 電子發(fā)燒友App
電子發(fā)燒友App


進(jìn)行深度學(xué)習(xí)的訓(xùn)練向來不被認(rèn)為是CPU的強(qiáng)項(xiàng),但是以CPU研發(fā)見長的英特爾并不甘心屈服于這個(gè)定位,在過去的幾年里,英特爾及其合作伙伴一直在探索用CPU來進(jìn)行快速有效的深度學(xué)習(xí)開發(fā)的方法。代號(hào)KNL的Xeon Phi至強(qiáng)芯片是英特爾的努力嘗試之一,同時(shí)在深度學(xué)習(xí)算法的改進(jìn)上,英特爾也做了一些努力。
在美國舊金山舉行的IDF16大會(huì)上,與英特爾聯(lián)合宣布啟動(dòng)了KNL試用體驗(yàn)計(jì)劃的浪潮集團(tuán)副總裁、技術(shù)總監(jiān)胡雷鈞做了基于英特爾至強(qiáng)融合處理器KNL和FPGA上的深度學(xué)習(xí)的試用體驗(yàn)報(bào)告。報(bào)告介紹了高性能計(jì)算和深度學(xué)習(xí)發(fā)展的趨勢(shì)、深度學(xué)習(xí)在高性能計(jì)算平臺(tái)上的挑戰(zhàn)和解決辦法、大規(guī)模深度學(xué)習(xí)平臺(tái)的系統(tǒng)設(shè)計(jì)、多核設(shè)備和機(jī)群系統(tǒng)的算法設(shè)計(jì)(包括KNL和FPGA各自的技術(shù)分析) 4部分的內(nèi)容。下面我們從摩爾定律的演變開始,看企業(yè)在實(shí)踐過程中,如何基于英特爾至強(qiáng)融合處理器KNL和FPGA,搭建最佳的深度學(xué)習(xí)算法。
摩爾定律的革命
1965年摩爾定律提出后,我們開始依次進(jìn)入1965-2005年的單核CPU時(shí)代;2006至如今的多核CPU時(shí)代;2012至如今的多核英特爾MIC時(shí)代。
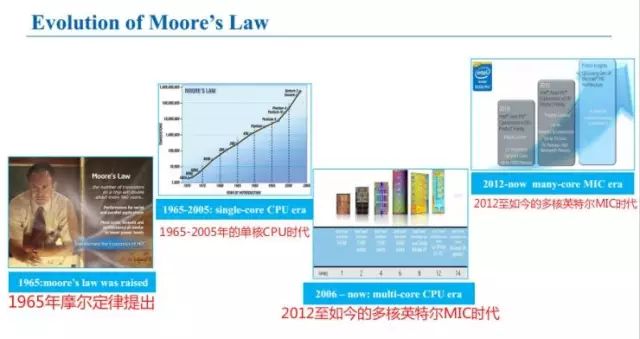
而現(xiàn)在,深度學(xué)習(xí)正在成為高性能計(jì)算的全新驅(qū)動(dòng)力
高性能計(jì)算設(shè)備聯(lián)手大數(shù)據(jù)提升深度學(xué)習(xí)的發(fā)展的同時(shí),深度學(xué)習(xí)也在促進(jìn)新的高性能計(jì)算模型的發(fā)展。歸根結(jié)底,我們把深度學(xué)習(xí)現(xiàn)在的成功歸功于三方面:
1)大量標(biāo)簽數(shù)據(jù)樣本的出現(xiàn):圖片(10億級(jí))/語音(10萬小時(shí)以上)。
2)好的算法,模型,軟件的出現(xiàn):?算法:DNN/CNN/RNN ?軟件:Caffe/TensorFlow/MXNet
3)高性能計(jì)算樣本的激勵(lì):AlphaGo可視為典型例子。

不可避免地,深度學(xué)習(xí)在高性能計(jì)算上遇到了挑戰(zhàn) ?
具體表現(xiàn)為兩方面,其一,大規(guī)模深度學(xué)習(xí)平臺(tái)的系統(tǒng)設(shè)計(jì)。比如離線訓(xùn)練要求的:高性能;在線識(shí)別要求的:低功耗。其二,多核設(shè)備和機(jī)群系統(tǒng)的算法設(shè)計(jì)問題。比如,多核設(shè)備異構(gòu)細(xì)粒度并行算法;機(jī)群系統(tǒng)的分布式以及粗粒度并行算法。這些都是不容易解決的問題。

