 電子發(fā)燒友App
電子發(fā)燒友App


AI 時(shí)代的曙光就在這里,了解 AI 驅(qū)動(dòng)軟件的成本結(jié)構(gòu)與傳統(tǒng)軟件有很大差異至關(guān)重要。芯片微架構(gòu)和系統(tǒng)架構(gòu)在這些創(chuàng)新軟件的開發(fā)和可擴(kuò)展性方面發(fā)揮著至關(guān)重要的作用。運(yùn)行軟件的硬件基礎(chǔ)設(shè)施對(duì)資本支出和運(yùn)營(yíng)支出以及隨后的毛利率有明顯更大的影響,這與前幾代軟件相比,前幾代軟件的開發(fā)人員成本相對(duì)較高。因此,更加重要的是要投入大量精力來(lái)優(yōu)化您的 AI 基礎(chǔ)設(shè)施,以便能夠部署 AI 軟件。在基礎(chǔ)設(shè)施方面具有優(yōu)勢(shì)的公司在使用 AI 部署和擴(kuò)展應(yīng)用程序的能力方面也將具有優(yōu)勢(shì)。
谷歌早在 2006 年就提出了構(gòu)建 AI 專用基礎(chǔ)設(shè)施的想法,但這個(gè)問題在 2013 年達(dá)到了定點(diǎn)。他們意識(shí)到,如果他們想以任何規(guī)模部署 AI,就需要將現(xiàn)有數(shù)據(jù)中心的數(shù)量增加一倍。因此,他們開始為 2016 年投入生產(chǎn)的 TPU 芯片奠定基礎(chǔ)。將此與亞馬遜進(jìn)行比較很有趣,亞馬遜在同一年意識(shí)到他們也需要構(gòu)建定制芯片。
自 2016 年以來(lái),谷歌現(xiàn)已構(gòu)建了 6 種不同的 AI 芯片,TPU、TPUv2、TPUv3、TPUv4i、TPUv4 和 TPUv5。谷歌主要設(shè)計(jì)了這些芯片,并與博通進(jìn)行了不同程度的中后端合作。這些芯片全部由臺(tái)積電代工。自 TPUv2 以來(lái),這些芯片還使用了三星和 SK 海力士的 HBM 內(nèi)存。雖然谷歌的芯片架構(gòu)很有趣,我們將在本報(bào)告的后面深入探討,但還有一個(gè)更重要的話題在起作用。
谷歌擁有近乎無(wú)與倫比的能力,能夠以低成本和高性能可靠地大規(guī)模部署人工智能。話雖如此,讓我們?yōu)檫@個(gè)論點(diǎn)帶來(lái)一些合理性,因?yàn)楣雀枰沧龀隽伺c芯片級(jí)性能相關(guān)的虛偽聲明,需要糾正。我們認(rèn)為,由于谷歌從微架構(gòu)到系統(tǒng)架構(gòu)的整體方法,與微軟和亞馬遜相比,谷歌在 AI 工作負(fù)載方面具有性能/總擁有成本 (perf/TCO) 優(yōu)勢(shì),而將生成人工智能商業(yè)化給企業(yè)和消費(fèi)者的能力是一個(gè)不同的討論。
技術(shù)領(lǐng)域是一場(chǎng)永無(wú)休止的軍備競(jìng)賽,人工智能是移動(dòng)最快的戰(zhàn)場(chǎng)。隨著時(shí)間的推移,經(jīng)過(guò)訓(xùn)練和部署的模型架構(gòu)發(fā)生了顯著變化。案例和重點(diǎn)是谷歌的內(nèi)部數(shù)據(jù)。CNN 模型在 2016 年到 2019 年迅速上升,但隨后又下降了。與 DLRM、Transformers 和 RNN 相比,CNN 在計(jì)算、內(nèi)存訪問、網(wǎng)絡(luò)等方面具有非常不同的配置文件。同樣的情況也發(fā)生在完全被 Transformer 取代的 RNN 上。
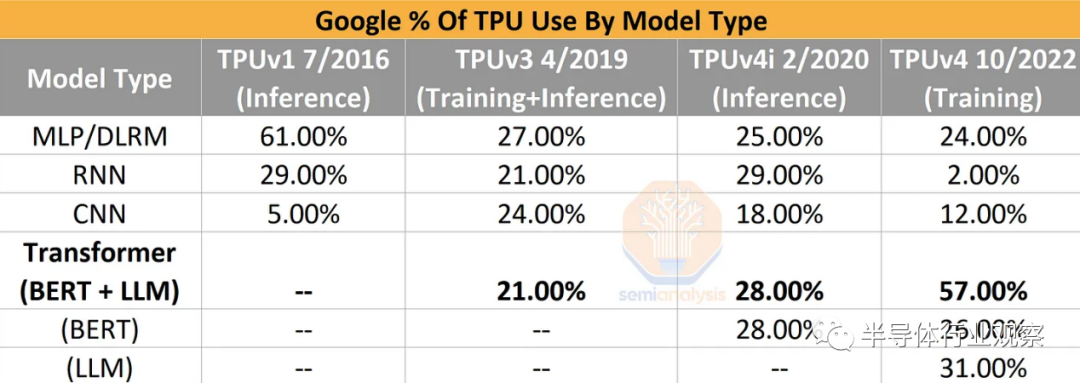
因此,硬件必須靈活地適應(yīng)行業(yè)的發(fā)展并支持它們。底層硬件不能過(guò)度專注于任何特定的模型架構(gòu),否則它可能會(huì)隨著模型架構(gòu)的變化而變得過(guò)時(shí)。芯片開發(fā)到大規(guī)模部署一般需要 4 年時(shí)間,因此,硬件可以被軟件想在其上做的事情拋在腦后。這已經(jīng)可以從使用特定模型類型作為優(yōu)化點(diǎn)的初創(chuàng)公司的某些 AI 加速器架構(gòu)中看出。這是大多數(shù) AI 硬件初創(chuàng)公司已經(jīng)/將要失敗的眾多原因之一。
這一點(diǎn)在谷歌自己的 TPUv4i 芯片上尤為明顯,該芯片專為推理而設(shè)計(jì),但無(wú)法在谷歌最好的模型(如 PaLM)上運(yùn)行推理。上一代 Google TPUv4 和 Nvidia A100 不可能在設(shè)計(jì)時(shí)考慮到大型語(yǔ)言模型。同樣,最近部署的谷歌 TPUv5 和 Nvidia H100 不可能在設(shè)計(jì)時(shí)考慮到”AI墻”,也沒有為解決它而開發(fā)的新模型架構(gòu)策略。這些策略是 GPT-4 模型架構(gòu)的核心部分。
