 電子發燒友App
電子發燒友App


之前在做光照對于高層視覺任務的影響的相關工作,看了不少基于深度學習的低光照增強(low-light enhancement)的文章[3,4,5,7,8,9,10],于是決定簡單梳理一下。
光照估計(illumination estimation)和低光照增強(low-light enhancement)的區別:光照估計是一個專門的底層視覺任務(例如[1,2,6]),它的輸出結果可以被用到其它任務中,例如圖像增強、圖像恢復(處理色差,白平衡)。而低光照增強是針對照明不足的圖像存在的低亮度、低對比度、噪聲、偽影等問題進行處理,提升視覺質量。值得一提的是,低光照增強方法有兩種常見的模式,一種是直接end-to-end訓練,另一種則包含了光照估計。
LLNet: A deep autoencoder approach to natural low-light image enhancement
2017 Pattern Recognition
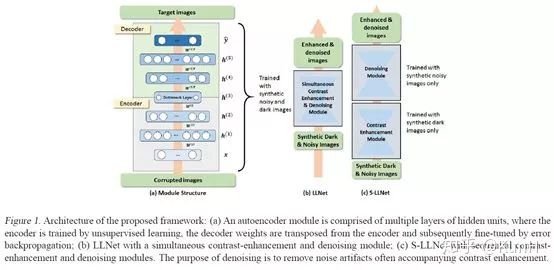
這篇文章應該是比較早的用深度學習方法完成低光照增強任務的文章,它證明了基于合成數據訓練的堆疊稀疏去噪自編碼器能夠對的低光照有噪聲圖像進行增強和去噪。模型訓練基于圖像塊(patch),采用sparsity regularized reconstruction loss作為損失函數。
主要貢獻如下:
(1)我們提出了一種訓練數據生成方法(即伽馬校正和添加高斯噪聲)來模擬低光環境。
(2)探索了兩種類型的網絡結構:(a) LLNet,同時學習對比度增強和去噪;(b) S-LLNet,使用兩個模塊分階段執行對比度增強和去噪。
(3)在真實拍攝到的低光照圖像上進行了實驗,證明了用合成數據訓練的模型的有效性。
(4)可視化了網絡權值,提供了關于學習到的特征的insights。
MSR-net:Low-light Image Enhancement Using Deep Convolutional Network
2017 arXiv
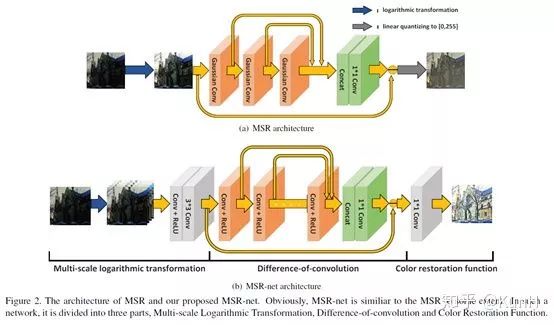
這篇文章引入了CNN,它提了一個有趣的觀點,傳統的multi-scale Retinex(MSR)方法可以看作是有著不同高斯卷積核的前饋卷積神經網絡,并進行了詳細論證。
接著,仿照MSR的流程,他們提出了MSR-net,直接學習暗圖像到亮圖像的端到端映射。MSR-net包括三個模塊:多尺度對數變換->卷積差分->顏色恢復,上面的結構圖畫得非常清楚了。
訓練數據采用的是用PS調整過的高質量圖像和對應的合成低光照圖像(隨機減少亮度、對比度,伽馬校正)。損失函數為帶正則項的誤差矩陣的F-范數平方,即誤差平方和。
Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images
2018 TIP
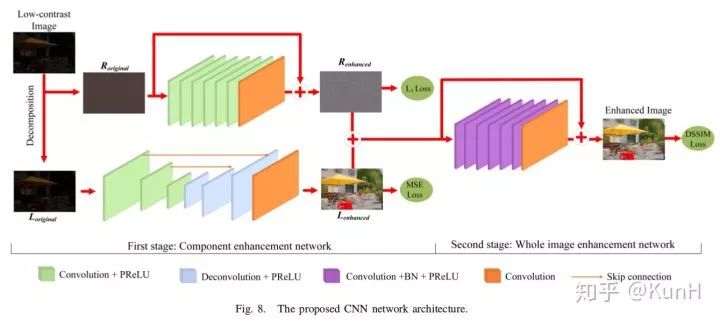
這篇文章其實主要關注單圖像對比度增強(SICE),針對的是欠曝光和過曝光情形下的低對比度問題。其主要貢獻如下:
(1)構建了一個多曝光圖像數據集,包括了不同曝光度的低對比度圖像以及對應的高質量參考圖像。
(2)提出了一個兩階段的增強模型,如上圖所示。第一階段先用加權最小二乘(WLE)濾波方法將原圖像分解為低頻成分和高頻成分,然后對兩種成分分別進行增強;第二階段對增強后的低頻和高頻成分融合,然后再次增強,輸出結果。
對于為什么要設計兩階段結構,文章中是這樣解釋的:單階段CNN的增強結果并不令人滿意,且存在色偏現象,這可能是因為單階段CNN難以平衡圖像的平滑成分與紋理成分的增強效果。
值得一提的是,模型第一階段的Decomposition步驟采用的是傳統方法,而后面介紹的Retinex-Net使用CNN實現了。
Deep Retinex Decomposition for Low-Light Enhancement
