 電子發(fā)燒友App
電子發(fā)燒友App


作者:周蘇,支雪磊,劉懂,寧皓,蔣連新,石繁槐
PVANet(performance vs accuracy network)卷積神經(jīng)網(wǎng)絡(luò)用于小目標(biāo)檢測(cè)的檢測(cè)能力較弱。針對(duì)這一瓶頸問題, 采用對(duì)PVANet網(wǎng)絡(luò)的淺層特征提取層、深層特征提取層和HyperNet層(多層特征信息融合層)進(jìn)行改進(jìn)的措施, 提出了一種適用于小目標(biāo)物體檢測(cè)的改進(jìn)PVANet卷積神經(jīng)網(wǎng)絡(luò)模型, 并在TT100K(Tsinghua-Tencent 100K)數(shù)據(jù)集上進(jìn)行了交通標(biāo)志檢測(cè)算法驗(yàn)證實(shí)驗(yàn)。結(jié)果表明, 所構(gòu)建的卷積神經(jīng)網(wǎng)絡(luò)具有優(yōu)秀的小目標(biāo)物體檢測(cè)能力, 相應(yīng)的交通標(biāo)志檢測(cè)算法可以實(shí)現(xiàn)較高的準(zhǔn)確率。
計(jì)算機(jī)目標(biāo)檢測(cè)是指計(jì)算機(jī)根據(jù)視頻、圖像信息對(duì)目標(biāo)物體的類別與位置的檢測(cè), 是計(jì)算機(jī)視覺研究領(lǐng)域的基本內(nèi)容。隨著硬件和軟件技術(shù)的發(fā)展, 尤其是基于卷積神經(jīng)網(wǎng)絡(luò)目標(biāo)檢測(cè)算法的普及應(yīng)用, 計(jì)算機(jī)目標(biāo)檢測(cè)的準(zhǔn)確率及速度都有了很大提高[1]。而且, 異于傳統(tǒng)的人工設(shè)計(jì)特征提取器, 卷積神經(jīng)網(wǎng)絡(luò)目標(biāo)物體檢測(cè)可自主學(xué)習(xí)視頻、圖像信息中的特征, 從而檢測(cè)到更多類別以及更細(xì)分類的物體[2]。小目標(biāo)檢測(cè)主要是對(duì)圖像或視頻中的標(biāo)志、行人或車輛等顯示尺寸較小的目標(biāo)進(jìn)行檢測(cè), 在民用、軍事和安防等領(lǐng)域具有十分重要的作用[1]。
近年來卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)及目標(biāo)檢測(cè)算法被廣泛應(yīng)用, 如用于手寫數(shù)字識(shí)別的LeNet(lecun network)[3]、用于圖像分類的VGGNet(visual geometry group network)、GoogLeNet(Google network)及ResNet(residual network)等[4], 用于目標(biāo)檢測(cè)的Faster R-CNN(faster region-based convolutional neural network)、R-FCN(region-based fully convolutional network)、YOLO(you-only-look-once)和SSD(single shot detector)等[5-7]。但是, 當(dāng)檢測(cè)圖像中目標(biāo)物體很小時(shí), 主流卷積神經(jīng)網(wǎng)絡(luò)的檢測(cè)能力仍然較弱, 這是其在目標(biāo)檢測(cè)應(yīng)用方面的主要瓶頸問題之一。吳雙忱等[8]基于SEnet(Squeeze-and-Excitation network)提出了一種解決紅外小目標(biāo)檢測(cè)問題的深度卷積網(wǎng)絡(luò)。趙慶北等[9]對(duì)Faster R-CNN網(wǎng)絡(luò)進(jìn)行改進(jìn), 引入候選區(qū)域方案提高了公司徽標(biāo)的檢測(cè)性能。彭小飛等[10]對(duì)原始FPN(feature pyramid network)網(wǎng)絡(luò)進(jìn)行改進(jìn), 利用淺層網(wǎng)絡(luò)豐富的位置信息, 進(jìn)行小目標(biāo)的全圖搜索檢測(cè)。梁華等[11]針對(duì)航拍小目標(biāo)識(shí)別率低、定位差的問題, 基于VGG16網(wǎng)絡(luò)進(jìn)行改進(jìn), 提高其實(shí)時(shí)性和精度性能.PVANet網(wǎng)絡(luò)具有訓(xùn)練效率高、對(duì)不同尺度目標(biāo)的適應(yīng)性強(qiáng)等適合于復(fù)雜多變交通場(chǎng)景的優(yōu)勢(shì)。本研究工作對(duì)PVANet(performance vs accuracy network)網(wǎng)絡(luò)進(jìn)行改進(jìn), 解決其交通標(biāo)志小目標(biāo)檢測(cè)能力不足的問題。
1 相關(guān)工作
