 電子發燒友App
電子發燒友App


作者:方佳瑞
?
Continuous Batching現已成為大型模型推理框架的關鍵技術,也是框架性能優化的主戰場。通過將多個在線請求進行批處理(Batching),可以提高 GPU 的使用效率。在 Transformer 出現之前,在模型服務過程中,Batching功能通常由一個與推理框架分離的服務框架來完成,例如 tfserving之于TensorFlow XLA和NVIDIA Triton之于TensorTR。這些框架的Batching設計是針對具有相同形狀的輸入請求,如相同尺寸的圖像。然而,Transformer 的出現使得輸入序列和批次大小都變得可變,這為Batching帶來了新的挑戰和機遇。
最近系統看了一下Continuous Batching的工作,讓我回憶起了在騰訊微信(WXG)工作時的一段往事。
2019年下半年,我校招加入微信WeChat AI做了一個Transformer模型的推理服務框架TurboTransformers[1],目的是對標FasterTransformers,滿足所在團隊NLP服務上線需求。隨后我把TurboTransformers里幾個亮點整理成一篇論文發表在PPoPP 21[2]上,里面介紹了我提出了針對encoder-only架構的變長輸入問題的兩個創新點。第一個是用chunk來管理動態內存,平衡GPU內存footprint大小和臨時分配overhead。想法和Paged Attention的思想有些類似,只不過是用page(chunk)管理推理的中間結果activations,而PagedAttention用page來管理KVCache。第二個是,用動態規劃尋找最優的padding策略以獲得最優吞吐速度,減少無效計算。雖然思路比較巧妙,但其實實用性一般,比較適合只能處理靜態shape的推理runtime。Encoder結構的padding問題還可以被同時期字節的EffectiveTransformer[3]的工作解決,可以只對Attention部分計算加pad,其他部分則把batch size和sequence length維度融合,不需要要padding。所以實際上,TurboTransformers開源Repo實現了兩種Batch Padding方法,如果模型是黑盒不能改就用動態規劃padding,如果模型是白盒可以改動則用類EffectiveTransformer的方法。
當時,我所在的團隊線上業務的主流encoder-only和encoder-decoder類Transformer架構。當時好像WeChat AI只有Decoder-only的GPT做文本生成,他們組后來在ChatGPT爆火前弄了WeLM。
TurboTransformers算是比較早期指出輸入變長需要新的Batching方法的論文。在2020年上半年,我開始思考如何把變長輸入Batching方法擴展到Decoder架構中。當時,我深受RNN Batching方法BatchMaker的啟發,認為可以將其應用于Transformer-Decoder模型中。BatchMaker也是ORCA論文中最主要的相關工作之一,對其進行了詳細的介紹。說來也巧,BatchMaker的第一作者Pin Gao正是我在清華高性能所隔壁實驗室的學長。BatchMaker是他在2018年訪問紐約大學期間發表的一篇EuroSys論文,論文剛出來就關注過。更巧的是,當時他也在WXG的做圖神經網絡的團隊,我還和他說可以把他的論文想法套到Transformer推理中。
正當我躍躍欲試之際,突然臨時接了項目,20年下半年我在做微信輸入法的封閉開發。顯然,微信鍵盤更能讓NLP技術普惠人民群眾,所以那個想法擱置了。21年一整年我的關注點轉移到大模型訓練上面,做了PatrickStar[4]工作。BatchMaker+Tranformer Decoder的想法也是我的一個未了心結。
在2022年的某一天,當我在Google Scholar的推薦論文中看到ORCA時,我眼前一亮,因為這不就是當年我想實現的那個點子嗎?系統研究知易行難,總是有很多好的點子,但要真正將它們付諸實踐,還是非常難的。ORCA的完成度非常高,假設我去做,是做不出OSDI水平工作的。不過ORCA也真是趕上了好時代,LLM爆火讓大家非常關心推理性能,否則如果Encoder時代沒有結束,ORCA很可能和BatchMaker一樣被長期埋沒。
