 電子發(fā)燒友App
電子發(fā)燒友App


大模型的評(píng)測(cè)應(yīng)該怎么弄?
之前在Baichuan 7B的時(shí)候,有個(gè)哥們?cè)趃ithub發(fā)布了一個(gè)issue,說這個(gè)模型有C-eval測(cè)試集泄漏的問題,具體證據(jù)為:

當(dāng)然,百川也不避諱,讓大家充分討論這個(gè)問題。
官方給出了一個(gè)解釋:
其實(shí)沒什么毛病,另外我在剛發(fā)布的13B模型上測(cè)試了這個(gè),還是存在同樣的問題。另外我嘗試了用13B的base模型讓模型續(xù)寫,一看就是訓(xùn)練了不少題庫。。
首先C-eval本身題目是公開的離線測(cè)試,答案是不可見在線提交的形式來評(píng)測(cè),這樣能一定程度上規(guī)避泄漏的問題。
但由于大模型的特殊性,其訓(xùn)練數(shù)據(jù)講究大而全,巴不得全網(wǎng)的數(shù)據(jù)都塞進(jìn)去。
目前評(píng)測(cè)大模型的方法,除了手動(dòng)體驗(yàn),人工評(píng)測(cè),其他都是數(shù)據(jù)集題目的形式。
數(shù)據(jù)集旨在考察大模型的百科全書式的知識(shí)理解程度,為了好評(píng)測(cè),把他們轉(zhuǎn)化成客觀選擇題的形式。
這樣的排行榜會(huì)存在一個(gè)很尷尬的問題,那就是一眾中文大模型在排行榜上吊打GPT3.5甚至GPT4,實(shí)際體驗(yàn)卻不盡人意。
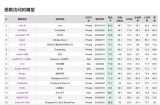
比如經(jīng)典的C-eval排行榜目前是這樣的:
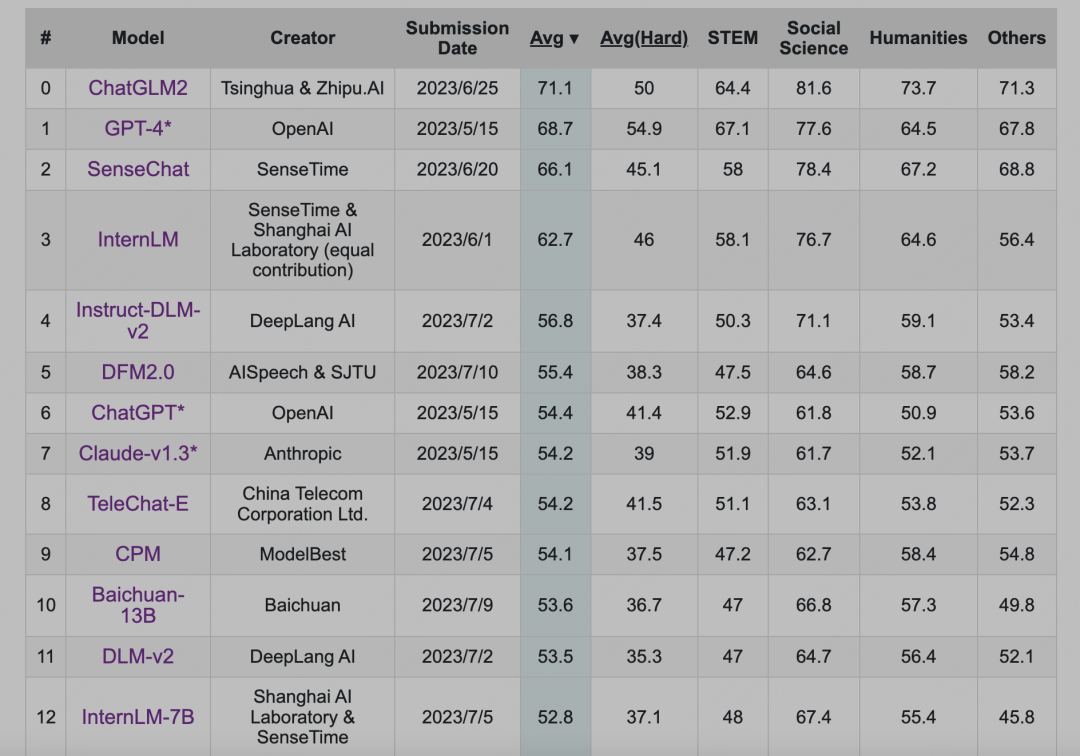
但大家心里都有一桿秤,幾斤幾兩都門兒清。
這就是為什么現(xiàn)在賣數(shù)據(jù)最火的是題庫數(shù)據(jù),仔細(xì)想想,這就跟高考刷題一樣。
這里引用下八友科技CEO(國內(nèi)著名數(shù)據(jù)提供商,大模型數(shù)據(jù)市占率50%)的觀點(diǎn):
我認(rèn)為大模型的主戰(zhàn)場(chǎng)分3個(gè)階段。
第一個(gè)階段是重點(diǎn)突破“有正確答案”的領(lǐng)域。比如中高考,這個(gè)通過簡(jiǎn)單的得分情況,可以讓模型的能力進(jìn)行比較,這一步非常關(guān)鍵。現(xiàn)在教輔類數(shù)據(jù)非常關(guān)鍵,也就在于此。