硬件架構(gòu)師必須對(duì)機(jī)器學(xué)習(xí)在他們?cè)O(shè)計(jì)的芯片中的發(fā)展方向做出最好的猜測(cè)。這包括內(nèi)存訪問模式、張量大小、數(shù)據(jù)重用結(jié)構(gòu)、算術(shù)密度與網(wǎng)絡(luò)開銷等。
此外,芯片微架構(gòu)只是人工智能基礎(chǔ)設(shè)施真實(shí)成本的一小部分。系統(tǒng)級(jí)架構(gòu)和部署靈活性是更為重要的因素。今天,我們想深入探討 Google 的 TPU 微架構(gòu)、系統(tǒng)架構(gòu)、部署切片、可擴(kuò)展性,以及他們?cè)诨A(chǔ)設(shè)施方面與其他技術(shù)巨頭相比的巨大優(yōu)勢(shì)。這包括我們?cè)?TCO 模型中的想法,該模型將 Google 的 AI 基礎(chǔ)設(shè)施成本與 Microsoft、Amazon 和 Meta 的成本進(jìn)行比較。
我們還將從從業(yè)者的角度對(duì)大型模型研究、訓(xùn)練和部署進(jìn)行研究。我們還想深入研究 DLRM 模型,盡管目前是最大的大規(guī)模 AI 模型架構(gòu),但這些模型經(jīng)常被低估。此外,我們將討論 DLRM 和 LLM 模型類型之間的基礎(chǔ)設(shè)施差異。最后,我們將討論谷歌利用 TPU 為外部云客戶取得成功的能力。同樣在最后,我們認(rèn)為谷歌的 TPU 有一個(gè)異常的復(fù)活節(jié)彩蛋是一個(gè)錯(cuò)誤。
谷歌的系統(tǒng)基礎(chǔ)設(shè)施優(yōu)勢(shì)
谷歌在基礎(chǔ)設(shè)施方面的部分優(yōu)勢(shì)在于,他們始終從系統(tǒng)級(jí)的角度設(shè)計(jì) TPU。這意味著單個(gè)芯片很重要,但如何在現(xiàn)實(shí)世界的系統(tǒng)中一起使用它更為重要。因此,在我們的分析中,我們將逐層從系統(tǒng)架構(gòu)到部署使用再到芯片級(jí)別。
雖然從系統(tǒng)的角度思考,但他們的系統(tǒng)規(guī)模比谷歌更小、更窄。此外,直到最近,Nvidia 還沒有云部署方面的經(jīng)驗(yàn)。谷歌在其 AI 基礎(chǔ)設(shè)施方面最大的創(chuàng)新之一是在 TPU、ICI 之間使用自定義網(wǎng)絡(luò)堆棧。相對(duì)于昂貴的以太網(wǎng)和 InfiniBand 部署,此鏈接具有低延遲和高性能。它更類似于 Nvidia 的 NVLink。
谷歌的 TPUv2 可以擴(kuò)展到 256 個(gè) TPU 芯片,與 Nvidia 當(dāng)前一代 H100 GPU 的數(shù)量相同。他們使用 TPUv3 將這個(gè)數(shù)字增加到 1024,使用 TPUv4 增加到 4096。根據(jù)趨勢(shì)線,我們假設(shè)當(dāng)前一代 TPUv5 可以擴(kuò)展到 16,384 個(gè)芯片,而無(wú)需通過(guò)低效的以太網(wǎng)。雖然從大規(guī)模模型訓(xùn)練的性能角度來(lái)看這很重要,但更重要的是他們將其劃分以供實(shí)際使用的能力。

谷歌的 TPUv4 系統(tǒng)每臺(tái)服務(wù)器有 8 個(gè) TPUv4 芯片和 2 個(gè) CPU。此配置與 Nvidia 的 GPU 相同,后者配備 8 個(gè) A100 或 H100 服務(wù)器,每臺(tái)服務(wù)器 2 個(gè) CPU。單個(gè)服務(wù)器通常是 GPU 部署的計(jì)算單元,但對(duì)于 TPU,部署單元是更大的“slice”,由 64 個(gè) TPU 芯片和 16 個(gè) CPU 組成。這 64 個(gè)芯片通過(guò)直接連接的銅纜在 4^3 立方體中與 ICI 網(wǎng)絡(luò)內(nèi)部連接。

在這個(gè) 64 芯片單元之外,通信轉(zhuǎn)而轉(zhuǎn)移到光學(xué)領(lǐng)域。這些光收發(fā)器的成本是無(wú)源銅纜的 10 倍以上。
將此與 2023 Nvidia SuperPod 部署進(jìn)行比較,后者使用 NVLink 最多配備 256 個(gè) GPU,僅為 4096 的芯片的 2020 TPUv4 pod 的十六分之一。此外,基于 Nvidia 的第一方渲染和 DGX Superpod 系統(tǒng),Nvidia 顯然不太關(guān)注密度和網(wǎng)絡(luò)成本。Nvidia 的部署通常是每個(gè)機(jī)架 4 個(gè)服務(wù)器。
除了 4 臺(tái)服務(wù)器總共 32 個(gè) GPU 之外,通常,通信必須采用光學(xué)方式。因此,Nvidia 需要更多的光收發(fā)器來(lái)進(jìn)行大規(guī)模部署。
