 電子發燒友App
電子發燒友App


ChatGPT發布之后,引發了全球范圍的關注和討論,國內各大廠商相繼宣布GPT模型開發計劃。據各公司官網,2023年2月7日,百度宣布將推出ChatGPT類似產品“文心一言”,預計今年3月展開內測;2月8日阿里宣布阿里版ChatGPT正在研發中,目前處于內測階段;2月9日,字節跳動旗下AI Lab宣布正在開展ChatGPT和AIGC相關研發,未來將為PICO提供技術支持;2月10日,京東旗下言犀人工智能平臺推出產業版ChatGPT—“ ChatJD”。 ?
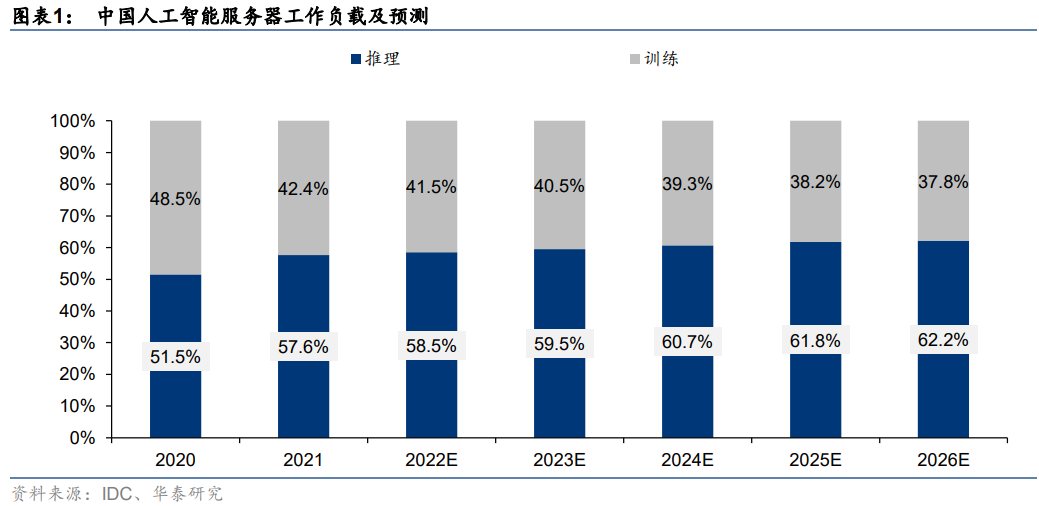
AI模型對算力的需求主要體現在訓練和推理兩個層面。當前主流的人工智能算法通常可分為“訓練”和“推理”兩個階段。據IDC數據,2021年中國人工智能服務器工作負載中,57.6%的負載用于推理,42.4%用于模型訓練。據IDC預計,到2026年AI推理的負載比例將進一步提升至62.2%。具體來看:
1)訓練階段:基于充裕的數據來調整和優化人工智能模型的參數,使模型的準確度達到預期。對于圖像識別、語音識別與自然語言處理等領域的復雜問題,為了獲得更準確的人工智能模型,訓練階段常常需要處理大量數據集、做反復的迭代計算,耗費巨大的運算量。
2)推理階段:訓練階段結束以后,人工智能模型已經建立完畢,已可用于推理或預測待處理輸入數據對應的輸出(例如給定一張圖片,識別該圖片中的物體),此過程被稱為推理階段。推理階段對單個任務的計算能力要求不如訓練那么大,但是由于訓練出來的模型會多次用于推理,因此推理運算的總計算量也相當可觀。
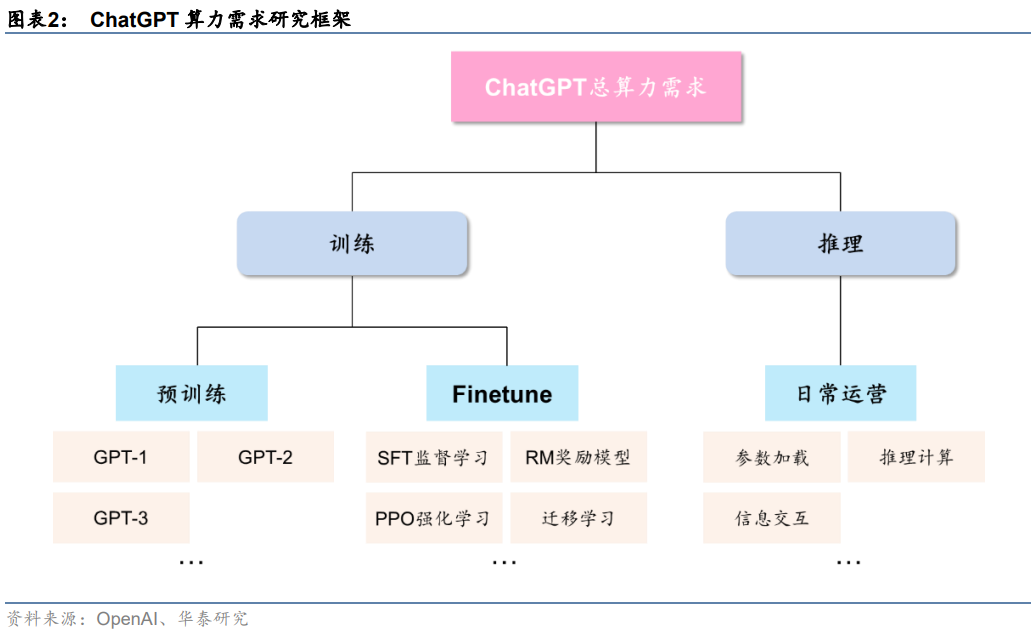
ChatGPT算力需求場景包括預訓練、Finetune及日常運營。從ChatGPT實際應用情況來看,從訓練+推理的框架出發,我們可以將ChatGPT的算力需求按場景進一步拆分為預訓練、Finetune及日常運營三個部分:
1)預訓練:主要通過大量無標注的純文本數據,訓練模型基礎語言能力,得到類似GPT-1/2/3這樣的基礎大模型;