這就是我在Pre-LLM時代做推理框架的往事,下面進入本文正題,Continous Batching。
很多人是從23年6月份AnyScale的博客[5]的這幅圖了解Continous Batching的,以至于很多講Continous Batching技術的PPT或公眾號都默認引用這幅圖。再次證明一圖勝千言,ORCA論文里那么多灰頭土臉的設計圖都不如這張圖讓人一目了然。正是因為vLLM和AnyScale這些伯克利大佬們管它叫Continous Batching,Continous Batching也成為中文世界的默認稱法。雖然,來自首爾大學的OCRA團隊稱之為Iteration batching。韓國人的工作命名權也只能掌握在美國人手里里,背后也反映MLSys的美國中心主義。順便說一下,OCRA的團隊也創立了一個PaaS創業公司FriendliAI,做大模型推理PaaS服務。
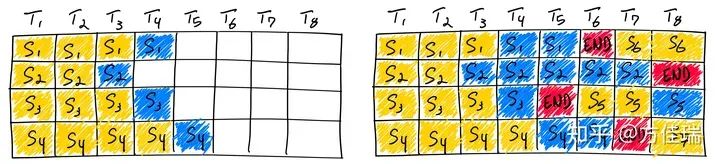
咱們還是先從RNN時代的Batching方法BatchMaker講起。
BatchMaker:Low Latency RNN Inference with Cellular Batching
BatchMaker是一個為RNNs設計的serving系統,它以RNN Cell為粒度進行調度和Batching。RNN使用相同權重對不同輸入進行計算。當收到請求時,BatchMaker將用于處理請求的數據流圖分解為RNN Cell(即一個iteration step),并以Cell的粒度進行執行調度,并批處理相同的單元執行。由于每個RNN Cell始終執行完全相同的計算,BatchMaker可以無論單元的位置(即標記索引)如何,都以Batching方式執行多個RNN Cell。通過這樣做,BatchMaker允許新到達的RNN請求加入(或已完成的請求離開)當前執行的批次,而無需等待批次完全完成。

看下圖可知,Cellular Batching方法已經和Continous Batching很相似了。
ORCA:更適合Transformer寶寶體質的Batching方法
ORCA借鑒BatchMaker方法,將它適配到Transformer Decoder生成過程。雖然Transformer Decoder和RNN在生成過程中都是逐個token地迭代生成,但它們之間存在一些本質區別。
1. 首先,Transformer Decoding階段每個迭代時,將當前token和之前生成的token序列拼接起來傳入模型。盡管每次只生成一個token,計算量近似,但每個迭代的KVCache的長度會逐漸增加。
2. 其次,Decoder在進行解碼時需要進行Prefill過程,這是RNN沒有的。Prefill計算是一堆token一起算,和Decoding階段計算模式截然不同。前者是計算密集,后者是訪存密集。
為了解決這些問題,OCRA提出了兩個設計思路:Iteration-level Batching和Selective Batching。Iteration-level Batching可以看作是對BatchMaker Cell粒度處理思想的一種致敬,而Selective Batching則是針對Transformer的獨特處理,以支持在batch size和input sequence這兩個維度動態變化對Batching執行的影響。
由于Attention機制和FNN的Batching方式不同。Linear層可以將batch size和seq_len這兩個維度融合為一個維度,類似于我前文提到的Efficient Transformer的思想,而Attention則不行。因此,一個Transformer Layer可以劃分為PreAttn、Attn和PostAttn三個部分。從而支持prefill階段和decoding一個step打成一個batch處理。如下圖所示,QKV Linear和Attn Out Linear打成一個batch size=7。Attn的計算沒有打Batch,每個request單獨處理。所以在Attn前后有Split和Merge操作。
