 電子發(fā)燒友App
電子發(fā)燒友App


曾經(jīng),人工智能被人們視作未來科技。但如今,人們想要看到超越人工智能的未來。在如今物聯(lián)網(wǎng)、機(jī)器人、納米科技及機(jī)器學(xué)習(xí)逐漸發(fā)展和崛起的背景下,本文試圖解讀人們對人工智能在未來五年內(nèi)發(fā)展的看法。
一、概要
很顯然,在過去幾年間,人工智能給許多領(lǐng)域造成了非常大影響。不過,人們現(xiàn)在考慮的是,人工智能在未來五年內(nèi)會在哪些領(lǐng)域發(fā)展。筆者認(rèn)為,有必要(撰寫一篇文章)描述如今我們?nèi)缃窨吹降囊恍┌l(fā)展趨勢,并對關(guān)于機(jī)器學(xué)習(xí)領(lǐng)域未來的發(fā)展做出一些預(yù)測。如下提出的列表并不一定窮舉了所有的可能,讀者也無需奉之為圭臬。但它們源自于在考慮人工智能對我們世界影響時,筆者認(rèn)為有用的一些觀點。
二、關(guān)于人工智能的十三點預(yù)測
1.人工智能工作時需要的數(shù)據(jù)量會變得更少。諸如 Vicarious 或 Geometric Intelligence 這樣的公司,正在努力減少訓(xùn)練神經(jīng)網(wǎng)絡(luò)所需要的數(shù)據(jù)集的大小。訓(xùn)練人工智能使用的數(shù)據(jù)量如今被視為其發(fā)展的主要障礙,同時也是其最主要的競爭優(yōu)勢。同時,使用概率歸納模型(probabilistic induction, Lake 等人提出, 2015)能夠解決這個在人工智能發(fā)展上的主要問題。某種不那么需要大量數(shù)據(jù)的算法,最終將會以豐富地方式學(xué)習(xí)、吸收并使用這個概念,無論是在行動上、想象上還是在探索中。
2.新的學(xué)習(xí)模型是關(guān)鍵要素。一種名為轉(zhuǎn)移學(xué)習(xí)(Transfer Learning)的技術(shù)能允許標(biāo)準(zhǔn)的強(qiáng)化學(xué)習(xí)(Reinforcement Learning)系統(tǒng)基于之前獲取的知識進(jìn)行構(gòu)建——而這是人類能輕松完成的。它隸屬于增量學(xué)習(xí)(Incremental Learning)技術(shù)。而 MetaMind 則在研究多任務(wù)學(xué)習(xí)(Multitask Learning)問題。在其中,同一個神經(jīng)網(wǎng)絡(luò)被用來解決不同類型的問題,且當(dāng)該神經(jīng)網(wǎng)絡(luò)能夠在一類問題上表現(xiàn)更好時,那么它也能在另一些問題上表現(xiàn)更好。MetaMind 的下一步發(fā)展,是引入動態(tài)神經(jīng)網(wǎng)絡(luò)(Dynamic Memory Network)的概念,它能夠回答特定問題,并能夠推斷一系列話語間的邏輯聯(lián)系。
3.人工智能會消除人類(認(rèn)知)偏差,并能讓我們變的更像“人造”的。人類的天性,將會因為人工智能而改變。Simon(1995)表示,人類不會作出完全理性的選擇,因為(做出)最優(yōu)化選擇代價高昂,還因為人腦計算能力有限(Lo, 2004)。人們常常做的是尋求滿意解,即挑選出至少是能使自己滿意的選擇。在生活中引入人工智能,或許會結(jié)束這樣的情況。當(dāng)(裝備了人工智能)人類不再受計算能力約束后,這終將會一勞永逸地回答,是認(rèn)知偏差真實存在并且是人類本能,還是這些行為只是在有限信息環(huán)境下或限制性情況下進(jìn)行決策的捷徑。