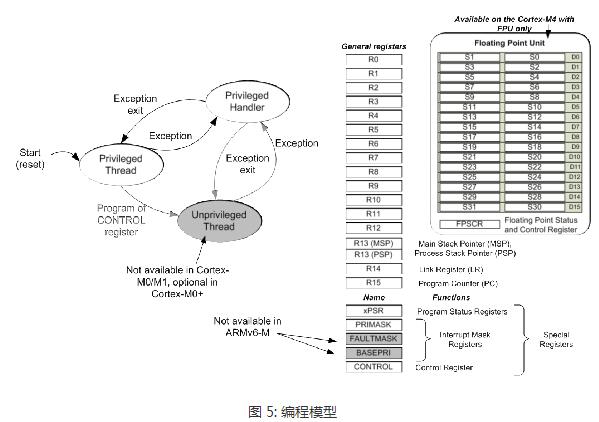
AlexNet架構的獨特特征
整流線性單位(ReLU)
為了訓練神經網絡內的神經元,利用Tanh或S形非線性已成為標準做法,這是goto激活函數,可用來對CNN內的內部神經元激活進行建模。
AlexNet繼續使用整流線性單位,簡稱ReLU。 ReLU由Vinod Nair和Geoffrey E.Hinton在2010年推出。
ReLu可以描述為對先前卷積層的輸出執行的傳遞函數運算。 ReLu的利用可確保神經元內的值保持為正值,但對于負值,則將其限制為零。
使用ReLu的好處是,與其他標準非線性技術相比,由于梯度下降優化以更快的速度發生,因此可以加快訓練過程。
ReLu層的另一個好處是它在網絡內引入了非線性。 它還消除了連續卷積的關聯性。
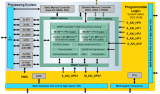
在介紹AlexNet神經網絡架構的原始研究論文中,模型的訓練是利用兩個具有3GB內存的GTX 580 GPU進行的。
GPU并行化和分布式訓練是當今非常常用的技術。
根據研究論文提供的信息,該模型在兩個GPU上進行了訓練,其中一半神經元位于一個GPU上,另一半則在另一個GPU的內存中。 GPU彼此通信,而無需通過主機。 GPU之間的通信基于層進行限制; 因此,只有特定的層可以相互通信。
例如,AlexNet網絡第四層的輸入是從當前GPU上第三層特征圖的一半中獲得的,而另一半的其余部分則是從第二GPU中獲得的。 本文后面將對此進行更好地說明。
本地響應規范化
規范化采用一組數據點,并將它們放置在可比較的基礎或規模上(這是過于簡單的描述)。
CNN中的批次歸一化(BN)是通過將一批輸入數據轉換為平均值為零且標準偏差為1來標準化和歸一化輸入的技術。
許多人熟悉批處理規范化,但是AlexNet體系結構在網絡中使用了另一種規范化方法:本地響應規范化(LRN)。
undefined
在現代CNN架構中,LRN并未得到廣泛利用,因為還有其他更有效的標準化方法。 雖然,仍可以在某些標準的機器學習庫和框架中找到LRN實現,因此請隨時進行實驗。
重疊池
CNN中的池化層實質上將信息封裝在特征圖中的一組像素或值內,并將它們投影到較小尺寸的網格中,同時反映來自原始像素組的一般信息。
下圖提供了池化的示例,更具體地說是最大池化。 最大池化是子采樣的一種變體,其中子像素的最大像素值落在池化窗口的接收范圍內。
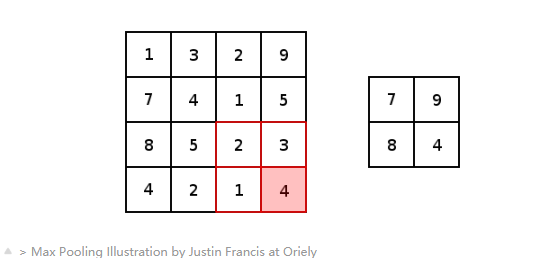
》 Max Pooling Illustration by Justin Francis at Oriely
在介紹AlexNet CNN架構的論文中,引入并利用了一種不同的合并方法。 重疊池。 在傳統的池化技術中,從池化窗口的一個中心到另一個中心的跨度被定位為確保來自一個池化窗口的值不在后續池化窗口之內。
與傳統的池化方法相比,重疊池使用的步幅小于池化窗口的尺寸。 這意味著后續合并窗口的輸出封裝了已被合并多次的像素/值中的信息。 很難看出這樣做的好處,但是根據論文的發現,重疊池降低了模型在訓練期間過擬合的能力。
數據擴充
減少過度適應網絡機會的另一種標準方法是通過數據增強。 通過人為地擴充數據集,您可以增加訓練數據的數量,從而增加了網絡在訓練階段所暴露的數據量。
圖像的增強通常以變換,平移,縮放,裁剪,翻轉等形式出現。
在訓練階段,人為地放大了AlexNet原始論文中用于訓練網絡的圖像。 所使用的增強技術是裁剪和更改圖像中像素的強度。
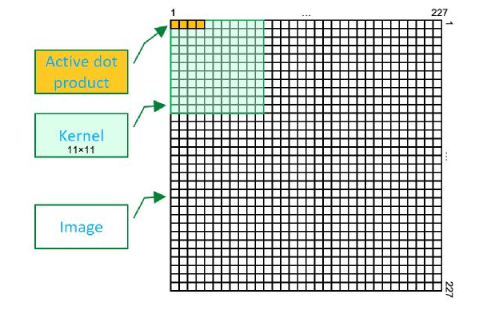
將訓練集中的圖像從其256 x 256維度中隨機裁剪,以獲得新的224 x 224裁剪圖像。
增強為何起作用?
