 電子發燒友App
電子發燒友App


毫無疑問,神經網絡和機器學習在過去幾年一直是高科技領域最熱門的話題之一。這一點很容易看出,因為它們解決了很多真正有趣的用例,如語音識別、圖像識別、甚至是樂曲譜寫。
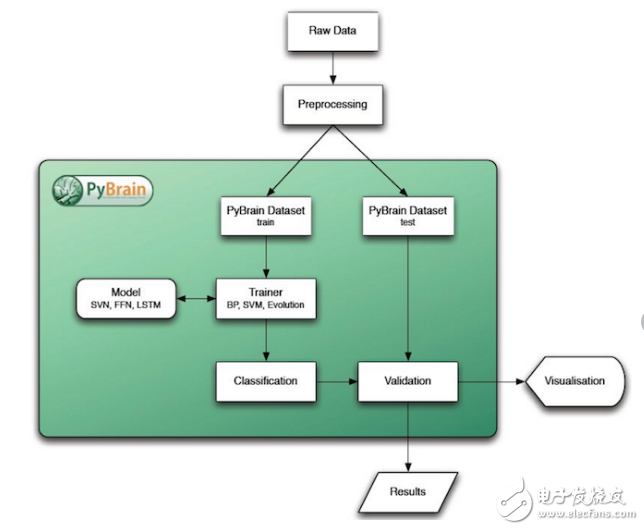
PyBrain的概念是將一系列的數據處理的算法封裝到被稱之為Module的模塊中。一個最小的Module通常包含基于機器學習算法的可調整的參數集合。Modules包含一個輸入和輸出的buffer,外加誤差buffer用于存在誤差反向傳播的場景。
Modules被嵌入到Network類中,并且使用Connection對象進行連接,其中可能包含一系列可調整的參數,比如連接的權重。而Network類本身又是一個Module,因此可以基于此構建多層網絡結構。庫中有快捷的方式構造最常用網絡結構,但原則上這個系統允許嵌入最隨機的連接方式來形成一個無循環圖。
網絡中的參數通過Trainer進行調節,它從Dataset中學習到最優化的參數。還有的增強方式的實驗是通過相關的最優化的目標構造模擬環境進行參數學習。
Python是最好的編程語言之一,在科學計算中用途廣泛:計算機視覺、人工智能、數學、天文等。它同樣適用于機器學習也是意料之中的事。
當然,它也有些缺點;其中一個是工具和庫過于分散。如果你是擁有unix思維(unix-minded)的人,你會覺得每個工具只做一件事并且把它做好是非常方便的。但是你也需要知道不同庫和工具的優缺點,這樣在構建系統時才能做出合理的決策。工具本身不能改善系統或產品,但是使用正確的工具,我們可以工作得更高效,生產率更高。因此了解正確的工具,對你的工作領域是非常重要的。
在我看來,Python是學習(和實現)機器學習技術最好的語言之一,其原因主要有以下幾點:
語言簡單:如今,Python成為新手程序員首選語言的主要原因是它擁有簡單的語法和龐大的社區。
功能強大:語法簡單并不意味著它功能薄弱。Python同樣也是數據科學家和Web程序員最受歡迎的語言之一。Python社區所創建的庫可以讓你做任何你想做的事,包括機器學習。
豐富的ML庫:目前有大量面向Python的機器學習庫。你可以根據你的使用情況、技術和需求從數百個庫中選擇最合適的一個。
上面最后一點可以說是最重要的。驅動機器學習的算法相當復雜,包括了很多的數學知識,所以自己動手去實現它們(并保證其正常運行)將會是一件很困難的任務。幸運地是,有很多聰明的、有奉獻精神的人為我們做了這個困難的工作,因此我們只需要專注于手邊的應用程序即可。
最受歡迎的庫
我已經對一些比較流行的庫和它們擅長的方向做了一個簡短的描述,在下一節,我會給出一個更完整的項目列表。
Tensorflow
這是清單中最新的神經網絡庫。在前幾天剛剛發行,Tensorflow是高級神經網絡庫,可以幫助你設計你的網絡架構,避免出現低水平的細節錯誤。重點是允許你將計算表示成數據流圖,它更適合于解決復雜問題。
此庫主要使用C++編寫,包括Python綁定,所以你不必擔心其性能問題。我最喜歡的一個特點是它靈活的體系結構,允許你使用相同的API將其部署到一個或多個CPU或GPU的臺式機、服務器或者移動設備。有此功能的庫并不多,如果要說有,Tensorflow就是其一。
它是為谷歌大腦項目開發的,目前已被數百名工程師使用,所以無須懷疑它是否能夠創造有趣的解決方案。
盡管和其它的庫一樣,你可能必須花一些時間來學習它的API,但花掉的時間應該是很值得的。我只花了幾分鐘了解了一下它的核心功能,就已經知道Tensorflow值得我花更多的時間讓我來實現我的網絡設計,而不僅僅是通過API來使用。
擅長:神經網絡
scikit-learn
scikit-learn絕對是其中一個,如果不是最流行的,那么也算得上是所有語言中流行的機器學習庫之一。它擁有大量的數據挖掘和數據分析功能,使其成為研究人員和開發者的首選庫。
