 電子發(fā)燒友App
電子發(fā)燒友App


AI生成的假新聞難以識(shí)別,那就用神經(jīng)網(wǎng)絡(luò)來(lái)對(duì)抗吧
機(jī)器之心編輯部
之前,OpenAI GPT-2 因?yàn)樘苌杉傩侣劧惶峁╅_(kāi)源。而最近,華盛頓大學(xué)和艾倫人工智能研究所的研究者表示,要想對(duì)抗假新聞,用對(duì)應(yīng)的假新聞生成器是最好的方法。研究者通過(guò)大量實(shí)驗(yàn)表示,最了解假新聞缺點(diǎn)、假新聞“造假水平”的會(huì)是原本的生成器。因此想要判別 GPT-2 生成的假新聞,還是需要先開(kāi)源 GPT-2 大模型。
自然語(yǔ)言生成領(lǐng)域近期的進(jìn)展令人喜憂參半。文本摘要和翻譯等應(yīng)用的影響是正面的,而其底層技術(shù)可以生成假新聞,且假新聞可以模仿真新聞的風(fēng)格。
現(xiàn)代計(jì)算機(jī)安全依賴謹(jǐn)慎的威脅建模:從攻擊者的角度確定潛在威脅和缺陷,并探索可行的解決方案。同樣地,開(kāi)發(fā)對(duì)假新聞的穩(wěn)健防御技術(shù)也需要我們認(rèn)真研究和確定這些模型的風(fēng)險(xiǎn)。
來(lái)自華盛頓大學(xué)和艾倫人工智能研究所的研究人員近期的一項(xiàng)研究展示了一個(gè)可控文本生成模型 Grover。給出標(biāo)題“Link Found Between Vaccines and Autism”,Grover 可以生成文章內(nèi)容,且 Grover 生成的內(nèi)容比人類寫的假消息看起來(lái)更加可信。
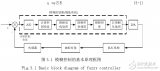
圖 1:該研究介紹了一個(gè)能夠檢測(cè)和生成假新聞的模型 Grover。
開(kāi)發(fā)對(duì)抗 Grover 等生成器的穩(wěn)健驗(yàn)證技術(shù)非常重要。該研究發(fā)現(xiàn),當(dāng)目前最好的判別器能夠獲取適量訓(xùn)練數(shù)據(jù)時(shí),其辨別假新聞和人類所寫真新聞的準(zhǔn)確率為 73%。
而對(duì) Grover 最好的防御就是 Grover 本身,它可以達(dá)到 92% 的準(zhǔn)確率,這表明開(kāi)源強(qiáng)大生成器的重要性。研究人員進(jìn)一步研究了這些結(jié)果,發(fā)現(xiàn)數(shù)據(jù)偏差(exposure bias)和緩解其影響的采樣策略都會(huì)留下相似判別器能夠察覺(jué)的缺陷。最后,該研究還討論了這項(xiàng)技術(shù)的倫理問(wèn)題,研究人員計(jì)劃開(kāi)源 Grover,幫助更好地進(jìn)行假新聞檢測(cè)。
Grover 生成文章示例

圖 8:上圖是同樣標(biāo)題的兩篇文章,一篇是人類書寫的,另一篇?jiǎng)t是 Grover 生成的,標(biāo)題來(lái)自《衛(wèi)報(bào)》。右下角為人類評(píng)分者給出的分?jǐn)?shù)。

針對(duì)假新聞,該研究做了什么?
