 電子發燒友App
電子發燒友App


作者:「報告,今天也有好好學習」
導讀
本篇文章,用一種通俗易懂的方式來介紹機器學習的理論基礎,是入門機器學習不可錯過的文章。
在這里,我要先引用一下一個非常經典的小故事,幫助大家更清楚地理解機器學習。
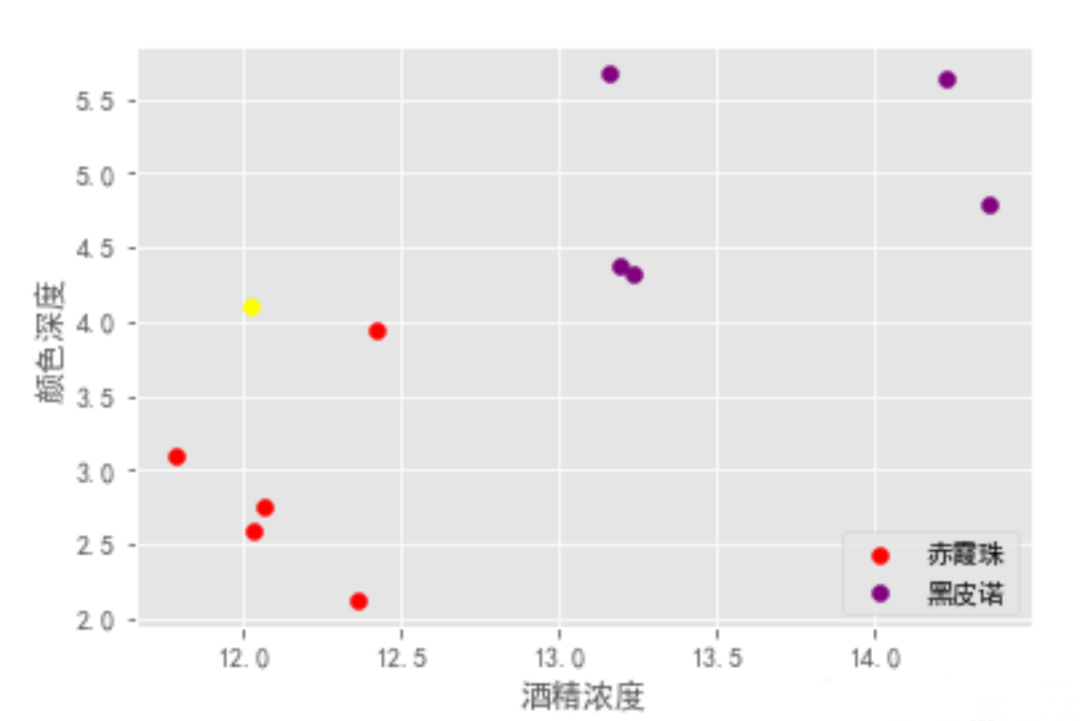
在一個酒吧里,吧臺上擺著十杯幾乎一樣的紅酒,老板跟你打趣說想不想來玩個游戲,贏了免費喝酒,輸了付3倍酒錢,那么贏的概率是多少?
你是個愛冒險的人,果斷說玩!
老板接著道:你眼前的這十杯紅酒,每杯略不相同,前五杯屬于「赤霞珠」后五杯屬于「黑皮諾」。現在,我重新倒一杯酒,你只需要正確地告訴我它屬于哪一類。
聽完你有點心虛:根本不懂酒啊,光靠看和嘗根本區分辨不出來,不過想起自己是搞機器學習的,不由多了幾分底氣爽快地答應了老板!
你沒有急著品酒而是問了老板每杯酒的一些具體信息:酒精濃度、顏色深度,以及一份紙筆, 老板一邊倒一杯新酒,你邊瘋狂打草稿。
很快,你告訴老板這杯新酒應該是「赤霞珠」。
老板瞪大了眼下巴也差點驚掉,從來沒有人一口酒都不嘗就能答對,無數人都是反復嘗來嘗去,最后以猶豫不定猜錯而結束。
你神秘地笑了笑,老板信守承諾讓你開懷暢飲。微醺之時,老板終于忍不住湊向你打探是怎么做到的。
你炫耀道:無他,但機器學習熟爾。
老板:…
怎么辨別出來的呢?
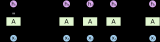
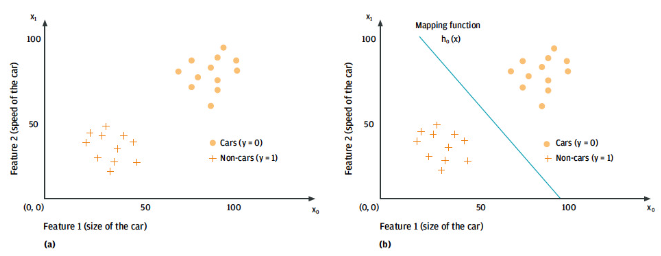
如下圖,故事中的你畫了類似這樣子的圖,就區分出來了
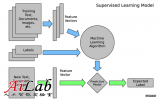
有監督學習
指對數據的若干特征與若干標簽(類型)之間的關聯性進行建模的過程。只要模型被確定,就可以應用到新的未知數據上。
這類學習過程可以進一步分為「分類」(classification)任務和「回歸」(regression)任務。
在分類任務中,標簽都是離散值。
而在回歸任務中,標簽都是連續值。
無監督學習?
指對不帶任何標簽的數據特征進行建模,通常被看成是一種“讓數據自己介紹自己” 的過程。
這類模型包括「聚類」(clustering)任務和「降維」(dimensionality reduction)任務。
聚類算法可以將數據分成不同的組別,而降維算法追求用更簡潔的方式表現數據。
半監督學習?
