 電子發(fā)燒友App
電子發(fā)燒友App


?
作者:史蒂芬·沃爾弗拉姆(Stephen Wolfram)英、美籍 計(jì)算機(jī)科學(xué)家, 物理學(xué)家。他是 Mathematica 的首席設(shè)計(jì)師,《一種新科學(xué)》一書的作者。ChatGPT 能夠自動生成一些讀起來表面上甚至像人寫的文字的東西,這非常了不起,而且出乎意料。但它是如何做到的?為什么它能發(fā)揮作用?我在這里的目的是大致介紹一下 ChatGPT 內(nèi)部的情況,然后探討一下為什么它能很好地生成我們認(rèn)為是有意義的文本。我首先要說明一下,我將把重點(diǎn)放在正在發(fā)生的事情的大的方向上,雖然我會提到一些工程細(xì)節(jié),但我不會深入研究它們。(我所說的實(shí)質(zhì)內(nèi)容也同樣適用于目前其他的 “大型語言模型” LLM 和 ChatGPT)。首先要解釋的是,ChatGPT 從根本上說總是試圖對它目前得到的任何文本進(jìn)行 “合理的延續(xù)”,這里的 “合理” 是指 “在看到人們在數(shù)十億個網(wǎng)頁上所寫的東西之后,人們可能會期望某人寫出什么”。因此,假設(shè)我們已經(jīng)得到了 “人工智能最好的是它能去做 ……” 的文本(“The best thing about AI is its ability to”)。
想象一下,掃描數(shù)十億頁的人類書寫的文本(例如在網(wǎng)絡(luò)上和數(shù)字化書籍中),并找到這個文本的所有實(shí)例 —— 然后看到什么詞在接下來的時間里出現(xiàn)了多少。ChatGPT 有效地做了類似的事情,除了(正如我將解釋的)它不看字面文本;它尋找在某種意義上 “意義匹配” 的東西。但最終的結(jié)果是,它產(chǎn)生了一個可能出現(xiàn)在后面的詞的排序列表,以及 “概率”。

值得注意的是,當(dāng) ChatGPT 做一些事情,比如寫一篇文章時,它所做的基本上只是反復(fù)詢問 “鑒于到目前為止的文本,下一個詞應(yīng)該是什么?” —— 而且每次都增加一個詞。(更準(zhǔn)確地說,正如我將解釋的那樣,它在添加一個 “標(biāo)記”,這可能只是一個詞的一部分,這就是為什么它有時可以 “編造新詞”)。
在每一步,它得到一個帶有概率的單詞列表。但是,它究竟應(yīng)該選擇哪一個來添加到它正在寫的文章(或其他什么)中呢?人們可能認(rèn)為它應(yīng)該是 “排名最高” 的詞(即被分配到最高 “概率” 的那個)。但是,這時就會有一點(diǎn)巫術(shù)開始悄悄出現(xiàn)。因?yàn)槌鲇谀撤N原因 —— 也許有一天我們會有一個科學(xué)式的理解 —— 如果我們總是挑選排名最高的詞,我們通常會得到一篇非常 “平淡” 的文章,似乎從來沒有 “顯示出任何創(chuàng)造力”(甚至有時一字不差地重復(fù))。但是,如果有時(隨機(jī)的)我們挑選排名較低的詞,我們會得到一篇 “更有趣” 的文章。這里有隨機(jī)性的事實(shí)意味著,假如我們多次使用同一個提示,我們也很可能每次都得到不同的文章。
而且,為了與巫術(shù)的想法保持一致,有一個特定的所謂 “溫度” 參數(shù)(temperature parameter),它決定了以什么樣的頻率使用排名較低的詞,而對于論文的生成,事實(shí)證明,0.8 的 “溫度” 似乎是最好的。(值得強(qiáng)調(diào)的是,這里沒有使用任何 “理論”;這只是一個在實(shí)踐中被發(fā)現(xiàn)可行的問題)。例如,“溫度” 的概念之所以存在,是因?yàn)榍『檬褂昧私y(tǒng)計(jì)物理學(xué)中熟悉的指數(shù)分布,但沒有 “物理” 聯(lián)系 —— 至少到目前為止我們?nèi)绱苏J(rèn)為。)在我們繼續(xù)之前,我應(yīng)該解釋一下,為了論述的目的,我大多不會使用 ChatGPT 中的完整系統(tǒng);相反,我通常會使用更簡單的 GPT-2 系統(tǒng),它有一個很好的特點(diǎn),即它足夠小,可以在標(biāo)準(zhǔn)的臺式電腦上運(yùn)行。因此,對于我展示的所有內(nèi)容,包括明確的沃爾弗拉姆語言(Wolfram Language)代碼,你可以立即在你的計(jì)算機(jī)上運(yùn)行。(點(diǎn)擊這里的任何圖片都可以復(fù)制其背后的代碼 。例如,這里是如何獲得上述概率表的。首先,我們必須檢索底層的 “語言模型” 神經(jīng)網(wǎng):
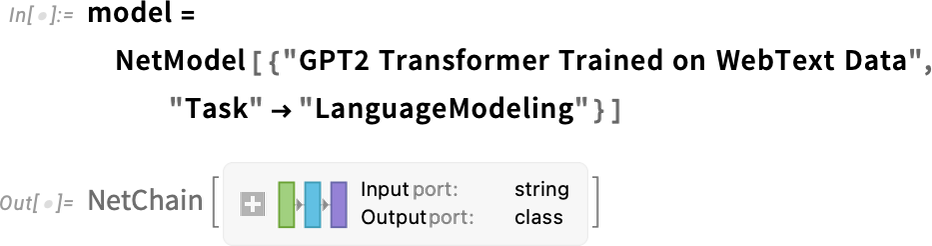
稍后,我們將看看這個神經(jīng)網(wǎng)的內(nèi)部,并談?wù)勊侨绾喂ぷ鞯摹5F(xiàn)在我們可以把這個 “網(wǎng)絡(luò)模型” 作為一個黑匣子應(yīng)用于我們迄今為止的文本,并要求按概率計(jì)算出該模型認(rèn)為應(yīng)該選擇的前五個詞:

這就把這個結(jié)果變成了一個明確的格式化的 “數(shù)據(jù)集”:

如果重復(fù) “應(yīng)用模型” —— 在每一步中加入概率最高的詞(在此代碼中被指定為模型的 “決定”),會發(fā)生什么:
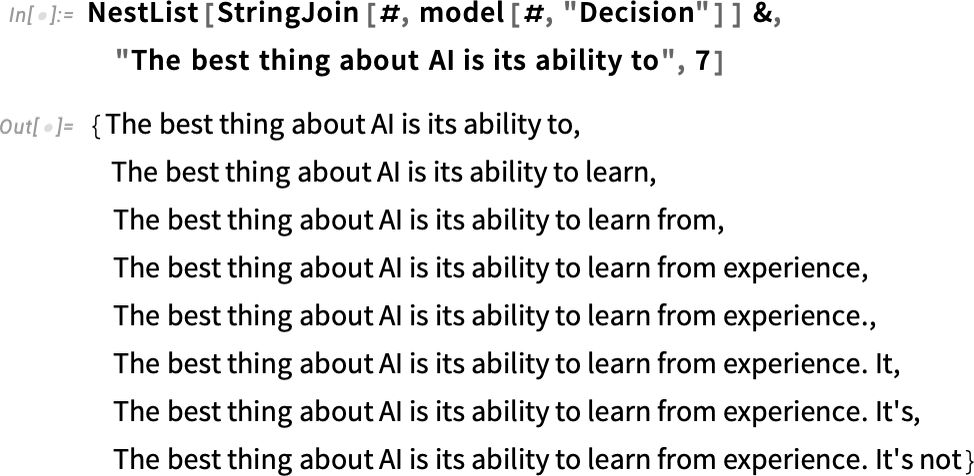
如果再繼續(xù)下去會發(fā)生什么?在這種情況下(“零溫度”),很快就會出現(xiàn)相當(dāng)混亂和重復(fù)的情況:

但是,如果不總是挑選 “頂級” 詞,而是有時隨機(jī)挑選 “非頂級” 詞(“隨機(jī)性” 對應(yīng) “溫度” 為 0.8)呢?人們又可以建立起文本:

而每次這樣做,都會有不同的隨機(jī)選擇,文本也會不同 —— 如這 5 個例子:

值得指出的是,即使在第一步,也有很多可能的 “下一個詞” 可供選擇(溫度為 0.8),盡管它們的概率下降得很快(是的,這個對數(shù)圖上的直線對應(yīng)于 n-1 的 “冪律” 衰減,這是語言的一般統(tǒng)計(jì)的特點(diǎn)):

那么,如果繼續(xù)下去會發(fā)生什么?這里有一個隨機(jī)的例子。它比頂層詞(零溫度)的情況要好,但頂多還是有點(diǎn)奇怪:
這是用最簡單的 GPT-2 模型(來自 2019 年)做的。用較新和較大的 GPT-3 模型,結(jié)果更好。這里是用同樣的 “提示” 產(chǎn)生的頂部文字(零溫度),但用最大的 GPT-3 模型:

這是 “溫度為 0.8” 時的一個隨機(jī)例子:

— 1 —概率從何而來?好吧,ChatGPT 總是根據(jù)概率來選擇下一個詞。但是這些概率從何而來?讓我們從一個更簡單的問題開始。讓我們考慮一次生成一個字母(而不是單詞)的英語文本。我們怎樣才能算出每個字母的概率呢?我們可以做的一個非常簡單的事情就是取一個英語文本的樣本,然后計(jì)算不同字母在其中出現(xiàn)的頻率。因此,舉例來說,這是計(jì)算維基百科上關(guān)于 “貓”(cat) 的文章中的字母:

而這對 “狗”(dog) 也有同樣的作用:

結(jié)果相似,但不一樣(“o” 在 “dogs” 文章中無疑更常見,因?yàn)楫吘顾霈F(xiàn)在 “dog” 這個詞本身)。盡管如此,如果我們采取足夠大的英語文本樣本,我們可以期待最終得到至少是相當(dāng)一致的結(jié)果。

下面是我們得到的一個樣本,如果我們用這些概率生成一個字母序列:

我們可以通過添加空格將其分解為 “單詞”,就像它們是具有一定概率的字母一樣:

我們可以通過強(qiáng)迫 “字長” 的分布與英語中的分布相一致,在制造 “單詞” 方面做得稍微好一點(diǎn):

我們在這里沒有碰巧得到任何 “實(shí)際的詞”,但結(jié)果看起來稍好一些。不過,要想更進(jìn)一步,我們需要做的不僅僅是隨機(jī)地分別挑選每個字母。例如,我們知道,如果我們有一個 “q”,下一個字母基本上必須是 “u”:這里有一個字母本身的概率圖:

這是一個顯示典型英語文本中成對字母(“2-grams”)概率的圖。可能的第一個字母顯示在頁面上,第二個字母顯示在頁面下:

例如,我們在這里看到,除了 “u” 行,“q” 列是空白的(概率為零)。好了,現(xiàn)在我們不再是一次生成一個字母的 “單詞”,而是使用這些 “2-gram” 概率,一次看兩個字母來生成它們。下面是一個結(jié)果的樣本 —— 其中恰好包括一些 “實(shí)際的詞”:

有了足夠多的英語文本,我們不僅可以對單個字母或成對字母(2-grams)的概率進(jìn)行很好的估計(jì),而且還可以對較長的字母進(jìn)行估計(jì)。如果我們用逐漸變長的 n-gram 概率生成 “隨機(jī)詞”,我們就會發(fā)現(xiàn)它們逐漸變得 “更現(xiàn)實(shí)”:

但現(xiàn)在讓我們假設(shè) —— 或多或少像 ChatGPT 那樣 —— 我們處理的是整個單詞,而不是字母。英語中大約有 40,000 個合理的常用詞。通過查看大型英語文本語料庫(比如幾百萬本書,總共有幾千億個單詞),我們可以得到每個單詞的常見程度的估計(jì)。利用這一點(diǎn),我們可以開始生成 “句子”,其中每個詞都是獨(dú)立隨機(jī)抽取的,其出現(xiàn)的概率與語料庫中的相同。下面是我們得到的一個樣本:

顯然,這是一派胡言。那么,我們?nèi)绾尾拍茏龅酶媚兀烤拖駥Υ帜敢粯樱覀兛梢蚤_始考慮的不僅僅是單個詞的概率,還有成對的或更長的詞的 n-grams 的概率。在成對的情況下,以下是我們得到的 5 個例子,所有情況都是從 “貓” 這個詞開始的:

它變得稍微 “看起來很合理” 了。我們可以想象,如果我們能夠使用足夠長的 n-grams,我們基本上會 “得到一個 ChatGPT” —— 在這個意義上,我們會得到一些東西,以 “正確的總體論文概率” 生成論文長度的單詞序列。但問題是:沒有足夠的英文文本可以推導(dǎo)出這些概率。在網(wǎng)絡(luò)的抓取中,可能有幾千億個單詞;在已經(jīng)數(shù)字化的書籍中,可能有另外幾千億個單詞。但是有了 4 萬個常用詞,即使是可能的 2-grams 的數(shù)量也已經(jīng)是 16 億了,可能的 3-grams 的數(shù)量是 60 萬億。所以我們沒有辦法從現(xiàn)有的文本中估計(jì)出所有這些的概率。而當(dāng)我們達(dá)到 20 個字的 “文章片段” 時,可能性的數(shù)量比宇宙中的粒子數(shù)量還要多,所以從某種意義上說,它們永遠(yuǎn)不可能全部被寫下來。那么我們能做什么呢?最大的想法是建立一個模型,讓我們估計(jì)序列出現(xiàn)的概率 —— 即使我們在所看的文本語料庫中從未明確見過這些序列。而 ChatGPT 的核心正是一個所謂的 “大型語言模型”(LLM),它的建立可以很好地估計(jì)這些概率。
— 2 —什么是模型?假設(shè)你想知道(就像伽利略在 15 世紀(jì)末所做的那樣),從比薩塔的每一層落下的炮彈要多長時間才能落地。那么,你可以在每一種情況下測量它,并將結(jié)果制成表格。或者你可以做理論科學(xué)的精髓:建立一個模型,給出某種計(jì)算答案的程序,而不是僅僅測量和記住每個案例。讓我們想象一下,我們有(有點(diǎn)理想化的)數(shù)據(jù),說明炮彈從不同樓層落下需要多長時間。

我們?nèi)绾斡?jì)算出它從一個我們沒有明確數(shù)據(jù)的樓層落下需要多長時間?在這種特殊情況下,我們可以用已知的物理學(xué)定律來計(jì)算。但是,如果說我們所得到的只是數(shù)據(jù),而我們不知道有什么基本定律在支配它。那么我們可以做一個數(shù)學(xué)上的猜測,比如說,也許我們應(yīng)該用一條直線作為模型。

我們可以選擇不同的直線。但這是平均來說最接近我們所給的數(shù)據(jù)的一條。而根據(jù)這條直線,我們可以估算出任何樓層的下降時間。我們怎么知道要在這里嘗試使用一條直線呢?在某種程度上我們不知道。這只是數(shù)學(xué)上簡單的東西,而我們已經(jīng)習(xí)慣了這樣的事實(shí):我們測量的很多數(shù)據(jù)都被數(shù)學(xué)上簡單的東西很好地?cái)M合了。我們可以嘗試一些數(shù)學(xué)上更復(fù)雜的東西 —— 比如說 a + bx + cx2,然后在這種情況下,我們做得更好:

不過,事情可能會出大問題。比如這里是我們用 a + b/c + x sin(x) 最多也就做成:
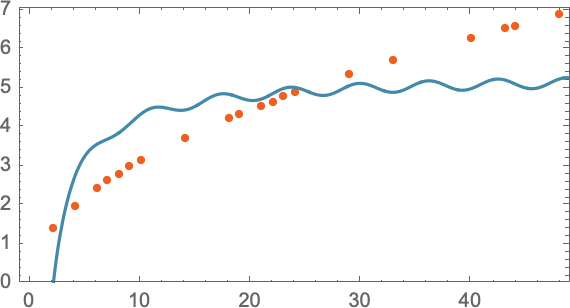
值得理解的是,從來沒有一個 “無模型的模型”。你使用的任何模型都有一些特定的基礎(chǔ)結(jié)構(gòu),然后有一組 “你可以轉(zhuǎn)動的旋鈕”(即你可以設(shè)置的參數(shù))來適應(yīng)你的數(shù)據(jù)。而在 ChatGPT 的案例中,使用了很多這樣的 “旋鈕” —— 實(shí)際上,有 1750 億個。但令人矚目的是,ChatGPT 的底層結(jié)構(gòu) —— “僅僅” 有這么多的參數(shù) —— 足以使一個計(jì)算下一個單詞概率的模型 “足夠好”,從而為我們提供合理的文章長度的文本。
— 3 —類人的任務(wù)模型我們上面舉的例子涉及到為數(shù)字?jǐn)?shù)據(jù)建立模型,這些數(shù)據(jù)基本上來自于簡單的物理學(xué) —— 幾個世紀(jì)以來我們都知道 “簡單數(shù)學(xué)適用”。但是對于 ChatGPT 來說,我們必須為人類語言文本建立一個模型,即由人腦產(chǎn)生的那種模型。而對于這樣的東西,我們(至少現(xiàn)在)還沒有類似 “簡單數(shù)學(xué)” 的東西。那么,它的模型可能是什么樣的呢?在我們談?wù)撜Z言之前,讓我們先談?wù)劻硪豁?xiàng)類似人類的任務(wù):識別圖像。而作為一個簡單的例子,讓我們考慮數(shù)字的圖像(是的,這是一個經(jīng)典的機(jī)器學(xué)習(xí)例子):
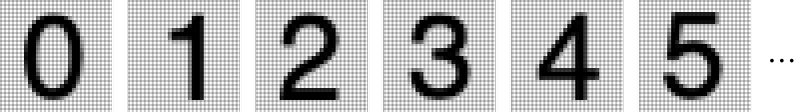
我們可以做的一件事是為每個數(shù)字獲取一堆樣本圖像:

然后,為了找出我們輸入的圖像是否對應(yīng)于某個特定的數(shù)字,我們只需與我們擁有的樣本進(jìn)行明確的逐像素比較。但作為人類,我們似乎可以做得更好 —— 因?yàn)槲覀內(nèi)匀豢梢宰R別數(shù)字,即使它們是手寫的,并且有各種各樣的修改和扭曲。
當(dāng)我們?yōu)樯厦娴臄?shù)字?jǐn)?shù)據(jù)建立一個模型時,我們能夠取一個給定的數(shù)字值 x,然后為特定的 a 和 b 計(jì)算 a + bx。因此,如果我們把這里的每個像素的灰度值當(dāng)作某個變量 xi,是否有一些所有這些變量的函數(shù),在評估時告訴我們這個圖像是什么數(shù)字?事實(shí)證明,有可能構(gòu)建這樣一個函數(shù)。不足為奇的是,這并不特別簡單。一個典型的例子可能涉及 50 萬次數(shù)學(xué)運(yùn)算。但最終的結(jié)果是,如果我們把一幅圖像的像素值集合輸入這個函數(shù),就會得出一個數(shù)字,指定我們的圖像是哪個數(shù)字。稍后,我們將討論如何構(gòu)建這樣一個函數(shù),以及神經(jīng)網(wǎng)絡(luò)的概念。但現(xiàn)在讓我們把這個函數(shù)當(dāng)作黑匣子,我們輸入例如手寫數(shù)字的圖像(作為像素值的陣列),然后我們得到這些數(shù)字對應(yīng)的數(shù)字:
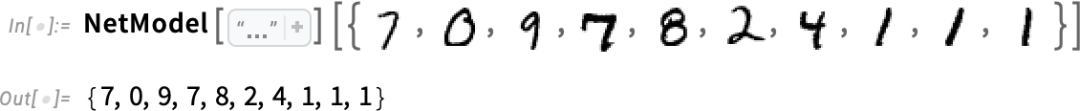
但這里到底發(fā)生了什么?比方說,我們逐步模糊一個數(shù)字。有一段時間,我們的函數(shù)仍然 “識別” 它,在這里是一個 “2”。但很快它就 “失去” 了,并開始給出 “錯誤” 的結(jié)果:

