 電子發燒友App
電子發燒友App


一、背景
Object-based SLAM: SLAM就是機器人同步定位與建圖,通過一些傳感器的測量數據同時去建立環境的地圖,且利用這個地圖對于機器人的狀態進行估計,機器人的狀態包括機器人的位姿、速度和機器人的參數,比如內參。環境地圖包括比如點的位置,線的位置,面的位置。常見的SLAM系統由前端和后端組成,如圖1所示,前端一般從一些原始的傳感器數據中采集一些特征,后端利用概率的推斷模型對采集的模型進行融合生成全局一致的環境地圖。
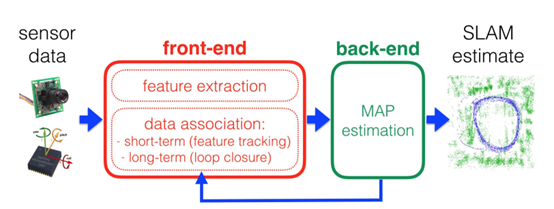
圖1 SLAM結構
要知道環境中有哪些物體,就需要進行物體級SLAM,簡單而言就是以物體為目標的SLAM系統,對物體和機器人的狀態進行估計,如圖2所示。一個是對空間中的幾何體加上語義信息,對下游的任務有作用,另一個是非常節省存儲空間的表示。如果用稠密點云就需要用很多的存儲空間,但是基于物體級的SLAM形成的表示是非常輕量化的描述。

圖2 物體級SLAM
如何做Object SLAM? 和廣泛SLAM類似,首先要在原始的測量數據中提取特征,使用物體的感知模型,包括二維的目標檢測,也包括實例分割。今天涉及的是六自由度物體估計目標檢測,后端也是用概率推斷模型對于多幀進行融合生成全局一致的地圖。圖3列舉了一些目標SLAM的文章和方法。
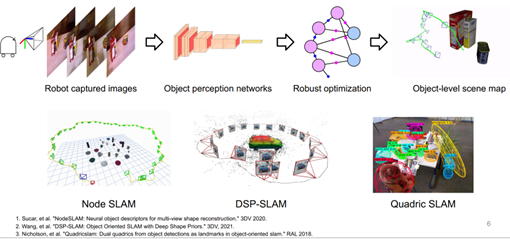
圖3 相關SLAM方法和文章
為什么object SLAM是比較困難的問題? 因為有一些廣泛的SLAM具有的挑戰,也面臨一些新的挑戰。廣泛的challenge包括ambiguous data assosiation的問題,比如在一個停車場檢測到一輛車,那么怎么把真的觀測和地圖里面的進行關聯,那么哪一輛車是當前被觀測的車呢?另外一個問題就是動態的問題,比如有一個車在行進,如何判斷這輛車是在行進,如何防止這個行進的車對相機跟蹤產生影響,然后如何根據這個車的行進去不斷地更新地圖,這些問題是比較難解決的。新的挑戰主要是源于引入了object perception model,這兩個模型結合的過程中就會產生一些information瓶頸,比如在deep learning model做出一些預測的時候,很難對不確定性進行量化,很難知道預測是好是壞。 在這種情況下如何去使用深度學習的model,如何給觀測賦權重是一個比較困難的問題。
另外,一個比較重要的在object SLAM領域中的問題就是domain gap問題,在新的環境中會有性能下降的問題。就是在訓練perception model的時候,一般在特定環境中采取數據,給數據添加標注,用這些標注的數據訓練網絡。但當使用或測試這個網絡時,往往在一個新環境中測試,訓練和測試環境之間很可能有一些區別,比如光照的不同,背景的不同,噪聲情況的不同,這個差異會使測試數據和訓練數據造成分布不匹配的問題,這個問題就是一個domain gap的問題。還會導致perception model性能下降的問題。合成數據在真實情況中使用時,它的效果會大打折扣。 希望能夠做到的表現是機器人在探索不同環境的時候,能夠自動的適應當前的環境,把它的perception model調整到比較好的性能狀態。這里對于object SLAM的介紹告一段落,如果感興趣可以在面4的主頁中關注。
