 電子發燒友App
電子發燒友App


作者:韓松
單位:中國移動智慧家庭運營中心
隨著互聯網技術的發展,網絡應用類型日益復雜,從Web、郵件等傳統應用,發展到各類P2P應用、自定義業務協議等。識別網絡流量中的應用協議類型成為網絡管理中的一個重要問題。傳統的模式匹配和特征提取方法在面對復雜應用協議時存在局限性。近年來,人工智能領域出現的大語言模型為應用協議識別帶來新的契機。大語言模型通過預訓練學習獲得對語言的深刻理解,可以運用到對網絡流量的語義分析中。
具體來說,大語言模型可以“讀懂”網絡流量中應用層的協議語義,判斷HTTP、DNS等常見協議的格式,并可以對不常見協議進行anomaly detection。另外,大語言模型學習的知識可以幫助進行零樣本和少樣本學習,識別全新或樣本稀少的應用協議。業界一些最新研究已經證明了大語言模型在應用協議識別中的效果。例如華為提出的ProtocolMate系統使用RoBERTa模型,實現了高達99.7%的準確率。另外基于BERT等模型的語義模糊方法,也表現出色。這些成果都表明了大語言模型的潛力。
Part 01 ●??應用協議識別是什么?●?
應用協議識別(Application Protocol Identification)指的是識別網絡流量所使用的應用層協議的方法。互聯網上的應用通信需要遵循某種應用層協議,比如HTTP協議用于網頁瀏覽,DNS協議用于域名解析等。為了管理網絡流量,需要能自動識別流量所使用的應用協議。
應用協議識別的主要方法包括:
- 基于端口的識別:通過判斷特定端口號來識別協議,如80端口通常為HTTP。但有局限性。
- 模式匹配:通過查找協議特有的字節模式來匹配協議。
- 統計分析:提取流量統計特征,使用機器學習方法識別。
- 深度學習:使用LSTM、CNN等對流量進行端到端的深度學習,自動提取特征。
- 語法分析:解析應用層數據,判斷遵循的協議語法。
- 語義分析:利用大語言模型分析應用層語義,識別協議含義。
應用協議識別對于網絡流量監控、安全防護等都有重要作用。隨著網絡應用日益復雜,更智能高效的應用協議識別技術變得尤為重要。
Part 02 ●?大語言模型的特點?●?
大語言模型具有以下幾個主要特點:(1)卓越的語義理解能力;(2)強大的遷移學習能力;(3)多樣化的應用形式。
(1)卓越的語義理解能力
大語言模型通過預訓練,可以深度理解語言的上下文和語義關系,對詞匯、語法、常識都有很強的理解能力。這使其可以進行復雜的語義分析、文本生成等高難度語言處理任務。
(2)強大的遷移學習能力
大語言模型學到的語言知識具有很好的普適性,可以遷移至下游的不同任務中。即使下游任務數據不足,也可以取得不錯的效果。這使大語言模型可以擴展到更多不同的應用領域。
(3)多樣化的應用形式
大語言模型可以以不同的形式集成到實際應用中,如通過微調進行文本分類、句子匹配;用作Encoder來提取語義特征;生成回復文本等。這使其能夠靈活地服務于不同的NLP應用。
Part 03
●??大語言模型的數據結構?●?