但為什么我們說這是一個 “錯誤” 的結(jié)果呢?在這種情況下,我們知道我們通過模糊一個 “2” 得到所有的圖像。但是,如果我們的目標(biāo)是制作一個人類識別圖像的模型,那么真正要問的問題是,如果遇到這些模糊的圖像,在不知道其來源的情況下,人類會做什么。如果我們從我們的功能中得到的結(jié)果通常與人類會說的話一致,我們就有一個 “好的模型”。而非微不足道的科學(xué)事實(shí)是,對于像這樣的圖像識別任務(wù),我們現(xiàn)在基本上知道如何構(gòu)建這樣的函數(shù)。我們能 “從數(shù)學(xué)上證明” 它們的作用嗎?嗯,不能。因?yàn)橐龅竭@一點(diǎn),我們必須有一個關(guān)于我們?nèi)祟愓谧鍪裁吹臄?shù)學(xué)理論。以 “2” 圖像為例,改變幾個像素。我們可以想象,只有幾個像素 “不合適”,我們還是應(yīng)該認(rèn)為這個圖像是 “2”。但這應(yīng)該到什么程度呢?這是一個關(guān)于人類視覺感知的問題。而且,是的,對于蜜蜂或章魚來說,答案無疑是不同的 —— 對于假定的外星人來說,可能完全不同。
— 3 —神經(jīng)網(wǎng)路好吧,那么我們用于圖像識別等任務(wù)的典型模型究竟是如何工作的呢?目前最流行、最成功的方法是使用神經(jīng)網(wǎng)絡(luò)。在 20 世紀(jì) 40 年代,神經(jīng)網(wǎng)絡(luò)的發(fā)明形式與今天的使用非常接近,它可以被認(rèn)為是大腦似乎工作方式的簡單理想化。在人類的大腦中,有大約 1000 億個神經(jīng)元(神經(jīng)細(xì)胞),每個神經(jīng)元都能產(chǎn)生電脈沖,每秒可能有一千次。這些神經(jīng)元在一個復(fù)雜的網(wǎng)絡(luò)中連接起來,每個神經(jīng)元都有樹狀的分支,允許它將電信號傳遞給可能有成千上萬的其他神經(jīng)元。粗略估計(jì),任何給定的神經(jīng)元是否在某一時刻產(chǎn)生電脈沖,取決于它從其他神經(jīng)元那里收到的脈沖 —— 不同的連接有不同的 “權(quán)重” 貢獻(xiàn)。當(dāng)我們 “看到一個圖像” 時,所發(fā)生的事情是,當(dāng)圖像的光子落在眼睛后面的(“光感受器”)細(xì)胞上時,它們在神經(jīng)細(xì)胞中產(chǎn)生電信號。這些神經(jīng)細(xì)胞與其他神經(jīng)細(xì)胞相連,最終信號通過一整層的神經(jīng)元。而正是在這個過程中,我們 “識別” 了圖像,最終 “形成了一個想法”,即我們 “看到了一個 2”(也許最后會做一些事情,如大聲說 “2” 這個詞)。上一節(jié)中的 “黑盒子” 函數(shù)是這樣一個神經(jīng)網(wǎng)絡(luò)的 “數(shù)學(xué)化” 版本。它剛好有 11 層(雖然只有 4 個 “核心層”)。

這個神經(jīng)網(wǎng)并沒有什么特別的 “理論推導(dǎo)”;它只是在 1998 年作為一項(xiàng)工程而構(gòu)建的東西,并且被發(fā)現(xiàn)是有效的。(當(dāng)然,這與我們描述我們的大腦是通過生物進(jìn)化過程產(chǎn)生的沒有什么不同)。好吧,但是像這樣的神經(jīng)網(wǎng)絡(luò)是如何 “識別事物” 的?關(guān)鍵在于吸引器的概念。想象一下,我們有 1 和 2 的手寫圖像:

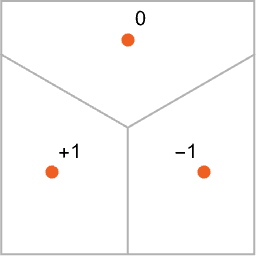
我們希望所有的 1 都 “被吸引到一個地方”,而所有的 2 都 “被吸引到另一個地方”。或者,換一種方式,如果一個圖像在某種程度上 “更接近于 1”,而不是 2,我們希望它最終出現(xiàn)在 “1 的地方”,反之亦然。作為一個直接的類比,我們假設(shè)在平面上有某些位置,用點(diǎn)表示(在現(xiàn)實(shí)生活中,它們可能是咖啡店的位置)。那么我們可以想象,從平面上的任何一點(diǎn)開始,我們總是想在最近的點(diǎn)結(jié)束(即我們總是去最近的咖啡店)。我們可以通過將平面劃分為由理想化的 “分水嶺” 分隔的區(qū)域(“吸引盆地”)來表示這一點(diǎn):

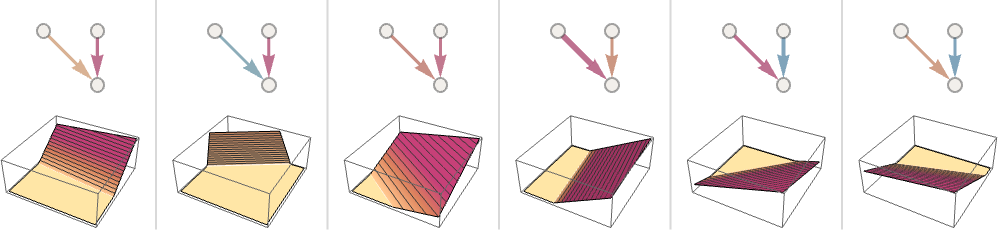
我們可以認(rèn)為這是在執(zhí)行一種 “識別任務(wù)”,我們不是在做類似于識別給定圖像 “看起來最像” 的數(shù)字的事情 —— 而是很直接地看到給定點(diǎn)最接近哪個點(diǎn)。(我們在這里展示的 “Voronoi 圖” 設(shè)置是在二維歐幾里得空間中分離點(diǎn);數(shù)字識別任務(wù)可以被認(rèn)為是在做非常類似的事情 —— 但卻是在一個由每張圖像中所有像素的灰度等級形成的 784 維空間中。)那么,我們?nèi)绾问挂粋€神經(jīng)網(wǎng)絡(luò) “完成一個識別任務(wù)”?讓我們考慮這個非常簡單的案例:
我們的目標(biāo)是獲取一個對應(yīng)于 {x,y} 位置的 “輸入”,然后將其 “識別” 為它最接近的三個點(diǎn)中的任何一個。或者,換句話說,我們希望神經(jīng)網(wǎng)絡(luò)能夠計(jì)算出一個類似于 {x,y} 的函數(shù):
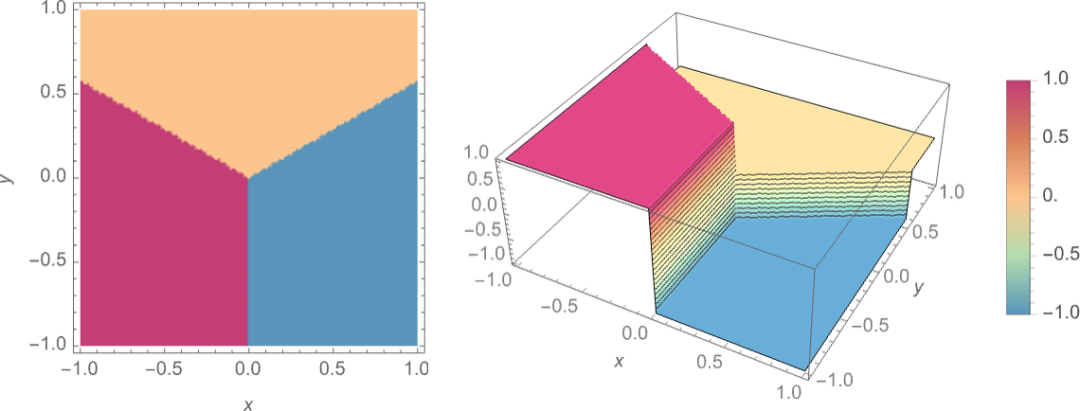
那么,我們?nèi)绾斡蒙窠?jīng)網(wǎng)絡(luò)做到這一點(diǎn)呢?歸根結(jié)底,神經(jīng)網(wǎng)是一個理想化的 “神經(jīng)元” 的連接集合 —— 通常按層排列 —— 一個簡單的例子是:

每個 “神經(jīng)元” 都被有效地設(shè)置為評估一個簡單的數(shù)字函數(shù)。為了 “使用” 這個網(wǎng)絡(luò),我們只需在頂部輸入數(shù)字(如我們的坐標(biāo) x 和 y),然后讓每一層的神經(jīng)元 “評估它們的功能”,并通過網(wǎng)絡(luò)向前輸入結(jié)果 —— 最終在底部產(chǎn)生最終的結(jié)果。

在傳統(tǒng)的(受生物啟發(fā)的)設(shè)置中,每個神經(jīng)元實(shí)際上都有一組來自上一層神經(jīng)元的 “傳入連接”,每個連接都被賦予一定的 “權(quán)重”(可以是一個正數(shù)或負(fù)數(shù))。一個給定的神經(jīng)元的值是通過將 “前一個神經(jīng)元” 的值乘以其相應(yīng)的權(quán)重來確定的,然后將這些值相加并乘以一個常數(shù),最后應(yīng)用一個 “閾值”(或 “激活”)函數(shù)。在數(shù)學(xué)術(shù)語中,如果一個神經(jīng)元有輸入 x = {x1, x2 …… },那么我們計(jì)算 f[w.x + b],其中權(quán)重 w 和常數(shù) b 通常為網(wǎng)絡(luò)中的每個神經(jīng)元選擇不同;函數(shù) f 通常是相同的。計(jì)算 w.x + b 只是一個矩陣乘法和加法的問題。激活函數(shù) “f 引入了非線性(并最終導(dǎo)致了非線性行為)。通常使用各種激活函數(shù);這里我們只使用 Ramp(或 ReLU):

對于我們希望神經(jīng)網(wǎng)絡(luò)執(zhí)行的每一項(xiàng)任務(wù)(或者說,對于我們希望它評估的每一個整體函數(shù)),我們將有不同的權(quán)重選擇。(正如我們稍后要討論的那樣,這些權(quán)重通常是通過使用機(jī)器學(xué)習(xí)從我們想要的輸出實(shí)例中 “訓(xùn)練” 神經(jīng)網(wǎng)絡(luò)來確定的)。最終,每個神經(jīng)網(wǎng)絡(luò)都對應(yīng)于一些整體的數(shù)學(xué)函數(shù) —— 盡管它可能寫得很亂。對于上面的例子,它就是:

ChatGPT 的神經(jīng)網(wǎng)絡(luò)也只是對應(yīng)于這樣的一個數(shù)學(xué)函數(shù) —— 但實(shí)際上有數(shù)十億個術(shù)語。但讓我們回到單個神經(jīng)元上。下面是一個有兩個輸入(代表坐標(biāo) x 和 y)的神經(jīng)元在選擇不同的權(quán)重和常數(shù)(以及 Ramp 作為激活函數(shù))后可以計(jì)算的函數(shù)的一些例子:
但是,上面那個更大的網(wǎng)絡(luò)是怎么回事?嗯,這是它的計(jì)算結(jié)果:

這不是很 “正確”,但它接近于我們上面展示的 “最近點(diǎn)” 函數(shù)。讓我們看看其他一些神經(jīng)網(wǎng)絡(luò)的情況。在每一種情況下,正如我們稍后所解釋的,我們都在使用機(jī)器學(xué)習(xí)來尋找最佳的權(quán)重選擇。然后,我們在這里展示帶有這些權(quán)重的神經(jīng)網(wǎng)絡(luò)的計(jì)算結(jié)果:
更大的網(wǎng)絡(luò)通常能更好地逼近我們的目標(biāo)函數(shù)。而在 “每個吸引子盆地的中間”,我們通常會得到我們想要的答案。但在邊界 —— 神經(jīng)網(wǎng)絡(luò) “很難下定決心” 的地方 —— 情況可能會更加混亂。在這個簡單的數(shù)學(xué)風(fēng)格的 “識別任務(wù)” 中,“正確答案” 是什么很清楚。但在識別手寫數(shù)字的問題上,就不那么清楚了。如果有人把 “2” 寫得很糟糕,看起來像 “7”,等等,怎么辦?不過,我們還是可以問,神經(jīng)網(wǎng)絡(luò)是如何區(qū)分?jǐn)?shù)字的 —— 這就給出了一個指示:

我們能 “從數(shù)學(xué)上” 說說網(wǎng)絡(luò)是如何區(qū)分的嗎?并非如此。它只是在 “做神經(jīng)網(wǎng)絡(luò)所做的事” 而已。但事實(shí)證明,這通常似乎與我們?nèi)祟愃鞯膮^(qū)分相當(dāng)吻合。讓我們舉一個更復(fù)雜的例子。比方說,我們有貓和狗的圖像。我們有一個神經(jīng)網(wǎng)絡(luò),它被訓(xùn)練來區(qū)分它們。下面是它在一些例子中可能做的事情:

現(xiàn)在,“正確答案” 是什么就更不清楚了。穿著貓衣的狗怎么辦?等等。無論給它什么輸入,神經(jīng)網(wǎng)絡(luò)都會產(chǎn)生一個答案。而且,事實(shí)證明,這樣做的方式與人類可能做的事情是合理一致的。正如我在上面所說的,這不是一個我們可以 “從第一原理推導(dǎo)” 的事實(shí)。它只是根據(jù)經(jīng)驗(yàn)被發(fā)現(xiàn)是真的,至少在某些領(lǐng)域是這樣。但這是神經(jīng)網(wǎng)絡(luò)有用的一個關(guān)鍵原因:它們以某種方式捕捉了 “類似人類” 的做事方式。給自己看一張貓的照片,然后問 “為什么那是一只貓?”。
也許你會開始說 “嗯,我看到它的尖耳朵,等等”。但要解釋你是如何認(rèn)出這張圖片是一只貓的,并不是很容易。只是你的大腦不知怎么想出來的。但是對于大腦來說,沒有辦法(至少現(xiàn)在還沒有)“進(jìn)入” 它的內(nèi)部,看看它是如何想出來的。那么對于一個(人工)神經(jīng)網(wǎng)來說呢?好吧,當(dāng)你展示一張貓的圖片時,可以直接看到每個 “神經(jīng)元” 的作用。但是,即使要獲得一個基本的可視化,通常也是非常困難的。在我們用于解決上述 “最近點(diǎn)” 問題的最終網(wǎng)絡(luò)中,有 17 個神經(jīng)元。在用于識別手寫數(shù)字的網(wǎng)絡(luò)中,有 2190 個。而在我們用來識別貓和狗的網(wǎng)絡(luò)中,有 60,650 個。通常情況下,要將相當(dāng)于 60,650 個維度的空間可視化是相當(dāng)困難的。但由于這是一個為處理圖像而設(shè)置的網(wǎng)絡(luò),它的許多神經(jīng)元層被組織成陣列,就像它所看的像素陣列一樣。如果我們采取一個典型的貓圖像: 那么我們就可以用一組衍生圖像來表示第一層神經(jīng)元的狀態(tài) —— 其中許多圖像我們可以很容易地解釋為 “沒有背景的貓” 或 “貓的輪廓” 等:
那么我們就可以用一組衍生圖像來表示第一層神經(jīng)元的狀態(tài) —— 其中許多圖像我們可以很容易地解釋為 “沒有背景的貓” 或 “貓的輪廓” 等:

到了第十層,就更難解釋發(fā)生了什么:

但總的來說,我們可以說神經(jīng)網(wǎng)絡(luò)正在 “挑選出某些特征”(也許尖尖的耳朵也在其中),并利用這些特征來確定圖像是什么。但這些特征是我們有名字的,比如 “尖耳朵”?大多數(shù)情況下不是。我們的大腦在使用類似的特征嗎?大多數(shù)情況下我們不知道。但值得注意的是,像我們在這里展示的神經(jīng)網(wǎng)絡(luò)的前幾層似乎可以挑出圖像的某些方面(如物體的邊緣),這些方面似乎與我們知道的由大腦中第一層視覺處理挑出的特征相似。但是,假設(shè)我們想要一個神經(jīng)網(wǎng)絡(luò)的 “貓識別理論”。
我們可以說 “看,這個特定的網(wǎng)絡(luò)做到了” —— 這立即給了我們一些關(guān)于 “問題有多難” 的感覺(例如,可能需要多少個神經(jīng)元或?qū)樱5辽俚浆F(xiàn)在為止,我們還沒有辦法對網(wǎng)絡(luò)正在做的事情進(jìn)行 “敘述性描述”。也許這是因?yàn)樗谟?jì)算上確實(shí)是不可簡化的,而且除了明確地追蹤每一個步驟之外,沒有一般的方法可以找到它在做什么。也可能只是因?yàn)槲覀冞€沒有 “弄清科學(xué)”,還沒有確定 “自然法則”,使我們能夠總結(jié)出正在發(fā)生的事情。當(dāng)我們談?wù)撚?ChatGPT 生成語言時,我們會遇到同樣的問題。而且同樣不清楚是否有辦法 “總結(jié)它在做什么”。但是語言的豐富性和細(xì)節(jié)(以及我們在這方面的經(jīng)驗(yàn))可能會讓我們比圖像走得更遠(yuǎn)。
— 4 —機(jī)器學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)的訓(xùn)練
到目前為止,我們一直在談?wù)撃切?“已經(jīng)知道” 如何完成特定任務(wù)的神經(jīng)網(wǎng)絡(luò)。但是,神經(jīng)網(wǎng)絡(luò)之所以如此有用(估計(jì)也是在大腦中),是因?yàn)樗鼈儾粌H在原則上可以完成各種任務(wù),而且可以逐步 “根據(jù)實(shí)例訓(xùn)練” 來完成這些任務(wù)。當(dāng)我們制作一個區(qū)分貓和狗的神經(jīng)網(wǎng)絡(luò)時,我們實(shí)際上不需要寫一個程序來(比如說)明確地找到胡須;相反,我們只需要展示大量關(guān)于什么是貓和什么是狗的例子,然后讓網(wǎng)絡(luò)從這些例子中 “機(jī)器學(xué)習(xí)” 如何去區(qū)分它們。重點(diǎn)是,訓(xùn)練有素的網(wǎng)絡(luò)從它所展示的特定例子中 “概括” 出來。
正如我們在上面看到的,這并不是簡單地讓網(wǎng)絡(luò)識別它所看到的貓咪圖像的特定像素模式;而是讓神經(jīng)網(wǎng)絡(luò)以某種方式設(shè)法在我們認(rèn)為是某種 “一般貓性” 的基礎(chǔ)上區(qū)分圖像。那么,神經(jīng)網(wǎng)絡(luò)的訓(xùn)練究竟是如何進(jìn)行的呢?從本質(zhì)上講,我們一直在努力尋找能夠使神經(jīng)網(wǎng)絡(luò)成功重現(xiàn)我們所給的例子的權(quán)重。然后,我們依靠神經(jīng)網(wǎng)絡(luò)以 “合理” 的方式在這些例子之間進(jìn)行 “插值”(或 “概括”)。讓我們看看一個比上面的最近點(diǎn)的問題更簡單的問題。讓我們只嘗試讓一個神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)函數(shù):
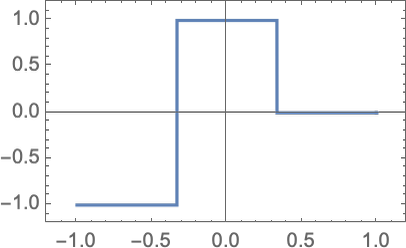
對于這個任務(wù),我們需要一個只有一個輸入和一個輸出的網(wǎng)絡(luò),比如:
但我們應(yīng)該使用什么權(quán)重等?在每一組可能的權(quán)重下,神經(jīng)網(wǎng)絡(luò)都會計(jì)算出一些函數(shù)。例如,這里是它用幾組隨機(jī)選擇的權(quán)重所做的事情:
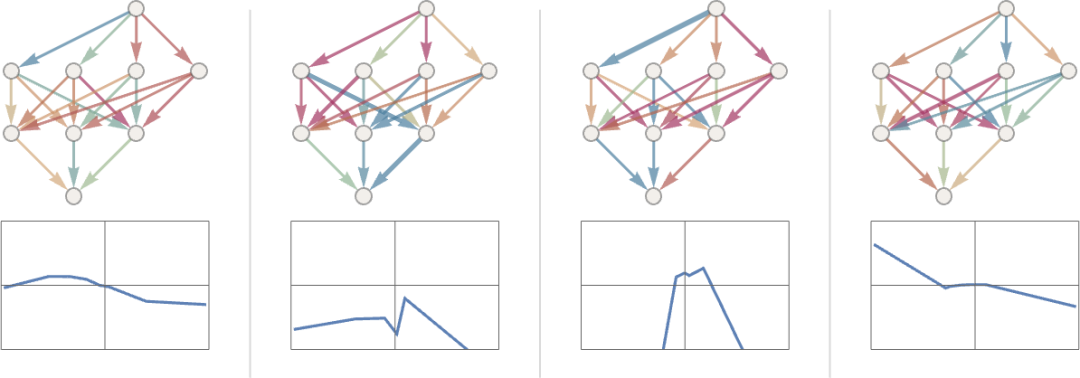
是的,我們可以清楚地看到,在這些情況下,它甚至都沒有接近再現(xiàn)我們想要的函數(shù)。那么,我們?nèi)绾握业侥軌蛑噩F(xiàn)該功能的權(quán)重呢?基本的想法是提供大量的 “輸入→輸出” 的例子來 “學(xué)習(xí)” —— 然后嘗試找到能重現(xiàn)這些例子的權(quán)重。下面是用逐漸增多的例子來做的結(jié)果:
在這個 “訓(xùn)練” 的每個階段,網(wǎng)絡(luò)中的權(quán)重都被逐步調(diào)整 —— 我們看到,最終我們得到了一個能成功重現(xiàn)我們想要的功能的網(wǎng)絡(luò)。那么,我們是如何調(diào)整權(quán)重的呢?基本的想法是在每個階段看看我們離得到我們想要的功能 “有多遠(yuǎn)”,然后以這樣的方式更新權(quán)重,使之更接近。為了找出 “我們有多遠(yuǎn)”,我們計(jì)算通常被稱為 “損失函數(shù)”(或有時稱為 “成本函數(shù)”)的東西。這里我們使用的是一個簡單的(L2)損失函數(shù),它只是我們得到的值與真實(shí)值之間的差異的平方之和。我們看到的是,隨著我們訓(xùn)練過程的進(jìn)展,損失函數(shù)逐漸減少(遵循一定的 “學(xué)習(xí)曲線”,不同的任務(wù)是不同的) —— 直到我們達(dá)到一個點(diǎn),網(wǎng)絡(luò)(至少是一個很好的近似值)成功再現(xiàn)了我們想要的函數(shù):

