 電子發燒友App
電子發燒友App


什么是循環神經網絡(RNN),如何使用它們?本文所討論的就是關于循環神經網絡的基礎內容,RNN 是變得日益流行的深度學習模型。本文不打算深入講解其晦澀的數學原理,而是旨在讓讀者獲得關于RNN 的抽象理解。
一般的循環神經網絡信息
循環神經網絡出現于20世紀 80年代,最近由于網絡設計的推進和圖形處理單元上計算能力的提升,循環神經網絡變得越來越流行。這種網絡尤其是對序列數據非常有用,因為每個神經元或者單元能用它的內部存儲來保存之前輸入的相關信息。在語言的案例中,“I had washed my house”這句話的意思與“I had my house washed”大不相同。這就能讓網絡獲取對該表達更深的理解。
注意到這點很重要,因為當閱讀一個句子甚至是一個人時,你就是要從它之前的單詞中提出每個詞的語境。
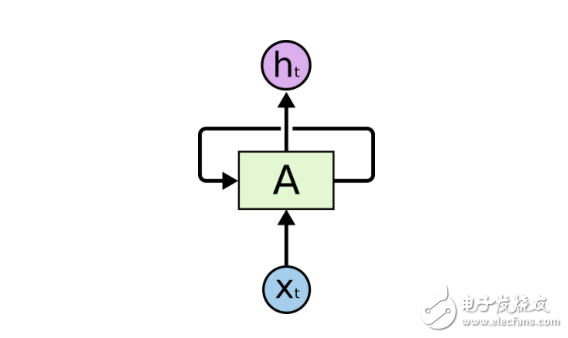
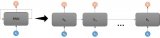
一個卷起的循環神經網絡
一個循環神經網絡里有很多個環,這些環能允許帶著信息通過神經元,同時在輸入中讀取它們。
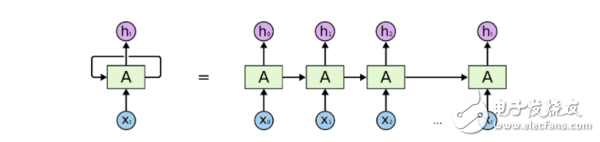
一個展開的循環神經網絡
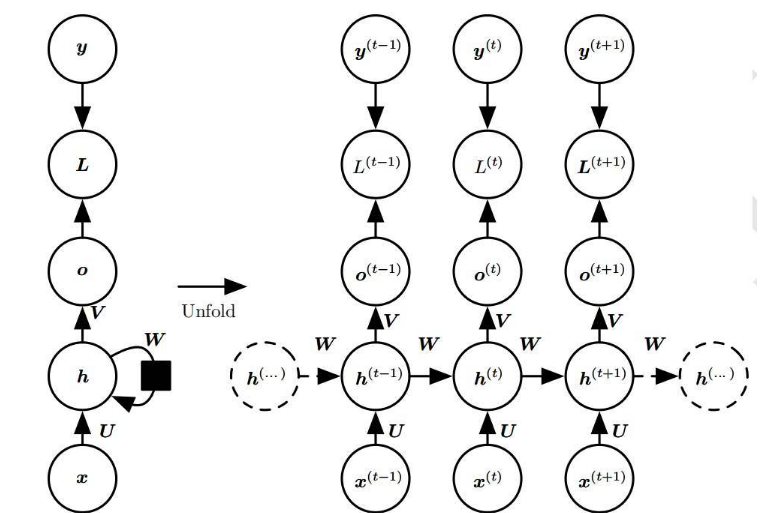
在這些圖表中, xt是某些輸入,A 是這個循環神經網絡的一部分,而 ht 是輸出。基本上,你能輸入句子中的詞或者甚至是像 xt 這樣的字符串中的字符,然后通過該循環神經網絡它會得出一個 ht。
目標是用 ht 作為輸出,并將它與你的測試數據(通常是原始數據的一個小子集)比較。然后你會得出你的誤差率。比較完之后,有了誤差率,你就能使用一種叫隨時間反向傳播(BPTT)的技術。BPTT 返回檢查這個網絡,并基于誤差率調整權重。這樣也調整了這個網絡,并讓它學習去做得更好。
理論上說,循環神經網絡能從句子開頭處理語境,它允許對一個句子末尾的詞進行更精確的預測。在實踐中,對于 vanilla RNN 來說,這并不是真正需要的。這就是為什么 RNN 在出現之后淡出研究圈一段時間直到使用神經網絡中的長短期記憶(LSTM)單元取得了一些不錯的結果后又重新火起來的主要原因。加上 LATM 后的網絡就像是加了一個記憶單元,能記住輸入的最初內容的語境。
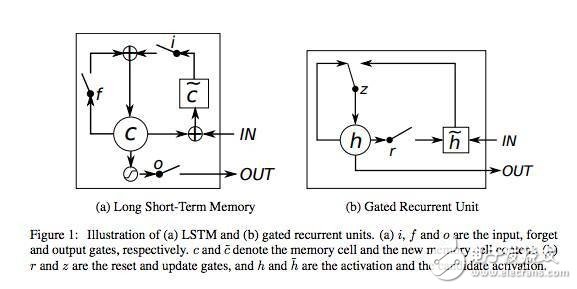
這些少量記憶單元能讓 RNN 更加精確,而且是這種模型流行的最新原因。這些記憶單元允許跨輸入以便記住上下文語境。這些單元中,LSTM 與 門控循環單元(GRU)是當下使用比較廣泛的兩個,后者的計算效率更高,因為它們占用的計算機內存比較少。
循環神經網絡的應用
RNN 有很多應用。一個不錯的應用是與自然語言處理(NLP)的合作。網上已經有很多人證明了 RNN,他們創造出了令人驚訝的模型,這些模型能表示一種語言模型。這些語言模型能采納像莎士比亞的詩歌這樣的大量輸入,并在訓練這些模型后生成它們自己的莎士比亞式的詩歌,而且這些詩歌很難與原作區分開來。
下面是莎士比亞式詩歌。
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain‘d into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.
