 電子發燒友App
電子發燒友App


本篇文章以Yolov5+圖像分割+調用百度AI的接口實現車牌實時監測識別的效果,識別效果非常優秀。
01 Yolov5介紹
YOLOv5算法整體主要有3部分組成:Backbone、Neck和Prediction,以 YOLOv5s模型為例整體算法結構如下所示。Backbone主要有Conv,C3和SPPF基本網絡模塊組成,其主要功能就是提取圖像特征信息,C3模塊使用殘差網絡結構,可以學習到更多的特征信息,SPPF模塊是空間金字塔池化,也是Backbone網絡的輸出端,主要功能是將提取到的任意大小的特征信息轉換成固定大小的特征向量。Neck網絡采用FPN+ PAN的特征金字塔結構網絡,可以實現不同尺寸目標特征信息的傳遞,可以有效解決多尺度問題。Prediction采用3種損失函數分別計算目標分類損失,目標定位損失和置信度損失,并通過NMS提高網絡檢測的準確度。 模型默認輸入圖像尺寸大小為640×640的3通道圖像,最終輸出格式是 3×(5+ncls),ncls表示目標檢測分類數量。
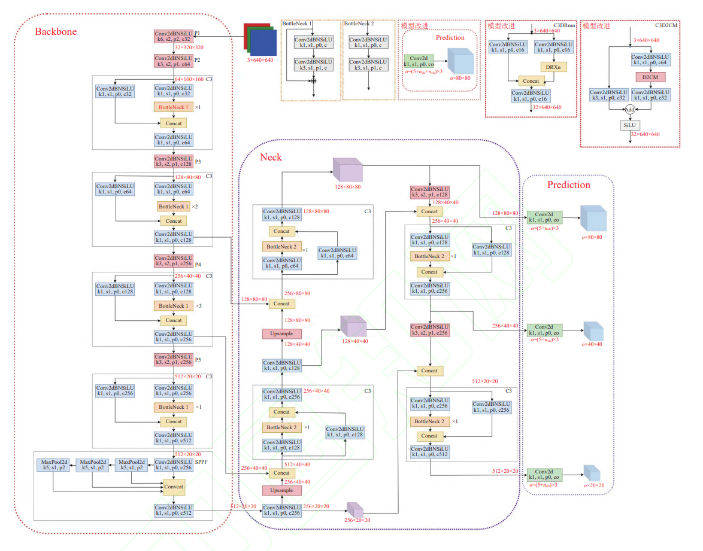
YOLO算法從總體上看,是單階段端到端的基于anchor-free的檢測算法。將圖片輸入網絡進行特征提取與融合后,得到檢測目標的預測框位置以及類概率。而YOLOv5相較前幾代YOLO算法,模型更小、部署靈活且擁有更好的檢測精度和速度,適合實時目標檢測。YOLOv5根據模型不同深度和不同特征圖寬度劃分為YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四個模型。其中YOLOv5s是最小的模型,本文車牌檢測既是用YOLOv5s模型。02 圖像分割圖像分割就是把圖像分成若干個特定的、具有獨特性質的區域并提出感興趣目標的技術和過程。它是由圖像處理到圖像分析的關鍵步驟。現有的圖像分割方法主要分以下幾類:基于閾值的分割方法、基于區域的分割方法、基于邊緣的分割方法以及基于特定理論的分割方法等。從數學角度來看,圖像分割是將數字圖像劃分成互不相交的區域的過程。圖像分割的過程也是一個標記過程,即把屬于同一區域的像素賦予相同的編號。主要是用opencv進行矩陣切割,img = cv2.imread(‘圖片.jpg’)dst = img[num1:num2,num3:num4] #裁剪坐標為[y0:y1, x0:x1]我們看一個demo,還記得我們之前寫的算法嗎?我們進行一下改進,之前的效果是:我們將代碼優化一下,不僅要在原圖上用紅框標記出來,而且要切割出來。代碼如下:
import cv2 as cv
def face_detect_demo(img):
img = cv.resize(img, dsize=(800, 800))
gary = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier(“D:/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml”)
face = face_detect.detectMultiScale(gary, 1.004, 28, 0, (40, 40), (50, 50))
count = 1
for x, y, w, h in face:
cv.rectangle(img, (x, y), (x + w, y + h), color=(0, 0, 225), thickness=4)
dst = img[y:y + h, x:x + w]
# cv.imshow(“demo”,dst)
cv.imwrite(“temp/face_{0}.jpg”.format(count), dst)
count += 1
cv.imshow(“result”, img)
