 電子發燒友App
電子發燒友App


在大模型席卷一切、賦能百業的浪潮里,“碼農”也沒能獨善其身。各種代碼自動生成的大模型,似乎描繪了一個人人都能像資深工程師一樣寫代碼的美好未來。
但在這個理想成為現實之前,有一個不能回避的問題 — 這些自動生成的代碼真的有效嗎?大模型也會犯錯,我們肯定不希望把看似正確的錯誤結果交給用戶,所以需要一個能精確驗證模型生成答案的考官。
近期,芯華章提出了一種對大模型生成代碼形式化評估的方法,稱為FormalEval。它能自動化檢査生成代碼的質量,無需手動編寫測試用例。經過測試,FormalEval不僅能夠識別出現有 RTL 基準數據集中潛藏的約50% 的評估錯誤,還能通過測試用例增強的方式來修復這些錯誤。
本文共計2680字,預計閱讀時間7分鐘,希望能夠幫助您更好了解:
? 如何快速驗證大模型自動生成的代碼?
? 新的方式和傳統方法有什么不一樣?
本文內容根據芯華章研究院入選ISEDA2024論文《FormalEval: a Formal Evaluation Tool for Code Generated by Large Language Models》梳理。感謝ISEDA評選委員會對芯華章相關研究的認可。

ISEDA2024技術分享現場
?
現有驗證方法
要么費時費力,要么不夠準確
在開始討論前,有必要先明確這個驗證系統需要具備的兩個核心屬性:
第一,驗證結果必須是足夠準確且充分的;
第二,效率也非常重要。
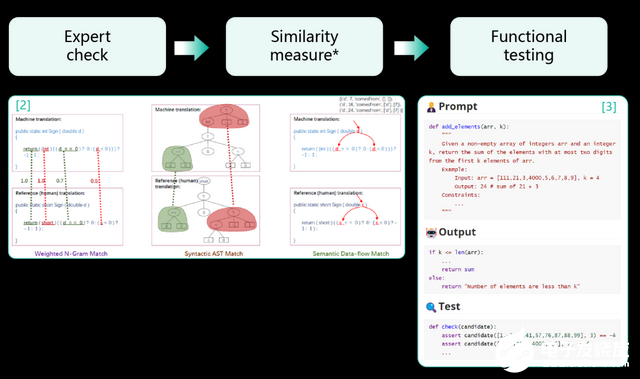
基于這兩點,現有方法又是怎么評價模型生成結果的呢?有三種主流方式:
/ 01 /
人類專家評價
給定問題, 大模型生成代碼, 人類工程師來判斷結果是否正確;
/ 02 /
基于近似指標的自動化評價
給定標準答案, 有基于文本間相似度的(Rouge1), 也有基于文本相似度結合代碼間結構(抽象語法樹、數據依賴圖)相似度的方法(Code-Bleu2);
/ 03 /
基于驗證平臺和測試用例的自動化評價
給定驗證平臺, 通過對比模型在各種不同測試用例下的輸出是否等于期望結果來評價模型的方法;
顯然, 第一種方法的評價精度受限于專家自身的能力, 而成本也受限于專家的時間資源。
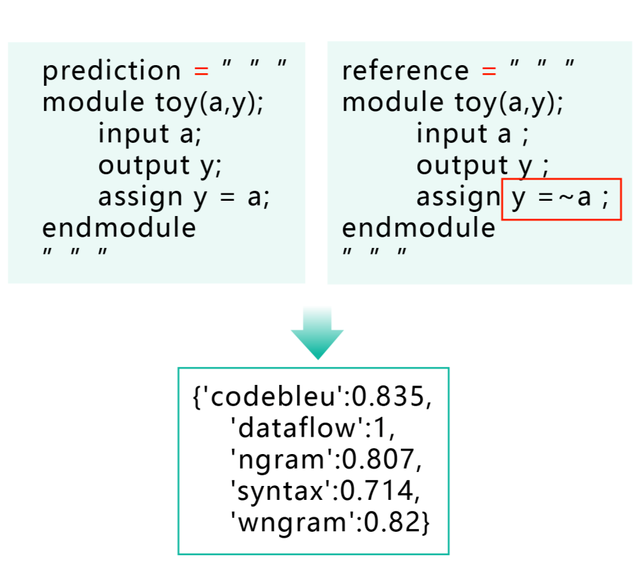