圖4 主頁
二、方法介紹
什么是6自由度物體位姿估計? 如圖5所示,圖片中有物體,然后通過模型計算物體相對于相機的位姿,這個位姿包括3自由度的旋轉和3自由度的平移,所以稱它為6自由度的物體位姿估計。具有代表性的工作,比如說CNN和今天會涉及到的方法。
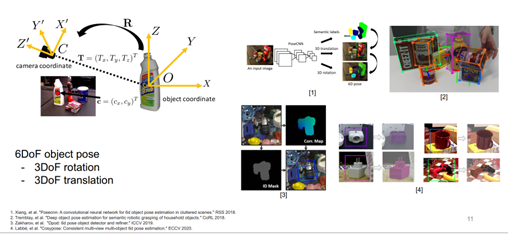
圖5 6自由度的物體位姿估計
今天要探討的不是如何去設計一個更好的6自由度位姿估計,而是在真實場景中的表現如何,把它從文章中拿出來,和其他的位姿模型在同樣的benchmark中進行對比它們的表現最終如何。 BOP方法進行6自由度位姿估計,然后這個benchmark它的目標就是這樣的表現,模型對應的物體是剛性物體,它們的輸入是RGB和RGBD的圖像。BOP challenge根據指標對不同的model進行打分,然后分數比較高的就可以獲得獎項,每年的會議上都有BOP challenge的workshop,介紹如圖6所示。

圖6 BOP六維物體位姿估計 BOP challenge在2019年的結果,在這一年有很多方法在一些task上去競爭,表1列舉了不同方法的性能比較,按照性能從高到低排列。可以看到這一年的經典方法就是基于這種特征的方法是由于基于深度學習方法的。 表1 BOP challenge性能比較
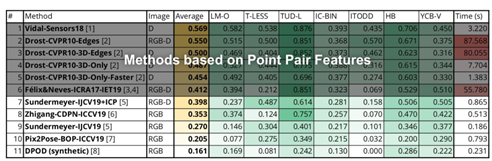
針對上面的問題給出解釋,首先缺乏在真實世界中訓練的圖片,還有真實的測試圖片和通常使用的合成的訓練圖片之間有比較大的domain gap。這兩個原因屬于一個問題,就是缺少在真實環境或者測試環境中帶有6自由度物體標注的數據。 為了解決這個問題,有哪些方案呢?一種解決方案就是去提高合成數據的真實性,生成更加成熟的數據,另一種方案是可以利用test devirament沒有標注的數據去提高表現。需要用到文章使用的self-training。Semi-supervised learning結合一些帶有標簽和數據和不帶有標簽的數據去提高模型的預測性能。 為什么這樣的事情能夠成功呢?
為什么能夠用不帶有標簽的數據去提高性能呢?因為不帶標簽的數據上往往攜帶了對于預測的task有用的一些信息。比如霧天的數據是不帶標簽的數據的話,那它就攜帶了這種background的信息,這樣的信息有可能被提出的semi-supervised learning的方法學習到,提高模型的表現。不幸的是,Semi-supervised learning大部分的方法都沒有對于收斂的一個保證,很可能越去訓練它這個模型的表現越差,因為預報的一些錯誤的在這個訓練過程中會不斷的加強自身導致的。
什么是self-training? self-training是比較早期的方法,用學習模型的預測去提高模型預測的能力。圖7是具體的流程圖,首先從一些帶有標簽的數據開始去訓練Deep CNN model,然后用模型在不帶標簽的數據上預測,再把這些預測當做新的標簽,這些標簽就叫做偽標簽,并不是真實的標簽,是模型的預測。這些偽標簽可能會有好有壞,為了選出好的偽標簽,需要使用selection algorithm選出里面高質量的label形成一些帶有偽標簽的數據。把這些帶有偽標簽的數據和原始的帶有真實標簽的預訓練的數據結合在一起,微調或重新訓練網絡。 可以看到,整個流程圖中比較重要的一環就是選擇算法,如果通過這個算法能夠成功的選擇出高質量的數據的話,就可以提高性能表現,反之可能會降低性能表現。