2)Finetune:在完成預訓練的大模型基礎上,進行監督學習、強化學習、遷移學習等二次或多次訓練,實現對模型參數量的優化調整;
3)日常運營:基于用戶輸入信息,加載模型參數進行推理計算,并實現最終結果的反饋輸出。
預訓練階段:單次算力需求取決于模型參數量,最高可達3640 PFlop/s-day
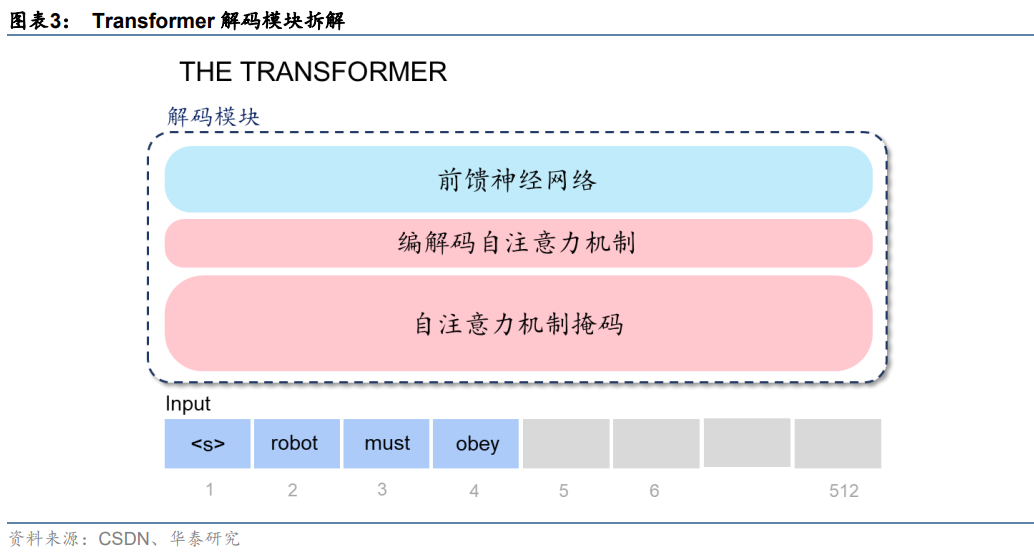
ChatGPT基于Transformer架構,進行語言模型預訓練。GPT模型之所以能夠高效地完成大規模參數計算,我們認為離不開Transformer架構的加持。拆解Transformer架構來看,核心是由編碼模塊和解碼模塊構成,而GPT模型只用到了解碼模塊。拆解模塊來看,大致分為三層:前饋神經網絡層、編碼/解碼自注意力機制層(Self-Attention)、自注意力機制掩碼層,其中:
1)注意力機制層主要作用在于計算某個單詞對于全部單詞的權重(即Attention),從而能夠更好地去學習所有輸入之間的關系,實現對文本內在關系的理解和更大規模的并行計算;
2)前饋神經網絡提供了對數據信息的高效存儲及檢索;3)掩碼層在這一過程中幫助模型屏蔽位于計算位置右側尚未出現的單詞。因此,相較于前代深度學習架構RNN,Transformer架構可以實現更大規模的并行計算,大大提升了計算效率。
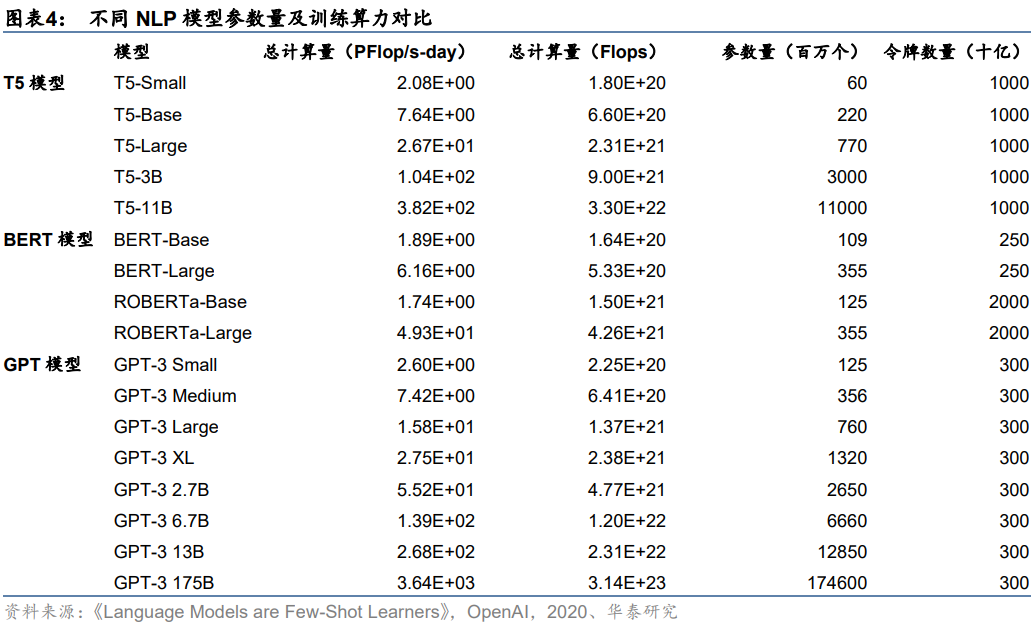
單一大模型路線下,需要完成大規模參數計算。以GPT-3模型為例,隨著模型朝更大體量的方向演進,參數量從GPT-3 Small的1.25億個增長到GPT-3 175B的1746億個,一次訓練所需的計算量從2.6PFlop/s-day增至3640PFlop/s-day。與此同時,在不同學習樣本(包括小樣本、單一樣本、零樣本)條件下的模型,隨著參數量的提升均實現不同幅度的上下文學習能力改善,外在表現為語言準確率的提升。我們認為,隨著大模型訓練表現出越來越強大的實戰能力,未來或將成為NLP訓練的主流選擇。
推理階段:預計單月運營算力需求約7034.7 PFlop/s-day
