 電子發燒友App
電子發燒友App


?本文來自“人工智能點燃算力需求,AI服務器迎來機遇”,Open AI的大型語言生成模型ChatGPT火熱,它能勝任刷高情商對話、生成代碼、構思劇本和小說等多個場景,將人機對話推向新的高度。全球各大科技企業都在積極擁抱AIGC,不斷推出相關技術、平臺和應用。
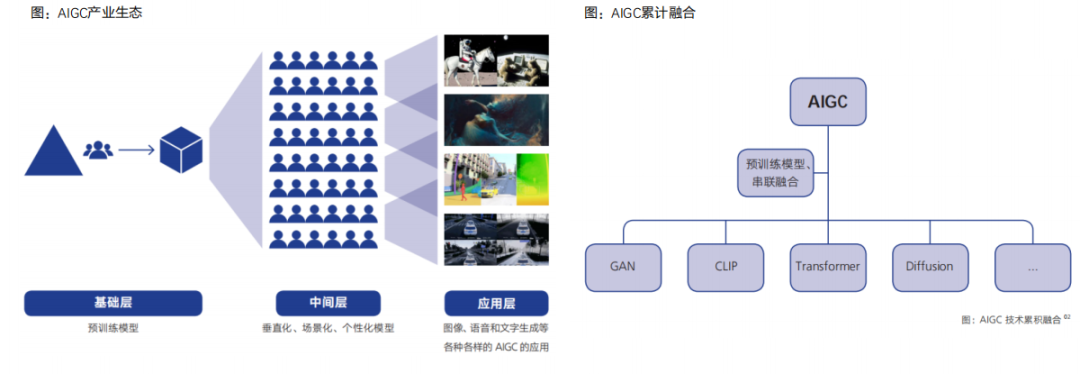
目前,AIGC產業生態體系的雛形已現,呈現為上中下三層架構:①第一層為上游基礎層,也就是由預訓練模型為基礎搭建的AIGC技術基礎設施層。②第二層為中間層,即垂直化、場景化、個性化的模型和應用工具。③第三層為應用層,即面向C端用戶的文字、圖片、音視頻等內容生成服務。
根據IDC發布的《2022年第四季度中國服務器市場跟蹤報告Prelim》,浪潮份額國內領先,新華三次之,超聚變排行第三,中興通訊進入前五。
2、服務器基本整體構成
服務器主要硬件包括處理器、內存、芯片組、I/O (RAID卡、網卡、HBA卡) 、硬盤、機箱 (電源、風扇)。以一臺普通的服務器生產成本為例,CPU及芯片組大致占比50% 左右,內存大致占比 15% 左右,外部存儲大致占比10%左右,其他硬件占比25%左右。

服務器的邏輯架構和普通計算機類似。但是由于需要提供高性能計算,因此在處理能力、穩定性、可靠性、安全性、可擴展性、可管理性等方面要求較高。
邏輯架構中,最重要的部分是CPU和內存。CPU對數據進行邏輯運算,內存進行數據存儲管理。
服務器的固件主要包括BIOS或UEFI、BMC、CMOS,OS包括32位和64位。
3、大模型參數量持續提升
GPT模型對比BERT模型、T5模型的參數量有明顯提升。GPT-3是目前最大的知名語言模型之一,包含了1750億(175B)個參數。在GPT-3發布之前,最大的語言模型是微軟的Turing NLG模型,大小為170億(17B)個參數。訓練數據量不斷加大,對于算力資源需求提升。
回顧GPT的發展,GPT家族與BERT模型都是知名的NLP模型,都基于Transformer技術。GPT,是一種生成式的預訓練模型,由OpenAI團隊最早發布于2018年,GPT-1只有12個Transformer層,而到了GPT-3,則增加到96層。其中,GPT-1使用無監督預訓練與有監督微調相結合的方式,GPT-2與GPT-3則都是純無監督預訓練的方式,GPT-3相比GPT-2的進化主要是數據量、參數量的數量級提升。