谷歌OCS
谷歌部署了其定制光開關(guān),它使用基于 mems 的微鏡陣列陣列在 64 個(gè) TPU slice之間切換。簡(jiǎn)短的總結(jié)是,谷歌聲稱他們的自定義網(wǎng)絡(luò)將吞吐量提高了 30%,使用的電力減少了 40%,資本支出減少了 30%,流程完成減少了 10%,并且在他們的網(wǎng)絡(luò)中減少了 50 倍的停機(jī)時(shí)間,
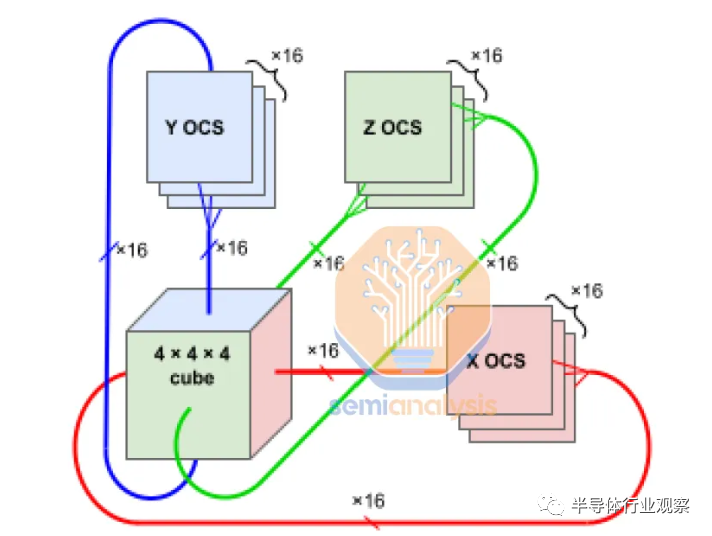
谷歌使用這些 OCS 來(lái)構(gòu)建其數(shù)據(jù)中心主干。他們還使用它們將 TPU pod 互連和內(nèi)部連接在一起。此 OCS 的一大優(yōu)勢(shì)是信號(hào)僅保留在光域中,從任何 64 TPU slice到 4096 TPU Pod 內(nèi)的任何其他 TPU slice。
將此與具有多個(gè) Nvidia SuperPods 的 4,096 個(gè) GPU 的 Nvidia GPU 部署進(jìn)行比較。該系統(tǒng)需要在這些 GPU 之間進(jìn)行多層切換,總共需要約 568 個(gè) InfiniBand 交換機(jī)。谷歌只需要 48 個(gè)光開關(guān)來(lái)部署 4096 個(gè) TPU。
應(yīng)該注意的是,與第三方從 Nvidia 購(gòu)買 Nvidia 的 InfiniBand 交換機(jī)相比,直接從 Google 的合同制造商處購(gòu)買時(shí), Google 的 OCS每個(gè)交換機(jī)的價(jià)格也高出 3.2 到 3.5 倍。不過(guò),這不是一個(gè)公平的比較,因?yàn)樗?Nvidia 約 75% 的數(shù)據(jù)中心毛利率。
如果我們只比較合同制造成本,谷歌的 IE 成本與 Nvidia 的成本;然后成本差異上升到 Nvidia InfiniBand 交換機(jī)的 12.8 到 14 倍。部署4096芯片所需的交換機(jī)數(shù)量為48 vs 568,IE為11.8x。Nvidia 的解決方案在交換機(jī)基礎(chǔ)上的制造成本更低。當(dāng)包括額外的光收發(fā)器的成本時(shí),這個(gè)等式趨于平衡或向有利于谷歌的方向移動(dòng)。
每層交換之間的每個(gè)連接都是另一個(gè)需要更多布線的點(diǎn)。雖然其中一些可以通過(guò)直接連接的銅纜完成,但仍有多個(gè)點(diǎn)的信號(hào)也需要通過(guò)光纖傳輸。這些層中的每一層都會(huì)在每一層切換之間從電轉(zhuǎn)換為光再轉(zhuǎn)換為電。這將使大型電氣開關(guān)系統(tǒng)的功耗遠(yuǎn)高于谷歌的OCS。
谷歌聲稱所有這些功率和成本的節(jié)省都非常大,以至于它們的網(wǎng)絡(luò)成本不到 TPU v4 超級(jí)計(jì)算機(jī)總資本成本的 5% 和總功率的不到 3%。這不僅僅是通過(guò)從電氣開關(guān)轉(zhuǎn)向內(nèi)部光開關(guān)來(lái)實(shí)現(xiàn)的。
通過(guò)拓?fù)渥钚』W(wǎng)絡(luò)成本
雖然谷歌大力推動(dòng)這一觀點(diǎn),但重要的是要認(rèn)識(shí)到 Nvidia 和 Nvidia 網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)完全不同。Nvidia 系統(tǒng)部署了“non-blocking”的“Clos 網(wǎng)絡(luò)”。這意味著它們可以同時(shí)在所有輸入和輸出對(duì)之間建立全帶寬連接,而不會(huì)發(fā)生任何沖突或阻塞。此設(shè)計(jì)提供了一種可擴(kuò)展的方法,用于連接數(shù)據(jù)中心中的許多設(shè)備、最大限度地減少延遲并增加冗余。
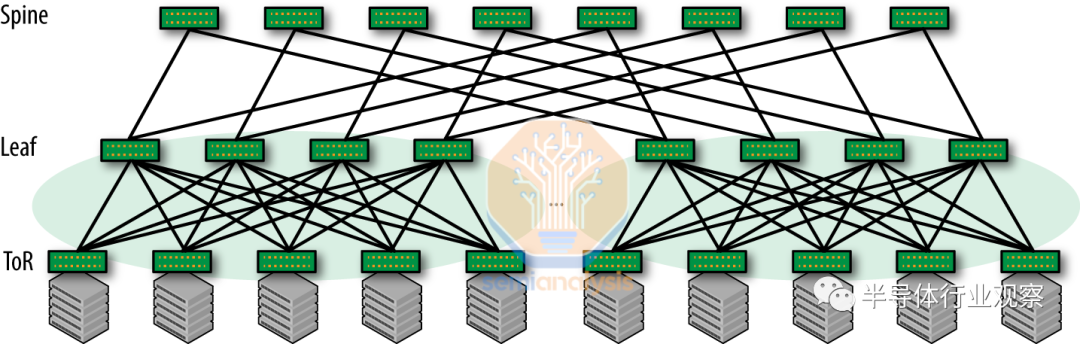
谷歌的 TPU 網(wǎng)絡(luò)放棄了這一點(diǎn)。他們使用 3D 環(huán)面拓?fù)溥B接三維網(wǎng)格狀結(jié)構(gòu)中的節(jié)點(diǎn)。每個(gè)節(jié)點(diǎn)都連接到網(wǎng)格中的六個(gè)相鄰節(jié)點(diǎn)(上、下、左、右、前和后),在三個(gè)維度(X、Y 和 Z)中的每一個(gè)維度上形成一個(gè)閉環(huán)。這創(chuàng)建了一個(gè)高度互連的結(jié)構(gòu),其中節(jié)點(diǎn)在所有三個(gè)維度上形成一個(gè)連續(xù)的循環(huán)。

第一張圖比較合乎邏輯,但如果你想一想有點(diǎn)餓了,這個(gè)網(wǎng)絡(luò)拓?fù)浜?jiǎn)直就是一個(gè)甜甜圈!

