 電子發燒友App
電子發燒友App


2023年11月,趨動科技聯合創始人兼CTO陳飛博士,在數據中心標準大會上以《從小模型到大模型——AI時代下的數據中心建設》為題發表演講,根據演講內容整理下文,供數據中心行業內的廣大讀者參考。
01.?人工智能的發展和現狀
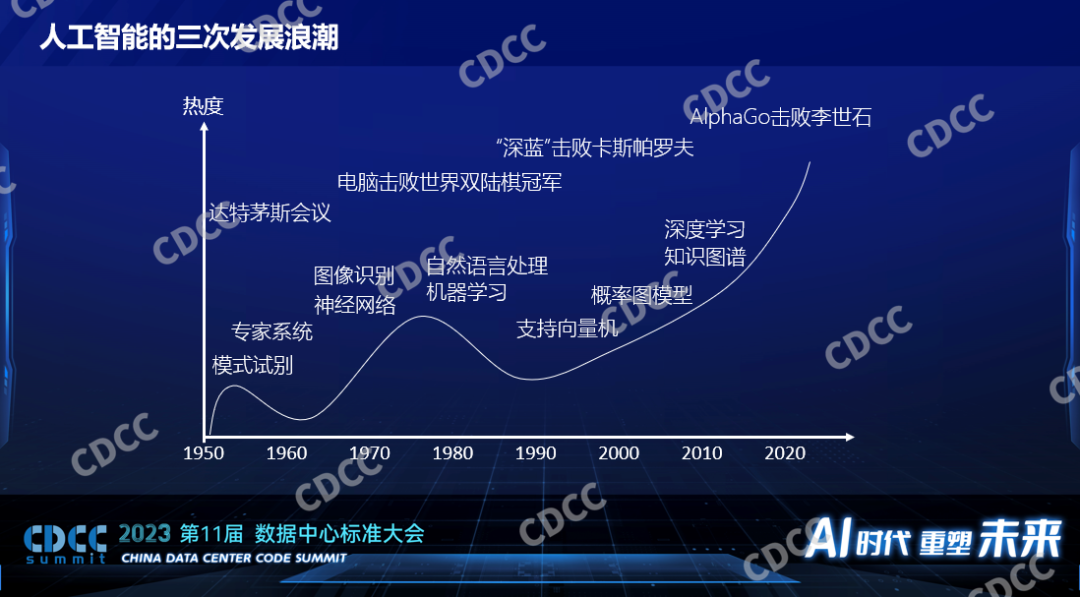
AI或者人工智能自1956年提出至今已有幾十年的歷史。過去的幾十年里面,人工智能的熱度經歷了三次浪潮,第一次提出人工智能之后出現一些新的技術,也應用到了工業生產上,但是很快大家發現所謂的人工智能還不是那么智能,一波浪潮過去之后,大家對它的關注度也就降低了。隨著一些新技術的出現,1979年電腦程序擊敗了當時的世界冠軍,1997年IBM的深藍擊敗了卡斯帕羅夫,這樣標志性事件提升了人們對人工智能的期望,人工智能迎來了一波高峰。2006年Hinton提出了深度學習的概念,標志著第三次人工智能發展的浪潮。
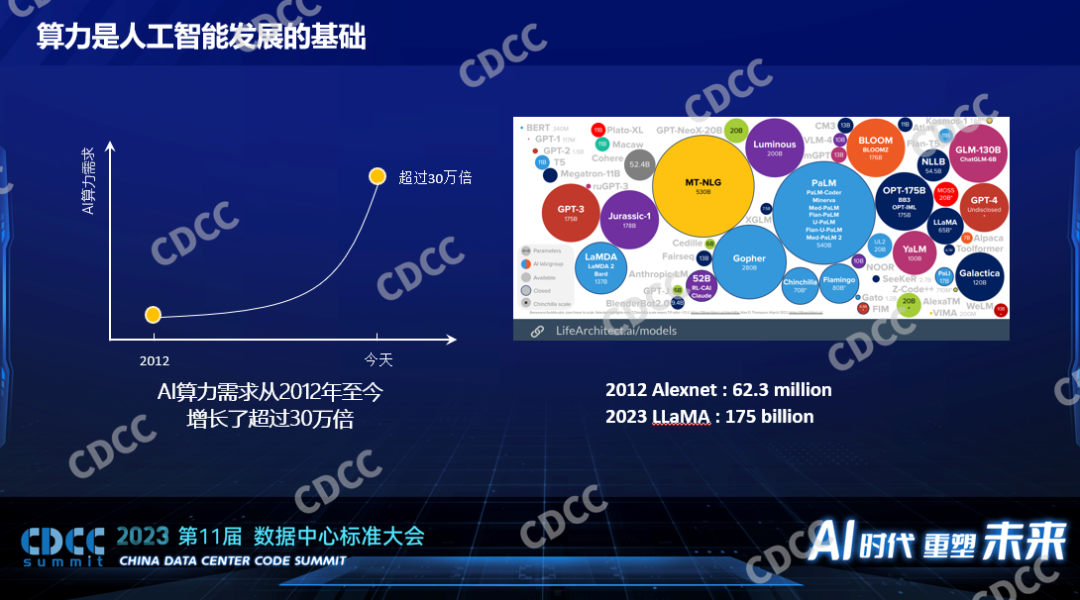
第三次人工智能浪潮開始后,有很多新的算法出現,同時有GPU這樣的硬件支撐這類算法。據統計,2012年至今,我們對算力的需求漲了30萬倍。這么多的算力需求都消耗在哪了?大量消耗在模型算法本身的快速發展。上圖是國外的一個網站,他們自動統計了一些公開的模型的大小,圖左上角很小的一個點是BERT,它在兩三年前小模型時代還是比較重量級別的模型,到現在圖里幾乎已經看不到了。2012年標志性的深度學習模型Alexnet(百萬參數)到2023年 LLaMa,是2800倍的模型的增長,模型的增長意味著算力的消耗增長。
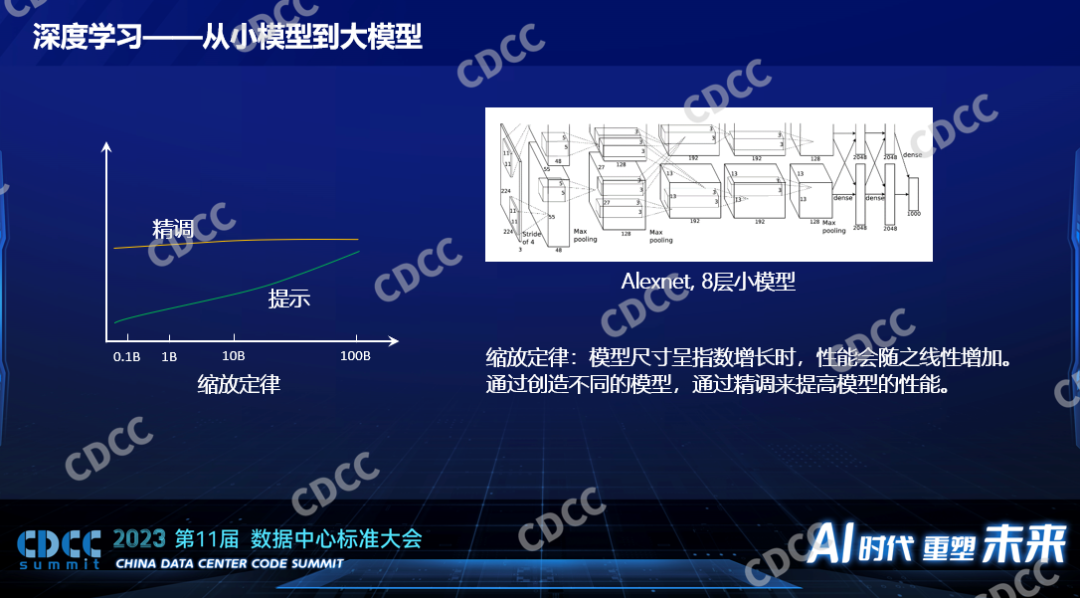
