 電子發(fā)燒友App
電子發(fā)燒友App


人工智能那么火熱,作為游戲行業(yè)的技術(shù)人員可定也不會放過,今天,我們就一起來聊聊,在游戲中人工智能是如何實(shí)現(xiàn)深度學(xué)習(xí)技術(shù)的。
我們關(guān)注基于深度學(xué)習(xí)的游戲 AI 中廣泛存在的問題以及使用的環(huán)境,如 Atari/ALE、《毀滅戰(zhàn)士》(Doom)、《我的世界》(Minecraft)、《星際爭霸》(StarCraft)和賽車游戲。另外,我們綜述了現(xiàn)有的研究,指出亟待解決的重要挑戰(zhàn)。我們對能夠玩好電子游戲(非棋類游戲,如圍棋等)的方法很感興趣。本文分析了多種游戲,指出這些游戲給人類和機(jī)器玩家?guī)淼奶魬?zhàn)。必須說明,本文并未涉及所有 AI 在游戲中的應(yīng)用,而是專注于深度學(xué)習(xí)方法在電子游戲中的應(yīng)用。深度學(xué)習(xí)并非唯一應(yīng)用于游戲中的 AI 方法,其他有效方法還有蒙特卡洛樹搜索 [12] 和進(jìn)化計算 [85], [66]。
深度學(xué)習(xí)概述
本節(jié)我們概述了應(yīng)用于電子游戲中的深度學(xué)習(xí)方法,及多種方法結(jié)合起來的混合方法。
A. 監(jiān)督學(xué)習(xí)
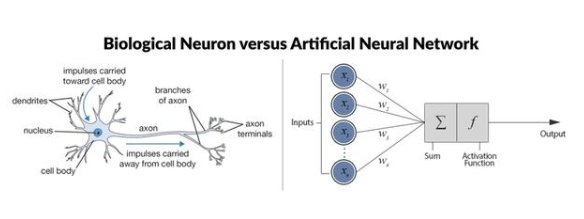
在人工神經(jīng)網(wǎng)絡(luò)(ANN)的監(jiān)督訓(xùn)練中,智能體通過樣本進(jìn)行學(xué)習(xí) [56], [86]。智能體需要做出決策(已知正確答案),之后,使用誤差函數(shù)確定智能體提供的答案和真正答案之間的區(qū)別;這將作為損失用于更新模型。在大數(shù)據(jù)集上進(jìn)行訓(xùn)練后,智能體應(yīng)該學(xué)習(xí)通用模型,使之在未見過的輸入上依然表現(xiàn)良好。
這些神經(jīng)網(wǎng)絡(luò)的架構(gòu)大致可分為兩個主要范疇:前饋網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)。
B. 無監(jiān)督學(xué)習(xí)
無監(jiān)督學(xué)習(xí)的目標(biāo)不是學(xué)習(xí)數(shù)據(jù)和標(biāo)簽之間的映射,而是在數(shù)據(jù)中發(fā)現(xiàn)模式。這些算法可以學(xué)習(xí)數(shù)據(jù)集的特征分布,用于集中相似的數(shù)據(jù)、將數(shù)據(jù)壓縮成必要特征,或者創(chuàng)建具備原始數(shù)據(jù)特征的新的合成數(shù)據(jù)。
深度學(xué)習(xí)中有多種不同的技術(shù)允許使用無監(jiān)督學(xué)習(xí)。其中最重要的是自編碼器技術(shù),這種神經(jīng)網(wǎng)絡(luò)嘗試輸出自我輸入的復(fù)制版本。
C. 強(qiáng)化學(xué)習(xí)方法
在用于游戲的強(qiáng)化學(xué)習(xí)中,智能體通過與環(huán)境互動來學(xué)習(xí)打游戲。其目標(biāo)在于學(xué)習(xí)策略,即每一步需要用什么操作才能達(dá)到想要的狀態(tài)。這種情況通常出現(xiàn)在電子游戲中,玩家每一步可以采取的操作數(shù)量有限,動作的順序決定玩家玩的如何。
D. 進(jìn)化方法
另一個訓(xùn)練神經(jīng)網(wǎng)絡(luò)的方法基于進(jìn)化算法。該方法通常指神經(jīng)進(jìn)化(neuroevolution,NE),可以優(yōu)化網(wǎng)絡(luò)權(quán)重和拓?fù)洹Ec基于梯度下降的訓(xùn)練方法相比,NE 方法的優(yōu)勢在于不要求網(wǎng)絡(luò)可微分,且可用于監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)問題。
E. 混合方法
近期,研究者開始研究適用于玩電子游戲的混合方法,即將深度學(xué)習(xí)方法和其他機(jī)器學(xué)習(xí)方法結(jié)合起來。
