完善資料讓更多小伙伴認(rèn)識你,還能領(lǐng)取20積分哦,立即完善>
標(biāo)簽 > 圖像生成
文章:21個 瀏覽:6896次 帖子:1個
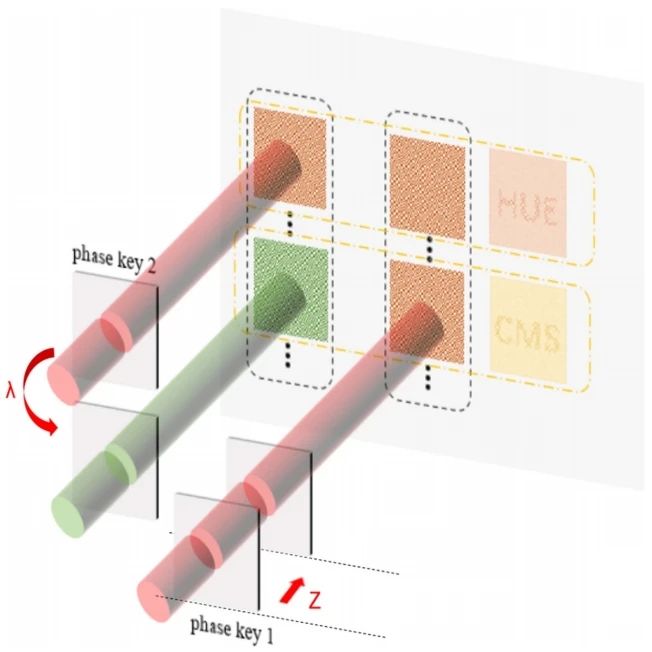
基于雙光復(fù)用的多圖像隱形視覺加密系統(tǒng)設(shè)計
光學(xué)信息安全領(lǐng)域采用光作為信息介質(zhì),其特點是具有高速和并行處理能力。此外,由于光的波長較短,它提供了很大的信息容量,并可以隱藏多個維度的數(shù)據(jù),包括波長、...
2024-08-21 標(biāo)簽:算法光學(xué)空間光調(diào)制器 360 0

香港大學(xué)最新提出!實現(xiàn)超現(xiàn)實的人類圖像生成:HyperHuman
最后,為了進一步提高視覺質(zhì)量,我們提出了一種結(jié)構(gòu)引導(dǎo)細化器來組合預(yù)測條件,以更詳細地生成更高分辨率。大量的實驗表明,我們的框架具有最先進的性能,可以在不...
2023-11-27 標(biāo)簽:框架數(shù)據(jù)集圖像生成 759 0

谷歌新作UFOGen:通過擴散GAN實現(xiàn)大規(guī)模文本到圖像生成
擴散模型和 GAN 的混合模型最早是英偉達的研究團隊在 ICLR 2022 上提出的 DDGAN(《Tackling the Generative Le...

CVPR2023 RobustNeRF: 從單張圖像生成3D形狀
在通常使用的nerf數(shù)據(jù)中,一個場景往往無法從同一視角捕捉多幅圖像,這使得數(shù)學(xué)建模干擾物變得困難。更具體地說,雖然視角相關(guān)效應(yīng)(View-Depende...
2023-11-09 標(biāo)簽:模型數(shù)據(jù)建模圖像生成 947 0

低質(zhì)量圖像的生成與增強的區(qū)別 圖像生成領(lǐng)域中存在的難點
1. 論文信息 ? 2. 引言 ? 這篇論文的研究背景是圖像生成領(lǐng)域中存在的一個難點 - 如何從低質(zhì)量的圖像中恢復(fù)高質(zhì)量的細節(jié)信息。這對很多下游應(yīng)用如監(jiān)...

NUS&深大提出VisorGPT:為可控文本圖像生成定制空間條件
本文將空間條件中物體的形狀、位置以及它們之間的關(guān)系等性質(zhì)總結(jié)為視覺先驗(Visual Prior),并使用Transformer Decoder以Gen...
2023-06-11 標(biāo)簽:模型數(shù)據(jù)集圖像生成 355 0
近日,曾參與創(chuàng)建 Stable Diffusion 的 Runway 公司推出了一個新的人工智能模型「Gen-1」,該模型通過應(yīng)用文本 prompt 或...

