 電子發(fā)燒友App
電子發(fā)燒友App


導(dǎo)讀
Deep learning在訓(xùn)練的時候往往有很多trick,不可否認(rèn)這些trick也是DL成功的關(guān)鍵因素之一,所謂“the devil is in the details”。除了batch大小的改變以及初始化等trick,還有哪些提升performance的利器?
Focal Loss
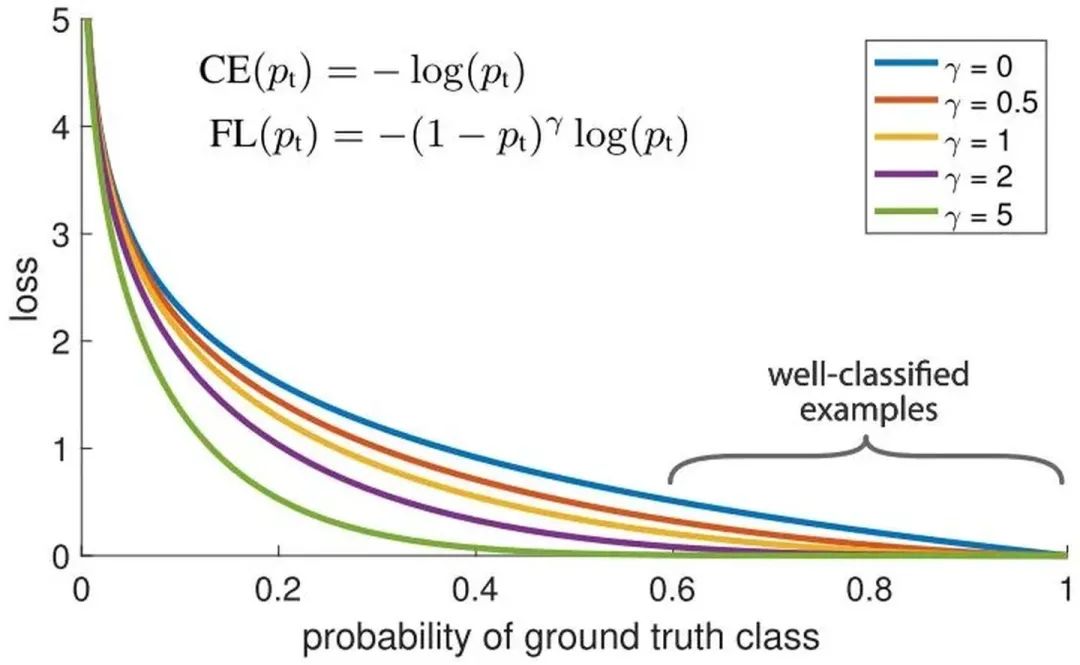
針對類別不平衡問題,用預(yù)測概率對不同類別的loss進(jìn)行加權(quán)。Focal loss對CE loss增加了一個調(diào)制系數(shù)來降低容易樣本的權(quán)重值,使得訓(xùn)練過程更加關(guān)注困難樣本。
loss = -np.log(p) loss = (1-p)^G * loss
Dropout
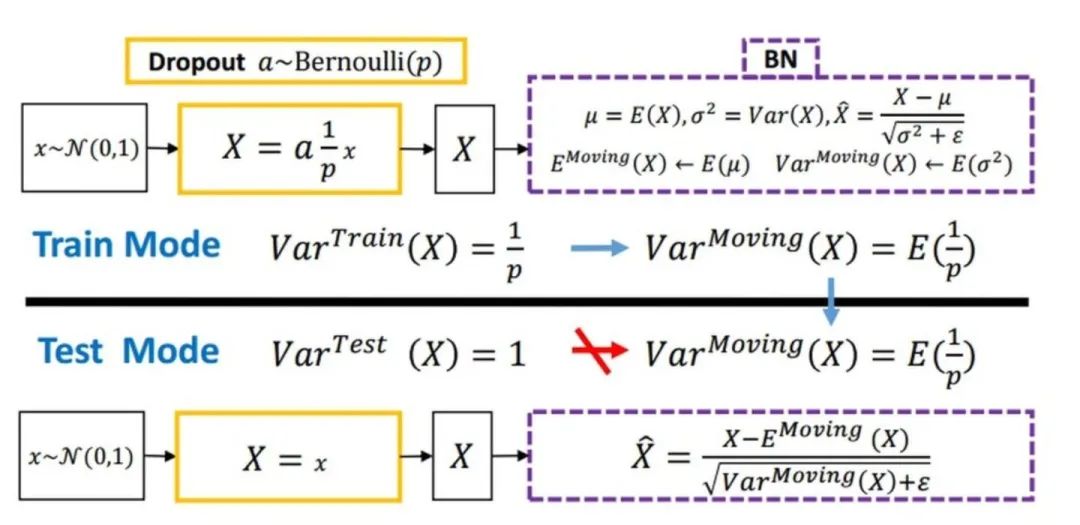
隨機(jī)丟棄,抑制過擬合,提高模型魯棒性。
Normalization