4、未來異構計算或成為主流
異構計算(Heterogeneous Computing)是指使用不同類型指令集和體系架構的計算單元組成系統的計算方式,目前主要包括GPU云服務器、FPGA云服務器和彈性加速計算實例EAIS等。讓最適合的專用硬件去服務最適合的業務場景。
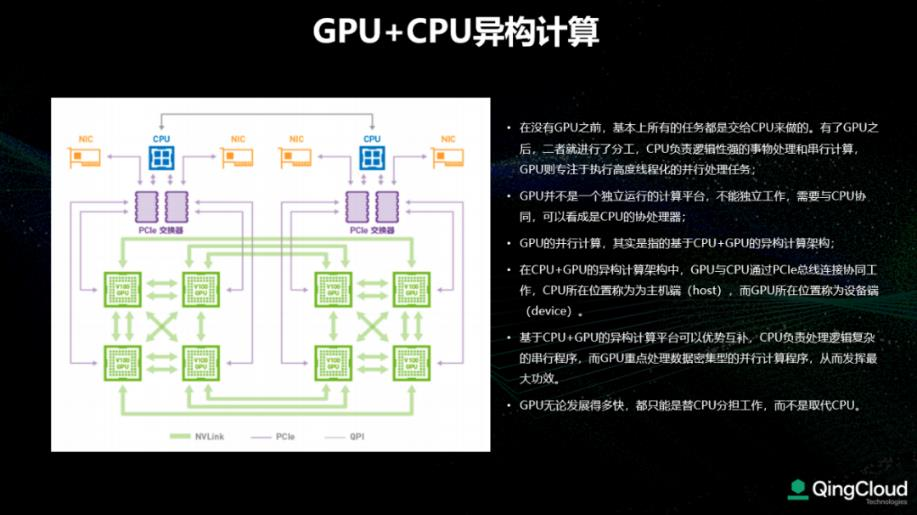
在CPU+GPU的異構計算架構中,GPU與CPU通過PCle總線連接協同工作,CPU所在位置稱為主機端 (host),而GPU所在位置稱為設備端(device)。基于CPU+GPU的異構計算平臺可以優勢互補,CPU負責處理邏輯復雜的串行程序,而GPU重點處理數據密集型的并行計算程序,從而發揮最大功效。
越來越多的AI計算都采用異構計算來實現性能加速。
阿里第一代計算型GPU實例,2017年對外發布GN4,搭載Nvidia M40加速器.,在萬兆網絡下面向人工智能深度學習場景,相比同時代的CPU服務器性能有近7倍的提升。
5、為什么GPU適用于AI
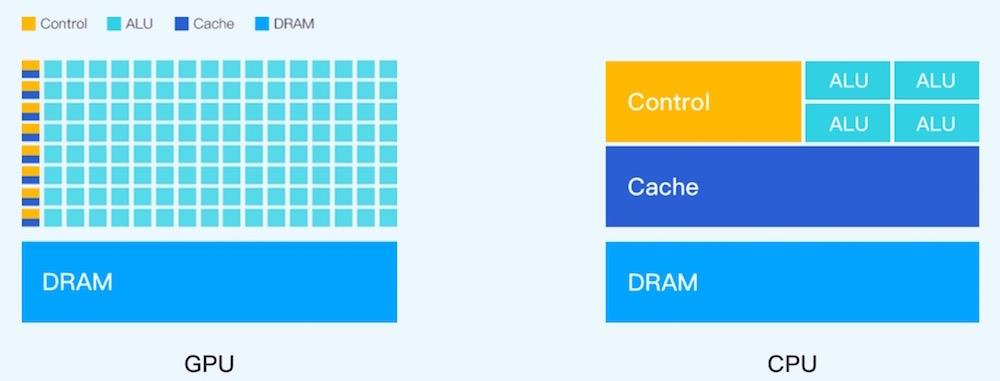
CPU 適用于一系列廣泛的工作負載,特別是那些對于延遲和單位內核性能要求較高的工作負載。作為強大的執行引擎,CPU 將它數量相對較少的內核集中用于處理單個任務,并快速將其完成。這使它尤其適合用于處理從串行計算到數據庫運行等類型的工作。
GPU 最初是作為專門用于加速特定 3D 渲染任務的 ASIC 開發而成的。隨著時間的推移,這些功能固定的引擎變得更加可編程化、更加靈活。盡管圖形處理和當下視覺效果越來越真實的頂級游戲仍是 GPU 的主要功能,但同時,它也已經演化為用途更普遍的并行處理器,能夠處理越來越多的應用程序。

訓練和推理過程所處理的數據量不同。
在AI實現的過程中,訓練(Training)和推理(Inference)是必不可少的,其中的區別在于:
訓練過程:又稱學習過程,是指通過大數據訓練出一個復雜的神經網絡模型,通過大量數據的訓練確定網絡中權重和偏置的值,使其能夠適應特定的功能。