大語言模型通過組合使用各種特殊的數據結構,模擬并實現了人類語言的關鍵能力。它使用詞向量把詞轉換成數字編碼,類似詞典定義。注意力機制讓詞語之間進行交流,理解上下文,就像人類的語言交流。深層網絡提取語義特征,殘差連接傳遞信息,位置編碼理解順序,都增強了模型的語言理解能力。遮蔽語言模型進行自主學習,像人類通過閱讀學習語言。數以億計的參數幫助記憶知識。通過集成這些數據結構,大語言模型建立了一個像人腦一樣的語言理解和生成系統。它不僅能學習語言知識,理解語義,還能應用語言進行創造性的生成。大語言模型的數據結構實現了它對語言的深刻理解,使其達到了接近人類的語言處理能力。
數據結構作用
嵌入層(Embedding Layer)將詞符號表示轉換為稠密向量表示
多頭注意力機制(Multi-Head Attention)允許模型同時關注文本不同位置信息
前饋全連接網絡(Feed Forward Fully Connected Network)在多頭注意力后進行語義特征提取
殘差連接(Residual Connection)將前一層輸出同當前層輸出相加,緩解梯度消失
Layer Normalization加速深層網絡訓練,穩定訓練過程
位置編碼(Positional Encoding)為模型提供單詞順序信息
Mask機制在預訓練中屏蔽部分輸入,實現自監督
權重參數矩陣(Weight Matrices)計算注意力分數、變換等,占用大量存儲和計算
大語言模型的運行原理簡要概括如下:
首先,大語言模型會將輸入的文本序列轉化為數字表示的詞向量,就像一個詞典將詞語映射為向量。然后這些詞向量被輸入到由多層Transformer模塊組成的編碼器結構中。在每個Transformer模塊內,通過多頭注意力機制使詞向量之間進行交互,計算出詞與詞之間的相關性,以此來學習文本的上下文語義信息。
接著,經過一個前饋全連接網絡進行特征提取和表示變換。為了訓練更深層的模型,還使用了殘差連接、層規范化等技術。位置編碼為模型加入了順序信息。大量的參數支持復雜的語義計算。在預訓練階段,大語言模型通過自監督任務如遮蔽語言模型學到通用的語言知識。在微調階段,加入監督學習特定下游任務。這樣,大語言模型通過先獲得泛化語言表示能力,再遷移到具體任務中,實現了對人類語言的建模和強大的語義理解與生成。它模擬人類獲取語言知識然后應用的過程。
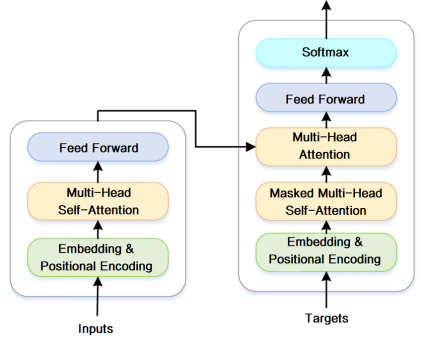
圖2 大語言模型核心模塊運行機制
各種數據源通過Kafka接入到數據平臺層,數據平臺講明細數據存入數據存儲層的ClickHouse中,明細數據的存活時間可以根據業務需求設置。同時可以根據業務報表查詢的不同維度,利用ClickHouse的物化視圖形成預聚合數據,提高數據查詢效率。由數據服務層的定時任務周期性地從ClickHouse的預聚合數據中查詢業務所需的展示數據,把展示數據存入MySQL。由數據服務層的報表服務向數據展示層提供查詢服務,報表服務直接查詢MySQL中的結果數據,保證了查詢效率和并發性。
Part 04
●??大語言模型在應用協議識別中的應用?●?
