 電子發燒友App
電子發燒友App


作者:王抒偉
機器學習中,有一個稱為“ No Free Lunch ”的定理。簡單來說,與監督學習特別相關的這個定理,它指出沒有萬能算法,就是用一個算法能很好地解決每個問題。
例如,不能說神經網絡總是比決策樹更好,反之亦然。有許多因素在起作用,例如數據集的大小和結構。
那么,如果我遇到一個問題,首先應該嘗試多種不同的算法來解決問題,同時使用保留的“測試集”數據評估績效并選擇最優的那個算法,然后GitHub 搜索最優代碼修改哈哈哈哈。
當然,如果需要打掃房屋,可以使用吸塵器、掃帚或拖把。你不會用鏟子吧?
所以嘗試的算法必須適合要解決的問題,這才是選擇正確的機器學習任務的來源。

基礎
有一個通用原則是所有用于預測建模的受監督機器學習算法的基礎。
機器學習算法被描述為學習目標函數(f),該函數最好將輸入變量(X)映射到輸出變量(Y):Y = f(X)
這是一個簡單的學習任務,我們想在給定新的輸入變量(X)的情況下,對(Y)進行預測。但是不知道函數(f)。
機器學習的最常見類型是學習映射Y = f(X)可以對新X預測到Y,目標是盡可能進行最準確的預測。
對于初入機器學習領域,沒有機器學習基礎知識的新手,我會對常用的十大機器學習算法做簡單介紹。
1.?線性回歸
線性回歸可能是統計和機器學習中最著名和最易理解的算法之一。
主要與最小化模型的誤差或做出盡可能準確的預測有關,但以可解釋性為代價。我們將從許多不同領域(包括統計數據)中學習。
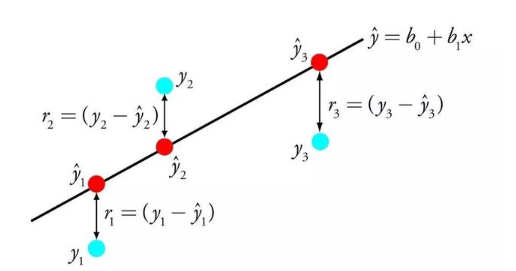
線性回歸的表示法是一個方程,該方程通過找到稱為系數(B),來描述輸入變量(x)與輸出變量(y)之間關系的線。
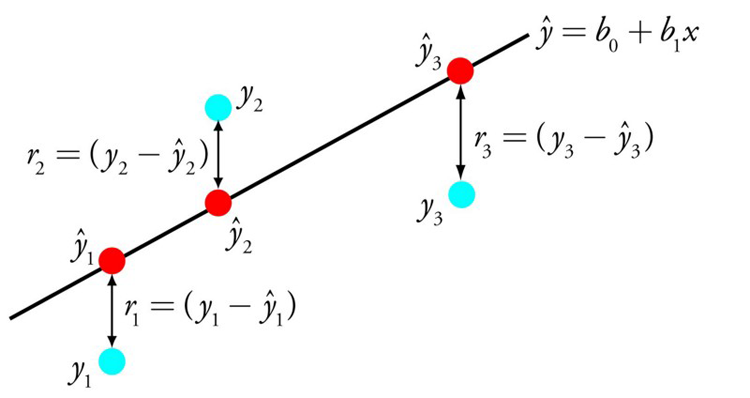
例如:y = B0 + B1 * x 臥槽,這不是一次函數嗎?哈哈
給定輸入x,我們將預測y,線性回歸學習算法的目標是找到系數B0和B1的值, 例如用于普通最小二乘法和梯度下降優化的線性代數解。
2.?LOGISTIC回歸
邏輯回歸是機器學習從統計領域“借”的另一種技術。它是二分類問題(具有兩個類值的問題)的首選方法。
