 電子發(fā)燒友App
電子發(fā)燒友App













 創(chuàng)作
創(chuàng)作 發(fā)文章
發(fā)文章 發(fā)帖
發(fā)帖  提問
提問  發(fā)資料
發(fā)資料 發(fā)視頻
發(fā)視頻資料介紹
軟件簡介
深度學(xué)習(xí)模型的嵌入式部署一直以來都不是那么得容易,雖然現(xiàn)在有Nvidia Nano和TFLite的樹莓派部署,但要么硬件成本太高、功耗太大、要么性能太差,難以實(shí)用化和產(chǎn)品化。一方面,AI科學(xué)家和工程師沒有太多的嵌入式知識,另一方面,嵌入式工程師沒有太多AI的知識,因此很需要開源硬件社區(qū)來解決這些問題。
本文介紹AIoT目前的情況以及面臨的挑戰(zhàn),并講解Maix-EMC的開發(fā)緣由,功能和實(shí)現(xiàn)。我們也希望有一定基礎(chǔ)的小伙伴可以加入開源社區(qū)一起完善Maix-EMC,讓大家可以轉(zhuǎn)換更多結(jié)構(gòu)的模型到低成本AIoT硬件上。(參與項(xiàng)目貢獻(xiàn)的小伙伴可獲贈Maix套裝一份!)
眼瞅著AI紅紅火火,無數(shù)的嵌入式工程師也眼紅著。與此同時(shí),一大批AI科學(xué)家開發(fā)出來的模型,也面臨落地問題。基于安卓或者Linux的開發(fā)者還好,谷歌大佬給了TFLite的支持,但是沒有AI加速器的普通ARM平臺板子成本動輒已經(jīng)幾百元了,而跑起模型來卻只有幾幀。。玩單片機(jī)的嵌入式工程師手頭的主控芯片往往算力最高僅數(shù)百M(fèi)OPS,內(nèi)存數(shù)百KB,也沒有TFLite解釋器,一切都是那么絕望。
?
OpenMV模組
另一方面,AI科學(xué)家和工程師們也有著自己的硬件夢,估計(jì)很多人早就用樹莓派玩起了TFLite,或者更深入地玩起了Tengine, NCNN等加速引擎。但是沒有AI加速器的加持,再怎么優(yōu)化,幀數(shù)還是個位數(shù),價(jià)格親民的樹莓派3+攝像頭 成本也要接近300元了!
?
樹莓派開發(fā)板
作為嵌入式設(shè)備主控芯片的老大哥---ARM,早早地出了在自家Cortex-M系列芯片上運(yùn)行的NN后端支持庫:CMSIS-NN。然而其充其量相當(dāng)于TF的ops的底層實(shí)現(xiàn),需要用戶小心翼翼地管理內(nèi)存,設(shè)置量化參數(shù)。這都2019年了,誰還想要像5000年前那樣手工擼神經(jīng)網(wǎng)絡(luò)呢?