各國(guó)交通標(biāo)志都有其規(guī)定的顏色、形狀、圖案等特征, 采用傳統(tǒng)的手工設(shè)計(jì)特征提取器, 可以從圖像中提取特征信息進(jìn)行交通標(biāo)志檢測(cè).Ritter等[12]采用圖像顏色組合檢測(cè)交通標(biāo)志, 在紅、綠和藍(lán)色(RGB)中引入查表法(LUT)消除不需要的顏色.Priese等[13]設(shè)計(jì)了用于顏色分割的顏色結(jié)構(gòu)代碼(CSC), 并且生成CSC數(shù)據(jù)庫。研究結(jié)果表明, 道路標(biāo)志顏色的RGB分量差異雖可用于目標(biāo)分割和檢測(cè), 但不便于直接描述光照變化。因此, 人們開始研究由色調(diào)、飽和度和強(qiáng)度(HSI)或者色調(diào)、飽和度等組成的顏色特征空間下的交通標(biāo)志檢測(cè)[14]。其中, HSI因其模擬人類感知的能力優(yōu)于RGB, 其交通標(biāo)志檢測(cè)應(yīng)用效果更好。 Zaklouta等[15]結(jié)合HOG(histogram of oriented gradients)描述符和線性SVM(support vector machine)算法在處理實(shí)時(shí)性要求和性能之間取得了良好的折衷。
手工設(shè)計(jì)特征提取方法對(duì)圖像特征的提取能力有限, 交通標(biāo)志檢測(cè)應(yīng)用效果很大程度上取決于設(shè)計(jì)者經(jīng)驗(yàn), 因此不適用于大規(guī)模交通標(biāo)志檢測(cè)。神經(jīng)網(wǎng)絡(luò)具有學(xué)習(xí)非線性、復(fù)雜關(guān)系的能力[16], 尤其是卷積神經(jīng)網(wǎng)絡(luò)可自主學(xué)習(xí)圖像特征, 越來越多地被用于交通標(biāo)志檢測(cè).Sermanet等[17]用卷積網(wǎng)絡(luò)從GTSRB數(shù)據(jù)集(德國(guó)交通標(biāo)志檢測(cè)數(shù)據(jù)集)的彩色圖像中提取并學(xué)習(xí)交通標(biāo)志的特征信息, 檢測(cè)準(zhǔn)確率高達(dá)98.97%.Aghdam等[18]提出一種新的ReLU(rectified linear unit)作為激活函數(shù)的CNN(convolutional neural network)架構(gòu), 實(shí)現(xiàn)了更佳的精確度和檢測(cè)時(shí)間。
2 PVANet網(wǎng)絡(luò)結(jié)構(gòu)與改進(jìn)
2.1 PVANet網(wǎng)絡(luò)簡(jiǎn)介
PVANet[19]是Intel公司Kim等人在2016年提出的一種用于實(shí)時(shí)物體檢測(cè)的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。在VOC(visual object classes)[20-21]數(shù)據(jù)集物體檢測(cè)比賽項(xiàng)目上PVANet取得了第2名的成績(jī), 其平均準(zhǔn)確率(mAP)為82.5%.
PVANet采用基于C.ReLU(concatenated rectified linear unit)激活函數(shù)的淺層特征提取方法, 改善參數(shù)冗余問題, 減小了網(wǎng)絡(luò)參數(shù)量, 提高了訓(xùn)練效率.PVANet還借鑒Inception(谷歌基礎(chǔ)神經(jīng)元結(jié)構(gòu)思想), 將輸入分別通過4個(gè)不同的卷積核進(jìn)行卷積和池化操作后串聯(lián)合并在一起, 增加了網(wǎng)絡(luò)對(duì)不同尺度目標(biāo)的適應(yīng)性。另外, PVANet將conv3中原圖的1/8、1/16和1/32特征圖連接起來, 增強(qiáng)了最終特征圖中的多尺度信息。
2.2 PVANet網(wǎng)絡(luò)結(jié)構(gòu)的改進(jìn)
PVANet網(wǎng)絡(luò)進(jìn)行目標(biāo)檢測(cè)時(shí), 雖然其準(zhǔn)確率和實(shí)時(shí)性較好, 但針對(duì)小目標(biāo)物體的檢測(cè)能力仍有很大的提升空間。對(duì)此, 本文提出了更適用于小目標(biāo)物體檢測(cè)的改進(jìn)網(wǎng)絡(luò)結(jié)構(gòu), 對(duì)淺層特征提取層、深層特征提取層和HyperNet層進(jìn)行了改進(jìn)。圖 1是改進(jìn)前PVANet網(wǎng)絡(luò)結(jié)構(gòu)(圖 1a)與改進(jìn)后結(jié)構(gòu)(圖 1b)的對(duì)比, 其中虛線邊框模塊為本文提出的改進(jìn)模塊。詳細(xì)的改進(jìn)后PVANet網(wǎng)絡(luò)信息見表 1.