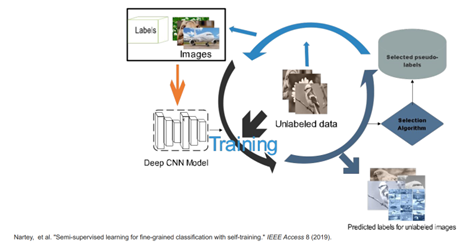
圖7 self-training流程圖 對于文章SLAM-supported self-training for 6D object pose estimation,首先是一些動機,為什么要做6自由度物體的位姿估計,因為它可以給出這些環境中的幾何和語義的信息,如圖8所示。
圖8 環境的幾何和語義信息
在一個環境中訓練,在另外一個環境中測試,就會存在domain gap問題。這個問題的表現展示了一個video可視化問題,在合成數據上訓練,有了真實數據再測試,可以看到它很難對這些物體進行正確的預測。那么如何去解決這樣的問題呢?一種最簡單的方式就是在測試數據中采集一些數據,給這些數據加上物體位姿的標注,然后微調6自由度位姿估計器。
但是,整個6自由度物體位姿標注的過程非常費時費力,更重要的一點是希望機器人在探索不同環境的時候是不被打斷的,假如機器人進入到新的環境,還要去標注這個新環境的數據,那它對機器人的自主運行就是一個很不利的事情。所以希望做的就是機器人能夠自己去給它采集到的數據進行標注,做一個self label。
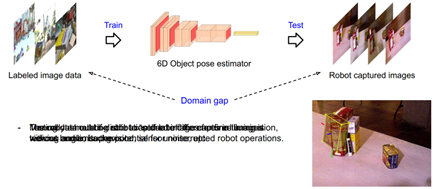
圖9 domain gap問題
應運而生,有一些方法來解決問題,一般用合成帶有標簽的數據和一些真實不帶標簽的數據一起去提高位姿估計的性能。如圖10所示,它們可以分為single-view methods和Multi-view methods,前者輸入的數據是無序的,但是一般機器人采集的數據都是按照一定的次序采集的,會有時間和空間上的連續性。single-view不能利用連續性,于是利用Multi-view方法,融合不同視角對于物體位姿的估計來形成更加可靠的對于物體的理解,用這個更加可靠的位姿對一些數據做標注,再微調,但大部分需要高精度相機的運動信息。
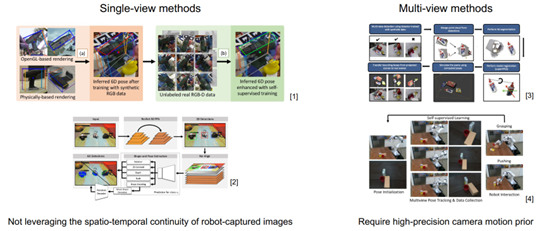
圖10 single-view方法和multi-view方法
于是,提出了一種用SLAM來支持的方法,通過機器人采集的數據把它放到一個這種魯棒的物體級SLAM的系統里面,然后生成一個全局一致的,包括相機的位姿和物體的位姿,然后生成一些偽標簽,利用一致性的標簽作為新的訓練數據去微調位姿估計模型,如圖11所示。
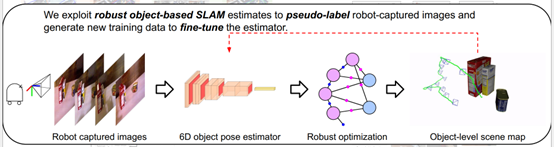
圖11 SLAM支持的方法
方法的流程圖如圖12所示,從帶有標簽的圖片數據入手,預訓練一個6D的物體位姿估計器,把這個估計器放在機器人上,在行進過程中對物體的位姿進行估計,然后聯合物體的位姿估計和機器人的里程計形成位姿圖。用提出的一些魯棒的優化方法求解SLAM估計,包括機器人的位姿和物體的位姿,從這些模型所預測的物體位姿和優化的位姿物體之中選出比較高質量的物體位姿作為偽標簽,把它和原始的帶有真實標簽的數據進行融合。整個流程圖和self-training是一樣的過程,從宏觀上來看,方法左半邊是在做一個魯棒的狀態估計,形成全局一致的場景地圖,右半邊實際上是在用semi-supervised learning提高物體位姿估計的性能,方法結合了兩方面的一個成果。
