 電子發燒友App
電子發燒友App


?
摘 要:?針對鋁型材表面缺陷快速準確檢測的需求,提出一種基于 YOLO 深度學習模型的鋁型材表面缺陷識別方法。對鋁型材數據集進行圖像增廣,解決原始數據集中圖像數量少且缺陷數據不均衡問題。建立基于 YOLO 的鋁型材表面缺陷識別模型,通過增加模型預測尺度,提高對微小缺陷的識別能力。對鋁型材缺陷數據集的目標框重新進行聚類分析,改進 YOLO 算法的模型參數。通過多尺度訓練方法,增強模型對不同尺度缺陷的適應性和識別精度。實驗結果表明,本文方法識別效果較改進前有較明顯提升,準確率均值 MAP 從 95.66% 提升至 97. 46% ,單幅圖像平均識別時間約 45 ms,可有效實現鋁型材表面缺陷的快速與準確識別。
鋁型材作為建筑和機械工業領域中重要的應用材料,其全行業的產量和消費量在世界范圍內逐年遞增。鋁型材在生產過程中,由于材料特性和加工工藝,不可避免存在表面缺陷,嚴重影響鋁型材的可靠性、安全性和可加工性。在實際生產中,對鋁型材表面缺陷進行準確快速識別,對保證鋁型材的質量至關重要。傳統的鋁型材表面缺陷識別方法包括渦流檢測法、超聲導波檢測及紅外檢測法等識別成本高、設備復雜,且不易實現缺陷識別過程的可視化。機器視覺檢測作為一種非接觸式在線自動檢測技術,具有非接觸、安全性高、識別效率高和工作時間長的特點,是實現表面缺陷準確與快速識別的有效手段。例如,胡繼文等針對帶有紋理的鋁型材圖像,提出基于 Gabor 濾波的紋理分析方法,實現鋁型材噴涂表面圖像快速分類,但該方法極易受到噴涂表面粗糙度的影響。劉澤等針對鋼軌表面典型的缺陷圖像設計動態閾值分割算法和缺陷區域提取算法,優先實現鋼軌缺陷的檢測。孫雪晨等設計了一種基于機器視覺的凸輪軸表面缺陷識別系統,能夠有效識別與定位 1 mm 以上的缺陷。
以上識別方法多采用傳統機器視覺算法,通過圖像形態學處理與特征提取進行缺陷識別,往往需要根據不同形態的缺陷特征,設計不同的特征提取與識別算法。鋁型材表面缺陷形態不規則、位置隨機且大小不一,采用傳統機器視覺缺陷識別方法進行鋁型材缺陷識別,難以同時滿足檢測精度與效率的要求。
近些年,隨著人工智能技術的發展,基于深度學習的目標識別方法在工業零件的缺陷識別中得到應用,并取得較好的效果。YOLO( You Only Look Once) 識別算法是目前深度學習領域執行速度較優算法,其將目標識別問題轉化為回
歸問題可以同時預測多個識別框的位置和類別,具備較高準確率和執行速度。在 YOLO 的基礎上,又出現 YOLOv2、YOLOv3改進算法,在識別速度和準確率上有所提高。其中,YOLOv3 對不同大小的多尺度目標識別效果較好,在齒輪、玻璃外觀等表面缺陷識別領域得到應用。深度學習的識別方法用于工業產品的缺陷識別,具有較好的泛化性和魯棒性。目前,鋁型材表面缺陷的識別方法多采用傳統的缺陷識別技術,將 YOLO 深度學習模型用于鋁型材識別,將有助于改善鋁型材表面缺陷識別的準確率與速度,提高鋁型材的產品質量與生產效率。針對鋁型材表面缺陷快速準確識別的需求,本文提出一種基于 YOLO 深度學習模型的鋁型材表面缺陷識別方法。首先,采用圖像增廣對原始圖像進行擴充,解決原始數據集中圖像數量少且缺陷數據不均衡問題,并構建 3 個不同分辨率的數據集,提高訓練過程中對不同尺度圖像的魯棒性。然后,建立鋁型材表面缺陷的 YOLO 識別模型,通過增加模型預測尺度,提高對微小缺陷的識別能力。最后,對鋁型材缺陷數據集的目標框重新進行聚類分析,并利用多尺度訓練的方法,在低分辨率數據集上進行預訓練,再利用中高分辨率數據集微調識別模型,以增強模型的適應性和準確率。