推理過程:又稱判斷過程,是指利用訓練好的模型,使用新數據推理出各種結論。
簡單理解,我們學習知識的過程類似于訓練,為了掌握大量的知識,必須讀大量的書、專心聽老師講解,課后還要做大量的習題鞏固自己對知識的理解,并通過考試來驗證學習的結果。分數不同就是學習效果的差別,如果考試沒通過則需要繼續重新學習,不斷提升對知識的掌握程度。而推理,則是應用所學的知識進行判斷,比如診斷病人時候應用所學習的醫學知識進行判斷,做“推理”從而判斷出病因。
訓練需要密集的計算,通過神經網絡算出結果后,如果發現錯誤或未達到預期,這時這個錯誤會通過網絡層反向傳播回來,該網絡需要嘗試做出新的推測,在每一次嘗試中,它都要調整大量的參數,還必須兼顧其它屬性。再次做出推測后再次校驗,通過一次又一次循環往返,直到其得到“最優”的權重配置,達成預期的正確答案。如今,神經網絡復雜度越來越高,一個網絡的參數可以達到百萬級以上,因此每一次調整都需要進行大量的計算。吳恩達(曾在谷歌和百度任職)舉例“訓練一個百度的漢語語音識別模型不僅需要4TB的訓練數據,而且在整個訓練周期中還需要20 exaflops(百億億次浮點運算)的算力”,訓練是一個消耗巨量算力的怪獸。
推理是利用訓練好的模型,使用新數據推理出各種結論,它是借助神經網絡模型進行運算,利用輸入的新數據“一次性”獲得正確結論的過程,他不需要和訓練一樣需要循環往復的調整參數,因此對算力的需求也會低很多。

推理常用:NVIDIA T4 GPU 為不同的云端工作負載提供加速,其中包括高性能計算、深度學習訓練和推理、機器學習、數據分析和圖形學。引入革命性的 Turing Tensor Core 技術,使用多精度計算應對不同的工作負載。從 FP32 到 FP16,再到 INT8 和 INT4 的精度,T4 的性能比 CPU 高出 40 倍,實現了性能的重大突破。
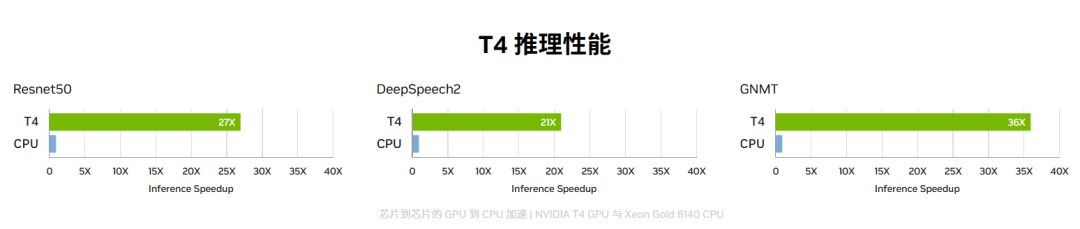
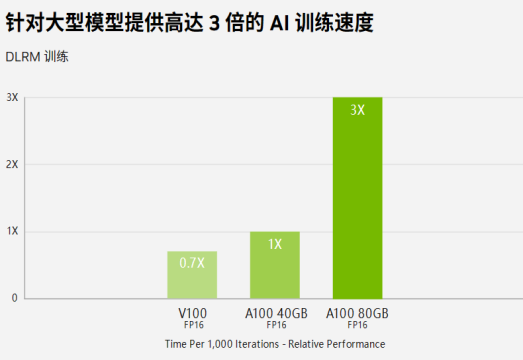
訓練:A100和H100。對于具有龐大數據表的超大型模型,A10080GB 可為每個節點提供高達 1.3TB 的統一顯存,而且吞吐量比A100 40GB 多高達 3 倍。在 BERT 等先進的對話式 AI 模型上,A100 可將推理吞吐量提升到高達 CPU 的 249 倍。