這些混合方法旨在結(jié)合兩種方法的優(yōu)點(diǎn):深度學(xué)習(xí)方法能夠直接從高維原始像素值中學(xué)習(xí),進(jìn)化方法不需要依賴可微分架構(gòu),且在稀疏獎勵的游戲中表現(xiàn)良好。
在棋類游戲中有重大意義的混合方法是 AlphaGo [97],該方法依賴深度神經(jīng)網(wǎng)絡(luò)和樹搜索方法,打敗了圍棋領(lǐng)域的世界冠軍。
游戲類型和研究平臺
本節(jié)概述流行的游戲類型和研究平臺(與深度學(xué)習(xí)相關(guān))。我們簡略地概述了這些游戲的特點(diǎn)和算法在玩游戲時遇到的挑戰(zhàn)。
A. 街機(jī)游戲
經(jīng)典的街機(jī)游戲是上世紀(jì) 70 年代晚期 80 年代早期流行的游戲類型,在過去十年中這種游戲常常作為 AI 的測試基準(zhǔn)。
街機(jī)游戲的代表性平臺是 Atari 2600、Nintendo NES、Commodore 64 和 ZX Spectrum。大多數(shù)經(jīng)典街機(jī)游戲的特點(diǎn)是在二維空間中的移動、圖文邏輯(graphical logic)的大量使用、連續(xù)時間進(jìn)度(continuous-time progression),以及連續(xù)空間或離散空間移動。這類游戲的挑戰(zhàn)因游戲而異,不過大部分此類游戲都需要快速反應(yīng)和抓住時機(jī)。很多游戲需要優(yōu)先處理多個同時發(fā)生的事件,這要求預(yù)測游戲中其他實(shí)體的行為或軌跡。另一個普遍要求是穿過迷宮或其他復(fù)雜環(huán)境,比如吃豆人(Pac-Man,1980 年出現(xiàn)的游戲)和鉆石小子(Boulder Dash,1984 年出現(xiàn)的游戲)。
最著名的用于深度學(xué)習(xí)方法的游戲平臺是街機(jī)模式學(xué)習(xí)環(huán)境(Arcade Learning Environment,ALE)[6]。ALE 由 Atari 2600 模擬機(jī) Stella 打造,包含 50 個 Atari 2600 游戲。該框架抽取游戲得分、160×210 的屏幕像素和可用于游戲智能體的輸入的 RAM 內(nèi)容。該平臺是第一批深度強(qiáng)化學(xué)習(xí)論文(使用原始像素作為輸入)探索的主要環(huán)境。
另一個經(jīng)典的街機(jī)游戲平臺是 Retro Learning Environment(RLE),目前該平臺包含 7 個發(fā)布到超級任天堂(SNES)的游戲 [9]。這些游戲中很多都有 3D 圖畫,控制器允許超過 720 種組合操作,這使得 SNES 游戲比 Atari 2600 游戲更加復(fù)雜和生動,但這個環(huán)境目前沒有 ALE 那么流行。
圖 1. 作為深度學(xué)習(xí)研究平臺的幾款游戲的截圖。
B. 競速游戲
競速游戲中,玩家控制某種車或某個人物在最短的時間內(nèi)到達(dá)目的地,或者在給定時間內(nèi)沿軌道行駛最遠(yuǎn)的距離。通常情況下,該游戲使用第一人稱視角或玩家控制車輛的后方有利的位置作為視角。
競速游戲中的一個普遍挑戰(zhàn)是智能體需要利用微調(diào)后的持續(xù)輸入來控制車輛的位置,調(diào)整加速或剎車,以盡快走完軌道。這至少需要短期規(guī)劃、一次或兩次轉(zhuǎn)彎。如果游戲中還需要管理其他資源,如能源、破壞或提速,則還需要長期規(guī)劃。如果軌道上出現(xiàn)其他車輛,還需要加入對抗規(guī)劃,以管理或阻止超車。
帶 3D 圖像的視覺強(qiáng)化學(xué)習(xí)經(jīng)常使用的環(huán)境是開源賽車模擬器 TORCS [121]。
C. 第一人稱射擊游戲(FPS)
近期,第一人稱射擊游戲(FPS)設(shè)置成為適合視覺強(qiáng)化學(xué)習(xí)智能體的先進(jìn)游戲環(huán)境。與 ALE 基準(zhǔn)中的經(jīng)典街機(jī)游戲相比,F(xiàn)PS 具備 3D 圖像,狀態(tài)部分可觀測,因此是更加生動的研究環(huán)境。通常的游戲視角是玩家控制的人物的視角,但 FPS 范疇內(nèi)的多款游戲采用了過肩視角。這種設(shè)計造成的挑戰(zhàn)是快速感知和快速反應(yīng),尤其是看到敵人并快速瞄準(zhǔn)時。但是也存在其他認(rèn)知挑戰(zhàn),包括在復(fù)雜的三維環(huán)境中定向和移動,預(yù)測多個敵人的動作和位置;某些游戲模式還需要團(tuán)隊合作。如果游戲中使用了視覺輸入,那么從像素中抽取相關(guān)信息也是一個挑戰(zhàn)。