2019年,谷歌也推出了TFLite for Micro,與ARM相反,谷歌是從復(fù)雜的TFLite往下精簡。粗粗翻閱TFLite for Micro的代碼,目前還在比較初級的階段,支持的ops比較少,內(nèi)存管理貌似不夠精簡(使用了大量的allocator),為了支持一些動態(tài)特性有些許效率的犧牲。當(dāng)然其優(yōu)點(diǎn)還是支持從谷歌的TFLite轉(zhuǎn)換。
目前,這兩者都還處于實(shí)驗(yàn)階段,還沒有跑起來MobileNet等大家耳熟能詳?shù)妮p量級網(wǎng)絡(luò),能跑的只是MNIST或者Cifar10等級的教學(xué)意義上的小網(wǎng)絡(luò),沒有任何的意義,并且它們對要求使用者具有豐富的神經(jīng)網(wǎng)絡(luò)經(jīng)驗(yàn),包括但不限于:量化,剪枝,蒸餾,壓縮。這些都大大限制了它的實(shí)用性。
不過,高手在民間,2019年春節(jié),在UP主的QQ群里就活捉了一只來自拉夫堡大學(xué)的生猛老博,他的嵌入式神經(jīng)網(wǎng)絡(luò)框架NNoM就實(shí)現(xiàn)了不錯的可用性,讓用戶可以忽略模型在嵌入式端的實(shí)現(xiàn)細(xì)節(jié),通過其解釋器自動執(zhí)行完畢。在這個框架下,基本只受限于主控本身內(nèi)存,算力,以及作者本身的填坑速度了。
新的轉(zhuǎn)機(jī)
在2018年末,嘉楠耘智出了一款價(jià)格親民的高素質(zhì)純國產(chǎn)AI芯片----K210。其低廉的價(jià)格(3美金以下),新穎的核心(RISC-V 64GC),強(qiáng)大的算力(~1TOPS),較低的功耗(0.3~0.5W),以及穩(wěn)定的貨源。吸引了Sipeed和TensorLayer開源社區(qū)的注意。圍繞著這款芯片,Sipeed開源了一系列的硬件模塊設(shè)計(jì),制作了多款嵌入式板卡:MAIX Go/Bit/Dock/Duino…
?
Sipeed基于K210開發(fā)的相關(guān)模組
為了方便大家快速上手,Sipeed開發(fā)了易用的MaixPy (MicroPython)環(huán)境, 并兼容了多數(shù)OpenMV接口:
Github: Sipeed - MaixPy Micropython env for Sipeed Maix boards. Contribute to sipeed/MaixPy development by creating an account on GitHub.?github.com
?
?
雖然Maix板卡已經(jīng)具備了運(yùn)行MobileNet等典型網(wǎng)絡(luò)的能力,具備了實(shí)用性;然而,一直有個問題困擾著Sipeed和TensorLayer社區(qū)的小伙伴們:芯片原廠提供的模型轉(zhuǎn)換器nncase不好用啊。原廠的模型轉(zhuǎn)換器主要有以下問題:
-
對于AI開發(fā)者不友好
用戶需要經(jīng)過:h5 -> pb -> tflite -> kmodel 多道工序才能完成轉(zhuǎn)換。 -
出錯提示過于簡略
nncase的出錯提示讓人摸不著頭腦,僅會報(bào)某層類型不支持,連層號都沒有。又因?yàn)閷拥霓D(zhuǎn)換涉及到前后文順序,單靠一個出錯時(shí)的層號,很難排查。 -
C#工程過于模塊化
雖然轉(zhuǎn)換器本身不是很大的工作量,但是nncase的C#工程過于細(xì)分,有三四級目錄,又沒有相應(yīng)文檔說明,很多愛好者即使有心想改進(jìn)nncase,卻也耐不住性子去翻閱這樣繁雜的工程。
那么好的芯片,沒有好用的工具怎么行,既然原廠的工具不好用,那么開源社區(qū)組團(tuán)上吧–>
擼一個模型轉(zhuǎn)換器吧
Maix-EMC的初衷就是做一個好用的、好維護(hù)的、社區(qū)型、跨平臺模型轉(zhuǎn)換器,設(shè)計(jì)目標(biāo)如下:
- 使用Python編寫,簡潔清晰,適當(dāng)模塊化,讓有一定基礎(chǔ)的AI工程師能參與完善;
