 電子發燒友App
電子發燒友App


什么是機器學習?機器學習是英文名稱MachineLearning(簡稱ML)的直譯。機器學習涉及概率論、統計學、逼近論、凸分析、算法復雜度理論等多門學科。專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。它是人工智能的核心,是使計算機具有智能的根本途徑,其應用遍及人工智能的各個領域,它主要使用歸納、綜合而不是演繹。相對于傳統的計算機工作,我們給它一串指令,然后它遵照這個指令一步步執行下去即可。機器學習根本不接受你輸入的指令,相反,它只接受你輸入的數據!也就是說它某種意義上具有了我們人處理事情的能力。
機器學習發展史
機器學習是人工智能研究較為年輕的分支,它的發展過程大體上可分為4個時期。第一階段是在20世紀50年代中葉到60年代中葉,屬于熱烈時期。第二階段是在20世紀60年代中葉至70年代中葉,被稱為機器學習的冷靜時期。第三階段是從20世紀70年代中葉至80年代中葉,稱為復興時期。機器學習的最新階段始于1986年。機器學習進入新階段的重要表現在下列諸方面:
(1)機器學習已成為新的邊緣學科并在高校形成一門課程。它綜合應用心理學、生物學和神經生理學以及數學、自動化和計算機科學形成機器學習理論基礎。
(2)結合各種學習方法,取長補短的多種形式的集成學習系統研究正在興起。特別是連接學習符號學習的耦合可以更好地解決連續性信號處理中知識與技能的獲取與求精問題而受到重視。
(3)機器學習與人工智能各種基礎問題的統一性觀點正在形成。例如學習與問題求解結合進行、知識表達便于學習的觀點產生了通用智能系統SOAR的組塊學習。類比學習與問題求解結合的基于案例方法已成為經驗學習的重要方向。
(4)各種學習方法的應用范圍不斷擴大,一部分已形成商品。歸納學習的知識獲取工具已在診斷分類型專家系統中廣泛使用。連接學習在聲圖文識別中占優勢。分析學習已用于設計綜合型專家系統。遺傳算法與強化學習在工程控制中有較好的應用前景。與符號系統耦合的神經網絡連接學習將在企業的智能管理與智能機器人運動規劃中發揮作用。(5)與機器學習有關的學術活動空前活躍。國際上除每年一次的機器學習研討會外,還有計算機學習理論會議以及遺傳算法會議。
機器學習的范圍
機器學習跟模式識別,統計學習,數據挖掘,計算機視覺,語音識別,自然語言處理等領域有著很深的聯系。從范圍上來說,機器學習跟模式識別,統計學習,數據挖掘是類似的,同時,機器學習與其他領域的處理技術的結合,形成了計算機視覺、語音識別、自然語言處理等交叉學科。因此,一般說數據挖掘時,可以等同于說機器學習。同時,我們平常所說的機器學習應用,應該是通用的,不僅僅局限在結構化數據,還有圖像,音頻等應用。
模式識別
模式識別=機器學習。兩者的主要區別在于前者是從工業界發展起來的概念,后者則主要源自計算機學科。在著名的《PatternRecognitionAndMachineLearning》這本書中,ChristopherM.Bishop在開頭是這樣說的“模式識別源自工業界,而機器學習來自于計算機學科。不過,它們中的活動可以被視為同一個領域的兩個方面,同時在過去的10年間,它們都有了長足的發展”。
數據挖掘
數據挖掘=機器學習+數據庫,記得大學的最后一學期開了一門數據挖掘的課,何為數據挖掘,就是從海量的數據中挖掘出有用的數據,其實從某種意義上來說和大數據分析很像。數據挖掘通常與計算機科學有關,并通過統計、在線分析處理、情報檢索、機器學習、專家系統(依靠過去的經驗法則)和模式識別等諸多方法來實現上述目標。