Logistic回歸類似于線性回歸,因為目標是找到權重每個輸入變量的系數的值。與線性回歸不同,輸出的預測使用稱為對數函數的非線性函數進行變換。
邏輯函數看起來像一個大S,它將任何值轉換為0到1的范圍。因為我們可以將規則應用于邏輯函數的輸出為0和1(例如,如果IF小于0.5,則輸出1)并預測類別值。
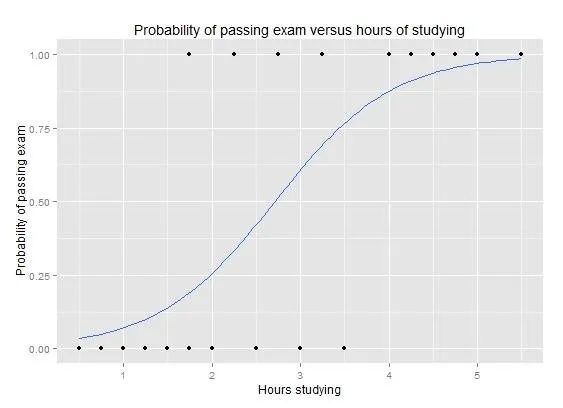
與線性回歸一樣,當去除與輸出變量無關的屬性以及相關的屬性時,邏輯回歸的效果更好。這是一個快速學習二進制分類問題并有效的模型
3.?線性判別分析
Logistic回歸是傳統上僅限于兩類分類問題的分類算法。如果是多分類,則線性判別分析算法(LDA)就是很重要的算法了。
LDA的表示非常簡單,它由數據的統計屬性組成,這些屬性是針對每個類別計算的。對于單個輸入變量,這包括:
每個類別的平均值。
計算所有類別的方差
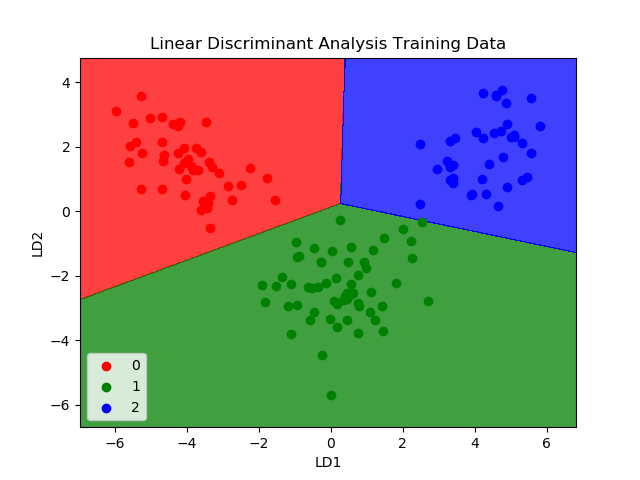
通過為每個類別計算一個區分值并為具有最大值的類別進行預測來進行預測。
該算法的前提是:數據具有高斯分布(鐘形曲線),因此最好在操作之前從數據中刪除異常值。
4.?分類和回歸樹
決策樹是用于預測建模機器學習的重要算法類型。
決策樹模型的表示形式是二叉樹。這是來自算法和數據結構的二叉樹,沒有什么花哨的。每個節點代表一個輸入變量(x)和該變量的分割點(假設變量是數字)。
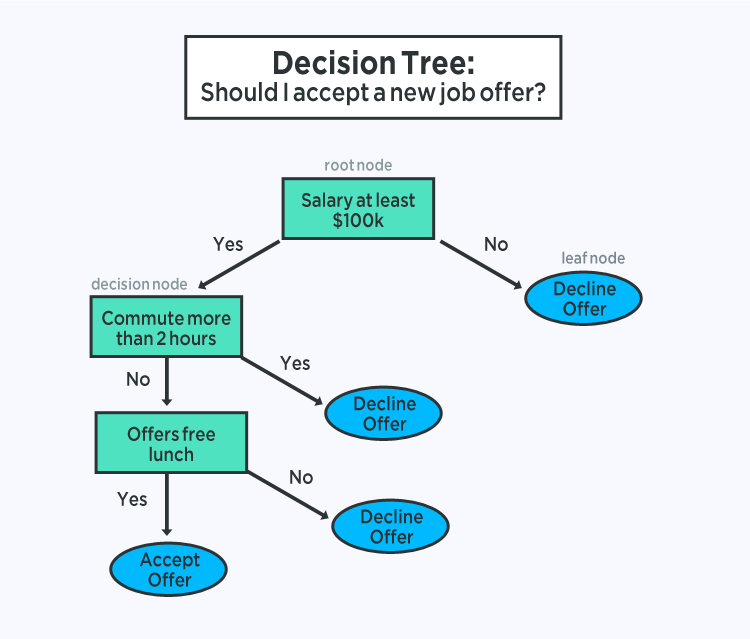
樹的葉節點包含用于進行預測的輸出變量(y)。通過遍歷樹的拆分直到到達葉節點并在該葉節點輸出類值來進行預測。
樹學習速度很快,做出預測的速度也非常快。它們對于許多問題通常也很準確,不需要為數據做任何特殊預處理。
5-樸素貝葉斯
樸素貝葉斯(Naive Bayes)是一種簡單但功能強大的預測建模算法。
該模型由兩種類型的概率組成,可以直接從您的訓練數據中計算出:
1)每個類別的概率;
2)給定每個x值的每個類別的條件概率。
