 電子發燒友App
電子發燒友App


谷歌推出BERT模型被認為是NLP新時代的開始,NLP終于找到了一種方法,可以像計算機視覺那樣進行遷移學習。本文用圖解的方式,生動易懂地講解了BERT和ELMo等模型。
2018年已經成為自然語言處理機器學習模型的轉折點。我們對如何以最能捕捉潛在意義和關系的方式、最準確地表示單詞和句子的理解正在迅速發展。
此外,NLP社區開發了一些非常強大的組件,你可以免費下載并在自己的模型和pipeline中使用。

ULM-FiT跟甜餅怪沒有任何關系,但我想不出其它的了...
最新的一個里程碑是BERT的發布,這一事件被描述為NLP新時代的開始。BERT是一個NLP模型,在幾個語言處理任務中打破了記錄。在描述模型的論文發布后不久,該團隊還公開了模型的源代碼,并提供了已經在大量數據集上預訓練過的下載版本。
這是一個重大的進展,因為任何需要構建語言處理模型的人都可以將這個強大的預訓練模型作為現成的組件使用,從而節省了從頭開始訓練模型所需的時間、精力、知識和資源。
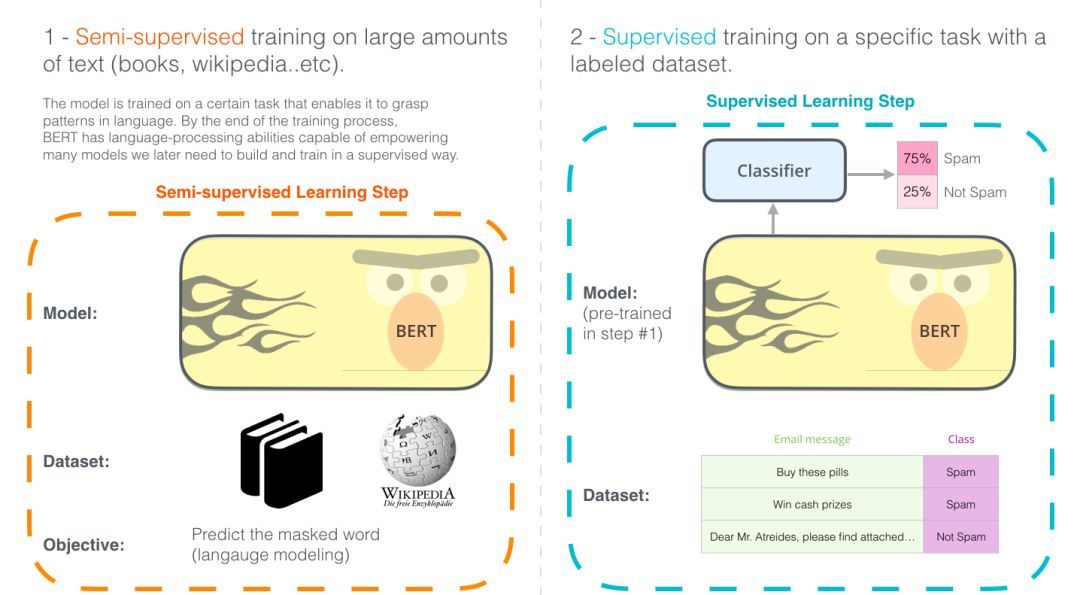
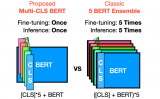
圖示的兩個步驟顯示了BERT是如何運作的。你可以下載步驟1中預訓練的模型(在未經注釋的數據上訓練),然后只需在步驟2中對其進行微調。
BERT建立在最近NLP領域涌現的許多聰明方法之上——包括但不限于半監督序列學習(作者是AndrewDai和QuocLe)、ELMo(作者是MatthewPeters和來自AI2和UWCSE的研究人員)、ULMFiT(作者是fast.ai創始人JeremyHoward和SebastianRuder),OpenAItransformer(作者是OpenAI研究員Radford、Narasimhan、Salimans和Sutskever),以及Transformer(作者是Vaswanietal.)。