Batch Normalization 于2015年由 Google 提出,開 Normalization 之先河。其規(guī)范化針對單個神經(jīng)元進(jìn)行,利用網(wǎng)絡(luò)訓(xùn)練時一個 mini-batch 的數(shù)據(jù)來計算該神經(jīng)元的均值和方差,因而稱為 Batch Normalization。
x = (x - x.mean()) / x.std()
relu
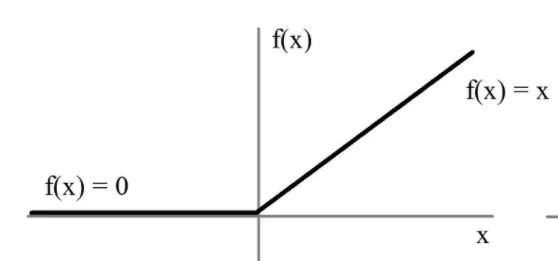
用極簡的方式實現(xiàn)非線性激活,緩解梯度消失。
x = max(x, 0)
Cyclic LR
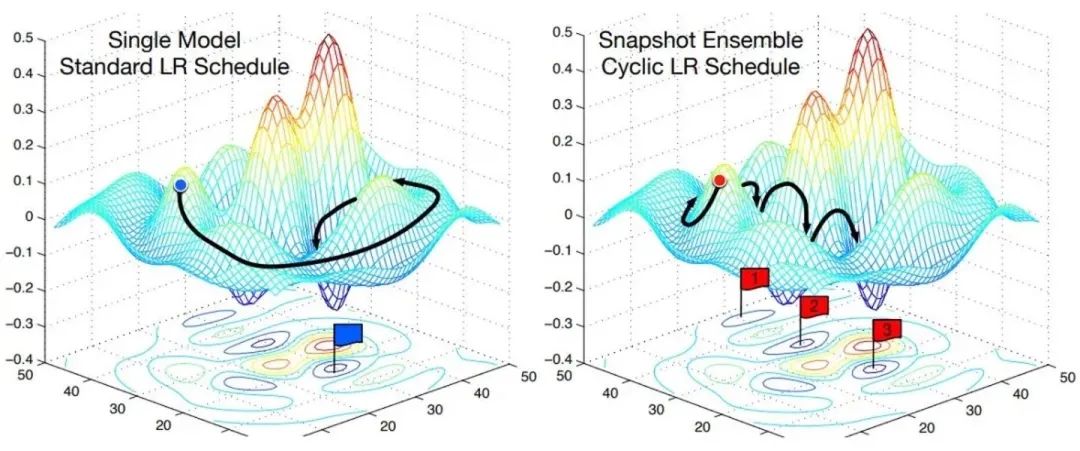
每隔一段時間重啟學(xué)習(xí)率,這樣在單位時間內(nèi)能收斂到多個局部最小值,可以得到很多個模型做集成。
scheduler = lambda x: ((LR_INIT-LR_MIN)/2)*(np.cos(PI*(np.mod(x-1,CYCLE)/(CYCLE)))+1)+LR_MIN
With Flooding
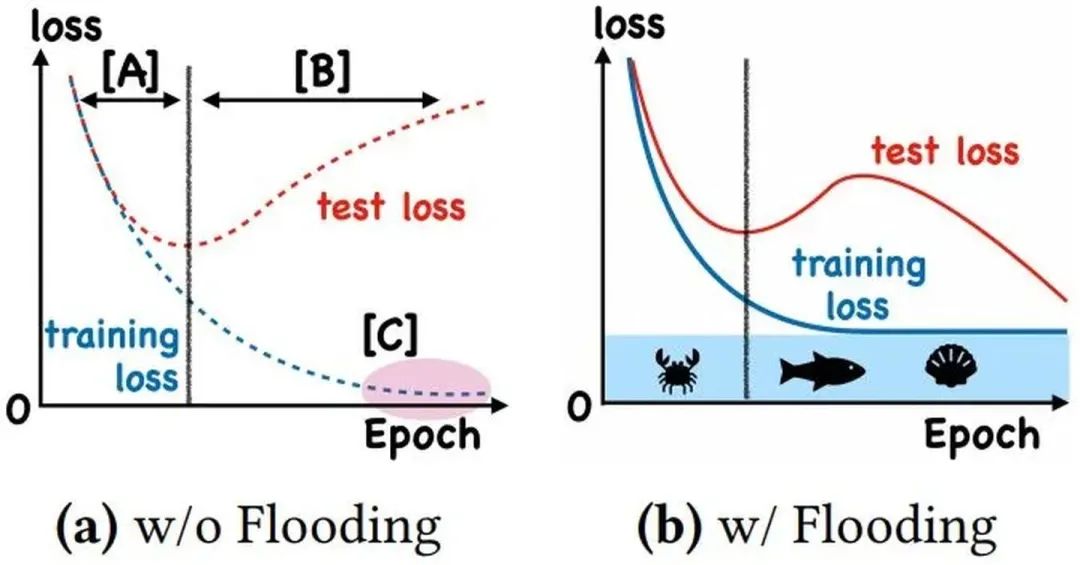
當(dāng)training loss大于一個閾值時,進(jìn)行正常的梯度下降;當(dāng)training loss低于閾值時,會反過來進(jìn)行梯度上升,讓training