2018 BMVC
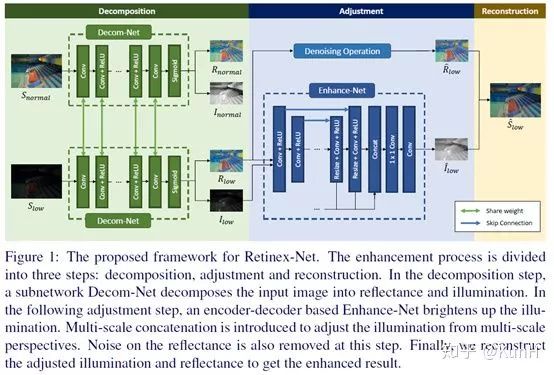
這篇文章是我前后讀過許多遍,比較值得介紹。受Retinex理論的啟發,它采用了兩階段式的先分解后增強的步驟,完全采用CNN實現。對于Decom-Net的訓練,引入了反射圖一致性約束(consistency of reflectance)和光照圖平滑性約束(smoothness of illumination),非常容易復現,實驗效果也不錯。
主要貢獻如下:
(1)構建了paired的低光照/正常光照數據集LOL dataset,應該也是第一個在真實場景下采集的paired dataset.該數據集分為兩部分:真實場景的圖像數據是通過改變相機感光度和曝光時間得到的;合成的圖像數據是用Adobe Lightroom接口調節得到的,并且調節后圖像的Y通道直方圖必須盡可能地接近真實低光照場景。
(2)提出了Retinex-Net,它分為兩個子網絡:Decom-Net能夠對圖像進行解耦,得到光照圖和反射圖;Enhance-Net對前面得到的光照圖進行增強,增強后的光照圖和原來的反射圖相乘就得到了增強結果。另外,考慮到噪聲問題,采用一種聯合去噪和增強的策略,去噪方法采用BM3D。
(3)提出一個structure-aware total variation constraint,就是用反射圖梯度作為權值對TV loss進行加權,從而在保證平滑約束的同時不破壞紋理細節和邊界信息。
MBLLEN: Low-light Image/Video Enhancement Using CNNs
2018 BMVC
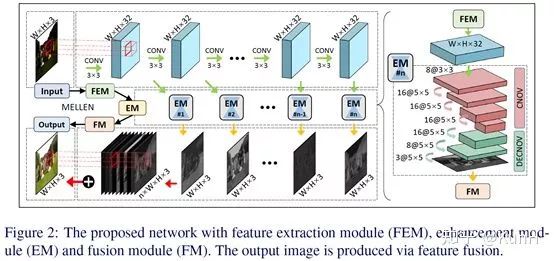
這篇文章的核心思想是,網絡中不同層次的特征的提取和融合。此外,該文的另一個亮點是針對視頻的低光照增強網絡,和一幀一幀處理的直接做法不同,它們使用3D卷積對網絡進行了改進,有效提升了性能。
補充說明一下,視頻的低光照增強會存在的一種負面情況,閃爍(flickering),即幀與幀之間可能存在不符合預期的亮度跳變。這一問題可以用AB(avr)指標(即平均亮度方差)來度量。
網絡結構:包括特征提取模塊FEM、增強模塊EM和融合模塊FM。FEM是有10層卷積的單流向網絡,每層的輸出都會被輸入到各個EM子模塊中分別提取層次特征。最終這些層次特征被拼接到一起并通過1x1卷積融合得到最終結果。為了用于視頻增強,還需要對網絡進行修改,具體可參考原文。
損失函數:本文不采用常規的MSE或者MAE損失,而是提了一個新的損失函數,包括三個部分,即結構損失、內容損失和區域損失。結構損失采用SSIM和MS-SSIM度量相結合的形式;內容損失,就是VGG提取的特征應該盡可能相似;區域損失令網絡更關注于圖像中低光照的區域。
Learning to See in the Dark
2018 CVPR

傳統成像系統的pipeline
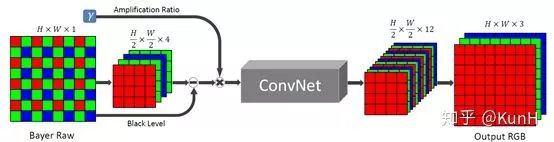
提出的新成像系統
這篇文章主要關注于極端低光條件和短時間曝光條件下的圖像成像系統,它用卷積神經網絡去完成Raw圖像到RGB圖像的處理,實驗效果非常驚艷。
網絡結構基于全卷積網絡FCN,直接通過端到端訓練,損失函數采用L1 loss。此外,文章提出了See-in-the-Dark數據集,由短曝光圖像及對應的長曝光參考圖像組成。
Kindling the Darkness: A Practical Low-light Image Enhancer
2019 arXiv
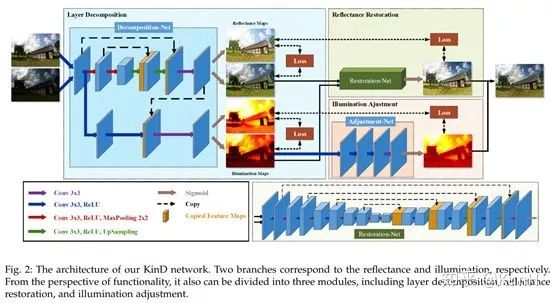
這篇文章在今年5月份掛到了arXiv上,干貨挺多,據稱是state-of-the-art。它提出了低光照增強任務存在的三個難點:
(1) 如何有效的從單張圖像中估計出光照圖成分,并且可以靈活調整光照level?