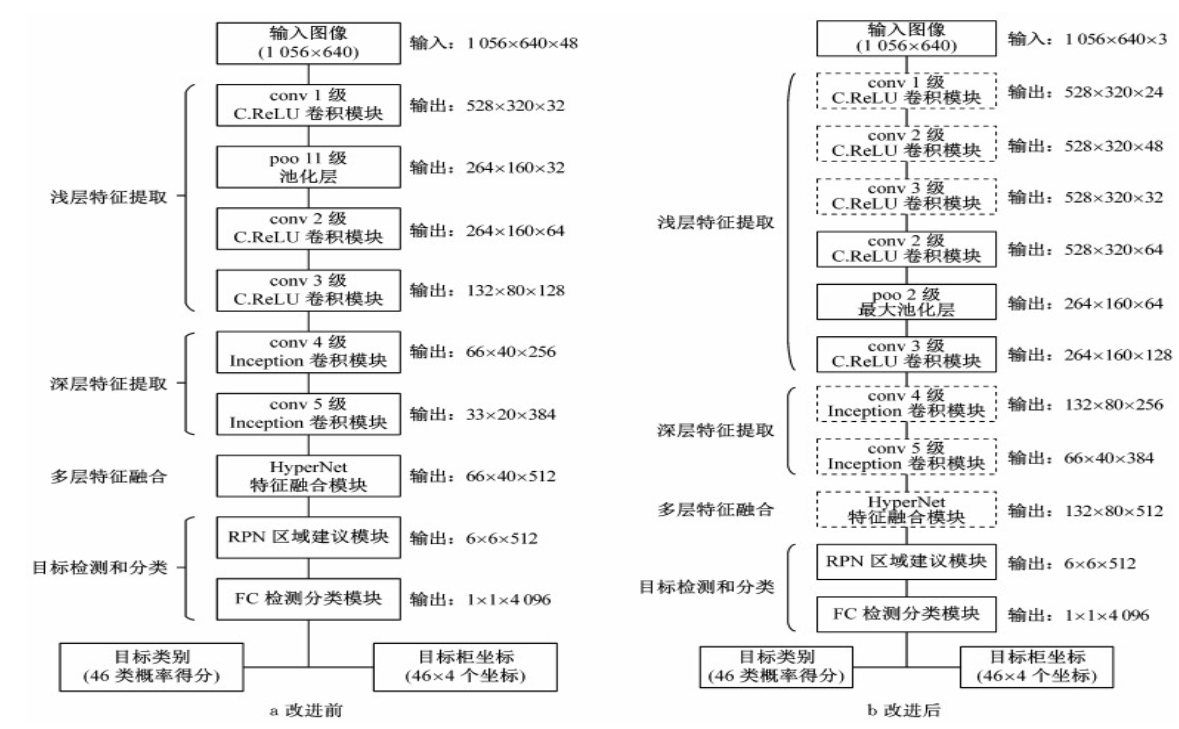
注: conv i—第i級(jí)卷積; pool—池化; RPN—region proposal network; FC— fully connected layer
圖 1 PVANet網(wǎng)絡(luò)改進(jìn)前后結(jié)構(gòu)圖
Fig.1 Structure of PVANet before and after improvement
2.2.1 淺層特征提取
PVANet網(wǎng)絡(luò)的第1層卷積層通常采用7×7或更大維度的卷積核(步長(zhǎng)為2)進(jìn)行卷積, 同時(shí)在本層即采用了C.ReLU型激活函數(shù), 這樣可以避免淺層卷積濾波器的參數(shù)冗余問題。
與單個(gè)的7×7或更大維度的卷積核相比, 采用多個(gè)3×3卷積核的組合, 可以減少參數(shù)量并加快檢測(cè)速度, 同時(shí)增強(qiáng)網(wǎng)絡(luò)的非線性表達(dá)能力。另外, C.ReLU激活函數(shù)雖然具有提高參數(shù)效率、避免淺層卷積濾波器參數(shù)冗余的優(yōu)點(diǎn), 但是特征圖經(jīng)過C.ReLU處理后輸出維度會(huì)增加一倍。因此, 目前PVANet使用C.ReLU時(shí)通常對(duì)輸入特征圖的維度加以限制, 如設(shè)定conv1卷積模塊的輸出期望維度為32, 第1層卷積層的輸出維度必須限定為16.對(duì)于較大圖片來說, 這樣的設(shè)計(jì)會(huì)限制淺層網(wǎng)絡(luò)提取特征的能力, 致使圖像的細(xì)粒度和小目標(biāo)特征信息部分丟失。
鑒于上述原因, 本文提出將PVANet第1層卷積層中7×7維度的卷積核拆解成3層3×3維度的卷積層。其中, 第1層卷積層使用普通的ReLU激活函數(shù), 將其輸出維度提高至24;第2層卷積開始使用C.ReLU激活函數(shù), 輸出維度增加至48;第3層卷積層輸出維度減小至32.這樣的結(jié)構(gòu)改進(jìn)(圖 2)旨在增加淺層卷積濾波器的細(xì)粒度和小目標(biāo)圖像特征的提取能力。此外, 為增強(qiáng)改進(jìn)效果, 將conv 2和conv 3卷積模塊中每個(gè)子模塊中第1層卷積層的輸出維度增大至48和72, 如表 1所示。