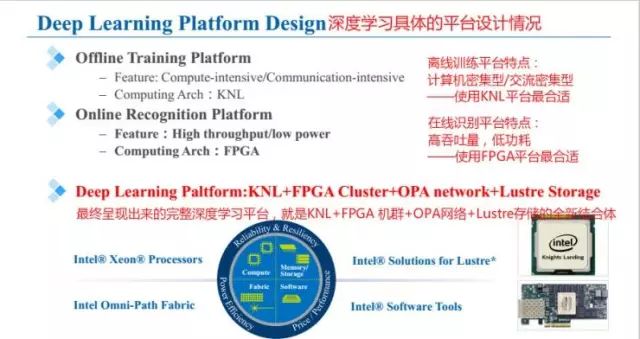
上述的挑戰(zhàn)之一,大規(guī)模深度學(xué)習(xí)平臺(tái)的系統(tǒng)設(shè)計(jì)問題,具體分為兩種:
離線訓(xùn)練平臺(tái)特點(diǎn):計(jì)算機(jī)密集型/交流密集型——使用KNL平臺(tái)最合適。
在線識(shí)別平臺(tái)特點(diǎn):高吞吐量,低功耗——使用FPGA平臺(tái)最合適。
最終呈現(xiàn)出來的完整深度學(xué)習(xí)平臺(tái),就是KNL+FPGA 機(jī)群+OPA網(wǎng)絡(luò)+Lustre存儲(chǔ) (由Linux和Clusters演化而來, 可以看做一個(gè)解決海量存儲(chǔ)問題而設(shè)計(jì)的全新文件系統(tǒng))的全新結(jié)合體。
上述的挑戰(zhàn)之二,多核設(shè)備和機(jī)群系統(tǒng)的算法設(shè)計(jì)問題
在我們的浪潮—Intel中國并行計(jì)算實(shí)驗(yàn)室里,KNL/FPGA技術(shù)研究;HPC/深度學(xué)習(xí)應(yīng)用;第一代 Xeon Phi Book三個(gè)方向的探索正如火如荼地進(jìn)行著。
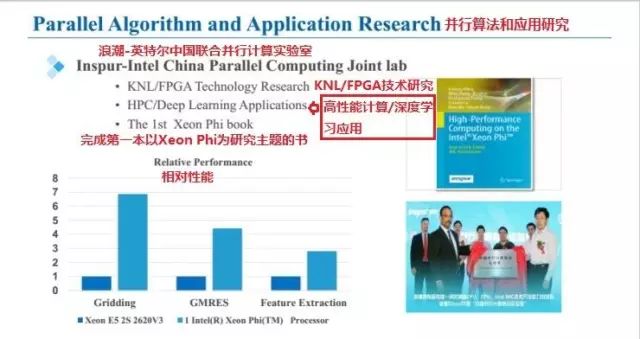
下面詳細(xì)介紹具體應(yīng)用實(shí)踐中(SKA【平方公里陣列望遠(yuǎn)鏡】的數(shù)據(jù)處理軟件Gridding、大規(guī)模線性方程組求解器GMRES和開源深度學(xué)習(xí)并行計(jì)算框架Caffe-MPI的KNL版本)的高性能計(jì)算平臺(tái)和其算法表現(xiàn)。
先談?wù)凨NL技術(shù)本身
它是英特爾第二代MIC架構(gòu),基于X86 架構(gòu)的多核計(jì)算:擁有最多72核,總計(jì)288線程。目前有3個(gè)產(chǎn)品模型:包括處理器;協(xié)處理器;KNL-F。支持大規(guī)模記憶和高速寬帶:DDR4:384 GB,90+GB/s。MCDRAM: 16GB, 500GB/s。