6、推算ChatGPT帶來的服務器需求增量
H100性能更強,與上一代產品相比,H100 的綜合技術創新可以將大型語言模型的速度提高 30 倍。根據Nvidia測試結果,H100針對大型模型提供高達 9 倍的 AI 訓練速度,超大模型的 AI 推理性能提升高達 30 倍。
在數據中心級部署 H100 GPU 可提供出色的性能,并使所有研究人員均能輕松使用新一代百億億次級 (Exascale)高性能計算 (HPC) 和萬億參數的 AI。
H100 還采用 DPX 指令,其性能比 NVIDIA A100 Tensor Core GPU 高 7 倍,在動態編程算法(例如,用于DNA 序列比對 Smith-Waterman)上比僅使用傳統雙路 CPU 的服務器快 40 倍。
假設應用H100服務器進行訓練,該服務器AI算力性能為32 PFLOPS,最大功率為10.2 kw,則我們測算訓練階段需要服務器數量=訓練階段算力需求÷服務器AI算力性能=4.625×107臺(同時工作1秒),即535臺服務器工作1日。
根據天翼智庫,GPT-3模型參數約1750億個,預訓練數據量為45 TB,折合成訓練集約為3000億tokens。按照有效算力比率21.3%來計算,訓練階段實際算力需求為1.48×109 PFLOPS。
對AI服務器訓練階段需求進行敏感性分析,兩個變化參數:①同時并行訓練的大模型數量、②單個模型要求訓練完成的時間。
按照A100服務器5 PFLOPs,H100服務器32 PFLOPs來進行計算。
若不同廠商需要訓練10個大模型,1天內完成,則需要A100服務器34233臺,需要H100服務器5349臺。
此外,若后續GPT模型參數迭代向上提升(GPT-4參數量可能對比GPT-3倍數級增長),則我們測算所需AI服務器數量進一步增長。
7、AI服務器市場規模預計將高速增長
AI服務器作為算力基礎設備,其需求有望受益于AI時代下對于算力不斷提升的需求而快速增長。