與 Nvidia 使用的 Clos 拓?fù)湎啾龋瑃orus 拓?fù)溆袔讉€(gè)優(yōu)點(diǎn):
更低的延遲:3D 環(huán)面拓?fù)淇梢蕴峁└偷难舆t,因?yàn)樗谙噜徆?jié)點(diǎn)之間有短而直接的鏈接。這在運(yùn)行需要節(jié)點(diǎn)之間頻繁通信的緊密耦合的并行應(yīng)用程序時(shí)特別有用,例如某些類型的 AI 模型。
更好的局部性:在 3D 環(huán)面網(wǎng)絡(luò)中,物理上彼此靠近的節(jié)點(diǎn)在邏輯上也很接近,這可以帶來(lái)更好的數(shù)據(jù)局部性并減少通信開銷。雖然延遲是一個(gè)方面,但功耗也是一個(gè)巨大的好處。
較低的網(wǎng)絡(luò)直徑:對(duì)于相同數(shù)量的節(jié)點(diǎn),3D 環(huán)面拓?fù)涞木W(wǎng)絡(luò)直徑低于 Clos 網(wǎng)絡(luò)。由于相對(duì)于 Clos 網(wǎng)絡(luò)需要更少的交換機(jī),因此可以節(jié)省大量成本。
另一方面,3D 環(huán)面網(wǎng)絡(luò)有很多缺點(diǎn)。
可預(yù)測(cè)的性能:Clos 網(wǎng)絡(luò),尤其是在數(shù)據(jù)中心環(huán)境中,由于其非阻塞特性,可以提供可預(yù)測(cè)和一致的性能。它們確保所有輸入輸出對(duì)都可以在全帶寬下同時(shí)連接,而不會(huì)發(fā)生沖突或阻塞,而這在 3D 環(huán)面網(wǎng)絡(luò)中是無(wú)法保證的。
更易于擴(kuò)展:在脊葉(spine-leaf )架構(gòu)中,向網(wǎng)絡(luò)添加新的葉交換機(jī)(例如,以容納更多服務(wù)器)相對(duì)簡(jiǎn)單,不需要對(duì)現(xiàn)有基礎(chǔ)設(shè)施進(jìn)行重大更改。相比之下,縮放 3D 環(huán)面網(wǎng)絡(luò)可能涉及重新配置整個(gè)拓?fù)洌@可能更加復(fù)雜和耗時(shí)。
負(fù)載平衡:Clos 網(wǎng)絡(luò)在任意兩個(gè)節(jié)點(diǎn)之間提供更多路徑,從而實(shí)現(xiàn)更好的負(fù)載平衡和冗余。雖然 3D 環(huán)面網(wǎng)絡(luò)也提供多條路徑,但 Clos 網(wǎng)絡(luò)中的備選路徑數(shù)量可能更多,具體取決于網(wǎng)絡(luò)的配置。
總的來(lái)說(shuō),雖然 Clos 有優(yōu)勢(shì),但谷歌的 OCS 減輕了其中的許多優(yōu)勢(shì)。OCS 支持在多個(gè)切片和多個(gè) pod 之間進(jìn)行簡(jiǎn)單縮放。
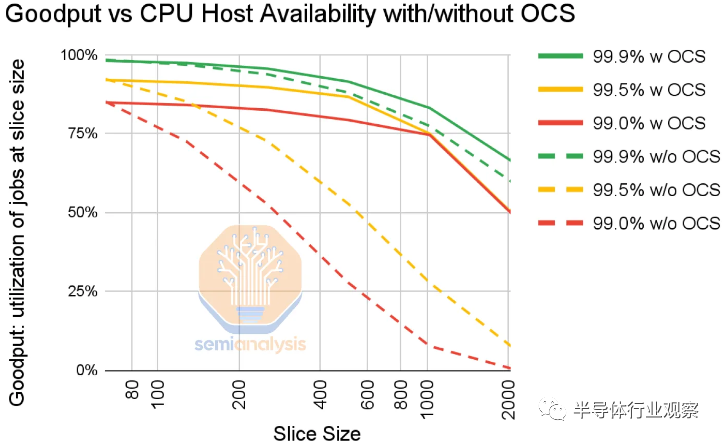
3D 環(huán)面拓?fù)涿媾R的最大問題是錯(cuò)誤可能是一個(gè)更大的問題。錯(cuò)誤可能會(huì)突然出現(xiàn)并發(fā)生。即使主機(jī)可用性為 99%,2,048 個(gè) TPU 的幻燈片也將具有接近 0 的正常工作能力。即使在 99.9% 的情況下,使用 2,000 個(gè) TPU 運(yùn)行的訓(xùn)練在沒有 Google 的 OCS 的情況下也有 50% 的有效輸出。
OCS 的美妙之處在于它支持動(dòng)態(tài)重新配置路由。
盡管有一些節(jié)點(diǎn)出現(xiàn)故障,但仍需要備件以允許調(diào)度作業(yè)。操作員無(wú)法在不冒失敗風(fēng)險(xiǎn)的情況下從 4k 節(jié)點(diǎn) pod 實(shí)際調(diào)度兩個(gè) 2k 節(jié)點(diǎn)切片。基于 Nvidia 的訓(xùn)練運(yùn)行通常需要過(guò)多的開銷,專門用于檢查點(diǎn)、拉出故障節(jié)點(diǎn)并重新啟動(dòng)它們。谷歌通過(guò)繞過(guò)故障節(jié)點(diǎn)路由在某種程度上簡(jiǎn)化了這一點(diǎn)。