要正確理解BERT是什么,我們需要了解一些概念。讓我們先看看如何使用BERT,然后再看模型本身涉及的概念。
例子:句子分類
最直接的使用BERT的方法就是使用它來對單個文本進行分類。這個模型看起來是這樣的:

要訓練一個這樣的模型,主要需要訓練分類器,在訓練階段對BERT模型的更改非常小。這種訓練過程稱為微調(Fine-Tuning),并且具有半監督序列學習(Semi-supervisedSequenceLearning)和ULMFiT的根源。
具體來說,由于我們討論的是分類器,這屬于機器學習的監督學習范疇。這意味著我們需要一個標記數據集來訓練模型。比如說,對于一個垃圾郵件分類器,標記數據集是一個電子郵件列表及其標簽(將每封電子郵件標記為“垃圾郵件”或“非垃圾郵件”)。

模型架構
現在,你已經有了一個如何使用BERT的示例用例,接下來讓我們進一步了解它是如何工作的。
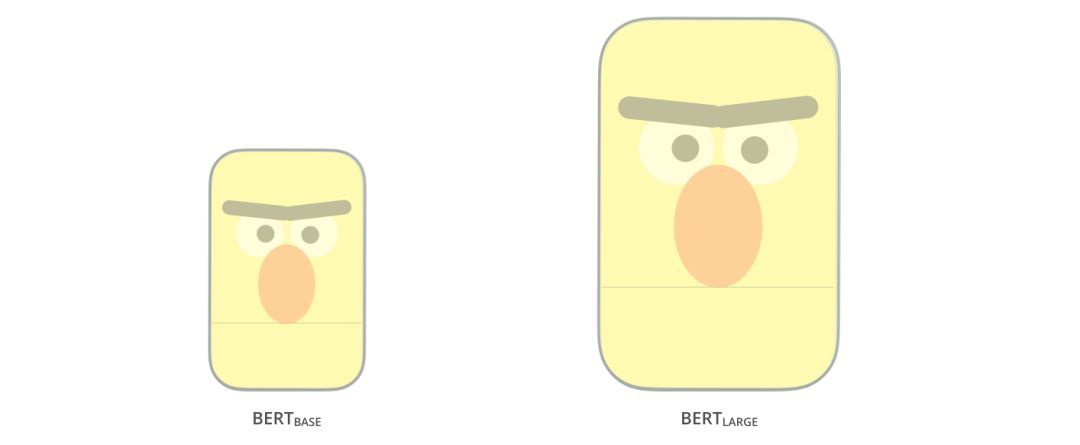
論文中提供了兩種尺寸的BERT模型:
- BERTBASE-大小與OpenAITransformer相當
- BERTLARGE-一個非常龐大的模型,實現了最先進的結果
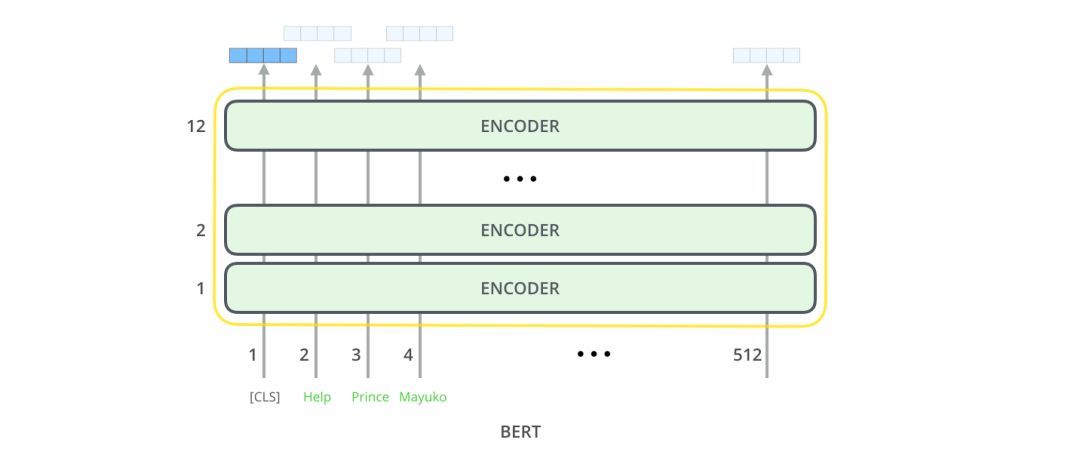
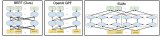
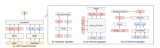
BERT基本上是一個訓練好的TransformerEncoder堆棧。Transformer模型是BERT的一個基本概念,我們將在下文中討論。

這兩種BERT模型都有大量的編碼器層(論文中稱之為TransformerBlocks)——Base版本有12層,Large版本有24層。它們也比初始論文里的Transformer的默認配置(6個編碼器層,512個隱藏單元,8個attentionheads)有更大的前饋網絡(分別為768個和1024個隱藏單元),attentionheads(分別為12個和16個)。
模型輸入
?