KNL技術(shù)的優(yōu)勢(shì):高性能、高應(yīng)用可適性、高可擴(kuò)展性、可編程。

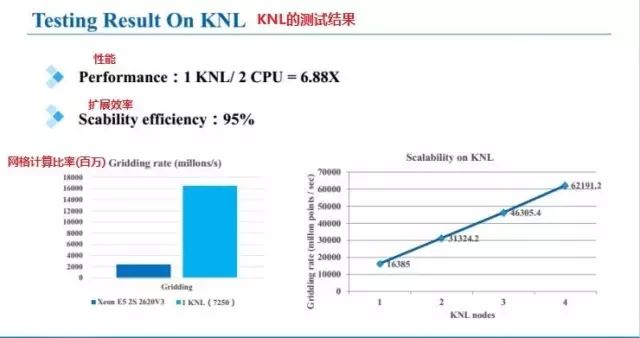
關(guān)于KNL測(cè)試結(jié)果
性能:1KNL/2 CPU=6.88X 。(疊加)擴(kuò)展效率:95%
以浪潮全球首發(fā)基于KNL平臺(tái)的深度學(xué)習(xí)計(jì)算框架Caffe-MPI舉例
Caffe有許多用戶,在中國非常流行。在數(shù)據(jù)規(guī)模很大的情況下,一個(gè)節(jié)點(diǎn)通常需要很長的時(shí)間去訓(xùn)練。這就要求,Caffe的前饋計(jì)算,權(quán)重計(jì)算,網(wǎng)絡(luò)更新可在并行機(jī)群環(huán)境中處理。

來自伯克利大學(xué)的原始版本的Caffe語言在處理的數(shù)據(jù)規(guī)模太大時(shí)需要的時(shí)間太長了,并且默認(rèn)情況下并不支持多節(jié)點(diǎn)、并行文件系統(tǒng)。因此不是很擅長超大規(guī)模的深度學(xué)習(xí)運(yùn)算。不過由于Caffe是開源的,因此理論上任何人都能對(duì)其進(jìn)行自己需要的改進(jìn)。Caffe的多種功能事實(shí)上都有很好的被改進(jìn)以支持集群并行計(jì)算的潛力。而浪潮集團(tuán)在原版Caffe的基礎(chǔ)上加以改進(jìn),開發(fā)出了第一代支持在KNL上進(jìn)行叢集并行計(jì)算的Caffe版本。支持英特爾的Luster存儲(chǔ)器、OPA網(wǎng)絡(luò)和KNL叢集。