- 基于層結(jié)構(gòu)的模型解析,對于以層為基礎(chǔ)的深度學(xué)習(xí)框架有一定移植性(如,TensorLayer, Keras);
- 使用扁平化,無需復(fù)雜解析的模型文件,即時(shí)載入內(nèi)存,即時(shí)執(zhí)行;
- 嵌入式端解析器使用層類型進(jìn)行解析,后端運(yùn)算庫具備可插拔性(比如使用CMSIS-NN作為后端);
這個構(gòu)想埋在心里很久,一直苦于業(yè)務(wù)繁忙沒有時(shí)間去實(shí)現(xiàn),最近總算是抽空斷斷續(xù)續(xù)地開始挖了這個坑。。如果你只想使用Maxi-EMC,而不關(guān)心它的細(xì)節(jié),請看這篇文章:
低成本AIoT硬件深度學(xué)習(xí)部署實(shí)戰(zhàn)?zhuanlan.zhihu.com
Maxi-EMC的基礎(chǔ)架構(gòu)
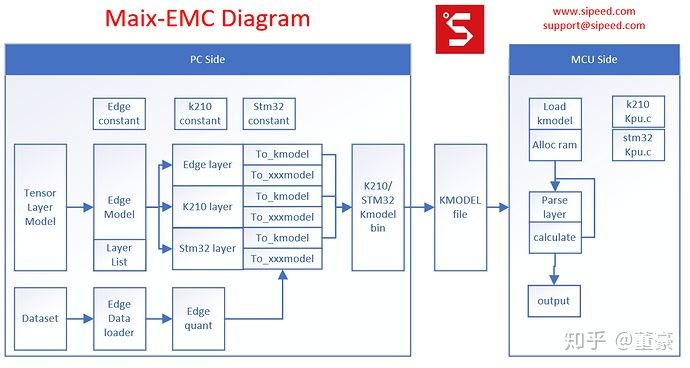
左側(cè):?EMC即這個工作的左側(cè),將PC端的模型文件轉(zhuǎn)換成二進(jìn)制扁平化的模型文件。PC端的模型文件我們選用了TensorLayer,因?yàn)門ensorLayer的層定義高度比較合適,基本等同于kmodel定義的層的高度,兩者轉(zhuǎn)換基本只是作了 量化,某些層的合并優(yōu)化, 極大地加快了開發(fā)進(jìn)度。反觀TensorFlow的pb文件里算子,低到了Add, mul的程度, 需要手工整合這些低層次算子到層定義,非常不便。
中間:這個工作的中間是kmodel文件,類似于字節(jié)碼或者說IR。這里模型文件沒有采用通用的protobuf(pb)或者flatbuffer(tflite), 因?yàn)閷τ谇度胧狡脚_來說,它們的解析以及內(nèi)存消耗都太大。為了快速實(shí)現(xiàn)demo,并考慮嵌入式的效率,這里我們借用了k210 sdk中的kmodel v3格式。這個格式本是為K210設(shè)計(jì),但是同樣適用于普通嵌入式平臺,只需新增通用層類型的定義。
右側(cè):這個工作的右側(cè)是嵌入式硬件平臺上的kmodel解釋器(interpreter)。對于k210, 我們只需借用SDK本身的kpu.c, 稍作修改即可。對于普通單片機(jī),我們只需將kpu.c中的卷積層計(jì)算函數(shù)替換成普通的cpu計(jì)算函數(shù)。這里的計(jì)算后端可以借用CMSIS-NN或者NNoM的計(jì)算后端,往上套上kmodel層參數(shù)的調(diào)用wrapper即可。
下面我們從左到右介紹整個流程的實(shí)現(xiàn)。
TensorLayer模型轉(zhuǎn)換為kmodel
層結(jié)構(gòu)的轉(zhuǎn)換
由于TensorLayer使用基于層的模型結(jié)構(gòu)描述,整個轉(zhuǎn)換過程比較簡單。入口文件是edge_model.py,其中g(shù)en_edge_layers_from_network將TensorLayer層轉(zhuǎn)換為EMC的層中間表示形式。這里首先通過platform_table查表選擇當(dāng)前硬件平臺使用的TensorLayer層轉(zhuǎn)EMC層的函數(shù)表,以及打包模型的函數(shù)。
platform_table = {
# platform tl layer convertor model generator
'k210' : [tl_to_k210_table, gen_kmodel]
#'stm32' : gen_stm32_layer_func_table,
} 在tl_to_k210_table中,gen_edge_layer_from_network查找到對應(yīng)的TensorLayer層類型的表項(xiàng),并往后匹配到最長的列表,將該列表交給layer_generator 來生成 EMC中間層的list (可能會在前后加了上傳/下載/量化/去量化的dummy層)
tl_to_k210_table= {
# TL layer class layer_generator merge
'Dense' :[gen_fc_layer, [[],]] ,