1 數據集構建
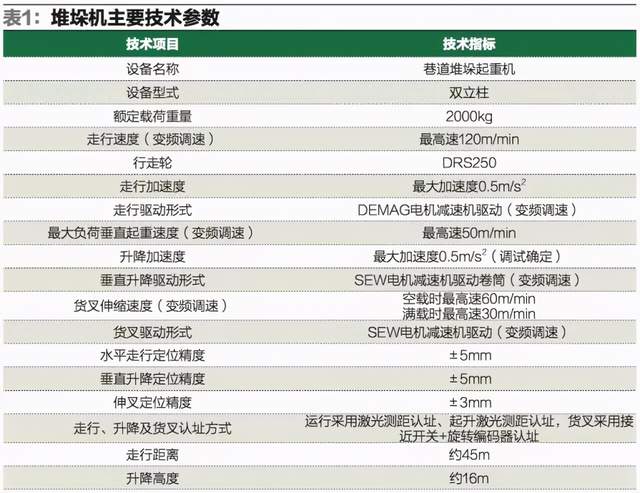
如圖 1 所示,鋁型材常見的缺陷有 4 種,分別是擦花、漏底、碰凹、凸粉。本文的鋁型材圖像數據集來源于江蘇省某鋁材公司。原始的鋁型材圖像數據集一共包括 342 張鋁型材缺陷圖像,缺陷圖像樣本較少,且部分缺陷占整個數據集比例過小、缺陷數據不均衡。深度學習在進行訓練時,如果數據集較少會導致模型出現過擬合的問題。為解決上述問題,本文對有缺陷的鋁型材圖像,采用圖像增廣來進行數據集擴充。圖像增廣技術是對原圖像數據進行一系列隨機對比度調整、旋轉等處理,產生相似但不同的訓練數據,以擴大訓練圖像集的規模,同時降低模型對某些特征的依賴,提高模型的泛化能力。

▲圖 1 常見的 4 種鋁型材缺陷
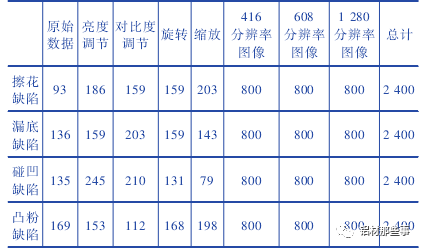
本文采用的圖像增廣方法包括調整對比度、亮度、旋轉和縮放,每張增廣后的圖片為原圖經過多種隨機組合變換得到。圖像增廣后每種缺陷類別的圖像的數量為 2 400 張,各缺陷比例為 1∶ 1∶ 1∶ 1。訓練集的圖像被轉換為 PASCAL-VOC格式,其長度分別調整為 416、608、1 280,并調整寬度以保持原始縱橫比。整個鋁型材圖像數據集的圖片為 9 600 張,如表 1 所示。與一般的圖像分類數據集不同,鋁型材數據集在進行深度學習訓練時,需提供圖片缺陷區域的坐標位置。本文中通過 labellmg 軟件來進行缺陷位置的標注。鋁型材數據集中擦花、漏底、碰凹、凸粉四種缺陷分別標注,并保存其路徑、標簽和缺陷坐標信息。
表 1 鋁型材缺陷數據集組成
2 識別方法
2. 1 鋁型材表面缺陷的 YOLO 識別模型
YOLOv3 作為一種基于回歸的目標識別算法,能夠實現多目標的快速、準確識別。YOLOv3 對輸入圖像的全局區域進行訓練,可加快訓練速度且能更好地區分目標和背景。先利用 Darknet-53主干網絡完成鋁型材表面缺陷特征提取,再采用目標框直接預測目標類別和位置。鋁型材表面缺陷形態不規則、位置隨機且大小不一,直接應用 YOLOv3 模型進行識別難以保證微小缺陷的精密識別。本文在深入分析 YOLOv3 模型特性的基礎上對其進行改進。將原有 3 尺度識別結構擴展為 4 尺度,提高對微小缺陷的識別能力; 通過重新聚類分析構建適合鋁型材表面缺陷的初始目標框,改進 YOLO 算法的模型參數; 采用多尺度訓練方式對訓練流程進行優化,以增強模型對不同尺度缺陷的適應性和識別精度,解決鋁型材表面缺陷識別困難、精度低等問題。
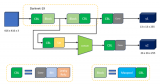
基于 YOLO 的鋁型材多尺度識別模型架構如圖 2 所示。在數據集構建后,以 Darknet-53 為主干網絡進行特征提取,并融合多尺度識別,實現鋁型材表面缺陷的有效識別。該網絡從訓練集和驗證集中快速提取鋁型材表面缺陷相應特征,并融合多尺度特征信息,同時得到缺陷預測框和類別,從而快速精確地識別出缺陷種類和位置。其中,訓練集用于擬合識別網絡,驗證集用于調整識別網絡的超參數以及對網絡性能進行評估。