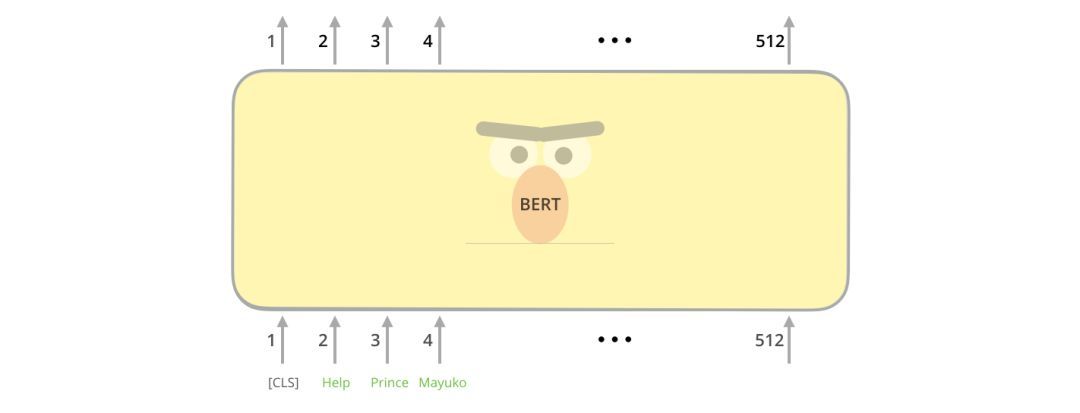
第一個輸入token是一個特殊的[CLS]token,這里的CLS代表分類。
就像transformer的普通編碼器一樣,BERT以一串單詞作為輸入。每一層應用self-attention,并通過前饋網絡傳遞其結果,然后將結果傳遞給下一個編碼器。
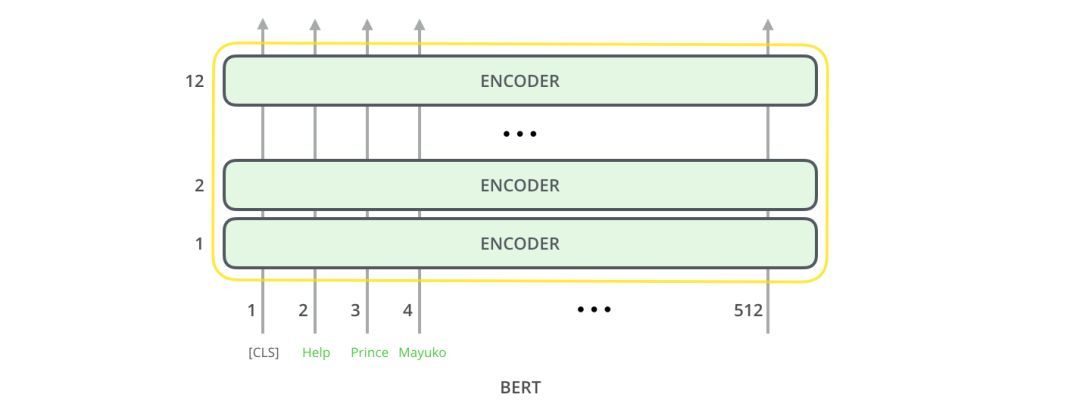
在架構方面,到目前為止,這與Transformer完全相同(除了大小之外,不過大小是我們可以設置的配置)。在輸出端,我們才開始看到兩者的區別。
模型輸出
每個位置輸出大小為hidden_size的向量(BERTBase中為768)。對于上面看到的句子分類示例,我們只關注第一個位置的輸出(我們將那個特殊的[CLS]標記傳遞給它)。
這個向量可以作為我們選擇的分類器的輸入。論文中利用單層神經網絡作為分類器,取得了很好的分類效果。
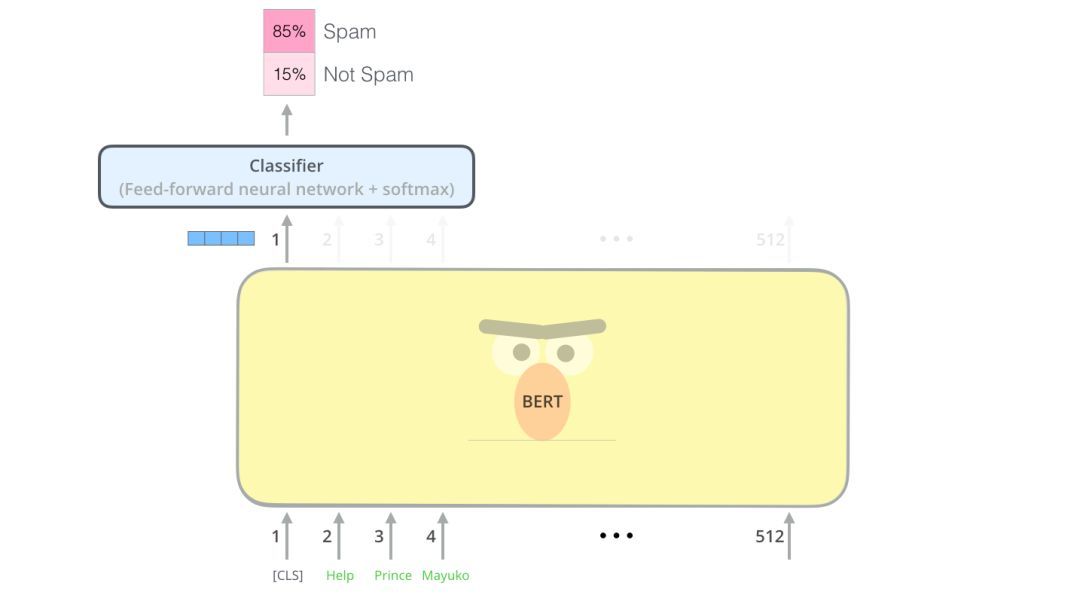
如果你有更多的標簽(例如,如果是電子郵件,你可以將郵件標記為“垃圾郵件”、“非垃圾郵件”、“社交”和“促銷”),只需調整分類器網絡,使其有更多的輸出神經元,然后通過softmax。
與卷積網絡的相似之處
對于具有計算機視覺背景的人來說,這種向量傳遞的方式很容易讓人聯想到VGGNet之類的網絡的卷積部分與網絡末端完全連接的分類部分之間的事情。
嵌入的新時代
這些新進展帶來了詞匯編碼方式的新變化。詞匯嵌入一直是領先的NLP模型處理語言的主要能力。Word2Vec、Glove等方法已廣泛應用于此類任務。讓我們先回顧一下如何使用它們。
詞匯嵌入的回顧