(2) 在提升圖像亮度后,如何移除諸如噪聲和顏色失真之類的退化?
(3) 在沒有ground-truth的情況下,樣本數目有限的情況下,如何訓練模型?
這篇文章的增強思路還是沿用了Retinex-Net的decomposition->enhance的兩階段方式,網絡總共分為三個模塊:Decomposition-Net、Restoration-Net和Adjustment-Net,分別執行圖像分解、反射圖恢復、光照圖調整。一些創新點如下:
(a)對于Decomposition-Net,其損失函數除了沿用Retinex-Net的重構損失和反射圖一致損失外,針對光照圖的區域平滑性和相互一致性,還增加了兩個新的損失函數。
(b)對于Restoration-Net,考慮到了低光照情況下反射圖往往存在著退化效應,因此使用了良好光照情況下的反射圖作為參考。反射圖中的退化效應的分布很復雜,高度依賴于光照分布,因此引入光照圖信息。
(c)對于Adjustment-Net,實現了一個能夠連續調節光照強度的機制(將增強比率作為特征圖和光照圖合并后作為輸入)。通過和伽馬校正進行對比,證明它們的調節方法更符合實際情況。
參考文獻
[1] Shi, W., Loy, C. C., & Tang, X. (2016). Deep Specialized Network for Illuminant Estimation.?ECCV,?9908, 371–387.?doi.org/10.1007/978-3-3
[2] Guo, X., Li, Y., & Ling, H. (2017). LIME: Low-light image enhancement via illumination map estimation.?IEEE Transactions on Image Processing,?26(2), 982–993.?doi.org/10.1109/TIP.201
[3] Lore, K. G., Akintayo, A., & Sarkar, S. (2017). LLNet: A deep autoencoder approach to natural low-light image enhancement.?Pattern Recognition,?61, 650–662.?doi.org/10.1016/j.patco
[4] Shen, L., Yue, Z., Feng, F., Chen, Q., Liu, S., & Ma, J. (2017). MSR-net:Low-light Image Enhancement Using Deep Convolutional Network.?ArXiv. Retrieved from?arxiv.org/abs/1711.0248
[5] Cai, J., Gu, S., & Zhang, L. (2018). Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images.?IEEE Transactions on Image Processing,?1(c), 1–14. Retrieved from?www4.comp.polyu.edu.hk/
[6] Gao, Y., Hu, H. M., Li, B., & Guo, Q. (2018). Naturalness preserved nonuniform illumination estimation for image enhancement based on retinex.?IEEE Transactions on Multimedia,?20(2), 335–344.?doi.org/10.1109/TMM.201
[7] Chen, C., Chen, Q., Xu, J., & Koltun, V. (2018). Learning to See in the Dark.?CVPR, 3291–3300.?doi.org/10.1109/CVPR.20
[8] Lv, F., Lu, F., Wu, J., & Lim, C. (2018). MBLLEN: Low-light Image/Video Enhancement Using CNNs.?BMVC, 1–13.
[9] Wei, C., Wang, W., Yang, W., & Liu, J. (2018). Deep Retinex Decomposition for Low-Light Enhancement.?BMVC, (61772043). Retrieved from?arxiv.org/abs/1808.0456
[10] Zhang, Y., Zhang, J., & Guo, X. (2019). Kindling the Darkness: A Practical Low-light Image Enhancer.?ArXiv, 1–13. Retrieved from?arxiv.org/abs/1905.0416
編輯:黃飛





















 工商網監
工商網監
評論