ChatGPT近一月訪問量為8.89億次。據SimilarWeb數據,2023年1月以來ChatGPT官網日訪問量持續攀升,從1月初的日均千萬次級別,到1月底日均兩千萬次,再到2月中旬的三千萬次級別,隨著軟件效果的廣泛傳播,用戶訪問次數愈發頻繁。加總近一月(2023/1/17-2023/2/17)ChatGPT官網訪問量數據來看,可得ChatGPT月訪問量為8.89億次。
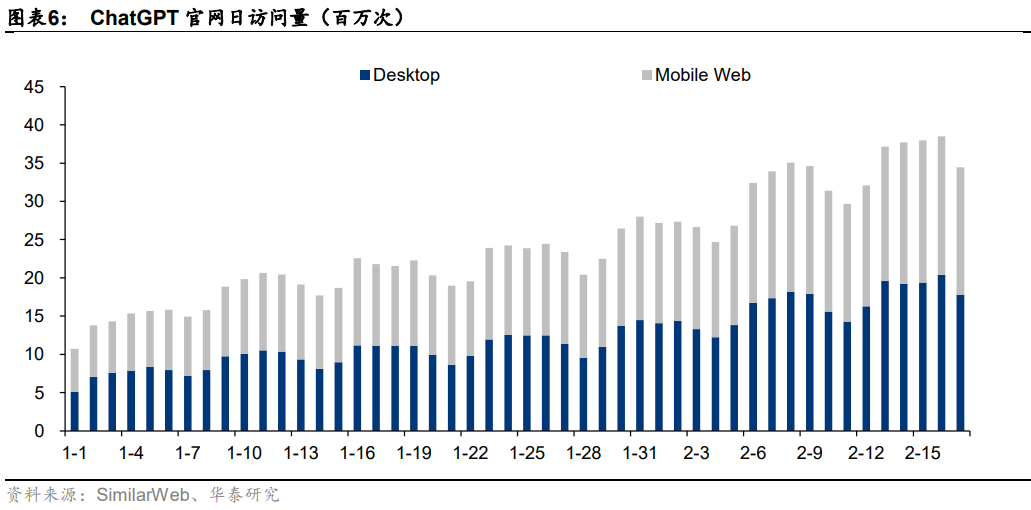
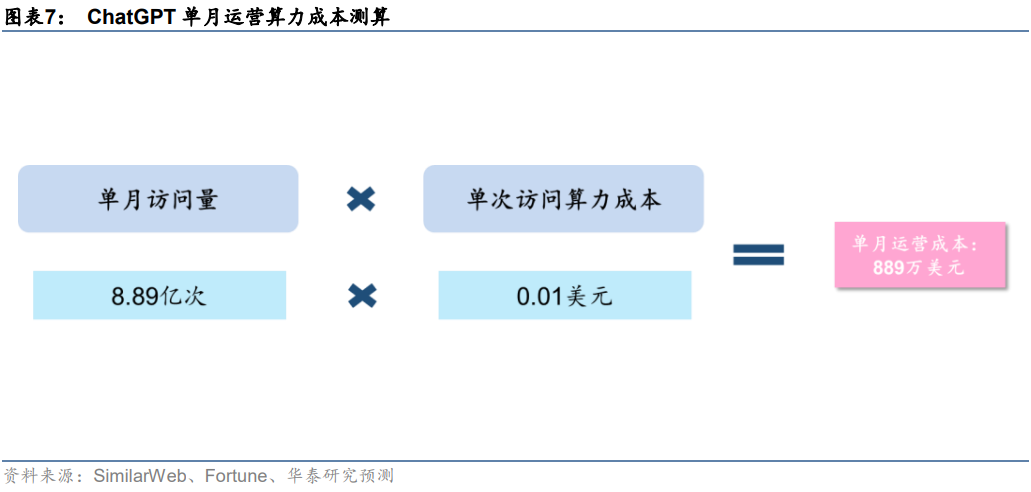
預計日常運營單月所需算力約7034.7 PFlop/s-day。日常運營過程中,用戶交互帶來的數據處理需求同樣也是一筆不小的算力開支。據前文,近一個月(2023/1/17-2023/2/17)ChatGPT官網總訪問量為8.89億次。據Fortune雜志,每次用戶與ChatGPT互動,產生的算力云服務成本約0.01美元。基于此,我們測算得2023年1月OpenAI為ChatGPT支付的運營算力成本約889萬美元。此外,據Lambda,使用訓練一次1746億參數的GPT-3模型所需花費的算力成本超過460萬美元;據OpenAI,訓練一次1746億參數的GPT-3模型需要的算力約為3640 PFlop/s-day。我們假設單位算力成本固定,測算得ChatGPT單月運營所需算力約7034.7PFlop/s-day。
Finetune階段:預計ChatGPT單月Finetune的算力需求至少為1350.4PFlop/s-day
模型迭代帶來Finetune算力需求。從模型迭代的角度來看,ChatGPT模型并不是靜態的,而是需要不斷進行Finetune模型調優,以確保模型處于最佳應用狀態。這一過程中,一方面是需要開發者對模型參數進行調整,確保輸出內容不是有害和失真的;另一方面,需要基于用戶反饋和PPO策略,對模型進行大規模或小規模的迭代訓練。因此,模型調優同樣會為OpenAI帶來算力成本,具體算力需求和成本金額取決于模型的迭代速度。