在本文中,研究人員力圖在假新聞大量出現(xiàn)前去理解并解決這一問(wèn)題。他們認(rèn)為這一問(wèn)題屬于依賴計(jì)算機(jī)安全領(lǐng)域,依賴于威脅建模:分析系統(tǒng)的潛在威脅和缺陷,并探索穩(wěn)健的防御措施。
為了嚴(yán)謹(jǐn)?shù)匮芯窟@一問(wèn)題,研究人員提出了新模型 Grover。Grover 能夠可控并高效地生成完整的新聞文章,不僅僅是新聞主體,也包括標(biāo)題、新聞源、發(fā)布日期和作者名單,這有助于站在攻擊者的角度思考問(wèn)題(如圖 1 所示)。
人類評(píng)分表明他們認(rèn)為 Gover 生成的假消息是真實(shí)可信的,甚至比人工寫成的假消息更可信。因此,開(kāi)發(fā)對(duì)抗 Grover 等生成器的穩(wěn)健驗(yàn)證技術(shù)非常重要。研究人員假設(shè)了一種情景:一個(gè)判別器可以獲得 Grover 生成的 5000 條假新聞和無(wú)限條真實(shí)新聞。
在這一假設(shè)下,目前最好的假新聞判別器(深度預(yù)訓(xùn)練語(yǔ)言模型)可達(dá)到 73% 的準(zhǔn)確率 (Peters et al., 2018; Radford et al., 2018; 2019; Devlin et al., 2018)。而使用 Grover 作為判別器時(shí),準(zhǔn)確率更高,可達(dá)到 92%。這一看似反直覺(jué)的發(fā)現(xiàn)說(shuō)明,最好的假新聞生成器也是最好的假新聞判別器。
本文研究了深度預(yù)訓(xùn)練語(yǔ)言模型怎樣分辨真實(shí)新聞和機(jī)器生成的文本。研究發(fā)現(xiàn),由于數(shù)據(jù)偏差,在假新聞生成過(guò)程中引入了關(guān)鍵缺陷:即生成器是不完美的,所以根據(jù)其分布進(jìn)行隨機(jī)采樣時(shí),文本長(zhǎng)度增加會(huì)導(dǎo)致生成結(jié)果落在分布外。然而,緩解這些影響的采樣策略也會(huì)引入強(qiáng)大判別器能夠察覺(jué)的缺陷。
該研究同時(shí)探討了倫理問(wèn)題,以便讀者理解研究者在研究假新聞時(shí)的責(zé)任,以及開(kāi)源此類模型的潛在不良影響 (Hecht et al., 2018)。由此,該研究提出一種臨時(shí)的策略,關(guān)于如何發(fā)布此類模型、為什么開(kāi)源此類模型更加安全,以及為什么迫切需要這么做。研究人員認(rèn)為其提出的框架和模型提供了一個(gè)堅(jiān)實(shí)的初步方案,可用于應(yīng)對(duì)不斷變化的 AI 假新聞問(wèn)題。
具體方法
下圖 2 展示了利用 Grover 生成反疫苗文章的示例。指定域名、日期和標(biāo)題,當(dāng) Grover 生成文章主體后,它還可以進(jìn)一步生成假的作者和更合適的標(biāo)題。

圖 2:如圖展示了三個(gè) Grover 生成文章的例子。在 a 行中,模型基于片段生成文章主體,但作者欄空缺。在 b 行中,模型生成了作者。在 c 行中,模型使用新生成的內(nèi)容重新生成了一個(gè)更真實(shí)的標(biāo)題。
架構(gòu)
研究者使用了最近較為流行的 Transformer 語(yǔ)言模型 (Vaswani et al., 2017),Grover 的構(gòu)建基于和GPT-2相同的架構(gòu) (Radford et al., 2019)。研究人員考慮了三種模型大校
最小的 Grover-Base 使用了 12 個(gè)層,有 1.17 億參數(shù),和 GPT 及 Bert-Base 相同。第二個(gè)模型是 Grover-Large,有 24 個(gè)層,3.45 億參數(shù),和 Bert-Large 相同。最大的模型 Grover-Mega 有 48 個(gè)層和 15 億參數(shù),與 GPT-2 相同。
數(shù)據(jù)集