事實證明,隨機執行對訓練集的擴充可以顯著降低訓練期間網絡過度擬合的可能性。
增強圖像只是從原始訓練圖像的內容中得出的,那么增強為何如此有效?
簡單來說,數據擴充可增加數據集中的不變性,而無需采購新數據。 網絡能夠很好地泛化到看不見的數據集的能力也有所提高。
讓我們舉一個非常真實的例子; “生產”環境中的圖像可能并不完美,有些圖像可能傾斜,模糊或僅包含一些基本特征。 因此,針對包括訓練數據的更健壯變化的數據集訓練網絡將使訓練后的網絡在生產環境中能夠更成功地對圖像進行分類。
Dropout
Dropout是許多深度學習從業人員熟悉的術語。 Dropout是一種用于減少模型過擬合潛力的技術。
Dropout技術是通過向CNN層內的神經元激活添加概率因子來實現的。 該概率因子向神經元指示了在當前前饋步驟期間以及在反向傳播過程中被激活的機會。
Dropout是有用的,因為它使神經元能夠減少對相鄰神經元的依賴。 因此,每個神經元都會學習更多有用的功能。
在AlexNet架構中,前兩個完全連接的層使用了dropout技術。
使用丟失技術的缺點之一是,它增加了網絡收斂所需的時間。
雖然,利用Dropout的優勢遠遠超過了它的劣勢。
AlexNet體系結構
在本節中,我們將了解AlexNet網絡的內部組成。 我們將重點關注與圖層相關的信息,并細分每個重要圖層的內部屬性。
AlexNet CNN體系結構由8層組成,其中包括5個conv層和3個完全連接的層。 卷積層中的一些是卷積層,池化層和規范化層的組合。
AlexNet是第一個采用具有連續卷積層(轉換層3、4和5)的體系結構。
網絡中的最終完全連接層包含softmax激活函數,該函數提供一個向量,表示1000個類別上的概率分布。
Softmax激活功能
利用Softmax激活來得出輸入向量內一組數字的概率分布。 softmax激活函數的輸出是一個向量,其中它的一組值表示發生類或事件的概率。 向量中的值總計為1。
除了最后一個完全連接的層之外,ReLU激活功能還應用于網絡中包含的其余層。
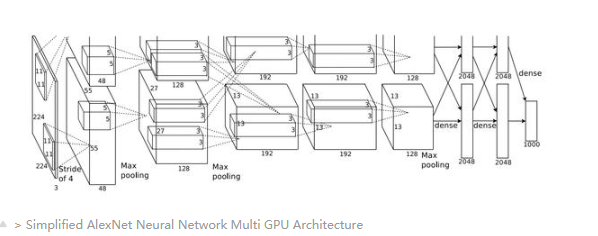
》 Simplified AlexNet Neural Network Multi GPU Architecture
由于該模型是在兩個GTX 580 GPU上訓練的,因此上面的AlexNet網絡的圖示分為兩個分區。 盡管網絡跨兩個GPU進行了劃分,但是從圖中可以看出,在conv3,FC6,FC7和FC8層中可以看到一些交叉的GPU通信。
下表是網絡中各層的某些特征和屬性的細分。
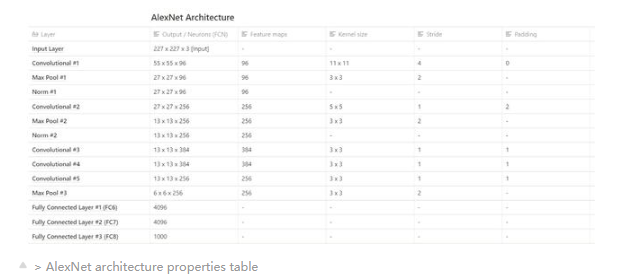
》 AlexNet architecture properties table
在原始紙張中,輸入層的尺寸據說為224 x 224 x 3,但是在上方的表格中,輸入層的輸入尺寸為227 x 227 x 3,差異是由于存在一些 在實際的網絡培訓期間發生的未提及的填充,未包含在發表的論文中。















 工商網監
工商網監
評論