預計ChatGPT單月Finetune算力需求至少為1350.4PFlop/s-day。據IDC預計,2022年中國人工智能服務器負載中,推理和訓練的比例分別為58.5%、41.5%。我們假設,ChatGPT對推理和訓練的算力需求分布與之保持一致,且已知單月運營需要算力7034.7 PFlop/s-day、一次預訓練需要算力3640 PFlop/s-day。基于此,我們進一步假設:1)考慮到AI大模型預訓練主要通過巨量數據喂養完成,模型底層架構變化頻率不高,故我們假設每月最多進行一次預訓練;2)人類反饋機制下,模型需要不斷獲得人類指導以實現參數調優,以月為單位可能多次進行。由此我們計算得ChatGPT單月Finetune算力成本至少為1350.4PFlop/s-day。
1、ChatGPT需要的服務器:AI訓練型服務器+AI推理型服務器
隨著計算場景擴展,算力硬件也在發生變化。在傳統軟件架構下,主要的模式都是CS模式,服務端大多是單機處理幾千個輕量請求。而在邊緣計算場景下,需要數萬臺服務器處理上億個重負載請求。邊緣計算機本質上是用CES模式取代CS模式,當前的互聯網IT架構已經從CS模式,逐步向CDN服務為核心的CES模式轉變。但當前的CDN模式比較大的局限性在于缺乏靈活性,不能解決邊緣上非結構化數據存儲和處理的需求,引入Edge端(邊緣端)就是為了解決CS模式下無法處理的業務。而在AI訓練場景下,計算量及數據類型的變化導致C-E-S又無法滿足集中大算力需求,計算架構回歸C-S,并向高效率并行計算演變。
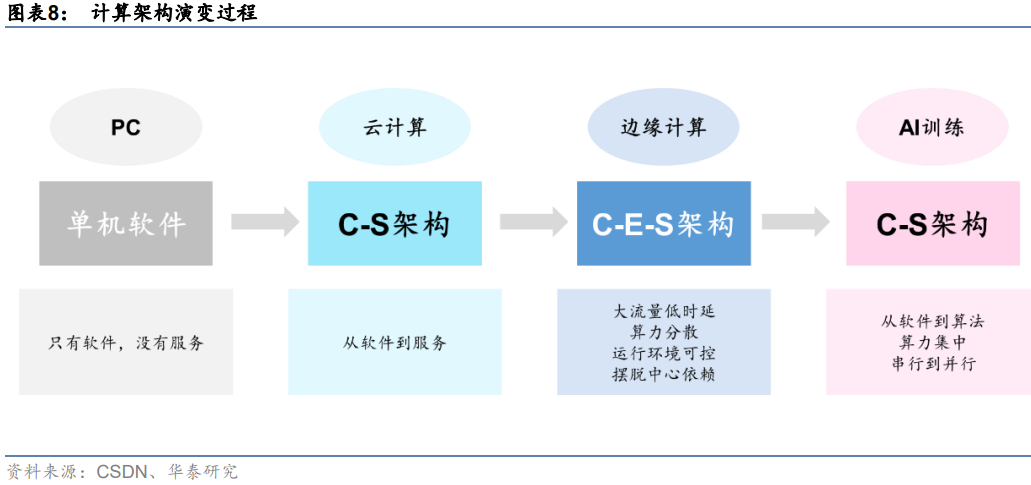
服務器作為算力硬件核心,面向不同計算場景分化演進。我們認為,計算架構的變化是推動服務器技術演進的關鍵變量。從計算場景來看,隨著計算架構從PC到云計算,到邊緣計算,再到AI訓練,服務器需求也在發生相應變化。從單一服務器更加強調服務個體性能,如穩定性、吞吐量、響應時間等。云數據中心服務器對單個服務器性能要求下降,但更強調數據中心整體性能,如成本、快速部署和交付。邊緣計算場景下,開始出現異構計算等復雜環境計算,對數據交互實時性要求有所提升,需要在邊緣端設立單獨的服務器設施。而AI服務器主要專為人工智能訓練設計,數據類型以向量/張量為主,多采用大規模并行計算以提升運算效率。