上圖是一個Alexnet很小的內部結構圖,Alexnet相對今天來說是一個非常小的模型,它為什么叫深度學習呢?它的模型是分層的,一層一層,最左邊這層,給大家打一個比喻,它就是一幅圖片,我們都知道它是二維的像素點,寬和高,像素點就是一些數值,最黑就是0,最亮就是255,這個是它的一層。一層進來了之后,它要和一個模型的參數進行數學運算,從一個二維的圖象經過數學運算數學變換之后變成一個三維的立體,從數據的表達上是個三維的立體,一層一層的去運算,每一層的運算都不一樣,有做卷積的,有求最大值的,有求最小值的,一層一層下來最后得出一個結果,這個結果就是給這個圖片做一個分類,是貓還是狗,這就是一個模型。深度學習就是這個意思,一層歸一層。Alexnet是8層的小模型,后面在小模型時代還有ResNet50,具有50層,ResNet 152,有152層,每一層的增加以及每一層規模的大小背后都意味著巨大的算力的消耗。
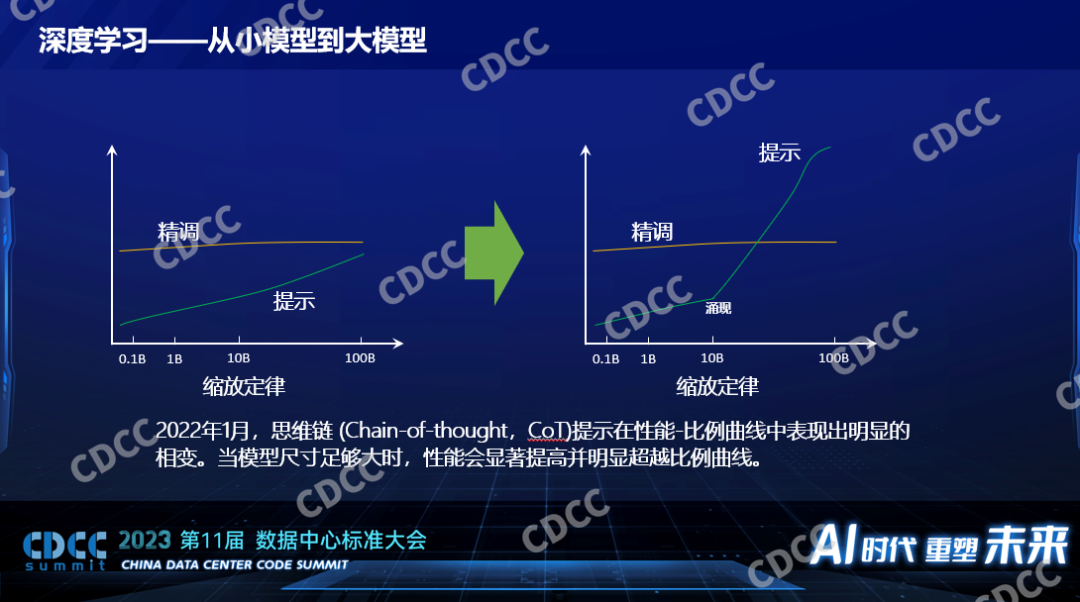
GPT模型結構有可能不一樣,比喻成初期的小模型,那都是千層級別,所以深度學習的模型消耗著巨大的算力,大家為什么熱衷于增大模型?,過去的時候學術界里有一個結論,他們認為有個縮放定律,這個縮放定律就是當這個模型的尺寸呈指數增長的時候性能呈線性增長,性能不是指運算的速度,在人工智能領域里面性能指的是模型的質量,比如識別圖象的精確率,如果是大語言模型的話就是它生成的內容的質量,這個性能會隨之線性增長,這個規律其實是挺悲觀的規律,因為模型是指數性增長換來的才是性能的線性增長,意味著我們有可能對這個模型背后算力的需求要消耗非常非常大,之前估計大到整個太陽的能量都提供給一個模型都不足以產生具有人一樣的智能的模型出來。
如果落地到一些具體小的應用,具體的場景里面還是有非常好的效果的,像人臉的識別,精確度非常高。