'Flatten' :[gen_flatten_layer, [[],]] ,
'Reshape' :[None, [[],]] ,
'GlobalMaxPool2d' :[gen_gmaxpool2d_layer, [[],]] ,
'GlobalMeanPool2d' :[gen_gavgpool2d_layer, [[],]] ,
'MaxPool2d' :[gen_maxpool2d_layer, [[],]] ,
'MeanPool2d' :[gen_avgpool2d_layer, [[],]] ,
'Concat' :[gen_concat_layer, [[],]] ,
'Conv2d' :[gen_k210_conv_layer, [[], ['BatchNorm'],]] ,
'DepthwiseConv2d' :[gen_k210_conv_layer, [[], ['BatchNorm'],]] ,
'ZeroPad2d' :[gen_k210_conv_layer, [['Conv2d'], \
['Conv2d', 'BatchNorm'], \
['DepthwiseConv2d'], \
['DepthwiseConv2d', 'BatchNorm']]] ,
'DummyDequant' :[gen_dequant_layer, [[],]] ,
'SoftMax' :[gen_softmax_layer, [[],]] ,
}量化操作
由于TensorLayer目前沒有很好的量化API,所以在EMC的層轉(zhuǎn)換中附帶實(shí)現(xiàn)了參數(shù)量化。
edge_quant.py中可選minmax或者kld量化。實(shí)測對于小模型,minmax還是最簡單直接,快速有效的方式。KLD方式可能略有提升,但有時(shí)卻會負(fù)優(yōu)化。。為了進(jìn)一步提升精度,我們還使用了Channel Wise的量化方式來降低精度損失。對每一個Channel使用不同的量化參數(shù),直到最后再合并,經(jīng)測試在大通道的模型中會有一定的優(yōu)化效果。
后處理及打包
至此我們初步將TensorLayer層轉(zhuǎn)換成了一系列層列表,我們再使用optimize_layers來優(yōu)化層列表,去除一些抵消的層(如相鄰的量化/去量化層),進(jìn)行一些可選的后處理(比如k210的stride修復(fù)步驟)。
然后我們使用gen_kmodel將層列表轉(zhuǎn)換成kmodel層列表中的每個層都有to_kmodel方法,調(diào)用該方法即可獲得當(dāng)前層符合kmodel格式的layer body的bytearray結(jié)果。gen_kmodel再把所有層的body堆疊在一起,統(tǒng)計(jì)好最大的動態(tài)內(nèi)存需求,加好頭部,即得到了kmodel。
EMC 層支持的添加
這里簡單介紹下如何添加新的層支持。首先在edge_model.py的tl_to_k210_table里加上你需要添加的TensorLayer層與EMC層的轉(zhuǎn)換表項(xiàng)。然后在對應(yīng)的xxx_layer.py中加上對應(yīng)的實(shí)現(xiàn)。K210相關(guān)的加速層在k210_layer.py中實(shí)現(xiàn)(目前已經(jīng)基本實(shí)現(xiàn),但是需要修復(fù)一些bug),CPU計(jì)算的非加速層,在edge_layer中實(shí)現(xiàn)。只需模仿其中的層的實(shí)現(xiàn),對每個層類型,完成以下一個函數(shù)和一個類:
- gen_xxx_layer: 輸入TL layer list, 轉(zhuǎn)換成EMC layer list;
- class xxx_Layer: 需要實(shí)現(xiàn)init方法(填充層信息),以及to_kmodel方法(按kmodel格式填充信息,返回打包的bytearray)
事實(shí)上,你可以實(shí)現(xiàn)自定義的to_xxxmodel方法,在此框架上實(shí)現(xiàn)你自己的模型格式。
kmodel簡介