對于要由機器學習模型處理的單詞,它們需要以某種數字形式表示,以便模型可以在其計算中使用。Word2Vec表明我們可以用一個向量(一個數字列表)以捕捉語義或意義關系(如判斷單詞的近義、反義關系)、以及語法或語法關系(例如,“had”和“has”、“was”and“is”有同樣的語法關系)的方式恰當地表示單詞。
研究人員很快發現,使用經過大量文本數據進行預訓練的嵌入(embeddings)是一個好主意,而不是與小數據集的模型一起訓練。因此,通過使用Word2Vec或GloVe進行預訓練,可以下載單詞列表及其嵌入。如下圖是單詞“stick”的GloVe嵌入示例(嵌入向量大小為200)
單詞“stick”的GloVe嵌入
因為這些向量很大,并且數字很多,所以本文后面用下面這個基本圖形來表示向量:
ELMo:上下文很重要
如果我們使用GloVe表示,那么不管上下文是什么,“stick”這個詞都會由這個向量表示。很多研究人員就發現不對勁了。“stick”“有多種含義,取決于它的上下文是什么。那么,為什么不根據它的上下文給它一個嵌入呢——既要捕捉該上下文中的單詞含義,又要捕捉其他上下文信息?因此,語境化的詞嵌入(contextualizedword-embeddings)就出現了。
語境化詞嵌入可以根據單詞在句子的上下文中表示的不同含義,給它們不同的表征
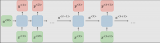
ELMo不是對每個單詞使用固定的嵌入,而是在為每個單詞分配嵌入之前查看整個句子。它使用針對特定任務的雙向LSTM來創建嵌入。

ELMo為NLP中的預訓練提供了重要的一步。ELMoLSTM在大型數據集上進行訓練,然后我們可以將其用作所處理語言的其他模型中的組件使用。
ELMo的秘訣是什么?
