 電子發燒友App
電子發燒友App


背景
在深度學習火爆的今天,大規模數據下訓練的大規模模型在線上任務中日益常見。隨著大模型效果的提升,隨之帶來了一些使用上的不便。通常情況下,大模型需要基于大量語料、文本訓練,迭代周期長。且對于特定場景下詞語在訓練語料中出現次數不多,常常擬合不好。本文介紹的是關鍵詞即特定場景語料,在序列到序列任務中通過構建狀態轉移自動機的方法改善最終效果的方案。
生成模型即生成模型解碼
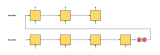
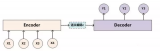
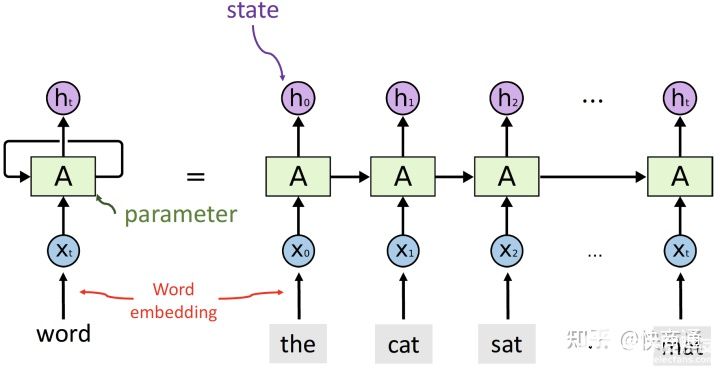
序列到序列模型常用于機器翻譯、語音識別等任務。其架構提出于 2014 年 [1],包含兩個核心組件:編碼器、解碼器。本文中略去這種模型的訓練過程,對該模型在使用過程中解碼這一過程進行介紹
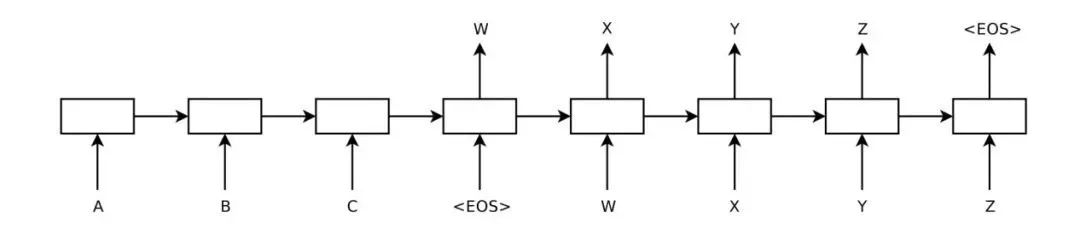
通過這個圖我們不難發現,每個時刻的生成結果不僅于輸入時刻序列有關,還與輸出序列相關,一個簡單的想法,將每個時刻置信度最高的結果存下來,做為下一個時刻輸入,但這樣很容易產生問題:在一個時刻缺乏全局視野,即某一個時刻最優不代表是全局最優的結果。而將所有結果都記錄下來,這將會是指數級增長的數據量。因此一種 beam search 的方法被提出用來解決這一問題,我們用一個形象的例子來講述 beam search 這一過程。
假設我們得到了一串拼音序列:
| y | i | d | a | l | i | zh | i |
我們如何知道這個拼音序列代表什么意思呢?