以前一般都通過精調來提高模型的性能,比如改變數據集,人工做更好的標注,提高更高質量的數據集,讓模型的性能越來越好,對模型做變種,比如覺得ResNet 50不夠,用ResNet 152,大模型和以前很不一樣的是大模型都是要有提示詞的,提示詞在小模型時代已經出現了,但這個技術比起人工標注數據的方式效果并不好,小模型的時候離人工精調一個模型得到的性能差別非常遠,所以在那個時候提示詞并沒有成為人工智能的主流,并且當時人們認為基于提示詞這種比較簡單的模型訓練的方法要到模型非常大的時候才能媲美一個很小的模型,比如要在100B的參數的模型下面,它的性能和0.1B的小模型相媲美,那時候不成為主流。
為什么突然大模型出現了?2022年一篇來自谷歌的文章向技術領域公開了思維鏈的技術,簡單的說以前人工智能訓練一個模型是給一個數據并且人工告訴它關于這個數據的結果。但是在思維鏈的訓練模型下面,它會像人教學生一樣一步一步的推到這個結果是怎么得到的,這種思維鏈的產生出現了讓科學家們意料不到的現象,這個現象叫涌現,意思就是當模型大到一定程度之后使用思維鏈的訓練方式會引起相變或者突變,它不再是我們以前預期的平緩的上升,而是突然有一個飛躍的發展。這種思維鏈用在小模型的時候是不生效的,但是用在模型參數大概10Billion的時候會生效,并且得到的性能比以前精調的方式有了本質的差異。所以我們說什么是小模型和什么是大模型,一個特征就是是否會在模型變得足夠大的時候有涌現的現象出現,如果沒有的話,它的模型參數再大,我們還是認為它是小模型,雖然說它對算力的消耗也是巨大的。正因為有了涌現的現象出現,大家對人工智能的期望再次被拔高了,現在大家都在討論大模型。
02.?企業人工智能的開發和生產
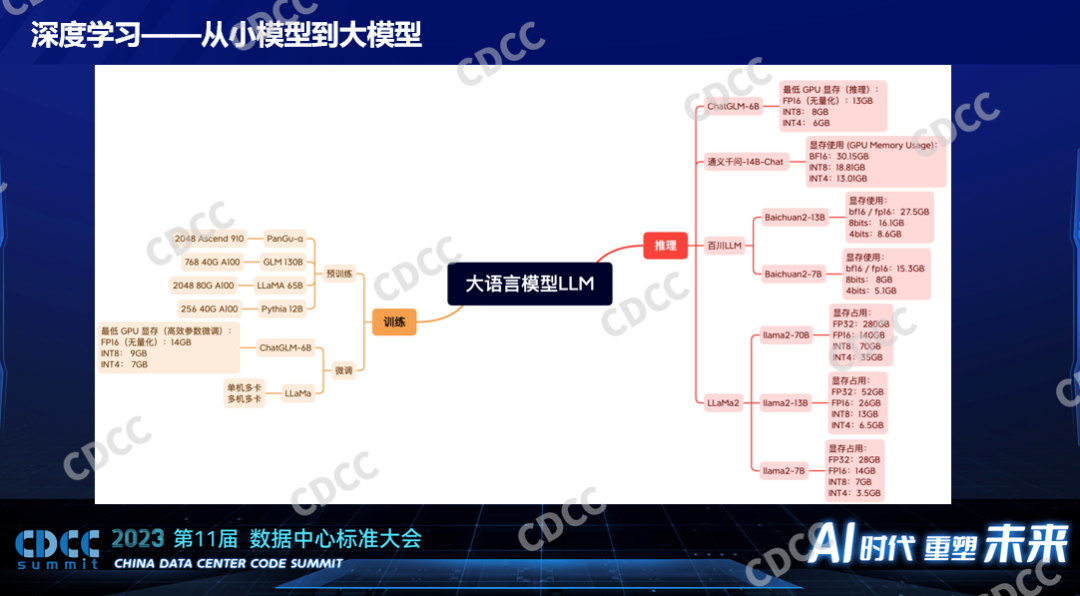