鋁型材表面缺陷識別模型的工作流程如下: 首先,構建鋁型材表面缺陷圖像數據集,將缺陷圖像輸入識別模型進行訓練; 再根據預測邊界框及所屬類別的概率對缺陷進行多尺度預測; 最后通過損失函數不斷調整訓練參數,以得到改進
后識別模型的參數。
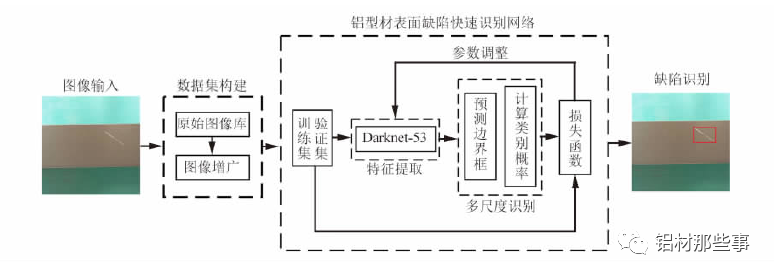
▲圖 2 鋁型材多尺度識別模型架構
2. 2 特征提取網絡
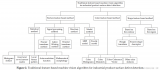
采用 Darknet-53 網絡作為圖像特征提取的主干網絡,其網絡結構如圖 3( a) 所示。整個網絡采用完整的卷積層,沒有池化層和固定輸出的連接層。Darknet-53 網絡結構借鑒殘差神經網絡 Res Net( ResidualNetwork),在其網絡中加入 5 個殘差塊( residual) 。每個殘差塊中包含不同數量的殘差單元,殘差單元由特征提取層與兩個 DBL( Darknetconv2d BN Leaky) 單元經過兩層卷積所構成,如圖 3( b) 所示。其中,殘差單元中的 DBL 單元也是YOLOv3 的基本構成單元,由卷積( Conv) 、批歸一化( BN) 和激活函數 Leaky Relu 共同構成,如圖 3( c) 所示。Darknet-53網絡中加入殘差單元,可以保證主網絡結構在不斷加深的情況下不會造成梯度消失或爆炸,以加強主網絡對圖像特征的提取效果,進而提高模型識別的準確率。
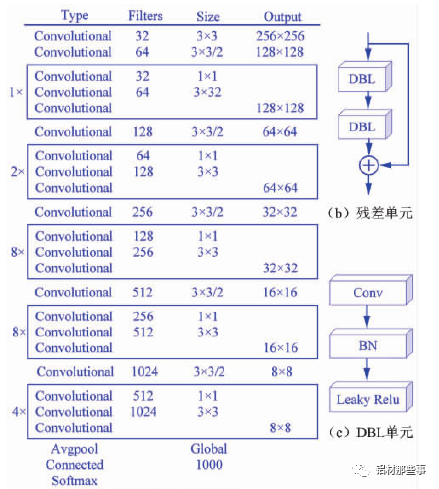
▲圖 3 Darknet-53 網絡結構
2. 3 多尺度識別的模型結構
對于大多數卷積神經網絡,通過特征提取網絡獲取圖像最終的特征圖后,直接在該特征圖上進行預測。這種方式僅能獲取圖像中單一尺度的語義信息,識別的尺度范圍有限。在鋁型材表面缺陷識別過程中,缺陷區域往往大小不一,且具有不同特征,因而需要利用不同尺度的識別網絡來適應多尺度目標。YOLOv3 通過多尺度預測的方式對不同尺寸的目標來識別,其結構如圖 4 所示。以本文的研究對象鋁型材為例,輸入的圖像經過 Dark-net-53 主干網絡時,共進行 5 次下采樣。每進行一次下采樣,鋁型材的特征圖就會變成原輸入圖像尺寸一半。經過 5 次即 32 倍下采樣后,生成尺度 1 的鋁型材特征圖。該尺度特征圖為 13 ×13 分辨率,通過卷積等操作后進行一次 2 倍上采樣,生成 26 ×26 分辨率的特征圖,將其與特征提取網絡中16 倍下采樣生成的 26 × 26 分辨率的特征圖進行張量連接。通過張量連接融合兩個圖像的特征信息,生成一個雙尺度融合的鋁型材特征圖( 尺度 2) 。以此類推,該尺度特征圖再次通過 2 倍上采樣,與 8 倍下采樣生成的 52 × 52 分辨率的特征圖進行張量連接,生成同為 52 × 52 分辨率且 3 尺度融合的鋁型材特征圖( 尺度 3) 。在鋁型材缺陷識別中,存在微小的缺陷區域,使用原YOLOv3 中多尺度預測的方法難以滿足微小缺陷精確識別的需求。