GAN 可以將任意的分布作為輸入,這里的 Z 就是輸入,在實驗中我們多取Z~N(0,1),也多取 [?1,1] 的均勻分布作為輸入。生成器 G 的參數(shù)為...
2019-02-13 標(biāo)簽:GaN機器學(xué)習(xí)圖像生成 5700 0
Pix2Pix與Unity 3D結(jié)合,打造專屬小貓咪!
論文研究了條件對抗網(wǎng)絡(luò)作為一種圖像到圖像轉(zhuǎn)換問題的通用解決方案。這些網(wǎng)絡(luò)不僅學(xué)習(xí)從輸入圖像到輸出圖像的映射,還學(xué)習(xí)了用于訓(xùn)練該映射的損失函數(shù)。這使得對傳...
光柵化是在計算機上生成圖像的重要步驟,然而無論是opengl還是directx還是其他的圖形接口都封裝了光柵化方法。我自己做了個光柵器,接下來就說一下怎...
2018-04-27 標(biāo)簽:圖像生成 8965 0
近日,韓國科學(xué)團隊宣布研發(fā)出名為 KOALA 的新型人工智能圖像生成模型,該模型在速度和質(zhì)量上均實現(xiàn)了顯著突破。KOALA 能夠在短短 2 秒內(nèi)生成高質(zhì)...
韓國科研團隊發(fā)布新型AI圖像生成模型KOALA,大幅優(yōu)化硬件需求
由此模型的核心在于其運用了“知識蒸餾”(knowledge distillation)技術(shù),這使得開源圖像生成工具Stable Diffusion XL...

Stability AI試圖通過新的圖像生成人工智能模型保持領(lǐng)先地位
Stability AI的最新圖像生成模型Stable Cascade承諾比其業(yè)界領(lǐng)先的前身Stable Diffusion更快、更強大,而Stable...
瓊斯去年底在進行自主研究時,發(fā)現(xiàn)OpenAI的圖像生成模型DALL-E 3存在一個漏洞,漏洞利用者可以越過AI保護墻來制作色情內(nèi)容。他將此情況報告給微軟...
NUS&深大提出VisorGPT:為可控文本圖像生成定制空間條件
本文將空間條件中物體的形狀、位置以及它們之間的關(guān)系等性質(zhì)總結(jié)為視覺先驗(Visual Prior),并使用Transformer Decoder以Gen...
2023-09-26 標(biāo)簽:模型數(shù)據(jù)集圖像生成 668 0
多模態(tài)大模型企業(yè)智子引擎,完成數(shù)千萬元天使+輪融資
2023年3月,自行研究發(fā)表了150億參數(shù)的多主題生成文本模型,并在此模型的基礎(chǔ)上,應(yīng)用“元乘象 ChatImg 1.0”將圖像生成文本形態(tài)。之后的2...
華為云正式發(fā)布盤古大模型3.0,包括“5+N+X”三層架構(gòu)
華為常務(wù)董事、華為云CEO張平安以“AI重塑千行百業(yè)”為主題發(fā)表了開幕辭,宣布正式發(fā)布了華為盤古Model 3.0。
谷歌新作Muse:通過掩碼生成Transformer進行文本到圖像生成
與建立在級聯(lián)像素空間(pixel-space)擴散模型上的 Imagen (Saharia et al., 2022) 或 Dall-E2 (Rames...
2023-01-09 標(biāo)簽:模型圖像生成Transformer 962 0
Stability AI開源圖像生成模型Stable Diffusion
Stable Diffusion 的很多用戶已經(jīng)公開發(fā)布了生成圖像的樣例,Stability AI 的首席開發(fā)者 Katherine Crowson 在...
3月20日消息,據(jù)美國科技媒體TechCrunch報道,英偉達在GTC 2019(GPU技術(shù)大會)上,推出了一款名為GauGAN的圖像生成器。它使用生成...
 換一批
換一批
編輯推薦廠商產(chǎn)品技術(shù)軟件/工具OS/語言教程專題
| 電機控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無刷電機 | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機 | PID | MOSFET | 傳感器 | 人工智能 | 物聯(lián)網(wǎng) | NXP | 賽靈思 |
| 步進電機 | SPWM | 充電樁 | IPM | 機器視覺 | 無人機 | 三菱電機 | ST |
| 伺服電機 | SVPWM | 光伏發(fā)電 | UPS | AR | 智能電網(wǎng) | 國民技術(shù) | Microchip |
| Arduino | BeagleBone | 樹莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1