ViZDoom 是一個 FPS 平臺,該框架允許智能體使用屏幕緩沖作為輸入來玩經(jīng)典的第一人稱射擊游戲 Doom[50]。DeepMind Lab 是一個基于《雷神之錘》(Quake III)Arena 引擎的三維導(dǎo)航和解謎任務(wù)平臺 [2]。
D. 開放世界游戲
開放世界游戲,如 Minecraft、Grand Theft Auto V,這類游戲的特點(diǎn)是非線性,有一個很大的游戲世界供玩家探索,沒有既定目標(biāo)或清晰的內(nèi)在次序,玩家在既定時間內(nèi)有很大的操作自由。智能體的關(guān)鍵挑戰(zhàn)是探索游戲世界,設(shè)定真實(shí)、有意義的目標(biāo)。鑒于這是一項(xiàng)非常復(fù)雜的挑戰(zhàn),大部分研究使用這些開放環(huán)境探索強(qiáng)化學(xué)習(xí)方法,這些方法可以重用和遷移學(xué)得的知識到新的任務(wù)中。Project Malmo 是一個根據(jù)開放世界游戲 Minecraft 構(gòu)建的平臺,可用于定義多種復(fù)雜問題 [43]。
E. 即時戰(zhàn)略游戲
這類游戲中玩家控制多個人物或單元,游戲目標(biāo)是在競賽或戰(zhàn)爭中獲勝。即時戰(zhàn)略游戲的關(guān)鍵挑戰(zhàn)是制定和執(zhí)行涉及多個單元的復(fù)雜計劃。這個挑戰(zhàn)通常比經(jīng)典棋類游戲如象棋中的規(guī)劃挑戰(zhàn)更難,因?yàn)槎鄠€單元會隨時移動,有效的分支因子通常非常大。另外一個挑戰(zhàn)是預(yù)測一個或多個敵人的移動,敵人本身就有多個單元。即時戰(zhàn)略游戲(RTS)在戰(zhàn)略游戲本就很多的挑戰(zhàn)之上又增加了時間優(yōu)先次序(time prioritization)的挑戰(zhàn)。
星際爭霸游戲系列無疑是即時戰(zhàn)略游戲中研究最多的游戲。《星際爭霸·母巢之戰(zhàn)》的 API(BWAPI)使軟件可以在游戲運(yùn)行中與星際爭霸交流,如抽取狀態(tài)特征、執(zhí)行操作。BWAPI 曾廣泛應(yīng)用于游戲 AI 研究,但是目前只有少數(shù)使用了深度學(xué)習(xí)。近期根據(jù) BWAPI 構(gòu)建的庫 TorchCraft 將科學(xué)計算框架 Torch 和 StarCraft 聯(lián)系起來,使用機(jī)器學(xué)習(xí)方法研究該游戲 [106]。DeepMind 和暴雪(星際爭霸的開發(fā)者)已經(jīng)開發(fā)了機(jī)器學(xué)習(xí) API,以支持機(jī)器學(xué)習(xí)在星際爭霸 2 中的研究 [114]。該 API 包含多個小挑戰(zhàn),盡管它支持 1v1 游戲設(shè)置。有兩個抽象出來的 RTS 游戲引擎值得一提:RTS [77] 和 ELF [109],后者實(shí)現(xiàn)了 RTS 游戲中的多個特征。
F. OpenAI Gym & Universe
OpenAI Gym 是一個對比強(qiáng)化學(xué)習(xí)算法和單獨(dú)接口的大型平臺,該接口包含一系列不同的環(huán)境,包括 ALE、MuJoCo、Malmo、ViZ-Doom 等等 [11]。OpenAI Universe 是 OpenAI Gym 的擴(kuò)展,目前可以接入一千多個 Flash 游戲,并且計劃接入更多現(xiàn)代電子游戲。
玩游戲的深度學(xué)習(xí)方法
A. 街機(jī)游戲
街機(jī)模式學(xué)習(xí)環(huán)境(ALE)已經(jīng)成為深度強(qiáng)化學(xué)習(xí)算法直接從原始像素中學(xué)習(xí)控制策略的主要試驗(yàn)平臺。本節(jié)概述 ALE 中的主要進(jìn)展。