loss保持在一個閾值附近,讓模型持續(xù)進(jìn)行"random walk",并期望模型能被優(yōu)化到一個平坦的損失區(qū)域,這樣發(fā)現(xiàn)test loss進(jìn)行了double decent。
flood = (loss - b).abs() + b
Group Normalization
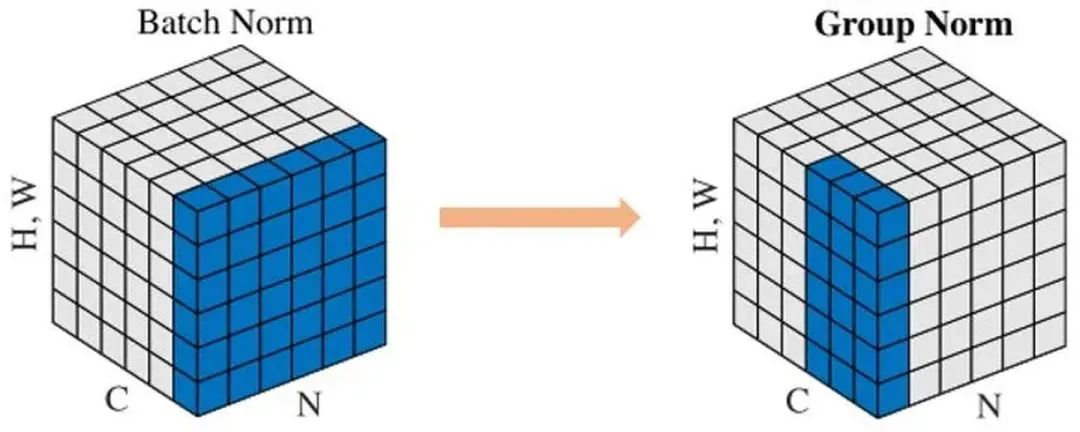
Face book AI research(FAIR)吳育昕-愷明聯(lián)合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度學(xué)習(xí)里程碑式的工作Batch normalization。一句話概括,Group Normbalization(GN)是一種新的深度學(xué)習(xí)歸一化方式,可以替代BN。
def GroupNorm(x, gamma, beta, G, eps=1e-5):
# x: input features with shape [N,C,H,W]
# gamma, beta: scale and offset, with shape [1,C,1,1]
# G: number of groups for GN
N, C, H, W = x.shape