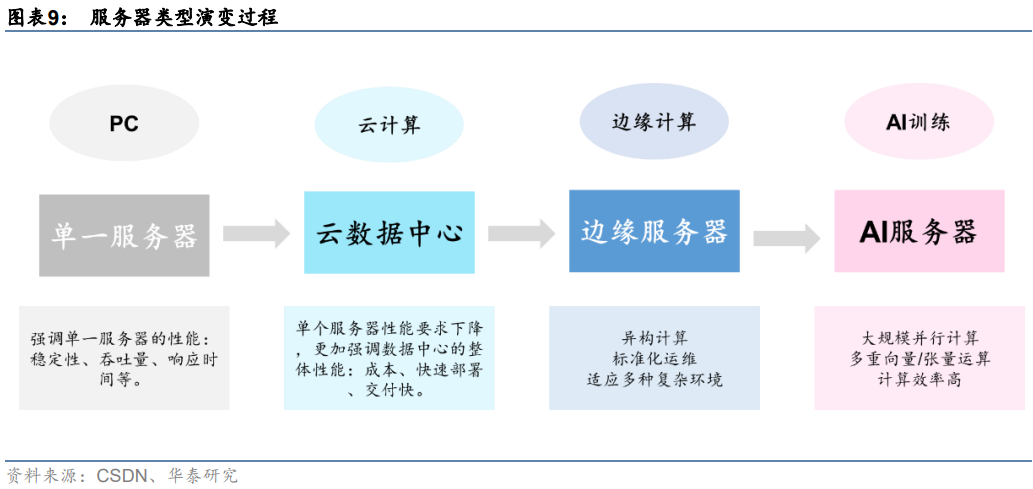
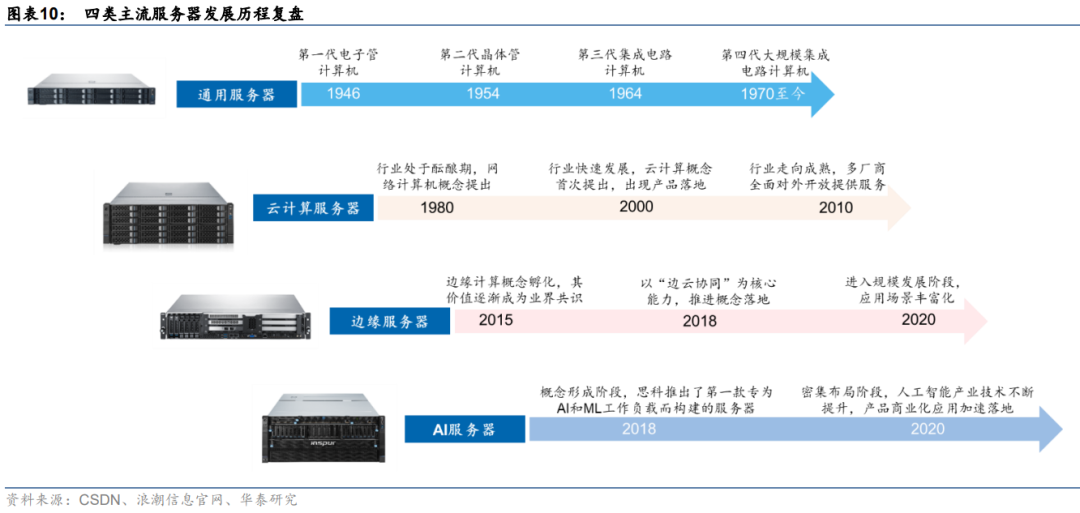
同一技術路線下,服務器面向數據處理需求持續迭代。復盤主流服務器發展歷程來看,隨著數據量激增、數據場景復雜化,不同類型服務器發展驅動力也有所差異。具體來看:
1)通用服務器:傳統通用服務器的發展與計算機架構發展同步,通過處理器的時鐘頻率、指令集并行度、核數等硬件指標的提升優化自身性能,發展較為緩慢。
2)云計算服務器:云計算的概念于20世紀80年代提出,僅20年后就有較為成熟的產品推出,如VMware的VMware Workstation和亞馬遜AWS等。2010年隨著OpenStack開源,阿里云、華為云等項目相繼布局,云計算行業快速走向成熟。
3)邊緣計算服務器:邊緣計算概念孵化于2015年,僅2年后就有諸如亞馬遜AWS Greengrass、谷歌GMEC等邊緣計算平臺產生,并在微軟的帶領下提前進入技術并購期。
4)AI服務器:AI服務器最早由思科在2018推出,專為人工智能、機器學習的工作服務而設計,硬件架構更加適合AI訓練場景下的算力需求。
2、云計算服務器:大規模數據處理需求下的商業模式變革
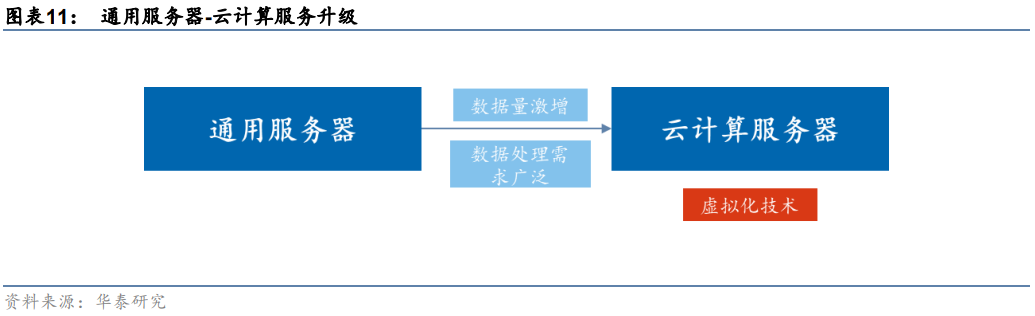
數據量激增帶來大算力需求,云計算服務器應運而生。通用服務器通過提高硬件指標提升性能,而隨著CPU的工藝和單個CPU的核心數量接近極限,通用服務器性能難以支持數據量激增帶來的性能需求。云計算服務器則通過虛擬化技術,將計算和存儲資源進行池化,把原來物理隔離的單臺計算資源進行虛擬化和集中化。最終以集群化處理來達到單臺服務器所難以實現的高性能計算。同時,云計算服務器集群的計算能力可以通過不斷增加虛擬化服務器的數量來進行擴展,突破單個服務器硬件限制,應對數據量激增帶來的性能需求。