Lo(2004)認(rèn)為,人類(做決策時)的滿意點,是在一系列的進(jìn)化嘗試和自然選擇的過程中形成的。在其中,個體基于過去數(shù)據(jù)和經(jīng)驗進(jìn)行預(yù)測并做出選擇。他們根據(jù)接受的正/負(fù)反饋進(jìn)行學(xué)習(xí),并能夠啟發(fā)式的快速解決相關(guān)問題。但是,一旦環(huán)境改變,適應(yīng)過程則有些延遲和緩慢,而且一些老的習(xí)慣并不能適應(yīng)新的改變——這就造成了行為偏差。人工智能則會縮減這些延遲時間到 0,虛擬化的消除任何行為偏差。
此外,基于經(jīng)驗隨時間進(jìn)行學(xué)習(xí),人工智能成為新的變革工具:我們通常不評估所有的備選決策,因為我們不能想到所有決策(知識空間有限)。
4.人工智能會被愚弄。如今的人工智能遠(yuǎn)非完美,同時也有很多人正專注于研究如何欺騙人工智能設(shè)備。最近一個被叫做對抗樣例(Adeversarial Examples; Papernot 等人, 2016; Kurakin 等人, 2016)算法被研發(fā)出來,它是首個能夠誤導(dǎo)計算機(jī)視覺的方法。智能圖像識別軟件會被經(jīng)過微妙處理的圖像所愚弄,該軟件會對這些圖像進(jìn)行錯誤地分類。但有趣的是,這種方法卻不會欺騙人類。
5.人工智能的發(fā)展伴隨著風(fēng)險。主流的聲音認(rèn)為,人工智能正越來越成為人類潛在的災(zāi)難。當(dāng)一個超級人工智能系統(tǒng)(ASI, Artificial Super Intelligence)被造出的時候,也許它的智慧遠(yuǎn)超過人類,甚至它能夠想到并做到我們今天不能預(yù)測的事情。盡管如此,我們認(rèn)為,在這些可怕的于人類存亡相關(guān)的威脅之外,還存在著不少和人工智能相關(guān)的風(fēng)險。我們對于超級人工智能會做什么、怎么做,這背后隱藏的風(fēng)險實際上都無法理解,無論它們會對人們造成正面的還是負(fù)面的影響。再之,在從狹義人工智能(Narrow Artifical Intelligence)向強(qiáng)人工智能乃至超級人工智能轉(zhuǎn)換的過程中,會產(chǎn)生一個內(nèi)在的責(zé)任風(fēng)險——誰會對可能出現(xiàn)的錯誤或者故障負(fù)責(zé)?更進(jìn)一步,在究竟誰能主導(dǎo)人工智能、人工智能的能力應(yīng)該被如何使用的方面,也同樣存在著風(fēng)險。在這種情況下,我們確實覺得,人工智能應(yīng)當(dāng)作為一個工具(或是面向所有人的公眾服務(wù))被使用,并預(yù)留一定程度的決策權(quán)給人類以幫助該系統(tǒng)處理罕見的意外情況。
6.真正的通用性人工智能很可能是一種集體智能(Collective Intelligence)。強(qiáng)人工智很有可能不會是一個具有強(qiáng)大決策功能的單一終端,而是一種集體智能。群體智能(Swarm or Collective Intelligence, Rosenberg, 2015;2016)可以被視作“一群大腦的大腦”。到目前為止,我們僅讓個體提供輸入值,然后我們以一種“平均情緒”的智能方式整合這些事后輸入。Rosenberg 稱,現(xiàn)存的實現(xiàn)人類集體智能的方法,甚至都不允許用戶之間互相影響。它們通常的處理方式,是只允許影響非同步出現(xiàn)——這會導(dǎo)致群體性偏差。