x = tf.reshape(x, [N, G, C // G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep dims=True)
x = (x - mean) / tf.sqrt(var + eps)
x = tf.reshape(x, [N, C, H, W])
return x * gamma + beta
Label Smoothing
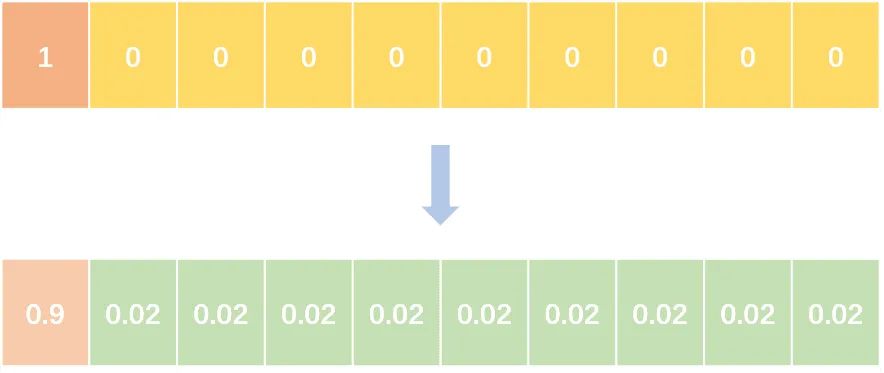
abel smoothing將hard label轉(zhuǎn)變成soft label,使網(wǎng)絡(luò)優(yōu)化更加平滑。標(biāo)簽平滑是用于深度神經(jīng)網(wǎng)絡(luò)(DNN)的有效正則化工具,該工具通過在均勻分布和hard標(biāo)簽之間應(yīng)用加權(quán)平均值來生成soft標(biāo)簽。它通常用于減少訓(xùn)練DNN的過擬合問題并進(jìn)一步提高分類性能。
targets = (1 - label_smooth) * targets + label_smooth / num_classes
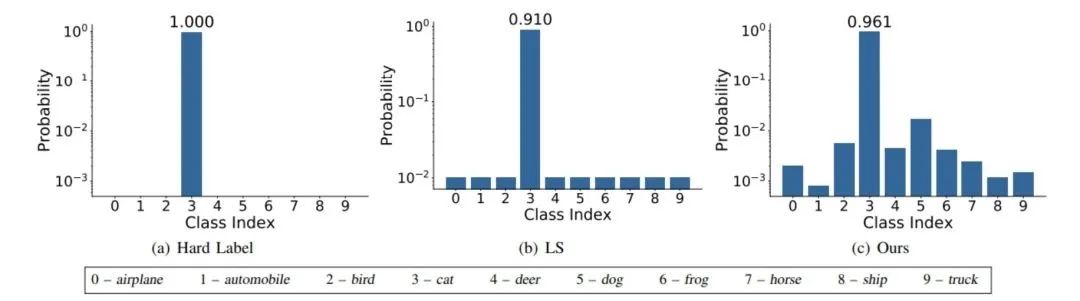
?