小模型和大模型在硬件方面的一些需求上的差異:小模型在V100的時候甚至更小,比V100等同算力的硬件下面已經工作的非常好,比如早些年小模型的訓練各個廠家打榜用1024個V100多快的時間訓練,在時間的生產里面一般都在一個節點8個V100下面訓練幾天就可以訓練出來,這是個小模型。當時以比較好的硬件單個節點做訓練是完全可接受的,也是實踐中比較常用的。如果在線推理的話,一個卡都用不滿,連一個只有V100幾分之一性能的T4都綽綽有余,這是小模型的時候。大模型對硬件的要求就變得高得多了,現在大模型還是發展的階段,大模型和大模型之間的大小差異也非常大,也有百倍的差異,有10個Billion的也有上百個Billion,對硬件的需求差異比較大。我們和比較多的公司或產業有過合作,我們看到的更多的是百這個量級,H100或H800或者A100、A00,100還是200還是512,這是比較常見的。如果是ChatGPT的模型的話,根據爆料應該是萬這個級別,這是做訓練。做推理,現在單個節點一般來說都是夠的,不管什么模型,更常見的單個卡也已經夠了,畢竟現在的硬件性能也已經比之前有一個飛躍的發展。
大模型是不是意味著一定是幾百個卡才能完成的任務呢?不是,大模型里面訓練也分為預訓練和微調,預訓練用卡比較多,比如GLM130B的模型要2000多個A100,訓練一個月到幾個月之間,不同的模型不一樣,這個預訓練模型是消耗算力比較大的。但是對于微調來說,對于資源的消耗小很多,比如基于一個開源的LLaMa模型進行一些微調,一個配置比較高的單節點是可以完成的,時間長一點而已,如果是更小的模型,單卡都是可以完成微調的。現在大家也會發現他們會通過一些技術減少模型的大小,通過量化的手段通過剪枝的手段,不斷的把大模型裁小。對推理來說,大部分情況下一個卡是足夠的,我們收集到了模型使用的資源情況,比如剛才說的LLaMa2,如果是7B的模型的話,它對顯存的占用也就是28個G,以現在的中高端的GPU來說就算是一個不大的消耗了,單卡都能完成,半個卡都已經足夠了。百川13B的或7B的都是單卡就可以完成了,它對顯存的占用并沒有那么高,能把顯存縮下來用了很多技術。
