 電子發燒友App
電子發燒友App


深度學習雖然到現在依然火熱,Gary Marcus 卻向我們潑了冷水,Gary Marcus 表示別忽視深度學習的種種問題,其實深度學習的現狀一點都不樂觀,我們還有許多的難題沒有解決,學到的知識并不深入而且很難遷移。
紐約大學心理學教授 Gary Marcus 曾是 Uber 人工智能實驗室的負責人,他自己創立的人工智能創業公司 Geometric Intelligence 2016 年 12 月被 Uber 收購,自己也就加入 Uber 幫助他們建立人工智能實驗室。Gary Marcus 也曾號召研究人員們「借用認知科學領域的知識」,更多地構建和人類類似的認識概念。
然而 Gary Marcus 卻不是一個令人深受鼓舞的「正面人物」,實際上他曾反復對人工智能和深度學習潑冷水,警告大家我們現在取得的進展多么微不足道、人們又有多么過于樂觀。
圣誕-元旦長假剛過,Gary Marcus 在 arXiv 上傳了一篇論文,對現在火熱的深度學習的現狀進行了全面的、而且一點都不樂觀的分析。他在論文中針對現在火熱的深度學習指出了十個問題,小編把這十個問題簡單介紹如下:
一,渴求大量的數據
人類學可以根據明確的規律學習,比如學會一元二次方程的三種形式以后就可以用來解各種題目;也可以從不多的幾個樣本中迅速學到隱含的規律,見過了京巴、柴犬之后,再見到德牧就知道它也是一種狗。然而深度學習不是這樣的,「越多的數據 = 越好的模型表現」就是深度學習的基本規律,它沒有能力從字面上給出的規律學習。
對企業來說,IT 巨頭在深度學習時代更容易憑更大的數據量建立起馬太效應,第二梯隊的競爭者們已經開始感到擔憂。學者們也對此不是很樂觀,Geoffrey Hinton 在近期的膠囊論文中也提到「卷積網絡在新類別上泛化能力的困難度……要么在網格中復制特征檢測器,網格的大小隨著維度數目指數增長,要么同樣以指數方式增加的標注訓練集的大小」。對于可用的數據有限的場合,深度學習往往并不是最佳的選擇。
二,學到的知識并不深入而且很難遷移
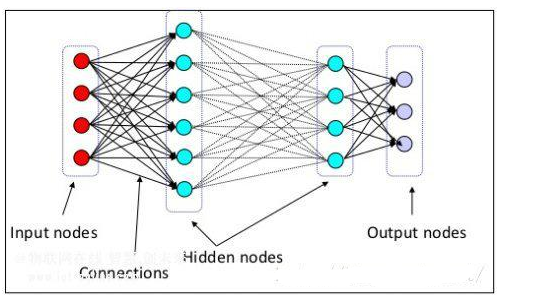
我們都知道深度學習的「深」指的是網絡的層數深、隱層數目多,而人類喜歡且崇敬的對事物運行規律的深刻總結則在深度學習中無處可尋。
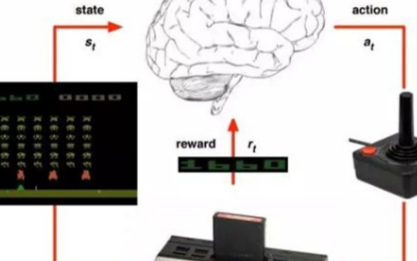
即便對于需要和環境交互、理應更好地認識到環境規律的強化學習模型,一旦環境發生任何變化,它們也仍然需要重新適應——它們其實沒有真的理解「墻」是什么、「通道」是什么。除了 DeepMind 的玩 Atari 游戲的強化學習模型表現出了這樣的特點,其它許多研究者在各自的研究領域中也都觀察到了輕微改變輸入數據就會造成輸出結果有巨大差別的現象。
深度學習模型學到的數據模式,看起來要比我們認為的弱得多。
三,難以處理層次化的結構
舉例來說,對多數深度學習語言模型來說,句子就是一串單詞而已,然而在語言學家眼中,句子是有固有的層次結構的;英文長句中的定語從句就是一類經典的例子,同樣是結構基本完整的句子,從層次結構角度講卻只是某一個詞或者詞組的補充說明。
深度學習對于各種層次化的結構都無能為力。人類可以把「煮米飯」這個目標拆分成「淘米、加水、設火力時間」幾個動作逐個完成,游戲 AI 也有需求找到單個操作和全局戰略之間的平衡和協調。然而深度學習是提供不了層次化的理解、總結、控制等等能力的,它本身學到的特征就是「平坦」的,或者說是非層次化的,每個特征都只是清單中的一項。所以深度學習系統自身沒有能力表示出層次化結構,嘗試用一些技巧提取層次化結構的 Word2Vec 之類的模型就馬上可以脫穎而出。
