 電子發(fā)燒友App
電子發(fā)燒友App


目前,AIGC(AI-Generated Content,人工智能生產(chǎn)內(nèi)容)發(fā)展迅猛,選代速度呈現(xiàn)指數(shù)級(jí)增長(zhǎng),全球范圍內(nèi)經(jīng)濟(jì)價(jià)值預(yù)計(jì)將達(dá)到數(shù)萬(wàn)億美元。在中國(guó)市場(chǎng),AIGC的應(yīng)用規(guī)模有望在2025年突破2000億元,這一巨大的潛力吸引著業(yè)內(nèi)領(lǐng)軍企業(yè)競(jìng)相推出千億、萬(wàn)億級(jí)參數(shù)量的大模型,底層GPU算力部署規(guī)模也達(dá)到萬(wàn)卡級(jí)別。以GPT3.5為例,參數(shù)規(guī)模達(dá)1750億,作為訓(xùn)練數(shù)據(jù)集的互聯(lián)網(wǎng)文本量也超過(guò)45TB,其訓(xùn)練過(guò)程依賴于微軟專門建設(shè)的AI超算系統(tǒng),以及由1萬(wàn)顆V100GPU組成的高性能網(wǎng)絡(luò)集群,總計(jì)算力消耗約為3640PF-days(即每秒一千萬(wàn)億次計(jì)算,運(yùn)行3640天)。
分布式并行計(jì)算是實(shí)現(xiàn)AI大模型訓(xùn)練的關(guān)鍵手段,通常包含數(shù)據(jù)并行、流水線并行及張量并行等多種并行計(jì)算模式。所有并行模式均需要多個(gè)計(jì)算設(shè)備間進(jìn)行多次集合通信操作。另外,訓(xùn)練過(guò)程中通常采用同步模式,多機(jī)多卡間完成集合通信操作后才可進(jìn)行訓(xùn)練的下一輪迭代或計(jì)算。
Transformer 是 Google 的團(tuán)隊(duì)在 2017 年提出的一種 NLP 經(jīng)典模型,現(xiàn)在比較火熱的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 機(jī)制,不采用 RNN 的順序結(jié)構(gòu),使得模型可以并行化訓(xùn)練,而且能夠擁有全局信息。
Transformer模型實(shí)在論文《Attention Is All You Need》里面提出來(lái)的,用來(lái)生成文本的上下文編碼,傳統(tǒng)的上下問(wèn)編碼大多數(shù)是由RNN來(lái)完成的,不過(guò),RNN存在兩個(gè)缺點(diǎn):
a、計(jì)算是順序進(jìn)行的,無(wú)法并行化,例如:對(duì)于一個(gè)有10個(gè)單詞的文本序列,如果我們要得到最后一個(gè)單詞的處理結(jié)果,就必須要先計(jì)算前面9個(gè)單詞的處理結(jié)果。
b、RNN是順序計(jì)算,存在信息的衰減,所以很難處理相隔比較遠(yuǎn)的兩個(gè)單詞之間的信息,因此,RNN通常和attention相結(jié)合使用。 ? ?
針對(duì)RNN的缺陷,《Attention Is All You Need》提出了Transformer模型解決這個(gè)問(wèn)題。Transformer由多頭注意力、位置編碼、層歸一化和位置前向神經(jīng)網(wǎng)絡(luò)等部分構(gòu)成。
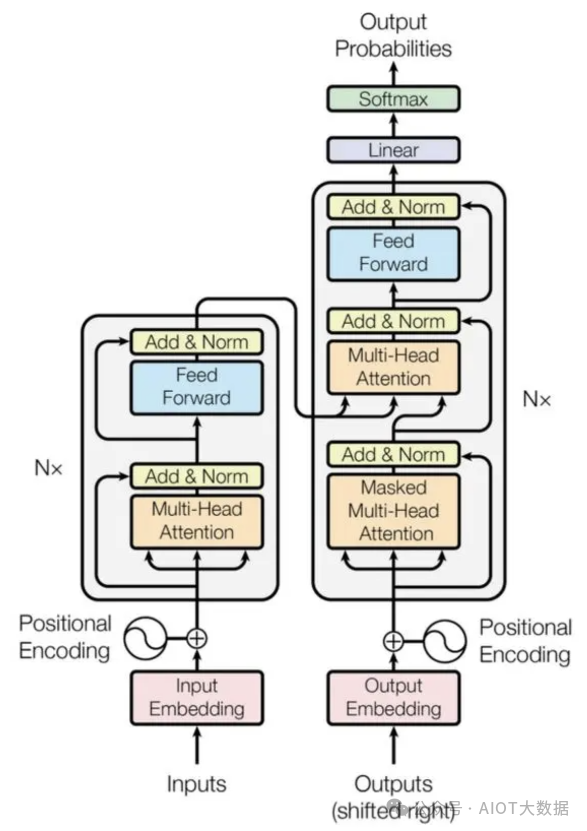
Transormer和seq2seq模型一樣,由Encoder和Decoder兩大部分組成,其中左側(cè)的是Encoder,右側(cè)的是Decoder。模型主要由多頭注意力和前饋神經(jīng)網(wǎng)絡(luò)組成。 ? ?
這里有個(gè)關(guān)鍵的點(diǎn)--位置編碼。使用RNN的進(jìn)行處理的時(shí)候,每個(gè)輸入天然存在位置屬性,但這也是RNN的弊端之一。文本單詞的排列與文本的語(yǔ)義有很大的關(guān)聯(lián),所以文本的位置是一個(gè)很重要的特征,因此,在Transformer模型里面,加入了位置編碼來(lái)保留單詞的位置信息。
編碼部分:Encoder
a、多頭注意力
多頭注意力是Transformer模型的重要組成部分,通過(guò)下面的圖,我們來(lái)看看多頭注意力的結(jié)構(gòu)。

多頭注意力是self-attention(自注意力)的拓展,對(duì)與self-attention不熟悉,可以參考self-attention詳解 ,相對(duì)于self-attention,多頭注意力再兩個(gè)方面有所提高:
擴(kuò)展了模型在文本序列不同位置的注意力能力。相對(duì)于self-attention,self-attention的最終輸出中,包含了其他詞的很少信息,其注意力權(quán)重主要由詞語(yǔ)本身即query占主導(dǎo)位置。
賦予attention多種子表達(dá)方式。使用多頭注意力機(jī)制,我們會(huì)有多組的Q、K、V參數(shù)矩陣(Transformer使用了8個(gè)heads,所以會(huì)有8組參數(shù)矩陣)。 ? ?
1. Transformer 結(jié)構(gòu)
首先介紹 Transformer 的整體結(jié)構(gòu),下圖是 Transformer 用于中英文翻譯的整體結(jié)構(gòu)。
Transformer 整體結(jié)構(gòu)
可以看到 Transformer 由 Encoder 和 Decoder 兩個(gè)部分組成,Encoder 和 Decoder 都包含 6 個(gè) block。Transformer 的工作流程大體如下:
第一步:獲取輸入句子的每一個(gè)單詞的表示向量?X,X由單詞的 Embedding 和單詞位置的 Embedding 相加得到。 ? ?
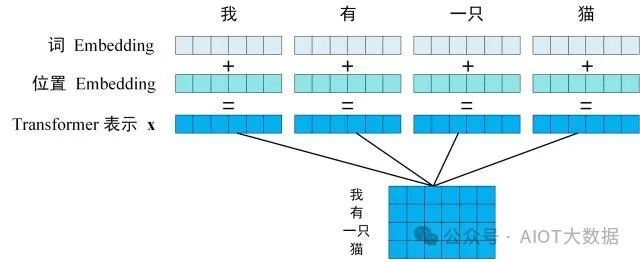
Transformer 的輸入表示
第二步:將得到的單詞表示向量矩陣 (如上圖所示,每一行是一個(gè)單詞的表示?x) 傳入 Encoder 中,經(jīng)過(guò) 6 個(gè) Encoder block 后可以得到句子所有單詞的編碼信息矩陣?C,如下圖。單詞向量矩陣用?X(n×d)表示, n 是句子中單詞個(gè)數(shù),d 是表示向量的維度 (論文中 d=512)。每一個(gè) Encoder block 輸出的矩陣維度與輸入完全一致。 ? ?
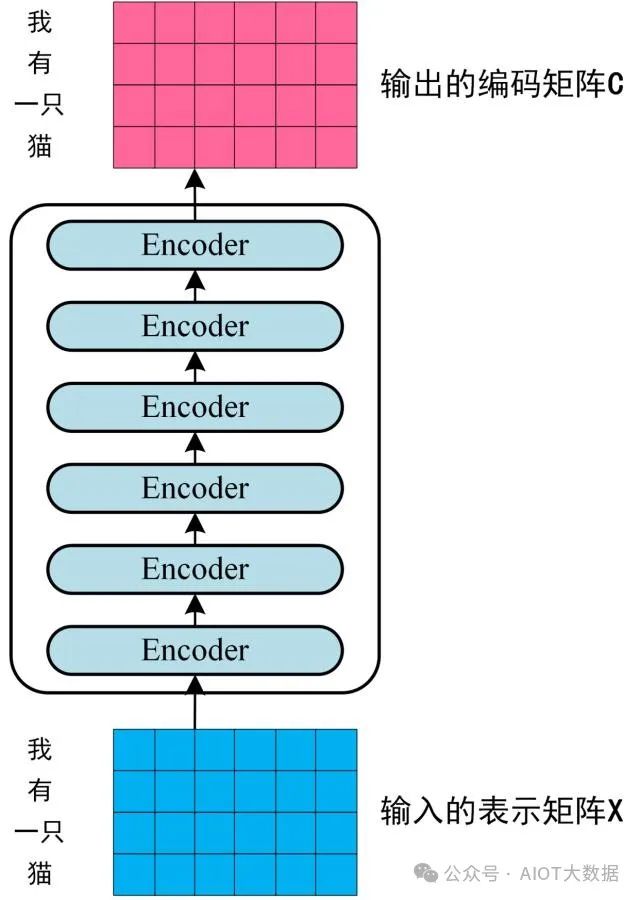
Transformer Encoder 編碼句子信息
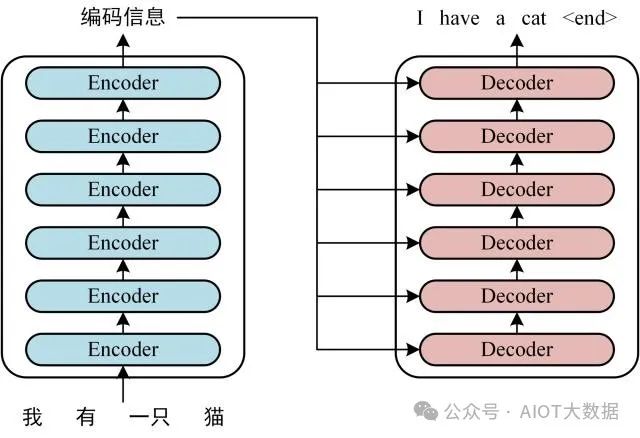
第三步:將 Encoder 輸出的編碼信息矩陣?C傳遞到 Decoder 中,Decoder 依次會(huì)根據(jù)當(dāng)前翻譯過(guò)的單詞 1~ i 翻譯下一個(gè)單詞 i+1,如下圖所示。在使用的過(guò)程中,翻譯到單詞 i+1 的時(shí)候需要通過(guò)?Mask (掩蓋)?操作遮蓋住 i+1 之后的單詞。 ? ?