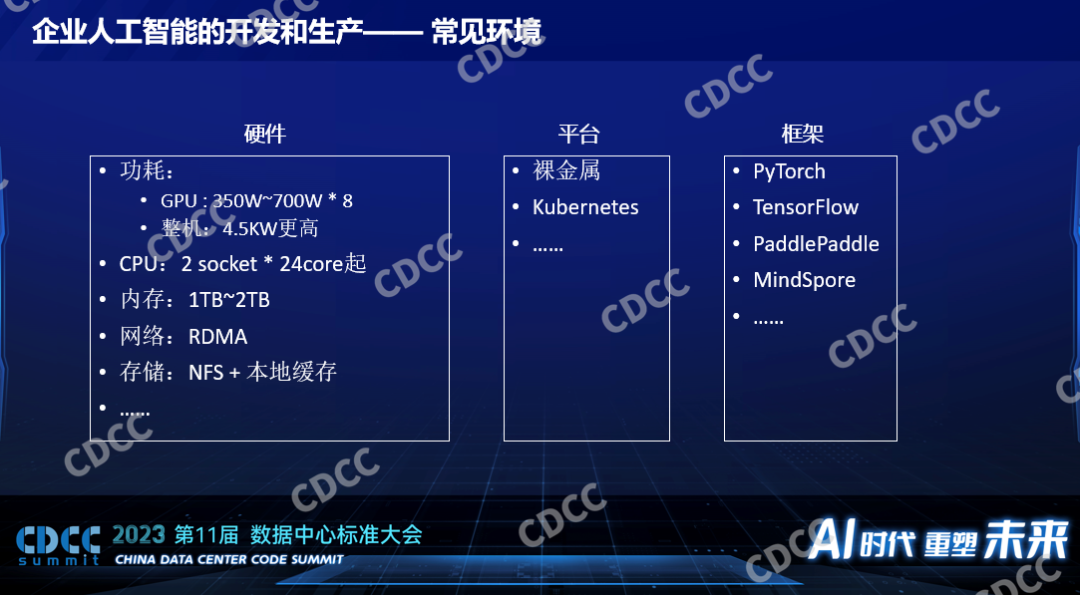
一個企業要開展人工智能的開發需要什么樣的條件,它要考慮哪個方面的事情,這是影響數據中心建設的一個重要因素。所以這里面講到的數據中心的建設,包括一些企業部署他內部使用的私有的環境,也有一些會把數據中心貢獻給到第三方貢獻到外部去使用的情況。對于所有數據中心建設來說都是用戶的需求驅動的,這是比較常見的一個企業要開展人工智能方面的開發和生產他們需要的一些事情,當然首先要有硬件,其次在管理這個平臺上面因為他要做訓練,他要做推理,而且推理的任務不是一個而是多個,他一定會有一個平臺。現在80%以上的客戶都是基于Kubernetes管的,和超算不一樣,超算用Slurm,人工智能用Kubernetes是比較通用的,這是一個平臺能夠讓任務分發到我們的硬件上面去運行,在上面不同的模型不同的算法要基于一些框架,這些框架在開源界有PyTorch、TensorFlow等,隨著國產化的需求以及國內科技的進步,百度主導的PaddlePaddle,它是開源的,華為的MindSpore比PaddlePaddle晚一點。這是不管是開源、學術還是企業用的比較多的框架。
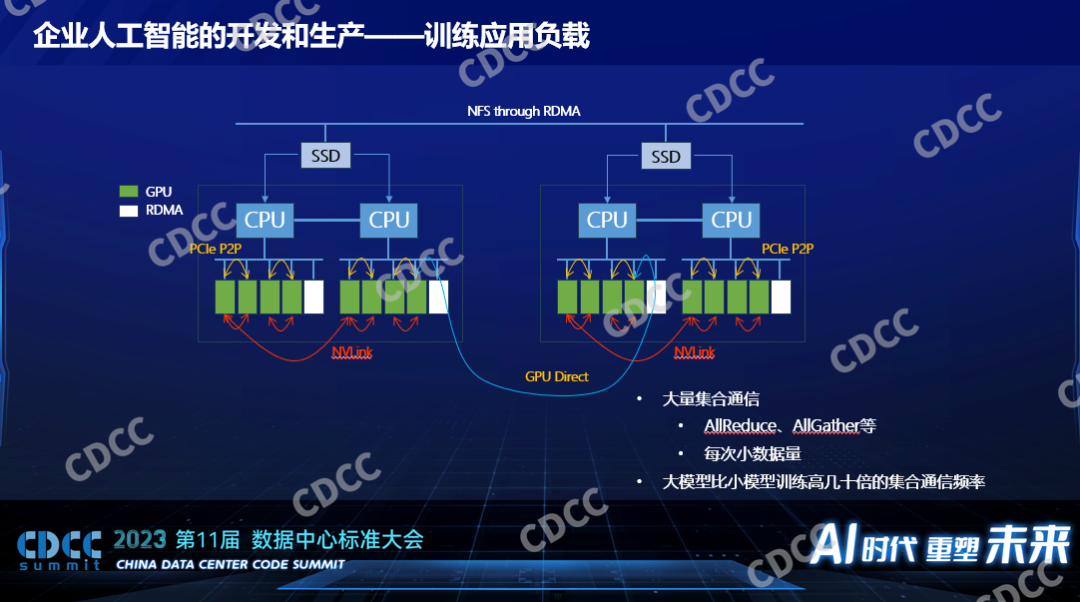
在數據中心建設里面仍然要考慮的是人工智能背后的負載究竟是什么。對于訓練來說,一個分布式訓練,一般說來都是多卡,如果是大模型還是多節點也就是分布式,我們知道數據中心建設,網絡是一個非常關鍵的因素,我們考慮算法或者模型在訓練過程中對網絡的沖擊是怎么樣的,它分好幾層,卡和卡之間的交換如果是英偉達有NVLink,點對點的傳輸,如果對于沒有NVLink的來說,也有基于PCIE Swich的協議,可以完成卡到卡的通訊,對CPU的負載比較低,只在節點內完成,只要在硬件配置或者服務器的采購定制上面做好就行。