統計學習
統計學習近似等于機器學習。統計學習是個與機器學習高度重疊的學科。因為機器學習中的大多數方法來自統計學,甚至可以認為,統計學的發展促進機器學習的繁榮昌盛。例如著名的支持向量機算法,就是源自統計學科。但是在某種程度上兩者是有分別的,這個分別在于:統計學習者重點關注的是統計模型的發展與優化,偏數學,而機器學習者更關注的是能夠解決問題,偏實踐,因此機器學習研究者會重點研究學習算法在計算機上執行的效率與準確性的提升。
計算機視覺
計算機視覺=圖像處理+機器學習。圖像處理技術用于將圖像處理為適合進入機器學習模型中的輸入,機器學習則負責從圖像中識別出相關的模式。隨著機器學習的新領域深度學習的發展,大大促進了計算機圖像識別的效果,因此未來計算機視覺界的發展前景不可估量。
語音識別
語音識別=語音處理+機器學習。語音識別就是音頻處理技術與機器學習的結合。語音識別技術一般不會單獨使用,一般會結合自然語言處理的相關技術。目前的相關應用有蘋果的語音助手siri,訊飛等國內很多的科技公司和機構。
自然語言處理
自然語言處理=文本處理+機器學習。自然語言處理技術主要是讓機器理解人類的語言的一門領域。在自然語言處理技術中,大量使用了編譯原理相關的技術,例如詞法分析,語法分析等等,除此之外,在理解這個層面,則使用了語義理解,機器學習等技術。
機器學習算法
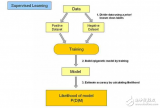
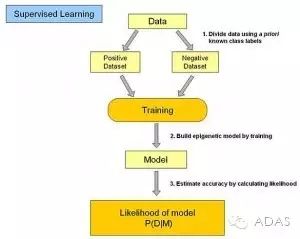
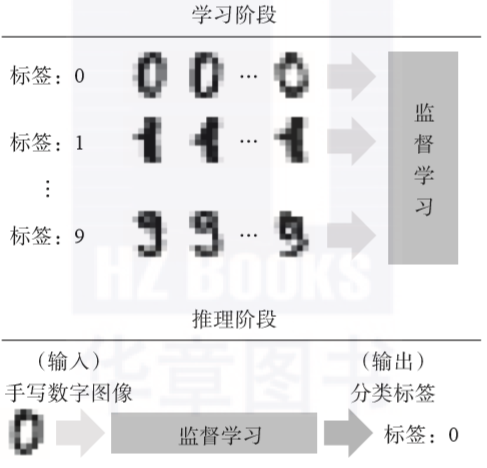
監督式學習
監督式學習算法包括一個目標變量(因變量)和用來預測目標變量的預測變量(自變量)。通過這些變量我們可以搭建一個模型,從而對于一個已知的預測變量值,我們可以得到對應的目標變量值。重復訓練這個模型,直到它能在訓練數據集上達到預定的準確度。屬于監督式學習的算法有:回歸模型,決策樹,隨機森林,K鄰近算法,邏輯回歸等。
無監督式學習
與監督式學習不同的是,無監督學習中我們沒有需要預測或估計的目標變量。無監督式學習是用來對總體對象進行分類的。它在根據某一指標將客戶分類上有廣泛應用。屬于無監督式學習的算法有:關聯規則,K-means聚類算法等。
強化學習
這個算法可以訓練程序做出某一決定。程序在某一情況下嘗試所有的可能行動,記錄不同行動的結果并試著找出最好的一次嘗試來做決定。屬于這一類算法的有馬爾可夫決策過程。
常見算法
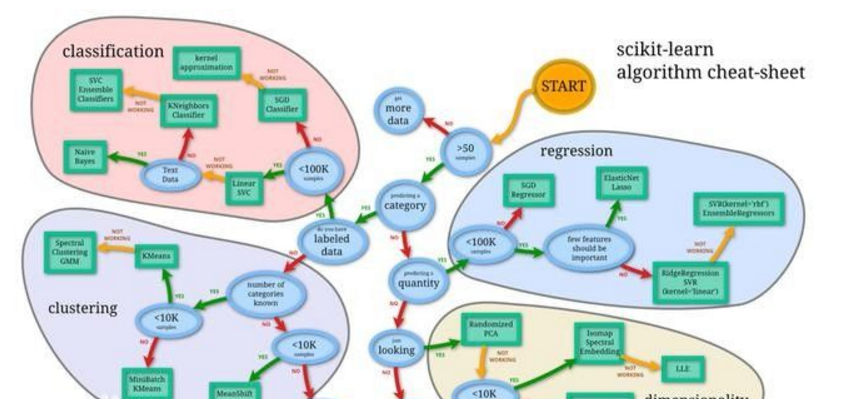
常見的機器學習算法以下是最常用的機器學習算法,大部分數據問題都可以通過它們解決:1.線性回歸(LinearRegression)2.邏輯回歸(LogisticRegression)3.決策樹(DecisionTree)4.支持向量機(SVM)5.樸素貝葉斯(NaiveBayes)6.K鄰近算法(KNN)7.K-均值算法(K-means)8.隨機森林(RandomForest)9.降低維度算法(DimensionalityReductionAlgorithms)10.GradientBoost和Adaboost算法
機器學習分類
基于學習策略的分類
學習策略是指學習過程中系統所采用的推理策略。一個學習系統總是由學習和環境兩部分組成。由環境(如書本或教師)提供信息,學習部分則實現信息轉換,用能夠理解的形式記憶下來,并從中獲取有用的信息。在學習過程中,學生(學習部分)使用的推理越少,他對教師(環境)的依賴就越大,教師的負擔也就越重。學習策略的分類標準就是根據學生實現信息轉換所需的推理多少和難易程度來分類的,依從簡單到復雜,從少到多的次序分為以下六種基本類型:
1)機械學習(Rotelearning)
學習者無需任何推理或其它的知識轉換,直接吸取環境所提供的信息。如塞繆爾的跳棋程序,紐厄爾和西蒙的LT系統。這類學習系統主要考慮的是如何索引存貯的知識并加以利用。系統的學習方法是直接通過事先編好、構造好的程序來學習,學習者不作任何工作,或者是通過直接接收既定的事實和數據進行學習,對輸入信息不作任何的推理。
2)示教學習(Learningfrominstruction或Learningbybeingtold)
學生從環境(教師或其它信息源如教科書等)獲取信息,把知識轉換成內部可使用的表示形式,并將新的知識和原有知識有機地結合為一體。所以要求學生有一定程度的推理能力,但環境仍要做大量的工作。教師以某種形式提出和組織知識,以使學生擁有的知識可以不斷地增加。這種學習方法和人類社會的學校教學方式相似,學習的任務就是建立一個系統,使它能接受教導和建議,并有效地存貯和應用學到的知識。不少專家系統在建立知識庫時使用這種方法去實現知識獲取。示教學習的一個典型應用例是FOO程序。
3)演繹學習(Learningbydeduction)
學生所用的推理形式為演繹推理。推理從公理出發,經過邏輯變換推導出結論。這種推理是“保真”變換和特化(specialization)的過程,使學生在推理過程中可以獲取有用的知識。這種學習方法包含宏操作(macro-operation)學習、知識編輯和組塊(Chunking)技術。演繹推理的逆過程是歸納推理。
4)類比學習(Learningbyanalogy)
利用二個不同領域(源域、目標域)中的知識相似性,可以通過類比,從源域的知識(包括相似的特征和其它性質)推導出目標域的相應知識,從而實現學習。類比學習系統可以使一個已有的計算機應用系統轉變為適應于新的領域,來完成原先沒有設計的相類似的功能。類比學習需要比上述三種學習方式更多的推理。它一般要求先從知識源(源域)中檢索出可用的知識,再將其轉換成新的形式,用到新的狀況(目標域)中去。類比學習在人類科學技術發展史上起著重要作用,許多科學發現就是通過類比得到的。例如著名的盧瑟福類比就是通過將原子結構(目標域)同太陽系(源域)作類比,揭示了原子結構的奧秘。
5)基于解釋的學習(Explanation-basedlearning,EBL)
學生根據教師提供的目標概念、該概念的一個例子、領域理論及可操作準則,首先構造一個解釋來說明為什該例子滿足目標概念,然后將解釋推廣為目標概念的一個滿足可操作準則的充分條件。EBL已被廣泛應用于知識庫求精和改善系統的性能。著名的EBL系統有迪喬恩(G.DeJong)的GENESIS,米切爾(T.Mitchell)的LEXII和LEAP,以及明頓(S.Minton)等的PRODIGY。
6)歸納學習(Learningfrominduction)
歸納學習是由教師或環境提供某概念的一些實例或反例,讓學生通過歸納推理得出該概念的一般描述。這種學習的推理工作量遠多于示教學習和演繹學習,因為環境并不提供一般性概念描述(如公理)。從某種程度上說,歸納學習的推理量也比類比學習大,因為沒有一個類似的概念可以作為“源概念”加以取用。歸納學習是最基本的,發展也較為成熟的學習方法,在人工智能領域中已經得到廣泛的研究和應用。
基于所獲取知識的表示形式分類
學習系統獲取的知識可能有:行為規則、物理對象的描述、問題求解策略、各種分類及其它用于任務實現的知識類型。對于學習中獲取的知識,主要有以下一些表示形式:
1)代數表達式參數
學習的目標是調節一個固定函數形式的代數表達式參數或系數來達到一個理想的性能。
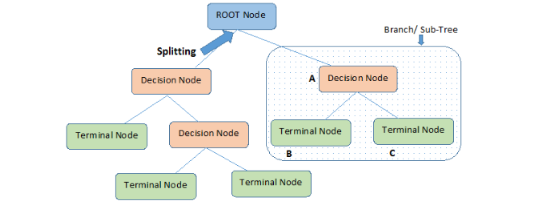
2)決策樹
用決策樹來劃分物體的類屬,樹中每一內部節點對應一個物體屬性,而每一邊對應于這些屬性的可選值,樹的葉節點則對應于物體的每個基本分類。
3)形式文法
在識別一個特定語言的學習中,通過對該語言的一系列表達式進行歸納,形成該語言的形式文法。
4)產生式規則
產生式規則表示為條件—動作對,已被極為廣泛地使用。學習系統中的學習行為主要是:生成、泛化、特化(Specialization)或合成產生式規則。
5)形式邏輯表達式
形式邏輯表達式的基本成分是命題、謂詞、變量、約束變量范圍的語句,及嵌入的邏輯表達式。
6)圖和網絡
有的系統采用圖匹配和圖轉換方案來有效地比較和索引知識。
7)框架和模式(schema)
每個框架包含一組槽,用于描述事物(概念和個體)的各個方面。
8)計算機程序和其它的過程編碼
獲取這種形式的知識,目的在于取得一種能實現特定過程的能力,而不是為了推斷該過程的內部結構。
9)神經網絡
這主要用在聯接學習中。學習所獲取的知識,最后歸納為一個神經網絡。
10)多種表示形式的組合
根據表示的精細程度,可將知識表示形式分為兩大類:泛化程度高的粗粒度符號表示、??泛化程度低的精粒度亞符號(sub-symbolic)表示。像決策樹、形式文法、產生式規則、形式邏輯表達式、框架和模式等屬于符號表示類;而代數表達式參數、圖和網絡、神經網絡等則屬亞符號表示類。
按應用領域分類
最主要的應用領域有:專家系統、認知模擬、規劃和問題求解、數據挖掘、網絡信息服務、圖象識別、故障診斷、自然語言理解、機器人和博弈等領域。從機器學習的執行部分所反映的任務類型上看,大部分的應用研究領域基本上集中于以下兩個范疇:分類和問題求解。(1)分類任務要求系統依據已知的分類知識對輸入的未知模式(該模式的描述)作分析,以確定輸入模式的類屬。相應的學習目標就是學習用于分類的準則(如分類規則)。(2)問題求解任務要求對于給定的目標狀態,??尋找一個將當前狀態轉換為目標狀態的動作序列;機器學習在這一領域的研究工作大部分集中于通過學習來獲取能提高問題求解效率的知識(如搜索控制知識,啟發式知識等)。
綜合分類
1)經驗性歸納學習(empiricalinductivelearning)
經驗性歸納學習采用一些數據密集的經驗方法(如版本空間法、ID3法,定律發現方法)對例子進行歸納學習。其例子和學習結果一般都采用屬性、謂詞、關系等符號表示。它相當于基于學習策略分類中的歸納學習,但扣除聯接學習、遺傳算法、加強學習的部分。
2)分析學習(analyticlearning)
分析學習方法是從一個或少數幾個實例出發,運用領域知識進行分析。其主要特征為:·推理策略主要是演繹,而非歸納;·使用過去的問題求解經驗(實例)指導新的問題求解,或產生能更有效地運用領域知識的搜索控制規則。分析學習的目標是改善系統的性能,而不是新的概念描述。分析學習包括應用解釋學習、演繹學習、多級結構組塊以及宏操作學習等技術。
3)類比學習
它相當于基于學習策略分類中的類比學習。在這一類型的學習中比較引人注目的研究是通過與過去經歷的具體事例作類比來學習,稱為基于范例的學習(case_basedlearning),或簡稱范例學習。
責任編輯人:CC



















 工商網監
工商網監
評論