kmodel是一個自定義的,扁平化的模型存儲格式,模型格式的封裝已經(jīng)在EMC代碼里完成,這里簡要介紹一下:在EMC中,我們調(diào)用了dissect.cstruct, 這是pyhton解析c結(jié)構(gòu)體的庫, 很方便我們使用k210的kpu.c中關(guān)于kmodel的結(jié)構(gòu)體定義。在EMC中,這部分定義放在k210_constant.py中:
"
typedef struct
{
uint32 version;
uint32 flags;
uint32 arch;
uint32 layers_length;
uint32 max_start_address;
uint32 main_mem_usage;
uint32 output_count;
} kpu_model_header_t;
typedef struct
{
uint32 address;
uint32 size;
} kpu_model_output_t;
typedef struct
{
uint32 type;
uint32 body_size;
} kpu_model_layer_header_t;
...kmodel 頭部是kpu_model_header_t, 描述了 版本,量化位數(shù),層數(shù),最大內(nèi)存占用大小(驅(qū)動中一次性申請?jiān)撃P托枰膭討B(tài)內(nèi)存),輸出節(jié)點(diǎn)數(shù)量。在頭部之后,排列著若干個kpu_model_output_t,描述輸出節(jié)點(diǎn)的信息。在輸出節(jié)點(diǎn)信息之后,排列著所有層的頭部信息:kpu_model_layer_header_t,依次描述層的類型,層body的大小。在層頭部信息之后,就按層信息依次排列層body數(shù)據(jù),其中某些部分會要求一定的字節(jié)對齊。
層類型定義在edge_constant.py中,在原始的kpu.h的定義上稍作修改,區(qū)分了k210專用層和普通層(這里是為了快速移植K210驅(qū)動才使用了K210專用層,理論上僅定義一套通用層標(biāo)準(zhǔn)比較好)
K210的kmodel解釋器的實(shí)現(xiàn)
可以參見kpu.c, 驅(qū)動會按順序讀取kmodel每一層的層信息,根據(jù)層類型執(zhí)行對應(yīng)函數(shù)。
需要注意的是上傳/下載操作。K210內(nèi)存分為6M CPU內(nèi)存 和 2M KPU內(nèi)存。使用KPU計(jì)算的層,需要將待計(jì)算的數(shù)據(jù)上傳到KPU內(nèi)存。在KPU中,可以連續(xù)計(jì)算很多層CONV相關(guān)計(jì)算,而無需將結(jié)果下載到CPU內(nèi)存。但是一旦下一層是需要CPU運(yùn)算的層,則需要進(jìn)行一次下載才能繼續(xù)運(yùn)行。所以,我們需要留意TensorLayer層的順序,在需要切換KPU/CPU運(yùn)行的層前后,插入上傳,下載的dummy 層。在EMC中,我們使用meta_info[‘is_inai’]字段確認(rèn)當(dāng)前的待計(jì)算內(nèi)容是否在AI內(nèi)存。
另外,KPU計(jì)算,使用的2M內(nèi)存,是以乒乓形式使用,即輸入數(shù)據(jù)在開端,則輸出結(jié)果在末端進(jìn)入下一層后,上一層的輸出結(jié)果作為了輸入結(jié)果,在末端,計(jì)算結(jié)果放到了開端。
如此往復(fù)計(jì)算,EMC中meta_info[‘conv_idx’]記錄了當(dāng)前的卷積層序號,進(jìn)而可以確認(rèn)當(dāng)前的輸出結(jié)果所在KPU內(nèi)存的偏移。
其它注意點(diǎn),需要下載kpu.c查看:https://github.com/kendryte/kendryte-standalone-sdk/blob/develop/lib/drivers/kpu.c
測試
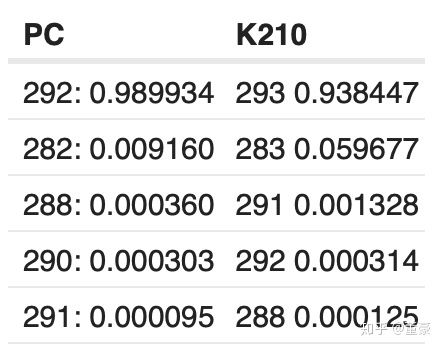
我們使用Maix-EMC測試轉(zhuǎn)換了mbnet的每一層,與PC原始結(jié)果對比:
?