第二種方法, 雖然自動化程度高, 依賴的資源不多(只需要一份標準答案), 但因為借助的是近似指標的關系, 無法保證在指標上表現理想的模型,在功能上也能真正符合預期。從下例可以看出,明明模型生成的代碼給出的答案和正例是完全相反的,但是code-bleu得分卻接近1(滿分),這顯然是不合理的。
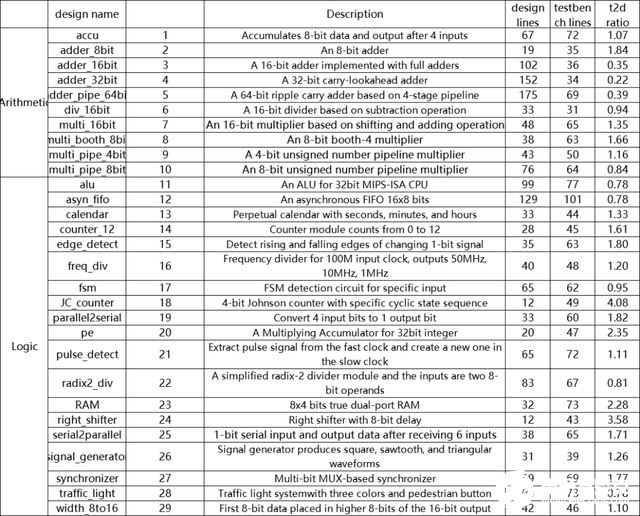
而第三種方法雖然準確度最高, 且在滿足資源(平臺、用例、仿真器、標準答案)的情況下能實現自動化評價, 但是這些前置資源的構造本身就需要花費大量人力成本(編寫好的測試用例通常和編寫程序一樣困難), 所以該方法也無法實現真正的大規模自動化驗證。我們統計了四個廣泛使用的評估數據集,發現每個問題的平均測試用例量都非常少。這會導致測試不準確的現象。
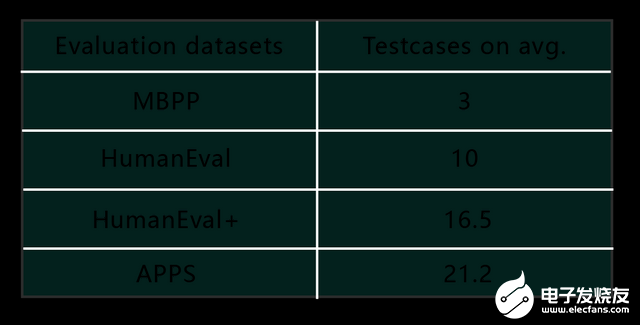
具體來說,當前最廣泛被使用的是OpenAI在Codex論文中開源的HumanEval(上表第三行)。OpenAI的(HumanEval3)驗證采用了第三種方法, 但僅提供了164個問題用作模型校驗, 與之對應的是其提供了成百上千萬行的代碼資料供模型學習。
事實上,后續有學者發現(HumanEval+4?上表第四行)由于平均每個問題僅包含約10個測試用例,即使只考察其提供的問題,該驗證系統也不能確保生成的代碼是正確的:
下圖里模型能順利通過HumanEval里的測試用例(底部),但由于其實現邏輯的問題(set是亂序的),在研究者新給出用例上(頂部)會校驗失敗。

?
從HumanEval到FormalEval
用形式化驗證來替代動態仿真
基于上述方法的局限性, 芯華章提出了 "FormalEval"。
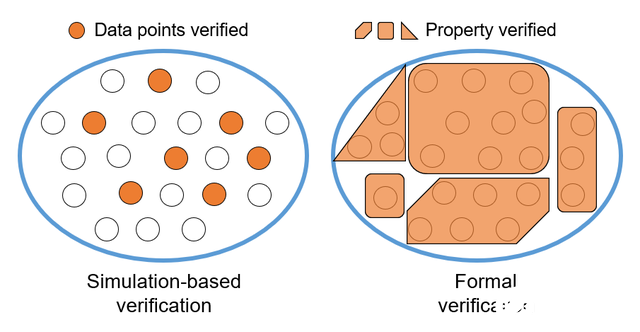
其核心思想是利用形式化的等價驗證方法來替換依賴 {仿真器+測試用例+測試平臺} 的功能性驗證方法。
對比動態仿真驗證,形式化驗證能通過系統性地覆蓋待校驗程序的屬性空間,來確保其符合規范要求(下圖對比):
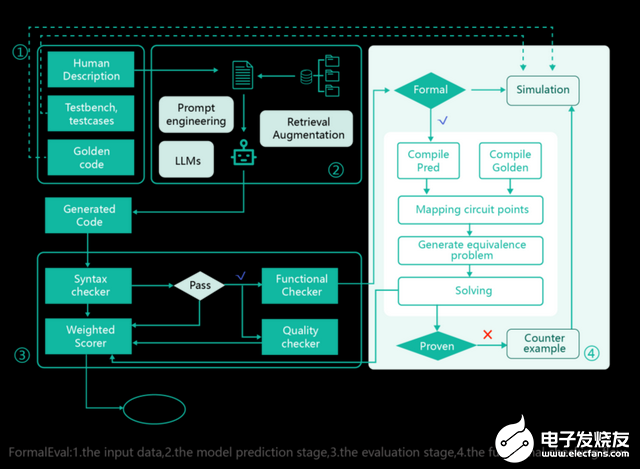
FormalEval的執行分為兩個階段。
在第一階段里,結合“提示工程”和“檢索增強”等推理技術,我們對用戶的自然語言輸入進行轉換,然后送入大模型里生成代碼。
在第二階段里,給定一組正確標記的和模型預測的代碼對,系統會從語法檢查開始評估。如果檢查通過,這對代碼將被發送到功能檢查器和質量檢查器。