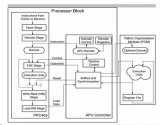
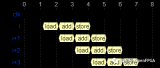
浪潮集團(tuán)將這個(gè)改進(jìn)版的Caffe框架命名為Caffe架構(gòu),下圖是關(guān)于Caffe-MPI在KNL上進(jìn)行運(yùn)算時(shí)的結(jié)構(gòu)的一些解釋。可以看到,其計(jì)算流程采用MPI主從模式,使用多個(gè)KNL處理器組成節(jié)點(diǎn)網(wǎng)絡(luò),主節(jié)點(diǎn)使用一個(gè)KNL,而從節(jié)點(diǎn)可以視需求由N個(gè)KNL構(gòu)成,因?yàn)槭褂昧藢镠PC設(shè)計(jì)的Lustre文件系統(tǒng),因此數(shù)據(jù)吞吐量并不會(huì)限制到計(jì)算和訓(xùn)練。OPA架構(gòu)也保證了網(wǎng)絡(luò)通信的順暢。軟件系統(tǒng)方面,支持Linux/Intel MKL和Mvapich2 。
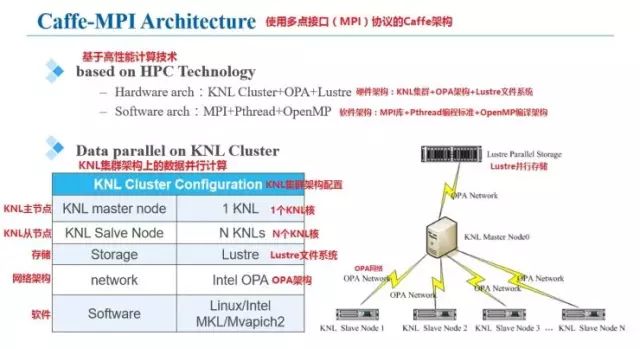
設(shè)計(jì)框架中的主節(jié)點(diǎn)為MPI單進(jìn)程+多Pthread線程,從節(jié)點(diǎn)為MPI多進(jìn)程,圖中展示了整個(gè)網(wǎng)絡(luò)訓(xùn)練的框圖。
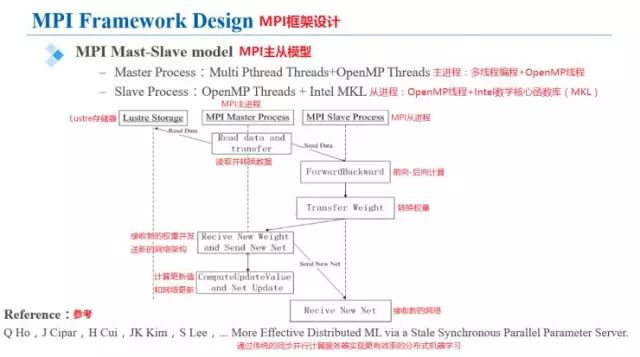
設(shè)計(jì)中對(duì)KNL的最多72個(gè)核心可以進(jìn)行充分利用,主進(jìn)程可以同時(shí)處理三個(gè)線程:并行讀取和發(fā)送數(shù)據(jù)、權(quán)重計(jì)算和參數(shù)更新、網(wǎng)絡(luò)間的參數(shù)溝通。下圖中給出了圖示。
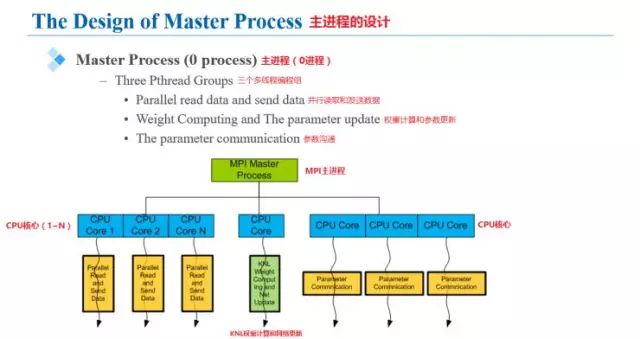
MPI結(jié)構(gòu)中的從進(jìn)程的主要處理流程是:從主進(jìn)程中接收訓(xùn)練數(shù)據(jù)、發(fā)送權(quán)重?cái)?shù)據(jù)、接收新的網(wǎng)絡(luò)數(shù)據(jù)、進(jìn)行前向、后向計(jì)算。從節(jié)點(diǎn)網(wǎng)絡(luò)中每一個(gè)KNL核代表了一個(gè)MPI網(wǎng)絡(luò)中的從節(jié)點(diǎn)。
下圖中的信息表示,改進(jìn)版的在KNL叢集上運(yùn)行的Caffe-MPI架構(gòu)對(duì)原版Caffe進(jìn)行了多項(xiàng)優(yōu)化。最終的效果表現(xiàn)是原版的3.78倍。增加KNL處理器的總數(shù)時(shí)的性能擴(kuò)展效率高達(dá)94.5%。

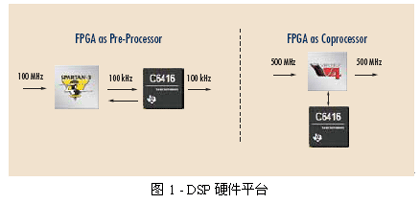
而FPGA是另一項(xiàng)在深度學(xué)習(xí)領(lǐng)域極有潛力的硬件。我們知道FPGA的特點(diǎn)包括高性能、支持更多并行模式、高密度、易編程、適配OpenCL。

目前浪潮、Altera和科大訊飛在在線識(shí)別領(lǐng)域?qū)PGA的應(yīng)用起到了很好的成效。結(jié)果表明,F(xiàn)PGA組成的系統(tǒng)在各項(xiàng)指標(biāo)上都顯著優(yōu)于傳統(tǒng)CPU組成的系統(tǒng)。

結(jié)論是
對(duì)于離線學(xué)習(xí)來說,基于KNL處理器搭建的MPI-Caffe架構(gòu)可以很好的完成任務(wù)。而在線語音平臺(tái)等在線認(rèn)知項(xiàng)目則很適合使用FPGA來搭建系統(tǒng)。

編輯:黃飛
?












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論