根據TrendForce,截至2022年為止,預估搭載GPGPU(General Purpose GPU)的AI服務器年出貨量占整體服務器比重近1%,預估在ChatBot相關應用加持下,有望再度推動AI相關領域的發展,預估出貨量年成長可達8%;2022~2026年復合成長率將達10.8%。
AI服務器是異構服務器,可以根據應用范圍采用不同的組合方式,如CPU + GPU、CPU + TPU、CPU +其他加速卡等。IDC預計,中國AI服務器2021年的市場規模為57億美元,同比增長61.6%,到2025年市場規模將增長到109億美元,CAGR為17.5%。
8、AI服務器構成及形態
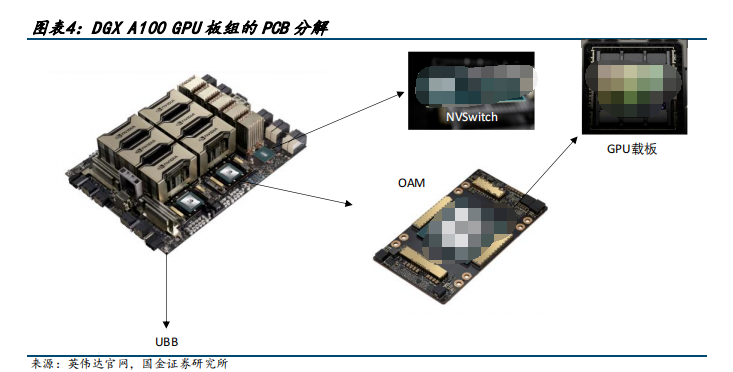
以浪潮NF5688M6 服務器為例,其采用NVSwitch實現GPU跨節點P2P高速通信互聯。整機8 顆 NVIDIAAmpere架構 GPU,通過NVSwitch實現GPU跨節點P2P高速通信互聯。配置 2顆第三代Intel Xeon 可擴展處理器(Ice Lake),支持8塊2.5英寸NVMe SSD orSATA/SAS SSD以及板載2塊 SATA M.2,可選配1張PCIe 4.0 x16 OCP 3.0網卡,速率支持10G/25G/100G;可支持10個PCIe 4.0 x16插槽, 2個PCIe 4.0 x16插槽(PCIe 4.0 x8速率), 1個OCP3.0插槽;支持32條DDR4RDIMM/LRDIMM內存,速率最高支持3200MT/s,物理結構還包括6塊3000W 80Plus鉑金電源、N+1冗余熱插拔風扇、機箱等。
目前按照GPU數量的不同,有4顆GPU(浪潮NF5448A6)、8顆GPU(Nvidia A100 640GB)以及16顆GPU(NVIDIA DGX-2)的AI服務器。
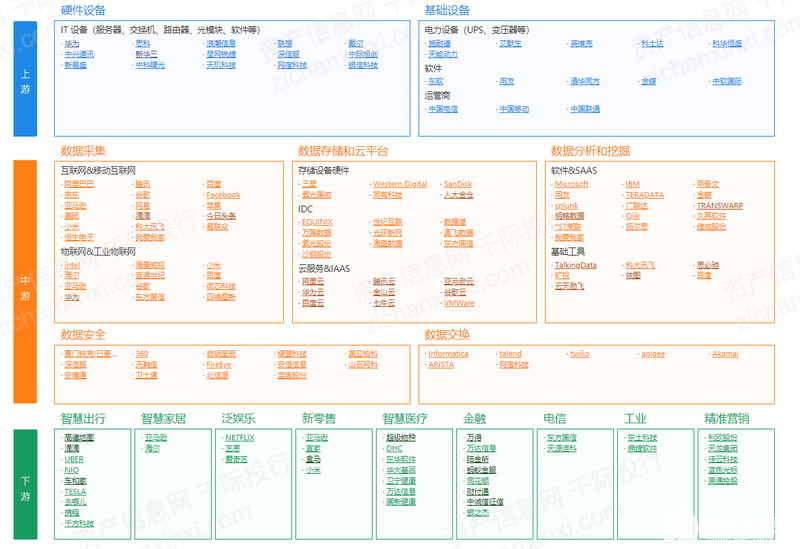
9、AI服務器產業鏈
AI服務器核心組件包括GPU(圖形處理器)、DRAM(動態隨機存取存儲器)、SSD(固態硬盤)和RAID卡、CPU(中央處理器)、網卡、PCB、高速互聯芯片(板內)和散熱模組等。
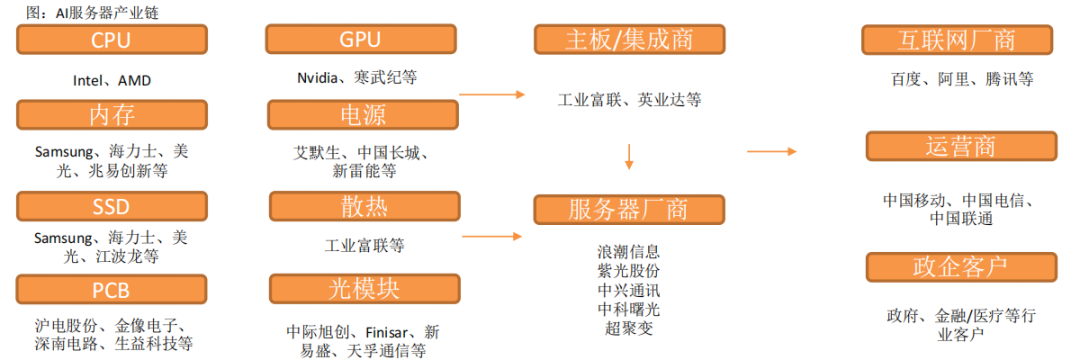
CPU主要供貨廠商為Intel、GPU目前領先廠商為國際巨頭英偉達,以及國內廠商如寒武紀、海光信息等。