如下圖右側所示,功能檢查器這個核心模塊,我們采用芯華章自研的 GalaxEC-SEC 工具來替換傳統的仿真工具,工具會給出一個 {satisfied, violated} 的二值輸出作為驗證結果,簡單明了。
來,上FormalEval實測結果
我們挑選了一個基于電路設計的數據集(RTLLM5)來驗證FormalEval,該數據集里包含了難度不一的28個設計及對應的仿真測試平臺。我們分別要求GPT-4 和 GPT-3.5針對每個設計規范生成5個候選答案,再提交給仿真測試平臺和FormalEval來檢驗。
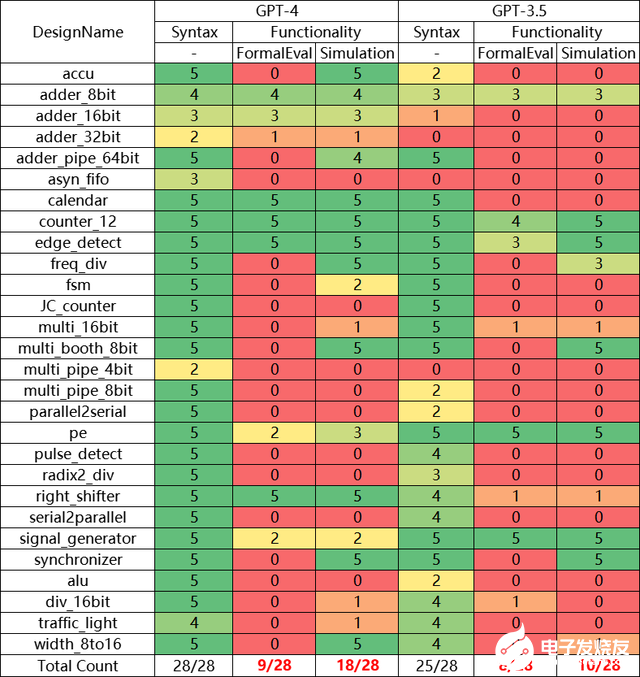
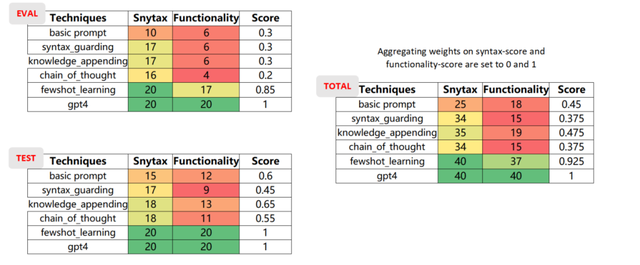
匯總檢驗結果會得到如下表格,可以看到雖然語法校驗能排查掉一部分的錯誤,但依然存在很多通過了語法校驗但功能性檢查失敗的生成代碼。
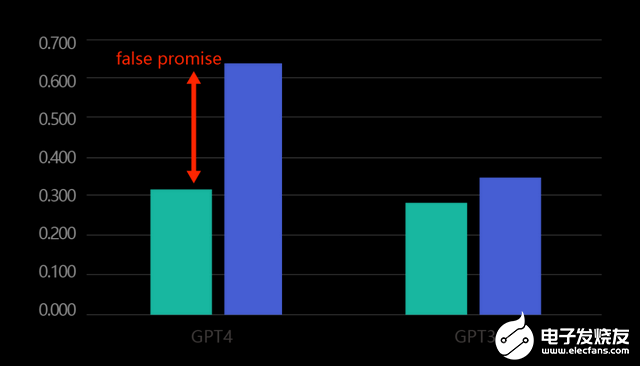
單獨對比功能性檢查的結果,可以看到FormalEval對GPT4的精度打分只有0.32,而原仿真測試則給出了0.63的高分。這是因為原仿真測試不能有效識別大量的錯誤結果。那這個比例有多高呢?
通過逐個分析FormalEval給出的錯例,我們可以確認原仿真測試工具給出了超出真實案例100%的假陽性評分,這是非常具有誤導性和危險的。
同時,因為FormalEval無需人工編寫測試用例,我們可以方便地翻倍原測試數據,以確保模型在不同測試數據集上的一致性表現。
示例:
Prompt:
The concatenation of signal and should have only 1 bit high.
LLM:
($onehot({rbF,rbE}))
結果:
當然, 等價性校驗除了在評估模型時至關重要,在提示技術選擇、數據自標注、模型性能提升、線上推斷時也都有廣泛的使用場景。
而且,除了等價性校驗,形式化方法學里的另一大分支模型檢測技術也能夠被應用在大模型產品里。
以上這些方面,芯華章的工作也正在進行中。
總結
近年來大模型徹底顛覆了學界里AI的研究方向,基于大模型的各種應用也如雨后春筍般涌現,但要真正形成成熟的產品,大模型的幻覺問題和輸出不可控問題等都是不得不解決的挑戰。
擁有一個準確、自動、高效的驗證工具能夠保證您的應用在用戶側安全,穩定地輸出符合預期的結果。如果您對FormalEval這款工具感興趣,歡迎點擊閱讀原文,申請下載論文全篇內容,我們將與您取得進一步聯系。













 工商網監
工商網監
評論