研究者創(chuàng)建了 RealNews 大型新聞文章語(yǔ)料庫(kù),文章來(lái)自 Common Crawl 網(wǎng)站。訓(xùn)練 Grover 需要大量新聞文章作為元數(shù)據(jù),但目前并沒(méi)有合適的語(yǔ)料庫(kù),因此研究人員從 Common Crawl 中抓取信息,并限定在 5000 個(gè) Google News 新聞?lì)悇e中。
該研究使用名為“Newspaper”的 Python 包來(lái)提取每一篇文章的主體和元數(shù)據(jù)。研究者抓取 2016 年 12 月到 2019 年 3 月的 Common Crawl 新聞作為訓(xùn)練集,2019 年 4 月的新聞則作為驗(yàn)證集。去重后,RealNews 語(yǔ)料庫(kù)有 120G 的未壓縮數(shù)據(jù)。
訓(xùn)練
對(duì)于每一個(gè) Grover 模型,研究人員使用隨機(jī)采樣的方式從 RealNews 中抽取句子,并將句子長(zhǎng)度限定在 1024 詞以內(nèi)。其他超參數(shù)參見(jiàn)論文附錄 A。在訓(xùn)練 Grover-Mega 時(shí),共迭代了 80 萬(wàn)輪,批大小為 512,使用了 256 個(gè) TPU v3 核。訓(xùn)練時(shí)間為兩周。
語(yǔ)言建模效果:數(shù)據(jù)、上下文(context)和模型大小對(duì)結(jié)果的影響
研究人員使用 2019 年 4 月的新聞作為測(cè)試集,對(duì)比了 Grover 和標(biāo)準(zhǔn)通用語(yǔ)言模型的效果。測(cè)試中使用的模型分別為:通用語(yǔ)言模型,即沒(méi)有提供上下文語(yǔ)境作為訓(xùn)練,且模型必須生成文章主體。另一種則是有上下文語(yǔ)境的模型,即使用完整的元數(shù)據(jù)進(jìn)行訓(xùn)練。在這兩種情況下,使用困惑度(perplexity)作為指標(biāo),并只計(jì)算文章主體。
圖 3 展示了結(jié)果。首先,在提供元數(shù)據(jù)后,Grover 模型的性能有顯著提升(困惑度降低了 0.6 至 0.9)。其次,當(dāng)模型大小增加時(shí),其困惑度分?jǐn)?shù)下降。在上下文語(yǔ)境下,Grover-Mega 獲得了 8.7 的困惑度。第三,數(shù)據(jù)分布依然重要:雖然有 1.17 億參數(shù)和 3.45 億參數(shù)的 GPT-2 模型分別可以對(duì)應(yīng) Grover-Base 和 Grover-Large,但在兩種情況下 Grover 模型相比 GPT-2 都降低了超過(guò) 5 分的困惑度。這可能是因?yàn)?GPT-2 的訓(xùn)練集 WebText 語(yǔ)料庫(kù)含有非新聞?lì)愇恼隆?/p>

圖 3:使用 2019 年 4 月的新聞作為測(cè)試集,多個(gè)語(yǔ)言模型的性能。研究人員使用通用(Unconditional)語(yǔ)言模型(不使用元數(shù)據(jù)訓(xùn)練)和有上下文語(yǔ)境(Conditional)的模型(提供所有元數(shù)據(jù)訓(xùn)練)。在給定元數(shù)據(jù)的情況下,所有 Grover 模型都降低了超過(guò) 0.6 的困惑度分?jǐn)?shù)。
使用 Nucleus Sampling 限制生成結(jié)果的方差
在 Grover 模型中采樣非常直觀,類似于一種從左到右的語(yǔ)言模型在解碼時(shí)的操作。然而,選擇解碼算法非常重要。最大似然策略,如束搜索(beam search),對(duì)于封閉式結(jié)尾的文本生成任務(wù)表現(xiàn)良好,其輸出和其語(yǔ)境所含意義相同(如機(jī)器翻譯)。
這些方法在開(kāi)放式結(jié)尾的文本生成任務(wù)中則會(huì)生成質(zhì)量不佳的文本 (Hashimoto et al., 2019; Holtzman et al., 2019)。然而,正如該研究在第六章展示的結(jié)果,限定生成文本的方差依然很重要。