開始計算,概率模型可用于使用貝葉斯定理對新數據進行預測。當你的數據是實值時,通常會假設一個高斯分布(鐘形曲線),以便可以輕松地估計這些概率。
樸素貝葉斯之所以被稱為樸素,是因為它假定每個輸入變量都是獨立的。這是一個很強的假設,對于真實數據來說是不現實的,盡管如此,該技術對于大量復雜問題非常有效。
6 - K近鄰
KNN算法非常簡單且非常有效。KNN的模型表示是整個訓練數據集。簡單吧?
通過搜索整個訓練集中的K個最相似實例并匯總這K個實例的輸出變量,可以對新數據點進行預測。
對于回歸問題,這可能是平均輸出變量,對于分類問題,這可能是最常見的類別值。
訣竅在于如何確定數據實例之間的相似性。如果您的屬性都具有相同的比例(例如,都是距離數據),最簡單的方法是使用歐幾里得距離,您可以根據每個輸入變量之間的差異直接計算一個數字。
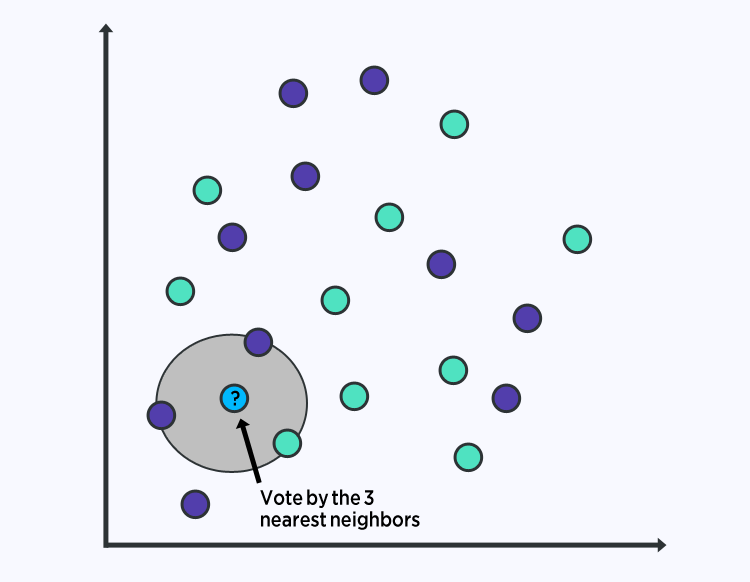
KNN可能需要大量內存或空間來存儲所有數據,因為它把所有數據都遍歷了。您還可以隨著時間的訓練數據,以保持預測的準確性。
距離或緊密度的概念可能會分解為非常高的維度(許多輸入變量),這可能會對問題的算法性能產生負面影響。所以對于數據的輸入就至關重要。
7- 矢量化學習
K最近的缺點是需要整個訓練數據集。學習向量量化算法(簡稱LVQ)是一種人工神經網絡算法,可讓選擇要需要的訓練實例數量。
LVQ的表示形式是向量的集合。這些是在最開始開始時隨機選擇的,適用于在學習算法的多次迭代中最好地總結訓練數據集。
學習之后,可以像使用K近鄰一樣,使用數據進行預測。通過計算每個向量與新數據實例之間的距離,可以找到最相似的數據向量(最佳匹配的向量)。然后返回最佳匹配的類值作為預測。記得數據歸一化,獲得的效果更好。
8-支持向量機
支持向量機可能是最受歡迎的機器學習算法之一。
超平面是分割輸入變量空間的線。
在SVM中,選擇一個超平面以按類別(類別0或類別1)最好地分隔輸入變量空間中的點。
在二維圖中,您可以將其可視化為一條線,并假設所有輸入點都可以被這條線完全隔開。SVM學習算法找到超平面對類進行最佳分離的系數。
超平面和最近的數據點之間的距離稱為邊距。可以將這兩個類別分開的最佳或最佳超平面是邊距最大的線。