# img.save(“result.jpg”) # 保存圖片
cv.imwrite(r“final_result.jpg”, img)
img = cv.imread(“photo.jpg”)
face_detect_demo(img) # 檢測單個圖片
while True:
if ord(“q”) == cv.waitKey(1):
break
cv.destroyAllWindows()
03 百度AI百度智能云AR開放平臺提供領先的AR技術能力與一站式平臺工具,開放感知跟蹤、人機交互等40+技術能力。它提供了很多技術的接口,比如說人臉識別,文字識別,語言識別等等。
這次我們通過調用文字識別的接口,用來識別我們本地圖片上的文字,詳細教程可以看這位博主的:百度AI調接口教程。對了,大家記得領一下百度免費送的優惠,要不然程序運行會報錯,別問我怎么知道的,問就是搞了兩個半小時總結出來的。這個過程可以理解為調用百度文字識別這個函數,傳入本地的一張圖片,它可以返回本地圖片上的文字。只不過這個函數不是內置的,需要你去配置才能夠使用。代碼如下:
# 測試百度在線圖片文本識別包
# 導入百度的OCR包
from aip import AipOcr
if __name__ == “__main__”:
# 此處填入在百度云控制臺處獲得的appId, apiKey, secretKey的實際值
appId, apiKey, secretKey = [‘28509942’, ‘HbB3GChFwWENkXEI7uCuNG5V’, ‘IRnFhizLzlXnYFiNoq3VcyLxRHaj2dZU’]
# 創建ocr對象
ocr = AipOcr(appId, apiKey, secretKey)
with open(‘D:/cartarget/result_1.png’, ‘rb’) as fin:
img = fin.read()
res = ocr.basicGeneral(img)
print(res[‘words_result’][0][‘words’])
這里的appId, apiKey, secretKey需要更換成自己的,圖片檢測的位置也要換成自己的。我是要下載SDK運行的,你們也可以試試別的方法。
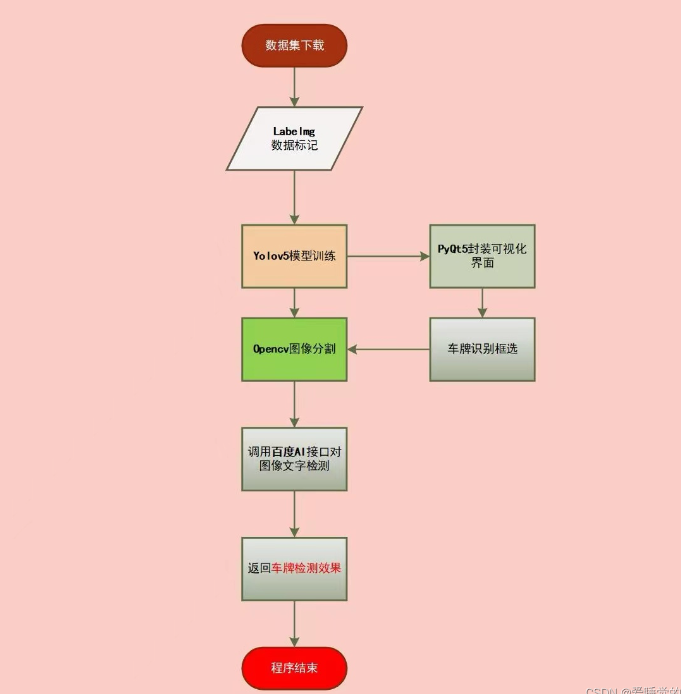
04 Yolov5+圖片分割+百度AI車牌實時檢測識別系統4.1 流程圖Visio淺淺畫了一個流程圖,用來表達整個項目的邏輯:
4.2 數據集下載首先是數據集下載,我用的是CCPD2020的數據集,CCPD2020數據集采集方法應該CCPD2019數據集類似。CCPD2020僅僅有新能源車牌圖片,包含不同亮度,不同傾斜角度,不同天氣環境下的車牌。CCPD2020中的圖像被拆分為train/val/test數據集,train/val/test數據集中圖片數分別為5769/1001/5006。
我用的時候取了100張train,80張val和20張test。
4.3 Yolov5模型訓練然后是Yolov5模型的訓練,詳細代碼還是看之前那篇口罩檢測的文章吧,配置文件只要改這幾個。1、數據集的配置文件:mask_data.yaml:
修改train的路徑 注意是 /(反斜杠)
修改val的路徑
修改類別 nc :1、2 names [“標簽名稱1”、“標簽名稱2”] 具體幾個看你的類別有幾個
2、模型配置文件:yolov5s.yaml
修改類別個數 nc:1、2
這里貼上檢測數據,由于是用CPU跑的,考慮到時間問題,我這里僅訓練了20次,用時在40min左右。
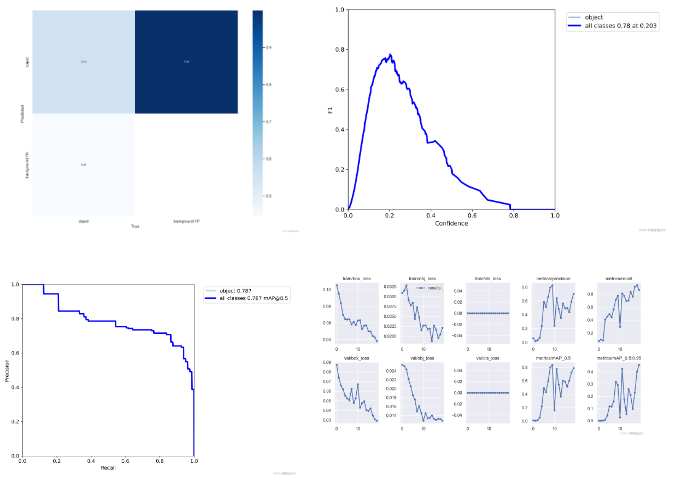
可以看到,識別的精度為80%左右,還是比較可觀的,通過增大epoch的值,可以調整成100,識別率達到95%是沒有問題的。
再點擊開始檢測 ,調用訓練好的pt模型進行識別。
?