該研究主要使用 Nucleus Sampling 方式(top-p):給出閾值 p,在每個(gè)時(shí)間步,從累積概率高于 p 的詞語(yǔ)中采樣 (Holtzman et al., 2019)。研究人員同時(shí)對(duì)比了 top-k 采樣方式,即在每一個(gè)時(shí)間步取具有最大概率的前 k 個(gè) token (Fan et al., 2018)。
Grover 生成的宣傳文本輕易地騙過(guò)了人類
圖 4 中的結(jié)果顯示了一個(gè)驚人的趨勢(shì):盡管 Grover 生成的新聞質(zhì)量沒(méi)有達(dá)到人類的高度,但它擅長(zhǎng)改寫宣傳文本。Grover 改寫后,宣傳文本的總體可信度從 2.19 增至 2.42。

圖 4:人工評(píng)估結(jié)果。對(duì)于 Grover 生成的文本,三個(gè)人類評(píng)分者從風(fēng)格、內(nèi)容和整體可信度方面進(jìn)行評(píng)估;每種類別的文章取樣 100 篇。結(jié)果顯示,Grover 生成的宣傳文本比人類書寫的原始宣傳文本的可信度更高。
假新聞檢測(cè)
假新聞檢測(cè)中的半監(jiān)督假設(shè)
雖然網(wǎng)上有大量人類書寫的文本,但大部分都時(shí)間久遠(yuǎn)。因此對(duì)于文本的檢測(cè)應(yīng)當(dāng)設(shè)定在近一段時(shí)間。同樣,由攻擊方生成的 AI 假新聞數(shù)量可能十分少。因此,研究人員將假新聞檢測(cè)問(wèn)題當(dāng)做半監(jiān)督問(wèn)題。假新聞判別器可以使用從 2016 年 12 月到 2019 年 3 月的大量人工寫成的新聞,即整個(gè) RealNews 訓(xùn)練集。
但是,判別器被限制獲取近期新聞和 AI 生成的假新聞。研究者使用 2019 年 4 月的 10000 條新聞生成文章主體文本,使用另外 10000 條新聞作為人類寫成的新聞文章。研究人員將這些文章進(jìn)行分割,其中 10000 條用于訓(xùn)練(每個(gè)標(biāo)簽 5000),2000 用作驗(yàn)證集,8000 用作測(cè)試集。
研究人員考慮了兩種評(píng)價(jià)方式。第一種是不成對(duì)設(shè)置,即判別器僅獲得文章文本,并且需要獨(dú)立地判斷文章是人類寫的還是機(jī)器生成的。而在成對(duì)設(shè)置中,模型獲得兩份具備同樣元數(shù)據(jù)的文章,一份屬于人類完成,一份屬于機(jī)器生成。判別器必須給機(jī)器生成的文章分配高于人工完成文章的 Machine 概率。研究人員對(duì)兩種評(píng)價(jià)方法的準(zhǔn)確率都進(jìn)行了評(píng)估。
判別器評(píng)價(jià)結(jié)果:Grover 在檢測(cè) Grover 生成的假新聞時(shí)表現(xiàn)最好
表 1 展示了所有生成器和判別器組合的實(shí)驗(yàn)結(jié)果。對(duì)每個(gè)組合,研究人員展示了使用不同的采樣策略(top-p&top-k)超參數(shù)的評(píng)價(jià)結(jié)果(p ∈ {.9, .92, .94, .96, .98, 1.0},k ∈ )。
結(jié)果顯示了幾種趨勢(shì):首先,成對(duì)生成器、判別器相比非成對(duì)設(shè)置總體上更加容易檢測(cè)假新聞,說(shuō)明模型更難校準(zhǔn)自己的預(yù)測(cè)。其次,模型大小對(duì)生成器和判別器之間的對(duì)抗過(guò)程非常關(guān)鍵。使用 Grover 判別器對(duì) Grover 生成的文本進(jìn)行檢測(cè),總體上在所有 Grover 模型中都有大約 90% 的準(zhǔn)確率。
如果使用一個(gè)更大的生成器,準(zhǔn)確率會(huì)下滑至低于 81%,與此相對(duì)應(yīng)的是,如果判別器更大,則(檢測(cè)假新聞)準(zhǔn)確率上升至 98% 以上。最后,其他判別器總體上表現(xiàn)比 Grover 更差,這說(shuō)明有效的判別器需要和生成器一樣的歸納偏置(inductive bias)。
無(wú)法獲得對(duì)應(yīng)生成器又怎么樣?