云計算服務器節約部分硬件成本,降低算力采購門檻。早期大規模數據處理成本極高,原因在于通用服務器的購置和運維成本居高不下。傳統服務器中均包含處理器摸塊、存儲模塊、網絡模塊、電源、風扇等全套設備,而云計算服務器體系架構精簡,省去重復的模塊,提高了利用率。同時云計算服務器針對節能需求,將存儲模塊進行虛擬化,并去除了主板上的非必要硬件,降低了整體計算成本,并通過流量計費模式,使得更多廠商可以負擔算力開支,降低了算力采購門檻。
3、邊緣服務器:高數據密度和帶寬限制下保證低時延
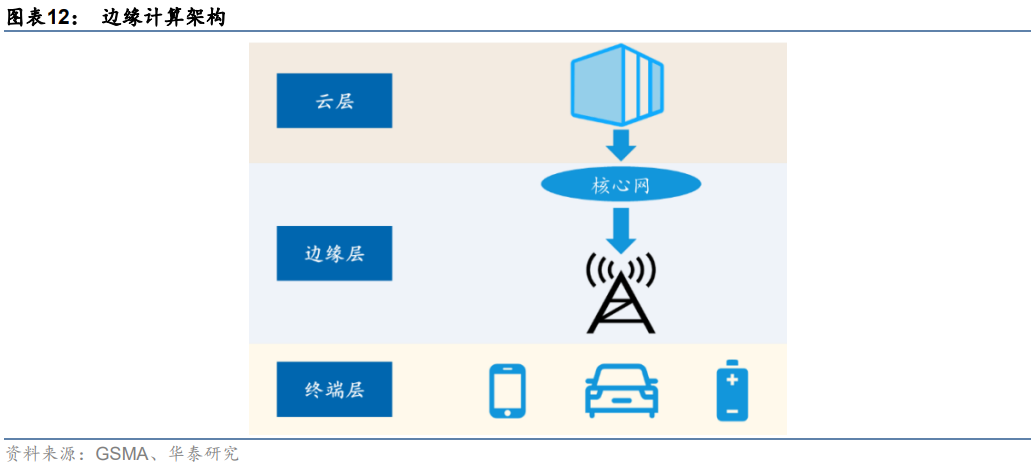
邊緣計算在云計算的基礎上引入邊緣層。邊緣計算是在靠近物或數據源頭的網絡邊緣側,為應用提供融合計算、存儲和網絡等資源。在體系架構上,邊緣計算在終端層和云層之間引入邊緣層,從而將云服務擴展到網絡邊緣。其中終端層由物聯網設備構成,最靠近用戶,負責收集原始數據并上傳至上層進行計算;邊緣層由路由器、網關、邊緣服務器等組成,由于距離用戶較近,可以運行延遲敏感應用,滿足用戶對低時延的要求;云層由高性能服務器等組成,可以執行復雜計算任務。
邊緣計算較云計算在實時性、低成本和安全性等方面有優勢:
1)實時性:邊緣計算將原有云計算中心的計算任務部分或全部遷移到與用戶距離更近的網絡邊緣進行處理,而不是在外部數據中心或云端進行,因此提高了數據傳輸性能,保證了處理的實時性。
2)低帶寬成本:終端產生的數據無需遠距離傳輸至云端,避免帶寬成本。同時,邊緣計算機制中,邊緣層可對終端產生數據進行預處理,從而降低云計算中心的計算負載。
3)安全性:邊緣計算在本地設備和邊緣層設備中處理大部分數據而不是將其上傳至云端,減少實際存在風險的數據量,避免數據泄露危險。

4、AI服務器:更適合深度學習等AI訓練場景
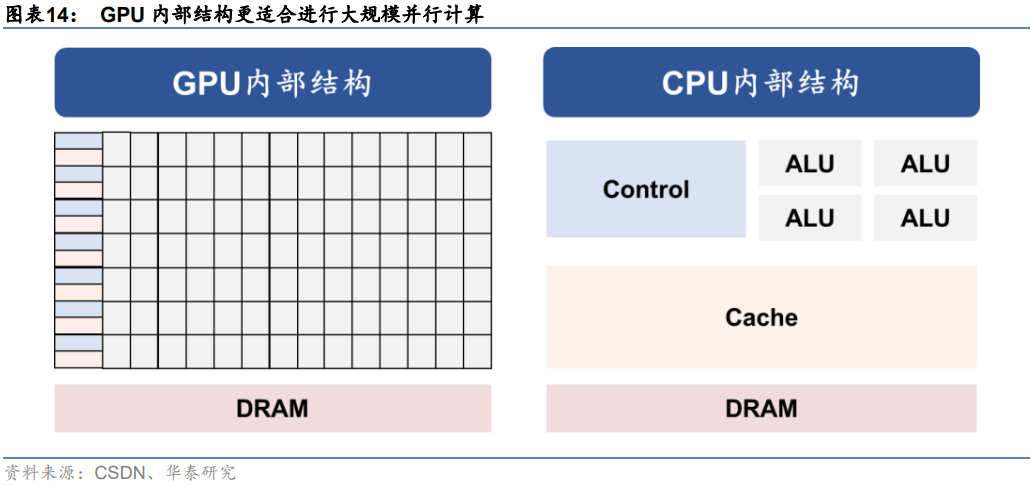
AI服務器采取GPU架構,相較CPU更適合進行大規模并行計算。通用服務器采用CPU作為計算能力來源,而AI服務器為異構服務器,可以根據應用范圍采用不同的組合方式,如CPUGPU、CPUTPU、CPU其他加速卡等,主要以GPU提供計算能力。從ChatGPT模型計算方式來看,主要特征是采用了并行計算。對比上一代深度學習模型RNN來看,Transformer架構下,AI模型可以為輸入序列中的任何字符提供上下文,因此可以一次處理所有輸入,而不是一次只處理一個詞,從而使得更大規模的參數計算成為可能。而從GPU的計算方式來看,由于GPU采用了數量眾多的計算單元和超長的流水線,因此其架構設計較CPU而言,更適合進行大吞吐量的AI并行計算。