OCS 的另一個(gè)好處是切片可以在部署后立即使用,而不是等待整個(gè)網(wǎng)絡(luò)。
部署基礎(chǔ)設(shè)施——用戶的視角
從成本和功耗的角度來(lái)看,基礎(chǔ)設(shè)施效率很高,允許谷歌每美元部署更多的 TPU,而不是其他公司可以部署的 GPU,但這意味著沒有任何用處。谷歌內(nèi)部用戶體驗(yàn)到的最大優(yōu)勢(shì)之一是他們可以根據(jù)自己的模型定制基礎(chǔ)設(shè)施需求。
沒有任何芯片或系統(tǒng)能夠匹配所有用戶想要的內(nèi)存、網(wǎng)絡(luò)和計(jì)算配置文件類型。芯片必須通用化,但與此同時(shí),用戶需要這種靈活性,他們不想要一種放之四海而皆準(zhǔn)的解決方案。Nvidia 通過(guò)提供許多不同的 SKU 變體來(lái)解決這個(gè)問題。此外,它們還提供一些不同的內(nèi)存容量層級(jí)以及更緊密的集成選項(xiàng),例如 Grace + Hopper 和為SuperPods準(zhǔn)備的 NVLink Network。
谷歌負(fù)擔(dān)不起這種奢侈。每個(gè)額外的 SKU 意味著每個(gè)單獨(dú) SKU 的總部署量較低。這反過(guò)來(lái)又降低了他們整個(gè)基礎(chǔ)設(shè)施的利用率。更多的 SKU 也意味著用戶更難在需要時(shí)獲得他們想要的計(jì)算類型,因?yàn)槟承┻x項(xiàng)將不可避免地被超額訂閱。然后,這些用戶將被迫使用次優(yōu)配置。
因此,谷歌面臨著一個(gè)棘手的問題,即向研究人員提供他們想要的確切產(chǎn)品,同時(shí)還要最大限度地減少 SKU 差異。與 Nvidia 必須支持其更大、更多樣化的客戶群的數(shù)百種不同規(guī)模的部署和 SKU 相比,谷歌恰好有 1 個(gè) TPUv4 部署配置,即 4,096 個(gè) TPU。盡管如此,谷歌仍然能夠以一種獨(dú)特的方式對(duì)其進(jìn)行slice和切塊,使內(nèi)部用戶能夠擁有他們想要的基礎(chǔ)設(shè)施的靈活性。
Google 的 OCS 還支持創(chuàng)建自定義網(wǎng)絡(luò)拓?fù)洌缗でh(huán)面網(wǎng)絡(luò)。這些是 3d 環(huán)面網(wǎng)絡(luò),其中某些維度是扭曲的,這意味著網(wǎng)絡(luò)邊緣的節(jié)點(diǎn)以非平凡、非線性的方式連接,從而在節(jié)點(diǎn)之間創(chuàng)建額外的捷徑。這進(jìn)一步提高了網(wǎng)絡(luò)直徑、負(fù)載平衡和性能。
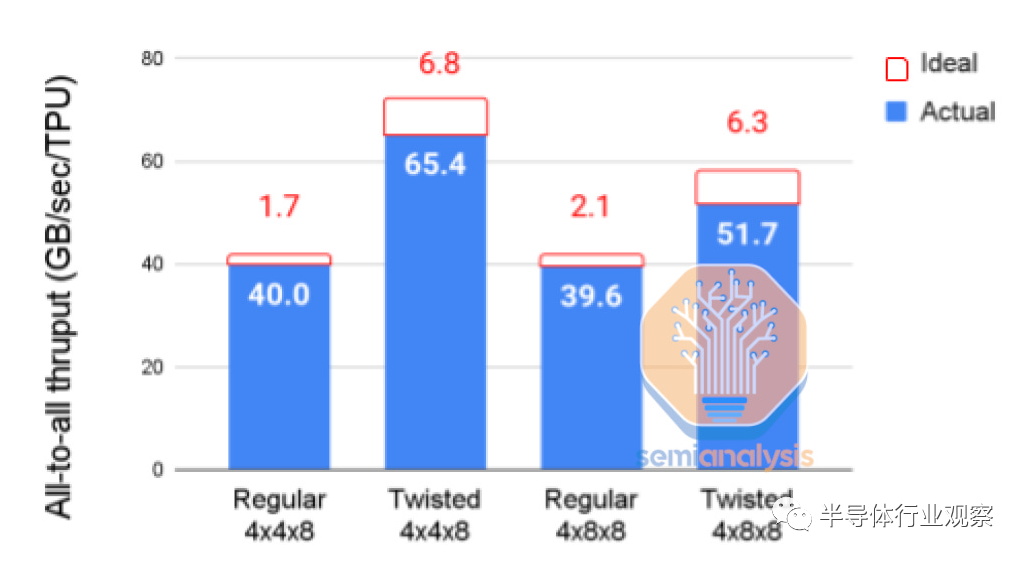
谷歌的團(tuán)隊(duì)充分利用這一點(diǎn)來(lái)協(xié)助某些模型架構(gòu)。以下是 2022 年 11 月僅 1 天的各種 TPU 配置的流行情況快照(按芯片數(shù)量和網(wǎng)絡(luò)拓?fù)洌S?30 多種不同的配置,盡管許多配置在系統(tǒng)中具有相同數(shù)量的芯片,以適應(yīng)正在開發(fā)的各種模型架構(gòu)。這是谷歌對(duì)他們使用 TPU 和靈活性的巨大深刻見解。此外,它們還有許多甚至未被描繪的較少使用的拓?fù)洹?/p>
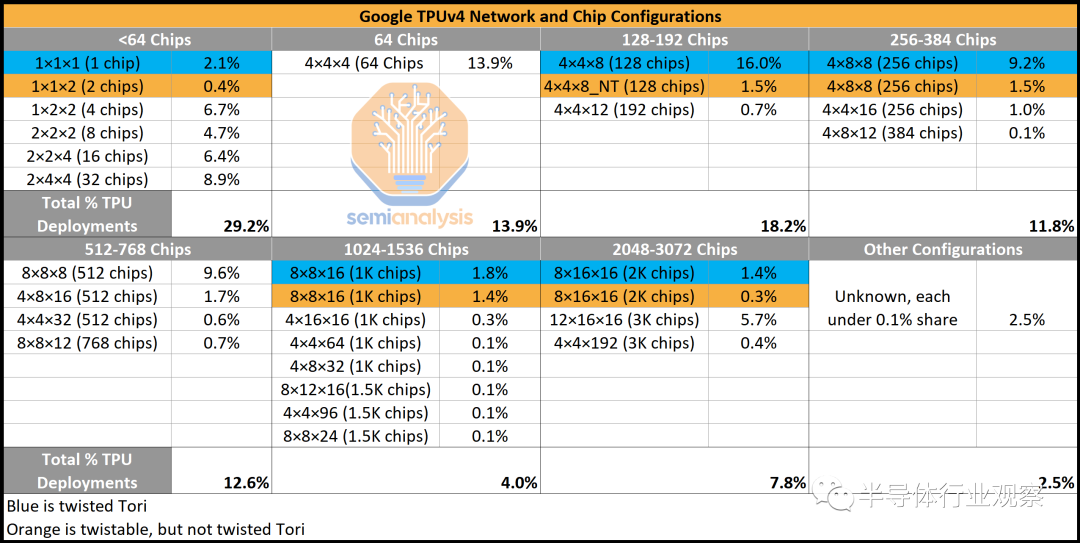
為充分利用可用帶寬,用戶沿 3D 環(huán)面的一個(gè)維度映射數(shù)據(jù)并行性,并在其他維度上映射兩個(gè)模型并行參數(shù)。谷歌聲稱最佳拓?fù)溥x擇可以使性能提高 1.2 到 2.3 倍。
規(guī)模最大的 AI 模型架構(gòu):DLRM