深度 Q 網(wǎng)絡(luò)(DQN)是第一個在 Atari 游戲中展示人類專業(yè)玩家控制水平的學(xué)習(xí)算法 [70]。該算法在七種 Atari 2600 游戲中進(jìn)行測試,表現(xiàn)優(yōu)于之前的方法,如具備特征構(gòu)建 [3] 和神經(jīng)卷積 [34] 的 Sarsa 算法,并在三種游戲上表現(xiàn)優(yōu)于人類專業(yè)水平。
深度循環(huán) Q 學(xué)習(xí)(DRQN)在輸出前使用循環(huán)層擴(kuò)展 DQN 架構(gòu),這對狀態(tài)部分可觀測的游戲效果很好。
Q 學(xué)習(xí)算法存在一個問題,即它通常高估動作值。基于雙 Q 學(xué)習(xí) [31] 的雙 DQN 通過學(xué)習(xí)兩個價值網(wǎng)絡(luò)降低觀測到的過高估計值,兩個價值網(wǎng)絡(luò)在更新時互為目標(biāo)網(wǎng)絡(luò) [113]。
Dueling DQN 使用的網(wǎng)絡(luò)在卷積層后可以分成兩個流,分別估計狀態(tài)值 V π (s) 和動作優(yōu)勢(action-advantage)Aπ (s, a),使 Qπ (s, a) = V π (s) + Aπ (s, a) [116]。Dueling DQN 優(yōu)于雙 DQN,且能夠連接優(yōu)先經(jīng)驗(yàn)回放。
本節(jié)還描述了 Advantage Actor-Critic (A3C) 算法、使用漸進(jìn)神經(jīng)網(wǎng)絡(luò)的 A3C 算法 [88]、非監(jiān)督強(qiáng)化和輔助學(xué)習(xí)(UNsupervised REinforcement and Auxiliary Learning,UNREAL)算法、進(jìn)化策略(Evolution Strategies,ES)等算法。
B. Montezuma‘s Revenge(略)
C. 競速游戲
Chen et al 認(rèn)為基于視覺的自動駕駛通常存在兩種范式 [15]:(1)直接學(xué)習(xí)將圖像映射到動作的端到端系統(tǒng)(行為反射);(2)分析傳感器數(shù)據(jù),制定明智決策的系統(tǒng)(介導(dǎo)感知)。
策略梯度方法,如 actor-critic [17] 和確定性策略梯度(Deterministic Policy Gradient,DPG)[98],可以在高維、持續(xù)的動作空間中學(xué)習(xí)策略。深度確定性策略梯度是一種實(shí)現(xiàn)回放記憶和獨(dú)立目標(biāo)網(wǎng)絡(luò)的策略梯度方法,二者都極大提升了 DQN。深度確定性策略梯度方法曾用于利用圖像訓(xùn)練 TORCS 的端到端 CNN 網(wǎng)絡(luò) [64]。
前面提到的 A3C 方法也被應(yīng)用于競速游戲 TORCS,僅使用像素作為輸入 [69]。
D. 第一人稱射擊游戲
使用同步定位與地圖構(gòu)建(Simultaneous Localization and Mapping,SLAM)從屏幕和深度緩沖區(qū)獲取位置推斷和物體映射,這二者也能改善 DQN 在《毀滅戰(zhàn)士》游戲中的效果 [8]。
死亡競賽的冠軍使用了直接未來預(yù)測(Direct Future Prediction,DFP)方法,該方法的效果優(yōu)于 DQN 和 A3C [18]。DFP 使用的架構(gòu)有三個流:一個用于屏幕像素,一個用于描述智能體當(dāng)前狀態(tài)的低維評估,一個用于描述智能體的目標(biāo),即優(yōu)先評估的線性結(jié)合。
3D 環(huán)境中的導(dǎo)航是 FPS 游戲所需的一個重要技巧,并且已經(jīng)被廣泛研究。CNN+LSTM 網(wǎng)絡(luò)使用 A3C 訓(xùn)練,A3C 用預(yù)測像素深度和環(huán)閉合的額外輸出擴(kuò)展而成,顯示出顯著改善 [68]。
內(nèi)在好奇心單元(Intrinsic Curiosity Module,ICM)包括多個神經(jīng)網(wǎng)絡(luò),在每個時間步內(nèi)基于智能體無法預(yù)測動作結(jié)果來計算內(nèi)在獎勵。
E. 開放世界游戲