然而考慮到多數任務、多數數據、多數電氣系統都有顯而易見的層次結構(這甚至就是人類構建實用系統的基本思路),深度學習在它們之上的表現都還很值得懷疑。
四,對于開放性推理問題愛莫能助
人類在看過書籍電影之后總能對其中的轉折和故事發展提出不同于原作的見解、對作者的暗示提出種種猜想,然而即便是在 SQuAD 問答數據集上表現最好的模型,也只能是在給定的文本中找到最相關的詞句然后把它們進行組合而已,完全沒有創新和理解暗示的能力。即便已經有研究者做出了嘗試,目前來說也沒有任何深度學習系統基于真實知識做開放性推理的能力可以和人類相提并論。
五,深度學習依然不夠透明
關于深度學習的「黑箱」神經網絡問題,在過去幾年來一直是被廣泛關注和討論的焦點。而在今天,深度學習系統動輒擁有數以百萬甚至十億計的參數,開發人員難以用可解釋的方式 (「last_character_typed」) 對一個復雜的神經網絡進行標注 (e.g., the activity value of the ith node in layer j in network module k)。盡管通過可視化工具,我們可以看到復雜網絡中的個體節點所產生的貢獻,但更多時候研究者會發現,神經網絡依然是一個黑匣子一般的謎。
這對于我們會產生什么樣的影響猶未可知,如果系統的魯棒性足夠、自適應性也做得夠好,那么可解釋與否并不成為問題。但如果它需要被用在一些更大的系統上,那么它所具備的可調試性就變得尤為重要。
深度學習的透明性問題尚未被解決,而對于以金融或是醫學診斷為代表的應用領域,它將是一個繞不過的坑,畢竟,人們需要向機器的決策要一個可解釋的答案。就像 Catherine O』Neill (2016) 所指出的那樣,深度學習的不透明性將引致偏見的系列問題。
六,深度學習遠未與先驗知識緊密結合
深度學習的一個重要方向在于解釋學,即將它與其它的知識區隔開來。典型的深度學習方式往往是尋找一個數據集,通過調參等各種方式,學習輸入輸出的關聯,并掌握解決問題的方法。有少數研究會刻意地弱化先驗知識,比如以 LeCun 為代表的神經網絡連接約束等研究。
而以 Lerer et al 的研究為例,團隊嘗試讓系統學習物體從高塔上掉落的物理特性,在這個研究中,除了卷積隱含內容外,團隊沒有加入物理學的先驗知識。我即將發表的論文中也提及了這一點,即深度學習研究者看起來對先驗知識偏見不小,即便這些知識都是眾所周知的。
此外,將先驗知識整合到深度學習系統中也并非易事。主要原因在于,知識表征主要描述不是抽象的量化特征,而是特征間的關系;機器學習過于強調系統的獨立性,而把通用性知識排除在外。以 Kaggle 機器學習競賽平臺為例,所給的數據集、所提出的問題,都是給定的,盡管在比賽的范式驅動下,研究者已經有了長足的進步,但與真實世界亟待解決的問題還有著很大差距。
生活并非一場 Kaggle 競賽。真實世界的數據并不會洗干凈打包好等著你,而問題也比競賽所遇到的要復雜得多。在以語音識別為代表的,有大量標記的問題上,深度學習可能表現不俗。但如果是開放性的問題呢?幾乎沒有人知道要怎么辦。被繩子卡住鏈條的自行車怎么修?我要主修數學還是神經科學?沒有數據集可以告訴我如何解決。
與分類離得越遠的問題、與常識靠得越近的問題,越難被機器學習所解決。而目前據我所知,也沒有人嘗試過解決這樣的問題。
七,深度學習無法區分因果性與相關性