4.5 opencv切割圖片我自定義了一個split.py,里面只有一個split函數,目的就是為了切割圖片,這里是運用了封裝思想。在windows.py文件中通過import導入,就可以直接運用這個函數了。以下為split.py文件內容。
import cv2 as cv
def split(list_1,img,i):
dst = img[int(list_1[1]):int(list_1[3]),int(list_1[0]):int(list_1[2])] # 裁剪坐標為[y0:y1, x0:x1] xyxy
cv.imwrite(“D:/cartarget/result_{0}.png”.format(i+1), dst)
# list_1 =[231,1391,586,1518]
# img = cv.imread(‘train_25.jpg’)
# split(list_1,img,0)
接著需要對windows.py進行修改,在檢測圖片detect_img函數中,添加
tem_list = []
tem_list.append(int(xyxy[0]))
tem_list.append(int(xyxy[1]))
tem_list.append(int(xyxy[2]))
tem_list.append(int(xyxy[3]))
print(“準備切割!”)
split.split(tem_list, im0,count_1)
count_1 += 1
print(“切割完成!”)
這樣,Yolov5檢測出幾個目標,就會調用幾次split方法從而切割出來幾張子圖片,由于這里圖片只有一輛車,所有只有一個檢測目標,所以只會得到一個車牌。4.6 調用百度AI進行圖片檢測這個邏輯就很好理解啦!只要把上面這個圖片丟給百度文字識別去識別內容就好啦!
if __name__ == “__main__”:
# 此處填入在百度云控制臺處獲得的appId, apiKey, secretKey的實際值
appId, apiKey, secretKey = [‘28509942’, ‘HbB3GChFwWENkXEI7uCuNG5V’, ‘IRnFhizLzlXnYFiNoq3VcyLxRHaj2dZU’]
# 創建ocr對象
ocr = AipOcr(appId, apiKey, secretKey)
with open(‘name.png’, ‘rb’) as fin:
img = fin.read()
res = ocr.basicGeneral(img)
print(res[‘words_result’][0][‘words’])
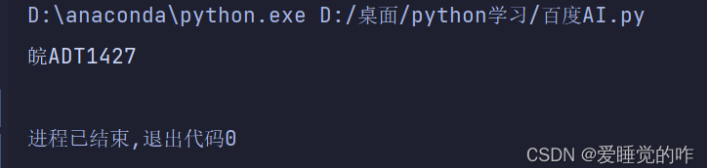
可以看到識別完全正確!大功告成!05 總結這個車牌識別系統到這里就算正式結束啦!感覺收獲還是蠻多的,對Yolov5的理解更加深刻,Opencv的運用更加熟練,PyQt5也算是熟悉了。目標檢測、圖片分割、圖像搜索、增強和特效、動作識別等等,慢慢覺得這些功能更像是一個個拼圖,想要完成一個較大的工程,需要將一個個小功能拼在一起。機器學習的路程還很漫長,很多知識我都未曾了解,其中的數學原理更是知之甚少。未來的學習還很漫長,人工智能的領域依然遼闊而精彩。車牌檢測這個項目只是一個載體,項目本身并不重要,重要的是項目背后學到的知識,定期總結才能更好的接受知識吧!好啦,今天的分享就到這里啦!
編輯:黃飛















 工商網監
工商網監
評論