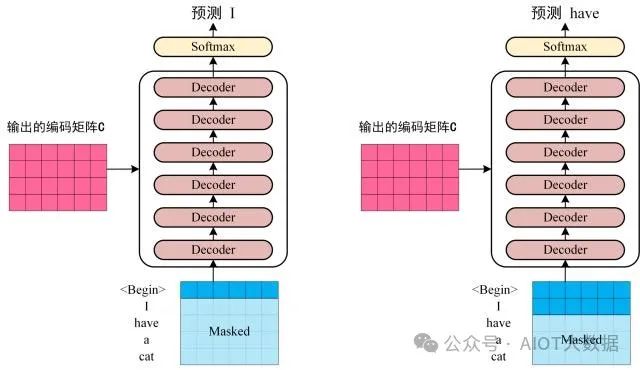
Transofrmer Decoder 預(yù)測(cè)
上圖 Decoder 接收了 Encoder 的編碼矩陣?C,然后首先輸入一個(gè)翻譯開(kāi)始符 "",預(yù)測(cè)第一個(gè)單詞 "I";然后輸入翻譯開(kāi)始符 "" 和單詞 "I",預(yù)測(cè)單詞 "have",以此類推。這是 Transformer 使用時(shí)候的大致流程,接下來(lái)是里面各個(gè)部分的細(xì)節(jié)。
2. Transformer 的輸入
Transformer 中單詞的輸入表示?x由單詞 Embedding 和位置 Embedding 相加得到。
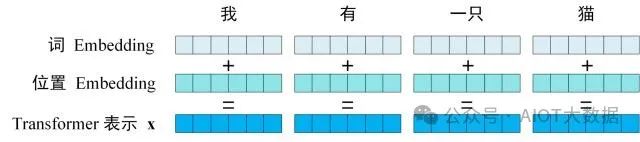
Transformer 的輸入表示
2.1 單詞 Embedding
單詞的 Embedding 有很多種方式可以獲取,例如可以采用 Word2Vec、Glove 等算法預(yù)訓(xùn)練得到,也可以在 Transformer 中訓(xùn)練得到。 ? ?
2.2 位置 Embedding
Transformer 中除了單詞的 Embedding,還需要使用位置 Embedding 表示單詞出現(xiàn)在句子中的位置。因?yàn)?Transformer 不采用 RNN 的結(jié)構(gòu),而是使用全局信息,不能利用單詞的順序信息,而這部分信息對(duì)于 NLP 來(lái)說(shuō)非常重要。所以 Transformer 中使用位置 Embedding 保存單詞在序列中的相對(duì)或絕對(duì)位置。
位置 Embedding 用?PE表示,PE?的維度與單詞 Embedding 是一樣的。PE?可以通過(guò)訓(xùn)練得到,也可以使用某種公式計(jì)算得到。在 Transformer 中采用了后者,計(jì)算公式如下:
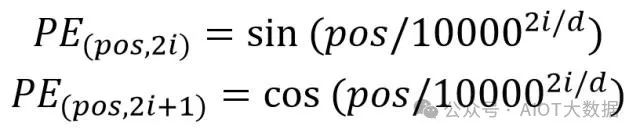
其中,pos 表示單詞在句子中的位置,d 表示?PE的維度 (與詞 Embedding 一樣),2i 表示偶數(shù)的維度,2i+1 表示奇數(shù)維度 (即 2i≤d, 2i+1≤d)。使用這種公式計(jì)算?PE?有以下的好處:
使?PE?能夠適應(yīng)比訓(xùn)練集里面所有句子更長(zhǎng)的句子,假設(shè)訓(xùn)練集里面最長(zhǎng)的句子是有 20 個(gè)單詞,突然來(lái)了一個(gè)長(zhǎng)度為 21 的句子,則使用公式計(jì)算的方法可以計(jì)算出第 21 位的 Embedding。可以讓模型容易地計(jì)算出相對(duì)位置,對(duì)于固定長(zhǎng)度的間距 k,PE(pos+k) 可以用?PE(pos) 計(jì)算得到。因?yàn)?Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。將單詞的詞 Embedding 和位置 Embedding 相加,就可以得到單詞的表示向量?x,x?就是 Transformer 的輸入。
3. Self-Attention ? ?
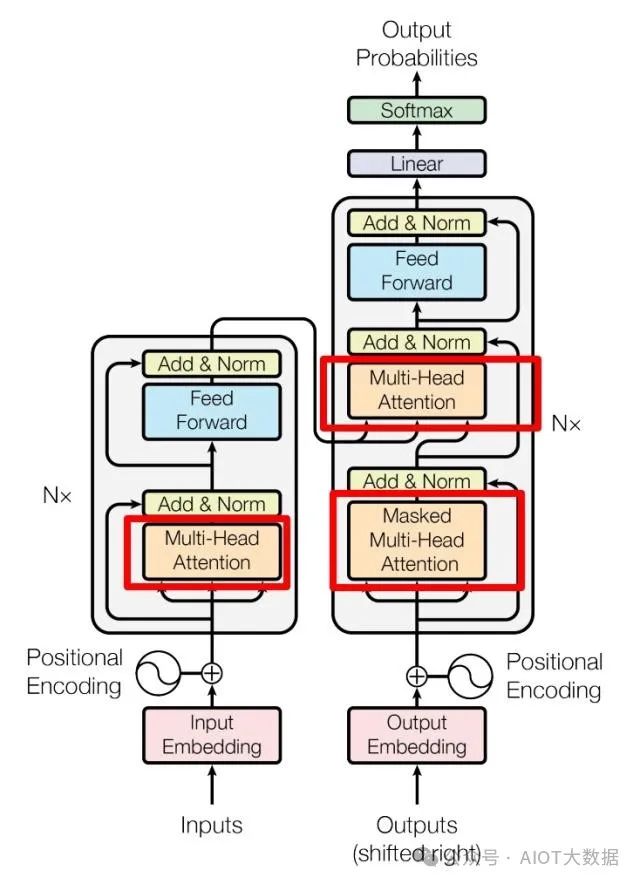
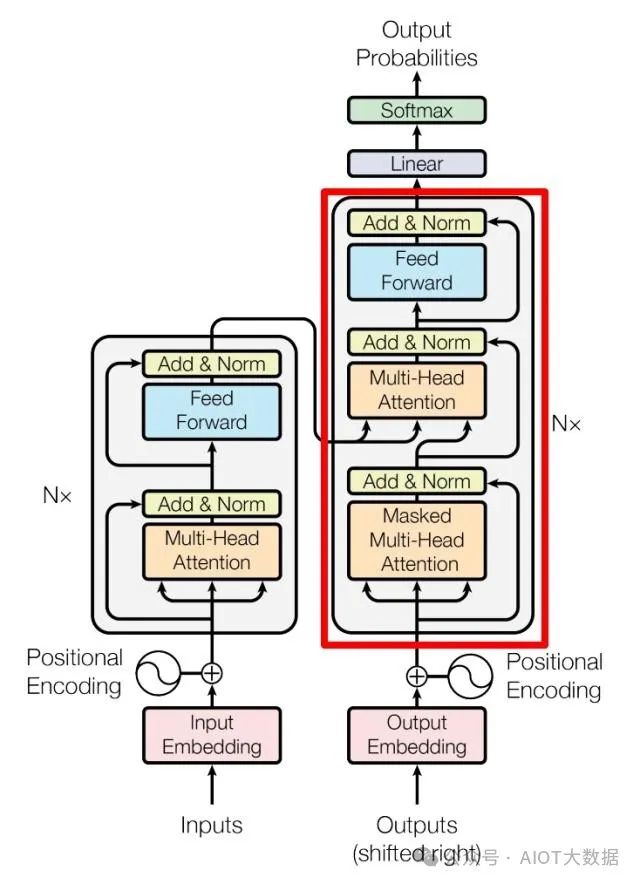
Transformer Encoder 和 Decoder
上圖是論文中 Transformer 的內(nèi)部結(jié)構(gòu)圖,左側(cè)為 Encoder block,右側(cè)為 Decoder block。紅色圈中的部分為?Multi-Head Attention,是由多個(gè)?Self-Attention組成的,可以看到 Encoder block 包含一個(gè) Multi-Head Attention,而 Decoder block 包含兩個(gè) Multi-Head Attention (其中有一個(gè)用到 Masked)。Multi-Head Attention 上方還包括一個(gè) Add & Norm 層,Add 表示殘差連接 (Residual Connection) 用于防止網(wǎng)絡(luò)退化,Norm 表示 Layer Normalization,用于對(duì)每一層的激活值進(jìn)行歸一化。 ? ?
因?yàn)?Self-Attention是 Transformer 的重點(diǎn),所以我們重點(diǎn)關(guān)注 Multi-Head Attention 以及 Self-Attention,首先詳細(xì)了解一下 Self-Attention 的內(nèi)部邏輯。
3.1 Self-Attention 結(jié)構(gòu)
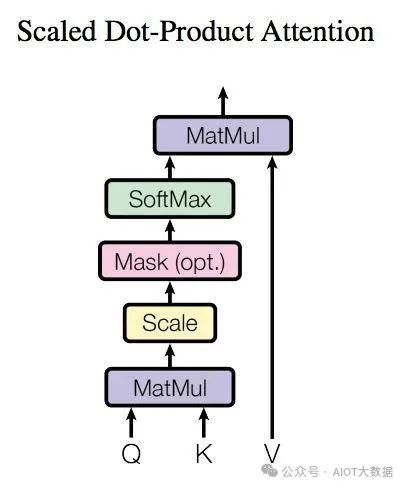
Self-Attention 結(jié)構(gòu)
上圖是 Self-Attention 的結(jié)構(gòu),在計(jì)算的時(shí)候需要用到矩陣?Q(查詢),?K(鍵值),?V(值)。在實(shí)際中,Self-Attention 接收的是輸入(單詞的表示向量?x組成的矩陣?X) 或者上一個(gè) Encoder block 的輸出。而?Q,?K,?V?正是通過(guò) Self-Attention 的輸入進(jìn)行線性變換得到的。 ? ?
3.2 Q, K, V 的計(jì)算
Self-Attention 的輸入用矩陣?X進(jìn)行表示,則可以使用線性變陣矩陣?WQ,?WK,?WV?計(jì)算得到?Q,?K,?V。計(jì)算如下圖所示,注意 X, Q, K, V 的每一行都表示一個(gè)單詞。
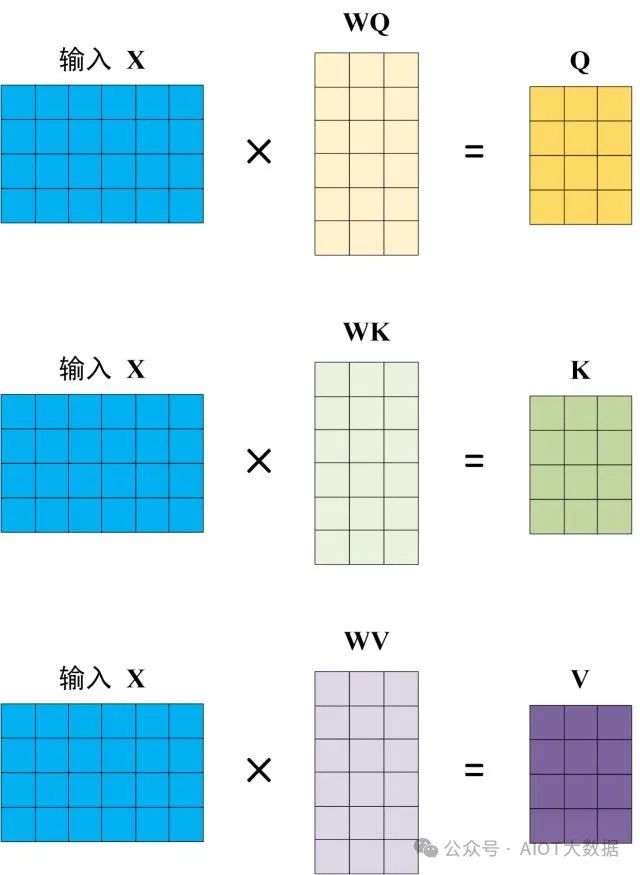
Q, K, V 的計(jì)算 ? ?
3.3 Self-Attention 的輸出
得到矩陣?Q,?K,?V之后就可以計(jì)算出 Self-Attention 的輸出了,計(jì)算的公式如下。

Self-Attention 的輸出
公式中計(jì)算矩陣?Q和?K?每一行向量的內(nèi)積,為了防止內(nèi)積過(guò)大,因此除以 dk 的平方根。Q?乘以?K?的轉(zhuǎn)置后,得到的矩陣行列數(shù)都為 n,n 為句子單詞數(shù),這個(gè)矩陣可以表示單詞之間的 attention 強(qiáng)度。下圖為?Q?乘以?K?的轉(zhuǎn)置,1234 表示的是句子中的單詞。
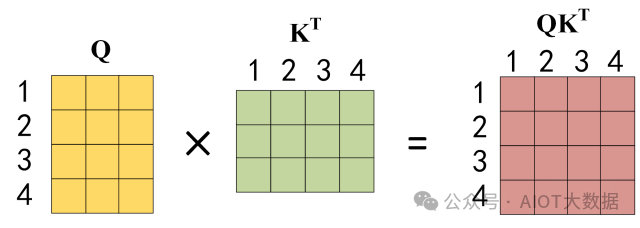
QKT 的計(jì)算
得到?QKT 之后,使用 Softmax 計(jì)算每一個(gè)單詞對(duì)于其他單詞的 attention 系數(shù),公式中的 Softmax 是對(duì)矩陣的每一行進(jìn)行 Softmax,即每一行的和都變?yōu)?1。 ? ?