針對該問題,本文對 YOLOv3 模型進行改進,將原有 3個尺度識別擴展為 4 個尺度,增加 104 × 104 分辨率的特征圖,見圖 4 新加結構。該尺度通過張量連接的方式,將 4 倍下采樣生成的 104 ×104 分辨率的特征圖與尺度 3 中 52 × 52分辨率的特征圖融合。通過多尺度特征融合方式,將不同分辨率的特征圖融合后單獨輸出且分別進行目標預測,以此提升小目標識別的精確度。融合后的尺度 4 包含之前各尺度信息的特征圖,可改善鋁型材表面微小缺陷的識別效果。

2. 4 目標框的聚類分析
目標框( anchor boxes) 是一組具有固定寬高比的數據集圖像初始候選框,其設定對圖像檢測的精度和處理速度有著重要影響。YOLO 算法對目標框的寬高比維度進行 K-menas聚類分析,并對神經網絡的訓練過程進行優化,即事先確定一組寬高比維度固定的矩形框作為選取目標包圍框時的參照物,通過預測目標框的偏移量取代直接預測坐標,以降低模型訓練的復雜度。在 YOLOv3 原模型中,目標框通過 Pas-cal VOC、COCO 等圖像標準數據集聚類得到,適用于自然場景中的目標。
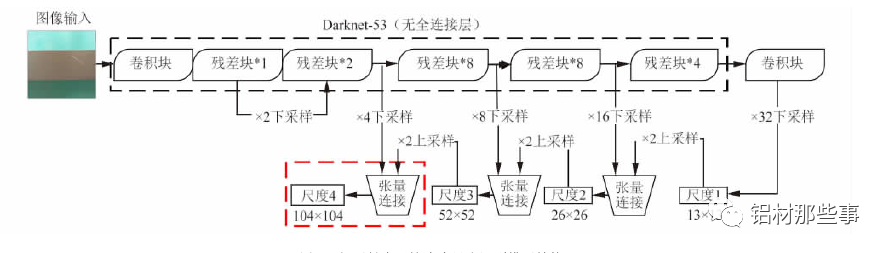
▲圖 4 鋁型材表面缺陷多尺度識別模型結構
本文要識別的目標為鋁型材表面缺陷,這些缺陷的特征與上述數據集中的目標完全不同,因此直接使用原算法中聚類分析過的目標框并不合理。基于上述考慮,為得到精準的鋁型材缺陷位置和類別信息,本文利用 K-menas 算法對數據集中目標框的寬高比維度重新進行聚類分析,得到適合鋁型材數據集的目標框。通過聚類分析主要是獲得更高的交并比 Io U( Averange intersection over union) 。Io U 代表預測的目標框與真實目標框的重疊率,其值越大表示聚類效果越好。因此,本文采用 Io U 取代 K-means 方法中的歐氏距離,用 Io U定義的距離 D 可表示為
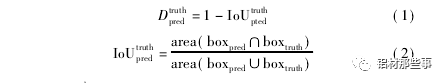
式中: Io Utruthpted為交并比,area( boxpred∩boxtruth表示預測目標框和真實目標框的交集部分面積,area( boxpred∪boxtruth表示預測目標框和真實目標框的并集部分面積。本文設定 K-means 聚類分析中簇的個數 K =1,2,…,20,聚類分析結果如圖 5 所示。可以看出,隨著 K 個數的增加,Io U 的數值不斷增加,增長率不斷減小。一般來說,最佳 K 值選取點為曲線斜率最大點之后的點。一方面,較少數量的 K值可以減少模型計算量,進一步加快損失函數的收斂。另一方面,也可以去除由較多目標框帶來的識別誤差。從圖中可以看出,K =9 時為最優點,其對應的目標框分別為( 25,33) ,( 26,101) ,( 50,555) ,( 62,235) ,( 80,587) ,( 90,37) ,( 133,325) ,( 257,86) ,( 554,58) 。
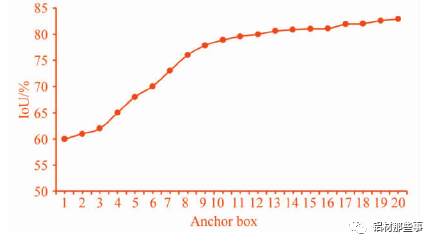
▲圖 5 聚類分析曲線圖
3 實驗與分析
3. 1 模型訓練