如果是服務器和服務器之間的訓練來說,RDMA幾乎是必備的,沒了它性能會慢到不可接受,所以每個節點上都會有配IDMA。而現在以英偉達為例的這種卡都支持GPU Direct,GPU和GPU之間的通訊不過CPU,它通過底層的硬件技術和驅動的配置,數據可以從一個GPU卡直接通過PCIE Swich到RDMA卡到另一個節點的RDMA卡直接灌到GPU上去,完成數據的交換。訓練的時候要有數據,AI的數據以讀為多,寫的少,一個典型得用法就是通過網絡的存儲方案配合本地的高速緩存,當然本地的高速緩存需要平臺需要框架支持使用,一般來說會用高速的SSD作為緩存。
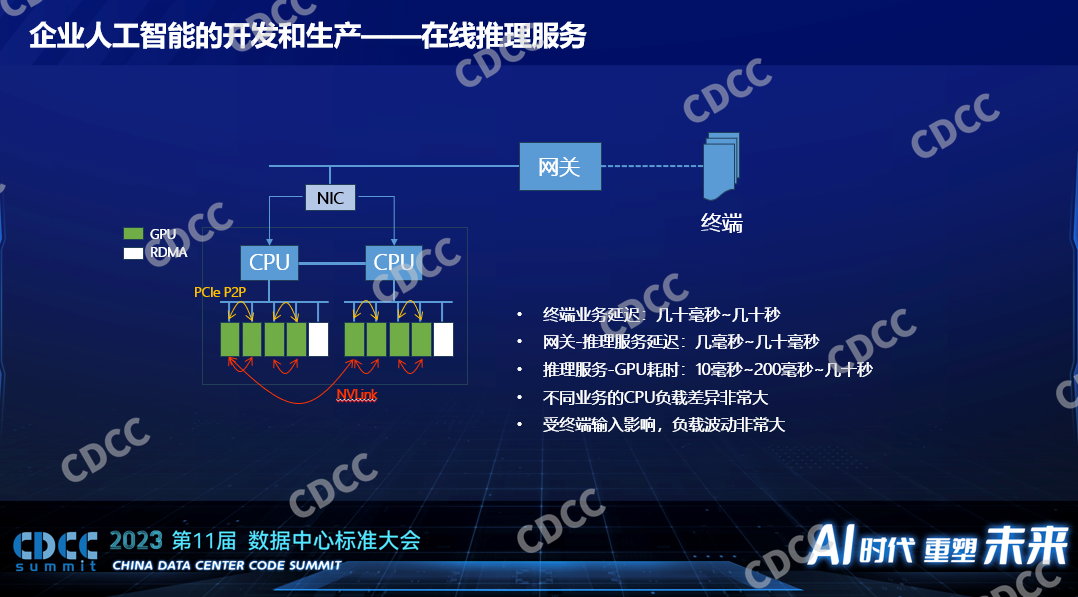
在線推理對于硬件的需求就少多了,大家會特別關心一個推理的性能嗎,不一定,一個在線的推理服務對端到端的性能有很多方面的影響,終端是手機到達數據中心或者到達企業的網關本身就有幾十毫秒的延遲,里面為什么寫了幾十秒呢,指的是得到一個業務的返回,以GPT為例,發一幅圖片給它,它把結果給我,人可以接受的延遲最長可以長到幾十秒,如果是刷人臉的話,人可以接受的延遲大概是500毫秒到1秒。落到GPU運算或者AI運算,這個延遲在整個通路里面占小頭,尤其在以前小模型里面它占小頭,在以前小模型的時候我們聽到的業務需求是幾百個毫秒到1秒它都可以接受,這個時候用來做推理的延遲一般才10個毫秒到小于100個毫秒,這個時候我們的算力低一點在小模型時代并不會影響端到端的服務質量,如果我們要做數據中心建設的話我們一定要考慮上面的推理服務究竟是什么類型的。
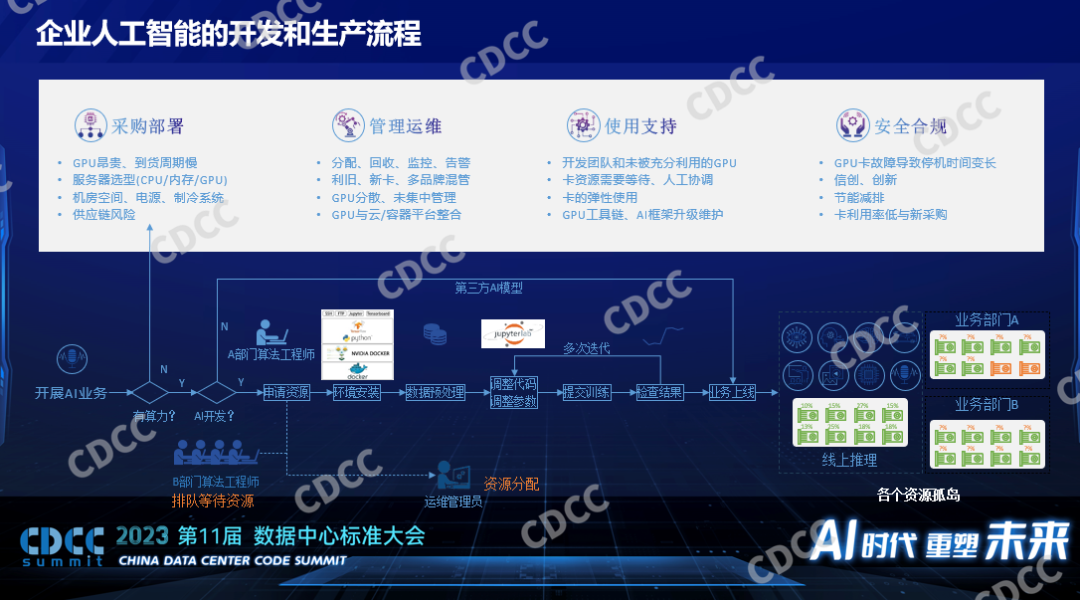