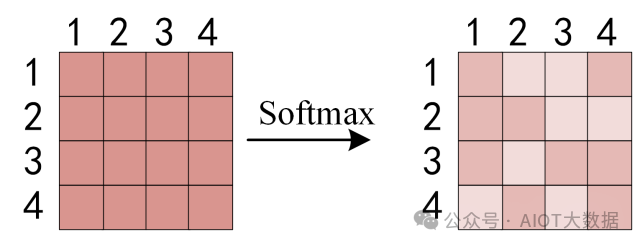
對(duì)矩陣的每一行進(jìn)行 Softmax
得到 Softmax 矩陣之后可以和?V相乘,得到最終的輸出?Z。
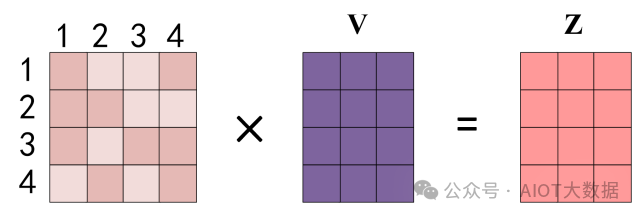
Self-Attention 輸出
上圖中 Softmax 矩陣的第 1 行表示單詞 1 與其他所有單詞的 attention 系數(shù),最終單詞 1 的輸出?Z1 等于所有單詞 i 的值?Vi 根據(jù) attention 系數(shù)的比例加在一起得到,如下圖所示:
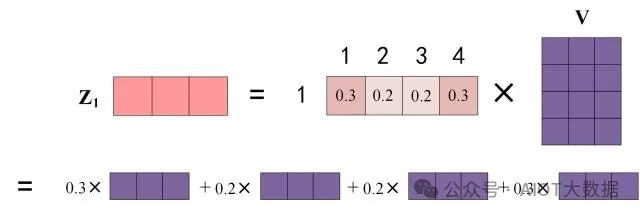
Zi 的計(jì)算方法 ? ?
3.4 Multi-Head Attention
在上一步,我們已經(jīng)知道怎么通過(guò) Self-Attention 計(jì)算得到輸出矩陣?Z,而 Multi-Head Attention 是由多個(gè) Self-Attention 組合形成的,下圖是論文中 Multi-Head Attention 的結(jié)構(gòu)圖。
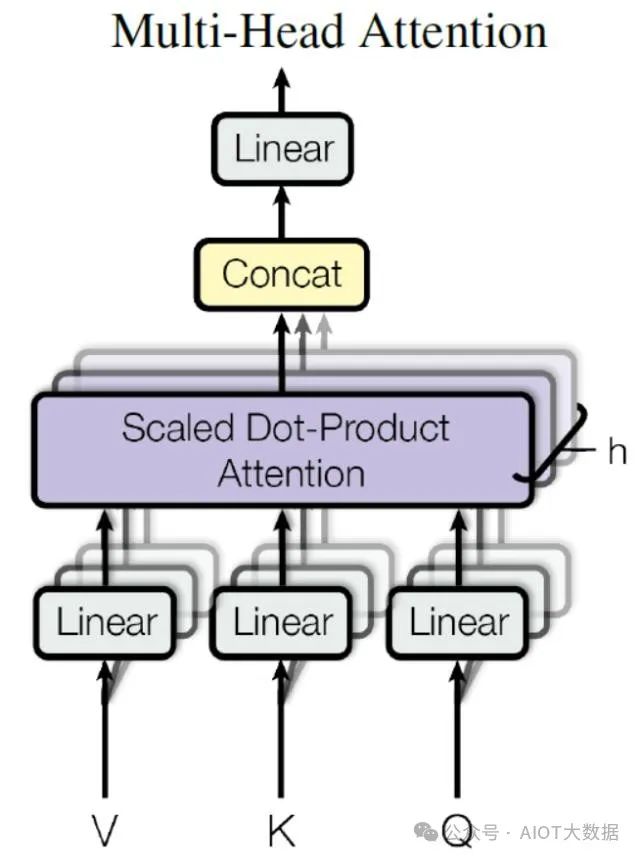
Multi-Head Attention ? ?
從上圖可以看到 Multi-Head Attention 包含多個(gè) Self-Attention 層,首先將輸入?X分別傳遞到 h 個(gè)不同的 Self-Attention 中,計(jì)算得到 h 個(gè)輸出矩陣?Z。下圖是 h=8 時(shí)候的情況,此時(shí)會(huì)得到 8 個(gè)輸出矩陣?Z。
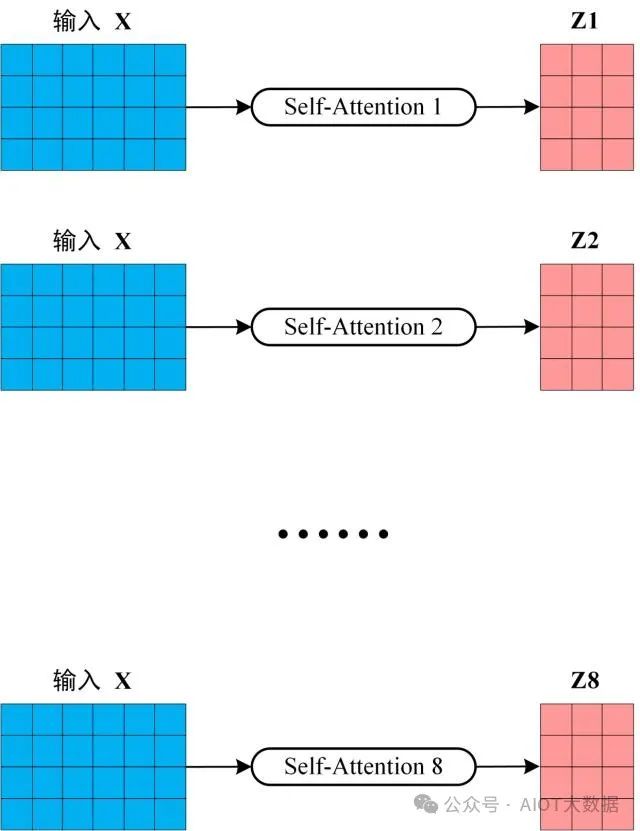
多個(gè) Self-Attention ? ?
得到 8 個(gè)輸出矩陣?Z1 到?Z8 之后,Multi-Head Attention 將它們拼接在一起 (Concat),然后傳入一個(gè)?Linear層,得到 Multi-Head Attention 最終的輸出?Z。
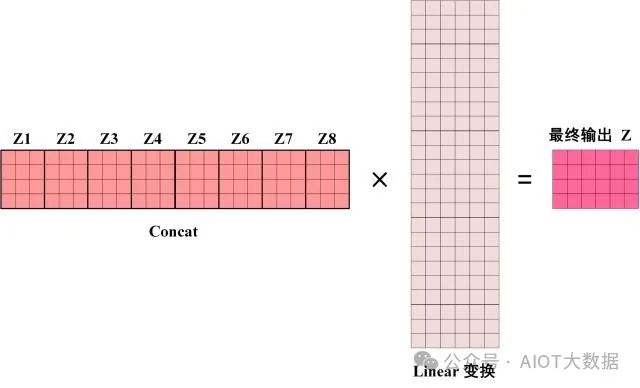
Multi-Head Attention 的輸出
可以看到 Multi-Head Attention 輸出的矩陣?Z與其輸入的矩陣?X?的維度是一樣的。
4. Encoder 結(jié)構(gòu) ? ?

Transformer Encoder block
上圖紅色部分是 Transformer 的 Encoder block 結(jié)構(gòu),可以看到是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 組成的。剛剛已經(jīng)了解了 Multi-Head Attention 的計(jì)算過(guò)程,現(xiàn)在了解一下 Add & Norm 和 Feed Forward 部分。 ? ?
4.1 Add & Norm
Add & Norm 層由 Add 和 Norm 兩部分組成,其計(jì)算公式如下:

Add & Norm 公式
其中?X表示 Multi-Head Attention 或者 Feed Forward 的輸入,MultiHeadAttention(X) 和 FeedForward(X) 表示輸出 (輸出與輸入?X?維度是一樣的,所以可以相加)。
Add指?X+MultiHeadAttention(X),是一種殘差連接,通常用于解決多層網(wǎng)絡(luò)訓(xùn)練的問(wèn)題,可以讓網(wǎng)絡(luò)只關(guān)注當(dāng)前差異的部分,在 ResNet 中經(jīng)常用到。

殘差連接
Norm指 Layer Normalization,通常用于 RNN 結(jié)構(gòu),Layer Normalization 會(huì)將每一層神經(jīng)元的輸入都轉(zhuǎn)成均值方差都一樣的,這樣可以加快收斂。
4.2 Feed Forward
Feed Forward 層比較簡(jiǎn)單,是一個(gè)兩層的全連接層,第一層的激活函數(shù)為 Relu,第二層不使用激活函數(shù),對(duì)應(yīng)的公式如下。
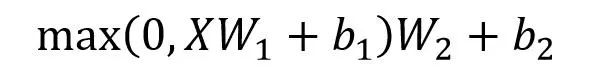
Feed Forward
X是輸入,F(xiàn)eed Forward 最終得到的輸出矩陣的維度與?X?一致。 ? ?
4.3 組成 Encoder
通過(guò)上面描述的 Multi-Head Attention, Feed Forward, Add & Norm 就可以構(gòu)造出一個(gè) Encoder block,Encoder block 接收輸入矩陣?X(n×d),并輸出一個(gè)矩陣?O(n×d)。通過(guò)多個(gè) Encoder block 疊加就可以組成 Encoder。
第一個(gè) Encoder block 的輸入為句子單詞的表示向量矩陣,后續(xù) Encoder block 的輸入是前一個(gè) Encoder block 的輸出,最后一個(gè) Encoder block 輸出的矩陣就是?編碼信息矩陣 C,這一矩陣后續(xù)會(huì)用到 Decoder 中。 ? ?
Encoder 編碼句子信息
5. Decoder 結(jié)構(gòu) ? ?
Transformer Decoder block
上圖紅色部分為 Transformer 的 Decoder block 結(jié)構(gòu),與 Encoder block 相似,但是存在一些區(qū)別:
包含兩個(gè) Multi-Head Attention 層。第一個(gè) Multi-Head Attention 層采用了 Masked 操作。第二個(gè) Multi-Head Attention 層的?K,?V?矩陣使用 Encoder 的編碼信息矩陣?C?進(jìn)行計(jì)算,而?Q?使用上一個(gè) Decoder block 的輸出計(jì)算。最后有一個(gè) Softmax 層計(jì)算下一個(gè)翻譯單詞的概率。5.1 第一個(gè) Multi-Head Attention ? ?
Decoder block 的第一個(gè) Multi-Head Attention 采用了 Masked 操作,因?yàn)樵诜g的過(guò)程中是順序翻譯的,即翻譯完第 i 個(gè)單詞,才可以翻譯第 i+1 個(gè)單詞。通過(guò) Masked 操作可以防止第 i 個(gè)單詞知道 i+1 個(gè)單詞之后的信息。下面以 "我有一只貓" 翻譯成 "I have a cat" 為例,了解一下 Masked 操作。
下面的描述中使用了類似 Teacher Forcing 的概念,不熟悉 Teacher Forcing 的童鞋可以參考以下上一篇文章Seq2Seq 模型詳解。在 Decoder 的時(shí)候,是需要根據(jù)之前的翻譯,求解當(dāng)前最有可能的翻譯,如下圖所示。首先根據(jù)輸入 "" 預(yù)測(cè)出第一個(gè)單詞為 "I",然后根據(jù)輸入 "I" 預(yù)測(cè)下一個(gè)單詞 "have"。

Decoder 預(yù)測(cè)
Decoder 可以在訓(xùn)練的過(guò)程中使用 Teacher Forcing 并且并行化訓(xùn)練,即將正確的單詞序列 (I have a cat) 和對(duì)應(yīng)輸出 (I have a cat) 傳遞到 Decoder。那么在預(yù)測(cè)第 i 個(gè)輸出時(shí),就要將第 i+1 之后的單詞掩蓋住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分別表示 "I have a cat"。
第一步:是 Decoder 的輸入矩陣和?Mask?矩陣,輸入矩陣包含 "I have a cat" (0, 1, 2, 3, 4) 五個(gè)單詞的表示向量,Mask?是一個(gè) 5×5 的矩陣。在?Mask?可以發(fā)現(xiàn)單詞 0 只能使用單詞 0 的信息,而單詞 1 可以使用單詞 0, 1 的信息,即只能使用之前的信息。 ? ?