另一方面,人工智能則會解決這樣的聯(lián)通缺陷,并且創(chuàng)建一個與其他物種非常相像的統(tǒng)一的集體智慧。自然中較好的例子來自于蜜蜂,它們進(jìn)行決策的方式和人類神經(jīng)運作的方式非常相像。它們都是用了大量的可執(zhí)行單元,它們同步運行,能夠整合噪聲、權(quán)衡替代方案,并最后能夠形成特定的決策。Rosenberg 認(rèn)為,這個決策經(jīng)過在分布的可執(zhí)行單元和子群上的實時閉環(huán)競爭而最終形成。每一個子群都支持一個不同的選擇,而最后共識的達(dá)成不是經(jīng)過經(jīng)過類似“平均情緒”的方法由大眾決定,而是以一種“足夠激勵量”(Sufficient Quorum of Excitation, Rosenberg, 2015)的方式確定的。對于替代方案的抑制機(jī)制,由其他子群產(chǎn)生,能夠避免整體系統(tǒng)達(dá)到一個局部優(yōu)化決策。
7.人工智能會帶來無法預(yù)期的社會政治影響。人工智能首先帶來的社會經(jīng)濟(jì)方面的影響,是失業(yè)問題。盡管從一方面來說這是一個非常現(xiàn)實的問題(當(dāng)然也在很多方面帶來了機(jī)會),我們認(rèn)為也應(yīng)當(dāng)從其他不同的方面來看這個問題。第一,工作機(jī)會是被完全地摧毀了,而是會變得不同。因為數(shù)據(jù)將能被個人而非企業(yè)直接獲取和分析,因而許多服務(wù)會逐步消失。并且,人工智能會使得知識分布趨于分散化。我們認(rèn)為在這場革命中更應(yīng)該關(guān)切的,是它帶來的雙重后果。首先,使用更聰明的(人工智能)系統(tǒng)后,在特定的領(lǐng)域內(nèi),越來越多人將喪失它們的專業(yè)性。這預(yù)示著,人工智能軟件需要被設(shè)計整合一套雙重反饋系統(tǒng),能夠整合人類和機(jī)器的處理方法。我們的第二點擔(dān)憂和之前提到的第一個風(fēng)險相關(guān),我們擔(dān)心人類將淪為“機(jī)器技術(shù)員”。因為大家都認(rèn)為人工智能更擅長于解決問題,覺得它們很更可靠(,所以我們會更多地部署人工智能系統(tǒng))。這種惡性循環(huán)將會讓我們變得更沒有創(chuàng)造力、失去獨創(chuàng)力、更不聰明,并會以指數(shù)地增加人機(jī)的差異。我們正體驗著這樣的系統(tǒng),或是當(dāng)我們使用它時我們會更聰明,或是當(dāng)我們不使用它時我們會覺得糟糕。我們希望人工智能更傾向于變?yōu)榍罢撸皇菐硇碌摹?a target="_blank">智能手機(jī)效應(yīng)”——我們會完全地依賴于它。最后,這個世界正變得越來越對機(jī)器人友好,人類在其中也扮演著連接機(jī)器人的角色而與之對立。機(jī)器人(在社會中)正逐步起到主導(dǎo)作用,它們對人類的影響相比人類對他們的影響也越來越大,這也許會讓人類最終變?yōu)椋ㄉ鐣到y(tǒng)中的那個)“故障”。
而在地緣政治方面,我們則認(rèn)為人工智能會對全球化造成巨大的影響。有這樣的可能,由人工智能系統(tǒng)控制機(jī)器人運行的被優(yōu)化的工廠,其廠址最終會重新回到發(fā)達(dá)國家。因為(到那時)在新興國家建廠,會失去那些傳統(tǒng)的低成本的理由。我們不清楚,這是會平衡國家之間的差異,還是會增大發(fā)達(dá)國家和發(fā)展中國家間已經(jīng)存在的差異。