一個企業開展人工智能生產流程有很多環節,如果我們要做開發而不是采購第三方的模型的話,我們涉及到的采購就會比較多,我們要去采購部署,要有相關的運維,運維只能解決硬件故障的問題,剛才說的平臺層、框架層,還要由更上一層的團隊去支持。對數據中心來說我們要滿足很多合規的要求,我們要知道GPU卡的故障率非常高,如果是消費級的卡甚至還有起火的案例,在整個過程中我們要考慮的是各個部門對于GPU集群使用的需求是什么,它要求有的部門做訓練,有的是推理的,他們是否要求獨占不同的資源,這也都是我們要考慮到的。
03.?面向人工智能的數據中心建設
根據我們對行業的觀察,我們發現有一些數據中心在使用GPU時候的挑戰:
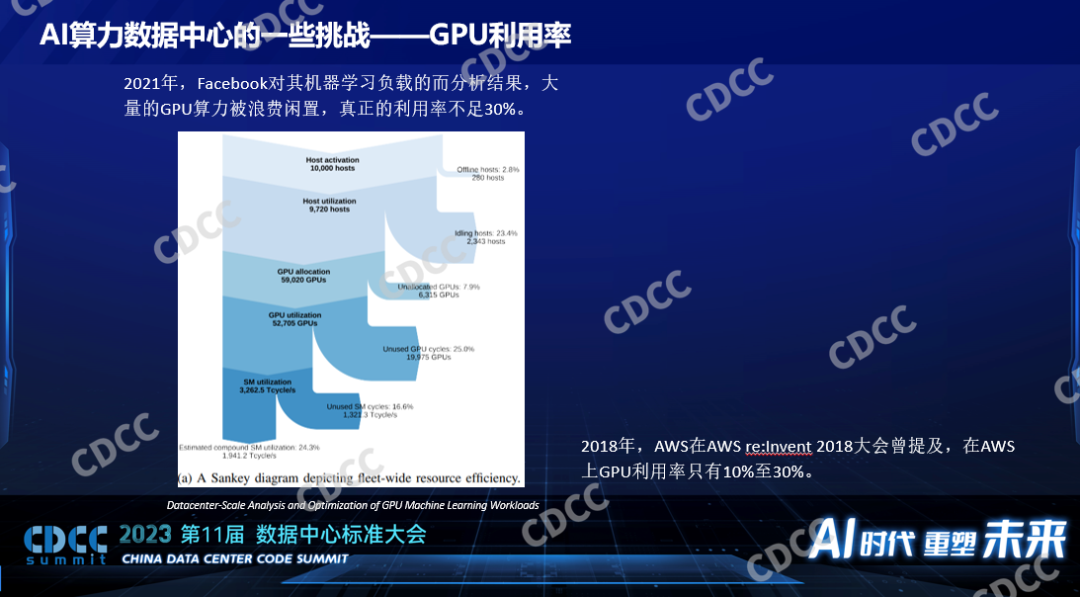
一是利用率。由于各種環節它都有損耗,導致最后GPU的實際利用率只有20%-30%,這是Facebook公開的一個數據,他們對GPU平均的實際的利用率只有10%-30%,每個環節都有可能引起它的損耗。
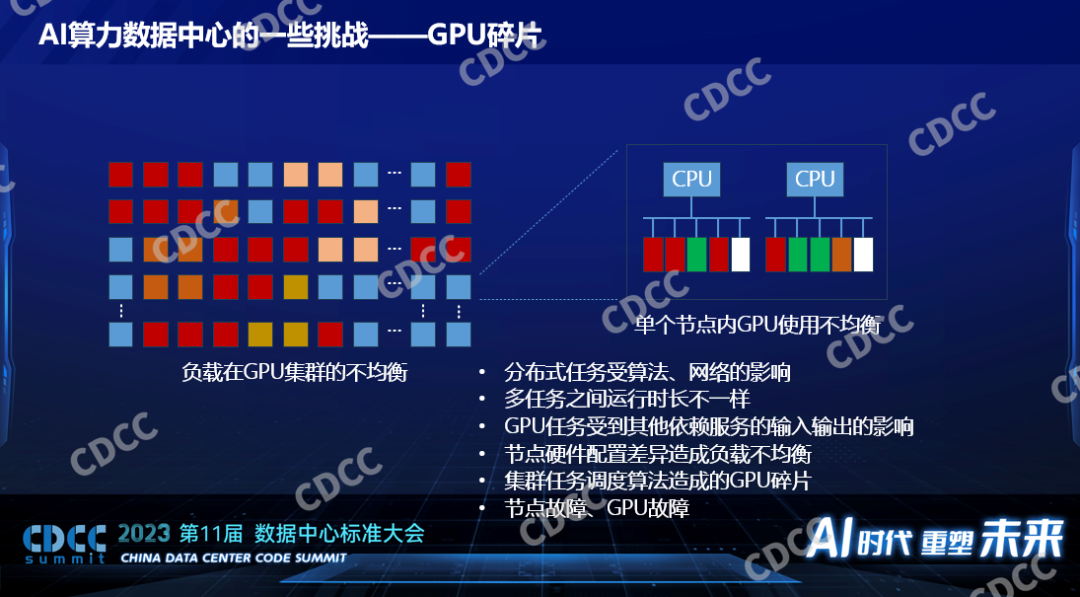
二、GPU碎片。這是引起損耗的一個重要因素,即使是百卡甚至千卡的分布式的大模型的訓練,也由于算法本身的特征,它并不是每個節點的每個卡都被100%使用的。我們觀察到的是大概有50%在大模型的訓練里面而且是一個不大的規模,百這個級別只有50%的GPU在100%被使用,還有50%經常會空閑,當然它不是靜態的,它是變化的過程。如果規模更大,比如GPT以萬為級別的訓練,根據他們公開的數據也只有30%的GPU利用率,以及每個節點也會出現有的卡被用滿,有的卡沒有被用上,這是GPU碎片。

三、功耗碳排放。不同模型的碳排放的指標是非常高的,像訓練一個BLOOM模型,30噸的二氧化碳的排放,一個GPT3 552噸的碳排放。