本文實驗平臺如表 2 所示。在模型訓練前,基本參數設置如下: 動量( momentum) 設為 0. 9,衰減系數( decay) 設為0. 000 5,初始學習率( learning rate) 為 0. 000 1,學習率調整策略為 steps,最大迭代次數為 10 000 次。
表 2 實驗平臺

為提高鋁型材缺陷識別的準確率,本文通過多尺度訓練的方法,對其訓練流程進行改進,使模型逐步適應不同分辨率的圖像,以更好適應鋁型材圖像中不同尺度的缺陷特征。
具體流程如下:
1) 采用 312 × 312 分辨率的鋁型材圖像對模型進行預訓練,獲得初始的預訓練權重;
2) 利用 416 × 416 分辨率的鋁型 材圖 像 對 模型 進 行 微調,使得模型能逐漸適應中等分辨率的缺陷特征;
3) 輸入 608 × 608 分辨率的鋁型材圖像進行訓練,自主調整每層權重來適應高分辨率圖像輸入,更好適應鋁型材圖像中不同尺度的缺陷特征,提高模型尺度不變性和魯棒性。在訓練過程中,損失函數 Loss 的定義為
Loss = lxyδ( x,y) + lwhδ( w,h) + lconfδ( conf) + lcδ( c) ( 3)
式中: δ( x,y) 為預測目標框中心坐標( x,y) 的誤差函數,δ( w,h) 為預測目標框寬高比維度的誤差函數。δ( conf) 為置信度 Confidence 的誤差函數,δ( c) 為類別 c 的誤差函數。lxy、lwh、lconf、lc分別為誤差權重系數。
圖 6 為本文模型在訓練時的損失曲線圖。本文模型隨著迭代次數增加,誤差損失經過震蕩呈下降趨勢,當訓練迭代批次達 8 000 次后損失基本趨于平穩。
3. 2 缺陷識別效果
利用鋁型材測試集圖像對訓練后的鋁型材 YOLO 模型進行實驗,以驗證本文方法的有效性。評價模型有效性的相關指標包括平均準確率 AP、平均準確率均值 MAP和平均識別時間 t。AP 用于衡量模型在單個類別上的識別性能; MAP用于衡量模型在所有類別上的平均識別性能; 識別時間為模型平均處理每張圖像所需時間,其單位為 ms。和 MAP用公式表示為
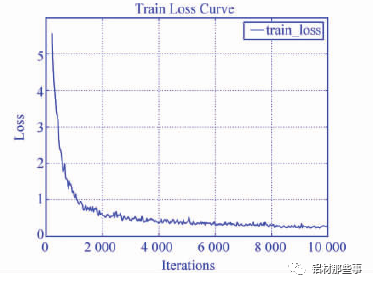
▲圖 6 損失曲線圖
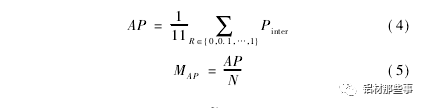
式中: PinterP( R) 為召回率滿足 R~≥R 時的準確率的最大值,N為模型中待識別類別的個數。召回率表示正確識別的目標個數占總目標數百分比,準確率表示正確識別的目標個數占總識別目標個數百分比。召回率 R、準確率 P 和 PinterP( R) 可用公式表示為
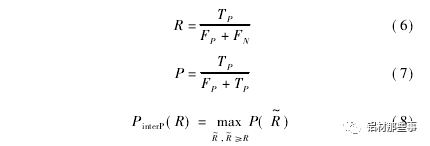
式中: TP為真正例,表示正樣本被預測為正樣本的數量; FP為假正例,表示負樣本被預測為正樣本的數量; FN為假負例,表示正樣本被預測為負樣本的數量; TN為真負例,表示負樣本被預測為負樣本的數量。為了定量分析本文方法實驗效果,將本文方法與 YOLO、YOLOv2、YOLOv3、YOLOv3-tiny 及文獻基于圖像特征的傳統機器視覺方法進行對比。表 3 所示為不同方法的實驗結果。可以看出,采用 YOLO 系列原模型,對于擦花缺陷,僅YOLOv3 的 AP 值達 到 95. 25% ,其 他 方法的 AP 值 都 較 低,YOLO 的 AP 值則低于 70% 。在凸粉和漏底缺陷的測試結果中,本文方法的 AP 最高,分別達到 95. 75% 與 96. 86% 。碰凹缺陷因特征明顯,其 AP 值在對比方法中都較高,尤其是本文方法 AP 達到 100% 。