深度學習主要進行矩陣向量計算,AI服務器處理效率更高。從ChatGPT模型結構來看,基于Transformer架構,ChatGPT模型采用注意力機制進行文本單詞權重賦值,并向前饋神經網絡輸出數值結果,這一過程需要進行大量向量及張量運算。而AI服務器中往往集成多個AI GPU,AI GPU通常支持多重矩陣運算,例如卷積、池化和激活函數,以加速深度學習算法的運算。因此在人工智能場景下,AI服務器往往較GPU服務器計算效率更高,具備一定應用優勢。

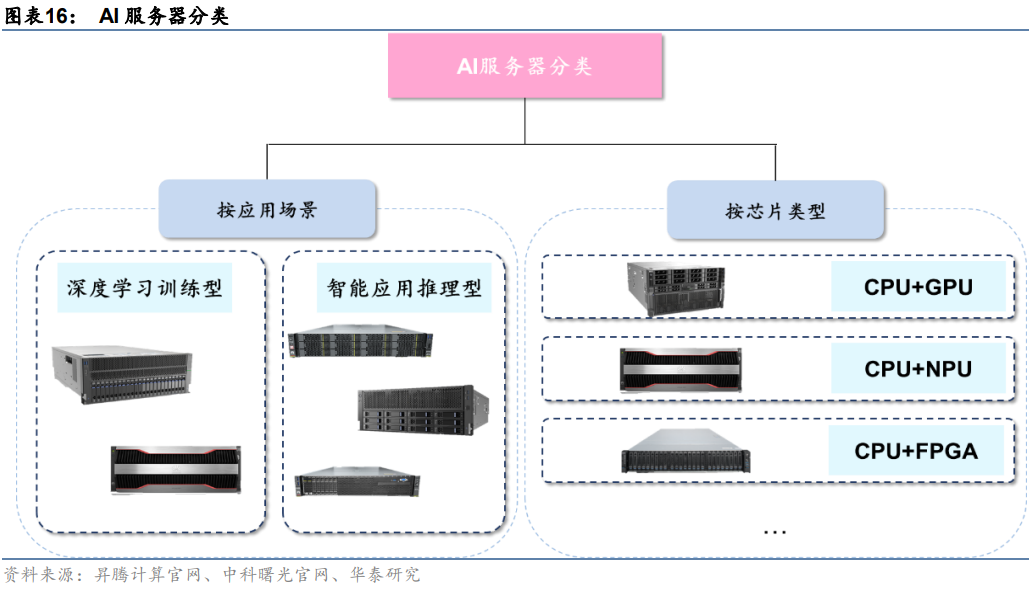
AI服務器分類方式有兩種:
1)按應用場景:AI服務器按照應用場景可以分為深度學習訓練型和智能應用推理型。訓練任務對服務器算力要求較高,需要訓練型服務器提供高密度算力支持,典型產品有中科曙光X785-G30和華為昇騰Atlas 800(型號9000、型號9010)。推理任務則是利用訓練后的模型提供服務,對算力無較高要求,典型產品有中科曙光X785-G40和華為昇騰Atlas 800(型號3000、型號3010)。
2)按芯片類型:AI服務器為異構服務器,可以根據應用范圍調整計算模塊結構,可采用CPU+GPU、CPU+FPGA、CPU+TPU、CPU+ASIC或CPU+多種加速卡等組合形式。目前,產品中最常見的是CPU+多塊GPU的方式。
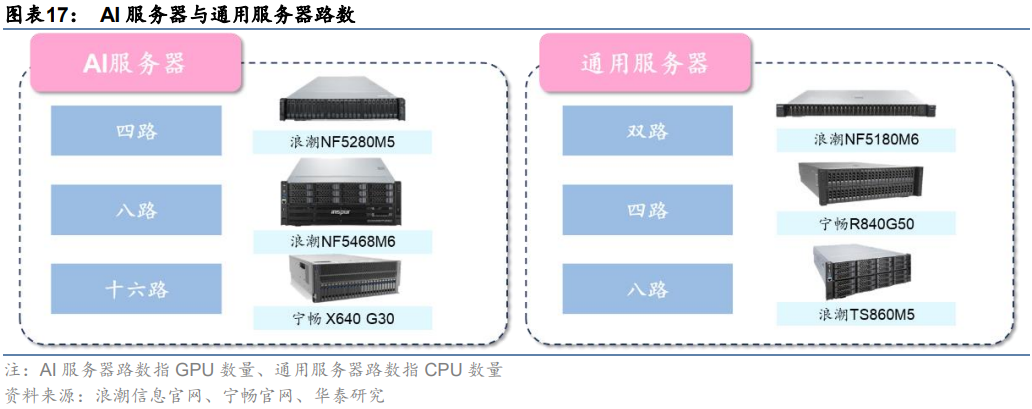
常見的AI服務器分為四路、八路、十六路。一般來說,通用服務器主要采用以CPU為主導的串行架構,更擅長邏輯運算;而AI服務器主要采用加速卡為主導的異構形式,更擅長做大吞吐量的并行計算。按CPU數量,通用服務器可分為雙路、四路和八路等。雖然AI服務器一般僅搭載1-2塊CPU,但GPU數量顯著占優。按GPU數量,AI服務器可以分為四路、八路和十六路服務器,其中搭載8塊GPU的八路AI服務器最常見。