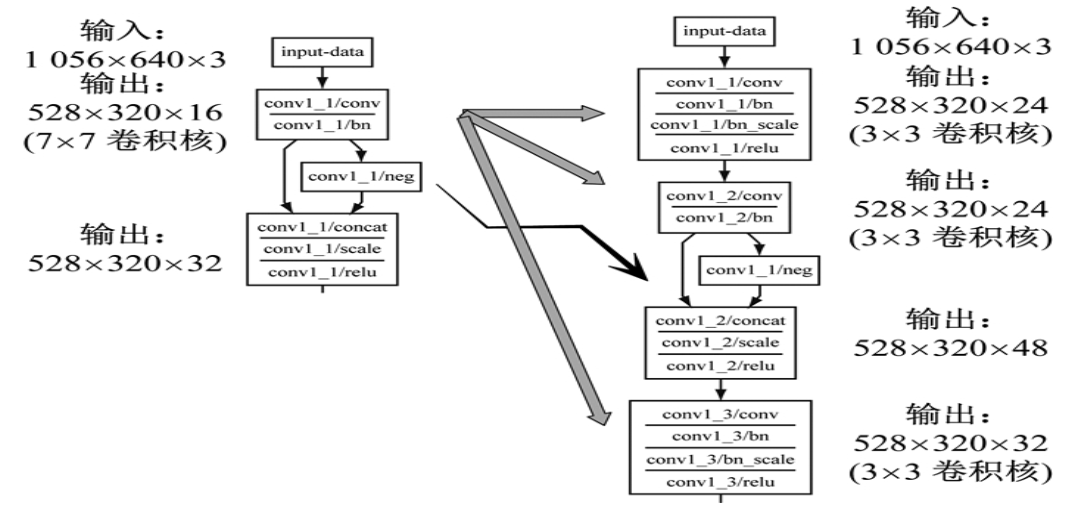
圖 2 淺層特征提取卷積層改進(jìn)示意圖
Fig.2 Improvement of shallow feature extraction
2.2.2 深層特征提取
PVANet網(wǎng)絡(luò)通常采用Inception v1模塊進(jìn)行深層特征提取。在該模塊中, 將5×5的卷積核分解為兩個(gè)3×3維度的卷積核, 可以減小網(wǎng)絡(luò)模型的參數(shù)量, 但是會(huì)發(fā)生一定程度的精度損失。為了克服這一不足, 在進(jìn)行上述卷積核分解的同時(shí), 本文將3×3卷積核進(jìn)一步非對(duì)稱地分解成兩個(gè)1×3和3×1維度的卷積核。這樣的非對(duì)稱分解(圖 3)不僅進(jìn)一步減少了網(wǎng)絡(luò)的參數(shù)量, 而且通過層數(shù)增加有望進(jìn)一步提高網(wǎng)絡(luò)的非線性表達(dá)能力。
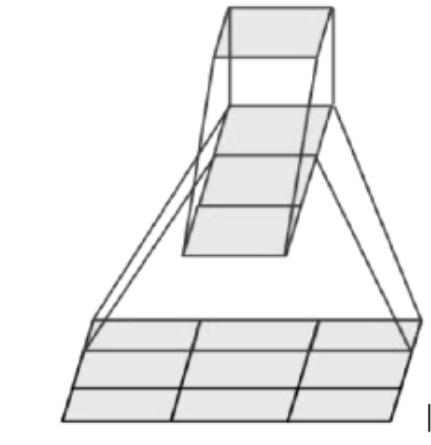
圖 3 非對(duì)稱1×3和3×1維度卷積核的卷積過程
Fig.3 Convolution process of asymmetric 1×3 and 3×1 dimensional convolution kernels
2.2.3 多層特征信息融合
在原版PVANet網(wǎng)絡(luò)中, conv 3_4淺層卷積層輸出的132×80像素特征圖的下采樣處理是通過3×3池化層進(jìn)行的, 最后的conv5_4深層卷積層輸出的33×20特征圖的上采樣處理則通過4×4像素卷積核進(jìn)行。兩者得到的特征圖大小相同(66×40像素), 合并之后作為目標(biāo)檢測(cè)和分類的依據(jù)。但是, 相比輸入圖片, 這一系列66×40像素特征圖已經(jīng)縮小了16倍。如果輸入圖片中存在一個(gè)32×32像素描述的小目標(biāo), 映射到最后的特征圖上就只有2×2個(gè)像素點(diǎn)信息。原版PVANet網(wǎng)絡(luò)的多層特征信息融合方式使得小目標(biāo)的特征表征能力受到限制, 難以準(zhǔn)確識(shí)別圖像中的小目標(biāo)。