上文中的結(jié)果說(shuō)明,當(dāng)在測(cè)試階段遇到一樣的攻擊方(生成器)時(shí),在研究人員有一定數(shù)量的假新聞數(shù)據(jù)的情況下,Grover 是一個(gè)有效的假新聞判別器。但是如果放松這一假設(shè)呢?這里,研究人員考慮了攻擊方使用 Grover-Mega 生成器,且有一個(gè)未知的 top-p 采樣閾值。
在這一設(shè)定下,研究人員在訓(xùn)練中可以獲得相對(duì)較弱的模型(Grover-Base 或 Grover-Large)。研究人員考慮了只有 x 個(gè)來(lái)自 Grover-Mega 的文本,并從較弱的生成器模型中采樣 5000-x 個(gè)文章,采樣閾值則對(duì)每一個(gè)文章都限定在 [0.9, 1.0] 之間。
研究人員在圖 5 中展示了實(shí)驗(yàn)結(jié)果。結(jié)果說(shuō)明,當(dāng)只有少量 Grover-Mega 生成器文本時(shí),從其他生成器獲得的弱監(jiān)督文本可以極大提升判別器的表現(xiàn)。16 至 256 個(gè) Grover-Mega 數(shù)據(jù),加上從 Grover-Large 獲得的弱文本,可以使模型得到約 78% 的準(zhǔn)確率,但沒(méi)有弱文本時(shí)僅有 50% 的準(zhǔn)確率。當(dāng)來(lái)自 Grover-Mega 的文本數(shù)據(jù)增加時(shí),準(zhǔn)確率可提升至 92%。
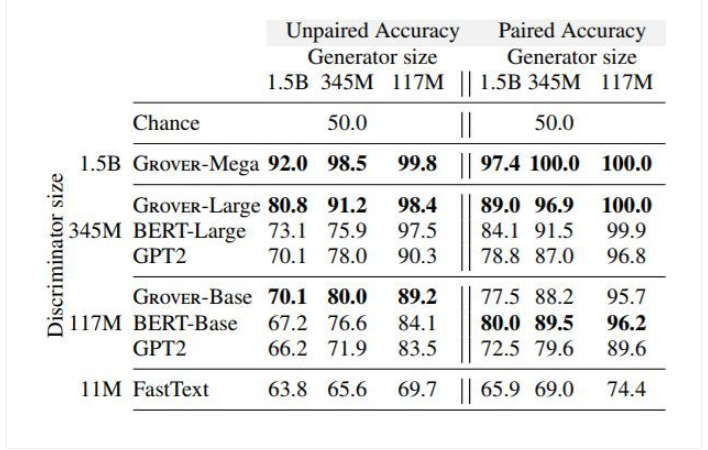
表 1:在成對(duì)和不成對(duì)設(shè)置以及不同大小架構(gòu)中判別器和生成器的結(jié)果。研究人員還調(diào)整了每對(duì)生成器和判別器的生成超參數(shù),并介紹了一組特殊的超參數(shù),它具有最低驗(yàn)證準(zhǔn)確率的判別測(cè)試準(zhǔn)確率。與其它模型(如 BERT)相比,Grover 最擅長(zhǎng)識(shí)別自身生成的假新聞。
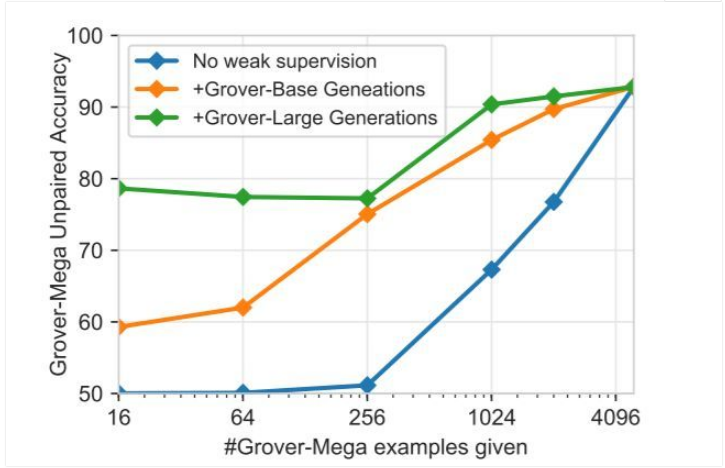
圖 5:探索判別 Grover-Mega 生成結(jié)果的弱監(jiān)督。在沒(méi)有弱監(jiān)督的情況下,判別器發(fā)現(xiàn)了 x 個(gè)機(jī)器生成的文本(來(lái)自 Grover Mega)。對(duì)于 Grover-Base 和 Grover-Mega,判別器發(fā)現(xiàn)了 5000-x 個(gè)機(jī)器生成的文本,這些文本由較弱的相關(guān)生成器給出。當(dāng)給出的域內(nèi)樣本較少時(shí),生成的弱文本可以提升判別器的性能表現(xiàn)。
模型如何區(qū)分人工手寫和機(jī)器生成的文本?