表 3 不同方法性能對比
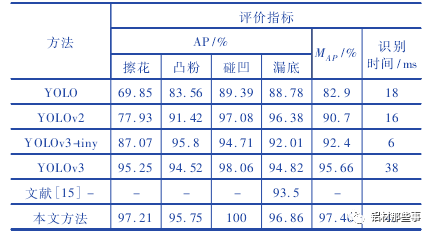
相較于 YOLOv3、YOLOv2,本文方法中的網絡模型更復雜,使得平均識別時間分別增加 7 ms、29 ms,但 MAP值分別提升 1. 8% 、6. 76% 。YOLOv3-tiny 模型結構簡單,檢測速度雖較快,但檢測精度明顯降低,其 MAP比本文方法低 5. 06% 和 3. 24% 。本文方法的多項性能指標相較于改進前均有顯著提升,尤其是 MAP達到 97. 46% 。與 YOLO 相比,本文方法 MAP提高14. 56% 。與文獻基于圖像特征處理的傳統機器視覺方法相比,本文方法的 MAP提升 3. 96% 。圖 7 所示為不同 YO-LO 系列方法及本文模型的缺陷識別效果圖,圖 7 ( a) - ( f)分別為原圖、本文方法、YOLOv3、YOLOv3tiny、YOLOv2、YOLO的識別效果圖。YOLOv3-tiny 模型結構較簡單,對于漏底缺陷 AP 雖然較高,但仍存在漏檢。YOLOv2 和 YOLO 在識別漏底和凸粉缺陷時也出現漏檢情況,由于缺少多尺度檢測結構,難以有效檢測不明顯的缺陷特征,從側面驗證了增加尺度預測結構對提高模型識別精度的重要性。相比之下,本文方法對測試圖像中的 8 個擦花缺陷全部識別成功,優于其他方法的檢測效果。在識別時間方面,本文方法相較于其他方法,單幅圖片的識別時間略有增加,達到 45 ms,但仍能滿足缺陷檢測的實時性要求。可以看出,本文方法整體性能表現最佳,可以同時滿足識別精度與速度的需求。

▲圖 7 不同方法對 4 種缺陷的識別效果圖
綜上所述,本文方法通過增加模型識別尺度,可精確識別鋁型材微小表面缺陷的類別和位置,提升識別精度和定位精度。通過聚類分析重新構建適合鋁型材表面缺陷的初始目標框,利用多尺度訓練優化模型參數,可更好適應鋁型材圖像中不同尺度的缺陷特征。本文方法對鋁型材表面缺陷具有較好的識別效果,缺陷識別準確率達到 97. 46% ,平均耗時為 45 ms,可同時滿足識別精度和速度要求。
4 結論
在鋁型材缺陷識別中,缺陷形態特征的復雜多變會嚴重影響模型識別準確率和效果。針對鋁型材缺陷快速準確識別問題,本文提出一種基于 YOLO 的鋁型材表面缺陷識別方法。對鋁型材數據集進行圖像增廣,解決原始數據集中圖像數量少且缺陷特征不均衡問題。建立鋁型材表面缺陷識別的 YOLO 模型,并通過增加模型預測尺度,提高對微小缺陷的識別能力。對鋁型材數據集目標框重新進行聚類分析,并采用多尺度訓練的方法,優化缺陷識別效果。本文方法的缺陷識別準確率達到 97. 46% ,優于其他 5 種對比算法。本文提出鋁型材表面缺陷快速識別方法,缺陷識別準確率高、實時性好,可用于鋁型材表面缺陷的快速準確識別,提高鋁型材生產的自動化水平與檢測效率。
編輯:黃飛
?

















 工商網監
工商網監
評論