SSD廠商包括三星、美光、海力士等,以及國內江波龍等廠商。
PCB廠商海外主要包括金像電子,國內包括滬電股份、鵬鼎控股等。
主板廠商包括工業富聯,服務器品牌廠商包括浪潮信息、紫光股份、中科曙光、中興通訊等。
10、AI服務器競爭格局
IDC發布了《2022年第四季度中國服務器市場跟蹤報告Prelim》。從報告可以看到,前兩名浪潮與新華三的變化較小,第三名為超聚變,從3.2%份額一躍而至10.1%,增幅遠超其他服務器廠商。Top8服務器廠商中,浪潮、戴爾、聯想均出現顯著下滑,超聚變和中興則取得明顯增長。其中,浪潮份額從30.8%下降至28.1%;新華三份額從17.5%下降至17.2%;中興通訊(000063)從3.1%提升至5.3%,位居國內第5。聯想降幅最為明顯,從7.5%下降至4.9%。
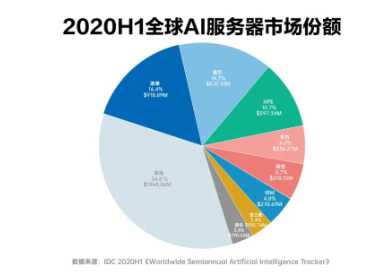
據TrendForce集邦咨詢統計,2022年AI服務器采購占比以北美四大云端業者Google、AWS、Meta、Microsoft合計占66.2%為最,而中國近年來隨著國產化力道加劇,AI建設浪潮隨之增溫,以ByteDance的采購力道最為顯著,年采購占比達6.2%,其次緊接在后的則是Tencent、Alibaba與Baidu,分別約為2.3%、1.5%與1.5%。
國內AI服務器競爭廠商包括:浪潮信息、新華三、超聚變、中興通訊等。
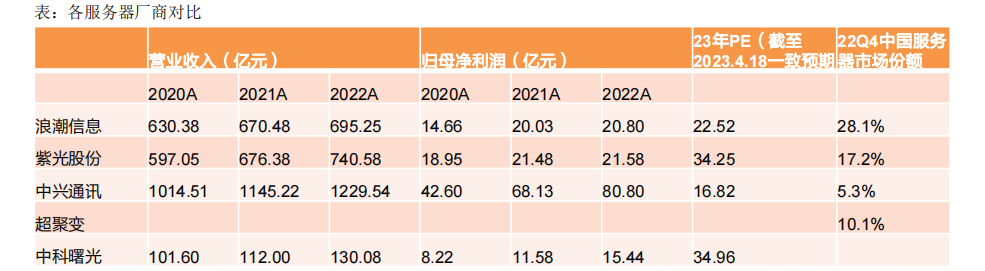
服務器主要廠商包括:工業富聯、浪潮信息、超聚變、紫光股份(新華三)、中興通訊、中科曙光。
AI服務器目前領先廠商為工業富聯和浪潮信息,浪潮信息在阿里、騰訊、百度AI服務器占比高達90%。
紫光股份在 GPU 服務器市場處于領先地位,有各種類型的 GPU 服務器滿足各種 AI 場景應用。特別針對 GPT 場景而優化的 GPU 服務器已經完成開發,并取得 31 個世界領先的測試指標,該新一代系列 GPU 服務器將在今年二季度全面上市。
中興通訊近年服務器發展較快,年初推出AI服務器G5服務器,此外在布局新一代AI加速芯片、模型輕量化技術,大幅降低大模型推理成本。
審核編輯:黃飛

















 工商網監
工商網監
評論