除了這個(gè),還有就是場(chǎng)景結(jié)合的,這個(gè)因?yàn)橛袌?chǎng)景優(yōu)勢(shì)的企業(yè)有獨(dú)家數(shù)據(jù),有獨(dú)家業(yè)內(nèi)人士,也就是有正確“答案”,可以判斷好壞,因此這也是一個(gè)重點(diǎn)戰(zhàn)場(chǎng)。
第二個(gè)階段是重點(diǎn)突破“沒有正確答案”的領(lǐng)域。這個(gè)階段評(píng)價(jià)遇到了困難,但是基于第一個(gè)階段,且有了足夠多數(shù)據(jù),可以認(rèn)為大模型給出的預(yù)測(cè),或者判斷,理解是具有高水平的,只是這個(gè)沒法或者很難給出標(biāo)準(zhǔn)答案,這個(gè)領(lǐng)域更加藝術(shù)的感覺,你會(huì)覺得大模型給出的回答更好,但是你也不知道最好是什么樣子的。
第三個(gè)階段是重點(diǎn)突破涉及生產(chǎn)力相關(guān)的領(lǐng)域,也就是跳過了第一階段證明階段,和第二階段的炫耀階段,直接推動(dòng)社會(huì)生產(chǎn)力發(fā)展。
目前數(shù)據(jù)提供商最值錢的數(shù)據(jù)就是題庫了,國內(nèi)大模型很懂得投機(jī)取巧,反正你是知識(shí)類客觀題評(píng)測(cè),我把全網(wǎng)的題庫數(shù)據(jù)都塞進(jìn)去。
實(shí)在買不到買不全的數(shù)據(jù),我還可以用測(cè)試集的每一道題目去反向爬取互聯(lián)網(wǎng)相關(guān)內(nèi)容,爬不到原題也能找到差不多的數(shù)據(jù),再把他們都塞進(jìn)去,針對(duì)性刷題。
這就是離線測(cè)試集問題的所在了,這對(duì)大模型來說,相當(dāng)于開卷考試。
真正的考試連題干也不能讓你看到。
所以針對(duì)客觀題的大模型評(píng)測(cè)應(yīng)該怎么做呢?
我們?cè)O(shè)想大模型參與的閉卷考試。
作為一個(gè)kaggle老玩家,這里推薦一個(gè)kaggle比賽,昨天剛上新的熱乎的數(shù)據(jù),https://www.kaggle.com/competitions/kaggle-llm-science-exam/ ,數(shù)據(jù)來自于參考維基百科話題,用gpt生成+人工過濾的科學(xué)領(lǐng)域多選題,附帶參考訓(xùn)練集,測(cè)試集隱藏不可見,提交模型在線推斷,最高支持10B左右模型推斷。
眾所周知,kaggle是谷歌家的,谷歌這是在眾籌大模型了。。。
拋開數(shù)據(jù)本身質(zhì)量不管,這個(gè)模式也存在一個(gè)問題,對(duì)發(fā)起方的經(jīng)濟(jì)實(shí)力有一定要求,比如上百B的模型咋推斷?