如果不討論深度學(xué)習(xí)推薦模型 (DLRM),任何關(guān)于 AI 基礎(chǔ)設(shè)施的討論都是不完整的。這些 DLRM 是百度、Meta、字節(jié)跳動(dòng)、Netflix 和谷歌等公司的支柱。它是廣告、搜索排名、社交媒體訂閱等領(lǐng)域年收入超過(guò) 1 萬(wàn)億美元的引擎。這些模型包含數(shù)十億個(gè)權(quán)重,對(duì)超過(guò)一萬(wàn)億個(gè)示例進(jìn)行訓(xùn)練,
以每秒超過(guò) 300,000 個(gè)查詢的速度處理推理。這些模型的大小 (10TB+) 甚至遠(yuǎn)遠(yuǎn)超過(guò)了最大的transformer模型,例如 GPT4,大約為 1TB+(模型架構(gòu)差異)。
上述所有公司的共同點(diǎn)是,它們依靠不斷更新的 DLRM 來(lái)推動(dòng)其在電子商務(wù)、搜索、社交媒體和流媒體服務(wù)等各個(gè)行業(yè)中的個(gè)性化內(nèi)容、產(chǎn)品或服務(wù)業(yè)務(wù)。這些模型的成本是巨大的,必須針對(duì)它共同優(yōu)化硬件。DLRM 并不是一成不變的,而是隨著時(shí)間的推移不斷改進(jìn),但在繼續(xù)之前讓我們先解釋一下通用模型架構(gòu)。我們將盡量保持簡(jiǎn)單。
DLRM 旨在通過(guò)對(duì)分類和數(shù)值特征進(jìn)行建模來(lái)學(xué)習(xí)用戶-項(xiàng)目交互的有意義的表示。該架構(gòu)由兩個(gè)主要組件組成:嵌入組件(處理分類特征)和多層感知器 (MLP) 組件(處理數(shù)字特征)。
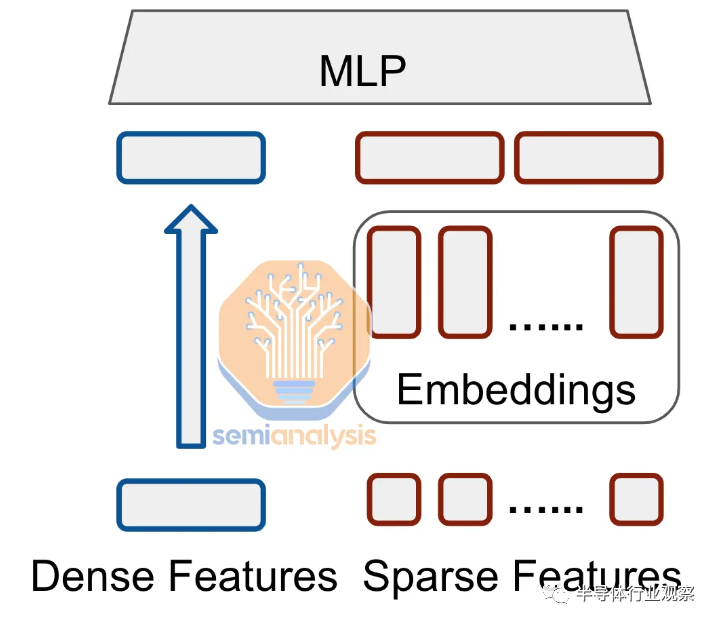
用最簡(jiǎn)單的術(shù)語(yǔ)來(lái)說(shuō), the 多層感知器組件是密集的。這些特征被饋送到一系列完全連接的層中。這類似于舊的 GPT 4 之前的transformer架構(gòu),它們也是密集的,密集層可以很好地映射到硬件上的大規(guī)模矩陣多單元。
嵌入組件對(duì)于 DLRM 來(lái)說(shuō)是非常獨(dú)特的,也是使其計(jì)算配置文件如此獨(dú)特的組件。DLRM 輸入是表示為離散、稀疏向量的分類特征。一個(gè)簡(jiǎn)單的谷歌搜索只包含整個(gè)語(yǔ)言中的幾個(gè)詞。這些稀疏輸入不能很好地映射到硬件中的大量矩陣乘法單元,因?yàn)樗鼈儚母旧细愃朴诠1恚皇菑埩俊S捎?a href="http://www.xsypw.cn/tags/神經(jīng)網(wǎng)絡(luò)/" target="_blank">神經(jīng)網(wǎng)絡(luò)通常在密集向量上表現(xiàn)更好,因此使用嵌入將分類特征轉(zhuǎn)換為密集向量。
稀疏輸入:[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
密集向量:[0.3261477, 0.4263801, 0.5121493]
嵌入函數(shù)將分類空間(英語(yǔ)單詞、社交媒體帖子的參與度、對(duì)某種帖子的行為)映射到更小的密集空間(100 個(gè)向量代表每個(gè)單詞)。這些功能是使用查找表實(shí)現(xiàn)的,查找表是 DLRM 的重要組成部分,通常構(gòu)成 DLRM 模型的第一層。嵌入表的大小可以有很大的不同,從幾十兆字節(jié)到幾百千兆字節(jié)甚至 TB 不等。
Meta 推出 2 年的 DLRM 參數(shù)超過(guò) 12 萬(wàn)億個(gè),需要 128 個(gè) GPU 來(lái)運(yùn)行推理。如今,最大的生產(chǎn) DLRM 模型至少大了好幾倍,并且僅僅為了保存模型嵌入就消耗了超過(guò) 30TB 的內(nèi)存。預(yù)計(jì)明年嵌入量會(huì)增加到 70TB 以上!因此,這些表需要在許多芯片的內(nèi)存中進(jìn)行分區(qū)。共有三種主要的分區(qū)方法:列分片(column sharding)、行分片(row sharding)和表分片(table sharding)。