因此, 本文提出減少1次池化和相應(yīng)的卷積特征提取, 使網(wǎng)絡(luò)能融合更淺層卷積層輸出的特征圖信息, 并在更大的132×80特征圖上進(jìn)行目標(biāo)檢測(cè)和分類(即只縮小8倍), 使其對(duì)小目標(biāo)有更強(qiáng)的檢測(cè)能力。
3 實(shí)驗(yàn)
3.1 實(shí)驗(yàn)條件與方法
采用TT100K[22]交通標(biāo)志數(shù)據(jù)集作為改進(jìn)網(wǎng)絡(luò)訓(xùn)練和測(cè)試用的基準(zhǔn)數(shù)據(jù)集, 其中訓(xùn)練集包括10 380張圖片, 測(cè)試集包括5 229張圖片。兩個(gè)子集覆蓋了所有需要檢測(cè)的標(biāo)志類別, 并且圖像數(shù)據(jù)互不包含。
訓(xùn)練所用的求解器為SGD(stochastic gradient descent), Batch Size為1, 起始學(xué)習(xí)率設(shè)置為0.01, 之后根據(jù)數(shù)據(jù)集的大小和Batch Size采用每40 000步減小0.1倍的方法, momentum和weight decay分別設(shè)置為0.9和0.000 2.
研究中所有深度學(xué)習(xí)算法的訓(xùn)練和測(cè)試全部使用了Caffe深度學(xué)習(xí)框架, 并且在一臺(tái)配備了Intel i7-5930K CPU和NVIDIA Titan X GPU的工作站上進(jìn)行, 操作界面采用Python軟件實(shí)現(xiàn)。
3.2 實(shí)驗(yàn)結(jié)果與分析
在實(shí)驗(yàn)過程中, 分別使用原版PVANet網(wǎng)絡(luò)模型結(jié)構(gòu)及加入本文所述各改進(jìn)算法的PVANet網(wǎng)絡(luò)模型結(jié)構(gòu), 在TT100K測(cè)試集上進(jìn)行交通標(biāo)志檢測(cè), 以準(zhǔn)確率、單幀檢測(cè)時(shí)間和PR(precision-recall)曲線作為評(píng)價(jià)指標(biāo)。實(shí)驗(yàn)結(jié)果見表 2和圖 4.