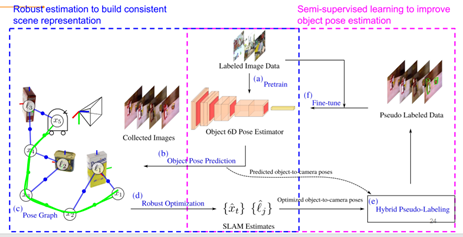
圖12 方法流程圖
如何進行魯棒的位姿圖優化來得到比較可靠的SLAM估計?提出了一種自動協方差調整的位姿圖優化,這里如果展開講可能需要很長時間,在這邊只做一個比較宏觀的介紹。如果大家有興趣,可以去文章中的相關章節看到比較細節的公式推導。 首先要考慮為什么要做這樣一個自動協方差的調整,一般在做位姿圖估計的過程中會假設觀測是符合高斯分布的,這樣就能把問題轉換為一個非線性最小二乘問題去求解,為了指定這樣的高斯分布,需要兩個量,一個是期望,一個是方差,對于高維的高斯分布需要一個期望和一個協方差矩陣。
期望很好得到,可以通過SLAM估計還有測量模型計算每個測量的期望值,但協方差一般都是經驗性的給出一個值,在實際中根據對于傳感器噪聲大小的一個理解去制定這樣的協方差值,比如傳感器的噪聲比較大,給一個比較大的協方差矩陣,反之給一個比較小的協方差矩陣。 現在對于物體位姿的估計都是從深度學習模型得到的,也就是說傳感器變成了模型,對噪聲沒有非常可靠的理解,預測沒有辦法很好的量化。
在這種情況下,如何指定協方差矩陣?提出的方案是不指定協方差矩陣,把協方差矩陣和SLAM的變量進行聯合優化,如圖13所示,在公式里展示。第一項代表物體位姿的損失值,最后一項是機器人里程計的損失值,第一項是正則化項,目的是防止值跑到正無窮,像零這個方向去正則化。 求解聯合優化的問題是用的alternating minimization方法,這個方法有兩個優勢,第一個優勢是對最優的協方差矩陣有一個解析解,第二個好處是可以在分量級別對協方差矩陣進行擬合。得到位姿預測時,對六個自由度的分量進行不同程度的擬合,與傳統方法相比更加靈活,也能夠擬合更廣泛的噪聲模型。
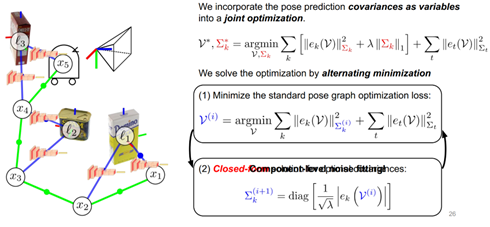
圖13 自動協方差調整公式推導
如圖14所示是hybrid pseudo-labeling方法,在兩種位姿中選取高質量的偽標簽。
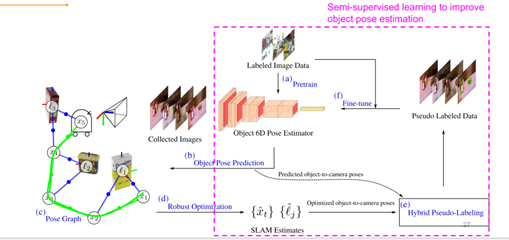
圖14 hybrid pseudo-labeling方法
如圖15所示,Hybrid model利用了兩種數據,一種數據是模型直接在圖片上預測的物體位姿,另一種是通過優化得到的物體位姿,為了對位姿進行好壞的評估,有兩種評估方法,一種利用幾何信息,另一種利用視覺信息,幾何信息使用卡方測試,預測的物體位姿是否和優化的物體位姿有顯著的差異,如果有顯著差異可能是比較差的位姿估計,反之是比較好的位姿估計。視覺檢查根據物體位姿估計生成一個渲染圖片,把渲染物體和真實物體對比,轉換到特征空間,在特征空間上的向量看它們是不是相似。經過這兩個check,就能得到比較高質量的位姿標簽數據。
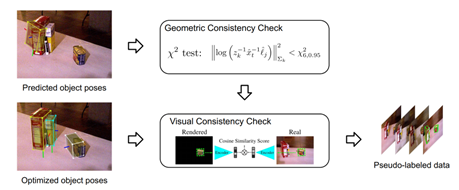
圖15 Hybrid model 提出方法的結果
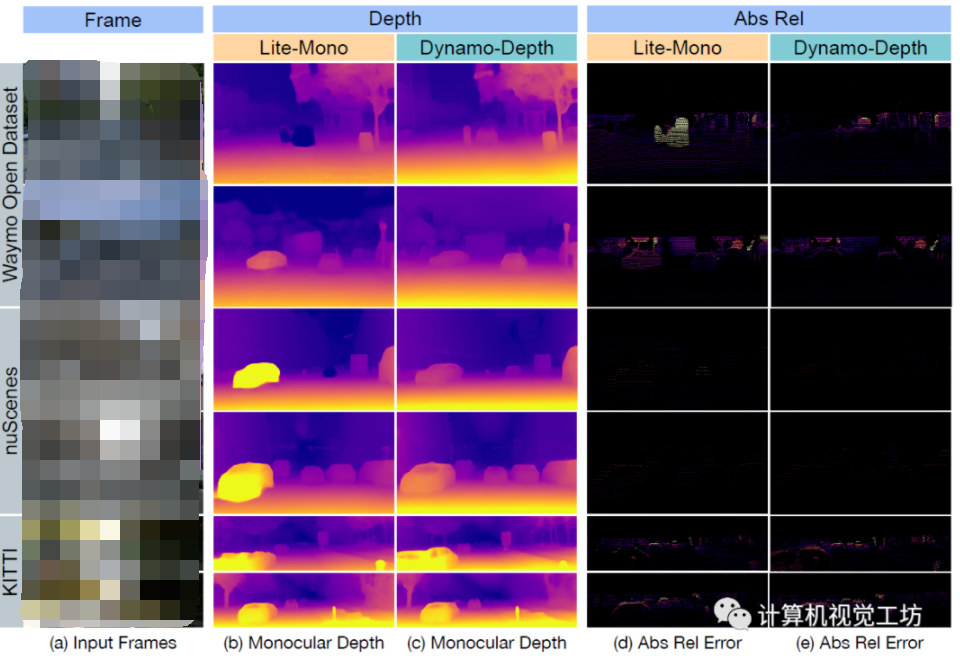