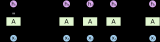
如下圖所示,我們展現了一個通過簡單概率模型產生的文本,在第零個時刻的 5 個候選(為了展示方便,這里省略了編號為④的候選),在第一個時刻各產生了三個延伸在這 15 個候選中,通過語言模型概率選取了 top5 保留,剩余的舍棄掉,以達到縮減搜索空間的目的。通過這樣的方法,每一個時刻不保留全部結果只保留 top N,最終將指數級增長的搜索空間變為平方級增長的搜索空間。
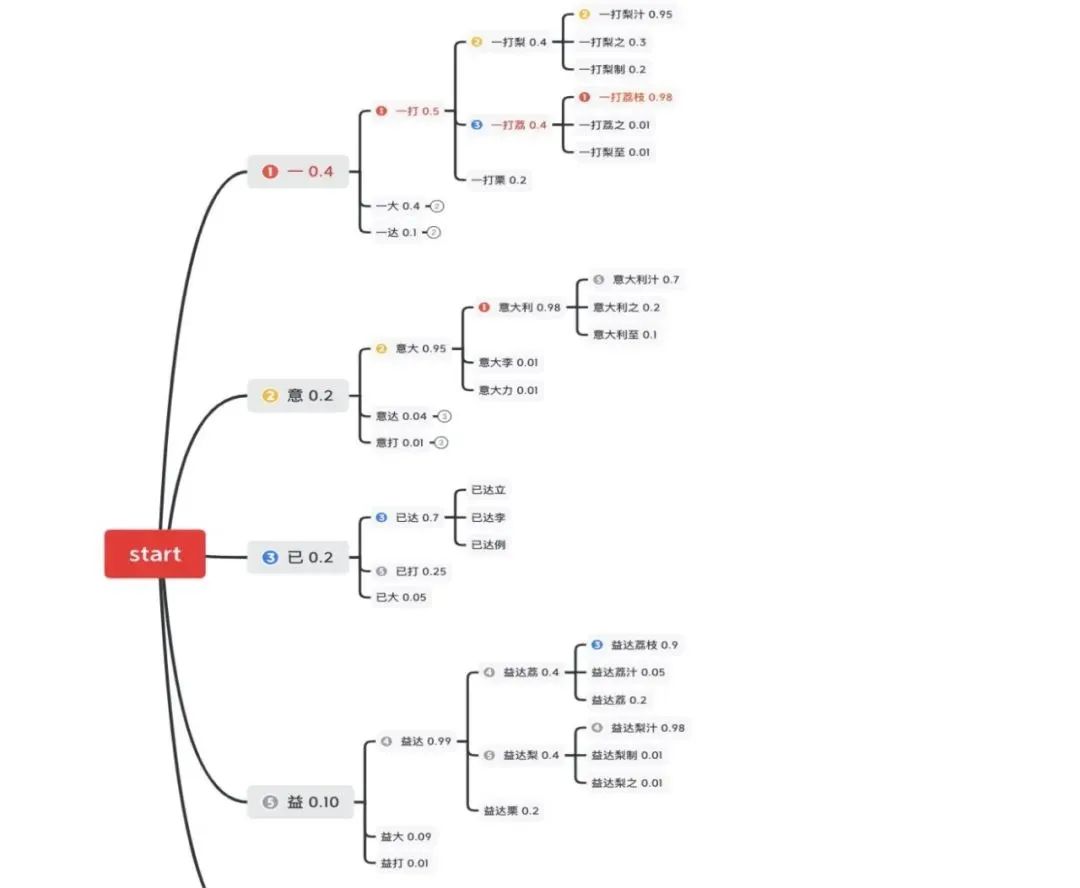
傳統解碼應用問題與改進
這種方法與全部狀態保存的方案相比犧牲了準確度以換取時間,具有一定局限性。對于通常情況,每個時刻 top N 能覆蓋當前時刻 90% 以上的情況,但是這種方法在面對關鍵詞檢測、風控詞語檢測等任務會產生兩個問題:
1、待檢測關鍵字在日常語料中較少出現,傳統 beam search 非常容易漏召回。
2、時效性強,經常有實時插入的新檢測詞語,要即時生效。
對于第一個問題,一種直觀的思想是通過標注數據,弱標注數據等重新訓練模型,但這顯然迭代周期長且迭代預期不穩定。
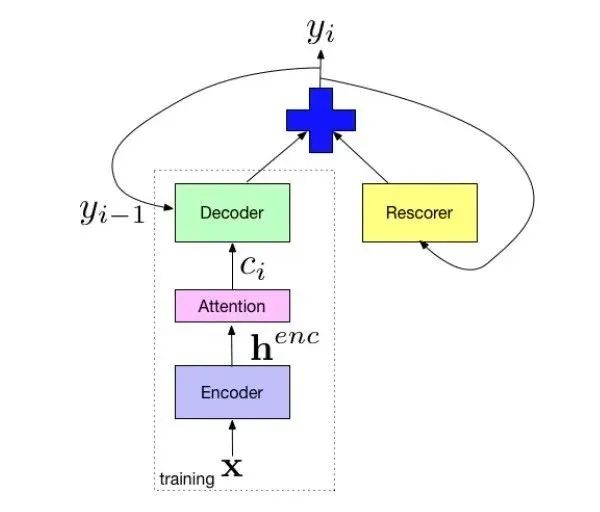
Google 在 2018 年論文中 [2],提出一種設計方案調整 beam search 的結果,即不重新訓練模型,僅在解碼時通過追加模型進行重新打分來改善對小眾語料的擬合。
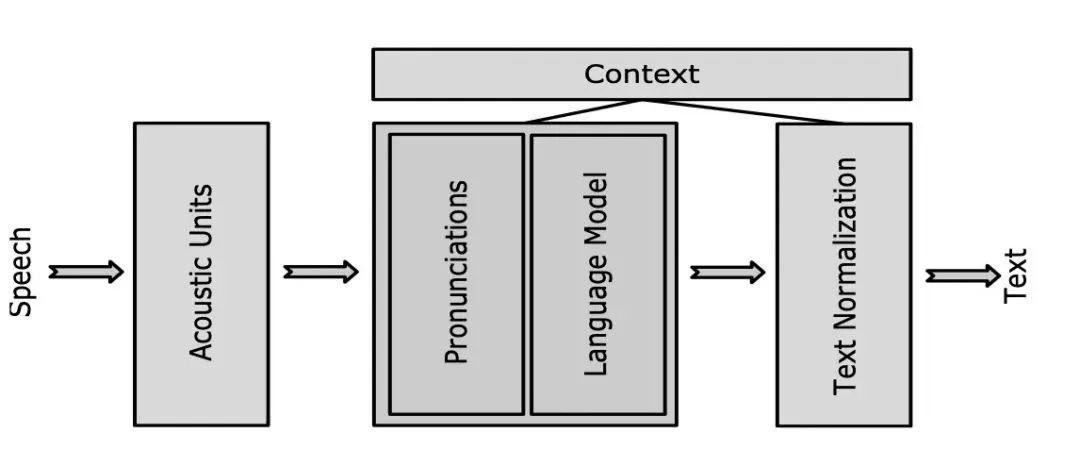