?
Wasserstein GAN
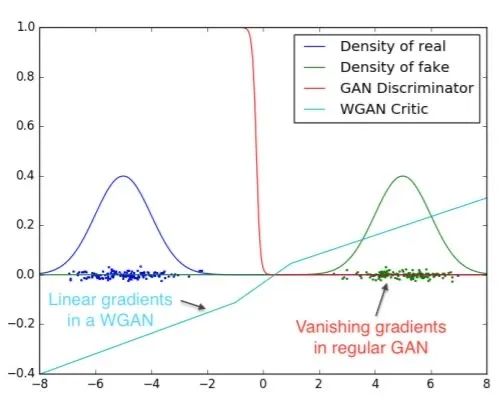
徹底解決GAN訓(xùn)練不穩(wěn)定的問題,不再需要小心平衡生成器和判別器的訓(xùn)練程度
基本解決了Collapse mode的問題,確保了生成樣本的多樣性訓(xùn)練過程中終于有一個像交叉熵、準(zhǔn)確率這樣的數(shù)值來指示
訓(xùn)練的進(jìn)程,數(shù)值越小代表GAN訓(xùn)練得越好,代表生成器產(chǎn)生的圖像質(zhì)量越高
不需要精心設(shè)計的網(wǎng)絡(luò)架構(gòu),最簡單的多層全連接網(wǎng)絡(luò)就可以做到以上3點。
Skip Connection
一種網(wǎng)絡(luò)結(jié)構(gòu),提供恒等映射的能力,保證模型不會因網(wǎng)絡(luò)變深而退化。
F(x) = F(x) + x
參考文獻(xiàn)
https://www.zhihu.com/question/427088601
https://arxiv.org/pdf/1701.07875.pdf
https://zhuanlan.zhihu.com/p/25071913
https://www.zhihu.com/people/yuconan/posts
#?回答二
作者:永無止境
來源鏈接:
https://www.zhihu.com/question/30712664/answer/1341368789
在噪聲較強(qiáng)的時候,可以考慮采用軟閾值化作為激活函數(shù):
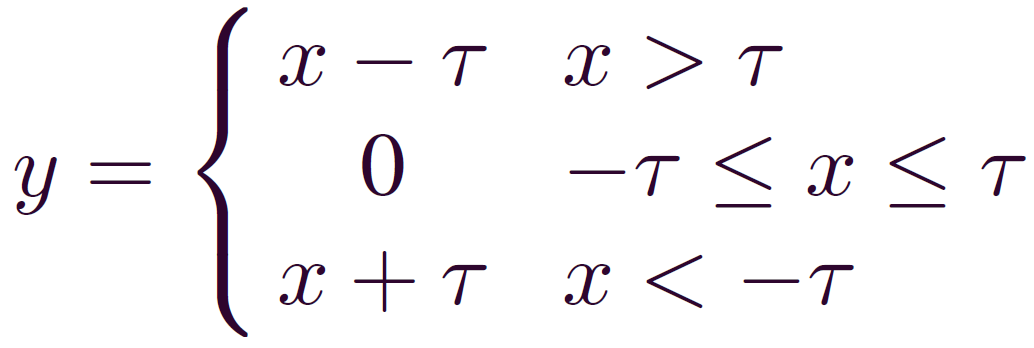
軟閾值化幾乎是降噪的必備步驟,但是閾值τ該怎么設(shè)置呢?