8.真正的人工智能應(yīng)該開始問“為什么”。到目前,大多機(jī)器學(xué)習(xí)系統(tǒng)都能夠在模式識別及輔助決策方面做的很好;并且因為大部分程序都被硬編碼了,所以它們?nèi)阅軌虮焕斫狻1M管我們已經(jīng)能讓人工智能闡明“是什么”和“如何做”,這已經(jīng)是一個不錯的成就,但人工智能仍未能夠理解事物背后的“為什么”。因此,我們需要設(shè)計一個通用算法,它能夠從物理上及精神上建立關(guān)于世界本質(zhì)的模型(Lake 等人, 2016)。
9.人工智能正在推進(jìn)隱私保護(hù)問題和數(shù)據(jù)泄漏預(yù)防問題。人工智能將隱私問題提升到了一個新的等級。新的隱私保護(hù)方法應(yīng)當(dāng)被發(fā)明及采用,它們應(yīng)當(dāng)比簡單的安全多方計算法(SMPC)復(fù)雜得多,也應(yīng)該比同態(tài)加密法(homomorphic encryption)高效迅速。最近的研究表明,差分隱私(Differential Privacy)法能夠解決大部分我們?nèi)粘S龅降碾[私問題。不過已經(jīng)有不少公司走得更遠(yuǎn),如 Post-Quantum 公司——這是一家基于量子計算的網(wǎng)絡(luò)安全創(chuàng)業(yè)公司。
10.人工智能正在改變物聯(lián)網(wǎng)(設(shè)備)。人工智能(的發(fā)展)允許物聯(lián)網(wǎng)設(shè)備能被以完全分布式的架構(gòu)進(jìn)行設(shè)計,在其中每一個節(jié)點都能夠進(jìn)行自己的預(yù)算(也就所謂的邊界計算)。在傳統(tǒng)的中心化模型中,有一個被稱作是服務(wù)器/客戶端模型的問題。其中的每一臺設(shè)備都連接到云端服務(wù)器,并由云端服務(wù)器識別、驗證,這導(dǎo)致了非常昂貴的設(shè)備費用。但基于分布式方法設(shè)計的物聯(lián)網(wǎng)網(wǎng)絡(luò)或是傳統(tǒng)的點對點(Peer-to-Peer, P2P)架構(gòu),則能夠解決這個問題、降低費用,并能夠避免因一個節(jié)點實效而造成整個系統(tǒng)損壞的問題。
11.機(jī)器人學(xué)正變?yōu)橹髁鳌9P者認(rèn)為,人工智能的發(fā)展會受到機(jī)器人學(xué)發(fā)展的制約。同時,這兩個關(guān)聯(lián)的領(lǐng)域會以相同的速度發(fā)展,以最終得到一個適當(dāng)?shù)膹?qiáng)人工智能或超級人工智能。如下圖所示,在我們的研究乃至我們的集體意識中,我們不會視那種沒有“物理實體”的人工智能為強(qiáng)人工智能或超級人工智能。
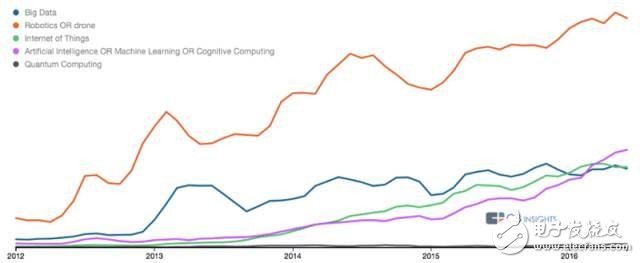
關(guān)于機(jī)器人學(xué)及人工智能相關(guān)領(lǐng)域的研究趨勢(由 CBInsights Trends tool 制作)
另外還有一些證據(jù)能證明這個趨勢:
最近激增的機(jī)器人相關(guān)專利申請數(shù)量。據(jù) IFI 稱,中國(近期)已經(jīng)有超過 3000 項目申請,在美國、歐洲、日本、韓國等地的數(shù)量大致相同。
如下圖所示的最近機(jī)器人相關(guān)基金的價格走向。
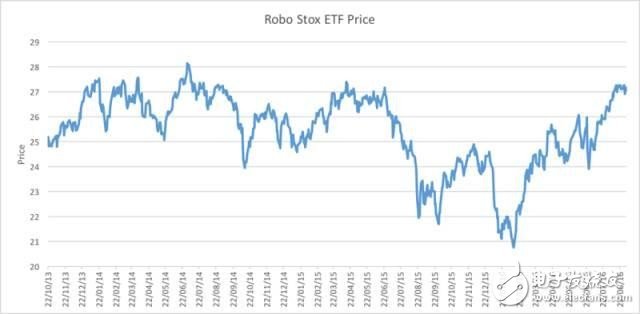
機(jī)器人 STOX 基金從 2013 年至 2016 年的價格走向