DLRM 的性能在很大程度上取決于內(nèi)存帶寬、內(nèi)存容量、矢量處理性能以及芯片之間的網(wǎng)絡(luò)/互連。嵌入查找操作主要由小的收集或分散內(nèi)存訪問組成,這些訪問具有低算術(shù)強(qiáng)度(FLOPS 根本無(wú)關(guān)緊要)。對(duì)嵌入表的訪問基本上是非結(jié)構(gòu)化的稀疏性。每個(gè)查詢都必須從 30TB 以上的嵌入中提取數(shù)據(jù),這些嵌入分布在數(shù)百或數(shù)千個(gè)芯片上。這會(huì)導(dǎo)致用于 DLRM 推理的超級(jí)計(jì)算機(jī)的計(jì)算、內(nèi)存和通信負(fù)載不平衡。
這對(duì)于 MLP 和類似 GPT-3 的轉(zhuǎn)換器中的密集操作有很大不同。 芯片 FLOPS/秒仍然是主要性能驅(qū)動(dòng)因素之一當(dāng)然,除了 FLOPs 之外beyond FLOPs還有多種因素阻礙性能,但 仍然可以在 Chinchilla 風(fēng)格的 LLM 中實(shí)現(xiàn)超過(guò) 71% 的硬件觸發(fā)器利用率。
谷歌的 TPU 架構(gòu)
谷歌的 TPU 在架構(gòu)中引入了一些關(guān)鍵創(chuàng)新,使其有別于其他處理器。與傳統(tǒng)處理器不同,TPU v4 沒有專用的指令緩存。相反,它采用類似于 Cell 處理器的直接內(nèi)存訪問 (DMA) 機(jī)制。TPU v4 中的矢量緩存不是標(biāo)準(zhǔn)緩存層次結(jié)構(gòu)的一部分,而是用作暫存器。便簽本與標(biāo)準(zhǔn)緩存的不同之處在于它們需要手動(dòng)寫入,而標(biāo)準(zhǔn)緩存會(huì)自動(dòng)處理數(shù)據(jù)。由于不需要服務(wù)于大型通用計(jì)算市場(chǎng),谷歌可以利用這種更高效的基礎(chǔ)設(shè)施。這確實(shí)會(huì)在一定程度上影響編程模型,盡管 Google 工程師認(rèn)為 XLA 編譯器堆棧可以很好地處理這個(gè)問題。對(duì)于外部用戶則不能這樣說(shuō)。
TPU v4 擁有用于暫存器的 160MB SRAM 以及 2 個(gè) TensorCore,每個(gè) TensorCore 都有 1 個(gè)向量單元和 4 個(gè)矩陣乘法單元 (MXU) 和 16MB 向量?jī)?nèi)存 (VMEM)。兩個(gè) TensorCore 共享 128MB 內(nèi)存。它們支持 BF16 的 275 TFLOPS,還支持 INT8 數(shù)據(jù)類型。TPU v4 的內(nèi)存帶寬為 1200GB/s。芯片間互連 (ICI) 通過(guò)六個(gè) 50GB/s 鏈路提供 300GB/s 的數(shù)據(jù)傳輸速率。
TPU v4 中包含一個(gè) 322b 超長(zhǎng)指令字 (VLIW) 標(biāo)量計(jì)算單元。在 VLIW 架構(gòu)中,指令被組合成一個(gè)單一的長(zhǎng)指令字,然后被分派到處理器執(zhí)行。這些分組指令,也稱為束,在程序編譯期間由編譯器顯式定義。VLIW 包包含多達(dá) 2 條標(biāo)量指令、2 條矢量 ALU 指令、1 條矢量加載和 1 條矢量存儲(chǔ)指令,以及 2 個(gè)用于將數(shù)據(jù)傳入和傳出 MXU 的插槽。