其內置了流行的NumPy、SciPy,matplotlib庫,因此對許多已經使用這些庫的人來說就有一種熟悉的感覺。盡管與下面列出的其他庫相比,這個庫顯得水平層次略低,并傾向于作為許多其他機器學習實現的基礎。
scikit-learn是我們在CB Insights選用的機器學習工具。我們用它進行分類、特征選擇、特征提取和聚集。我們最愛的一點是它擁有易用的一致性API,并提供了很多開箱可用的求值、診斷和交叉驗證方法(是不是聽起來很熟悉?Python也提供了“電池已備(譯注:指開箱可用)”的方法)。錦上添花的是它底層使用Scipy數據結構,與Python中其余使用Scipy、Numpy、Pandas和Matplotlib進行科學計算的部分適應地很好。因此,如果你想可視化分類器的性能(比如,使用精確率與反饋率(precision-recall)圖表,或者接收者操作特征(Receiver Operating Characteristics,ROC)曲線),Matplotlib可以幫助進行快速可視化。考慮到花在清理和構造數據的時間,使用這個庫會非常方便,因為它可以緊密集成到其他科學計算包上。
另外,它還包含有限的自然語言處理特征提取能力,以及詞袋(bag of words)、tfidf(Term Frequency Inverse Document Frequency算法)、預處理(停用詞/stop-words,自定義預處理,分析器)。此外,如果你想快速對小數據集(toy dataset)進行不同基準測試的話,它自帶的數據集模塊提供了常見和有用的數據集。你還可以根據這些數據集創建自己的小數據集,這樣在將模型應用到真實世界中之前,你可以按照自己的目的來檢驗模型是否符合期望。對參數最優化和參數調整,它也提供了網格搜索和隨機搜索。如果沒有強大的社區支持,或者維護得不好,這些特性都不可能實現。我們期盼它的第一個穩定發布版。
擅長:非常多
Theano
Theano是一個機器學習庫,允許你定義、優化和評估涉及多維數組的數學表達式,這可能是其它庫開發商的一個挫折點。與scikit-learn一樣,Theano也很好地整合了NumPy庫。GPU的透明使用使得Theano可以快速并且無錯地設置,這對于那些初學者來說非常重要。然而有些人更多的是把它描述成一個研究工具,而不是當作產品來使用,因此要按需使用。
Theano最好的功能之一是擁有優秀的參考文檔和大量的教程。事實上,多虧了此庫的流行程度,使你在尋找資源的時候不會遇到太多的麻煩,比如如何得到你的模型以及運行等。
擅長:神經網絡和深度學習
Pylearn2
大多數Pylearn2的功能實際上都是建立在Theano之上,所以它有一個非常堅實的基礎。
據Pylearn2網址介紹:
Pylearn2不同于scikit-learn,Pylearn2旨在提供極大的靈活性,使研究者幾乎可以做任何想做的事情,而scikit-learn的目的是作為一個“黑盒”來工作,即使用戶不了解實現也能產生很好的結果。
記住,Pylearn2在合適的時候會封裝其它的庫,如scikit-learn,所以在這里你不會得到100%用戶編寫的代碼。然而,這確實很好,因為大多數錯誤已經被解決了。像Pylearn2這樣的封裝庫在此列表中有很重要的地位。
擅長:神經網絡
Pyevolve
神經網絡研究更讓人興奮和不同的領域之一是遺傳算法。從根本上說,遺傳算法只是一個模擬自然選擇的啟發式搜索過程。本質上它是在一些數據上測試神經網絡,并從一個擬合函數中得到網絡性能的反饋。然后對網絡迭代地做小的、隨機的變化,再使用相同的數據進行測試。將具有高度擬合分數的網絡作為輸出,然后使其作為下一個網絡的父節點。
Pyevolve提供了一個用于建立和執行這類算法很棒的框架。作者曾表示,V0.6版本也支持遺傳編程,所以在不久的將來,該框架將更傾向于作為一個進化的計算框架,而不只是簡單地遺傳算法框架。
擅長:遺傳算法的神經網絡
NuPIC