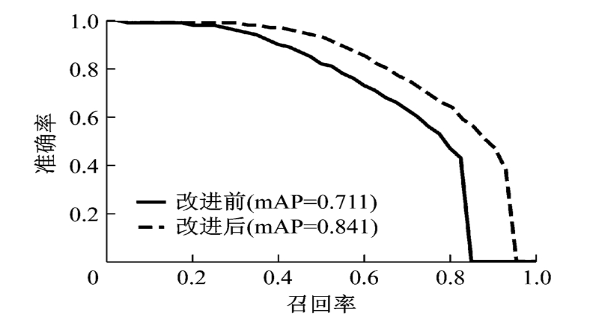
圖 4 算法改進(jìn)前后PR曲線對(duì)比圖
Fig.4 Comparison of PR curve
由表 2可以看出, 與PVANet 9.1在數(shù)據(jù)集上的檢測(cè)結(jié)果相比, 采用2.2.1節(jié)改進(jìn)算法可以將交通標(biāo)志檢測(cè)的mAP提升約4.2%.可知, 提高淺層神經(jīng)網(wǎng)絡(luò)的通道數(shù), 可以提高網(wǎng)絡(luò)對(duì)交通標(biāo)志小目標(biāo)的檢測(cè)能力。此外, 由于將大的7×7卷積核分解為多個(gè)小的3×3卷積核, 以減少計(jì)算量, 改進(jìn)后網(wǎng)絡(luò)模型的檢測(cè)時(shí)間無明顯增加。采用2.2.1、2.2.2節(jié)所述的改進(jìn)算法, 即再將深層網(wǎng)絡(luò)中的5×5卷積替換為兩個(gè)1×3和3×1卷積, 也會(huì)使網(wǎng)絡(luò)模型的檢測(cè)速度變快, 同時(shí)能夠保持較高的mAP.最后, 采用2.2節(jié)中的改進(jìn)算法, 再減小1次池化計(jì)算, 將神經(jīng)網(wǎng)絡(luò)的輸出特征圖增大一倍, 使得網(wǎng)絡(luò)對(duì)交通標(biāo)志檢測(cè)的mAP大幅提高約9%, 網(wǎng)絡(luò)的檢測(cè)時(shí)間雖然增加約0.02 s, 但是仍然具有很好的實(shí)時(shí)性, 滿足交通標(biāo)志檢測(cè)要求。由圖 4可知, 改進(jìn)后算法的準(zhǔn)確率和召回率都有所提升。綜上所述, 輸出更大的特征圖雖然使計(jì)算量有所增加, 但可增強(qiáng)網(wǎng)絡(luò)的特征表達(dá)能力, 大幅增加網(wǎng)絡(luò)的目標(biāo)檢測(cè)準(zhǔn)確率。
圖 5是算法對(duì)小目標(biāo)交通標(biāo)志檢測(cè)的效果圖, 其中存在一個(gè)超小且被遮擋的交通標(biāo)志(圖 5b標(biāo)注所示)。圖 5a為原版PVANet網(wǎng)絡(luò)模型檢測(cè)結(jié)果, 圖 5b為改進(jìn)后PVANet網(wǎng)絡(luò)模型檢測(cè)結(jié)果。可見, 改進(jìn)后PVANet網(wǎng)絡(luò)對(duì)于交通標(biāo)志小目標(biāo)物體有著很好的檢測(cè)能力, 且對(duì)于目標(biāo)物體的被遮擋問題有著一定的魯棒性。
圖 5 改進(jìn)前后PAVNet檢測(cè)效果對(duì)比圖
Fig.5 Comparison of detection before and after improvement
圖 6是圖 5場(chǎng)景經(jīng)算法模型卷積計(jì)算得到的中間層特征圖。可以看出, 淺層特征圖側(cè)重圖像宏觀特征的提取, 因此與原圖風(fēng)格相近, 而深層特征圖側(cè)重對(duì)細(xì)節(jié)像素的計(jì)算判斷, 對(duì)交通標(biāo)志的準(zhǔn)確檢測(cè)更為關(guān)鍵。對(duì)比算法改進(jìn)前后的效果可以看到, 改進(jìn)后算法在正確的交通標(biāo)志區(qū)域呈現(xiàn)出代表敏感性的更亮色, 具有更好的檢測(cè)效果。
圖 6 改進(jìn)前后淺層和深層卷積層特征對(duì)比圖
Fig.6 Comparison of shallow and deep convolutional layers
圖 7是改進(jìn)算法對(duì)于有更多超小目標(biāo)交通標(biāo)志圖像的更復(fù)雜交通場(chǎng)景的檢測(cè)效果, 其中圖 7a是原圖, 圖 7b和圖 7c分別是改進(jìn)前和改進(jìn)后算法檢測(cè)結(jié)果的局部放大圖。該場(chǎng)景共有5個(gè)交通標(biāo)志, 原版PVANet只檢測(cè)到3個(gè)交通標(biāo)志, 改進(jìn)后算法可檢測(cè)到所有5個(gè)交通標(biāo)志。由此可見, 改進(jìn)算法具有更好的檢測(cè)效果。
圖 7 檢測(cè)效果對(duì)比圖
Fig.7 Comparison of experimental results