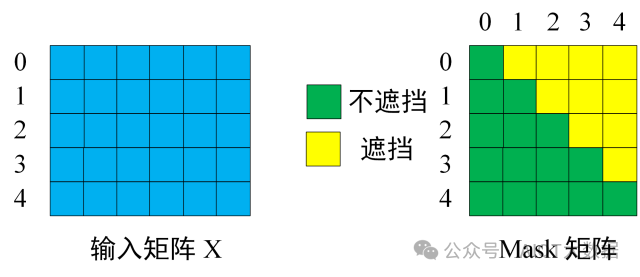
輸入矩陣與 Mask 矩陣
第二步:接下來(lái)的操作和之前的 Self-Attention 一樣,通過(guò)輸入矩陣?X計(jì)算得到?Q,?K,?V?矩陣。然后計(jì)算?Q?和?KT 的乘積?QKT。
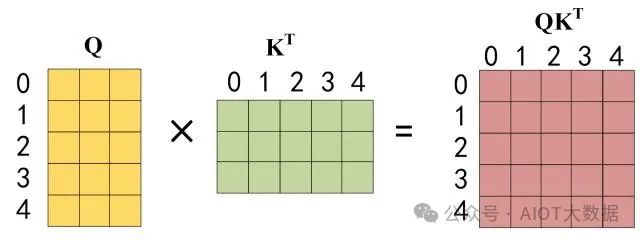
QKT
第三步:在得到?QKT 之后需要進(jìn)行 Softmax,計(jì)算 attention score,我們?cè)?Softmax 之前需要使用?Mask矩陣遮擋住每一個(gè)單詞之后的信息,遮擋操作如下:
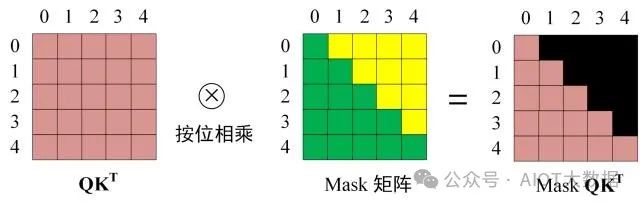
Softmax 之前 Mask ? ?
得到?Mask QKT 之后在?Mask QKT 上進(jìn)行 Softmax,每一行的和都為 1。但是單詞 0 在單詞 1, 2, 3, 4 上的 attention score 都為 0。
第四步:使用?Mask QKT 與矩陣?V相乘,得到輸出?Z,則單詞 1 的輸出向量?Z1 是只包含單詞 1 信息的。
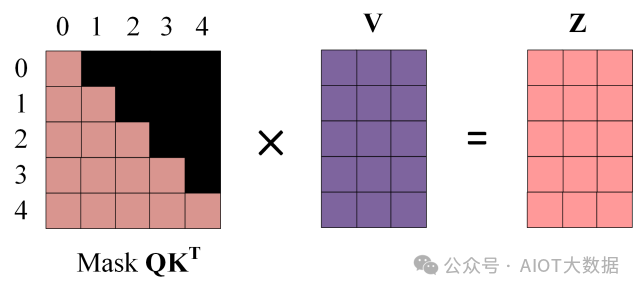
Mask 之后的輸出
第五步:通過(guò)上述步驟就可以得到一個(gè) Mask Self-Attention 的輸出矩陣?Zi,然后和 Encoder 類似,通過(guò) Multi-Head Attention 拼接多個(gè)輸出?Zi 然后計(jì)算得到第一個(gè) Multi-Head Attention 的輸出?Z,Z與輸入?X?維度一樣。
5.2 第二個(gè) Multi-Head Attention
Decoder block 第二個(gè) Multi-Head Attention 變化不大, 主要的區(qū)別在于其中 Self-Attention 的?K,?V矩陣不是使用 上一個(gè) Decoder block 的輸出計(jì)算的,而是使用?Encoder 的編碼信息矩陣 C?計(jì)算的。
根據(jù) Encoder 的輸出?C計(jì)算得到?K,?V,根據(jù)上一個(gè) Decoder block 的輸出?Z?計(jì)算?Q?(如果是第一個(gè) Decoder block 則使用輸入矩陣?X?進(jìn)行計(jì)算),后續(xù)的計(jì)算方法與之前描述的一致。
這樣做的好處是在 Decoder 的時(shí)候,每一位單詞都可以利用到 Encoder 所有單詞的信息 (這些信息無(wú)需 Mask)。 ? ?
5.3 Softmax 預(yù)測(cè)輸出單詞
Decoder block 最后的部分是利用 Softmax 預(yù)測(cè)下一個(gè)單詞,在之前的網(wǎng)絡(luò)層我們可以得到一個(gè)最終的輸出?Z,因?yàn)?Mask 的存在,使得單詞 0 的輸出?Z0 只包含單詞 0 的信息,如下。
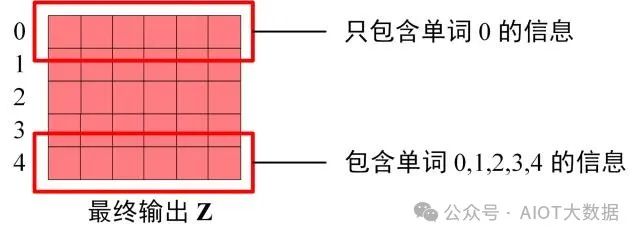
Decoder Softmax 之前的 Z
Softmax 根據(jù)輸出矩陣的每一行預(yù)測(cè)下一個(gè)單詞
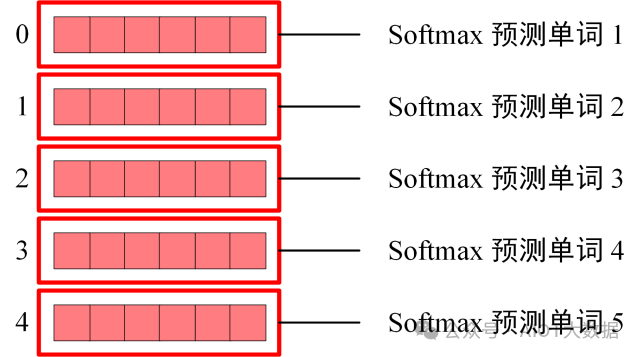
Decoder Softmax 預(yù)測(cè)
這就是 Decoder block 的定義,與 Encoder 一樣,Decoder 是由多個(gè) Decoder block 組合而成。 ? ?
6. Transformer 總結(jié)
Transformer 與 RNN 不同,可以比較好地并行訓(xùn)練。
Transformer 本身是不能利用單詞的順序信息的,因此需要在輸入中添加位置 Embedding,否則 Transformer 就是一個(gè)詞袋模型了。
Transformer 的重點(diǎn)是 Self-Attention 結(jié)構(gòu),其中用到的?Q,?K,?V矩陣通過(guò)輸出進(jìn)行線性變換得到。
Transformer 中 Multi-Head Attention 中有多個(gè) Self-Attention,可以捕獲單詞之間多種維度上的相關(guān)系數(shù) attention score。
參考文獻(xiàn)
論文:Attention Is All You NeedJay Alammar 博客:The Illustrated Transformerpytorch transformer 代碼:The Annotated Transformer
Attention是如何發(fā)揮作用的,其中的參數(shù)的含義和作用是什么,反向傳播算法如何更新其中參數(shù),又是如何影響其他參數(shù)的更新的?
為什么要用scaled attention?
Multi-head attention相比single head attention為什么更加work,其本質(zhì)上做了一件什么事?從反向傳播算法的角度分析?
Positional encoding是如何發(fā)揮作用的,應(yīng)用反向傳播算法時(shí)是如何影響到其他參數(shù)的更新的?同樣的理論可以延伸到其他additional embedding,比如多語(yǔ)言模型中的language embedding
每個(gè)encoder/decoder layer中feed-forward部分的作用,并且從反向傳播算法角度分析?
decoder中mask后反向傳播算法過(guò)程細(xì)節(jié),如何保證training和inference的一致性?
如果不一致(decoder不用mask)會(huì)怎么樣? ? ?
1. Attention的背景溯源
想要深度理解Attention機(jī)制,就需要了解一下它產(chǎn)生的背景、在哪類問(wèn)題下產(chǎn)生,以及最初是為了解決什么問(wèn)題而產(chǎn)生。
首先回顧一下機(jī)器翻譯領(lǐng)域的模型演進(jìn)歷史:
機(jī)器翻譯是從RNN開(kāi)始跨入神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯時(shí)代的,幾個(gè)比較重要的階段分別是: Simple RNN, Contextualize RNN,Contextualized RNN with attention, Transformer(2017),下面來(lái)一一介紹。
「Simple RNN」?:這個(gè)encoder-decoder模型結(jié)構(gòu)中,encoder將整個(gè)源端序列(不論長(zhǎng)度)壓縮成一個(gè)向量(encoder output),源端信息和decoder之間唯一的聯(lián)系只是: encoder output會(huì)作為decoder的initial states的輸入。這樣帶來(lái)一個(gè)顯而易見(jiàn)的問(wèn)題就是,隨著decoder長(zhǎng)度的增加,encoder output的信息會(huì)衰減。
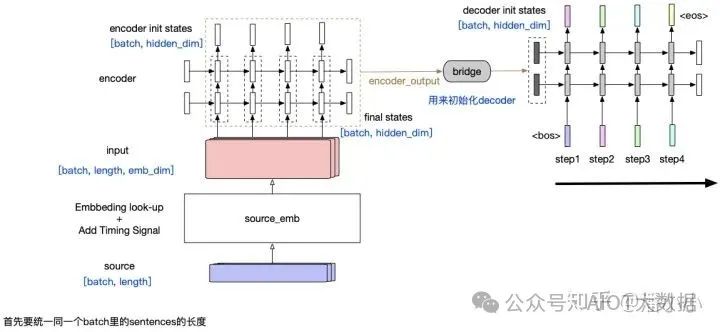
Simple RNN(without context)
這種模型有2個(gè)主要的問(wèn)題:
源端序列不論長(zhǎng)短,都被統(tǒng)一壓縮成一個(gè)固定維度的向量,并且顯而易見(jiàn)的是這個(gè)向量中包含的信息中,關(guān)于源端序列末尾的token的信息更多,而如果序列很長(zhǎng),最終可能基本上“遺忘”了序列開(kāi)頭的token的信息。 ? ?
第二個(gè)問(wèn)題同樣由RNN的特性造成: 隨著decoder timestep的信息的增加,initial hidden states中包含的encoder output相關(guān)信息也會(huì)衰減,decoder會(huì)逐漸“遺忘”源端序列的信息,而更多地關(guān)注目標(biāo)序列中在該timestep之前的token的信息。
「Contextualized RNN」?:為了解決上述第二個(gè)問(wèn)題,即encoder output隨著decoder timestep增加而信息衰減的問(wèn)題,有人提出了一種加了context的RNN sequence to sequence模型:decoder在每個(gè)timestep的input上都會(huì)加上一個(gè)context。為了方便理解,我們可以把這看作是encoded source sentence。這樣就可以在decoder的每一步,都把源端的整個(gè)句子的信息和target端當(dāng)前的token一起輸入到RNN中,防止源端的context信息隨著timestep的增長(zhǎng)而衰減。
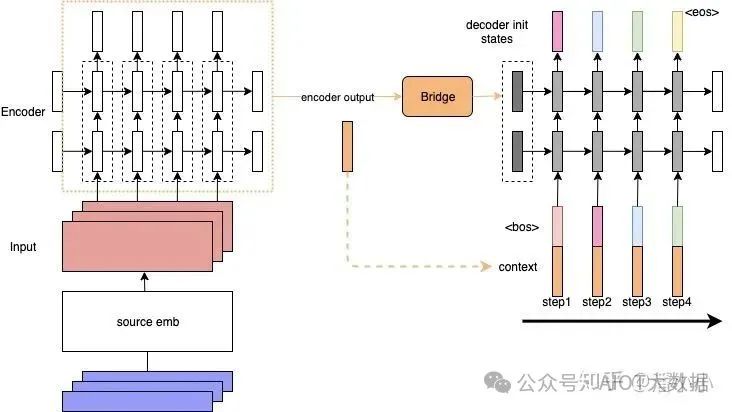
Contextualized RNN
但是這樣依然有一個(gè)問(wèn)題: context對(duì)于每個(gè)timestep都是靜態(tài)的(encoder端的final hiddenstates,或者是所有timestep的output的平均值)。但是每個(gè)decoder端的token在解碼時(shí)用到的context真的應(yīng)該是一樣的嗎?在這樣的背景下,Attention就應(yīng)運(yùn)而生了:
「Contextualized RNN with soft align (Attention)」?: Attention在機(jī)器翻譯領(lǐng)域的應(yīng)用最早的提出來(lái)自于2014年的一篇論文 ?Neural Machine Translation by Jointly Learning to Align and Translate ? ?