Nupic是另一個庫,與標準的機器學習算法相比,它提供了一些不同的功能。它基于一個稱作層次時間記憶(HTM)的新皮層理論,。HTMs可以看作是一類神經網絡,但在一些理論上有所不同。
從根本上說,HTMs是一個分層的、基于時間的記憶系統,可以接受各種數據。這意味著會成為一個新的計算框架,來模仿我們大腦中的記憶和計算是如何密不可分的。對于理論及其應用的詳細說明,請參閱 白皮書。
擅長:HTMs
Pattern
此庫更像是一個“全套”庫,因為它不僅提供了一些機器學習算法,而且還提供了工具來幫助你收集和分析數據。數據挖掘部分可以幫助你收集來自谷歌、推特和維基百科等網絡服務的數據。它也有一個Web爬蟲和HTML DOM解析器。“引入這些工具的優點就是:在同一個程序中收集和訓練數據顯得更加容易。
在文檔中有個很好的例子,使用一堆推文來訓練一個分類器,用來區分一個推文是“win”還是“fail”。
from pattern.web import Twitter
from pattern.en import tag
from pattern.vector import KNN, count
twitter, knn = Twitter(), KNN()
for i in range(1, 3):
for tweet in twitter.search(‘#win OR #fail’, start=i, count=100):
s = tweet.text.lower()
p = ‘#win’ in s and ‘WIN’ or ‘FAIL’
v = tag(s)
v = [word for word, pos in v if pos == ‘JJ’] # JJ = adjective
v = count(v) # {‘sweet’: 1}
if v:
knn.train(v, type=p)
print knn.classify(‘sweet potato burger’)
print knn.classify(‘stupid autocorrect’)
首先使用twitter.search()通過標簽‘#win’和‘#fail’來收集推文數據。然后利用從推文中提取的形容詞來訓練一個K-近鄰(KNN)模型。經過足夠的訓練,你會得到一個分類器。僅僅只需15行代碼,還不錯。
擅長:自然語言處理(NLP)和分類。
Caffe
Caffe是面向視覺應用領域的機器學習庫。你可能會用它來創建深度神經網絡,識別圖像中的實體,甚至可以識別一個視覺樣式。
Caffe提供GPU訓練的無縫集成,當你訓練圖像時極力推薦使用此庫。雖然Caffe似乎主要是面向學術和研究的,但它對用于生產使用的訓練模型同樣有足夠多的用途。
擅長:神經網絡/視覺深度學習
Statsmodels
Statsmodels是另一個聚焦在統計模型上的強大的庫,主要用于預測性和探索性分析。如果你想擬合線性模型、進行統計分析,或者預測性建模,那么Statsmodels非常適合。它提供的統計測試相當全面,覆蓋了大部分情況的驗證任務。如果你是R或者S的用戶,它也提供了某些統計模型的R語法。它的模型同時也接受Numpy數組和Pandas數據幀,讓中間數據結構成為過去!
與其他語言集成
你不了解Python但是很擅長其他語言?不要絕望!Python(還有其他)的一個強項就是它是一個完美的膠水語言,你可以使用自己常用的編程語言,通過Python來訪問這些庫。以下適合各種編程語言的包可以用于將其他語言與Python組合到一起:
R -》 RPython
Matlab -》 matpython
Java -》 Jython
Lua -》 Lunatic Python
Julia -》 PyCall.jl
不活躍的庫
這些庫超過一年沒有發布任何更新,我們列出是因為你有可能會有用,但是這些庫不太可能會進行BUG修復,特別是未來進行增強。
MDP
MlPy
FFnet
PyBrain












 工商網監
工商網監
評論