ELMo通過訓練預測單詞序列中的下一個單詞來獲得語言理解能力——這項任務被稱為語言建模。這很方便,因為我們有大量的文本數據,這樣的模型可以從這些數據中學習,不需要標簽。

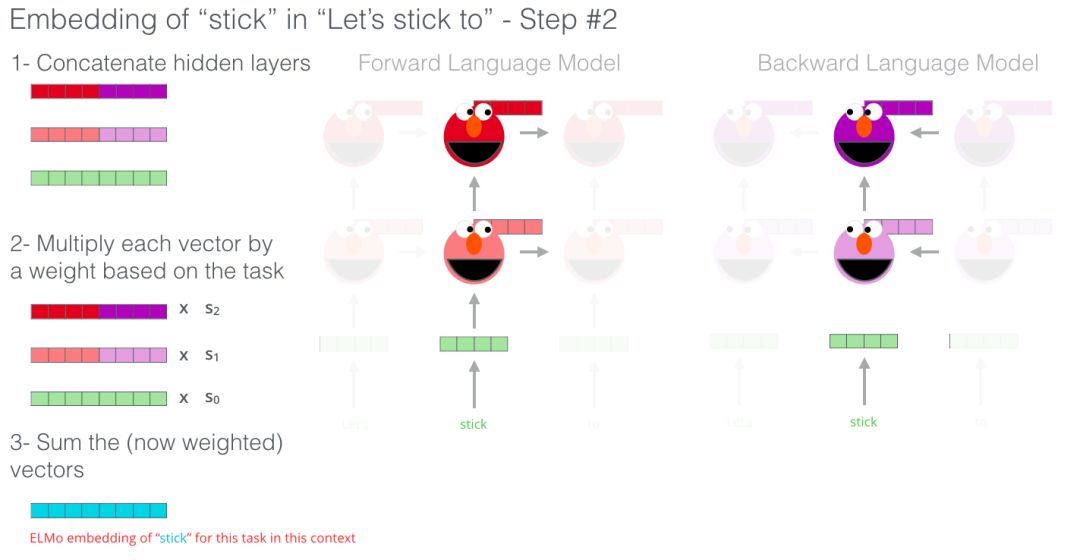
ELMo預訓練的一個步驟
我們可以看到每個展開的LSTM步驟的隱藏狀態從ELMo的頭部后面突出來。這些在預訓練結束后的嵌入過程中會派上用場。
ELMo實際上更進一步,訓練了雙向LSTM——這樣它的語言模型不僅考慮下一個單詞,而且考慮前一個單詞。

ELMo通過將隱藏狀態(和初始嵌入)以某種方式組合在一起(連接后加權求和),提出語境化詞嵌入。
ULM-FiT:NLP中的遷移學習
ULM-FiT引入了一些方法來有效地利用模型在預訓練期間學到的知識——不僅是嵌入,也不僅是語境化嵌入。ULM-FiT提出了一個語言模型和一個流程(process),以便針對各種任務有效地優化該語言模型。
NLP終于找到了一種方法,可以像計算機視覺那樣進行遷移學習。
Transformer:超越LSTM
Transformer的論文和代碼的發布,以及它在機器翻譯等任務上取得的成果,開始使一些業內人士認為Transformers是LSTM的替代品。而且,Transformer在處理長期以來性方便比LSTM更好。
Transformer的編碼器-解碼器結構使其非常適合于機器翻譯。但是如何使用它來進行句子分類呢?如何使用它來預訓練可以針對其他任務進行微調的語言模型(在NLP領域,使用預訓練模型或組件的監督學習任務被稱為下游任務)。
OpenAITransformer:為語言建模預訓練Transformer解碼器
事實證明,我們不需要一個完整的Transformer來采用遷移學習,也不需要為NLP任務采用一個可微調的語言模型。我們只需要Transformer的解碼器。解碼器是一個很好的選擇,因為它是語言建模(預測下一個單詞)的首選,因為它是為屏蔽未來的token而構建的——在逐字生成翻譯時,這是一個有用的特性。