以上圖中識別系統設計為例,除去傳統聲學識別模塊還增加了上下文模塊,這個模塊舉例了幾個功能,包括標點,語言模型打分,文本歸一。其中語言模型的使用如下圖,用 beam search 對中間結果進行追加打分,更新 beam search 中 top N,并將當前結果作為下一時刻解碼的輸入。這種方式的優點是,在不更新語音識別模型的情況下,也可以通過添加不同語境的語言模型影響 beam search 過程中 top N 選取,從而達到改善結果的目的。缺點便是顯著增加了計算量;盡管語言模型計算量常常不高,但 beam search 過程中每個候選結果都要多次經過語言模型,次數過多,耗時上升比較明顯。
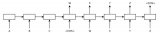
為了改進計算效率,經典 wfst 解碼 [3] 方案重新在 seq2seq 模型中使用 [4],這種解碼方案注意到了我們是在一個序列過程中重打分,不需在每一個時刻對從開始至當前所有文本進行重新計算,我們將語言模型生成新的概率轉移自動機 [5],解碼時,維護當前 beam search 過程中 top N 于圖 2 狀態。如下圖為 cat(音標:k?t) 這個單詞的狀態轉移圖,當聲學識別模塊產出 c 對應的 k 的音其轉移到狀態 1,而當 a 對應的?產生時,不在需要從狀態 0 計算 k ?一起的概率,而是計算當前狀態 1 的后繼狀態中是否有?。沒有則計算回退到初始狀態的概率。這樣對于在序列生成中的計算,只需要記錄其處于圖中狀態,在新的識別結果產生時對當前狀態計算可行的轉移狀態即可。與普通語言模型相比,相當于省去了從狀態 0 至當前狀態的重復計算,復雜度大為降低。
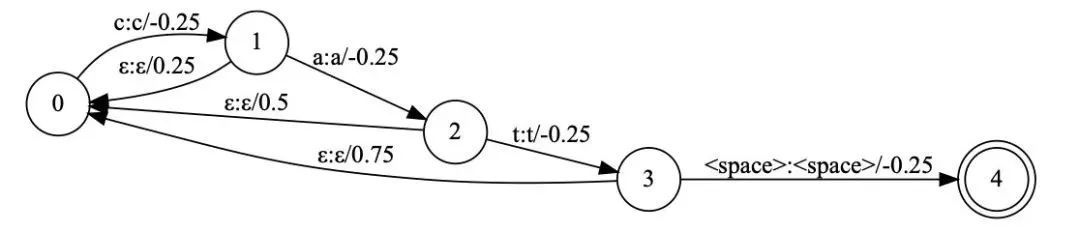
這種淺融合的方案很好的解決了訓練語料不均衡的問題,缺點是不能實時對圖進行修改,且缺乏對特定詞的加權,為此我們引入了前綴自動機來對這一過程改進。
基于前綴自動機的解碼加權方案