分層深度強(qiáng)化學(xué)習(xí)網(wǎng)絡(luò)(Hierarchical Deep Reinforcement Learning Network,H-DRLN)架構(gòu)實(shí)現(xiàn)終身學(xué)習(xí)框架,該框架能夠在游戲《我的世界》的簡單任務(wù)中遷移知識,比如導(dǎo)航、道具收集和布局任務(wù) [108]。H-DRLN 使用一個變種策略振蕩 [87] 來保留學(xué)得的知識,并將其封裝進(jìn)整個網(wǎng)絡(luò)。
F. 即時戰(zhàn)略游戲
即時戰(zhàn)略(RTS)游戲的環(huán)境更加復(fù)雜,玩家必須在部分可觀測的地圖中實(shí)時同步控制多個智能體。
即時戰(zhàn)略主要有以下幾種方法:
獨(dú)立 Q 學(xué)習(xí)(IQL)將多智能體強(qiáng)化學(xué)習(xí)問題簡化,智能體學(xué)習(xí)一種策略,可以獨(dú)立控制單元,而將其他智能體當(dāng)作環(huán)境的一部分 [107]。
多智能體雙向協(xié)調(diào)網(wǎng)絡(luò)(BiCNet)基于雙向 RNN 實(shí)現(xiàn)一種向量化的 actor-critic 框架,其中一個向度適用于每一個智能體,其輸出為一系列操作 [82]。
Counterfactual multi-agent(COMA)策略梯度是一種 actor-critic 方法,該方法具備一個中心化的 critic 和多個去中心化的 actor,用 critic 網(wǎng)絡(luò)計算出的反事實(shí)基線(counterfactual baseline)來解決多智能體信度分配的問題 [21]。
G. Physics Games(略)
H. 基于文本的游戲
這類游戲中的狀態(tài)和操作都以文本的形式呈現(xiàn),是一種特殊的電子游戲類型。研究者專門設(shè)計了一種叫作 LSTM-DQN [74] 的網(wǎng)絡(luò)架構(gòu)來玩這類游戲。使用 LSTM 網(wǎng)絡(luò)可以把文本從世界狀態(tài)轉(zhuǎn)換成向量表征,評估所有可能的狀態(tài)動作對(state-action pair)的 Q 值。
開放性挑戰(zhàn)
深度學(xué)習(xí),特別是深度強(qiáng)化學(xué)習(xí)方法,在電子游戲中取得了卓越的成果,但是仍然存在大量重要的開放性挑戰(zhàn)。本節(jié)我們將對此進(jìn)行概述。
A. 通用電子游戲
圖 3. 本文討論的深度學(xué)習(xí)技術(shù)的影響力圖
圖 3中每一個節(jié)點(diǎn)代表一個算法,顏色代表游戲基準(zhǔn),與中心的距離代表原始論文在 arXiv 上的發(fā)表時間,箭頭表示技術(shù)之間的關(guān)系,每一個節(jié)點(diǎn)指向所有使用或修改過該技術(shù)的節(jié)點(diǎn)。本論文未討論的影響力則不在圖中出現(xiàn)。
B. 稀疏獎勵的游戲
C. 多智能體學(xué)習(xí)
D. 計算資源
E. 深度學(xué)習(xí)方法在游戲產(chǎn)業(yè)中的應(yīng)用情況
F. 游戲開發(fā)交互工具
G. 創(chuàng)造新型電子游戲
H. 終身適應(yīng)性
I. 與人類相似的玩游戲方式
J. 性能水平可調(diào)整的智能體
K. 游戲的學(xué)習(xí)模型
L. 處理大型決策空間
結(jié)論
本論文對應(yīng)用到電子游戲中的深度學(xué)習(xí)方法進(jìn)行了綜述,涉及到的電子游戲類型包括:街機(jī)游戲、競速游戲、第一人稱射擊游戲、開放世界游戲、即時戰(zhàn)略游戲、物理游戲和基于文本的游戲。涉及到的多數(shù)工作研究端到端無模型深度強(qiáng)化學(xué)習(xí),其中卷積神經(jīng)網(wǎng)絡(luò)能夠通過游戲互動從原始像素中直接學(xué)習(xí)玩游戲。一些研究還展示了使用監(jiān)督學(xué)習(xí)從游戲日志中學(xué)習(xí),讓智能體自己在游戲環(huán)境中展開互動的模型。對于一些簡單的游戲,如很多街機(jī)游戲,本文談及的很多方法的表現(xiàn)已經(jīng)超過人類水平,而復(fù)雜度更高的游戲還面臨很多開放性挑戰(zhàn)。





















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論