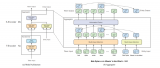
OpenAITransformer由Transformer的解碼器堆棧組成
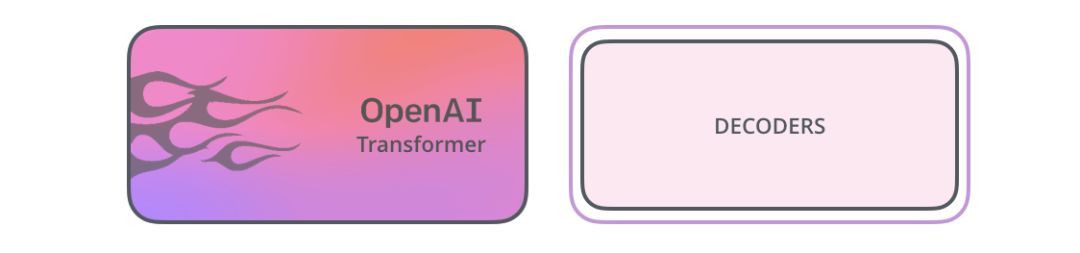
模型堆疊了12個解碼器層。由于在這種設置中沒有編碼器,這些解碼器層將不會有普通transformer解碼器層所具有的編碼器-解碼器注意力子層。但是,它仍具有自注意層。
通過這個結構,我們可以繼續在相同的語言建模任務上訓練模型:使用大量(未標記的)數據集預測下一個單詞。只是,我們可以把足足7000本書的文本扔給它,讓它學習!書籍非常適合這類任務,因為它允許模型學習相關信息,即使它們被大量文本分隔——假如使用推特或文章進行訓練,就無法獲得這些信息。

OpenAITransformer用由7000本書組成的數據集進行訓練,以預測下一個單詞。
將學習轉移到下游任務
既然OpenAItransformer已經經過了預訓練,并且它的層已經被調優以合理地處理語言,那么我們就可以開始將其用于下游任務。讓我們先來看看句子分類(將郵件分為“垃圾郵件”或“非垃圾郵件”):
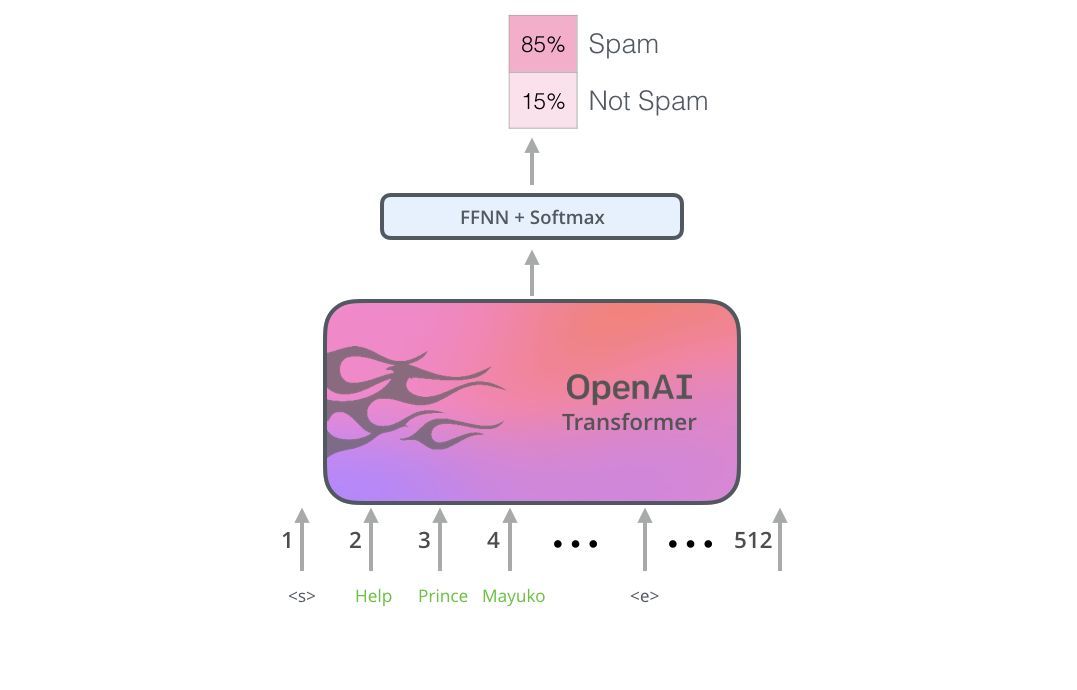
如何使用預訓練的OpenAI transformer來進行句子分割
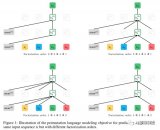
OpenAI論文中概述了一些用于處理不同類型任務輸入的輸入轉換。下圖描繪了模型的結構和執行不同任務的輸入轉換。

這是不很是聰明?
BERT:從解碼器到編碼器
OpenAItransformer為我們提供了一個基于Transformer的可微調預訓練模型。但是在從LSTM到Transformer的轉換過程中缺少了一些東西。ELMo的語言模型是雙向的,而OpenAITransformer只訓練一個正向語言模型。我們能否建立一個基于transformer的模型,它的語言模型既考慮前向又考慮后向(用技術術語來說,“同時受左右上下文的制約”)?