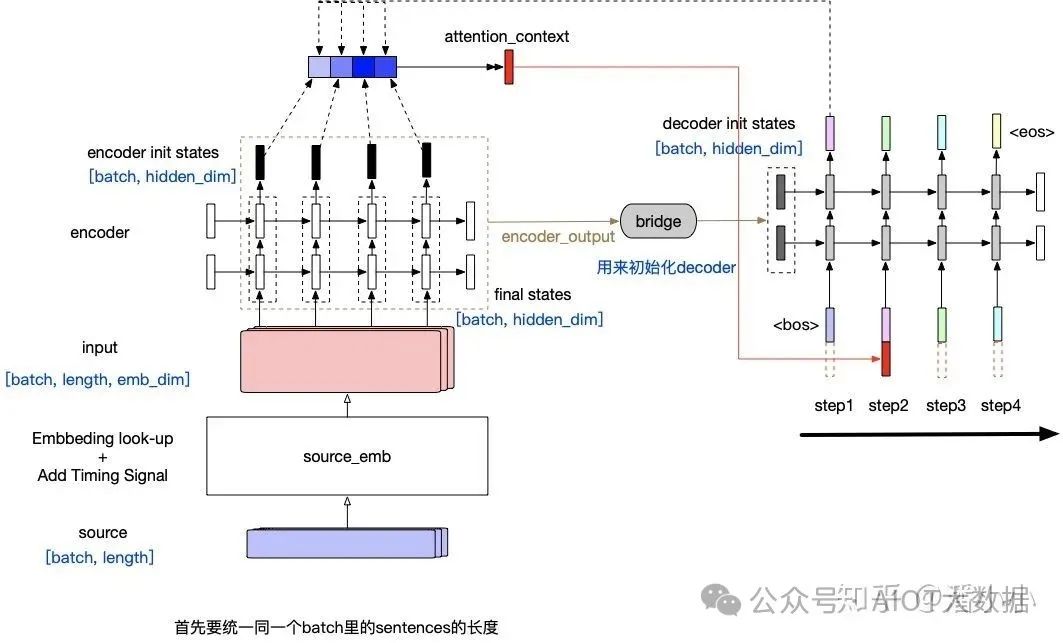
Contextualized RNN with Attention
在每個(gè)timestep輸入到decoder RNN結(jié)構(gòu)中之前,會(huì)用當(dāng)前的輸入token的vector與encoderoutput中的每一個(gè)position的vector作一個(gè)"attention"操作,這個(gè)"attention"操作的目的就是計(jì)算當(dāng)前token與每個(gè)position之間的"相關(guān)度",從而決定每個(gè)position的vector在最終該timestep的context中占的比重有多少。最終的context即encoderoutput每個(gè)位置vector表達(dá)的?「加權(quán)平均」?。
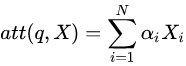 context的計(jì)算公式
context的計(jì)算公式
2. Attention的細(xì)節(jié)
2.1. 點(diǎn)積attention
我們來(lái)介紹一下attention的具體計(jì)算方式。attention可以有很多種計(jì)算方式:加性attention、點(diǎn)積attention,還有帶參數(shù)的計(jì)算方式。著重介紹一下點(diǎn)積attention的公式: ? ?
Attention中(Q^T)*K矩陣計(jì)算,query和key的維度要保持一致
如上圖所示, ???, ?分別是query和key,其中,query可以看作M個(gè)維度為d的向量(長(zhǎng)度為M的sequence的向量表達(dá))拼接而成,key可以看作N個(gè)維度為d的向量(長(zhǎng)度為N的sequence的向量表達(dá))拼接而成。
【一個(gè)小問(wèn)題】為什么有縮放因子 ????
先一句話回答這個(gè)問(wèn)題: 縮放因子的作用是?「歸一化」?。
假設(shè) ???, ???里的元素的均值為0,方差為1,那么 ???中元素的均值為0,方差為d. 當(dāng)d變得很大時(shí), ???中的元素的方差也會(huì)變得很大,如果 ???中的元素方差很大,那么 ???的分布會(huì)趨于陡峭(分布的方差大,分布集中在絕對(duì)值大的區(qū)域)。總結(jié)一下就是 ???的分布會(huì)和d有關(guān)。因此 ???中每一個(gè)元素乘上 ???后,方差又變?yōu)?。這使得 ???的分布“陡峭”程度與d解耦,從而使得訓(xùn)練過(guò)程中梯度值保持穩(wěn)定。
2.2. Attention機(jī)制涉及到的參數(shù)
一個(gè)完整的attention層涉及到的參數(shù)有:
把 ???, ???, ???分別映射到 ???, ???, ???的線性變換矩陣 ???( ???), ???( ???), ???( ???) ? ?
把輸出的表達(dá) ???映射為最終輸出 ???的線性變換矩陣 ???( ???)
2.3. Query, Key, Value
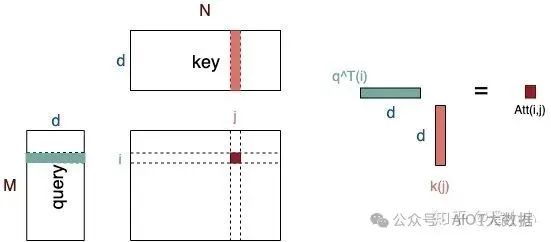
Query和Key作用得到的attention權(quán)值作用到Value上。因此它們之間的關(guān)系是:
Query ???和Key ???的維度必須一致,Value ???和Query/Key的維度可以不一致。
Key ???和Value ???的長(zhǎng)度必須一致。Key和Value本質(zhì)上對(duì)應(yīng)了同一個(gè)Sequence在不同空間的表達(dá)。
Attention得到的Output ???的維度和Value的維度一致,長(zhǎng)度和Query一致。
Output每個(gè)位置 i 是由value的所有位置的vector加權(quán)平均之后的向量;而其權(quán)值是由位置為i 的query和key的所有位置經(jīng)過(guò)attention計(jì)算得到的 ,權(quán)值的個(gè)數(shù)等于key/value的長(zhǎng)度。
Attention示意圖
在經(jīng)典的Transformer結(jié)構(gòu)中,我們記線性映射之前的Query, Key, Value為q, k, v,映射之后為Q, K, V。那么:
self-attention的q, k, v都是同一個(gè)輸入, 即當(dāng)前序列由上一層輸出的高維表達(dá)。
cross-attention的q代表當(dāng)前序列,k,v是同一個(gè)輸入,對(duì)應(yīng)的是encoder最后一層的輸出結(jié)果(對(duì)decoder端的每一層來(lái)說(shuō),保持不變) ? ?
而每一層線性映射參數(shù)矩陣都是獨(dú)立的,所以經(jīng)過(guò)映射后的Q, K, V各不相同,模型參數(shù)優(yōu)化的目標(biāo)在于將q, k, v被映射到新的高維空間,使得每層的Q, K,V在不同抽象層面上捕獲到q, k, v之間的關(guān)系。一般來(lái)說(shuō),底層layer捕獲到的更多是lexical-level的關(guān)系,而高層layer捕獲到的更多是semantic-level的關(guān)系。
2.4. Attention的作用
下面這段我會(huì)以機(jī)器翻譯為例,用通俗的語(yǔ)言闡釋一下attention的作用,以及query, key, value的含義。
Transformer模型Encoder, Decoder的細(xì)節(jié)圖(省去了FFN部分)
query對(duì)應(yīng)的是需要?「被表達(dá)」?的序列(稱為序列A),key和value對(duì)應(yīng)的是?「用來(lái)表達(dá)」A的序列(稱為序列B)。其中key和query是在同一高維空間中的(否則無(wú)法用來(lái)計(jì)算相似程度),value不必在同一高維空間中,最終生成的output和value在同一高維空間中。上面這段巨繞的話用一句更繞的話來(lái)描述一下就是:
? ? ?
序列A和序列B在高維空間 ???中的高維表達(dá) ?的每個(gè)位置 _「分別」?_ 和 ???計(jì)算相似度,產(chǎn)生的權(quán)重作用于序列B在高維空間??中的高維表達(dá) ???,獲得序列A在高維空間??中的高維表達(dá) ?
?
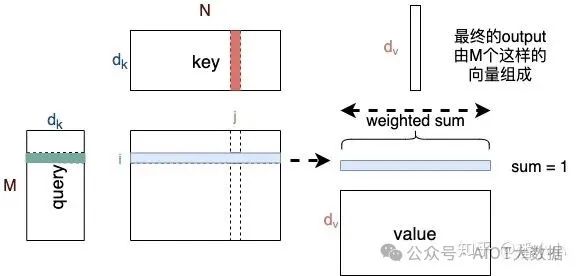
Encoder部分中只存在self-attention,而Decoder部分中存在self-attention和cross-attention
【self-attention】encoder中的self-attention的query, key,value都對(duì)應(yīng)了源端序列(即A和B是同一序列),decoder中的self-attention的query, key, value都對(duì)應(yīng)了目標(biāo)端序列。
【cross-attention】decoder中的cross-attention的query對(duì)應(yīng)了目標(biāo)端序列,key,value對(duì)應(yīng)了源端序列(每一層中的cross-attention用的都是encoder的最終輸出)
2.5. Decoder端的Mask
Transformer模型屬于自回歸模型(p.s.非自回歸的翻譯模型我會(huì)專門寫一篇文章來(lái)介紹),也就是說(shuō)后面的token的推斷是基于前面的token的。Decoder端的Mask的功能是為了保證訓(xùn)練階段和推理階段的一致性。
論文原文中關(guān)于這一點(diǎn)的段落如下:
?
We also modify the self-attention sub-layer in the decoder stack to preventfrom attending to subsequent positions. This masking, combined with the factthat the output embeddings are offset by one position, ensures that thepredictions for position i can depend only on the known outputs at positionsless than i.
? ? ?
在推理階段,token是按照從左往右的順序推理的。也就是說(shuō),在推理timestep=T的token時(shí),decoder只能“看到”timestep < T的T-1 個(gè)Token,不能和timestep大于它自身的token做attention(因?yàn)楦具€不知道后面的token是什么)。為了保證訓(xùn)練時(shí)和推理時(shí)的一致性,所以,訓(xùn)練時(shí)要同樣防止token與它之后的token去做attention。
2.6. 多頭Attention (Multi-head Attention)
Attention是將query和key映射到同一高維空間中去計(jì)算相似度,而對(duì)應(yīng)的multi-head attention把query和key映射到高維空間??的不同子空間 ?
中去計(jì)算相似度。
為什么要做multi-head attention?論文原文里是這么說(shuō)的:
?
Multi-head attention allows the model to jointly attend to information fromdifferent representation subspaces at different positions. With a singleattention head, averaging inhibits this.
?
也就是說(shuō),這樣可以在不改變參數(shù)量的情況下增強(qiáng)每一層attention的表現(xiàn)力。?
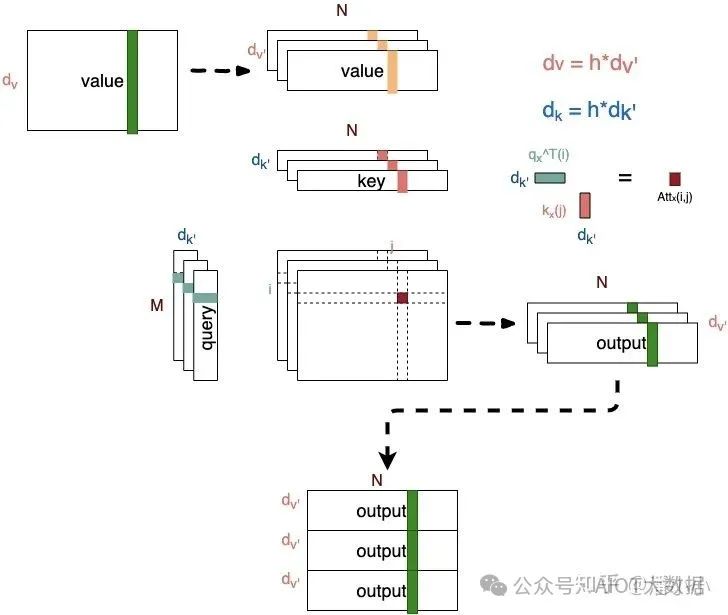
? ? ? ? ? ? ? ? ? ? ? ? ??Multi-headAttention示意圖 ? ?