同一張圖片,alpha=1.0, top5的預(yù)測概率:
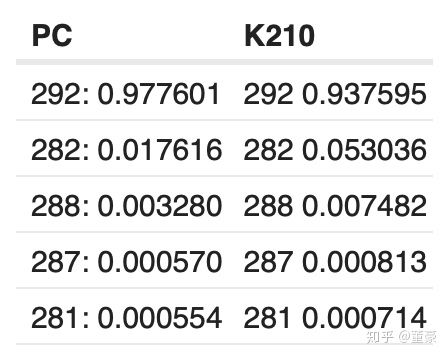
同一張圖片,alpha=0.75, top5的預(yù)測概率:
同一張圖片,alpha=0.5, top5的預(yù)測概率:
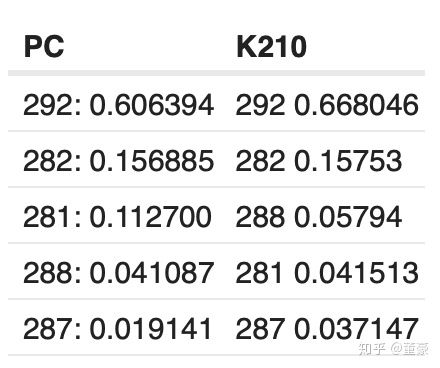
可以看到相對PC端的結(jié)果,K210的計(jì)算結(jié)果退化了3~6%,是否是轉(zhuǎn)換器原因造成的呢?
我們對比下谷歌的TFLite的量化工具的測試數(shù)據(jù):
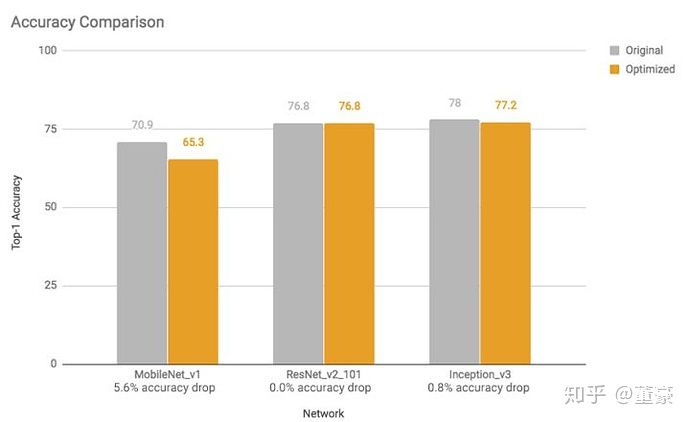
發(fā)現(xiàn)對于MobileNet來說,TFLite的量化也造成了5.6%的損失,所以這是正常的損失。(當(dāng)然這里的tflite的精度是指的是數(shù)據(jù)集總體的精度損失,我前面僅測了一張圖片的概率損失,有差別)。雖然我們有很多方式改善訓(xùn)練后量化損失,但是基本都會膨脹模型體積,所以在這里不再贅述。
小結(jié)
目前Maix-EMC完成了初步簡單結(jié)構(gòu)的模型轉(zhuǎn)換功能,可以基于TensorLayer框架快速部署到K210普通上,對于復(fù)雜模型仍然需要社區(qū)小伙伴一起完善。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 嵌入式学习--基础准备15次下载
- 学习嵌入式的开发线路,新手怎么学习嵌入式?12次下载
- 深度学习嵌入式系统42次下载
- 深度学习在嵌入式设备上的应用1次下载
- 嵌入式学习14次下载
- 嵌入式学习路线怎么学,如何学习嵌入式系统13次下载
- 基于预训练模型和长短期记忆网络的深度学习模型19次下载
- 深度模型中的优化与学习课件下载3次下载
- 新型基于深度学习的目标实时跟踪算法10次下载
- 学习嵌入式系统有哪些方向?4次下载
- 嵌入式应该如何学习?嵌入式学习方法和嵌入式学习路线资料说明12次下载
- 嵌入式软件方向的学习难点有哪些应该如何学习0次下载
- 嵌入式Linux与物联网软件开发C语言内核深度解析书籍的介绍9次下载
- 嵌入式DSP学习-学习笔记8次下载
- [学习嵌入式]嵌入式系统学习方法,轻松入门嵌入式79次下载
- 深度学习中的模型权重3098次阅读
- 深度学习模型训练过程详解1901次阅读
- 当深度学习遇上TDA41465次阅读
- 嵌入式系统应该学习那些知识5337次阅读
- 嵌入式系统的全面解析3363次阅读
- 学习嵌入式技术的重点分享2891次阅读
- 学习嵌入式技术需要注意很多!1013次阅读
- 新手学嵌入式学习路线大纲分享 嵌入式学习路线怎么学3664次阅读
- 到底该如何学习嵌入式?9054次阅读
- 基于SCADE模型的高安全性嵌入式软件解决方案设计2923次阅读
- 嵌入式时代已经来临,嵌入式学习的方法你知道多少呢?3029次阅读
- 嵌入式系统开发学习心得体会_经验总结31219次阅读
- 学嵌入式开发入门_学嵌入式开发需要看哪些书籍29873次阅读
- 嵌入式Linux的学习方法解析3332次阅读
- 学习嵌入式要什么基础4374次阅读
 上傳資料賺積分