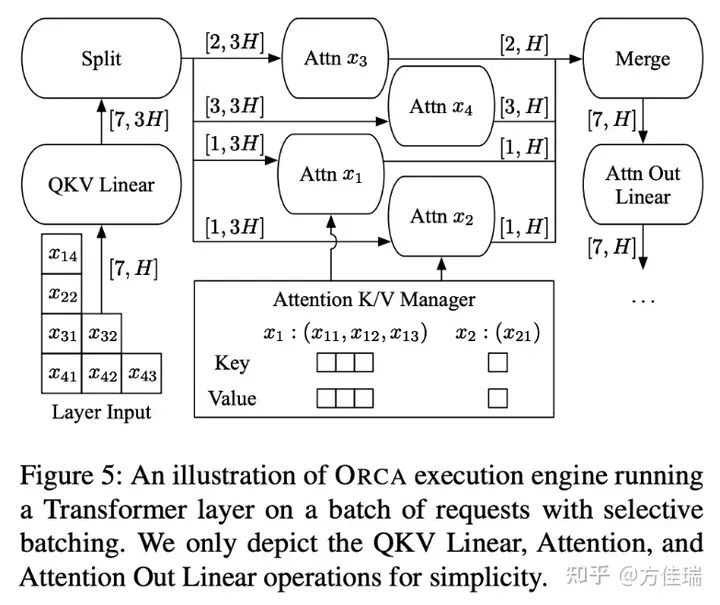
OCRA還沒考慮KVCache內存管理優化,它每個序列預先分配max token數的作為KVCache顯存空間。OCRA的實驗都是按照max token來生成,不會考慮遇到eos的情況。
2023年更多Continuous Batching的變種
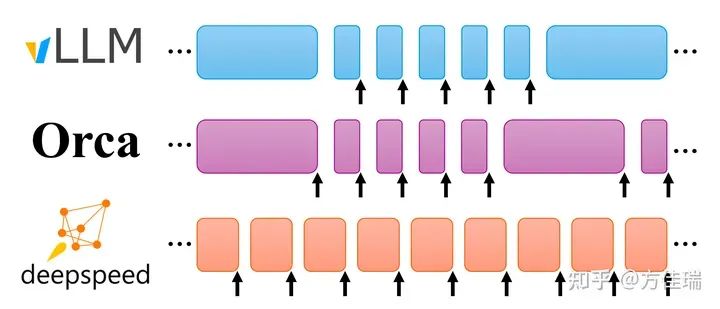
2023年Continous Batching迎來了大發展,在vLLM推動下已成為推理框架事實標準。不同框架實現有差別,主要體現在對prefill處理的方式上。將prefill單獨處理還是和decoding融合,以什么樣的粒度融合,有一些講究。
1. vLLM(UC Berkeley)
SOSP 2023的論文vLLM,也是熱門開源項目,其創新點paged attn(PA),減少內存碎片,增加memory efficiency,增大batch size從而增加吞吐。Batching策略是為PA設計服務的,所以沒有照搬OCRA的實現。
和ORCA不同之處在于,vLLM Batching時候prefill和decoding是分開的,一個Batching step要么處理decoding要么處理prefill。這樣實現比OCRA更簡單了,prefill直接調用xformers處理計算密集的prefill attn計算;decoding手寫CUDA PA處理訪存密集的attn計算。
我覺得vLLM之所以沒有采用OCRA設計,是因為vLLM的PA是手寫CUDA Kernel實現的,可以處理sequence長度不同的輸入,Attn的Batching方式可以和Non-Attn部分統一。因此,一個糙快猛方法是不采用Selective Batching的設計了,所Decoding整體一起處理一個Batch的step計算,prefill不和decoding step融合。如果把prefill計算和一個decoding step融合,則還需要拆分Attn和Non-Attn了,Attn實現也更更復雜了,不利于展示PA的思想。
不過因為Prefill過程會搶占decoding的step前進,如果輸入prompt sequence length過長,所有decoding過程都需要等待,造成大家更長的延遲,因此留下了一些優化空間,這后來這也造成了和DeepSpeed的一段孽緣。
2. FastGen(deepspeed)
微軟DeepSpeed團隊2023年11月在MII項目中提出了一種Continous Batching變種SplitFuse,在發布時把vLLM當靶子打,vLLM隨后還擊[6],逐漸演化成成為兩個大門派的口水戰。
SplitFuse的想法是,對長prompt request被分解成更小的塊,并在多個forward step中進行調度,只有最后一塊的forward完成后才開始這個prompt request的生成。對短prompt request將被組合以精確填充step的空隙。每個step的計算量基本相等,達到所有請求平均延遲更穩定的目的
3. LightLLM
這是商湯發布的pythonic LLM serving框架,簡單高效,易于二次開發,和其他框架的集成。和vLLM不同,它的prefill和decoding可以在一個step中打包成一個Batch處理,算是OCRA的原教旨主義者。同時,它改進了PagedAttention,弄成tokenAttn,也就是pagedattn的page size=1,也支持了FastGen的SpliteFuse方法。
4. TensorRT-LLM
TensorRT也用了Continous Batching,它們叫Inflight Batching。這個模塊是閉源的,不過它們也是把prefill和decoding step融合,更像OCRA而不是vLLM。
總結
Continous Batching這一大模型推理關鍵技術,并不是從石頭縫里蹦出來的,其思想來源于Pin Gao對RNN Batching的研究BatchMaker。目前不同大模型框架對Continous Batching實現略有差異,主要體現在如何處理prefill負載上。
審核編輯:黃飛









 工商網監
工商網監
評論