如果因果性與相關性確實不同,那么兩者的區分會是深度學習的一個嚴峻問題。簡單地說,深度學習習得的是輸入與輸出特征間的復雜關系,而非因果性的表征。深度學習系統可以把人類當作整體,并學習到身高與詞匯量(height and vocabulary)的相關性,但并不能了解到長大與發展間(growth and development)的關系。也就是說,孩子隨著長大會學到更多單詞,但不代表學習更多單詞會讓孩子長大。因果關系對于 AI 而言是一個核心問題,但可能因為深度學習的目標并非解決這些問題,因此深度學習領域很少涉足這一研究。
八,深度學習對環境的穩定性提出要求,這可能會存在問題
深度學習目前在高度穩定的環境中工作得最好,比如圍棋,因為它的規則不變,而一旦遇到政治和經濟問題(這些問題會不斷變化),效果則不盡人意。
在一定程度上來說,深度學習可以應用到諸如股票預測等任務上,但是有很大的可能最終會得到類似 Google Flu Trends 的結果,雖然一開始的疫情預測表現良好,但卻沒能提前預知 2013 年的流感高發季。
九,深度學習目前得出來的結果只是近似值,不能徹底相信
從前面提出的問題中可以看到,深度學習系統在某些給定領域的大部分情況下工作得很好,卻很容易被愚弄。
越來越多的論文表明深度學習容易受到攻擊,比如上面提到的 Robin Jia 和 Percy Liang 在語言方面的研究,以及計算機視覺領域的大規模的案例——將黃黑相間的條紋誤以為校車,將帶有貼紙的停車標志誤以為裝滿食品的冰箱。最近還有一些現實世界中的例子,比如被輕微涂損過的停車標志被深度學習系統誤認為是限速標志,3d 打印的烏龜被誤認為是步槍。近期,還有新聞報道了英國警局系統不能正確區分裸體和沙丘。
深度學習系統易受欺騙(spoofability)的特性可能是由 Szegedy 等在 2013 年的一篇論文中首次被提出的,四年過去了,經過了如此多的研究,研究人員還是沒能找到什么魯棒性的解決方法。
十,深度學習發展到現在還是很難工程化
從上面提到的所有問題中得出的另一個事實是,用深度學習來做魯棒性工程很難。谷歌團隊發表的論文 Machine Learning: The High-Interest Credit Card of Technical Debt 中,他們的標題將機器學習形容為「技術債務里高利息的信用卡」,這表明,系統在給定了限制的環境下會工作, 但是很難保證在添加了新的數據,并且這些數據與之前的訓練數據存在差異的情況下能工作。在 ICML 2015 上,Leon Bottou 將機器學習與飛機引擎的發展作了對比,他表示,飛機的設計依賴于構建復雜的系統,這可以保障可靠的性能,但機器學習系統的缺乏類似的保障。
正如谷歌的 Peter Norvig 在 2016 年所指出的那樣,機器學習與傳統項目相比,還缺乏增量性(incrementality)、透明性(transparency)和可調試性(debuggability),想要實現機器學習的魯棒性,這是一項挑戰。Henderson 和他的同事最近也提出了這一觀點,他們專注于深度強化學習,指出了這一領域在魯棒性和可復制性方面存在的一些嚴重問題。
盡管我們在開發機器學習系統的過程中已經取得了一些進步,但還有很長的路要走。
小結:誠然,深度學習在計算機視覺、強化學習、NLP 等領域都優異地解決了不少疑難問題,但我們在對深度學習抱有熱情的同時也應當看到,深度學習并不能解決所有的問題,它高超的提取特征和非線性抽象的能力也遠不足以構成通用人工智能的基礎架構。小編認為,深度學習的研究當然要持續,它的火熱也為整個機器學習、人工智能界帶來了大量關注和人才;但言必深度學習也并不是一個良好的發展狀況,我們更希望各種技術和認識方法可以齊頭并進,合力構建出人類理想中的「人工智能」。





















 工商網監
工商網監
評論