前綴自動機,是一種經典算法,常應用于多模式串匹配。如果我們有一個字典,對于輸入文本想檢測是否命中字典中詞語,這便是一個多模式串匹配任務。對于這類任務,一個顯然的方案是遍歷全部字典,但這樣復雜度太高。
對此我們開始優化,一種方式是優化字典結構,即字典中字符有公共部分的比如 teach 和 teacher 都在字典中,那如果 teach 不匹配了,teacher 這個單詞也不用匹配了。將順序的字典變為前綴樹的存儲方式。
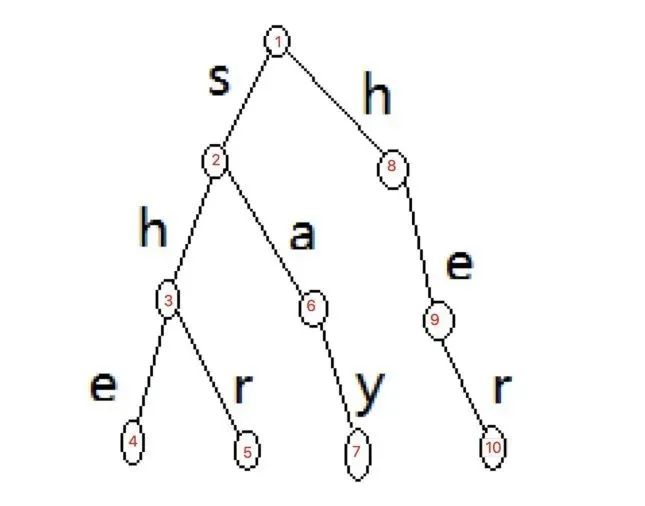
與此同時,我們繼續在這種情況下優化,如果一個詞前綴為另一個詞的子串,如上圖中 she 和 her,檢測字符串 sher 中含有前綴樹中多個詞,當 she 在狀態 4 匹配成功后我們知道 he 也是待匹配串中的,因此我們不需要跳回狀態 1,而是直接跳轉至狀態 9,從 r 開始匹配即可。這便是前綴自動機的核心思想。
這種跳轉關系構建方法是一種遞歸過程。用一句話來概括,一層一層的構建,如果我的父節點的跳轉狀態的子節點中有與我相同的,那就是我的跳轉狀態,否則我的跳轉狀態就是根結點。按照這個思路,我們將上圖的點按遍歷順序重新標號以便于理解
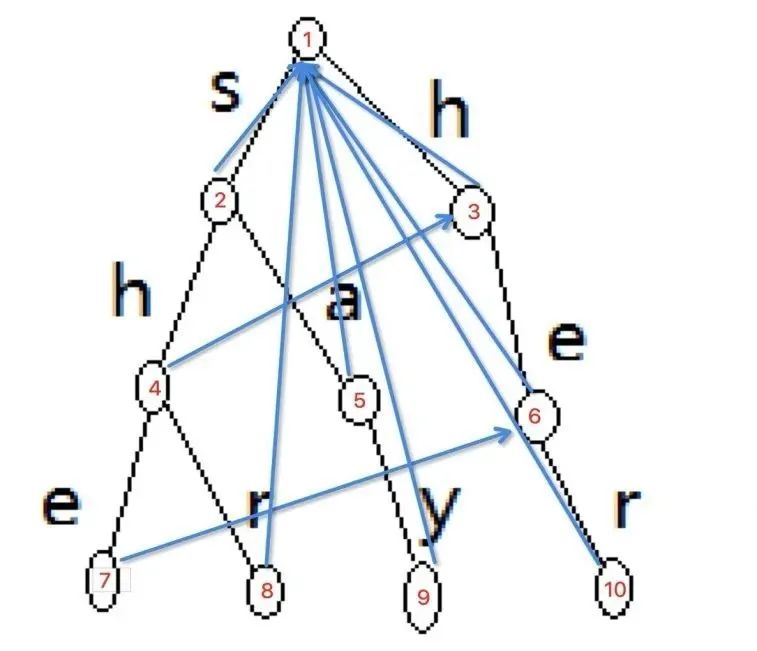
有了這個前綴轉移關系,我們便能高效的處理熱詞構建及查詢,一個帶有前綴自動機的解碼流程如下:

即對于每個 beam search 過程我們不僅維護 beam search 過程中結果,同時維護其處于前綴自動機狀態;此狀態便于維護,僅存儲狀態指針即可。從性能上看,執行時的額外計算量及內存使用量都可以認為是常數增加。
前綴自動機實時增加新詞方案
前一段中我們介紹了通過前綴自動機的解碼方案,但這一過程依然不能很好解決“實時”這一要求,如果我希望實時向解碼過程中添加熱詞,需要怎么改進?