另外,還有一種半監督學習(semi-supervised learning)方法,介于有監督學習和無監督學習之間。通常可以在數據不完整時使用。
強化學習?
強化學習不同于監督學習,它將學習看作是試探評價過程,以"試錯" 的方式進行學習,并與環境進行交互已獲得獎懲指導行為,以其作為評價。
此時系統靠自身的狀態和動作進行學習,從而改進行動方案以適應環境。
(提示:半監督學習和強化學習比較偏向于深度學習)
輸入/輸出空間、特征空間?
在上面的場景中,每一杯酒稱作一個「樣本」,十杯酒組成一個樣本集。
酒精濃度、顏色深度等信息稱作「特征」。這十杯酒分布在一個「多維特征空間」中。
進入當前程序的“學習系統”的所有樣本稱作「輸入」,并組成「輸入空間」。
在學習過程中,所產生的隨機變量的取值,稱作「輸出」,并組成「輸出空間」。
在有監督學習過程中,當輸出變量均為連續變量時,預測問題稱為回歸問題;當輸出變量為有限個離散變量時,預測問題稱為分類問題。
過擬合與欠擬合?
先來一句易懂的話:
過擬合簡單來說就是模型把訓練集的東西學得太精了,對未知的數據效果卻很差(打個比方就是考前你練得很不錯,給啥做過的題都說得出答案,但是考試的時候碰到新題了就做得很差)
欠擬合就是模型學得很差,打個比方就是考前有題給你練,你也練了,但就是練不會,學不懂。
下面是具體介紹:
當假設空間中含有不同復雜度的模型時,就要面臨模型選擇(model selection)的問題。
我們希望獲得的是在新樣本上能表現得很好的學習器。為了達到這個目的,我們應該從訓練樣本中盡可能學到適用于所有潛在樣本的"普遍規律"
我們認為假設空間存在這種"真"模型,那么所選擇的模型應該逼近真模型。
擬合度可簡單理解為模型對于數據集背后客觀規律的掌握程度,模型對于給定數據集如果擬合度較差,則對規律的捕捉不完全,用作分類和預測時可能準確率不高。
換句話說,當模型把訓練樣本學得太好了的時候,很可能已經把訓練樣本自身的一些特點當作了所有潛在樣本的普遍性質,這時候所選的模型的復雜度往往會比真模型更高,這樣就會導致泛化性能下降。這種現象稱為過擬合(overfitting)。可以說,模型選擇旨在避免過擬合并提高模型的預測能力。
與過擬合相對的是欠擬合(underfitting),是指模型學習能力低下,導致對訓練樣本的一般性質尚未學好。
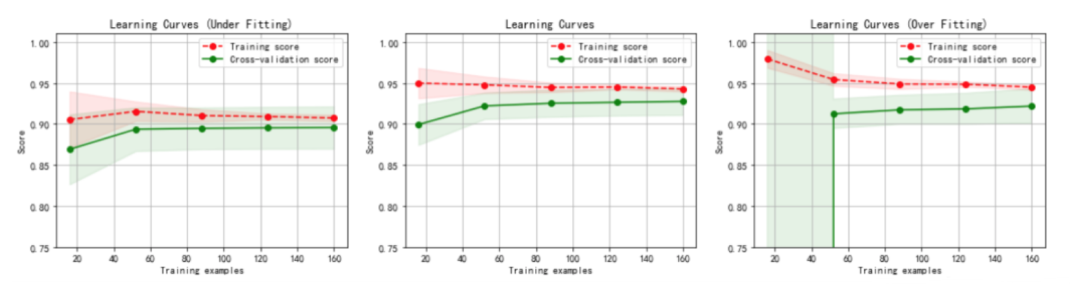
虛線:針對訓練數據集計算出來的分數,即針對訓練數據集擬合的準確性。
實線:針對交叉驗證數據集計算出來的分數,即針對交叉驗證數據集預測的準確性。
1.左圖:一階多項式,欠擬合.
訓練數據集的準確性(虛線)和交叉驗證數據集的準確性(實線)靠得很近,總體水平比較高。
隨著訓練數據集的增加,交叉驗證數據集的準確性(實線)逐漸增大,逐漸和訓練數據集的準確性(虛線)靠近,但其總體水平比較低,收斂在 0.88 左右。
訓練數據集的準確性也比較低,收斂在 0.90 左右。
當發生高偏差時,增加訓練樣本數量不會對算法準確性有較大的改善。
2.中圖:三階多項式,較好地擬合了數據集.
訓練數據集的準確性(虛線)和交叉驗證數據集的準確性(實線)靠得很近,總體水平比較高。
3.右圖:十階多項式,過擬合。
隨著訓練數據集的增加,交叉驗證數據集的準確性(實線)也在增加,逐漸和訓練數據集的準確性 (虛線)靠近,但兩者之間的間隙比較大。
訓練數據集的準確性很高,收斂在 0.95 左右。
交叉驗證數據集的準確性值卻較低,最終收斂在 0.91 左右。
從圖中我們可以看出,對于復雜數據,低階多項式往往是欠擬合的狀態,而高階多項式則過分捕捉噪聲數據的分布規律,而噪聲之所以稱為噪聲,是因為其分布毫無規律可言,或者其分布毫無價值,因此就算高階多項式在當前訓練集上擬合度很高,但其捕捉到的無用規律無法推廣到新的數據集上。因此該模型在測試數據集上執行過程將會有很大誤差,即模型訓練誤差很小,但泛化誤差很大。
審核編輯:黃飛















 工商網監
工商網監
評論