DUKE VINCENTIO:
Well, your wit is in the care of side and that.
Second Lord:
They would be ruled after this chamber, and
my fair nues begun out of the fact, to be conveyed,
Whose noble souls I’ll have the heart of the wars.
Clown:
Come, sir, I will make did behold your worship.
VIOLA:
I‘ll drink it.
這首詩完全是一個 RNN 寫出來的。這里有一篇好文章更深入地介紹了 Char RNNs 。
這種特殊類型的 RNN 是在一個文本數據集中喂養的,它要逐字讀取輸入。與一次投喂一個詞相比,這種方式讓人驚訝的地方是這個網絡能創造出它自己獨特的詞,這些詞是用于訓練的詞匯中沒有的。
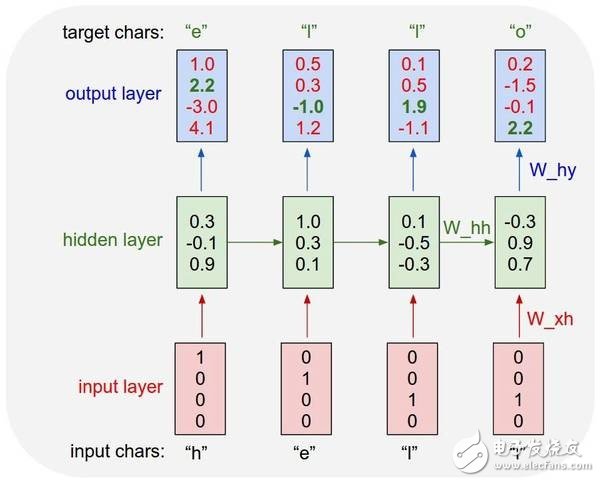
一個 char RNN 的例子
這張從以上參考文章中摘取的圖表展示了這個模型將會如何預測“Hello”這個詞。這張圖很好地將網絡如何逐字采納每個詞并預測下一個字符的可能性可視化了。
另一個讓人驚喜的 RNN 應用是機器翻譯。這種方法很有趣,因為它需要同時訓練兩個 RNN。在這些網絡中,輸入的是成對的不同語言的句子。例如,你能給這個網絡輸入意思相同的一對英法兩種語言的句子,其中英語是源語言,法語作為翻譯語言。有了足夠的訓練后,你給這個網絡一個英語句子,它就能把它翻譯成法語!這個模型被稱為序列到序列模型(Sequence to Sequences model )或者編碼-解碼模型(Encoder- Decoder model)。
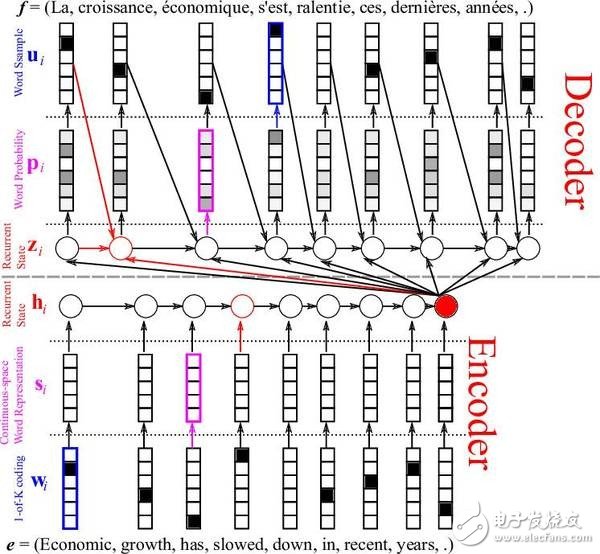
英法翻譯的例子
這張圖表展示了信息流是如何通過編碼-解碼模型的,它用了一個詞嵌入層( word embedding layer )來獲取更好的詞表征。一個詞嵌入層通常是 GloVe 或者 Word 2 Vec 算法,能批量采納詞,并創建一個權重矩陣,讓相似的詞相互連接起來。用一個嵌入層通常會讓你的 RNN 更加精確,因為它能更好的表征相似的詞是什么樣的,以便減少網絡的推斷。
結論
RNN 現在很流行。它們是自然語言處理中最有效的模型之一。這些模型會一直出現新的應用。









 工商網監
工商網監
評論