回顧上一節的內容,我們了解到前綴自動機構建應分為兩步,即前綴樹的構建與狀態轉移的構建。其中,前綴樹是算法正確性的保證,而狀態轉移可以大幅優化時間。同時,狀態轉移需要層次遍歷整棵前綴樹,這意味轉移狀態的構建不能隨前綴樹形態更改而自動更改,而必須全量重新構建。
當我們插入一個新詞,由于前綴樹的特性,可以在字符長度的復雜度將該詞插入前綴樹,但是構建新的轉移狀態需要遍歷所有節點,如果每次插入新詞都要重新訪問整棵樹全部節點,這種復雜度是難以接受的。比較起來,損失一些轉移狀態等價于將部分詞的查詢復雜度變大,對比遍歷全部詞典的復雜度這種損失是可以接受的。
根據上述想法,我們將整體查詢變為兩棵樹,一棵為帶轉移狀態的前綴自動機,另一棵為普通字典樹,當新詞插入時我們在普通字典樹插入,當普通字典樹規模大于一規定閾值后我們將他們合并,并在合并后的樹上構建轉移狀態。對于一次查詢,復雜度從詞長變為小字典樹規模,但能夠節省構建轉移狀態遍歷全文的時間。
方案效果
我在語音識別系統中應用了這種解碼方案,并通過兩方面指標評估該模塊效果,一方面通過標注帶關鍵詞語音數據集,評估關鍵詞準召。在下表中,beam search 代表普通方案,ac automation 代表前綴自動機加權解碼方案,發現在識別結果中對關鍵詞召回相對提升 4.6%。另外,我們對比在普通語音識別數據集上字錯誤率(CER),由于對特殊詞提升了權重使整體準確率有一定的下降,但整體損失可以接受,低于對關鍵詞召回的收益。

總結?
本文主要基于 seq2seq 類模型,通過追加狀態轉移自動機來減少模型在面對專有領域語料時的識別準確率;同時可以使語料實時生效,并將該工作的實時性流程構建方法加以介紹。對于語音轉錄文本中的關鍵詞檢測,常常局限于語音模型不能實時調整,很難識別出新詞,通過這種方案可以做到秒級別新詞添加,顯著改變這一困擾。
參考文獻
[1] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems 27 (2014).
[2] Zhao, Ding, et al. "Shallow-Fusion End-to-End Contextual Biasing." Interspeech. 2019.
[3] Hori T, Hori C, Minami Y, et al. Efficient WFST-based one-pass decoding with on-the-fly hypothesis rescoring in extremely large vocabulary continuous speech recognition[J]. IEEE Transactions on audio, speech, and language processing, 2007, 15(4): 1352-1365.
[4] Williams I, Kannan A, Aleksic P S, et al. Contextual Speech Recognition in End-to-end Neural Network Systems Using Beam Search[C]//Interspeech. 2018: 2227-2231.
[5] Hori T, Nakamura A. Speech recognition algorithms using weighted finite-state transducers[J]. Synthesis Lectures on Speech and Audio Processing, 2013, 9(1): 1-162.
[6]https://blog.csdn.net/weixin_53360179/article/details/119718426
編輯:黃飛
?











 工商網監
工商網監
評論