大語言模型具有強大的語言理解和建模能力,在應用協議識別等領域中展現出巨大的應用潛力。
下面將具體闡述大語言模型在應用協議識別任務中的運作機制和應用流程:
應用協議識別針對網絡流量中的應用層協議報文,判斷其所屬的協議類別,是網絡流量分析的關鍵環節。針對不同協議類型,可以進行定制化分析。相比基于規則的方法,基于大語言模型的協議識別具有更強的適應性和拓展性。
大語言模型在協議識別任務中的應用流程可以分成以下幾個步驟:
(1)數據預處理,需要收集大規模的應用協議報文數據,如HTTP、DNS等,對報文數據進行清洗,提取純凈的協議語料。
(2)構建協議詞表,將報文通過詞表轉換為數字id序列,方便模型處理。在獲取處理后的數據集后,需要預訓練語言模型以學習通用的協議語義特征。這里常用的預訓練模型是BERT等變種。通過使用大量協議報文數據Fine-tune預訓練模型,使其適應協議語言的模式,獲得協議方面的先驗知識。預訓練時也會使用Mask等技巧增強模型對協議語義的建模能力。
(3)微調模型以適應具體的協議識別任務。這里將建立一個協議類別分類模型,使用協議報文及其類別標簽進行監督訓練。通過反向傳播等技術迭代優化模型參數,使其逐步適應協議識別任務,輸出精確的類別判斷。
(4)部署微調模型。經過預訓練和微調后,可以導出獲得的協議識別模型,并集成到在線網絡流量分析系統中。在線部署后,對實時網絡流量進行抓取,提取協議報文,輸入到導出的協議識別模型中,完成在線流量的智能協議分析。
整個流程充分利用了大語言模型支持的遷移學習范式。先通過自監督在大規模語料上學習通用語言表示,然后快速適應下游任務。相比獨立訓練,這種方法顯著減少了人工特征工程,降低了對任務特定樣本量的依賴。同時也增強了模型的泛化能力。
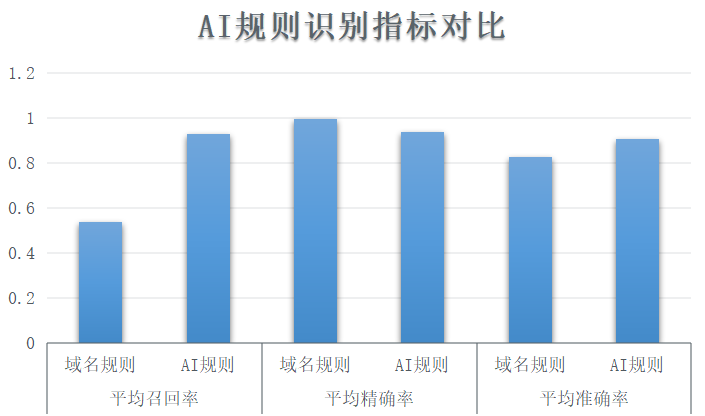
綜上所述,依托預訓練-微調框架,大語言模型可以高效適應協議識別等專業領域任務。它模擬人類語言學習過程,在大規模非標注語料上學習語義知識,然后遷移應用。這為解決更多特定領域的語言理解問題,提供了一個可靠的通用框架和技術路線。下圖給出了采用AI大語言模型的協議識別方法相對于傳統的基于域名規則的協議識別方法在準確率,識別精度和召回率上的效果提升。
各種數據源通過Kafka接入到數據平臺層,數據平臺講明細數據存入數據存儲層的ClickHouse中,明細數據的存活時間可以根據業務需求設置。同時可以根據業務報表查詢的不同維度,利用ClickHouse的物化視圖形成預聚合數據,提高數據查詢效率。由數據服務層的定時任務周期性地從ClickHouse的預聚合數據中查詢業務所需的展示數據,把展示數據存入MySQL。由數據服務層的報表服務向數據展示層提供查詢服務,報表服務直接查詢MySQL中的結果數據,保證了查詢效率和并發性。
Part 05
●??總結展望?●?
總結來說,大語言模型通過預訓練-微調的框架,先在大規模協議語料上學習通用語義表示,然后遷移應用到具體的協議識別任務,實現了對網絡流量的智能解析。相比規則方法,這種方式顯著提高了模型的適應性和拓展性。
展望未來,大語言模型在應用協議識別領域還有多個方向的探索價值:(1) 構建更大規模的跨協議預訓練語料庫,增強模型對協議語言的理解能力。(2)嘗試不同模型架構,如基于編碼器-解碼器的BART等,進一步提升建模效果。(3) 多任務學習框架,同時適配相關任務如協議語義解析,共享語義知識。(4) 在線增量學習機制,使deployed模型能隨新協議更新迭代。(5) 模型壓縮技術,部署輕量高效的協議識別引擎。(6) 可解釋性和安全性等考量,增加模型判斷的透明度和可控性。隨著模型和數據規模的提升,大語言模型必將持續改進應用協議理解,在更廣泛的網絡分析任務中發揮關鍵作用。
參考:
【1】自然語言大模型介紹,2023年04月01日,
編輯:黃飛
?








 工商網監
工商網監
評論