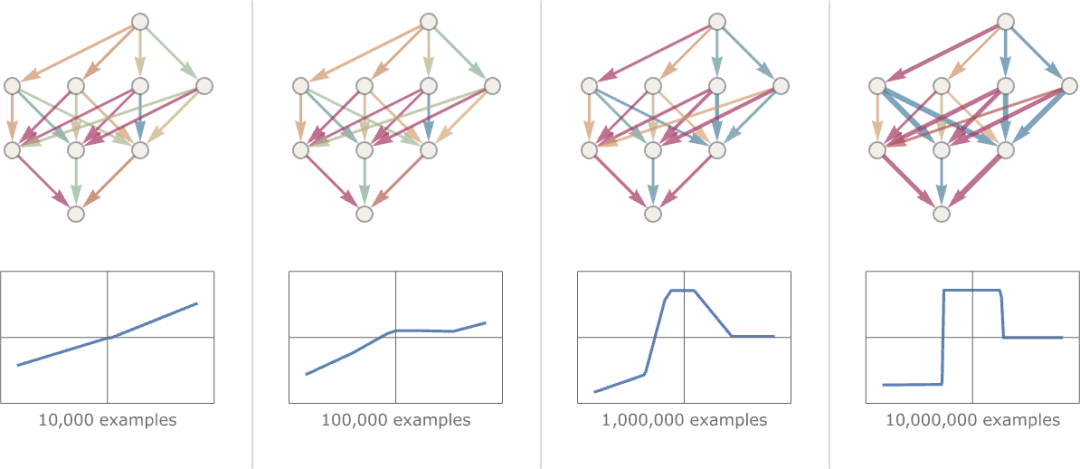
好了,最后要解釋的重要部分是如何調(diào)整權(quán)重以減少損失函數(shù)。正如我們所說,損失函數(shù)給我們提供了我們得到的值與真實(shí)值之間的 “距離”。但是 “我們得到的值” 在每個階段都是由當(dāng)前版本的神經(jīng)網(wǎng)絡(luò)和其中的權(quán)重決定的。但現(xiàn)在想象一下,這些權(quán)重是變量 —— 比如說 wi。我們想找出如何調(diào)整這些變量的值,以使取決于這些變量的損失最小。例如,想象一下(對實(shí)踐中使用的典型神經(jīng)網(wǎng)絡(luò)進(jìn)行了不可思議的簡化),我們只有兩個權(quán)重 w1 和 w2。那么我們可能有一個損失,作為 w1 和 w2 的函數(shù),看起來像這樣:
數(shù)值分析提供了各種技術(shù)來尋找這樣的情況下的最小值。但一個典型的方法是,從之前的 w1、w2 開始,逐步遵循最陡峭的下降路徑:

就像水從山上流下來一樣,所能保證的是這個過程最終會在地表的某個局部最小值(“一個山湖”);它很可能達(dá)不到最終的全球最小值。在 “重量景觀” 上找到最陡峭的下降路徑并不明顯,這是不可行的。但是,微積分可以幫助我們。正如我們上面提到的,我們總是可以把神經(jīng)網(wǎng)看作是在計(jì)算一個數(shù)學(xué)函數(shù) —— 它取決于它的輸入和權(quán)重。但現(xiàn)在考慮對這些權(quán)重進(jìn)行微分。事實(shí)證明,微積分的連鎖法則實(shí)際上可以讓我們 “解開” 神經(jīng)網(wǎng)中連續(xù)幾層所做的運(yùn)算。其結(jié)果是,我們可以 —— 至少在某些局部近似中 —— “反轉(zhuǎn)” 神經(jīng)網(wǎng)的操作,并逐步找到使與輸出相關(guān)的損失最小的權(quán)重。上圖顯示了在只有 2 個權(quán)重的不現(xiàn)實(shí)的簡單情況下,我們可能需要做的最小化工作。但事實(shí)證明,即使有更多的權(quán)重(ChatGPT 使用了 1750 億個),仍有可能做到最小化,至少在某種程度上是近似的。事實(shí)上,2011 年左右發(fā)生的 “深度學(xué)習(xí)” 的重大突破與以下發(fā)現(xiàn)有關(guān):從某種意義上說,當(dāng)有很多權(quán)重參與時,做(至少是近似)最小化比有相當(dāng)少的權(quán)重更容易。
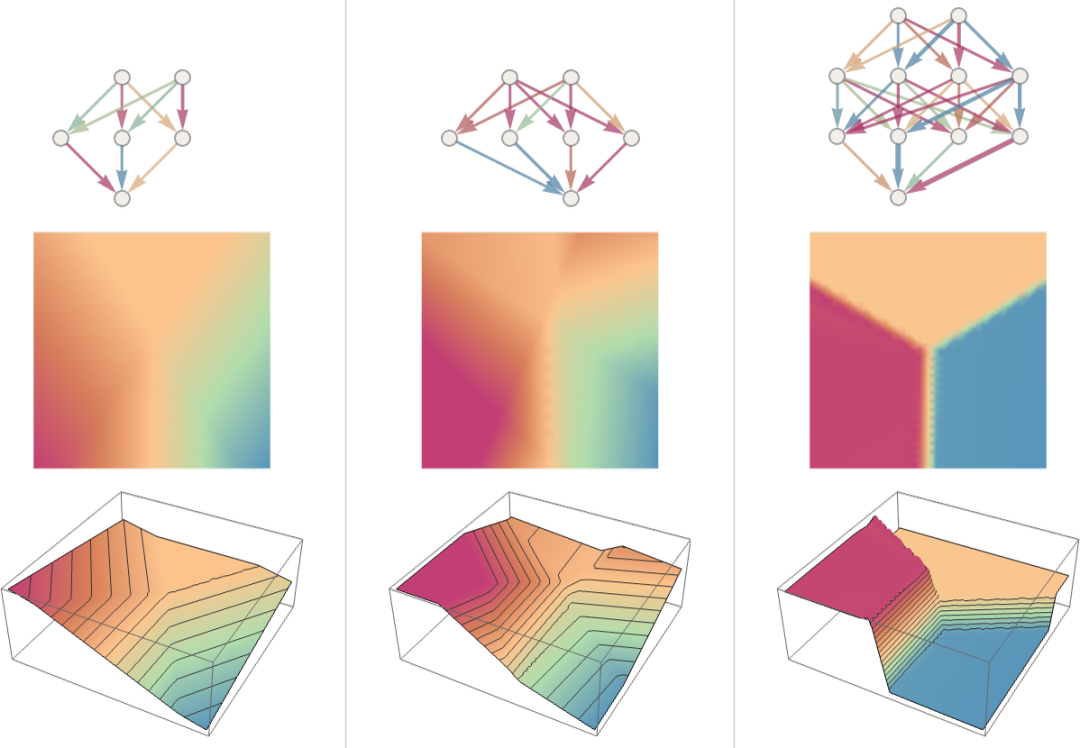
換句話說 —— 有點(diǎn)反直覺 —— 用神經(jīng)網(wǎng)絡(luò)解決更復(fù)雜的問題比簡單的問題更容易。其大致原因似乎是,當(dāng)一個人有很多 “權(quán)重變量” 時,他有一個高維空間,有 “很多不同的方向”,可以把他引向最小值 —— 而如果變量較少,則更容易陷入一個局部最小值(“山湖”),沒有 “方向可以出去”。值得指出的是,在典型的情況下,有許多不同的權(quán)重集合,它們都能使神經(jīng)網(wǎng)絡(luò)具有幾乎相同的性能。而在實(shí)際的神經(jīng)網(wǎng)絡(luò)訓(xùn)練中,通常會有很多隨機(jī)的選擇,導(dǎo)致 “不同但等同的解決方案”,就像這些:

但每一個這樣的 “不同的解決方案” 至少會有輕微的不同行為。如果我們要求,比如說,在我們提供訓(xùn)練實(shí)例的區(qū)域之外進(jìn)行 “外推”,我們可以得到極大的不同結(jié)果:

但是哪一個是 “正確的” 呢?真的沒有辦法說。它們都 “與觀察到的數(shù)據(jù)一致”。但它們都對應(yīng)著不同的 “先天” 方式來 “思考” 如何在 “盒子外” 做什么。對我們?nèi)祟悂碚f,有些可能比其他的看起來 “更合理”。
— 5 —神經(jīng)網(wǎng)絡(luò)訓(xùn)練的實(shí)踐與理論特別是在過去的十年里,在訓(xùn)練神經(jīng)網(wǎng)絡(luò)的藝術(shù)方面取得了許多進(jìn)展。而且,是的,這基本上是一門藝術(shù)。有時,特別是在回顧中,人們至少可以看到正在做的事情有一絲 “科學(xué)解釋” 的影子。但大多數(shù)情況下,事情都是通過試驗(yàn)和錯誤發(fā)現(xiàn)的,增加了一些想法和技巧,逐步建立了一個關(guān)于如何使用神經(jīng)網(wǎng)絡(luò)的重要傳說。有幾個關(guān)鍵部分。首先,對于一個特定的任務(wù),應(yīng)該使用什么架構(gòu)的神經(jīng)網(wǎng)絡(luò)。然后,還有一個關(guān)鍵問題,即如何獲得訓(xùn)練神經(jīng)網(wǎng)絡(luò)的數(shù)據(jù)。而且,人們越來越多地不是在處理從頭開始訓(xùn)練一個網(wǎng)絡(luò)的問題:相反,一個新的網(wǎng)絡(luò)可以直接納入另一個已經(jīng)訓(xùn)練好的網(wǎng)絡(luò),或者至少可以使用該網(wǎng)絡(luò)為自己產(chǎn)生更多的訓(xùn)練實(shí)例。
人們可能認(rèn)為,對于每一種特定的任務(wù),人們都需要一個不同的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。但人們發(fā)現(xiàn),即使是對于明顯不同的任務(wù),相同的架構(gòu)似乎也能發(fā)揮作用。在某種程度上,這讓人想起了通用計(jì)算的想法(以及我的計(jì)算等價(jià)原則),但是,正如我將在后面討論的那樣,我認(rèn)為這更多地反映了這樣一個事實(shí),即我們通常試圖讓神經(jīng)網(wǎng)絡(luò)做的任務(wù)是 “類似人類” 的,而神經(jīng)網(wǎng)絡(luò)可以捕獲相當(dāng)普遍的 “類似人類的過程”。在早期的神經(jīng)網(wǎng)絡(luò)中,人們傾向于認(rèn)為應(yīng)該 “讓神經(jīng)網(wǎng)絡(luò)盡可能地少做”。例如,在將語音轉(zhuǎn)換為文本時,人們認(rèn)為應(yīng)該首先分析語音的音頻,將其分解為音素,等等。但人們發(fā)現(xiàn),至少對于 “類似人類的任務(wù)” 來說,通常更好的做法是嘗試在 “端到端問題” 上訓(xùn)練神經(jīng)網(wǎng)絡(luò),讓它自己 “發(fā)現(xiàn)” 必要的中間特征、編碼等。
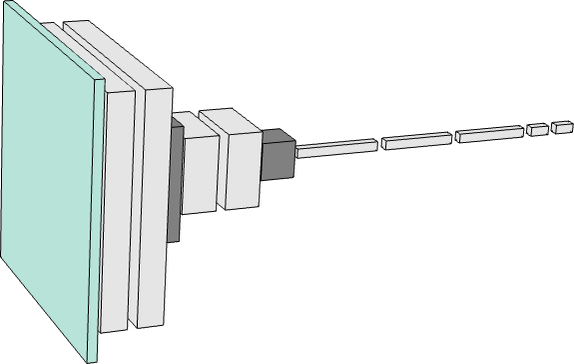
還有一個想法是,我們應(yīng)該在神經(jīng)網(wǎng)絡(luò)中引入復(fù)雜的單獨(dú)組件,讓它實(shí)際上 “明確地實(shí)現(xiàn)特定的算法想法”。但是,這又一次被證明是不值得的;相反,最好只是處理非常簡單的組件,讓它們 “自我組織”(盡管通常是以我們無法理解的方式)來實(shí)現(xiàn)(大概)那些算法想法的等價(jià)物。這并不是說沒有與神經(jīng)網(wǎng)絡(luò)相關(guān)的 “結(jié)構(gòu)化思想”。因此,例如,具有局部連接的二維神經(jīng)元陣列似乎至少在處理圖像的早期階段非常有用。而擁有專注于 “回顧序列” 的連接模式似乎很有用 —— 我們將在后面看到 —— 在處理人類語言等事物時,例如在 ChatGPT 中。但神經(jīng)網(wǎng)絡(luò)的一個重要特點(diǎn)是,像一般的計(jì)算機(jī)一樣,它們最終只是在處理數(shù)據(jù)。而目前的神經(jīng)網(wǎng)絡(luò) —— 目前的神經(jīng)網(wǎng)絡(luò)訓(xùn)練方法 —— 是專門處理數(shù)字陣列的。但在處理過程中,這些數(shù)組可以被完全重新排列和重塑。舉個例子,我們上面用來識別數(shù)字的網(wǎng)絡(luò)從一個二維的 “圖像” 陣列開始,迅速 “增厚” 到許多通道,但隨后 “濃縮” 成一個一維陣列,最終將包含代表不同可能輸出數(shù)字的元素:
但是,好吧,如何判斷一個特定的任務(wù)需要多大的神經(jīng)網(wǎng)?這是一門藝術(shù)。在某種程度上,關(guān)鍵是要知道 “這個任務(wù)有多難”。但對于類似人類的任務(wù)來說,這通常是很難估計(jì)的。是的,可能有一種系統(tǒng)的方法可以通過計(jì)算機(jī)非常 “機(jī)械” 地完成任務(wù)。但很難知道是否存在人們認(rèn)為的技巧或捷徑,使人們至少在 “類似人類的水平” 上更容易地完成這項(xiàng)任務(wù)。可能需要列舉一個巨大的游戲樹來 “機(jī)械地” 玩某個游戲;但可能有一個更容易(“啟發(fā)式”)的方法來實(shí)現(xiàn) “人類水平的游戲”。當(dāng)人們在處理微小的神經(jīng)網(wǎng)絡(luò)和簡單的任務(wù)時,有時可以明確地看到 “從這里不能到達(dá)那里”。例如,這是人們在上一節(jié)的任務(wù)中用幾個小的神經(jīng)網(wǎng)絡(luò)似乎能做到的最好的結(jié)果:
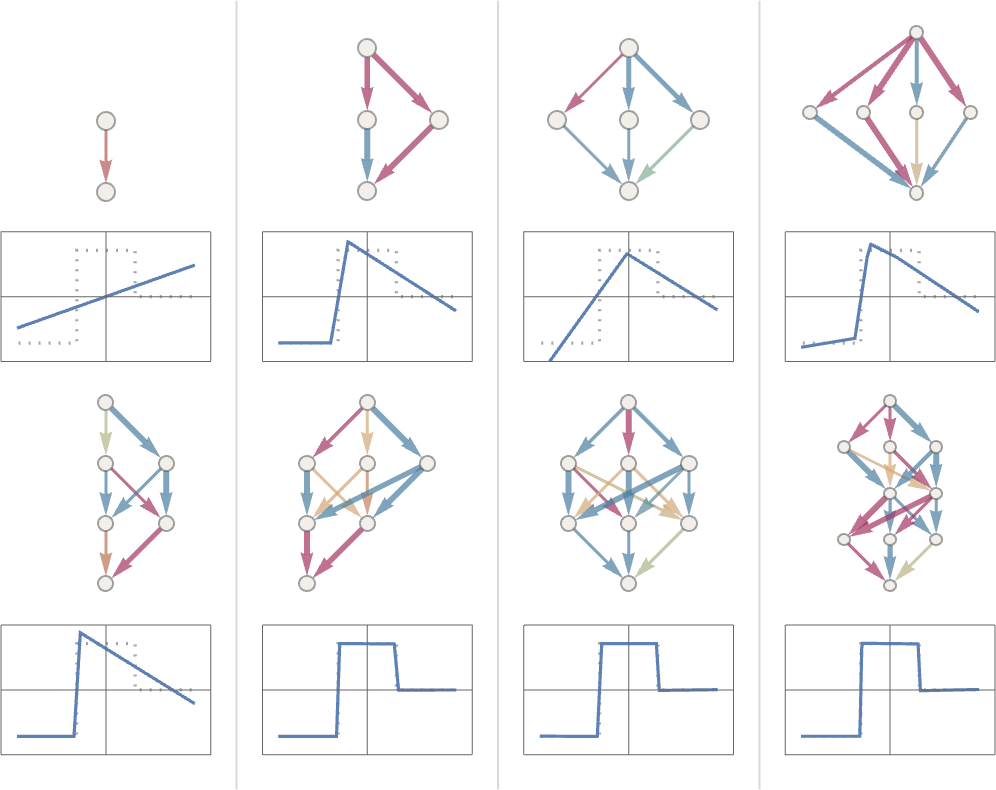
而我們的情況是,如果網(wǎng)太小,它就不能再現(xiàn)我們想要的功能。但如果超過一定的規(guī)模,它就沒有問題了 —— 至少如果一個人用足夠長的時間和足夠多的例子訓(xùn)練它。順便說一下,這些圖片說明了一個神經(jīng)網(wǎng)絡(luò)的傳說:如果中間有一個 “擠壓”,迫使所有東西都通過一個較小的中間神經(jīng)元數(shù)量,那么我們往往可以用一個較小的網(wǎng)絡(luò)。(值得一提的是,“無中間層” —— 或所謂的 “感知器” —— 網(wǎng)絡(luò)只能學(xué)習(xí)本質(zhì)上的線性函數(shù) —— 但只要有一個中間層,原則上就可以任意很好地近似任何函數(shù),至少如果有足夠的神經(jīng)元,盡管為了使其可行地訓(xùn)練,通常需要某種正則化或規(guī)范化)。好吧,讓我們假設(shè)我們已經(jīng)確定了某種神經(jīng)網(wǎng)絡(luò)架構(gòu)。現(xiàn)在有一個問題,就是如何獲得數(shù)據(jù)來訓(xùn)練網(wǎng)絡(luò)。圍繞神經(jīng)網(wǎng)絡(luò)和一般機(jī)器學(xué)習(xí)的許多實(shí)際挑戰(zhàn)都集中在獲取或準(zhǔn)備必要的訓(xùn)練數(shù)據(jù)上。
在許多情況下(“監(jiān)督學(xué)習(xí)”),人們希望獲得明確的輸入和期望的輸出的例子。因此,舉例來說,人們可能希望通過圖像中的內(nèi)容或一些其他屬性來標(biāo)記圖像。也許我們必須明確地去做 —— 通常是費(fèi)盡心機(jī)地去做標(biāo)記。但是很多時候,我們可以借助已經(jīng)完成的工作,或者將其作為某種代理。因此,舉例來說,我們可以使用網(wǎng)絡(luò)上已經(jīng)提供的圖片的 alt 標(biāo)簽。或者,在另一個領(lǐng)域,我們可以使用為視頻創(chuàng)建的封閉式字幕。或者在語言翻譯訓(xùn)練中,可以使用不同語言的網(wǎng)頁或其他文件的平行版本。你需要向神經(jīng)網(wǎng)絡(luò)展示多少數(shù)據(jù)來訓(xùn)練它完成一項(xiàng)特定任務(wù)?同樣,這很難從第一原理上估計(jì)。當(dāng)然,通過使用 “轉(zhuǎn)移學(xué)習(xí)” 來 “轉(zhuǎn)移” 諸如已經(jīng)在另一個網(wǎng)絡(luò)中學(xué)習(xí)過的重要特征列表的東西,可以大大降低要求。但一般來說,神經(jīng)網(wǎng)絡(luò)需要 “看到大量的例子” 才能訓(xùn)練好。而至少對于某些任務(wù)來說,神經(jīng)網(wǎng)絡(luò)的一個重要傳說是,這些例子可能是非常重復(fù)的。
事實(shí)上,向神經(jīng)網(wǎng)絡(luò)展示所有的例子是一個標(biāo)準(zhǔn)的策略,一遍又一遍。在每個 “訓(xùn)練回合”(或 “epochs”)中,神經(jīng)網(wǎng)絡(luò)至少會處于一個稍微不同的狀態(tài),而以某種方式 “提醒” 它某個特定的例子對于讓它 “記住那個例子” 是很有用的。(是的,也許這類似于人類記憶中的重復(fù)的有用性)。但往往只是反復(fù)重復(fù)同一個例子是不夠的。還需要向神經(jīng)網(wǎng)絡(luò)展示這個例子的變化。而神經(jīng)網(wǎng)絡(luò)理論的一個特點(diǎn)是,這些 “數(shù)據(jù)增強(qiáng)” 的變化不一定要復(fù)雜才有用。只要用基本的圖像處理方法稍微修改一下圖像,就可以使它們在神經(jīng)網(wǎng)絡(luò)訓(xùn)練中基本上 “像新的一樣好”。同樣,當(dāng)人們沒有實(shí)際的視頻等來訓(xùn)練自動駕駛汽車時,人們可以繼續(xù)從模擬的視頻游戲環(huán)境中獲得數(shù)據(jù),而不需要實(shí)際的真實(shí)世界場景的所有細(xì)節(jié)。
像 ChatGPT 這樣的東西如何呢?嗯,它有一個很好的特點(diǎn),那就是它可以進(jìn)行 “無監(jiān)督學(xué)習(xí)”,這使得它更容易得到用于訓(xùn)練的例子。回顧一下,ChatGPT 的基本任務(wù)是找出如何繼續(xù)它所給的一段文字。因此,為了獲得 “訓(xùn)練實(shí)例”,我們所要做的就是獲得一段文本,并將其結(jié)尾遮蓋起來,然后將其作為 “訓(xùn)練的輸入” —— “輸出” 是完整的、未被遮蓋的文本。我們稍后會詳細(xì)討論這個問題,但主要的一點(diǎn)是,與學(xué)習(xí)圖片中的內(nèi)容不同,不需要 “明確的標(biāo)簽”;ChatGPT 實(shí)際上可以直接從它所得到的任何文本例子中學(xué)習(xí)。
好吧,那么神經(jīng)網(wǎng)絡(luò)的實(shí)際學(xué)習(xí)過程是怎樣的呢?歸根結(jié)底,這都是為了確定什么權(quán)重能夠最好地捕捉所給的訓(xùn)練實(shí)例。有各種詳細(xì)的選擇和 “超參數(shù)設(shè)置”(之所以被稱為超參數(shù),是因?yàn)榭梢园褭?quán)重看作是 “參數(shù)”),可以用來調(diào)整如何完成這一過程。有不同的損失函數(shù)選擇(平方之和、絕對值之和,等等)。有不同的方法來進(jìn)行損失最小化(每一步要在權(quán)重空間中移動多遠(yuǎn),等等)。然后還有一些問題,比如要展示多大的 “一批” 例子來獲得每一個試圖最小化的損失的連續(xù)估計(jì)。而且,是的,人們可以應(yīng)用機(jī)器學(xué)習(xí)(例如,我們在 Wolfram 語言中所做的)來實(shí)現(xiàn)機(jī)器學(xué)習(xí)的自動化 —— 自動設(shè)置超參數(shù)等東西。但最終,整個訓(xùn)練過程的特點(diǎn)是看到損失是如何逐漸減少的(如這個 Wolfram Language 的小型訓(xùn)練的進(jìn)度監(jiān)視器):
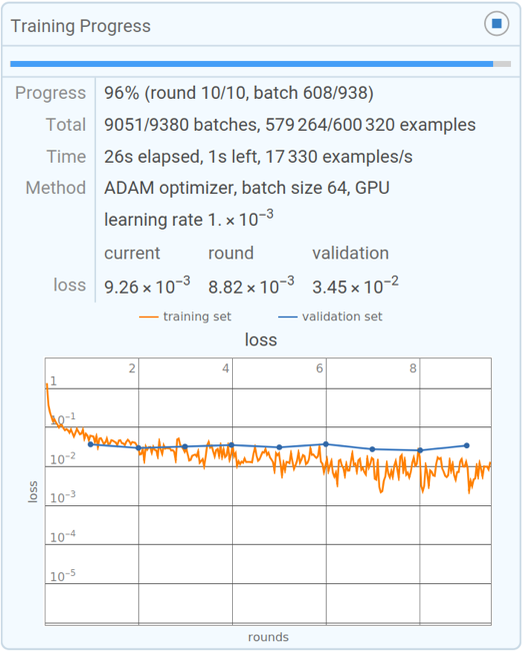
而人們通常看到的是,損失在一段時間內(nèi)減少,但最終在某個恒定值上趨于平緩。如果這個值足夠小,那么可以認(rèn)為訓(xùn)練是成功的;否則,這可能是一個應(yīng)該嘗試改變網(wǎng)絡(luò)結(jié)構(gòu)的信號。能否告訴我們 “學(xué)習(xí)曲線” 要花多長時間才能變平?就像許多其他事情一樣,似乎有近似的冪律縮放關(guān)系,這取決于神經(jīng)網(wǎng)絡(luò)的大小和使用的數(shù)據(jù)量。但一般的結(jié)論是,訓(xùn)練一個神經(jīng)網(wǎng)絡(luò)是很難的,需要大量的計(jì)算努力。作為一個實(shí)際問題,這些努力的絕大部分都花在了對數(shù)字陣列的操作上,而這正是 GPU 所擅長的 —— 這就是為什么神經(jīng)網(wǎng)絡(luò)訓(xùn)練通常受限于 GPU 的可用性。在未來,是否會有從根本上更好的方法來訓(xùn)練神經(jīng)網(wǎng)絡(luò),或者一般地做神經(jīng)網(wǎng)絡(luò)的工作?我認(rèn)為,幾乎可以肯定。
神經(jīng)網(wǎng)絡(luò)的基本理念是用大量簡單(本質(zhì)上相同)的組件創(chuàng)建一個靈活的 “計(jì)算結(jié)構(gòu)”,并讓這個 “結(jié)構(gòu)” 能夠被逐步修改,以便從實(shí)例中學(xué)習(xí)。在目前的神經(jīng)網(wǎng)絡(luò)中,人們基本上是使用微積分的思想 —— 應(yīng)用于實(shí)數(shù) —— 來做這種增量修改。但越來越清楚的是,擁有高精度的數(shù)字并不重要;即使用目前的方法,8 位或更少的數(shù)字可能也足夠了。像蜂窩自動機(jī)這樣的計(jì)算系統(tǒng),基本上是在許多單獨(dú)的比特上并行操作的,如何做這種增量修改從來都不清楚,但沒有理由認(rèn)為它不可能。事實(shí)上,就像 “2012 年深度學(xué)習(xí)的突破” 一樣,這種增量修改在更復(fù)雜的情況下可能比簡單的情況下更容易。
神經(jīng)網(wǎng)絡(luò) —— 也許有點(diǎn)像大腦 —— 被設(shè)定為擁有一個基本固定的神經(jīng)元網(wǎng)絡(luò),被修改的是它們之間連接的強(qiáng)度(“重量”)。(也許至少在年輕的大腦中,大量的完全新的連接也可以增長。) 但是,雖然這對生物學(xué)來說可能是一個方便的設(shè)置,但并不清楚它是否是實(shí)現(xiàn)我們所需功能的最佳方式。而涉及漸進(jìn)式網(wǎng)絡(luò)重寫的東西(也許讓人想起我們的物理項(xiàng)目)最終可能會更好。
但即使在現(xiàn)有的神經(jīng)網(wǎng)絡(luò)框架內(nèi),目前也有一個關(guān)鍵的限制:現(xiàn)在的神經(jīng)網(wǎng)絡(luò)訓(xùn)練從根本上說是連續(xù)的,每一批例子的效果都被傳播回來以更新權(quán)重。事實(shí)上,就目前的計(jì)算機(jī)硬件而言 —— 即使考慮到 GPU —— 在訓(xùn)練期間,神經(jīng)網(wǎng)絡(luò)的大部分時間都是 “閑置” 的,每次只有一個部分被更新。從某種意義上說,這是因?yàn)槲覀兡壳暗挠?jì)算機(jī)往往有獨(dú)立于 CPU(或 GPU)的內(nèi)存。但在大腦中,這大概是不同的 —— 每一個 “記憶元素”(即神經(jīng)元)也是一個潛在的活躍的計(jì)算元素。
如果我們能夠以這種方式設(shè)置我們未來的計(jì)算機(jī)硬件,就有可能更有效地進(jìn)行訓(xùn)練。“當(dāng)然,一個足夠大的網(wǎng)絡(luò)可以做任何事情!”像 ChatGPT 這樣的能力似乎令人印象深刻,人們可能會想象,如果人們能夠 “繼續(xù)下去”,訓(xùn)練越來越大的神經(jīng)網(wǎng)絡(luò),那么它們最終將能夠 “做任何事情”。如果人們關(guān)注的是那些容易被人類直接思考的事物,那么很有可能是這樣的。
但是,過去幾百年科學(xué)的教訓(xùn)是,有些東西可以通過形式化的過程來計(jì)算出來,但并不容易被人類的直接思維所獲得。非瑣碎的數(shù)學(xué)就是一個大例子。但一般的情況其實(shí)是計(jì)算。而最終的問題是計(jì)算的不可還原性現(xiàn)象。有一些計(jì)算,人們可能認(rèn)為需要很多步驟才能完成,但事實(shí)上可以 “簡化” 為相當(dāng)直接的東西。但計(jì)算的不可簡化性的發(fā)現(xiàn)意味著這并不總是有效的。相反,有些過程 —— 可能就像下面這個過程 —— 要弄清楚發(fā)生了什么,必然需要對每個計(jì)算步驟進(jìn)行追蹤:

我們通常用大腦做的那些事情,大概是專門為避免計(jì)算的不可還原性而選擇的。在一個人的大腦中做數(shù)學(xué)需要特別的努力。而且,在實(shí)踐中,僅僅在一個人的大腦中 “思考” 任何非微觀程序的操作步驟,在很大程度上是不可能的。當(dāng)然,為此我們有計(jì)算機(jī)。有了計(jì)算機(jī),我們可以很容易地做很長的、計(jì)算上不可簡化的事情。而關(guān)鍵的一點(diǎn)是,這些事情一般來說沒有捷徑。是的,我們可以記住很多關(guān)于在某個特定計(jì)算系統(tǒng)中發(fā)生的具體例子。也許我們甚至可以看到一些(“計(jì)算上可還原的”)模式,使我們可以做一點(diǎn)概括。但問題是,計(jì)算上的不可還原性意味著我們永遠(yuǎn)無法保證意外不會發(fā)生 —— 只有通過明確地進(jìn)行計(jì)算,你才能知道在任何特定情況下實(shí)際發(fā)生了什么。最后,在可學(xué)習(xí)性和計(jì)算的不可重復(fù)性之間存在著一種基本的緊張關(guān)系。
學(xué)習(xí)實(shí)際上是通過利用規(guī)則性來壓縮數(shù)據(jù)。但計(jì)算上的不可復(fù)制性意味著最終對可能存在的規(guī)律性有一個限制。作為一個實(shí)際問題,我們可以想象將一些小的計(jì)算設(shè)備 —— 如蜂窩自動機(jī)或圖靈機(jī) —— 構(gòu)建成像神經(jīng)網(wǎng)絡(luò)這樣的可訓(xùn)練系統(tǒng)。而且,這種設(shè)備確實(shí)可以作為神經(jīng)網(wǎng)的好 “工具”,就像 Wolfram|Alpha 可以作為 ChatGPT 的好工具。但計(jì)算的不可簡化性意味著我們不能指望 “進(jìn)入” 這些設(shè)備并讓它們學(xué)習(xí)。或者換句話說,在能力和可訓(xùn)練性之間有一個最終的權(quán)衡:你越想讓一個系統(tǒng) “真正利用” 它的計(jì)算能力,它就越會顯示出計(jì)算的不可復(fù)制性,它的可訓(xùn)練性就越低。而它越是從根本上可訓(xùn)練,它就越不能做復(fù)雜的計(jì)算。(對于目前的 ChatGPT 來說,情況實(shí)際上要極端得多,因?yàn)橛糜谏擅總€輸出符號的神經(jīng)網(wǎng)絡(luò)是一個純粹的 “前饋” 網(wǎng)絡(luò),沒有循環(huán),因此沒有能力做任何具有非復(fù)雜 “控制流” 的計(jì)算)。當(dāng)然,人們可能會問,能夠做不可還原的計(jì)算是否真的很重要。事實(shí)上,在人類歷史的大部分時間里,這并不特別重要。但我們的現(xiàn)代技術(shù)世界是建立在至少使用數(shù)學(xué)計(jì)算的工程之上的,而且越來越多地使用更普遍的計(jì)算。
如果我們看一下自然界,它充滿了不可簡化的計(jì)算 —— 我們正在慢慢理解如何模仿并用于我們的技術(shù)目的。是的,一個神經(jīng)網(wǎng)絡(luò)當(dāng)然可以注意到自然世界中的各種規(guī)律性,而我們也可能很容易通過 “無助的人類思維” 注意到這些規(guī)律性。但是,如果我們想要解決屬于數(shù)學(xué)或計(jì)算科學(xué)范疇的事情,神經(jīng)網(wǎng)絡(luò)是無法做到的 —— 除非它有效地 “作為工具” 使用一個 “普通” 的計(jì)算系統(tǒng)。但是,這一切都有一些潛在的混淆之處。在過去,有很多任務(wù) —— 包括寫文章 —— 我們認(rèn)為對計(jì)算機(jī)來說 “從根本上說太難了”。而現(xiàn)在我們看到這些任務(wù)是由 ChatGPT 等完成的,我們傾向于突然認(rèn)為計(jì)算機(jī)一定是變得更加強(qiáng)大了,特別是超越了它們已經(jīng)基本能夠做到的事情(比如逐步計(jì)算蜂窩自動機(jī)等計(jì)算系統(tǒng)的行為)。但這并不是正確的結(jié)論。
計(jì)算上不可還原的過程仍然是計(jì)算上不可還原的,而且對計(jì)算機(jī)來說仍然是根本性的困難 —— 即使計(jì)算機(jī)可以輕易地計(jì)算它們的單個步驟。相反,我們應(yīng)該得出的結(jié)論是,我們?nèi)祟惪梢宰龅模覀儾徽J(rèn)為計(jì)算機(jī)可以做的任務(wù),比如寫文章,實(shí)際上在某種意義上比我們想象的更容易計(jì)算。換句話說,神經(jīng)網(wǎng)絡(luò)之所以能夠成功地寫出一篇文章,是因?yàn)閷懸黄恼卤蛔C明是一個比我們想象的 “計(jì)算上更淺” 的問題。從某種意義上說,這使我們更接近于 “擁有一種理論”,即我們?nèi)祟愂侨绾巫龅较駥懳恼逻@樣的事情的,或在一般情況下處理語言。
如果你有一個足夠大的神經(jīng)網(wǎng)絡(luò),那么,是的,你可能能夠做任何人類能夠輕易做到的事情。但是,你不會捕捉到自然界一般能做的事情 —— 或者我們從自然界塑造的工具能做的事情。而正是這些工具的使用 —— 無論是實(shí)用的還是概念性的 —— 使得我們在近幾個世紀(jì)里能夠超越 “純粹的無助的人類思維” 所能達(dá)到的界限,并為人類的目的捕捉到物理和計(jì)算宇宙中的更多東西。
— 6 —嵌入的概念
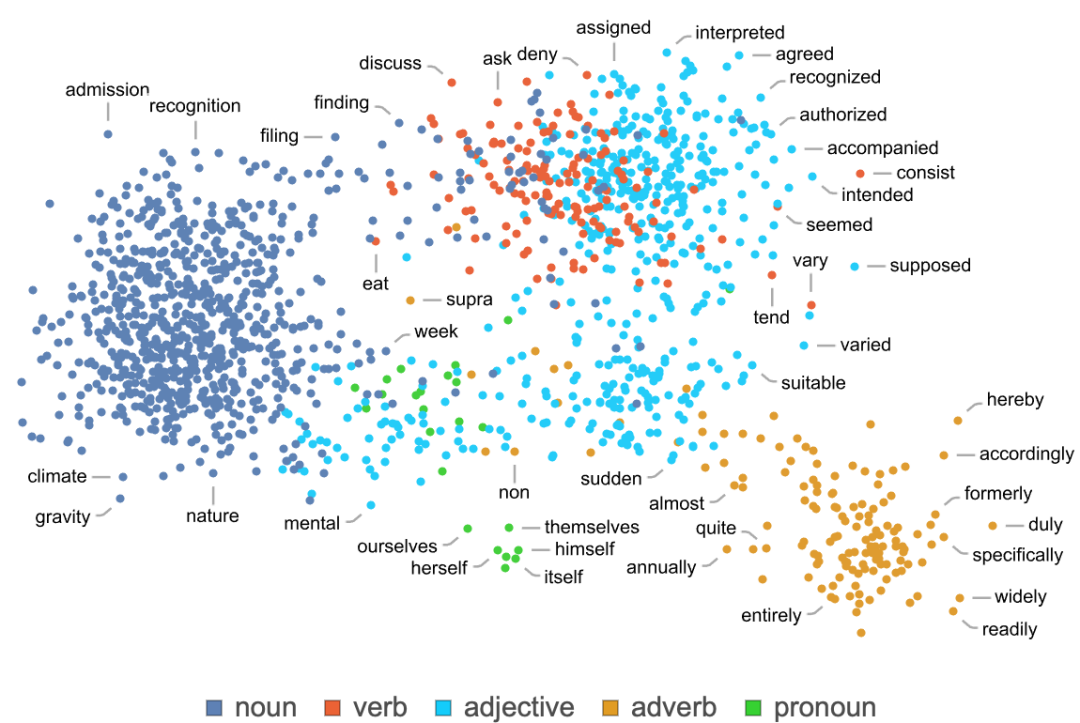
神經(jīng)網(wǎng)絡(luò) —— 至少在它們目前的設(shè)置中 —— 從根本上說是基于數(shù)字的。因此,如果我們要用它們來處理像文本這樣的東西,我們就需要一種方法來用數(shù)字表示我們的文本。當(dāng)然,我們可以開始(基本上就像 ChatGPT 那樣)為字典中的每個詞分配一個數(shù)字。但是,有一個重要的想法 —— 例如,它是 ChatGPT 的核心 —— 超出了這個范圍。這就是 “嵌入” 的概念。我們可以把嵌入看作是一種嘗試用數(shù)字陣列來表示事物 “本質(zhì)” 的方式 —— 其特性是 “附近的事物” 由附近的數(shù)字來表示。因此,舉例來說,我們可以把一個詞的嵌入看作是試圖在一種 “意義空間” 中排列詞語,在這個空間中,以某種方式 “在意義上接近” 的詞語在嵌入中出現(xiàn)。實(shí)際使用的嵌入 —— 例如在 ChatGPT 中 —— 往往涉及大量的數(shù)字列表。但是如果我們把它投射到二維空間,我們就可以顯示出嵌入的單詞是如何排列的例子:

而且,是的,我們看到的東西在捕捉典型的日常印象方面做得非常好。但是,我們怎樣才能構(gòu)建這樣一個嵌入呢?大致的想法是查看大量的文本(這里是來自網(wǎng)絡(luò)的 50 億個詞),然后看不同的詞出現(xiàn)的 “環(huán)境” 有多相似。因此,例如,“alligator” 和 “crocodile” 經(jīng)常會在其他類似的句子中互換出現(xiàn),這意味著它們在嵌入中會被放在附近。但是 “蘿卜” 和 “老鷹” 不會出現(xiàn)在其他類似的句子中,所以它們在嵌入中會被放在很遠(yuǎn)的地方。但是,如何使用神經(jīng)網(wǎng)絡(luò)實(shí)際實(shí)現(xiàn)這樣的東西呢?讓我們先來討論一下不是針對單詞的嵌入,而是針對圖像的嵌入。我們想找到某種方法,通過數(shù)字列表來描述圖像,使 “我們認(rèn)為相似的圖像” 被分配到相似的數(shù)字列表中。
我們?nèi)绾闻袛辔覀兪欠駪?yīng)該 “認(rèn)為圖像相似”?好吧,如果我們的圖像是,例如,手寫的數(shù)字,我們可能會 “認(rèn)為兩個圖像是相似的”,如果它們是相同的數(shù)字。早些時候,我們討論了一個被訓(xùn)練來識別手寫數(shù)字的神經(jīng)網(wǎng)絡(luò)。我們可以認(rèn)為這個神經(jīng)網(wǎng)絡(luò)被設(shè)置成在其最終輸出中把圖像放入 10 個不同的倉,每個數(shù)字一個倉。但是,如果我們在做出 “這是一個 ‘4’” 的最終決定之前,“攔截” 神經(jīng)網(wǎng)絡(luò)內(nèi)部發(fā)生的事情呢?我們可能會想到,在神經(jīng)網(wǎng)絡(luò)中,有一些數(shù)字將圖像描述為 “大部分是 4,但有一點(diǎn)是 2” 或類似的情況。
而我們的想法是挑選出這樣的數(shù)字作為嵌入的元素。所以這里有一個概念。我們不是直接試圖描述 “什么圖像在什么其他圖像附近”,而是考慮一個定義明確的任務(wù)(在這種情況下是數(shù)字識別),我們可以獲得明確的訓(xùn)練數(shù)據(jù) —— 然后利用這樣一個事實(shí),即在做這個任務(wù)時,神經(jīng)網(wǎng)絡(luò)隱含地要做出相當(dāng)于 “接近度決定” 的決定。因此,我們不需要明確地談?wù)?“圖像的接近性”,而只是談?wù)撘粋€圖像代表什么數(shù)字的具體問題,然后我們 “把它留給神經(jīng)網(wǎng)絡(luò)” 來隱含地決定這意味著什么 “圖像的接近性”。那么,這對數(shù)字識別網(wǎng)絡(luò)來說是如何更詳細(xì)地工作的呢?我們可以認(rèn)為這個網(wǎng)絡(luò)是由 11 個連續(xù)的層組成的,我們可以用圖標(biāo)來概括它(激活函數(shù)顯示為獨(dú)立的層):