訓練和推理的需求非常不一樣,小模型和大模型對硬件的需求也是非常有差異,管理異構的硬件配置對于數據中心的運維來說是非常大的挑戰。要解決這些問題,業內曾經給過一個很通用的方案,像存儲,我們之前用磁盤也遇到過類似的問題,磁盤的碎片怎么解決的呢?把磁盤變成一個分布式的存儲,這樣的話應用在使用存儲的時候從來不用關心我使用的磁盤是本地磁盤還是別的節點的磁盤,只要我整個機群里面的磁盤還有冗余,我的應用就可以使用,GPU之所以有這些缺點,因為它現在還不具備這個特征,對于我們公司來說使用的軟件就是讓GPU一個一個獨立的GPU卡就像當初一個一個獨立的磁盤一樣,能夠把它聚合起來,在數據中心里面通過網絡,對于應用來說它呈現的是一個最基本的算力,已經被還原成算力了,而不是一個一個的卡,這個時候只要我這個數據中心還有一張卡空閑,我的業務不管在數據中心的哪個節點,我都仍然可以使用這個卡的算力進行人工智能的計算,它可以解決負載不均衡、碎片等等的產生。
通過這個方案解決企業在AI開發和生產過程中各個階段的痛點問題,像預訓練、最后的上線,我們都提供了不同的支撐,比如雙資源池可以讓訓練的性能更快,最后的顯存和算力的超分支持熱遷移,支持它最后業務的上線和生產。
04.?思考和展望
最后有幾個思考,可以幫助我們提高GPU在數據中心中的利用率,尤其是對于一些私有化部署來說:
1、統一資源管理
越大的AI算力資源池效率越高 ? ? ? ?
2、開發、訓練、推理混合部署
通過不同大小的任務調度提高利用率
通過不同延遲敏感性的任務調度提高利用率
通過不同優先級的任務調度提高利用率 ? ? ?
3、通過提高運維的手段,GPU出現故障的時候能夠快速把它隔離出去,能夠把業務遷移走,減少對業務的沖擊。
審核編輯:黃飛
?





















 工商網監
工商網監
評論