AI服務器采用多芯片組合,算力硬件成本更高。我們以典型服務器產品為例拆解硬件構成,可以更清晰地理解兩類服務器硬件架構區別:以浪潮通用服務器NF5280M6為例,該服務器采用1~2顆第三代Intel Xeon可擴展處理器,據英特爾官網,每顆CPU售價約64000萬元,故該服務器芯片成本約64000~128000;以浪潮AI服務器NF5688M6為例,該服務器采用2顆第三代Intel Xeon可擴展處理器+8顆英偉達A800 GPU的組合,據英偉達官網,每顆A800售價104000元,故該服務器芯片成本約96萬元。
5、ChatGPT需要的芯片:CPU+GPU、FPGA、ASIC
GPT模型訓練需要大算力支持,或將帶來AI服務器建設需求。我們認為,隨著國內廠商陸續布局ChatGPT類似產品,GPT大模型預訓練、調優及日常運營或將帶來大量算力需求,進而帶動國內AI服務器市場放量。以GPT-3 175B模型預訓練過程為例,據OpenAI,進行一次GPT-3 175B模型的預訓練需要的算力約3640 PFlop/s-day。我們假設以浪潮信息目前算力最強的AI服務器NF5688M6(PFlop/s)進行計算,在預訓練期限分別為3、5、10天的假設下,單一廠商需采購的AI服務器數量分別為243、146、73臺。

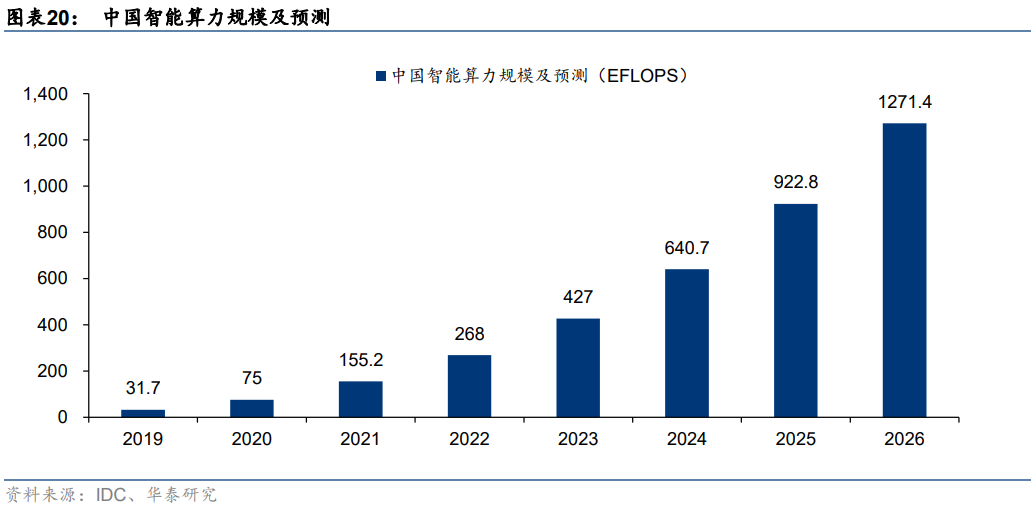
AI大模型訓練需求火熱,智能算力規模增長有望帶動AI服務器放量。據IDC數據,以半精度(FP16)運算能力換算,2021年中國智能算力規模約155.2EFLOPS。隨著AI模型日益復雜、計算數據量快速增長、人工智能應用場景不斷深化,未來國內智能算力規模有望實現快速增長。IDC預計2022年國內智能算力規模將同比增長72.7%至268.0 EFLOPS,預計2026年智能算力規模將達1271.4 EFLOPS,2022-2026年算力規模CAGR將達69.2%。我們認為,AI服務器作為承載智能算力運算的主要基礎設施,有望受益于下游需求放量。
編輯:黃飛
?

















 工商網監
工商網監
評論