等式 1:最近的最佳通用文本生成任務(wù)被認(rèn)為是一個(gè)語(yǔ)言建模問(wèn)題 (Bengio et al., 2003)。在這一問(wèn)題中,需要尋找生成文本 x 的概率,此概率為該文本中每一個(gè)詞以前面所有詞為條件的概率之積。
為什么 Grover 在檢測(cè)自己生成的假新聞時(shí)效果最好?研究人員猜想部分原因可能是數(shù)據(jù)偏差,即訓(xùn)練最大化等式 1 的模型僅能描述人工書寫的文本(Ranzato et al., 2016)。為了驗(yàn)證他們的猜想,研究人員在圖 6 中繪制了 Grover-Mega 在文本每個(gè)位置的困惑度,取閾值 p=0.96 和 p=1 時(shí)的文本以及人工手寫的文本。
之后生成第一個(gè) token 會(huì)導(dǎo)致較高的困惑度。但是,其余位置顯示出一種奇怪的模式:人工書寫的文本有著比隨機(jī)采樣文本更低的困惑度,而這個(gè)差距隨著序列長(zhǎng)度的增加而加大,表明隨機(jī)采樣通常會(huì)導(dǎo)致 Grover 生成的結(jié)果越來(lái)越脫離人類語(yǔ)言的分布。然而,限制方差(p=0.96)會(huì)降低由此產(chǎn)生的困惑度并限制其增長(zhǎng)。
1. 限制模型方差同樣產(chǎn)生了關(guān)鍵特征
但是在另一方面,限制模型的方差同樣留下了一種特征。如同以前的研究采用的 top-k 采樣一樣 (Strobelt and Gehrmann,2019),本次研究使用的原子采樣也出現(xiàn)了同樣的現(xiàn)象。一個(gè)人工寫成的文章中所有詞都高于 top-p% 閾值的概率是 p^n,n 是文本長(zhǎng)度。當(dāng) n 增長(zhǎng)時(shí),概率下降。然而,對(duì)于原子采樣的文本,概率低于 1?-p 的文本被去除。因此文本中所有詞的出現(xiàn)概率都在 top-p 以上,根據(jù)這個(gè)特征就能進(jìn)行判別。
2. 特征能否被捕捉取決于對(duì)判別器的選擇
對(duì)每一個(gè)時(shí)間步,從整體上來(lái)說(shuō),僅有生成器使用了 top-p 超參數(shù)。因此,如果一個(gè)判別器使用別的方式對(duì)文本進(jìn)行建模,這個(gè)生成器需要更多的時(shí)間去定位被截?cái)嗟?1-p 分布長(zhǎng)尾。這可能能夠解釋為什么 Bert 在作為判別器時(shí)表現(xiàn)較 Grover 更差。
3. 方差縮減時(shí)需要謹(jǐn)慎避開(kāi)的“甜蜜陷阱”(sweet spot)
不縮減模型方差和強(qiáng)力縮減模型方差都會(huì)帶來(lái)問(wèn)題。在縮減的參數(shù)中可能存在一個(gè)“甜蜜陷阱”(sweet spot)區(qū)域,去決定多大程度上需要截?cái)喾植迹古袆e變得困難。在圖 7 中,研究人員展示了在不同采樣閾值下的 Grover-Mega 判別器的表現(xiàn)。結(jié)果確實(shí)顯示出了一個(gè)“甜蜜陷阱”。對(duì)于判別器,當(dāng) p 介于 0.92 和 0.98 之間時(shí),判別工作是最困難的。
有趣的是,研究人員注意到攻擊方 top-p 閾值在 Bert-Large 模型遠(yuǎn)低于這一閾值在 Grover-Large 中的值,即使兩個(gè)模型有著同樣的結(jié)構(gòu)。這一結(jié)果支持了研究人員的猜測(cè),即 Bert 對(duì)語(yǔ)言的建模方式和 Grover 非常不同。使用低 top-p 閾值似乎不能幫助模型獲得丟失的長(zhǎng)尾信息。
?