TT100K數(shù)據(jù)集中的部分交通標(biāo)志屬于小目標(biāo)物體, 通過本研究中基于此數(shù)據(jù)集的實(shí)驗(yàn), 驗(yàn)證了所提出的改進(jìn)算法對(duì)于交通標(biāo)志小目標(biāo)具有優(yōu)秀的檢測(cè)能力。分析其原因, 由于淺層神經(jīng)網(wǎng)絡(luò)感知野(perception field)較小, 主要負(fù)責(zé)網(wǎng)絡(luò)的細(xì)節(jié)特征提取, 增加淺層網(wǎng)絡(luò)通道數(shù), 能夠使網(wǎng)絡(luò)提取更多細(xì)節(jié)信息, 這對(duì)交通標(biāo)志小目標(biāo)的檢測(cè)是有利的。而減小一次池化計(jì)算, 不僅增大網(wǎng)絡(luò)輸出的特征圖大小, 也使網(wǎng)絡(luò)模型中HyperNet模塊融合的淺層特征圖更“淺”, 這樣神經(jīng)網(wǎng)絡(luò)就能夠提取圖片中更多的細(xì)節(jié)特征信息, 提高網(wǎng)絡(luò)的小目標(biāo)檢測(cè)能力。雖然經(jīng)過多步改進(jìn)后, 所提出改進(jìn)算法的檢測(cè)時(shí)間有一定增加, 但總時(shí)間仍控制在0.09 s內(nèi), 具有很高的實(shí)時(shí)性。
4 結(jié)論
PVANet網(wǎng)絡(luò)具有訓(xùn)練效率高、對(duì)不同尺度目標(biāo)的適應(yīng)性強(qiáng)等適合于復(fù)雜多變交通場(chǎng)景應(yīng)用的優(yōu)勢(shì)。本文對(duì)其淺層特征提取、深層特征提取和HyperNet多層特征融合模塊分別進(jìn)行改進(jìn), 提出了一種改進(jìn)的PVANet卷積神經(jīng)網(wǎng)絡(luò)模型, 克服了小目標(biāo)交通標(biāo)志識(shí)別的瓶頸難點(diǎn)。基于TT100K交通標(biāo)志數(shù)據(jù)集, 對(duì)改進(jìn)算法進(jìn)行了實(shí)驗(yàn)驗(yàn)證。結(jié)果表明, 所提出的改進(jìn)網(wǎng)絡(luò)模型與原網(wǎng)絡(luò)模型相比, 交通標(biāo)志小目標(biāo)檢測(cè)的mAP有大幅提升, 證明了其對(duì)小目標(biāo)物體優(yōu)秀的檢測(cè)能力; 雖然檢測(cè)時(shí)間小幅上升, 但仍具有較好的實(shí)時(shí)性。
參考文獻(xiàn)[1]劉曉楠, 王正平, 賀云濤, 等。 基于深度學(xué)習(xí)的小目標(biāo)檢測(cè)研究綜述[J]。 戰(zhàn)術(shù)導(dǎo)彈技術(shù), 2019(1): 100
LIU Xiaonan, WANG Zhengping, HE Yuntao, et al. Research on small target detection based on deep learning[J]。 Tactical Missile Technology, 2019(1): 100
[2]郭之先。基于卷積神經(jīng)網(wǎng)絡(luò)的小目標(biāo)檢測(cè)[D]。南昌: 南昌航空大學(xué), 2018.
GUO Zhixian. Small object detection algorithm based on deep convolution neural network[D]。 Nanchang: Nanchang Hangkong University, 2018.
[3]LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]。 Proceedings of the IEEE, 1998, 86(11): 2278 DOI:10.1109/5.726791
[4]HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
[5]REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]。 IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137
[6]LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multiBox detector[C]//European Conference on Computer Vision. Cham: Springer, 2016: 21-37.