Multi-head Attention的本質(zhì)是,在?「參數(shù)總量保持不變」?的情況下,將同樣的query, key, value映射到原來(lái)的高維空間的「不同子空間」中進(jìn)行attention的計(jì)算,在最后一步再合并不同子空間中的attention信息。這樣降低了計(jì)算每個(gè)head的attention時(shí)每個(gè)向量的維度,在某種意義上防止了過(guò)擬合;由于Attention在不同子空間中有不同的分布,Multi-head Attention實(shí)際上是尋找了序列之間不同角度的關(guān)聯(lián)關(guān)系,并在最后concat這一步驟中,將不同子空間中捕獲到的關(guān)聯(lián)關(guān)系再綜合起來(lái)。
從上圖可以看出, ???和 ???之間的attentionscore從1個(gè)變成了h個(gè),這就對(duì)應(yīng)了h個(gè)子空間中它們的關(guān)聯(lián)度。
3. Transformer模型架構(gòu)中的其他部分
3.1. Feed Forward Network ? ?
每一層經(jīng)過(guò)attention之后,還會(huì)有一個(gè)FFN,這個(gè)FFN的作用就是空間變換。FFN包含了2層lineartransformation層,中間的激活函數(shù)是ReLu。
曾經(jīng)我在這里有一個(gè)百思不得其解的問(wèn)題:attention層的output最后會(huì)和 ?相乘,為什么這里又要增加一個(gè)2層的FFN網(wǎng)絡(luò)?
其實(shí),F(xiàn)FN的加入引入了非線性(ReLu激活函數(shù)),變換了attention output的空間,從而增加了模型的表現(xiàn)能力。把FFN去掉模型也是可以用的,但是效果差了很多。
3.2. Positional Encoding
位置編碼層只在encoder端和decoder端的embedding之后,第一個(gè)block之前出現(xiàn),它非常重要,沒(méi)有這部分,Transformer模型就無(wú)法用。位置編碼是Transformer框架中特有的組成部分,補(bǔ)充了Attention機(jī)制本身不能捕捉位置信息的缺陷。
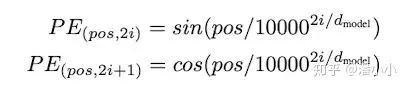
?positionencoding
PositionalEmbedding的成分直接疊加于Embedding之上,使得每個(gè)token的位置信息和它的語(yǔ)義信息(embedding)充分融合,并被傳遞到后續(xù)所有經(jīng)過(guò)復(fù)雜變換的序列表達(dá)中去。
論文中使用的PositionalEncoding(PE)是正余弦函數(shù),位置(pos)越小,波長(zhǎng)越長(zhǎng),每一個(gè)位置對(duì)應(yīng)的PE都是唯一的。同時(shí)作者也提到,之所以選用正余弦函數(shù)作為PE,是因?yàn)檫@可以使得模型學(xué)習(xí)到token之間的相對(duì)位置關(guān)系:因?yàn)閷?duì)于任意的偏移量k,??可以由 ???的線性表示:
上面兩個(gè)公式可以由 ???和 ?
的線性組合得到。也就是 ?乘上某個(gè)線性變換矩陣就得到了 ?
p.s. 后續(xù)有一個(gè)工作在attention中使用了“相對(duì)位置表示” ( ?Self-Attention with Relative PositionRepresentations) ,有興趣可以看看。 ? ?
3.3. Layer Normalization
在每個(gè)block中,最后出現(xiàn)的是Layer Normalization。LayerNormalization是一個(gè)通用的技術(shù),其本質(zhì)是規(guī)范優(yōu)化空間,加速收斂。
當(dāng)我們使用梯度下降法做優(yōu)化時(shí),隨著網(wǎng)絡(luò)深度的增加,數(shù)據(jù)的分布會(huì)不斷發(fā)生變化,假設(shè)feature只有二維,那么用示意圖來(lái)表示一下就是:
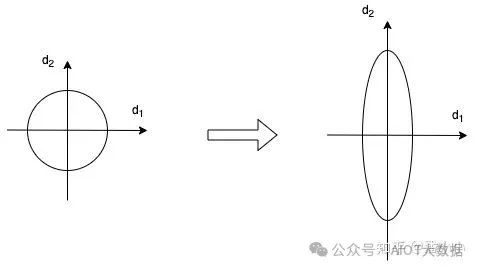
數(shù)據(jù)的分布發(fā)生變化,左圖比較規(guī)范,右圖變得不規(guī)范
為了保證數(shù)據(jù)特征分布的穩(wěn)定性(如左圖),我們加入Layer Normalization,這樣可以加速模型的優(yōu)化速度。
機(jī)器學(xué)習(xí)——圖解Transformer(完整版) ? ?
Transformer是一種基于注意力機(jī)制的序列模型,最初由Google的研究團(tuán)隊(duì)提出并應(yīng)用于機(jī)器翻譯任務(wù)。與傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)和卷積神經(jīng)網(wǎng)絡(luò)(CNN)不同,Transformer僅使用自注意力機(jī)制(self-attention)來(lái)處理輸入序列和輸出序列,因此可以并行計(jì)算,極大地提高了計(jì)算效率。下面是Transformer的詳細(xì)解釋。 ? ?
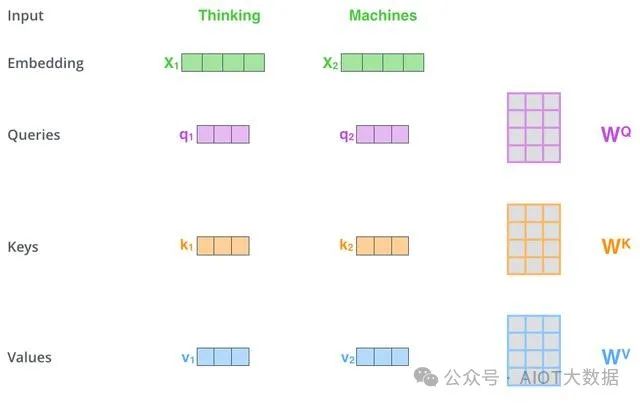
1. 自注意力機(jī)制
自注意力機(jī)制是Transformer的核心部分,它允許模型在處理序列時(shí),將輸入序列中的每個(gè)元素與其他元素進(jìn)行比較,以便在不同上下文中正確地處理每個(gè)元素。 ? ?
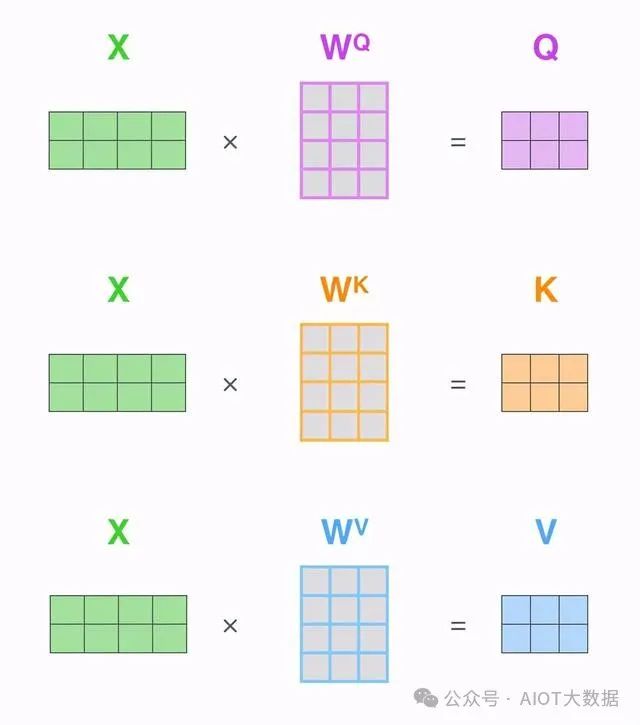
自注意力機(jī)制中有三個(gè)重要的輸入矩陣:查詢矩陣Q(query)、鍵矩陣K(key)和值矩陣V(value)。這三個(gè)矩陣都是由輸入序列經(jīng)過(guò)不同的線性變換得到的。然后,查詢矩陣Q與鍵矩陣K的乘積經(jīng)過(guò)一個(gè)softmax函數(shù),得到一個(gè)與輸入序列長(zhǎng)度相同的概率分布,該分布表示每個(gè)元素對(duì)于查詢矩陣Q的重要性。最后,將這個(gè)概率分布乘以值矩陣V得到自注意力向量,表示將每個(gè)元素的值加權(quán)平均后的結(jié)果。 ? ?

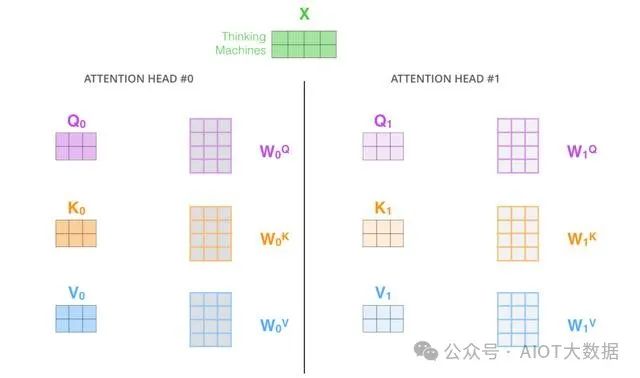
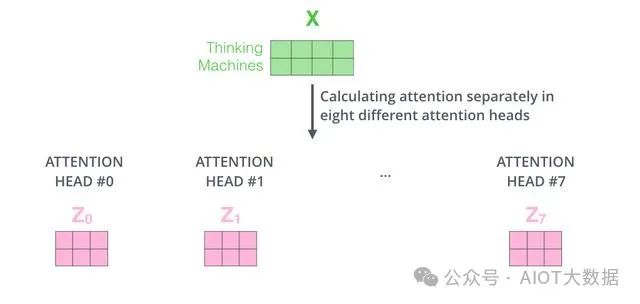
2. 多頭注意力機(jī)制
為了進(jìn)一步提高模型的性能,Transformer引入了多頭注意力機(jī)制(multi-head attention)。多頭注意力機(jī)制通過(guò)將自注意力機(jī)制應(yīng)用于多組不同的查詢矩陣Q、鍵矩陣K和值矩陣V,從而學(xué)習(xí)到不同的上下文表示。具體來(lái)說(shuō),將輸入序列分別通過(guò)不同的線性變換得到多組不同的查詢矩陣Q、鍵矩陣K和值矩陣V,然后將它們輸入到多個(gè)并行的自注意力機(jī)制中進(jìn)行處理。
Transformer在自然語(yǔ)言處理中廣泛應(yīng)用,例如機(jī)器翻譯、文本摘要、語(yǔ)言生成等領(lǐng)域。相比于傳統(tǒng)的遞歸神經(jīng)網(wǎng)絡(luò)(RNN)和卷積神經(jīng)網(wǎng)絡(luò)(CNN),Transformer的并行計(jì)算能力更強(qiáng),處理長(zhǎng)序列的能力更強(qiáng),且可以直接對(duì)整個(gè)序列進(jìn)行處理。 ? ?