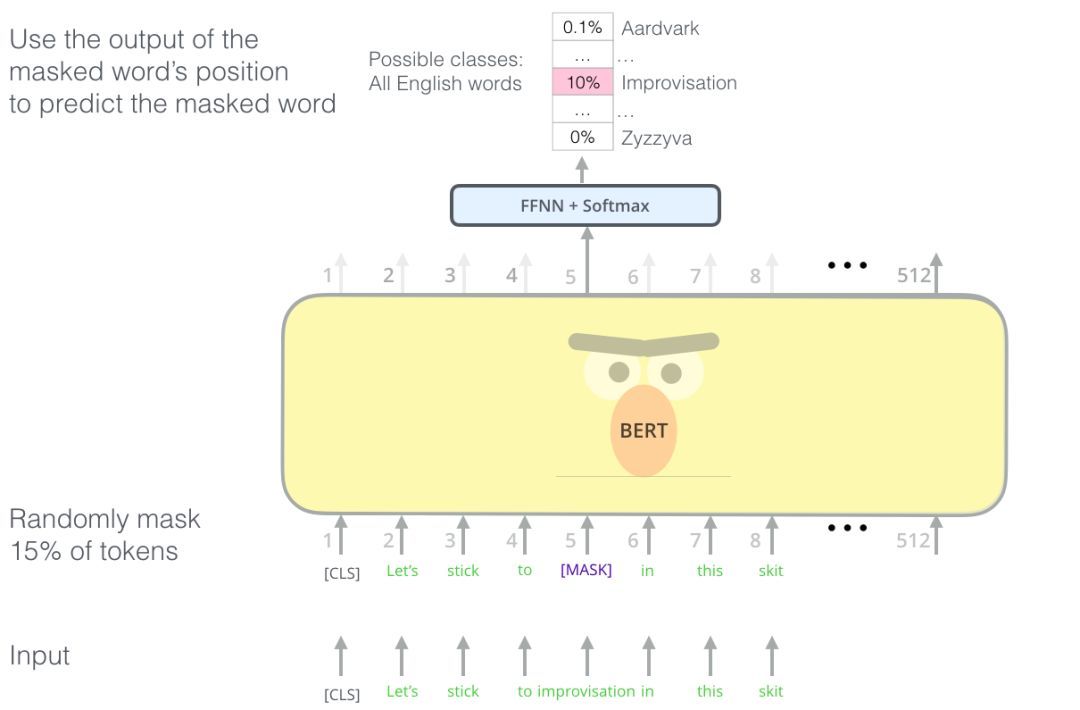
BERT聰明的語言建模任務遮蓋了輸入中15%的單詞,并要求模型預測丟失的單詞。
找到合適的任務來訓練Transformer的編碼器堆棧不容易,BERT采用了“maskedlanguagemodel”的概念(文獻中也成為完形填空任務)來解決這個問題。
除了遮蓋15%的輸入,BERT還混入了一些東西,以改進模型后來的微調方式。有時它會隨機地將一個單詞替換成另一個單詞,并要求模型預測該位置的正確單詞。
兩句話任務
如果你回顧OpenAItransformer處理不同任務時所做的輸入轉換,你會注意到一些任務需要模型說出關于兩個句子的一些信息(例如,它們是否只是同件事情的相互轉述?假設一個維基百科條目作為輸入,一個關于這個條目的問題作為另一個輸入,我們能回答這個問題嗎?)
為了讓BERT更好的處理多個句子之間的關系,預訓練過程增加了一個額外的任務:給定兩個句子(A和B),B可能是A后面的句子,還是A前面的句子?
BERT預訓練的第二個任務是一個兩句話分類任務。

特定任務的模型
BERT的論文展示了在不同的任務中使用BERT的多種方法。
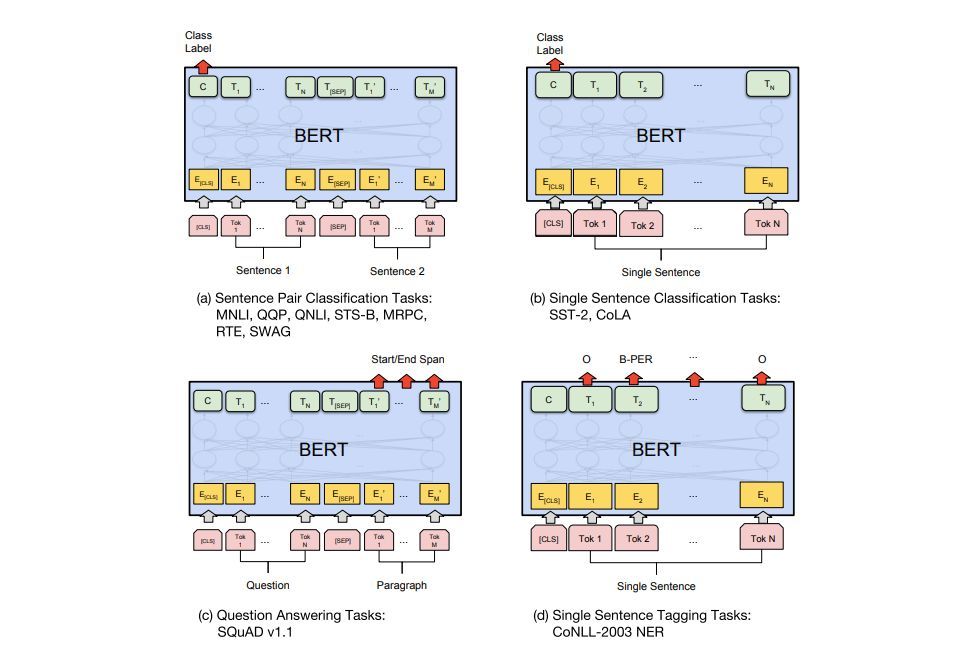
BERT用于特征提取
fine-tuning方法并不是使用BERT的唯一方法。就像ELMo一樣,你可以使用經過預訓練的BERT來創建語境化的單詞嵌入。然后,你可以將這些嵌入提供給現有的模型——論文中證明了,在諸如名稱-實體識別之類的任務上,這個過程產生的結果與對BERT進行微調的結果相差不遠。