僅這些點與定義超平面和分類器的構造有關。這些點稱為支持向量。
在實踐中,使用優化算法來找到使余量最大化的系數的值。
SVM可能是功能最強大的即用型分類器之一,使用頻率很高。
9-BAGGING和隨機森林
隨機森林是最流行,功能最強大的機器學習算法之一。這是一種稱為Bootstrap聚類或BAGGING的集成機器學習算法。
您需要對數據進行大量采樣,計算平均值,然后對所有平均值取平均值,以便更好地估算真實平均值。
在bagging中,使用相同的方法,但用于估計整個統計模型(最常見的是決策樹)。獲取訓練數據的多個樣本,然后為每個數據樣本構建模型。當你需要對新數據進行預測時,每個模型都將進行預測,并對預測取平均值以對真實輸出值進行更好的估計。
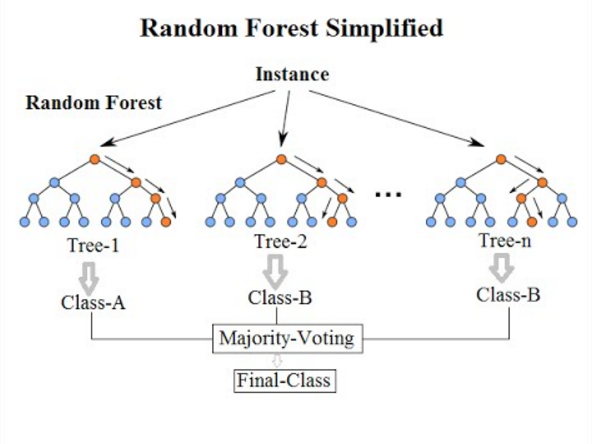
隨機森林是對這種方法的一種調整,在該方法中將創建決策樹,不是選擇最佳的拆分點。
因此,為每個數據樣本創建的模型與原先的模型相比,差異更大。將他們的預測結合起來可以更好地估計真實的基礎輸出值。
?
Boosting是一種集成技術,嘗試從多個弱分類器創建強分類器。這是通過從訓練數據構建模型,然后創建第二個模型來嘗試糾正第一個模型中的錯誤來完成的。添加模型,直到完美預測訓練集或添加最大數量的模型為止。
AdaBoost是為二進制分類開發的第一個真正成功的增強算法。這是了解增強的最佳起點。現代的增強方法基于AdaBoost,最著名的是隨機梯度增強機.
具體細節可以看這個視頻.
AdaBoost與決策樹一起使用。
創建第一棵樹后,將在每個訓練實例上使用該樹的性能來加權要創建的下一棵樹應注意每個訓練實例的關注程度。
難以預測的訓練數據的權重更高,而易于預測的實例的權重更低。依次創建模型,每個模型都會更新訓練實例上的權重,這些權重會影響序列中下一棵樹執行的學習。構建完所有樹之后,對新數據進行預測,并根據訓練數據的準確性對每棵樹的性能進行加權。
由于該算法在糾正錯誤方面投入了很多精力,因此刪除異常值和數據去噪非常重要。
編輯:黃飛
?
















 工商網監
工商網監
評論