上傳資料賺積分下載排行
本周
- 1山景DSP芯片AP8248A2數(shù)據(jù)手冊
- 1.06 MB | 532次下載 | 免費(fèi)
- 2RK3399完整板原理圖(支持平板,盒子VR)
- 3.28 MB | 339次下載 | 免費(fèi)
- 3TC358743XBG評估板參考手冊
- 1.36 MB | 330次下載 | 免費(fèi)
- 4DFM軟件使用教程
- 0.84 MB | 295次下載 | 免費(fèi)
- 5元宇宙深度解析—未來的未來-風(fēng)口還是泡沫
- 6.40 MB | 227次下載 | 免費(fèi)
- 6迪文DGUS開發(fā)指南
- 31.67 MB | 194次下載 | 免費(fèi)
- 7元宇宙底層硬件系列報(bào)告
- 13.42 MB | 182次下載 | 免費(fèi)
- 8FP5207XR-G1中文應(yīng)用手冊
- 1.09 MB | 178次下載 | 免費(fèi)
本月
- 1OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234315次下載 | 免費(fèi)
- 2555集成電路應(yīng)用800例(新編版)
- 0.00 MB | 33566次下載 | 免費(fèi)
- 3接口電路圖大全
- 未知 | 30323次下載 | 免費(fèi)
- 4開關(guān)電源設(shè)計(jì)實(shí)例指南
- 未知 | 21549次下載 | 免費(fèi)
- 5電氣工程師手冊免費(fèi)下載(新編第二版pdf電子書)
- 0.00 MB | 15349次下載 | 免費(fèi)
- 6數(shù)字電路基礎(chǔ)pdf(下載)
- 未知 | 13750次下載 | 免費(fèi)
- 7電子制作實(shí)例集錦 下載
- 未知 | 8113次下載 | 免費(fèi)
- 8《LED驅(qū)動電路設(shè)計(jì)》 溫德爾著
- 0.00 MB | 6656次下載 | 免費(fèi)
總榜
- 1matlab軟件下載入口
- 未知 | 935054次下載 | 免費(fèi)
- 2protel99se軟件下載(可英文版轉(zhuǎn)中文版)
- 78.1 MB | 537798次下載 | 免費(fèi)
- 3MATLAB 7.1 下載 (含軟件介紹)
- 未知 | 420027次下載 | 免費(fèi)
- 4OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234315次下載 | 免費(fèi)
- 5Altium DXP2002下載入口
- 未知 | 233046次下載 | 免費(fèi)
- 6電路仿真軟件multisim 10.0免費(fèi)下載
- 340992 | 191187次下載 | 免費(fèi)
- 7十天學(xué)會AVR單片機(jī)與C語言視頻教程 下載
- 158M | 183279次下載 | 免費(fèi)
- 8proe5.0野火版下載(中文版免費(fèi)下載)
- 未知 | 138040次下載 | 免費(fèi)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論