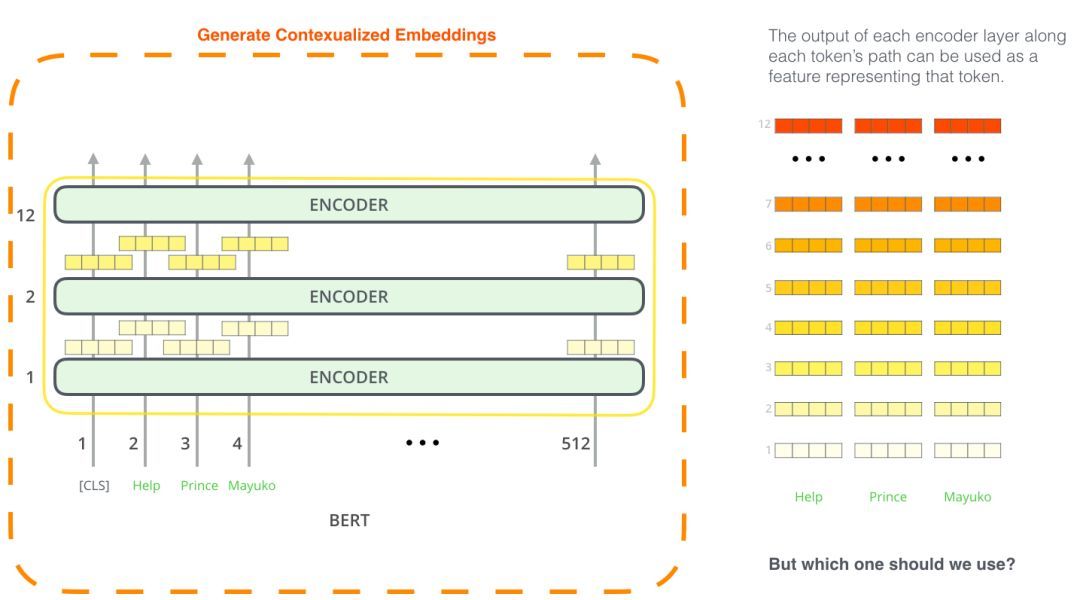
哪個向量最適合作為語境化化嵌入?我認為這取決于任務。論文考察了6個選項(與得分96.4的fine-tuned模型相比):

結語
試用BERT的最佳方式是通過使用托管在谷歌Colab上的CloudTPUsnotebook的BERTFineTuning。如果你以前從未使用過云TPU,那么這也是一個很好的起點,可以嘗試使用它們。BERT代碼也適用于TPU、CPU和GPU。
下一步是查看BERTrepo中的代碼:
- 該模型是在modeling.py(BertModel類)中構建的,與原始Transformer編碼器完全相同。
- run_classifier.py是fine-tuning過程的一個示例。它還構建了監督模型的分類層。如果要構建自己的分類器,請查看文件中的create_model()方法。
- 有幾個預訓練模型可供下載。包括BERTBase和BERTLarge,以及英語,中文等語言的單語言模型,以及涵蓋102種語言的多語言模型,這些語言在維基百科上訓練。
- BERT不是將單詞看作token。相反,它關注的是詞塊(WordPieces)。tokennization.py是將單詞轉換成適合BERT的WordPieces的工具。
BERT也有PyTorch實現。AllenNLPlibrary使用這個實現,允許在任何模型中使用BERT嵌入。
本文來自新智元編譯
























 工商網監
工商網監
評論