閾值τ不能太大,否則所有的輸出都是零,就沒有意義了。而且,閾值不能為負(fù)。
針對這個問題,深度殘差收縮網(wǎng)絡(luò)[1][2]提供了一個思路,設(shè)計了一個特殊的子網(wǎng)絡(luò)來自動設(shè)置:
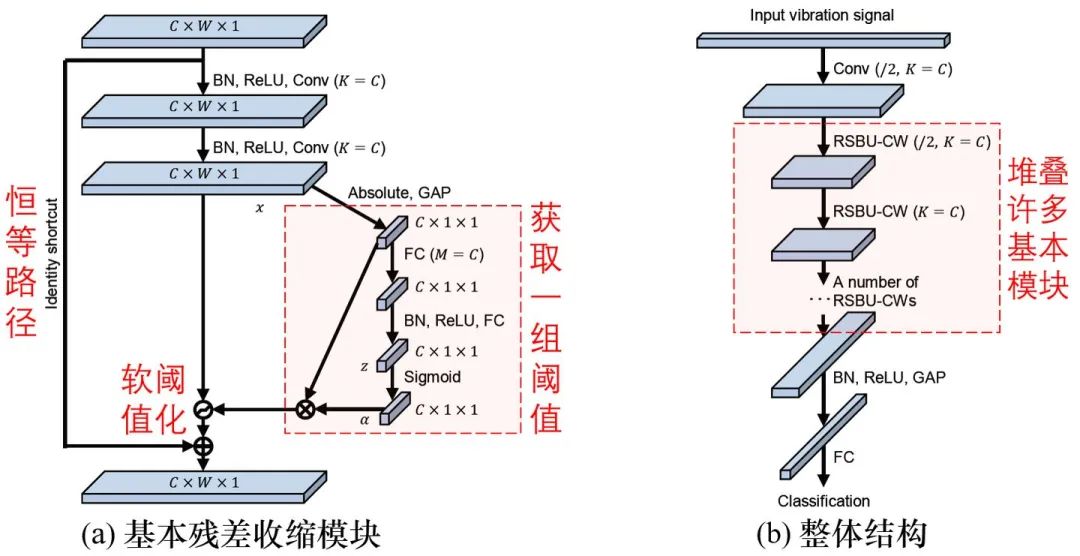
Zhao M, Zhong S, Fu X, Tang B, Pecht M. Deep residual shrinkage networks for fault diagnosis. IEEE Transactions on Industrial Informatics. 2019 Sep 26;16(7):4681-90.
參考:
^深度殘差收縮網(wǎng)絡(luò):從刪除冗余特征的靈活度進(jìn)行探討?https://zhuanlan.zhihu.com/p/118493090 ^深度殘差收縮網(wǎng)絡(luò):一種面向強(qiáng)噪聲數(shù)據(jù)的深度學(xué)習(xí)方法?https://zhuanlan.zhihu.com/p/115241985 ?
#?回答三
作者:馮遷
來源鏈接:https://www.zhihu.com/question/30712664/answer/1816283937
贊比較多的給了些,損失函數(shù)(focal),模型結(jié)構(gòu)(identity skip),訓(xùn)練方面(strategy on learning rate),穩(wěn)定性方面(normalization),復(fù)雜泛化性(drop out),宜優(yōu)化性(relu,smooth label)等,這些都可以擴(kuò)展。
focal 可以擴(kuò)展到centernet loss,結(jié)構(gòu)有尺度fpn,重復(fù)模塊,堆疊concatenate,splite,cross fusion等,訓(xùn)練方面有teaching,step learning,對抗(本身是個思想),多階段優(yōu)化,progress learning,穩(wěn)定性方面,batch normal,instance normal,group normal之外,還有譜范數(shù)等,復(fù)雜性還有正則l1/2等,宜優(yōu)化性,可以擴(kuò)展到檢測的anchor等。
dl你得說優(yōu)化器吧,把動量,一二階考慮進(jìn)來,梯度方向和一階動量的折中方向,把隨機(jī)考慮進(jìn)來sgd
以上可能帶來最多10的收益,你得搞數(shù)據(jù)啊
數(shù)據(jù)方面的處理clean,various ,distribution,aug data等更重要(逃…
“理論”在收斂速度,穩(wěn)定,泛化,通用,合理等方面著手,性能在數(shù)據(jù)方面著手,也許
編輯:黃飛
?






















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論