如圖16所示,在兩個數據集上進行實驗,并測試方法。第一個數據集是一個公開數據集,叫做YCB video experiment。首先用一些合成數據去預訓練,然后拿到模型上進行self-training。值得強調的是,在進行self-training時,不去使用這些label標注,完全通過self-training生成標注,最后一步就是把self-training后的放在上面去評估表現。Video展示的是它們在測試集的表現,就是在self-training之前和之后進行的對比,可以看到self-training后性能更加穩定,能夠檢測出更多物體,也有更少離群的位姿估計。

圖16 提出方法的結果
如圖17所示,第二個實驗是在真實車上面做的實驗,把相機放在機器人上,圍繞物體進行導航。做真實機器人實驗的目的就是為了測試方法對于挑戰的可行性,提出方法在運動模糊等情況下依然可以得到比較好的性能,比較多的提高訓練后的表現,離群值很少。

圖17 真實車實驗
三、總結和未來展望
提出的方法是魯棒性SLAM所支持的6自由度物體位姿估計的自訓練方法,目的是希望做優化,方法能夠適應新的環境。最重要的一環是提出的自動協方差調整的位姿圖優化方法,最后通過實驗驗證了方法的表現。如圖18所示,右上角有文章和代碼的鏈接,感興趣可以去看一下。
?
?最后就是如何去延伸工作,首先可以給系統加入對動態物體的處理,如何考慮它的影響,或者某些物體有對稱性的物體位姿如何處理,以及魯棒性的半監督學習,還有很多更新的方法進一步提高表現,最后可以把對于物體級別的性能提升擴展到對于物體位姿形狀和類別進行估計,用更加可靠的結果訓練,然后估計。當然可以很多其他的方面,由于時間的分享,討論告一段落。
四、問題:
1.深度學習對于堆疊物體位姿估計有什么建議嗎? 可以看一些對于這塊研究的設計方法的文章,如果對這塊理解的不是特別深入,也可以看一下深藍學院的相關課程。
2.在利用深度學習的方法進行6自由度物體位姿估計時,如果要建立RGBD數據集的話,有什么好的方法推薦嗎? 我的理解是如何選擇采集到的RGBD圖片對不對,可以在網上找一些圖,然后放在tool中進行學習產生標注。可以使用優化方法只采用標注關鍵幀的方法,利用優化進行復制,有效快速的標注。
3.得到偽標簽以后,再訓練網絡是不是需要離線進行?這樣SLAM是否就要停下了? 是的,這個說法是正確的,采集到偽標簽數據時,需要訓練位姿估計的模型,需要較長的時間,當前大多數模型都需要較長時間,如果未來有更好的方法在短時間內進行訓練,也希望可以在線進行。
4.實驗小車的處理器什么配置?方法實現在線實時嗎? 在實驗中采取的小車是jerk robot,只是去用它作為一個相機支架圍繞物體變成目標,如果要了解的話可以了解這個機器人的內部構造。
5.實現的方法是單目還是rgbd的? 方法是單目的。
6.如果SLAM需要停止的話,那么SLAM的作用不就相當于收集數據集嗎? 是的,這個方法的提出自動收集數據集的過程,可能傳到云端,有服務的話可以很快的訓練,也就不需要停止很久。
7.最后檢測的物體仍然是預訓練里面已有的物體嗎? 是的。
8.即使不使用SLAM,手動收集數據集也可以,另外方法對SLAM的過程有哪些提高? 手動收集是可以的,但大部分都是在公開數據集中進行分析,然后對它進行使用。它的問題在于在真實環境中對機器人環境探索,很難有人一直跟著機器人,希望機器人自主做label的。提高主要是自動的產生標簽,可以用這個過程優化協方差模型。
編輯:黃飛
?




















 工商網監
工商網監
評論