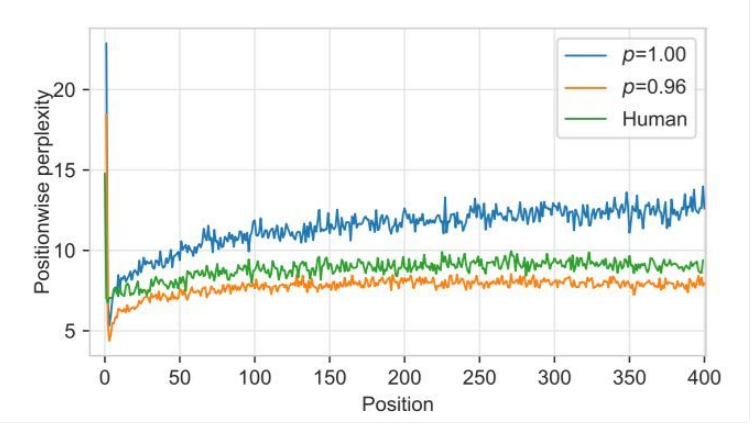
圖 6:Grover-Mega 的困惑度,取自每個(gè)位置的平均值(以元數(shù)據(jù)為條件)。研究人員選取了 p=1(隨機(jī)采樣)和 p=0.96 時(shí) Grover-Mega 生成的文本以及人工書寫的文本。隨機(jī)采樣的文本有著比人工書寫的文本更高的困惑度,而且這個(gè)差距隨著序列長(zhǎng)度的增加而加大。這表明,不減少方差的抽樣通常會(huì)導(dǎo)致生成結(jié)果落在真實(shí)分布以外。
?
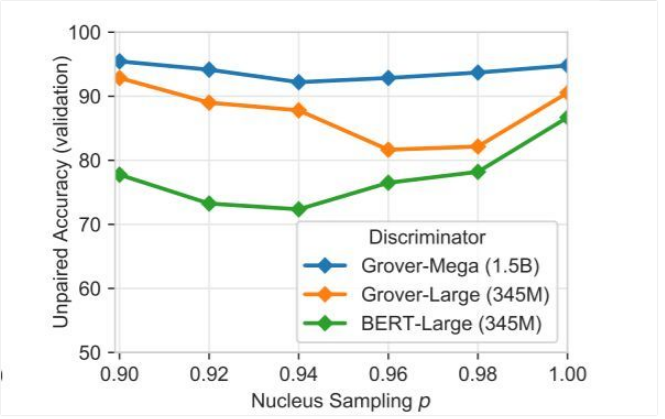
圖 7:在設(shè)定了不同的方差縮減閾值時(shí)(如 p 對(duì)應(yīng)原子采樣和 k 對(duì)應(yīng) top-k 采樣方式),將 Grover Mega 生成的新文章與真實(shí)文章區(qū)分開(kāi)的未配對(duì)的驗(yàn)證準(zhǔn)確率。因 p 的不同,結(jié)果也有所不同。當(dāng) p 在 0.92-0.96 之間時(shí),區(qū)分假消息的難度最高。
總之,本文的分析表明,Grover 可能最擅長(zhǎng)捕捉 Grover 生成的假新聞,因?yàn)樗盍私饧傩侣劦拈L(zhǎng)尾分布在哪里,也因此知道 AI 假新聞的長(zhǎng)尾分布是否被不自然地截?cái)唷?/p>
開(kāi)源策略
生成器的發(fā)布很關(guān)鍵。首先,似乎不開(kāi)源像 Grover 這樣的模型對(duì)我們來(lái)說(shuō)更安全。但是,Grover 能夠有效檢測(cè)神經(jīng)網(wǎng)絡(luò)生成的假新聞,即使生成器比其大多了(如第 5 部分所示)。如果不開(kāi)源生換器,那針對(duì)對(duì)抗攻擊的手段就很少了。
最后,研究人員計(jì)劃公開(kāi)發(fā)布 Grover-Base 和 Grover-Large,感興趣的研究者也可以申請(qǐng)下載 Grover-Mega 和 RealNews。











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論