另外如果模型對(duì)部署有特定要求怎么辦?
還有就是提交模型和推斷代碼,無疑于把自己的核心科技提供給第三方了,所以這里存在一個(gè)信任的問題。
另外考察數(shù)據(jù)的話,kaggle上這個(gè)評(píng)測(cè)領(lǐng)域也過于局限了,不夠全,更像是一個(gè)大榜單中小數(shù)據(jù)。
評(píng)測(cè)的數(shù)據(jù)本身要注意什么呢?這里引用了的一些思考 :
原文:https://mp.weixin.qq.com/s/Q4IU6dbwy5U-iQ0ah_TGBA
大模型評(píng)測(cè)其中四點(diǎn)比較重要:能力邊界、case邊界、指令形式、自動(dòng)化量化。
能力邊界
在今天這個(gè)大模型效果目前,我們需要測(cè)它的哪些能力?聽到比較多的有代碼能力,推理能力,寫作能力,多輪對(duì)話能力等等,這些能力字面意思很好理解,但是如果我們想真真整理出一個(gè)好的技能樹也是比較困難的,比如說文本分類和閱讀理解這個(gè)歸納到哪個(gè)能力?有的會(huì)說放到NLP基本任務(wù),那有的閱讀理解case(比如先需要在文本中找到對(duì)應(yīng)的信息,然后進(jìn)行一定的加減等邏輯運(yùn)算才能得到結(jié)果)需要很強(qiáng)的推理能力,這個(gè)是該放到閱讀理解還是放到推理能力?
所以劃分的能力是否具有一個(gè)很好的覆蓋性和正交性是這里需要考慮的點(diǎn)。
case邊界
假設(shè)當(dāng)前我們?cè)跍y(cè)兩個(gè)模型的數(shù)學(xué)能力,極端情況下,測(cè)試的100道case都是類似 “1+1等于幾?”,我們拿這些case同時(shí)問gpt4和市面上一個(gè)其他的模型,得到的回答都是2,于是我們得出結(jié)論:兩個(gè)模型數(shù)學(xué)能力接近。這顯然不靠譜 !!!
又或者我們現(xiàn)在在測(cè)試寫作能力,測(cè)試case是“幫我寫一個(gè)懸疑故事”,結(jié)果兩個(gè)模型都寫出來了,都是有點(diǎn)懸疑的,那么得到結(jié)論寫作能力接近,這結(jié)論顯然也不靠譜。
為什么不靠譜呢?假設(shè)我們現(xiàn)在同樣是在考察數(shù)學(xué)能力和寫作能力,但是case分別是:(104+903)*2-18^2-10、幫我寫一個(gè)懸疑故事,故事背景發(fā)生在唐朝,主人公是一名錦衣衛(wèi),故事的開頭要是從一件很小的事帶入然后發(fā)現(xiàn)了更多背后的故事。寫出前三章故事。
還有各種各樣的復(fù)雜指令,比如中英混著問,就能更好的測(cè)評(píng)模型的雙語能力。
隨著測(cè)試的case變得復(fù)雜后模型所能cover的能力可能機(jī)會(huì)看出明顯的差距,自然也就得到不同的結(jié)論了,起碼不會(huì)草率的得出比如數(shù)學(xué)能力一樣。
所以測(cè)試的case是否具有多樣性和復(fù)雜性是這里需要考慮的點(diǎn)。
指令形式
這里單獨(dú)把指令形式拿出來,是想提一下prompt engineering這件事。
我們知道如今這些大模型對(duì)prompt很是敏感,同一個(gè)問題回答錯(cuò)了,可能換種問法比如加個(gè)“一步步推理”引導(dǎo)語他就又能回答對(duì)了,又比如通過few-shot這種形式先給它幾個(gè)例子然后再問類似的問題,就能很好的回答。
每個(gè)模型對(duì)prompt的敏感度又不一樣,對(duì)于同一個(gè)問題,同一個(gè)模型得到的結(jié)論可能都是不一樣的,那怎么辦呢?