Transformer模型由編碼器(Encoder)和解碼器(Decoder)兩部分組成,下面將詳細(xì)介紹每個(gè)部分的構(gòu)成和作用。
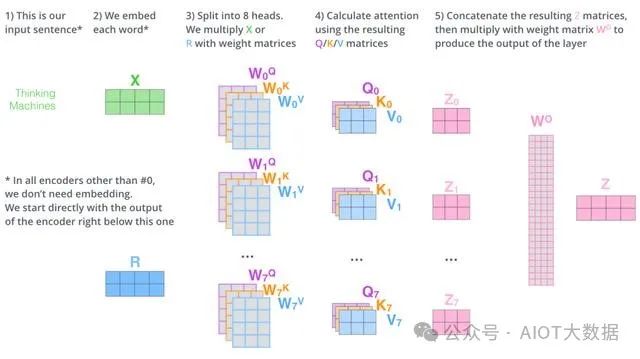
1. 編碼器(Encoder)
編碼器將輸入序列(例如一句話)轉(zhuǎn)化為一系列上下文表示向量(Contextualized Embedding),它由多個(gè)相同的層組成。每一層都由兩個(gè)子層組成,分別是自注意力層(Self-Attention Layer)和前饋全連接層(Feedforward Layer)。具體地,自注意力層將輸入序列中的每個(gè)位置與所有其他位置進(jìn)行交互,以計(jì)算出每個(gè)位置的上下文表示向量。前饋全連接層則將每個(gè)位置的上下文表示向量映射到另一個(gè)向量空間,以捕捉更高級(jí)別的特征。 ? ?

2. 解碼器(Decoder)
解碼器將編碼器的輸出和目標(biāo)序列(例如翻譯后的句子)作為輸入,生成目標(biāo)序列中每個(gè)位置的概率分布。解碼器由多個(gè)相同的層組成,每個(gè)層由三個(gè)子層組成,分別是自注意力層、編碼器-解碼器注意力層(Encoder-Decoder Attention Layer)和前饋全連接層。其中自注意力層和前饋全連接層的作用與編碼器相同,而編碼器-解碼器注意力層則將解碼器當(dāng)前位置的輸入與編碼器的所有位置進(jìn)行交互,以獲得與目標(biāo)序列有關(guān)的信息。 ? ?
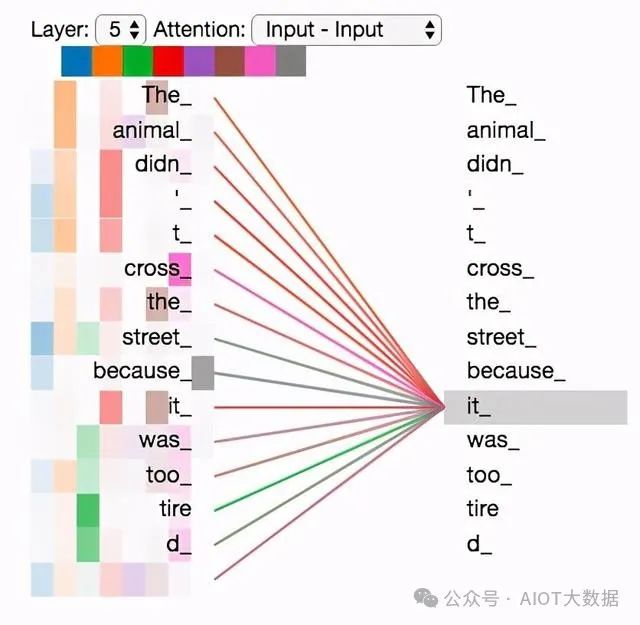
在Transformer中,自注意力機(jī)制是關(guān)鍵的組成部分。它可以將輸入序列中的任何兩個(gè)位置之間的關(guān)系建模,并且可以根據(jù)序列的內(nèi)容自動(dòng)學(xué)習(xí)不同位置之間的相互依賴關(guān)系。自注意力機(jī)制的計(jì)算包括三個(gè)步驟:計(jì)算查詢向量(Query Vector)、鍵向量(Key Vector)和值向量(Value Vector),并將它們組合起來(lái)計(jì)算注意力分?jǐn)?shù),最后將注意力分?jǐn)?shù)與值向量相乘得到自注意力向量。 ? ?
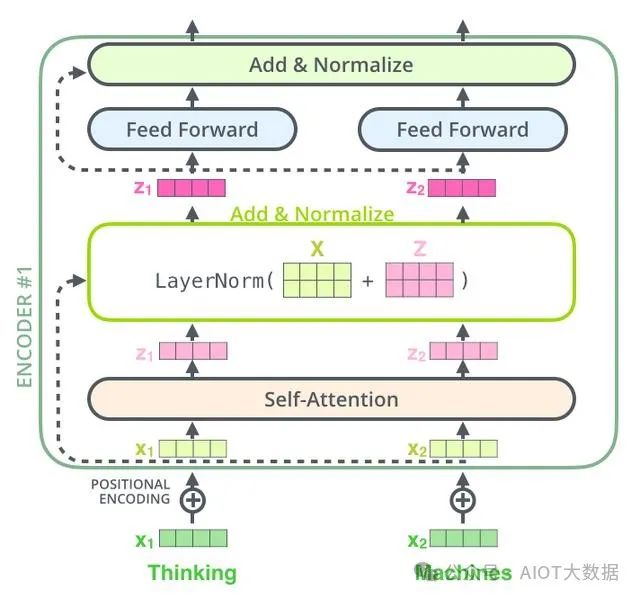
總體來(lái)說(shuō),Transformer通過(guò)引入自注意力機(jī)制和多頭注意力機(jī)制,使得神經(jīng)網(wǎng)絡(luò)能夠更好地捕捉序列中的長(zhǎng)程依賴關(guān)系,從而在自然語(yǔ)言處理等領(lǐng)域獲得了巨大的成功。
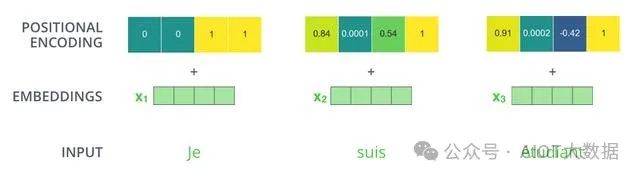
? ?

Mask
mask表示掩碼。即對(duì)某些值進(jìn)行掩蓋,不參與計(jì)算,不會(huì)對(duì)參數(shù)更新產(chǎn)生效果。Decoder計(jì)算注意力的時(shí)候,為了讓decoder不能看到未來(lái)的信息,需要把未來(lái)的信息隱藏。例如在 time_step 為 t 的時(shí)刻,解碼計(jì)算attention的時(shí)候應(yīng)該只能依賴于 t 時(shí)刻之前的輸出,而不能依賴 t 之后的輸出。因此需要想一個(gè)辦法,把 t 之后的信息給隱藏起來(lái)。這就是mask的作用。
具體的辦法是在計(jì)算attention步驟中,在計(jì)算softmax之前,在這些位置加上一個(gè)非常打的負(fù)數(shù)(-INF),這樣,經(jīng)過(guò)softmax這些位置的概率會(huì)接近0。
Linear和softmax
Decoder最終輸出的結(jié)果是一個(gè)浮點(diǎn)型數(shù)據(jù)的向量,我們要如何把這個(gè)向量轉(zhuǎn)為一個(gè)單詞呢?這個(gè)就是Linear和softmax要做的事情了。
Linear層是一個(gè)全連接的神經(jīng)網(wǎng)絡(luò),輸出神經(jīng)元個(gè)數(shù)一般等于我們的詞匯表大小。Decoder輸出的結(jié)果會(huì)輸入到Linear層,然后再用softmax進(jìn)行轉(zhuǎn)換,得到的是詞匯表大小的向量,向量的每個(gè)值對(duì)應(yīng)的是當(dāng)前Decoder是對(duì)應(yīng)的這個(gè)詞的概率,我們只要取概率最大的詞,就是當(dāng)前詞語(yǔ)Decoder的結(jié)果了。 ? ?
transformer模型詳解
一、transformer模型原理
Transformer模型是由谷歌公司提出的一種基于自注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)模型,用于處理序列數(shù)據(jù)。相比于傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)模型,Transformer模型具有更好的并行性能和更短的訓(xùn)練時(shí)間,因此在自然語(yǔ)言處理領(lǐng)域中得到了廣泛應(yīng)用。
在自然語(yǔ)言處理中,序列數(shù)據(jù)的輸入包括一系列文本、語(yǔ)音信號(hào)、圖像或視頻等。傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)模型已經(jīng)在這些任務(wù)中取得了很好的效果,但是該模型存在著兩個(gè)主要問(wèn)題:一是難以并行計(jì)算,二是難以捕捉長(zhǎng)距離依賴關(guān)系。為了解決這些問(wèn)題,Transformer模型應(yīng)運(yùn)而生。
作為一種基于自注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)模型,Transformer模型能夠?qū)π蛄兄械拿總€(gè)元素進(jìn)行全局建模,并在各個(gè)元素之間建立聯(lián)系。與循環(huán)神經(jīng)網(wǎng)絡(luò)模型相比,Transformer模型具有更好的并行性能和更短的訓(xùn)練時(shí)間。
Transformer模型中包含了多層encoder和decoder,每一層都由多個(gè)注意力機(jī)制模塊和前饋神經(jīng)網(wǎng)絡(luò)模塊組成。encoder用于將輸入序列編碼成一個(gè)高維特征向量表示,decoder則用于將該向量表示解碼成目標(biāo)序列。在Transformer模型中,還使用了殘差連接和層歸一化等技術(shù)來(lái)加速模型收斂和提高模型性能。
Transformer模型的核心是自注意力機(jī)制(Self-Attention Mechanism),其作用是為每個(gè)輸入序列中的每個(gè)位置分配一個(gè)權(quán)重,然后將這些加權(quán)的位置向量作為輸出。
自注意力機(jī)制的計(jì)算過(guò)程包括三個(gè)步驟:
計(jì)算注意力權(quán)重:計(jì)算每個(gè)位置與其他位置之間的注意力權(quán)重,即每個(gè)位置對(duì)其他位置的重要性。 ? ?
計(jì)算加權(quán)和:將每個(gè)位置向量與注意力權(quán)重相乘,然后將它們相加,得到加權(quán)和向量。
線性變換:對(duì)加權(quán)和向量進(jìn)行線性變換,得到最終的輸出向量。
通過(guò)不斷堆疊多個(gè)自注意力層和前饋神經(jīng)網(wǎng)絡(luò)層,可以構(gòu)建出Transformer模型。
對(duì)于Transformer模型的訓(xùn)練,通常采用無(wú)監(jiān)督的方式進(jìn)行預(yù)訓(xùn)練,然后再進(jìn)行有監(jiān)督的微調(diào)。在預(yù)訓(xùn)練過(guò)程中,通常采用自編碼器或者掩碼語(yǔ)言模型等方式進(jìn)行訓(xùn)練,目標(biāo)是學(xué)習(xí)輸入序列的表示。在微調(diào)過(guò)程中,通常采用有監(jiān)督的方式進(jìn)行訓(xùn)練,例如在機(jī)器翻譯任務(wù)中,使用平行語(yǔ)料進(jìn)行訓(xùn)練,目標(biāo)是學(xué)習(xí)將輸入序列映射到目標(biāo)序列的映射關(guān)系。
二、Transformer模型的優(yōu)缺點(diǎn)
Transformer模型的優(yōu)缺點(diǎn)
更好的并行性能:Transformer模型能夠在所有位置同時(shí)計(jì)算,從而充分利用GPU并行計(jì)算的優(yōu)勢(shì),加速了模型的訓(xùn)練和推理過(guò)程。
能夠處理長(zhǎng)序列:傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)模型在處理長(zhǎng)序列時(shí)容易出現(xiàn)梯度消失和梯度爆炸的問(wèn)題,而Transformer模型使用了自注意力機(jī)制,能夠同時(shí)考慮所有位置的信息,從而更好地處理長(zhǎng)序列。
更好的性能表現(xiàn):Transformer模型在自然語(yǔ)言處理領(lǐng)域中已經(jīng)取得了很多重要的研究成果,比如在機(jī)器翻譯、文本生成、語(yǔ)言模型等任務(wù)中都取得了很好的效果。
Transformer模型的缺點(diǎn)
對(duì)于小數(shù)據(jù)集,Transformer模型的表現(xiàn)可能會(huì)不如傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)模型,因?yàn)樗枰蟮臄?shù)據(jù)集來(lái)訓(xùn)練。
Transformer模型的計(jì)算復(fù)雜度較高,需要更多的計(jì)算資源,比如GPU等。
Transformer模型的可解釋性不如傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)模型,因?yàn)樗褂昧俗宰⒁饬C(jī)制,難以解釋每個(gè)位置的重要性。 ? ?