Vector Processing Unit (VPU) 配備了 32 個(gè) 2D 寄存器,包含 128x 8 個(gè) 32b 元素,使其成為一個(gè) 2D 矢量 ALU。矩陣乘法單元 (MXU) 在 v2、v3 和 v4 上為 128x128,v1 版本采用 256x256 配置。發(fā)生這種變化的原因是谷歌模擬了四個(gè) 128x128 MXU 的利用率比一個(gè) 256x256 MXU 高 60%,但四個(gè) 128x128 MXU 占用的面積與 256x256 MXU 相同。MXU 輸入使用 16b 浮點(diǎn) (FP) 輸入并使用 32b 浮點(diǎn) (FP) 進(jìn)行累加。
這些更大的單元允許更有效的數(shù)據(jù)重用以突破內(nèi)存墻。
谷歌 DLRM 優(yōu)化
谷歌是最早開始在其搜索產(chǎn)品中大規(guī)模使用 DLRM 的公司之一。這種獨(dú)特的需求導(dǎo)致了一個(gè)非常獨(dú)特的解決方案。上述架構(gòu)的主要缺陷在于它無(wú)法有效處理 DLRM 的嵌入。Google 的主要 TensorCore 非常大,與這些嵌入的計(jì)算配置文件不匹配。谷歌必須在他們的 TPU 中開發(fā)一種全新類型的“SparseCore”,它不同于上面描述的用于密集層的“TensorCore”
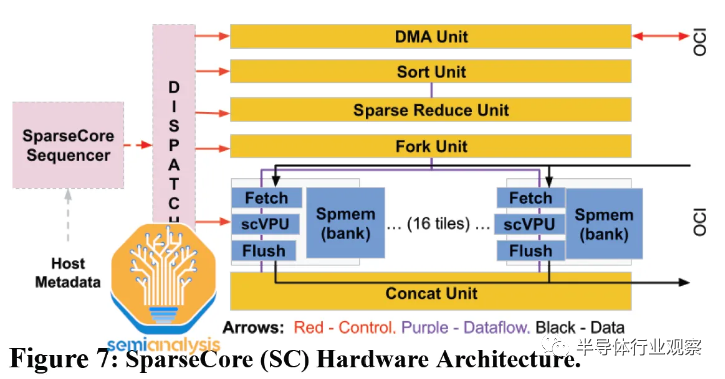
SparseCore (SC) 為 Google 的 TPU 中的嵌入提供硬件支持。早在 TPU v2 中,這些特定領(lǐng)域的處理器就有直接綁定到每個(gè) HBM 通道/子通道的塊。它們加速了訓(xùn)練深度學(xué)習(xí)推薦模型 (DLRM) 中內(nèi)存帶寬最密集的部分,同時(shí)僅占用大約 5% 的芯片面積和功率。通過(guò)在每個(gè) TPU v4 芯片而非 CPU 上使用快速的 HBM2 進(jìn)行嵌入,與將嵌入留在主機(jī) CPU 的主內(nèi)存上相比,谷歌展示了其內(nèi)部生產(chǎn) DLRM 的 7 倍加速(TPU v4 SparseCore vs TPU v4 Embeddings on Skylake-SP )。
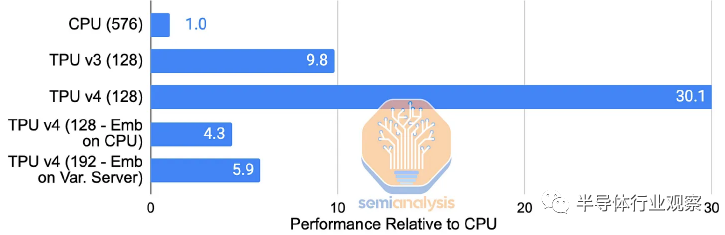
SparseCore 支持從 HBM 進(jìn)行快速內(nèi)存訪問,使用專用的獲取、處理和刷新單元將數(shù)據(jù)移動(dòng)到稀疏向量?jī)?nèi)存 (Spmem) 的組,并由可編程的 8 寬 SIMD 向量處理單元 (scVPU) 更新。這些單元的 16 個(gè)計(jì)算塊進(jìn)入一個(gè) SparseCore。
額外的跨通道單元執(zhí)行特定的嵌入操作(DMA、排序、稀疏減少、分叉、連接)。每個(gè) TPU v4 芯片有 4 個(gè) SparseCore,每個(gè)有 2.5MB 的 Smem。展望未來(lái),我們推測(cè)由于 HBM3 上子通道數(shù)量的增加,TPUv5 的 SparseCores 數(shù)量將繼續(xù)增加到 6,tiles數(shù)量將增加到 32。
雖然遷移到 HBM 帶來(lái)的性能提升是巨大的,但性能擴(kuò)展仍然受到互連對(duì)分帶寬的影響。TPU v4 中 ICI 的新 3D 環(huán)面有助于進(jìn)一步擴(kuò)展嵌入查找性能。然而,當(dāng)擴(kuò)展到 1024 個(gè)芯片時(shí),由于 SparseCore 開銷成為瓶頸,改進(jìn)會(huì)下降。
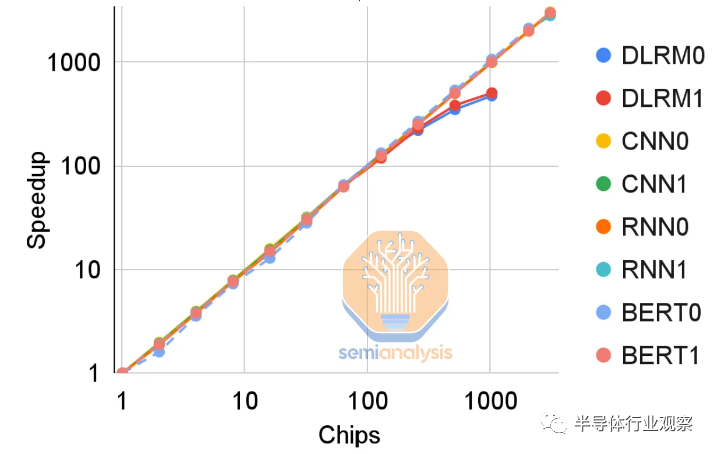
如果谷歌認(rèn)為他們的 DLRM 需要增加超過(guò)約 512 個(gè)芯片的大小和容量,這個(gè)瓶頸可能會(huì)導(dǎo)致每個(gè)圖塊的 Smem 也隨著 TPUv5 增加。
編輯:黃飛














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論