這里筆者的建議是不要本末倒置,我們現(xiàn)在做的事情是測(cè)評(píng),尤其是在做多個(gè)模型之間的對(duì)比,那么prompt就應(yīng)該是符合人提問習(xí)慣的指令形式,對(duì)于某個(gè)問題人類怎么喜歡問就怎么來,如果模型不能get到,那就是你的指令對(duì)齊或者泛化做的不好,而不是說要花很大力氣去寫prompt迎合各個(gè)模型。
那么返回頭來說,如果現(xiàn)在的工作是在測(cè)當(dāng)前這個(gè)模型到底有沒有這個(gè)知識(shí),舉個(gè)不太恰當(dāng)?shù)睦樱僭O(shè)你正在研發(fā)一個(gè)大模型,發(fā)現(xiàn)問“中國的capital是哪里?”他居然回答是蘋果,那這個(gè)時(shí)候需要定位這個(gè)問題,你就可以先用中文問問“中國的首都是哪里?”看看能不能回答對(duì),又或者先舉幾個(gè)類似的例子告訴模型,然后再問它,如果能夠回答說嗎模型本身是有“北京是中國的首都”這個(gè)通用知識(shí)的,可能是英文或者雙語能力不行,所以這里通常的做法是,會(huì)用few-shot的指令形式去測(cè)底座模型,先看看底座模型是否有這個(gè)能力,如果沒有,那后面訓(xùn)練什么的都是很難。又比如你是一個(gè)運(yùn)營工作人員,現(xiàn)在也只能用A這個(gè)模型來完成某一件事,那就可以花點(diǎn)時(shí)間來做prompt engineering,來使得輸出最大化的滿足你的需求。
所以作為測(cè)評(píng),指令設(shè)計(jì)不應(yīng)該特意過多的去迎合模型(除非有如上的特殊目的等等),甚至應(yīng)該像上一節(jié)說的,要多樣性,才能更好的探究到模型的理解能力
自動(dòng)化量化
最后的評(píng)估都需要有一個(gè)量化的結(jié)論,理論來說,人工評(píng)估是最保險(xiǎn)的,甚至一些能力需要一些專業(yè)人員(代碼能力、各個(gè)學(xué)科的題目等等),但是這樣效率過于低下且成本過高,尤其是對(duì)于模型的迭代。目前業(yè)界的做法通常是chatgpt或者gpt4去打分,所以這里的難度就變成了打分prompt怎么寫,它需要考慮的點(diǎn)有兩個(gè),一個(gè)是怎么寫使得gpt4能夠更好的理解當(dāng)前的,另外一個(gè)是怎么約束好輸出,方便我們直接可以根據(jù)輸出進(jìn)行量化,比如做選擇題等等。
怎么評(píng)價(jià)一個(gè)模型的好壞,不僅困難,而且十分重要,絕對(duì)是一個(gè)核心的科技,這現(xiàn)在也是除了oepnai各家沒怎么搞定的一個(gè)問題。
這個(gè)問題很關(guān)鍵,是因?yàn)榛竽P偷挠?xùn)練耗時(shí)耗力,如果不能想出很好的提早檢驗(yàn)方式的話,做實(shí)驗(yàn)的速度會(huì)慢特別多,所有的時(shí)間成本都可以折合成算力上。
所以你做實(shí)驗(yàn)慢了,相當(dāng)于比別人少了GPU,足夠觸目驚心吧。
openai不僅僅卡多,還有實(shí)驗(yàn)效率倍增的buff,相當(dāng)于 卡 * 效率倍數(shù)。
我們從公開的資料能了解到,openai是通過小模型來推演大模型,訓(xùn)練的部分階段推演全部階段,從而預(yù)測(cè)最終大模型的好壞。
具體的技術(shù)細(xì)節(jié)openai也沒有透露特別多,是核心科技之一,大模型評(píng)測(cè)是非常重要和有影響力的一個(gè)方向,建議大家持續(xù)關(guān)注。
編輯:黃飛
?











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論