三、Transformer模型的代碼示例
以下是使用PyTorch實(shí)現(xiàn)Transformer模型的代碼示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def?__init__(self, d_model, n_heads):
super(MultiHeadAttention,?self).__init__()
self.d_model?= d_model
self.n_heads?= n_heads
self.d_k?= d_model // n_heads
self.d_v?= d_model // n_heads
self.W_Q?= nn.Linear(d_model, d_model)
self.W_K?= nn.Linear(d_model, d_model)
self.W_V?= nn.Linear(d_model, d_model)
self.W_O?= nn.Linear(d_model, d_model)
def?forward(self, Q, K, V, mask=None):
Q?= self.W_Q(Q)
K?= self.W_K(K)
V?= self.W_V(V)
Q?= self.split_heads(Q)
K?= self.split_heads(K) ? ?
V?= self.split_heads(V)
scores?= torch.matmul(Q, K.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
if?mask is not None:
scores?= scores.masked_fill(mask == 0, -1e9)
attn_weights?= F.softmax(scores, dim=-1)
attn_output?= torch.matmul(attn_weights, V)
attn_output?= self.combine_heads(attn_output)
attn_output?= self.W_O(attn_output)
return?attn_output
def?split_heads(self, x):
batch_size,?seq_len, d_model = x.size()
x?= x.view(batch_size, seq_len, self.n_heads, self.d_k)
return?x.transpose(1, 2)
def?combine_heads(self, x):
batch_size,?n_heads, seq_len, d_v = x.size()
x?= x.transpose(1, 2).contiguous()
x?= x.view(batch_size, seq_len, n_heads * d_v)
return?x
class PositionalEncoding(nn.Module):
def?__init__(self, d_model, max_len=5000):
super(PositionalEncoding,?self).__init__() ? ?
self.d_model?= d_model
self.dropout?= nn.Dropout(p=0.1)
pe?= torch.zeros(max_len, d_model)
position?= torch.arange(0, max_len, dtype=torch.float32).unsqueeze(1)
div_term?= torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:,?0::2] = torch.sin(position * div_term)
pe[:,?1::2] = torch.cos(position * div_term)
pe?= pe.unsqueeze(0)
self.register_buffer('pe',?pe)
def?forward(self, x):
x?= x * math.sqrt(self.d_model)
x?= x + self.pe[:, :x.size(1)]
x?= self.dropout(x)
return?x
class FeedForward(nn.Module):
def?__init__(self, d_model, d_ff):
super(FeedForward,?self).__init__()
self.linear1?= nn.Linear(d_model, d_ff)
self.linear2?= nn.Linear(d_ff, d_model)
def?forward(self, x):
x?= self.linear1(x) ? ?
x?= F.relu(x)
x?= self.linear2(x)
return?x
class EncoderLayer(nn.Module):
def?__init__(self, d_model, n_heads, d_ff):
super(EncoderLayer,?self).__init__()
self.multi_head_attn?= MultiHeadAttention(d_model, n_heads)
self.feed_forward?= FeedForward(d_model, d_ff)
self.layer_norm1?= nn.LayerNorm(d_model)
self.layer_norm2?= nn.LayerNorm(d_model)
self.dropout1?= nn.Dropout(p=0.1)
self.dropout2?= nn.Dropout(p=0.1)
def?forward(self, x, mask=None):
attn_output?= self.multi_head_attn(x, x, x, mask=mask)
x?= x + self.dropout1(attn_output)
x?= self.layer_norm1(x)
ff_output?= self.feed_forward(x)
x?= x + self.dropout2(ff_output)
x?= self.layer_norm2(x)
return?x
class Encoder(nn.Module):
def?__init__(self, input_size, d_model, n_heads, d_ff, n_layers): ? ?
super(Encoder,?self).__init__()
self.embedding?= nn.Embedding(input_size, d_model)
self.pos_encoding?= PositionalEncoding(d_model)
self.layers?= nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff) for _ in range(n_layers)])
self.layer_norm?= nn.LayerNorm(d_model)
def?forward(self, x, mask=None):
x?= self.embedding(x)
x?= self.pos_encoding(x)
for?layer in self.layers:
x?= layer(x, mask=mask)
x?= self.layer_norm(x)
return?x
class Transformer(nn.Module):
def?__init__(self, input_size, output_size, d_model, n_heads, d_ff, n_layers):
super(Transformer,?self).__init__()
self.encoder?= Encoder(input_size, d_model, n_heads, d_ff, n_layers)
self.output_layer?= nn.Linear(d_model, output_size)
def?forward(self, x, mask=None):
x?= self.encoder(x, mask)
x?= x[:, 0, :]
x?= self.output_layer(x) ? ?
return?x
這段代碼實(shí)現(xiàn)了一個(gè)基于Transformer模型的文本分類器。
四、Transformer模型應(yīng)用領(lǐng)域
Transformer模型是一種基于注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)架構(gòu),最初被提出用于自然語(yǔ)言處理任務(wù)中的序列到序列學(xué)習(xí)。隨著時(shí)間的推移,Transformer模型被應(yīng)用于各種不同的領(lǐng)域,如下所示:
(一)?自然語(yǔ)言處理
自然語(yǔ)言處理是指將人類語(yǔ)言轉(zhuǎn)換為計(jì)算機(jī)可以理解的形式,以便計(jì)算機(jī)能夠處理和理解語(yǔ)言。Transformer模型在自然語(yǔ)言處理領(lǐng)域有許多應(yīng)用案例。以下是一些例子:
文本分類:Transformer模型可以對(duì)文本進(jìn)行分類,例如將電子郵件分類為垃圾郵件或非垃圾郵件。在這種情況下,Transformer模型可以將文本作為輸入,然后輸出類別標(biāo)簽。
機(jī)器翻譯:Transformer模型可以將一種語(yǔ)言的文本翻譯成另一種語(yǔ)言的文本。在這種情況下,Transformer模型可以將源語(yǔ)言的文本作為輸入,然后輸出目標(biāo)語(yǔ)言的文本。
命名實(shí)體識(shí)別:Transformer模型可以識(shí)別文本中的命名實(shí)體,例如人名、地名、組織名稱等。在這種情況下,Transformer模型可以將文本作為輸入,然后輸出命名實(shí)體的類型和位置。
情感分析:Transformer模型可以對(duì)文本進(jìn)行情感分析,例如判斷一篇文章是積極的還是消極的。在這種情況下,Transformer模型可以將文本作為輸入,然后輸出情感極性。
(二)?語(yǔ)音識(shí)別
語(yǔ)音識(shí)別是指將人類語(yǔ)音轉(zhuǎn)換為計(jì)算機(jī)可以理解的形式,以便計(jì)算機(jī)能夠處理和理解語(yǔ)音。一些最新的研究表明,基于Transformer的語(yǔ)音識(shí)別系統(tǒng)已經(jīng)取得了與傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)和卷積神經(jīng)網(wǎng)絡(luò)(CNN)相媲美的性能。下面是一些Transformer模型在語(yǔ)音識(shí)別領(lǐng)域的應(yīng)用案例: ? ?
語(yǔ)音識(shí)別:Transformer模型可以對(duì)語(yǔ)音信號(hào)進(jìn)行識(shí)別,例如將語(yǔ)音轉(zhuǎn)換為文本。在這種情況下,Transformer模型可以將語(yǔ)音信號(hào)作為輸入,然后輸出文本結(jié)果。
語(yǔ)音合成:Transformer模型可以將文本轉(zhuǎn)換為語(yǔ)音信號(hào)。在這種情況下,Transformer模型可以將文本作為輸入,然后輸出語(yǔ)音信號(hào)。
說(shuō)話人識(shí)別:Transformer模型可以識(shí)別不同說(shuō)話者的語(yǔ)音信號(hào)。在這種情況下,Transformer模型可以將語(yǔ)音信號(hào)作為輸入,然后輸出說(shuō)話者的身份。
聲紋識(shí)別:Transformer模型可以對(duì)聲音信號(hào)進(jìn)行識(shí)別,例如將聲音轉(zhuǎn)換為特征向量。在這種情況下,Transformer模型可以將聲音信號(hào)作為輸入,然后輸出特征向量。
這些應(yīng)用案例只是Transformer模型在語(yǔ)音識(shí)別領(lǐng)域中的一部分應(yīng)用。由于Transformer模型具有處理變長(zhǎng)序列數(shù)據(jù)的能力和更好的性能,因此在語(yǔ)音識(shí)別領(lǐng)域中得到了廣泛的應(yīng)用。
計(jì)算機(jī)視覺(jué)是指讓計(jì)算機(jī)理解和分析圖像和視頻。Transformer模型在計(jì)算機(jī)視覺(jué)領(lǐng)域也有廣泛應(yīng)用。以下是一些例子:
圖像分類:Transformer模型可以對(duì)圖像進(jìn)行分類,例如將圖像分類為不同的物體或場(chǎng)景。在這種情況下,Transformer模型可以將圖像作為輸入,然后輸出類別標(biāo)簽。
目標(biāo)檢測(cè):Transformer模型可以檢測(cè)圖像中的物體,并將它們分割出來(lái)。在這種情況下,Transformer模型可以將圖像作為輸入,然后輸出物體的位置和大小。
圖像生成:Transformer模型可以生成新的圖像,例如生成一張藝術(shù)作品或者修改一張圖像。在這種情況下,Transformer模型可以將圖像作為輸入,然后輸出新的圖像。
這些應(yīng)用案例只是Transformer模型在計(jì)算機(jī)視覺(jué)領(lǐng)域中的一部分應(yīng)用。由于Transformer模型具有處理變長(zhǎng)序列數(shù)據(jù)的能力和更好的性能,因此在計(jì)算機(jī)視覺(jué)領(lǐng)域中得到了廣泛的應(yīng)用。 ? ?
(四) 強(qiáng)化學(xué)習(xí)
Transformer模型在強(qiáng)化學(xué)習(xí)領(lǐng)域的應(yīng)用主要是應(yīng)用于策略學(xué)習(xí)和值函數(shù)近似。強(qiáng)化學(xué)習(xí)是指讓機(jī)器在與環(huán)境互動(dòng)的過(guò)程中,通過(guò)試錯(cuò)來(lái)學(xué)習(xí)最優(yōu)的行為策略。在強(qiáng)化學(xué)習(xí)中,模型需要通過(guò)學(xué)習(xí)狀態(tài)轉(zhuǎn)移概率,來(lái)預(yù)測(cè)下一個(gè)狀態(tài)和獎(jiǎng)勵(lì),從而實(shí)現(xiàn)增強(qiáng)學(xué)習(xí)。
1、Transformer模型可以通過(guò)多頭注意力機(jī)制來(lái)處理多個(gè)輸入序列,并將它們?nèi)诤铣梢粋€(gè)輸出序列。在強(qiáng)化學(xué)習(xí)中,Transformer模型可以將當(dāng)前狀態(tài)作為輸入,然后輸出一個(gè)行動(dòng)策略。具體而言,Transformer模型可以學(xué)習(xí)到狀態(tài)轉(zhuǎn)移概率函數(shù),使得在當(dāng)前狀態(tài)下,選擇行動(dòng)后可以獲得最大的獎(jiǎng)勵(lì)。
2、Transformer模型還可以用于值函數(shù)近似。值函數(shù)是指在給定狀態(tài)下,執(zhí)行一個(gè)特定行動(dòng)所能獲得的期望獎(jiǎng)勵(lì)。在強(qiáng)化學(xué)習(xí)中,值函數(shù)通常是通過(guò)蒙特卡羅方法來(lái)估計(jì)的。而Transformer模型可以通過(guò)學(xué)習(xí)值函數(shù)來(lái)近似這些值,從而提高強(qiáng)化學(xué)習(xí)的效率和精度。
3、Transformer模型已經(jīng)被廣泛應(yīng)用于自然語(yǔ)言處理、語(yǔ)音識(shí)別、計(jì)算機(jī)視覺(jué)和強(qiáng)化學(xué)習(xí)等領(lǐng)域,并且在這些領(lǐng)域中都取得了顯著的成果。它的廣泛應(yīng)用前景表明,Transformer模型在未來(lái)的人工智能領(lǐng)域中將扮演著越來(lái)越重要的角色。
總體來(lái)說(shuō),Transformer模型是一種高效、靈活、易于實(shí)現(xiàn)的神經(jīng)網(wǎng)絡(luò)模型,其在自然語(yǔ)言處理領(lǐng)域中發(fā)揮著越來(lái)越重要的作用。隨著深度學(xué)習(xí)技術(shù)的不斷發(fā)展,Transformer模型必將在未來(lái)的自然語(yǔ)言處理領(lǐng)域中發(fā)揮越來(lái)越重要的作用。
系統(tǒng)版本:macos 12.2.1
軟件版本:PaddlePaddle2.3.0
硬件型號(hào):MacBook Pro
審核編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論