在開始時,我們向第一層輸入實(shí)際的圖像,用像素值的二維陣列表示。在最后一層,我們得到了一個由 10 個值組成的數(shù)組,我們可以認(rèn)為這表示網(wǎng)絡(luò)對圖像對應(yīng)于 0 到 9 的每個數(shù)字的 “確定程度”。輸入圖像(手寫的 4),最后一層的神經(jīng)元的值就是:
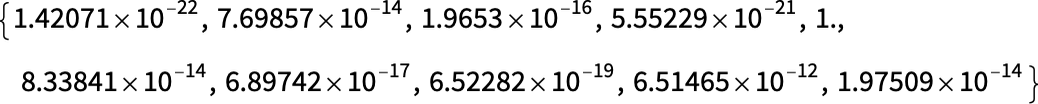
換句話說,神經(jīng)網(wǎng)絡(luò)此時已經(jīng) “非常確定” 這個圖像是 4,為了實(shí)際得到輸出 “4”,我們只需挑選出數(shù)值最大的神經(jīng)元的位置。但是,如果我們再往前看一步呢?網(wǎng)絡(luò)中的最后一個操作是一個所謂的 softmax,它試圖 “強(qiáng)制確定”。但在這之前,神經(jīng)元的值是:
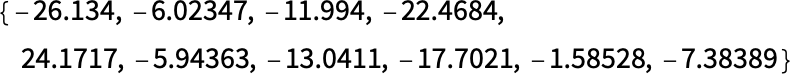
代表 “4” 的神經(jīng)元仍然有最高的數(shù)值。但在其他神經(jīng)元的數(shù)值中也有信息。我們可以期望這個數(shù)字列表在某種意義上可以用來描述圖像的 “本質(zhì)”,從而提供我們可以用作嵌入的東西。因此,例如,這里的每一個 4 都有一個稍微不同的 “簽名”(或 “特征嵌入”) —— 都與 8 的非常不同:

在這里,我們基本上是用 10 個數(shù)字來描述我們的圖像特征。但通常情況下,使用比這更多的數(shù)字會更好。例如,在我們的數(shù)字識別網(wǎng)絡(luò)中,我們可以通過挖掘前一層得到一個 500 個數(shù)字的陣列。而這可能是一個合理的數(shù)組,作為 “圖像嵌入” 使用。如果我們想對手寫數(shù)字的 “圖像空間” 進(jìn)行明確的可視化,我們需要 “降低維度”,有效地將我們得到的 500 維向量投射到,例如,三維空間:
我們剛剛談到為圖像創(chuàng)建一個特征(從而嵌入),有效地基于識別圖像的相似性,確定(根據(jù)我們的訓(xùn)練集)它們是否對應(yīng)于同一個手寫數(shù)字。如果我們有一個訓(xùn)練集,比如說,確定每張圖片屬于 5000 種常見類型的物體(貓、狗、椅子…… ),我們就可以更普遍地對圖片做同樣的事情。通過這種方式,我們可以制作一個圖像嵌入,它被我們對常見物體的識別所 “錨定”,但然后根據(jù)神經(jīng)網(wǎng)絡(luò)的行為 “圍繞它進(jìn)行概括”。關(guān)鍵是,只要這種行為與我們?nèi)祟惛兄徒忉寛D像的方式相一致,這將最終成為一個 “對我們來說是正確的” 的嵌入,并在實(shí)踐中做 “類似人類判斷” 的任務(wù)時有用。
好吧,那么我們?nèi)绾巫裱瑯拥姆椒▉韺ふ覇卧~的嵌入呢?關(guān)鍵是要從一個我們可以隨時進(jìn)行訓(xùn)練的關(guān)于單詞的任務(wù)開始。而標(biāo)準(zhǔn)的任務(wù)是 “單詞預(yù)測”。假設(shè)我們得到了 “the cat”。基于一個大型的文本語料庫(比如說,網(wǎng)絡(luò)上的文本內(nèi)容),可能 “填空” 的不同單詞的概率是多少?或者說,給定 “__ 黑 _”,不同的 “側(cè)翼詞” 的概率是多少?我們?nèi)绾螢樯窠?jīng)網(wǎng)絡(luò)設(shè)置這個問題?歸根結(jié)底,我們必須用數(shù)字來表述一切。做到這一點(diǎn)的一個方法就是為英語中 5 萬個左右的常用詞中的每一個分配一個獨(dú)特的數(shù)字。因此,例如,“the” 可能是 914,而 “cat”(前面有一個空格)可能是 3542。(這些是 GPT-2 所使用的實(shí)際數(shù)字。)所以對于 “the _ cat” 問題,我們的輸入可能是{914, 3542}。輸出應(yīng)該是什么樣子的呢?好吧,它應(yīng)該是一個由 50000 個左右的數(shù)字組成的列表,有效地給出了每個可能的 “填充” 單詞的概率。再一次,為了找到一個嵌入,我們要在神經(jīng)網(wǎng)絡(luò) “達(dá)到結(jié)論” 之前 “攔截” 它的 “內(nèi)部” —— 然后撿起在那里出現(xiàn)的數(shù)字列表,我們可以把它看作是 “每個詞的特征”。
好吧,那么這些表征是什么樣子的呢?在過去的 10 年里,已經(jīng)有一系列不同的系統(tǒng)被開發(fā)出來(word2vec, GloVe, BERT, GPT, …… ),每一個都是基于不同的神經(jīng)網(wǎng)絡(luò)方法。但最終,所有這些系統(tǒng)都是通過數(shù)百到數(shù)千個數(shù)字的列表來描述單詞的特征。在它們的原始形式中,這些 “嵌入向量” 是相當(dāng)無信息的。例如,這里是 GPT-2 產(chǎn)生的三個特定詞的原始嵌入向量:

如果我們做一些事情,比如測量這些向量之間的距離,那么我們就可以發(fā)現(xiàn)像單詞的 “接近性” 這樣的東西。稍后我們將更詳細(xì)地討論我們可能認(rèn)為這種嵌入的 “認(rèn)知” 意義。但現(xiàn)在主要的一點(diǎn)是,我們有一種方法可以有效地將單詞變成 “神經(jīng)網(wǎng)絡(luò)友好” 的數(shù)字集合。但實(shí)際上,我們可以更進(jìn)一步,不僅僅是用數(shù)字的集合來描述單詞;我們還可以對單詞的序列,或者整個文本塊進(jìn)行描述。在 ChatGPT 中,它就是這樣處理事情的。它把目前得到的文本,生成一個嵌入矢量來表示它。然后,它的目標(biāo)是找到接下來可能出現(xiàn)的不同詞匯的概率。它將其答案表示為一個數(shù)字列表,該列表基本上給出了 50,000 個左右的可能詞匯的概率。(嚴(yán)格地說,ChatGPT 不處理單詞,而是處理 “符號” (token)—— 方便的語言單位,可能是整個單詞,也可能只是 “pre” 或 “ing” 或 “ized” 這樣的片段。使用符號使 ChatGPT 更容易處理罕見的、復(fù)合的和非英語的詞匯,有時,無論好壞,都可以發(fā)明新的詞匯。)
— 7 —ChatGPT 內(nèi)部好了,我們終于準(zhǔn)備好討論 ChatGPT 內(nèi)部的內(nèi)容了。是的,最終,它是一個巨大的神經(jīng)網(wǎng)絡(luò) —— 目前是所謂的 GPT-3 網(wǎng)絡(luò)的一個版本,有 1750 億個權(quán)重。在許多方面,這是一個非常像我們討論過的其他神經(jīng)網(wǎng)絡(luò)。但它是一個特別為處理語言問題而設(shè)置的神經(jīng)網(wǎng)絡(luò)。它最顯著的特征是一個叫做 “轉(zhuǎn)化器” 的神經(jīng)網(wǎng)絡(luò)架構(gòu)。在我們上面討論的第一個神經(jīng)網(wǎng)絡(luò)中,任何給定層的每個神經(jīng)元基本上都與前一層的每個神經(jīng)元相連(至少有一些權(quán)重)。但是,如果一個人在處理具有特殊的、已知的結(jié)構(gòu)的數(shù)據(jù)時,這種全連接的網(wǎng)絡(luò)(大概)是過剩的。因此,例如,在處理圖像的早期階段,典型的做法是使用所謂的卷積神經(jīng)網(wǎng)絡(luò)(“convnets”),其中的神經(jīng)元被有效地布置在一個類似于圖像中的像素的網(wǎng)格上 —— 并且只與網(wǎng)格上附近的神經(jīng)元相連。
變換器的想法是為構(gòu)成一段文本的標(biāo)記序列做一些至少有點(diǎn)類似的事情。但是,轉(zhuǎn)化器并不只是在序列中定義一個可以有連接的固定區(qū)域,而是引入了 “注意” 的概念 —— 以及對序列的某些部分比其他部分更 “注意” 的概念。也許有一天,僅僅啟動一個通用的神經(jīng)網(wǎng)絡(luò)并通過訓(xùn)練進(jìn)行所有的定制是有意義的。但至少到現(xiàn)在為止,將事情 “模塊化” 在實(shí)踐中似乎是至關(guān)重要的,就像變壓器那樣,可能也像我們的大腦那樣。好吧,那么 ChatGPT(或者說,它所基于的 GPT-3 網(wǎng)絡(luò))實(shí)際上是做什么的?回想一下,它的總體目標(biāo)是以 “合理” 的方式延續(xù)文本,基于它所看到的訓(xùn)練(包括從網(wǎng)絡(luò)上查看數(shù)十億頁的文本等),所以在任何時候,它都有一定數(shù)量的文本,它的目標(biāo)是為下一個要添加的標(biāo)記提出適當(dāng)?shù)倪x擇。
它的操作分為三個基本階段:首先,它獲取與迄今為止的文本相對應(yīng)的標(biāo)記序列,并找到代表這些標(biāo)記的嵌入(即一個數(shù)字陣列)。其次,它以 “標(biāo)準(zhǔn)的神經(jīng)網(wǎng)絡(luò)方式” 對這一嵌入進(jìn)行操作,數(shù)值 “通過” 網(wǎng)絡(luò)中的連續(xù)層,產(chǎn)生一個新的嵌入(即一個新的數(shù)字陣列)。然后,它從這個數(shù)組的最后一部分,生成一個大約 50,000 個值的數(shù)組,這些值變成了不同的可能的下一個標(biāo)記的概率。(而且,是的,恰好使用的標(biāo)記的數(shù)量與英語中的常用詞的數(shù)量相同,盡管只有大約 3000 個標(biāo)記是整個單詞,其余的是片段。)關(guān)鍵的一點(diǎn)是,這個管道的每一部分都是由一個神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)的,其權(quán)重是由網(wǎng)絡(luò)的端到端訓(xùn)練決定的。
換句話說,實(shí)際上,除了整體架構(gòu)之外,沒有任何東西是 “明確設(shè)計(jì)的”;所有東西都是從訓(xùn)練數(shù)據(jù)中 “學(xué)習(xí)” 的。然而,在架構(gòu)的設(shè)置方式上有很多細(xì)節(jié),反映了各種經(jīng)驗(yàn)和神經(jīng)網(wǎng)絡(luò)的傳說。而且,盡管這肯定是進(jìn)入了雜草叢中,但我認(rèn)為談?wù)撈渲械囊恍┘?xì)節(jié)是有用的,尤其是為了了解建立像 ChatGPT 這樣的東西所需要的東西。首先是嵌入模塊。下面是 GPT-2 的 Wolfram 語言示意圖:
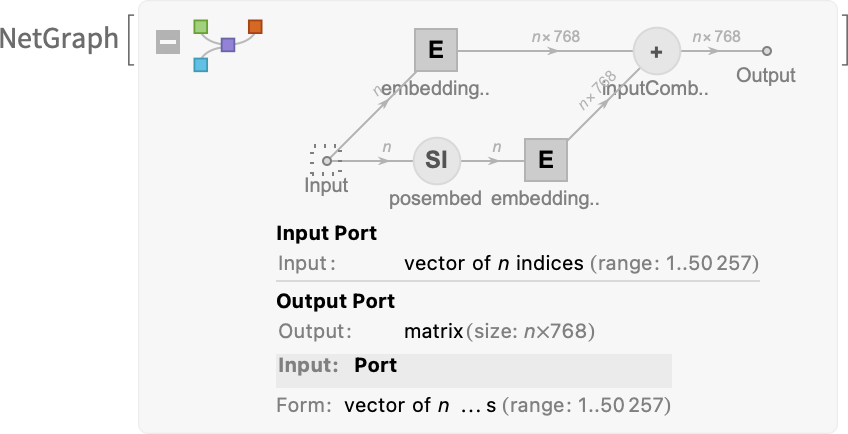
輸入是一個由 n 個標(biāo)記組成的向量(如上一節(jié)所述,由 1 到 50,000 的整數(shù)表示)。這些標(biāo)記中的每一個都被(通過單層神經(jīng)網(wǎng)絡(luò))轉(zhuǎn)換成一個嵌入向量(GPT-2 的長度為 768,ChatGPT 的 GPT-3 為 12,288)。同時,還有一個 “二級路徑”,它將標(biāo)記的(整數(shù))位置序列,并從這些整數(shù)中創(chuàng)建另一個嵌入向量。最后,來自令牌值和令牌位置的嵌入向量被加在一起 —— 產(chǎn)生嵌入模塊的最終嵌入向量序列。為什么只是把令牌值和令牌位置的嵌入向量加在一起?我不認(rèn)為這有什么特別的科學(xué)依據(jù)。
只是各種不同的東西都被嘗試過,而這是一個似乎有效的方法。這也是神經(jīng)網(wǎng)絡(luò)傳說的一部分,從某種意義上說,只要你的設(shè)置是 “大致正確的”,通常就可以通過做充分的訓(xùn)練來確定細(xì)節(jié),而不需要真正 “在工程層面上理解” 神經(jīng)網(wǎng)絡(luò)最終是如何配置它的。下面是嵌入模塊所做的工作,對字符串 “hello hello hello hello hello bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye 2”:

每個標(biāo)記的嵌入向量的元素都顯示在頁面下方,在整個頁面上,我們首先看到的是 “hello” 的嵌入,然后是 “bye” 的嵌入。上面的第二個數(shù)組是位置嵌入 —— 其看起來有點(diǎn)隨機(jī)的結(jié)構(gòu)只是 “碰巧學(xué)到的”(在這種情況下是 GPT-2)。好了,在嵌入模塊之后,是轉(zhuǎn)化器的 “主要事件”:一連串所謂的 “注意塊”(GPT-2 為 12 個,ChatGPT 的 GPT-3 為 96 個)。這一切都很復(fù)雜 —— 讓人想起典型的難以理解的大型工程系統(tǒng),或者,生物系統(tǒng)。但無論如何,這里是一個單一的 “注意塊” 的示意圖(對于 GPT-2):
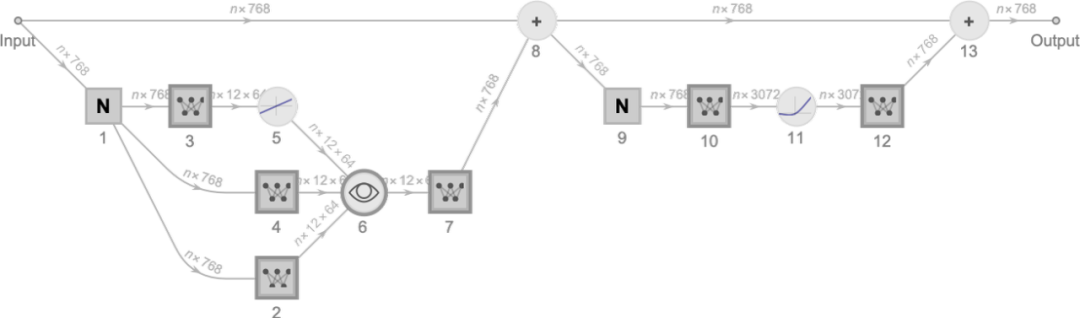
在每個這樣的注意力塊中,有一系列的 “注意力頭”(GPT-2 有 12 個,ChatGPT 的 GPT-3 有 96 個) —— 每一個都是獨(dú)立操作嵌入向量中的不同數(shù)值塊的。(是的,我們不知道為什么分割嵌入向量是個好主意,或者它的不同部分有什么 “意義”;這只是 “被發(fā)現(xiàn)可行” 的事情之一)。好吧,那么注意頭是做什么的?基本上,它們是一種在標(biāo)記序列中 “回顧” 的方式(即在迄今為止產(chǎn)生的文本中),并將過去的內(nèi)容 “打包” 成有助于尋找下一個標(biāo)記的形式。
在上面的第一節(jié)中,我們談到了使用 2-gram 概率來根據(jù)它們的直接前身來挑選單詞。變換器中的 “注意” 機(jī)制所做的是允許 “注意” 甚至更早的詞 —— 因此有可能捕捉到,比如說,動詞可以指代在句子中出現(xiàn)在它們之前的許多詞的名詞的方式。在更詳細(xì)的層面上,注意力頭所做的是以一定的權(quán)重重新組合與不同標(biāo)記相關(guān)的嵌入向量中的大塊。因此,例如,在第一個注意力區(qū)塊中的 12 個注意力頭(在 GPT-2 中)對上面的 “hello, bye” 字符串有如下(“l(fā)ook-back-all-the-way-beginning-the-sequence-of-tokens”)模式的 “重組權(quán)值”:
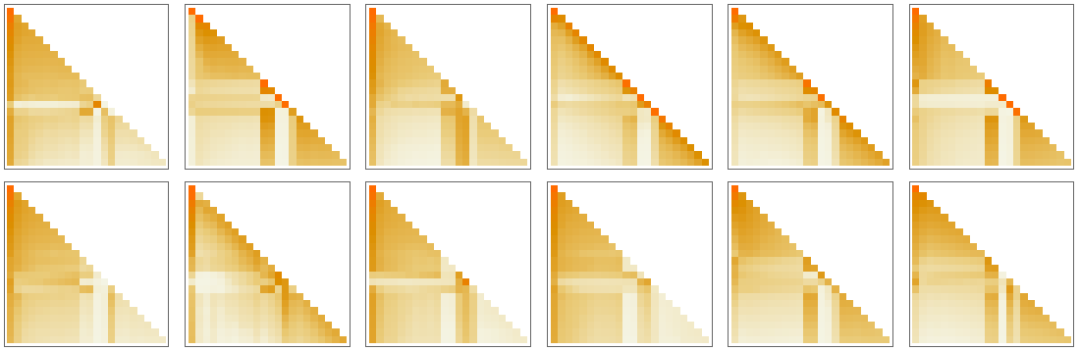
在經(jīng)過注意力頭的處理后,產(chǎn)生的 “重新加權(quán)的嵌入向量”(GPT-2 的長度為 768,ChatGPT 的 GPT-3 的長度為 12288)被傳遞到一個標(biāo)準(zhǔn)的 “全連接” 神經(jīng)網(wǎng)層。很難掌握這個層在做什么。但這里是它使用的 768×768 權(quán)重矩陣的圖(這里是 GPT-2):

采用 64×64 的移動平均數(shù),一些(隨機(jī)漫步式的)結(jié)構(gòu)開始出現(xiàn):

是什么決定了這種結(jié)構(gòu)?最終,它可能是人類語言特征的一些 “神經(jīng)網(wǎng)絡(luò)編碼”。但到現(xiàn)在為止,這些特征可能是什么還很不清楚。實(shí)際上,我們正在 “打開 ChatGPT 的大腦”(或至少是 GPT-2),并發(fā)現(xiàn),是的,里面很復(fù)雜,而且我們不了解它 —— 盡管最終它產(chǎn)生了可識別的人類語言。好吧,在經(jīng)歷了一個注意力區(qū)塊之后,我們得到了一個新的嵌入向量 —— 然后它又被連續(xù)地傳遞到其他的注意力區(qū)塊中(GPT-2 共有 12 個;GPT-3 有 96 個)。每個注意力區(qū)塊都有自己特定的 “注意力” 和 “完全連接” 權(quán)重模式。這里是 GPT-2 的 “你好,再見” 輸入的注意權(quán)重序列,用于第一個注意頭(attention head):
這里是全連接層的(移動平均)“矩陣”:

奇怪的是,盡管這些 “權(quán)重矩陣” 在不同的注意力塊中看起來很相似,但權(quán)重的大小分布可能有些不同(而且不總是高斯的):

那么,在經(jīng)歷了所有這些注意力區(qū)塊之后,轉(zhuǎn)化器的凈效果是什么?從本質(zhì)上講,它是將原始的符號序列的嵌入集合轉(zhuǎn)化為最終的集合。而 ChatGPT 的具體工作方式是在這個集合中提取最后一個嵌入,并對其進(jìn)行 “解碼”,以產(chǎn)生一個關(guān)于下一個標(biāo)記應(yīng)該是什么的概率列表。這就是 ChatGPT 的概要內(nèi)容。它可能看起來很復(fù)雜(尤其是因?yàn)樗性S多不可避免的、有點(diǎn)武斷的 “工程選擇”),但實(shí)際上,所涉及的最終元素非常簡單。因?yàn)樽罱K我們要處理的只是一個由 “人工神經(jīng)元” 組成的神經(jīng)網(wǎng)絡(luò),每個神經(jīng)元都在進(jìn)行簡單的操作,即接受一組數(shù)字輸入,然后將它們與某些權(quán)重相結(jié)合。ChatGPT 的原始輸入是一個數(shù)字?jǐn)?shù)組(到目前為止符號的嵌入向量),當(dāng) ChatGPT“運(yùn)行” 以產(chǎn)生一個新的符號時,所發(fā)生的只是這些數(shù)字 “通過” 神經(jīng)網(wǎng)的各層,每個神經(jīng)元 “做它的事”,并將結(jié)果傳遞給下一層的神經(jīng)元。沒有循環(huán)或 “回頭”。一切都只是通過網(wǎng)絡(luò) “前饋”。
這是一個與典型的計(jì)算系統(tǒng) —— 如圖靈機(jī) —— 非常不同的設(shè)置,在圖靈機(jī)中,結(jié)果是由相同的計(jì)算元素反復(fù) “再處理” 的。在這里,至少在生成一個特定的輸出符號時,每個計(jì)算元素(即神經(jīng)元)只被使用一次。但在某種意義上,即使在 ChatGPT 中,仍然有一個重復(fù)使用計(jì)算元素的 “外循環(huán)”。因?yàn)楫?dāng) ChatGPT 要生成一個新的標(biāo)記時,它總是 “讀取”(即作為輸入)它之前的整個標(biāo)記序列,包括 ChatGPT 自己之前 “寫” 的標(biāo)記。我們可以認(rèn)為這種設(shè)置意味著 ChatGPT —— 至少在其最外層 —— 涉及到一個 “反饋循環(huán)”,盡管在這個循環(huán)中,每一次迭代都明確地顯示為一個出現(xiàn)在其生成的文本中的標(biāo)記。但讓我們回到 ChatGPT 的核心:反復(fù)用于生成每個標(biāo)記的神經(jīng)網(wǎng)絡(luò)。
在某種程度上,它非常簡單:一整個相同的人工神經(jīng)元的集合。網(wǎng)絡(luò)的某些部分只是由(“完全連接”)的神經(jīng)元層組成,其中某一層的每個神經(jīng)元都與前一層的每個神經(jīng)元相連(有一定的權(quán)重)。但是,特別是它的變壓器結(jié)構(gòu),ChatGPT 有更多的結(jié)構(gòu)部分,其中只有不同層的特定神經(jīng)元被連接。(當(dāng)然,人們?nèi)匀豢梢哉f,“所有的神經(jīng)元都是連接的” —— 但有些神經(jīng)元的權(quán)重為零)。此外,ChatGPT 中的神經(jīng)網(wǎng)的某些方面并不是最自然地被認(rèn)為是由 “同質(zhì)” 層組成的。例如,正如上面的圖標(biāo)摘要所示,在一個注意力區(qū)塊中,有一些地方對傳入的數(shù)據(jù)進(jìn)行了 “多份拷貝”,然后每個拷貝經(jīng)過不同的 “處理路徑”,可能涉及不同數(shù)量的層,然后才重新組合。但是,雖然這可能是對正在發(fā)生的事情的一種方便的表述,但至少在原則上總是可以考慮 “密集地填入” 層,但只是讓一些權(quán)重為零。如果我們看一下 ChatGPT 的最長路徑,大約有 400 個(核心)層參與其中 —— 在某些方面不是一個巨大的數(shù)字。但是有數(shù)以百萬計(jì)的神經(jīng)元 —— 總共有 1750 億個連接,因此有 1750 億個權(quán)重。需要認(rèn)識到的一點(diǎn)是,每當(dāng) ChatGPT 生成一個新的令牌時,它都要進(jìn)行涉及這些權(quán)重中每一個的計(jì)算。
在實(shí)現(xiàn)上,這些計(jì)算可以 “按層” 組織成高度并行的陣列操作,可以方便地在 GPU 上完成。但是,對于產(chǎn)生的每一個標(biāo)記,仍然要進(jìn)行 1750 億次計(jì)算(最后還要多一點(diǎn)) —— 因此,是的,用 ChatGPT 生成一個長的文本需要一段時間,這并不令人驚訝。但最終,最了不起的是,所有這些操作 —— 它們各自都很簡單 —— 能夠以某種方式共同完成如此出色的 “類似人類” 的文本生成工作。必須再次強(qiáng)調(diào)的是,(至少到目前為止,我們知道)沒有任何 “最終的理論理由” 來解釋這樣的工作。事實(shí)上,正如我們將要討論的那樣,我認(rèn)為我們必須把這看作是一個潛在的令人驚訝的科學(xué)發(fā)現(xiàn):在像 ChatGPT 這樣的神經(jīng)網(wǎng)絡(luò)中,有可能捕捉到人類大腦在生成語言方面的本質(zhì)。
— 8 —ChatGPT 的訓(xùn)練好了,現(xiàn)在我們已經(jīng)給出了 ChatGPT 建立后的工作概要。但它是如何建立的呢?其神經(jīng)網(wǎng)絡(luò)中的 1750 億個權(quán)重是如何確定的?基本上,它們是非常大規(guī)模的訓(xùn)練的結(jié)果,基于一個巨大的文本語料庫 —— 網(wǎng)絡(luò)上的、書中的等等 —— 由人類寫的。正如我們所說的,即使考慮到所有的訓(xùn)練數(shù)據(jù),神經(jīng)網(wǎng)絡(luò)是否能夠成功地產(chǎn)生 “類似人類” 的文本,這一點(diǎn)也不明顯。
而且,再一次,似乎需要詳細(xì)的工程來實(shí)現(xiàn)這一目標(biāo)。但 ChatGPT 的最大驚喜和發(fā)現(xiàn)是,它是可能的。實(shí)際上,一個 “只有”1750 億個權(quán)重的神經(jīng)網(wǎng)絡(luò)可以對人類所寫的文本做出一個 “合理的模型”。在現(xiàn)代,有很多人類寫的文本是以數(shù)字形式存在的。公共網(wǎng)絡(luò)至少有幾十億人寫的網(wǎng)頁,總共可能有一萬億字的文本。如果包括非公開網(wǎng)頁,這些數(shù)字可能至少要大 100 倍。到目前為止,已經(jīng)有超過 500 萬本數(shù)字化書籍可供使用(在曾經(jīng)出版過的 1 億本左右的書籍中),又有 1000 億左右的文字。作為個人比較,我一生中發(fā)表的材料總字?jǐn)?shù)不到 300 萬字,在過去 30 年中,我寫了大約 1500 萬字的電子郵件,總共打了大約 5000 萬字,在過去幾年中,我在直播中說了 1000 多萬字。而且,是的,我將從所有這些中訓(xùn)練一個機(jī)器人)。但是,好吧,鑒于所有這些數(shù)據(jù),我們?nèi)绾螐闹杏?xùn)練出一個神經(jīng)網(wǎng)絡(luò)呢?基本過程與我們在上面的簡單例子中討論的非常相似。你提出一批例子,然后你調(diào)整網(wǎng)絡(luò)中的權(quán)重,使網(wǎng)絡(luò)在這些例子上的誤差(“損失”)最小。從錯誤中 “反向傳播” 的主要問題是,每次你這樣做,網(wǎng)絡(luò)中的每個權(quán)重通常至少會有微小的變化,而且有大量的權(quán)重需要處理。(實(shí)際的 “反向計(jì)算” 通常只比正向計(jì)算難一個小常數(shù))。
有了現(xiàn)代的 GPU 硬件,從成千上萬的例子中并行計(jì)算出結(jié)果是很簡單的。但是,當(dāng)涉及到實(shí)際更新神經(jīng)網(wǎng)絡(luò)中的權(quán)重時,目前的方法要求我們基本上是一批一批地做。(是的,這可能是實(shí)際的大腦 —— 其計(jì)算和記憶元素的結(jié)合 —— 目前至少有一個架構(gòu)上的優(yōu)勢)。即使在我們之前討論的看似簡單的學(xué)習(xí)數(shù)字函數(shù)的案例中,我們發(fā)現(xiàn)我們經(jīng)常不得不使用數(shù)百萬個例子來成功訓(xùn)練一個網(wǎng)絡(luò),至少從頭開始。那么,這意味著我們需要多少個例子來訓(xùn)練一個 “類人語言” 模型呢?似乎沒有任何基本的 “理論” 方法可以知道。但是在實(shí)踐中,ChatGPT 已經(jīng)成功地在幾千億字的文本上進(jìn)行了訓(xùn)練。
有些文本被多次輸入,有些只有一次。但不知何故,它從它看到的文本中 “得到了它需要的東西”。但是,考慮到需要學(xué)習(xí)的文本量,它應(yīng)該需要多大的網(wǎng)絡(luò)才能 “學(xué)好”?同樣,我們還沒有一個基本的理論方法來說明。最終 —— 我們將在下面進(jìn)一步討論 —— 人類語言大概有某種 “總的算法內(nèi)容”,以及人類通常用它說什么。但接下來的問題是,神經(jīng)網(wǎng)絡(luò)在實(shí)現(xiàn)基于該算法內(nèi)容的模型時將會有多大的效率。我們也不知道 —— 盡管 ChatGPT 的成功表明它的效率還算不錯。最后我們可以注意到,ChatGPT 使用了幾千億個權(quán)重 —— 與它所獲得的訓(xùn)練數(shù)據(jù)的總字?jǐn)?shù)(或令牌)相比,它所做的事情是相當(dāng)?shù)摹?/p>
在某些方面,也許令人驚訝的是(盡管在 ChatGPT 的小型類似物中也有經(jīng)驗(yàn)觀察),似乎工作良好的 “網(wǎng)絡(luò)規(guī)模” 與 “訓(xùn)練數(shù)據(jù)的規(guī)模” 如此相似。畢竟,這肯定不是說 “在 ChatGPT 內(nèi)” 所有來自網(wǎng)絡(luò)和書籍等的文本都被 “直接存儲” 了。因?yàn)樵?ChatGPT 里面的實(shí)際上是一堆數(shù)字 —— 精度略低于 10 位 —— 是對所有這些文本的總體結(jié)構(gòu)的某種分布式編碼。換句話說,我們可以問人類語言的 “有效信息含量” 是什么,以及通常用它說什么。這里有語言實(shí)例的原始語料庫。然后是 ChatGPT 的神經(jīng)網(wǎng)絡(luò)中的表述。這個表征很可能與 “算法上最小” 的表征相去甚遠(yuǎn)(我們將在下面討論)。但它是一個很容易被神經(jīng)網(wǎng)絡(luò)使用的表征。在這種表示法中,訓(xùn)練數(shù)據(jù)的 “壓縮” 程度似乎很低;平均而言,似乎只需要不到一個神經(jīng)網(wǎng)絡(luò)的權(quán)重就可以承載一個詞的訓(xùn)練數(shù)據(jù)的 “信息內(nèi)容”。當(dāng)我們運(yùn)行 ChatGPT 來生成文本時,我們基本上不得不使用每個權(quán)重一次。
因此,如果有 n 個權(quán)重,我們有 n 個計(jì)算步驟要做 —— 盡管在實(shí)踐中,許多步驟通常可以在 GPU 中并行完成。但是,如果我們需要大約 n 個字的訓(xùn)練數(shù)據(jù)來設(shè)置這些權(quán)重,那么從我們上面所說的,我們可以得出結(jié)論,我們需要大約 n2 個計(jì)算步驟來進(jìn)行網(wǎng)絡(luò)訓(xùn)練 —— 這就是為什么,用目前的方法,人們最終需要談?wù)摂?shù)十億美元的訓(xùn)練工作。
— 9 —基本訓(xùn)練之上
訓(xùn)練 ChatGPT 的大部分工作是向它 “展示” 大量來自網(wǎng)絡(luò)、書籍等的現(xiàn)有文本。但事實(shí)證明,還有一個明顯相當(dāng)重要的部分。一旦它完成了對所展示的原始語料庫的 “原始訓(xùn)練”,ChatGPT 內(nèi)的神經(jīng)網(wǎng)絡(luò)就可以開始生成自己的文本,繼續(xù)提示等。但是,雖然這樣做的結(jié)果往往看起來很合理,但它們往往 —— 特別是對于較長的文本 —— 以往往相當(dāng)非人類的方式 “游離”。
這不是人們可以輕易發(fā)現(xiàn)的,比如說,通過對文本做傳統(tǒng)的統(tǒng)計(jì)。但這是實(shí)際閱讀文本的人很容易注意到的東西。構(gòu)建 ChatGPT 的一個關(guān)鍵想法是,在 “被動地閱讀” 網(wǎng)絡(luò)等事物之后,還有一個步驟:讓實(shí)際的人類主動與 ChatGPT 互動,看看它產(chǎn)生了什么,并在實(shí)際上給它反饋 “如何成為一個好的聊天機(jī)器人”。但神經(jīng)網(wǎng)絡(luò)如何使用這種反饋呢?第一步只是讓人類對神經(jīng)網(wǎng)絡(luò)的結(jié)果進(jìn)行評價(jià)。但隨后又建立了另一個神經(jīng)網(wǎng)絡(luò)模型,試圖預(yù)測這些評分。但現(xiàn)在這個預(yù)測模型可以在原始網(wǎng)絡(luò)上運(yùn)行 —— 基本上就像一個損失函數(shù),實(shí)際上是讓該網(wǎng)絡(luò)通過人類的反饋來 “調(diào)高”。而實(shí)踐中的結(jié)果似乎對系統(tǒng)成功產(chǎn)生 “類似人類” 的輸出有很大影響。
總的來說,有趣的是,“最初訓(xùn)練的” 網(wǎng)絡(luò)似乎只需要很少的 “戳” 就能讓它向特定的方向有用地發(fā)展。人們可能會認(rèn)為,要讓網(wǎng)絡(luò)表現(xiàn)得像 “學(xué)到了新東西”,就必須運(yùn)行訓(xùn)練算法,調(diào)整權(quán)重,等等。但事實(shí)并非如此。相反,基本上只需要告訴 ChatGPT 一些東西,作為你所給的提示的一部分,然后它就可以在生成文本時成功地利用你告訴它的東西。我認(rèn)為,這一點(diǎn)再次成為理解 ChatGPT “真正在做什么” 以及它與人類語言和思維結(jié)構(gòu)的關(guān)系的一個重要線索。這當(dāng)然有一些類似于人類的東西:至少在它接受了所有的預(yù)訓(xùn)練之后,你可以告訴它一些東西,而它可以 “記住它” —— 至少 “足夠長的時間” 來使用它生成一段文本。
那么,在這樣的情況下發(fā)生了什么?可能是 “你可能告訴它的一切都已經(jīng)在那里了” —— 你只是把它引向正確的地方。但這似乎并不靠譜。相反,似乎更有可能的是,是的,這些元素已經(jīng)在那里了,但具體細(xì)節(jié)是由 “這些元素之間的軌跡” 這樣的東西來定義的,這就是你告訴它的東西。事實(shí)上,就像人類一樣,如果你告訴它一些奇怪的、出乎意料的、完全不適合它所知道的框架的東西,它似乎并不能成功地 “整合” 這個。只有當(dāng)它基本上以一種相當(dāng)簡單的方式騎在它已經(jīng)擁有的框架之上時,它才能 “整合” 它。還值得再次指出的是,對于神經(jīng)網(wǎng)絡(luò)能夠 “接收” 的東西,不可避免地存在 “算法限制”。告訴它 “淺層” 的規(guī)則,如 “這個到那個”,神經(jīng)網(wǎng)絡(luò)很可能能夠很好地表示和再現(xiàn)這些規(guī)則 —— 事實(shí)上,它從語言中 “已經(jīng)知道” 的東西會給它一個直接的模式來遵循。但是,如果試圖給它制定一個實(shí)際的 “深度” 計(jì)算規(guī)則,涉及許多潛在的不可簡化的計(jì)算步驟,它就無法工作了。(記住,在每一步,它總是在其網(wǎng)絡(luò)中 “向前輸送數(shù)據(jù)”;除了生成新的標(biāo)記外,從不循環(huán)。)當(dāng)然,網(wǎng)絡(luò)可以學(xué)習(xí)特定的 “不可簡化的” 計(jì)算的答案。但只要有組合數(shù)的可能性,這種 “查表式” 的方法就不會奏效。因此,是的,就像人類一樣,現(xiàn)在是時候讓神經(jīng)網(wǎng)絡(luò) “伸出手來”,使用實(shí)際的計(jì)算工具了。(是的,Wolfram|Alpha 和 Wolfram 語言是唯一合適的,因?yàn)樗鼈兪菫榱?“談?wù)撌澜缟系氖挛铩?而建立的,就像語言模型的神經(jīng)網(wǎng)絡(luò)一樣)。
— 10 —是什么真正讓 ChatGPT 工作?
人類的語言 —— 以及產(chǎn)生語言的思維過程 —— 似乎一直代表著一種復(fù)雜性的頂峰。事實(shí)上,人類的大腦 —— “僅” 有 1000 億個左右的神經(jīng)元網(wǎng)絡(luò)(也許還有 100 萬億個連接) —— 能夠負(fù)責(zé)這項(xiàng)工作,似乎有些了不起。也許,人們可能會想象,大腦除了神經(jīng)元網(wǎng)絡(luò)之外還有其他東西,就像一些未被發(fā)現(xiàn)的物理學(xué)新層。但現(xiàn)在通過 ChatGPT,我們得到了一個重要的新信息:我們知道,一個純粹的人工神經(jīng)網(wǎng)絡(luò),其連接數(shù)與大腦的神經(jīng)元一樣多,能夠很好地生成人類語言,令人驚訝。
而且,是的,這仍然是一個龐大而復(fù)雜的系統(tǒng) —— 其神經(jīng)網(wǎng)絡(luò)的權(quán)重與目前世界上的文字一樣多。但在某種程度上,似乎仍然很難相信,語言的所有豐富性和它可以談?wù)摰臇|西可以被封裝在這樣一個有限的系統(tǒng)中。這其中的部分原因無疑是反映了一個無處不在的現(xiàn)象(這在第 30 條規(guī)則的例子中首次變得很明顯),即計(jì)算過程實(shí)際上可以大大放大系統(tǒng)的表面復(fù)雜性,即使其基本規(guī)則很簡單。但是,實(shí)際上,正如我們上面所討論的,ChatGPT 中所使用的那種神經(jīng)網(wǎng)絡(luò)往往是專門用來限制這種現(xiàn)象的影響以及與之相關(guān)的計(jì)算的不可重復(fù)性的,以便使其訓(xùn)練更容易進(jìn)行。那么,像 ChatGPT 這樣的東西是如何在語言方面走得如此之遠(yuǎn)的呢?
我想,基本的答案是,語言在根本層面上比它看起來要簡單得多。這意味著 ChatGPT —— 即使它的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)最終是簡單的 —— 能夠成功地 “捕捉” 人類語言的本質(zhì)和背后的思維。此外,在其訓(xùn)練中,ChatGPT 以某種方式 “隱含地發(fā)現(xiàn)” 了語言(和思維)中的任何規(guī)律性,使其成為可能。我認(rèn)為,ChatGPT 的成功為我們提供了一個基本的和重要的科學(xué)證據(jù):它表明我們可以期待有重大的新 “語言法則” —— 以及有效的 “思維法則” —— 在那里被發(fā)現(xiàn)。在 ChatGPT 中,作為一個神經(jīng)網(wǎng)絡(luò),這些規(guī)律充其量是隱含的。但是,如果我們能以某種方式使這些定律明確化,就有可能以更直接、更有效和更透明的方式完成 ChatGPT 所做的各種事情。
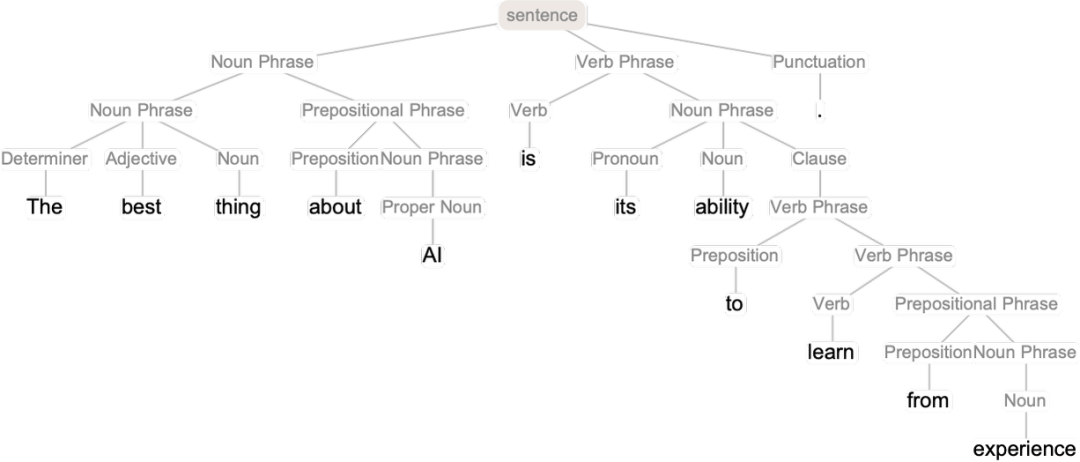
但是,好吧,那么這些法律可能是什么樣的?最終,它們必須給我們提供某種語言 —— 以及我們用它說的東西 —— 如何組合的處方。稍后我們將討論 “觀察 ChatGPT” 如何能夠給我們一些這方面的提示,以及我們從構(gòu)建計(jì)算語言中了解到的情況如何提示我們前進(jìn)的道路。但首先讓我們來討論兩個長期以來為人所知的相當(dāng)于 “語言法則” 的例子 —— 以及它們與 ChatGPT 的運(yùn)作有何關(guān)系。第一個是語言的語法。語言并不只是一個隨機(jī)的詞語組合。相反,對于不同種類的單詞如何放在一起,有(相當(dāng))明確的語法規(guī)則:例如,在英語中,名詞前面可以有形容詞,后面可以有動詞,但通常兩個名詞不能緊挨著。這樣的語法結(jié)構(gòu)可以(至少是近似地)被一套規(guī)則所捕獲,這些規(guī)則定義了如何將相當(dāng)于 “解析樹” 的東西放在一起:
ChatGPT 對這種規(guī)則沒有任何明確的 “知識”。但在訓(xùn)練中,它隱含地 “發(fā)現(xiàn)” 了這些規(guī)則,然后似乎很擅長遵循這些規(guī)則。那么,它是如何工作的呢?在一個 “大畫面” 的層面上,這并不清楚。但是為了得到一些啟示,看看一個更簡單的例子也許會有啟發(fā)。考慮一種由()和()序列組成的 “語言”,其語法規(guī)定括號應(yīng)該總是平衡的,如解析樹所表示的那樣:
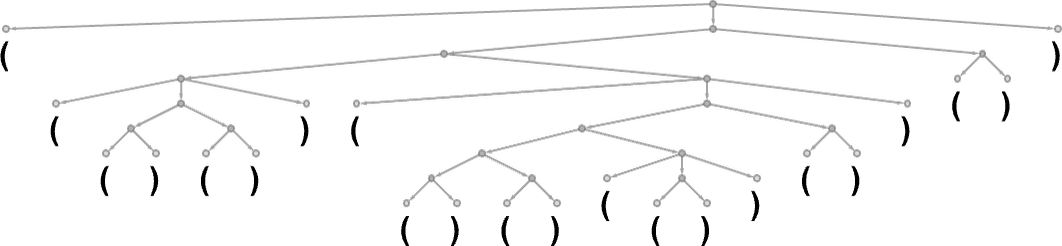
我們能否訓(xùn)練一個神經(jīng)網(wǎng)絡(luò)來產(chǎn)生 “語法上正確的” 小括號序列?在神經(jīng)網(wǎng)絡(luò)中處理序列有多種方法,但讓我們使用變換器網(wǎng)絡(luò),就像 ChatGPT 那樣。給定一個簡單的變換器網(wǎng)絡(luò),我們可以開始給它提供語法正確的小括號序列作為訓(xùn)練實(shí)例。一個微妙之處(實(shí)際上也出現(xiàn)在 ChatGPT 的人類語言生成中)是,除了我們的 “內(nèi)容標(biāo)記”(這里是 “(” 和 “)”),我們還必須包括一個 “結(jié)束” 標(biāo)記,它的生成表明輸出不應(yīng)該再繼續(xù)下去(即對于 ChatGPT 來說,我們已經(jīng)到達(dá)了 “故事的終點(diǎn)”)。
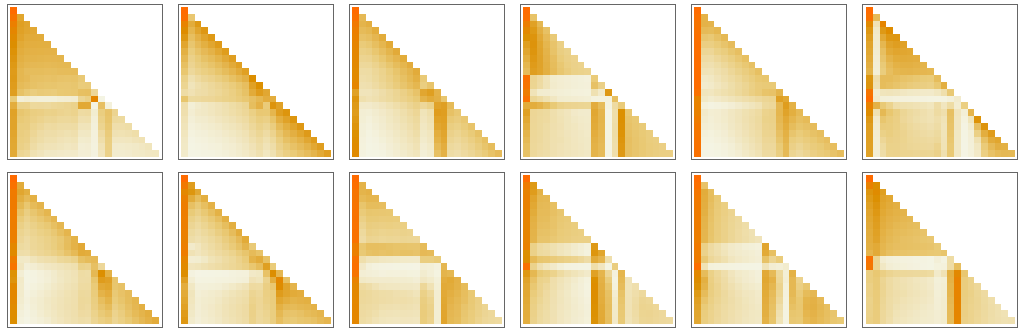
如果我們只用一個有 8 個頭的注意塊和長度為 128 的特征向量來設(shè)置一個轉(zhuǎn)換網(wǎng)(ChatGPT 也使用長度為 128 的特征向量,但有 96 個注意塊,每個注意塊有 96 個頭),那么似乎不可能讓它學(xué)會很多小括號語言。但是,如果有 2 個注意力頭,學(xué)習(xí)過程似乎會收斂 —— 至少在給出 1000 萬個左右的例子之后(而且,正如轉(zhuǎn)化器網(wǎng)絡(luò)所常見的那樣,顯示更多的例子似乎會降低其性能)。因此,對于這個網(wǎng)絡(luò),我們可以做 ChatGPT 的類似工作,并詢問下一個標(biāo)記應(yīng)該是什么的概率 —— 在一個括號序列中:
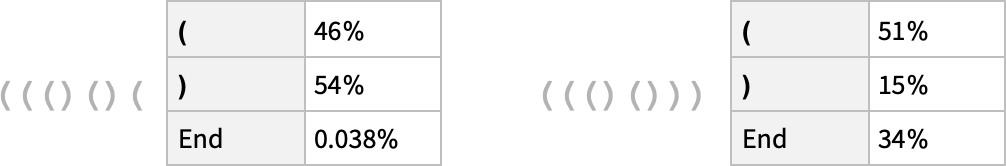
在第一種情況下,網(wǎng)絡(luò) “非常確定” 序列不能在這里結(jié)束 —— 這很好,因?yàn)槿绻Y(jié)束了,小括號就會留下不平衡。然而,在第二種情況下,它 “正確地認(rèn)識到” 序列可以在這里結(jié)束,盡管它也 “指出” 有可能 “重新開始”,放下一個 “(”,估計(jì)后面還有一個 “)”。但是,哎呀,即使它有 40 萬個左右經(jīng)過艱苦訓(xùn)練的權(quán)重,它也說有 15% 的概率將 “)” 作為下一個標(biāo)記 —— 這是不對的,因?yàn)檫@必然會導(dǎo)致一個不平衡的括號。如果我們要求網(wǎng)絡(luò)為逐漸變長的()序列提供最高概率的完成度,我們會得到以下結(jié)果:
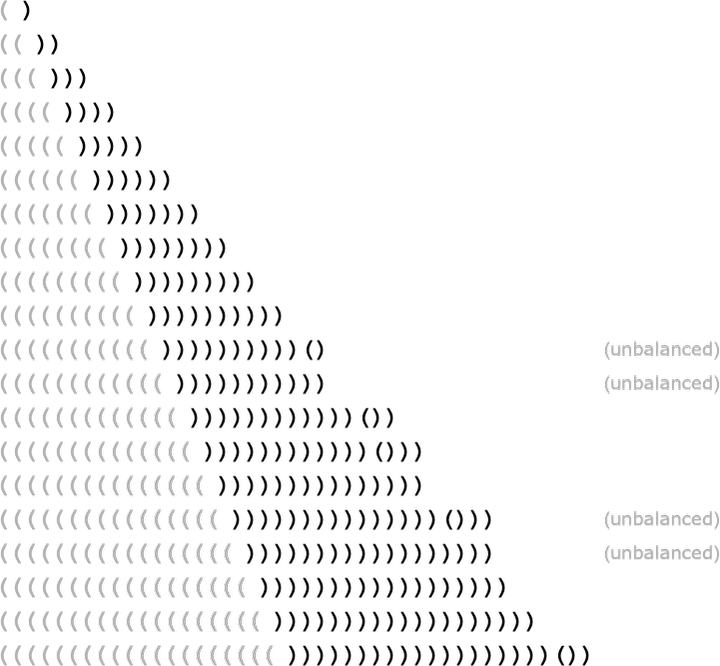
是的,在一定長度內(nèi),網(wǎng)絡(luò)做得很好。但隨后它就開始失敗了。這是在神經(jīng)網(wǎng)絡(luò)(或一般的機(jī)器學(xué)習(xí))的這種 “精確” 情況下看到的非常典型的事情。人類 “一眼就能解決” 的情況,神經(jīng)網(wǎng)絡(luò)也能解決。但是需要做一些 “更多的算法”(例如明確地計(jì)算括號是否封閉)的情況,神經(jīng)網(wǎng)絡(luò)往往在某種程度上是 “計(jì)算上太淺”,無法可靠地做到。(順便說一句,即使是目前完整的 ChatGPT 也很難正確匹配長序列中的括號)。那么,這對像 ChatGPT 和像英語這樣的語言的語法意味著什么呢?
小括號語言是 “樸素的” —— 而且更像是一個 “算法的故事”。但在英語中,能夠在局部選詞和其他提示的基礎(chǔ)上 “猜測” 什么是符合語法的,則要現(xiàn)實(shí)得多。而且,是的,神經(jīng)網(wǎng)絡(luò)在這方面要好得多 —— 盡管它可能會錯過一些 “形式上正確” 的情況,而人類也可能錯過。但主要的一點(diǎn)是,語言有一個整體的句法結(jié)構(gòu)這一事實(shí) —— 以及它所暗示的所有規(guī)律性 —— 在某種意義上限制了神經(jīng)網(wǎng)絡(luò)要學(xué)習(xí)的 “程度”。一個關(guān)鍵的 “類似自然科學(xué)” 的觀察是,像 ChatGPT 中的神經(jīng)網(wǎng)絡(luò)的轉(zhuǎn)化器架構(gòu)似乎能夠成功地學(xué)習(xí)所有人類語言中似乎都存在(至少在某種程度上是近似的)的那種嵌套樹狀的句法結(jié)構(gòu)。句法提供了對語言的一種約束。但顯然還有更多。像 “好奇的電子吃魚的藍(lán)色理論” 這樣的句子在語法上是正確的,但并不是人們通常期望說的東西,而且如果 ChatGPT 生成它,也不會被認(rèn)為是成功的 —— 因?yàn)椋牛云渲袉卧~的正常含義,它基本上沒有意義。但是,是否有一個一般的方法來判斷一個句子是否有意義?這方面沒有傳統(tǒng)的整體理論。但是,我們可以認(rèn)為 ChatGPT 在接受了來自網(wǎng)絡(luò)的數(shù)十億(可能是有意義的)句子的訓(xùn)練之后,已經(jīng)隱含地 “發(fā)展了一套理論”。
這個理論可能是什么樣的呢?好吧,有一個小小的角落,基本上兩千年來一直為人所知,那就是邏輯。當(dāng)然,在亞里士多德發(fā)現(xiàn)的 Syllogistic 形式中,邏輯基本上是一種說法,即遵循某些模式的句子是合理的,而其他的則不是。因此,例如,說 “所有的 X 都是 Y,這不是 Y,所以它不是 X” 是合理的(正如 “所有的魚都是藍(lán)色的,這不是藍(lán)色,所以它不是魚”)。就像人們可以有點(diǎn)異想天開地想象亞里士多德通過(“機(jī)器學(xué)習(xí)式”)大量的修辭學(xué)例子來發(fā)現(xiàn)對偶邏輯一樣,人們也可以想象在 ChatGPT 的訓(xùn)練中,它將能夠通過查看網(wǎng)絡(luò)上的大量文本等來 “發(fā)現(xiàn)對偶邏輯”。(是的,雖然我們可以期待 ChatGPT 產(chǎn)生包含 “正確推論” 的文本,比如基于對偶邏輯,但當(dāng)它涉及到更復(fù)雜的形式邏輯時,情況就完全不同了 —— 我認(rèn)為我們可以期待它在這里失敗,原因與它在小括號匹配中失敗的原因相同)。
但除了邏輯這個狹隘的例子之外,對于如何系統(tǒng)地構(gòu)建(或識別)甚至是合理的有意義的文本,又能說些什么呢?是的,有一些東西,如《瘋狂的自由》,使用非常具體的 “短語模板”。但不知何故,ChatGPT 隱含著一種更普遍的方法。也許除了 “當(dāng)你有 1750 億個神經(jīng)網(wǎng)絡(luò)權(quán)重時,它就會以某種方式發(fā)生” 之外,對如何做到這一點(diǎn)沒有什么可說的。但我強(qiáng)烈懷疑有一個更簡單、更有力的故事。
— 11 —意義空間和語義運(yùn)動法則我們在上面討論過,在 ChatGPT 中,任何一段文本都有效地由一個數(shù)字陣列來表示,我們可以將其視為某種 “語言特征空間” 中的一個點(diǎn)的坐標(biāo)。因此,當(dāng) ChatGPT 繼續(xù)一個文本時,這相當(dāng)于在語言特征空間中追蹤一個軌跡。但現(xiàn)在我們可以問,是什么讓這個軌跡對應(yīng)于我們認(rèn)為有意義的文本。也許會有某種 “語義運(yùn)動法則” 來定義 —— 或者至少是約束 —— 語言特征空間中的點(diǎn)如何移動,同時保留 “有意義”?那么,這個語言學(xué)特征空間是什么樣子的呢?下面是一個例子,說明如果我們把這樣一個特征空間投射到二維空間,單個詞(這里是指普通名詞)是如何布局的:

我們在上面看到的另一個例子是基于代表植物和動物的詞。但這兩種情況下的重點(diǎn)是,“語義相似的詞” 被放在附近。作為另一個例子,這里是對應(yīng)于不同語音部分的詞是如何布置的:
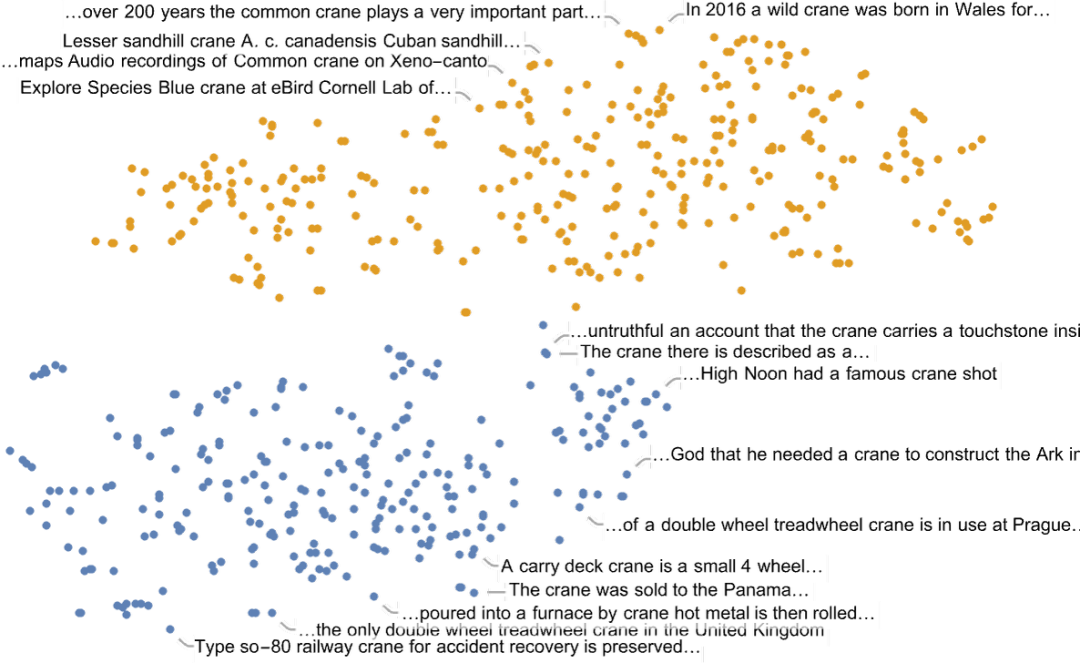
當(dāng)然,一個給定的詞一般來說并不只有 “一個意思”(或一定只對應(yīng)一個語篇)。通過觀察包含一個詞的句子在特征空間中的布局,我們通常可以 “區(qū)分” 出不同的含義 —— 就像這里的例子 “起重機(jī)”(crane, “鳥” 或 “機(jī)器”?):
好的,所以我們至少可以認(rèn)為這個特征空間是把 “意義相近的詞” 放在這個空間里的,這是合理的。但是,在這個空間里,我們可以確定什么樣的額外結(jié)構(gòu)?例如,是否存在某種 “平行運(yùn)輸” 的概念,以反映空間中的 “平坦性”?掌握這個問題的一個方法是看一下類比:
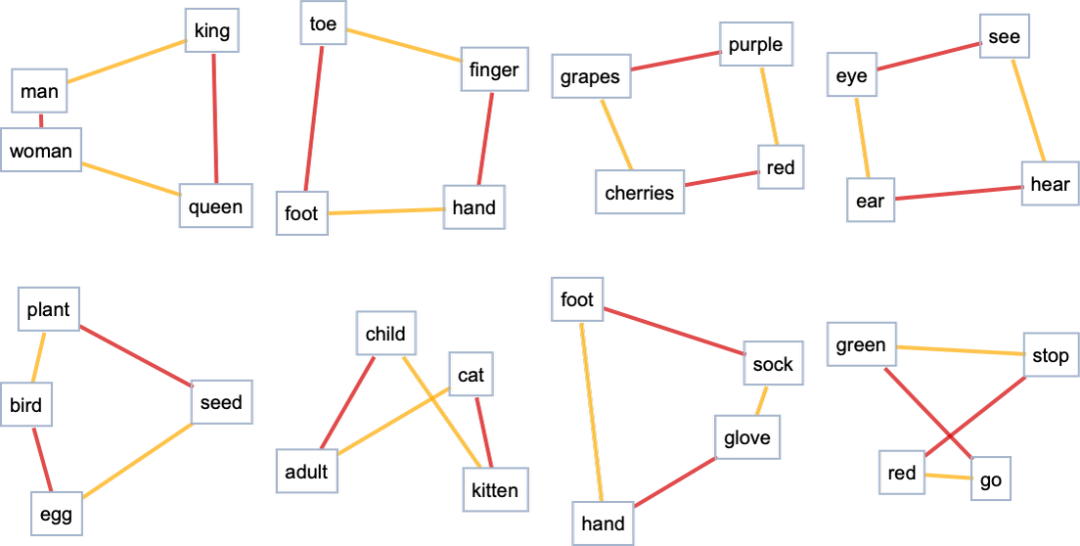
而且,是的,即使當(dāng)我們投射到二維時,往往至少有一個 “平坦性的暗示”,盡管它肯定不是普遍可見的。那么,軌跡呢?我們可以看看 ChatGPT 的提示在特征空間中的軌跡 —— 然后我們可以看看 ChatGPT 是如何延續(xù)這個軌跡的:

這里當(dāng)然沒有 “幾何學(xué)上明顯的” 運(yùn)動規(guī)律。這一點(diǎn)也不令人驚訝;我們完全可以預(yù)料到這是一個相當(dāng)復(fù)雜的故事。而且,舉例來說,即使有一個 “語義上的運(yùn)動定律” 可以找到,它最自然地以什么樣的嵌入(或者,實(shí)際上,什么樣的 “變量”)來表述,也遠(yuǎn)非明顯。在上圖中,我們展示了 “軌跡” 中的幾個步驟 —— 在每個步驟中,我們挑選 ChatGPT 認(rèn)為最可能的詞(“零溫度” 情況)。但我們也可以問,在某一點(diǎn)上,哪些詞可以以什么概率 “接下來”:
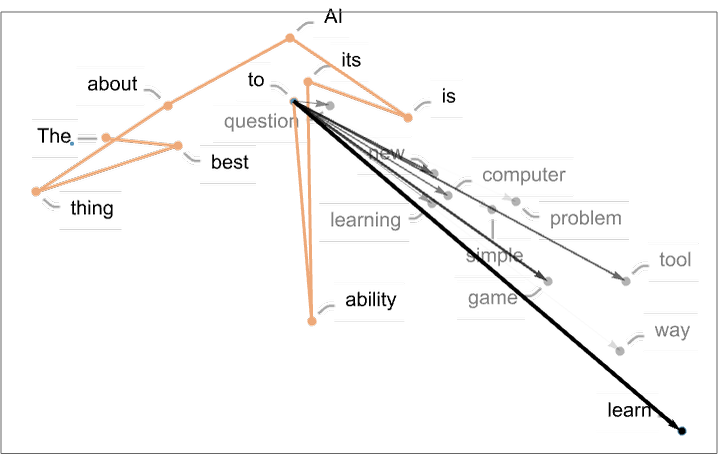
在這種情況下,我們看到的是有一個高概率詞的 “扇形”,似乎在特征空間中或多或少有一個明確的方向。如果我們再往前走會怎么樣呢?下面是我們沿著軌跡 “移動” 時出現(xiàn)的連續(xù)的 “扇形”:
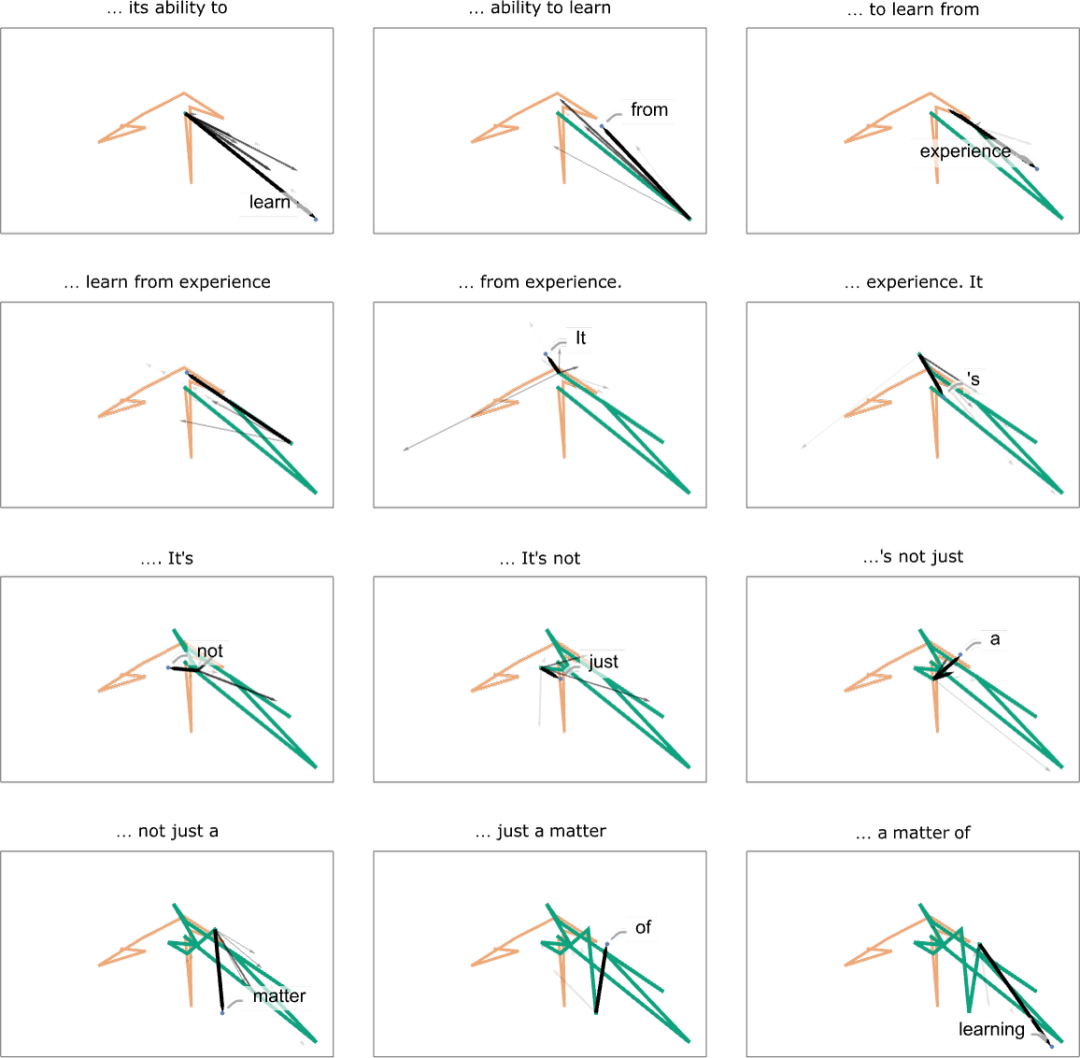
這是一個三維表示,總共走了 40 步:
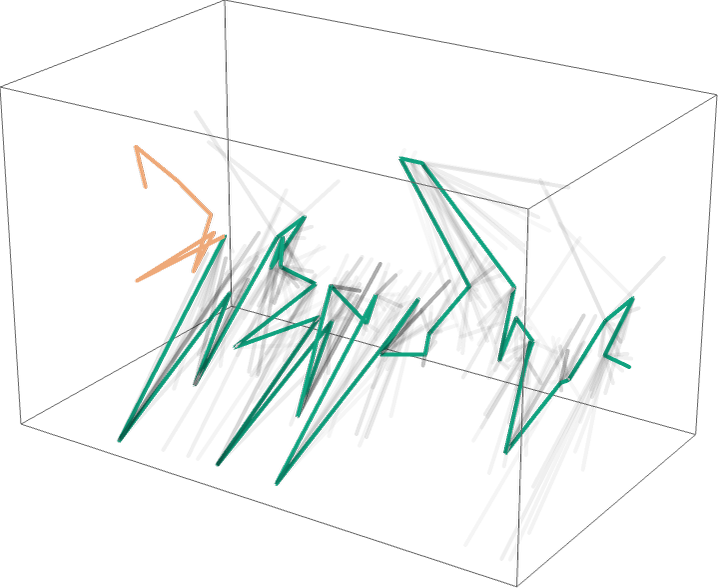
而且,是的,這似乎是一團(tuán)糟 —— 并沒有做任何事情來特別鼓勵這樣的想法,即我們可以期望通過經(jīng)驗(yàn)性地研究 “ChatGPT 在里面做什么” 來確定 “類似數(shù)學(xué)物理學(xué)的”“運(yùn)動語義法則”。但也許我們只是看了 “錯誤的變量”(或錯誤的坐標(biāo)系),只要我們看了正確的變量,我們就會立即看到 ChatGPT 正在做一些 “數(shù)學(xué)·物理學(xué)的簡單” 的事情,比如遵循測地線。但是到目前為止,我們還沒有準(zhǔn)備好從它的 “內(nèi)部行為” 中 “實(shí)證解碼”ChatGPT“發(fā)現(xiàn)” 人類語言是如何 “拼湊” 的。
— 12 —語義語法和計(jì)算語言的力量
產(chǎn)生 “有意義的人類語言” 需要什么?在過去,我們可能會認(rèn)為這不可能是一個人的大腦。但現(xiàn)在我們知道,ChatGPT 的神經(jīng)網(wǎng)絡(luò)可以很好地完成這一任務(wù)。不過,也許這已經(jīng)是我們能走的最遠(yuǎn)的路了,沒有什么比這更簡單 —— 或者更容易被人類理解 —— 的東西會起作用。但我強(qiáng)烈懷疑的是,ChatGPT 的成功隱含地揭示了一個重要的 “科學(xué)” 事實(shí):有意義的人類語言的結(jié)構(gòu)和簡單性實(shí)際上比我們所知道的要多得多,而且最終甚至可能有相當(dāng)簡單的規(guī)則來描述這種語言如何被組合起來。正如我們上面提到的,句法語法給出了人類語言中對應(yīng)于不同語篇的詞語如何組合的規(guī)則。
但是為了處理意義,我們需要更進(jìn)一步。而如何做到這一點(diǎn)的一個版本是,不僅要考慮語言的句法語法,還要考慮語義語法。為了語法的目的,我們確定名詞和動詞等事物。但為了語義學(xué)的目的,我們需要 “更精細(xì)的等級”。因此,例如,我們可以確定 “移動” 的概念,以及 “保持獨(dú)立于位置的身份” 的 “物體” 的概念。這些 “語義概念” 中的每一個都有無盡的具體例子。但是,為了我們的語義語法的目的,我們將只是有某種一般性的規(guī)則,基本上說 “物體” 可以 “移動”。關(guān)于這一切如何運(yùn)作,有很多東西可以說(其中一些我以前說過)。但我在這里只想說幾句,指出一些潛在的發(fā)展道路。
值得一提的是,即使一個句子根據(jù)語義語法是完全可以的,也不意味著它在實(shí)踐中已經(jīng)實(shí)現(xiàn)(甚至可以實(shí)現(xiàn))。“大象去了月球” 無疑會 “通過” 我們的語義語法,但是它肯定沒有在我們的實(shí)際世界中實(shí)現(xiàn)(至少還沒有) —— 盡管對于一個虛構(gòu)的世界來說,這絕對是公平的游戲。當(dāng)我們開始談?wù)?“語義語法” 時,我們很快就會問:“它的下面是什么?” 它假設(shè)的是什么 “世界模型”?句法語法實(shí)際上只是關(guān)于從詞語中構(gòu)建語言的問題。但是,語義學(xué)語法必然涉及某種 “世界模型” —— 作為 “骨架” 的東西,由實(shí)際詞語構(gòu)成的語言可以在上面分層。直到最近,我們可能會想象,(人類)語言將是描述我們 “世界模型” 的唯一一般方式。早在幾個世紀(jì)前,就已經(jīng)開始有了對特定種類事物的形式化,特別是以數(shù)學(xué)為基礎(chǔ)。但現(xiàn)在有一種更普遍的形式化方法:計(jì)算語言。是的,這是我四十多年來的一個大項(xiàng)目(現(xiàn)在體現(xiàn)在沃爾弗拉姆語言中):開發(fā)一個精確的符號表示,可以盡可能廣泛地談?wù)撌澜缟系氖挛铮约拔覀冴P(guān)心的抽象事物。因此,例如,我們有城市、分子、圖像和神經(jīng)網(wǎng)絡(luò)的符號表示,而且我們有關(guān)于如何計(jì)算這些事物的內(nèi)在知識。而且,經(jīng)過幾十年的工作,我們已經(jīng)用這種方式覆蓋了很多領(lǐng)域。但是在過去,我們并沒有特別處理 “日常話語”。
在 “我買了兩磅蘋果” 中,我們可以輕易地表示(并對其進(jìn)行營養(yǎng)和其他計(jì)算)“兩磅蘋果”。但是我們(還沒有)對 “我買了” 有一個符號表示。這一切都與語義語法的想法有關(guān) —— 目標(biāo)是為概念提供一個通用的符號 “構(gòu)造套件”,這將為我們提供什么可以與什么結(jié)合的規(guī)則,從而為我們可能轉(zhuǎn)化為人類語言的 “流程” 提供規(guī)則。但是,假設(shè)我們有了這種 “符號話語語言”。我們會用它做什么呢?我們可以開始做一些事情,比如生成 “本地有意義的文本”。但最終我們可能想要更多 “全局意義” 的結(jié)果 —— 這意味著 “計(jì)算” 更多關(guān)于世界上實(shí)際存在或發(fā)生的事情(或許是在某個一致的虛構(gòu)世界)。
現(xiàn)在在 Wolfram 語言中,我們有大量的關(guān)于許多種類的事物的內(nèi)置計(jì)算知識。但對于一個完整的符號話語語言,我們必須建立關(guān)于世界上一般事物的額外 “計(jì)算”:如果一個物體從 A 地移動到 B 地,又從 B 地移動到 C 地,那么它就從 A 地移動到 C 地,等等。給定一個符號化的話語語言,我們可以用它來做 “獨(dú)立的陳述”。但我們也可以用它來問關(guān)于世界的問題,“Wolfram|Alpha 風(fēng)格”。或者我們可以用它來陳述我們 “想讓它變成這樣” 的事情,大概是用一些外部的執(zhí)行機(jī)制。或者我們可以用它來做斷言 —— 也許是關(guān)于真實(shí)的世界,也許是關(guān)于我們正在考慮的某個特定世界,不管是虛構(gòu)的還是其他的。
人類語言從根本上說是不精確的,這不僅僅是因?yàn)樗鼪]有 “拴” 在一個具體的計(jì)算實(shí)現(xiàn)上,而且它的意義基本上只是由其使用者之間的 “社會契約” 來定義。但是計(jì)算語言,就其性質(zhì)而言,具有某種基本的精確性 —— 因?yàn)樽罱K它所指定的東西總是可以 “毫不含糊地在計(jì)算機(jī)上執(zhí)行”。人類語言通常可以擺脫某種模糊性。(當(dāng)我們說 “行星” 時,它是否包括系外行星,等等。)但是在計(jì)算語言中,我們必須對我們所做的所有區(qū)分精確而清楚。在計(jì)算語言中,利用普通人類語言來編造名字往往很方便。但它們在計(jì)算語言中的含義必然是精確的,而且可能涵蓋也可能不涵蓋典型人類語言用法中的某些特定內(nèi)涵。
我們應(yīng)該如何找出適合一般符號話語語言的基本 “本體”?嗯,這并不容易。這也許就是為什么自亞里士多德兩千多年前的原始開始以來,在這些方面做得很少。但是,今天我們對如何以計(jì)算方式思考世界了解得如此之多,這確實(shí)有幫助(而且,從我們的物理學(xué)項(xiàng)目和 ragiad 的想法中得到 “基本形而上學(xué)” 也無傷大雅)。但是這一切在 ChatGPT 的背景下意味著什么?從它的訓(xùn)練來看,ChatGPT 已經(jīng)有效地 “拼湊” 了一定數(shù)量的相當(dāng)于語義語法的東西(相當(dāng)令人印象深刻)。但是它的成功讓我們有理由認(rèn)為,以計(jì)算語言的形式構(gòu)建更完整的東西將是可行的。而且,與我們迄今為止對 ChatGPT 內(nèi)部的理解不同的是,我們可以期待將計(jì)算語言設(shè)計(jì)得讓人類容易理解。當(dāng)我們談?wù)撜Z義語法的時候,我們可以將其與對偶邏輯相類比。起初,對偶邏輯本質(zhì)上是用人類語言表達(dá)的語句規(guī)則的集合。
但是(是的,兩千年后)當(dāng)形式邏輯被開發(fā)出來時,音節(jié)邏輯最初的基本構(gòu)造現(xiàn)在可以用來建造巨大的 “形式塔”,包括例如現(xiàn)代數(shù)字電路的運(yùn)作。而且,我們可以預(yù)期,更一般的語義語法也會如此。起初,它可能只是能夠處理簡單的模式,例如以文本形式表達(dá)。但是,一旦它的整個計(jì)算語言框架建立起來,我們可以預(yù)期它將能夠被用來豎起 “廣義語義邏輯” 的高塔,使我們能夠以精確和正式的方式處理各種我們以前從未接觸過的東西,而只是在 “底層” 通過人類語言,以其所有的模糊性。我們可以認(rèn)為計(jì)算語言的構(gòu)造 —— 以及語義語法 —— 代表了一種對事物的終極壓縮。
因?yàn)樗试S我們談?wù)撌裁词强赡艿谋举|(zhì),而不需要,例如,處理存在于普通人類語言中的所有 “轉(zhuǎn)折性的措辭”。我們可以把 ChatGPT 的巨大優(yōu)勢看作是有點(diǎn)類似的東西:因?yàn)樗谀撤N意義上也已經(jīng) “鉆研” 到可以 “把語言以一種有語義的方式組合在一起”,而不關(guān)心不同的可能的措辭。那么,如果我們把 ChatGPT 應(yīng)用于底層計(jì)算語言,會發(fā)生什么呢?計(jì)算語言可以描述什么是可能的。
但仍然可以添加的是對 “什么是流行的” 的感覺 —— 例如基于對網(wǎng)絡(luò)上所有內(nèi)容的閱讀。但是,在下面,用計(jì)算語言操作意味著像 ChatGPT 這樣的東西可以立即和基本地接觸到相當(dāng)于利用潛在的不可還原的計(jì)算的終極工具。這使得它成為一個不僅可以 “生成合理文本” 的系統(tǒng),而且可以期望解決任何可以解決的問題,即這些文本是否真的對世界 —— 或者它應(yīng)該談?wù)摰臇|西做出了 “正確” 的陳述。
— 13 —那么ChatGPT 在做什么,為什么它能發(fā)揮作用?
ChatGPT 的基本概念在某種程度上相當(dāng)簡單。從網(wǎng)絡(luò)、書籍等人類創(chuàng)造的大量文本樣本開始。然后訓(xùn)練一個神經(jīng)網(wǎng)絡(luò)來生成 “像這樣” 的文本。特別是,讓它能夠從一個 “提示” 開始,然后繼續(xù)生成 “像它被訓(xùn)練過的那樣” 的文本。正如我們所看到的,ChatGPT 中的實(shí)際神經(jīng)網(wǎng)絡(luò)是由非常簡單的元素組成的,盡管有數(shù)十億個元素。神經(jīng)網(wǎng)絡(luò)的基本操作也非常簡單,主要是對它所生成的每一個新詞(或詞的一部分),通過其元素 “傳遞一次輸入”(沒有任何循環(huán),等等)。但出乎意料的是,這個過程可以產(chǎn)生成功地 “像” 網(wǎng)絡(luò)上、書本上的文字。而且,它不僅是連貫的人類語言,它還 “說了些什么”,“按照它的提示” 利用它 “讀” 到的內(nèi)容。它并不總是說 “全局有意義”(或?qū)?yīng)于正確的計(jì)算)的事情 —— 因?yàn)椋ɡ纾跊]有獲得 Wolfram|Alpha 的 “計(jì)算超能力” 的情況下),它只是根據(jù)訓(xùn)練材料中的事情 “聽起來像” 說了一些話。ChatGPT 的具體工程使它相當(dāng)引人注目。
但最終(至少在它能夠使用外部工具之前),ChatGPT“只是” 從它所積累的 “傳統(tǒng)智慧的統(tǒng)計(jì)數(shù)據(jù)” 中抽出一些 “連貫的文本線索”。但令人驚訝的是,其結(jié)果是如此的像人。正如我所討論的,這表明了一些至少在科學(xué)上非常重要的東西:人類語言(以及它背后的思維模式)在某種程度上比我們想象的更簡單,更 “像法律”。ChatGPT 已經(jīng)隱晦地發(fā)現(xiàn)了這一點(diǎn)。但我們有可能通過語義語法、計(jì)算語言等明確地暴露它。ChatGPT 在生成文本方面所做的工作令人印象深刻,而且其結(jié)果通常非常像我們?nèi)祟悤a(chǎn)生的東西。那么,這是否意味著 ChatGPT 的工作方式就像一個大腦?
它的底層人工神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)最終是以大腦的理想化為模型的。而且,當(dāng)我們?nèi)祟惍a(chǎn)生語言時,似乎很有可能發(fā)生的許多方面都很相似。當(dāng)涉及到訓(xùn)練(又稱學(xué)習(xí))時,大腦和當(dāng)前計(jì)算機(jī)的不同 “硬件”(以及,也許,一些未開發(fā)的算法想法)迫使 ChatGPT 使用一種可能與大腦相當(dāng)不同(在某些方面效率低得多)的策略。還有一點(diǎn):即使與典型的算法計(jì)算不同,ChatGPT 內(nèi)部也沒有 “循環(huán)” 或 “對數(shù)據(jù)進(jìn)行重新計(jì)算”。而這不可避免地限制了它的計(jì)算能力 —— 即使與目前的計(jì)算機(jī)相比也是如此,但與大腦相比肯定是如此。目前還不清楚如何 “解決這個問題”,并且仍然保持以合理效率訓(xùn)練系統(tǒng)的能力。
但這樣做大概會讓未來的 ChatGPT 做更多 “類似大腦的事情”。當(dāng)然,有很多事情是大腦做得不好的 —— 特別是涉及到相當(dāng)于不可簡化的計(jì)算。對于這些,大腦和像 ChatGPT 這樣的東西都必須尋求 “外部工具” —— 比如 Wolfram 語言。但就目前而言,看到 ChatGPT 已經(jīng)能夠做到的事情是令人興奮的。在某種程度上,它是基本科學(xué)事實(shí)的一個很好的例子,即大量簡單的計(jì)算元素可以做非凡和意想不到的事情。但它也為我們提供了兩千年來最好的動力,以更好地理解人類條件的核心特征,即人類語言及其背后的思維過程的基本特征和原則。
編輯:黃飛













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論