 電子發燒友App
電子發燒友App


注意力機制即Attention mechanism在序列學習任務上具有巨大的提升作用,在編解碼器框架內,通過在編碼段加入A模型,對源數據序列進行數據加權變換,或者在解碼端引入A模型,對目標數據進行加權變化,可以有效提高序列對序列的自然方式下的系統表現。
什么是Attention?
Attention模型的基本表述可以這樣理解成(我個人理解):當我們人在看一樣東西的時候,我們當前時刻關注的一定是我們當前正在看的這樣東西的某一地方,換句話說,當我們目光移到別處時,注意力隨著目光的移動野在轉移,這意味著,當人們注意到某個目標或某個場景時,該目標內部以及該場景內每一處空間位置上的注意力分布是不一樣的。這一點在如下情形下同樣成立:當我們試圖描述一件事情,我們當前時刻說到的單詞和句子和正在描述的該事情的對應某個片段最先關,而其他部分隨著描述的進行,相關性也在不斷地改變。從上述兩種情形,讀者可以看出,對于Attention的作用角度出發,我們就可以從兩個角度來分類Attention種類:空間注意力和時間注意力,即Spatial Attention 和Temporal Attention。這種分類更多的是從應用層面上,而從Attention的作用方法上,可以將其分為Soft Attention和Hard Attention,這既我們所說的,Attention輸出的向量分布是一種one-hot的獨熱分布還是soft的軟分布,這直接影響對于上下文信息的選擇作用。
為什么要加入Attention?
再解釋了Attention做了一件什么事之后,我們討論一下為什么需要Attention模型,即Attention加入的動機:
序列輸入時,隨著序列的不斷增長,原始根據時間步的方式的表現越來越差,這是由于原始的這種時間步模型設計的結構有缺陷,即所有的上下文輸入信息都被限制到固定長度,整個模型的能力都同樣收到限制,我們暫且把這種原始的模型稱為簡單的編解碼器模型。
編解碼器的結構無法解釋,也就導致了其無法設計。
Attention到底是什么原理?
下面我們來看一下Attention的具體原理:
首先讓編碼器輸出結構化的表示,假設這些表示,可以用下述集合表示,(Hold不住了,我要截圖了,太麻煩了!!!)
由于定長上下文特征表示帶來的信息損失,同時也是一種缺陷,由于不同的時間片或者空間位置的信息量明顯有差別,利用定常表示無法很好的解決損失的問題,而Attention則恰好解決了這個問題。
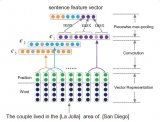
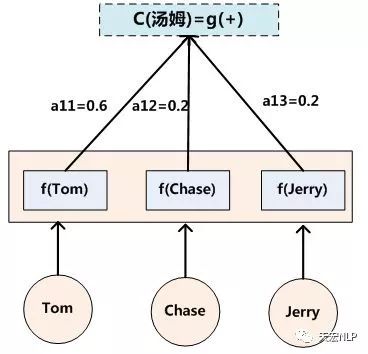
我們甚至可以進一步解釋,編解碼器內部大致是如何工作的,當然從我看來這有點馬后炮的意思,畢竟Attention是根據人的先驗設計出來的,因此導致最后訓練的結果朝著人指定的目標在走。可以說,就是輸入第j維的上下文表示信息與第t時間片輸出的關系,第j維可以是空間維度上,也可以是時序上。由于加入Attention會對輸入的上下文表示進行一次基于權重的篩選,然而這種顯示的篩選模式并不是人工制定這種機制所要看到的結果,而是通過此種加權的方式,讓網絡能學到空間上或者時序上的結構關系,前提當然是假設這里有一種原先不可解釋的相互關系。以上圖1可以很清晰地看出機器翻譯問題中,加入的attention模型輸出權重的分布與輸入與輸出信息的關系。
所以說Attention的作用是?
Attention的出現就是為了兩個目的:1. 減小處理高維輸入數據的計算負擔,通過結構化的選取輸入的子集,降低數據維度。2. “去偽存真”,讓任務處理系統更專注于找到輸入數據中顯著的與當前輸出相關的有用信息,從而提高輸出的質量。Attention模型的最終目的是幫助類似編解碼器這樣的框架,更好的學到多種內容模態之間的相互關系,從而更好的表示這些信息,克服其無法解釋從而很難設計的缺陷。從上述的研究問題可以發現,Attention機制非常適合于推理多種不同模態數據之間的相互映射關系,這種關系很難解釋,很隱蔽也很復雜,這正是Attention的優勢—不需要監督信號,對于上述這種認知先驗極少的問題,顯得極為有效。
讓我們來看一個具體的例子!
這里直接上一幅圖,舉個具體的例子,然后咱們慢慢來解釋:
讓我們來看一下論文里其他研究者都是如何利用AttentionModel的:
最新一篇CVPR2017年accepted paper關于VQA問題的文章中,作者使用到了基于Spatial和基于Temporal兩個層面的Attetion模型,效果肯定提升了不用說,該問題更是極好的利用了這兩點,其實這兩種應用方式早在MT中得到了利用。
**今天實在太晚了,我要回家睡覺,先寫到這,不然又不知道幾點睡,不能總熬夜,周五前更新完
**上次說周五前更新完,結果拖了一周了,不過想想也沒說哪個周五,啊哈哈哈。這里趕緊補上
上圖的兩種attention用法都屬于soft attention,即通過確定性的得分計算來得到attended之后的編碼隱狀態,圖示來自論文
Jang Y, Song Y, Yu Y, et al. TGIF-QA: Toward Spatio-Temporal Reasoning in Visual Question Answering[J]. arXiv preprint arXiv:1704.04497, 2017.
我們來討論一下圖示中的左邊和右邊兩種attention是如何實現的。
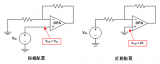
(a)空間注意力 Spatial Attention
對與視頻轉文字,圖像轉文字,VQA問題啊,這種task都需要視覺信息,那么和text信息一樣,對visual content進行編碼了以后,將編碼后的特征表示直接接入解碼器,可以得到我們想要的輸出,例如text sentences。這就是基礎的結構,但是現在加入空間Attention之后,如何改變結構呢。
假設前面視覺編碼后的特征表示為7x7x3072維featuremaps(論文里的參數)mt,然后來自text encoder的隱狀態為hq1x1024,生成一個7x7的attend mask,at=f(hq,mt),attended featuremaps 為atmt,所以現在的維度不就變成了1x3072了嗎?
















 工商網監
工商網監
評論