[7]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
[8]吳雙忱, 左崢嶸。 基于深度卷積神經(jīng)網(wǎng)絡(luò)的紅外小目標(biāo)檢測(cè)[J]。 紅外與毫米波學(xué)報(bào), 2019, 38(3): 371
WU Shuangchen, ZUO Zhengrong. Small target detection in infrared images using deep convolution neural networks[J]。 Journal Infrared Millimeter Waves, 2019, 38(3): 371
[9]趙慶北, 元昌安, 覃曉。 改進(jìn)Faster R-CNN的小目標(biāo)檢測(cè)[J]。 廣西師范學(xué)院學(xué)報(bào)(自然科學(xué)版), 2018, 35(2): 68
ZHAO Qingbei, YUAN Chang‘a(chǎn)n, QIN Xiao. Improved faster R-CNN for small object detection[J]。 Journal of Guangxi Teachers Education University (Natural Science Edition), 2018, 35(2): 68
[10]彭小飛, 方志軍。 復(fù)雜條件下小目標(biāo)檢測(cè)算法研究[J]。 智能計(jì)算機(jī)與應(yīng)用, 2019, 9(3): 171
PENG Xiaofei, FANG Zhijun. Research on small target detection algorithm under complex conditions[J]。 Intelligent Computer and Applications, 2019, 9(3): 171 DOI:10.3969/j.issn.2095-2163.2019.03.040
[11]梁華, 宋玉龍, 錢鋒, 等。 基于深度學(xué)習(xí)的航空對(duì)地小目標(biāo)檢測(cè)[J]。 液晶與顯示, 2018, 33(9): 793
LIANG Hua, SONG Yulong, QIAN Feng, et al. Detection of small target in aerial photography based on deep learning[J]。 Chinese Journal of Liquid Crystals and Displays, 2018, 33(9): 793
[12]RITTER W, STEIN F, JANSSEN R. Traffic sign recognition using color information[J]。 Math Compute Model, 1995, 22(4/5/6/7): 149
[13]PRIESE L, KLIEBER J, LAKMANN R, et al. New results on traffic sign recognition[C]//Proceedings of the Intelligent Vehicles’94 Symposium. Paris: IEEE, 1994: 249-254.
[14]MOGELMOSE A, TRIVEDI M M, MOESLUND T B. Vision-based traffic sign detection and analysis for intelligent driver assistance systems: perspectives and survey[J]。 IEEE Transactions on Intelligent Transportation Systems, 2012, 13(4): 1484 DOI:10.1109/TITS.2012.2209421
[15]ZAKLOUTA F, STANCIULESCU B. Real-time traffic sign recognition in three stages[J]。 Robotics and Autonomous Systems, 2014, 62(1): 16
[16]SABBEH A, AI-DUNAINAWI Y, AI-RAWESHIDY H S, et al. Performance prediction of software defined network using an artificial neural network[C]//2016 SAI Computing Conference (SAI)。 London: IEEE, 2016: 80-84.
[17]SERMANET P, LECUN Y, Traffic sign recognition with multiscale convolutional networks[C]//The 2011 International Joint Conference on Neural Networks. San Jose: IEEE, 2011: 2809-2813.
[18]AGHDAM H H, HERAVI E J, PUIG D. A practical approach for detection and classification of traffic signs using convolutional neural networks[J]。 Robotics and Autonomous Systems, 2016, 84: 97 DOI:10.1016/j.robot.2016.07.003
[19]KIM K H, CHEON Y, HONG S, et al. PVANet: deep but lightweight neural networks for real-time object detection[J]。 arXiv, 2016(8): 1
[20]EVERINGHAM M, ESLAMI S M A, GOOL L V, et al. The pascal, visual object classes challenge: a retrospective[J]。 International Journal of Computer Vision, 2015, 111(1): 98 DOI:10.1007/s11263-014-0733-5
[21]RUSSAKOVSKY O, DENG Jia, SU Hao, et al. ImageNet large scale visual recognition challenge[J]。 International Journal of Computer Vision, 2015, 115(3): 211 DOI:10.1007/s11263-015-0816-y
[22]ZHU Zhe, LIANG Dun, ZHANG Songhai, et al. Traffic-sign detection and classification in the wild[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2110-2118.
編輯:hfy












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論