12.人工智能在發(fā)展中也許會面臨阻礙。在實現(xiàn)強(qiáng)人工智能的過程中面臨的最大阻礙,不是算法的選擇或數(shù)據(jù)的使用(至少不只是),而是一個結(jié)構(gòu)上的問題。硬件性能、(設(shè)備間)物理的聯(lián)系(如互聯(lián)網(wǎng))及設(shè)備的耗能,是創(chuàng)建足夠快人工智能的瓶頸。這也是我相信存在著如 Google Fiber 這樣部門的原因,也是為什么量子計算正變得越來越相關(guān)的原因。量子計算允許我們以超高的速度進(jìn)行運算(根據(jù)物理規(guī)則它會瞬間完成),而這在傳統(tǒng)電腦上會耗費非常長的時間。它依靠量子力學(xué)的性質(zhì),基于傳統(tǒng)計算機(jī)用二進(jìn)制描述問題的想法。因此,據(jù) Frank Chen(在 Andreessen Horowitz 的合伙人)稱,晶體管、半導(dǎo)體及電子導(dǎo)體都將被量子比特所取代。量子比特由向量表示,這也意味著其運算律會不同于的傳統(tǒng)的布爾代數(shù)規(guī)則。
一種對傳統(tǒng)計算法和量子計算法區(qū)別的通俗比較,基于電話本問題(Phonebook Problem)。在電話本中搜尋號碼,傳統(tǒng)的方式是一條接著一條地搜索以最終找到匹配的號碼。但基本的量子搜索算法(也被叫做 Grover‘s 算法)則依靠所謂的“量子疊加態(tài)”。它能一次性分析所有的元素并確定最可能的答案。
建造量子計算也許會是科學(xué)界革命性的突破,但 Chen 表示現(xiàn)在建造它是非常困難的。亟待解決問題包括:建造計算機(jī)的超導(dǎo)材料需要的高溫,極短的貫通時間(Coherence Time)——這是量子計算機(jī)實際進(jìn)行計算的時間窗口,單次計算所需的時間,以及正誤答案之間的能量差過小難于被探測到。所有這些問題縮小了(量子計算機(jī)的)市場空間,并且只有小部分公司能夠涉足量子計算領(lǐng)域:科技界的巨擘如 IBM 和 Intel 已經(jīng)對其研究多年;創(chuàng)新公司如 D-Wave System(2013 年被谷歌收購)、Rigetti Computing、QxBranch、1Qbit、Post-Quantum、ID Quantique、Eagle Power Technologies、Qubitekk、QC Ware、Nano-Meta Technonoliges;還有奠定量子計算基礎(chǔ)的 Cambridge Quantum Computing 有限公司。
13.生物機(jī)器人和納米科技將是未來人工智能的應(yīng)用方向。我們正見證著在人工智能和納米機(jī)器人交叉領(lǐng)域,一些列令人震驚的發(fā)展。研究人員正致力于創(chuàng)造完全完全智能的裝置,同時也在研究相關(guān)的結(jié)合體。他們甚至嘗試研發(fā)出生物導(dǎo)線(一種由細(xì)菌制造的導(dǎo)線)及器官芯片(由人細(xì)胞制作的、人器官中起功能部分的微型模型,能夠復(fù)制器官的部分功能;在該領(lǐng)域,Emulate 是最領(lǐng)先的公司)。生物機(jī)器人方面的研究同時也考驗著著材料性能的極限。最近一種“軟”機(jī)器人被制造出來,他只有軟的構(gòu)建。BAS Systems 公司也在推進(jìn)計算的發(fā)展,正嘗試研發(fā)一種“化學(xué)計算機(jī)”(Chemputer),一種能夠使用先進(jìn)化學(xué)過程以“生長”復(fù)雜電子系統(tǒng)的裝置。







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論