 電子發(fā)燒友App
電子發(fā)燒友App


作者:羅華
相比Google的SDN流量調(diào)度方案,F(xiàn)acebook的Edge Fabric更具備可學習性,通過擴展一些組件來采集路由和流量信息,就可以通過使用標準的BGP來實現(xiàn)自動化的流量調(diào)度,對于很多內(nèi)容服務商來說只是需要添加少量組件就可以實現(xiàn)。
匯總起來的組件如下:
·?網(wǎng)絡的BGP架構; ·?網(wǎng)絡內(nèi)的流量采集(IPFIX或者sFlow); · BGP路由信息采集:BMP; ·?服務器端eBPF標識流量、被動測量性能; ·?整體控制框架。
大多數(shù)互聯(lián)網(wǎng)公司只是缺最后兩個部分而已。最后一部分豐儉由人,量力而行,都可以實現(xiàn)。 ?
?
Facebook的用戶數(shù)量超過20億,通過部署在6大洲的幾十個PoP節(jié)點向最終用戶提供服務,這些PoP節(jié)點通過BGP連接傳統(tǒng)運營商,每個節(jié)點的BGP連接數(shù)量從幾十個到幾百個不等。如何向最終用戶提供更好的服務,就需要將流量在這些BGP連接中合理調(diào)度了。
Facebook使用的叫做Edge Fabric的系統(tǒng)來實現(xiàn)這個任務,從廣義范疇上來講,這是一套SDN系統(tǒng),但具體對比同樣功效的Google的Espresso,還是可以看出兩者之間的差異是比較大的。簡單說Google的Espresso通過全局的應用感知在自研軟件、自研硬件上面來實現(xiàn)全球流量控制,F(xiàn)acebook則通過整體框架來實現(xiàn)性能感知的BGP調(diào)度,不僅可以用于自研設備、同時還將第三方的商業(yè)路由器納入統(tǒng)一的實現(xiàn)框架。這對于其他互聯(lián)網(wǎng)公司來講更具參考意義。
Edge Fabric有效的幫助Facebook降低的廣域鏈路的擁塞、丟包,同時大大提高了這些BGP連接的利用效率、節(jié)省了費用。
前? ?言
對比互聯(lián)網(wǎng)的十幾年前,近年來流量有著截然不同的特點。流量越來越多地來自少數(shù)大型內(nèi)容提供商、云提供商和CDN網(wǎng)絡。目前,僅十個AS(自治系統(tǒng))就貢獻了互聯(lián)網(wǎng)上70%的流量,而在2007年,需要數(shù)千個AS才能達到這個量級。這種內(nèi)容整合在很大程度上源于視頻、流媒體的崛起,如今,視頻、流媒體構成了互聯(lián)網(wǎng)上的主要流量。這種視頻流量既需要高吞吐量,又需要低延遲,在這種情況下,傳輸質(zhì)量會極大影響用戶體驗。 ? 為了提供這種高容量、高要求的流量,并改善用戶感知的性能和可用性,這些內(nèi)容服務商已經(jīng)重塑了他們自己的網(wǎng)絡拓撲結構。他們在全球部署眾多的PoP節(jié)點和具備有直連到最終用戶的電信運營商互聯(lián),為其提供服務。PoP節(jié)點通常有多個BGP可用路徑到達用戶網(wǎng)絡,這使得它可以優(yōu)選最“短”(AS-Path最短,但并非100%最優(yōu))路徑。這種豐富的互聯(lián)性使網(wǎng)絡運營者能夠控制大部分的路徑,總的來說提供了必要的容量。相比之下,傳統(tǒng)的通過大型電信運營商層級互聯(lián)的體系架構很難提供所需的容量,以滿足流量快速增長的需求。
盡管這種多BGP連接的連通性可能提供性能優(yōu)勢,但服務商想利用這些優(yōu)勢時會面臨挑戰(zhàn)。最重要的是,盡管在傳輸?shù)牧髁亢屯負渖习l(fā)生了巨大的變化,但路由流量的上層控制協(xié)議還是:BGP。BGP自身的本質(zhì)并不適合在扁平的拓撲結構上處理大量合并的流量:
BGP無法感知容量:BGP的互連帶寬和路徑的容量都是有限的。在對一個大型內(nèi)容服務商網(wǎng)絡的監(jiān)測表明,通過BGP策略的優(yōu)選路徑,流量無法在這個路徑中獲得需要的足夠帶寬。內(nèi)容服務商在做路由決策的時候應該考慮到這些限制,特別是因為可能會因為有大量的速率自適應視頻流量而導致?lián)砣?/p>
BGP無法感知性能。
在任何PoP節(jié)點,如果按照BGP的缺省最優(yōu)路徑轉發(fā)流量,可能會導致性能(性能:端到端的流量性能)不佳。BGP在選擇路徑時所依賴的屬性:例如AS-Path的長度、MED 等,都不是與性能實時強相關的。
想要讓BGP實現(xiàn)基于性能感知而替代傳統(tǒng)的選路機制是具有相當?shù)奶魬?zhàn)性。首先,BGP協(xié)議中不包含性能信息,性能感知的決策需要依靠外部機制來獲得性能數(shù)據(jù);第二,到達目的地的路徑的性能指標可能會隨著時間的變化而變化(例如,負載的響應),但BGP協(xié)議僅在更改策略或路由發(fā)送變化時才會改變其優(yōu)選路徑;第三,為了跟蹤性能數(shù)據(jù),內(nèi)容服務商可能需要準實時的地監(jiān)測多個非最優(yōu)的可用路徑,但傳統(tǒng)BGP在任何時間點只能使用一條最優(yōu)路徑到達目的地;第四,由于BGP對每個目的地都只使用一條路徑(非內(nèi)網(wǎng)ECMP,特指邊緣出口),它本身不支持將性能敏感的流量和彈性流量分配到不同的路徑上、以便在各自期望的最佳路徑上更好地利用有限的帶寬。 ? 盡管BGP存在上面所述的種種限制,F(xiàn)acebook還是通過Edge Fabric成功的部署到幾十個PoP節(jié)點的生產(chǎn)網(wǎng)絡中服務其20多億的用戶,本文將闡述Edge Fabric如何設計構建,并提供下面三點貢獻:
首先,由于上述BGP限制的影響大小取決于網(wǎng)絡的設計。網(wǎng)絡連通性和流量特性,使得流行的內(nèi)容服務商難以管理其出口流量。在Facebook中, PoP點通常有四個或更多的出口路由到其眾多的客戶網(wǎng)絡。在實際的出口監(jiān)測中,F(xiàn)acebook發(fā)現(xiàn)有10%的出口會由于BGP策略的分配問題導致某些地址前綴的流量需求是其出口帶寬的2倍,這導致了這些出口的擁塞,然而其他出口這個時候還有剩余可用的帶寬。從PoP節(jié)點到目的地的流量需求可能是很難預測的,同一目的地前綴的流量在幾周內(nèi)最高值和最低值之間會有多達170倍的差異。雖然Facebook的豐富的出口連接提供了更短的BGP路徑、更多的路由選擇以及更高的單個出口帶寬,但單個路徑的容量限制和變化的流量需求使得這種連接變得很難使用。必須使用動態(tài)變化的路由協(xié)議來處理流量,才能在這些限制內(nèi)應對實時變化的流量實現(xiàn)優(yōu)化的效率和性能。
其次,F(xiàn)acebook提出了Edge Fabric的設計,一個基于出口流量優(yōu)化的路由系統(tǒng)。Edge Fabric從Peer(特指BGP鄰居,F(xiàn)acebook的Peer通常是電信運營商)路由器接收BGP路由,監(jiān)控出口方向數(shù)據(jù)的帶寬和流量需求,并決定如何將出口方向流量分配給BGP的出口。Edge Fabric通過向BGP注入路由的方式來影響B(tài)GP的缺省選路過程。2013年開始Edge Fabric就開始了在生產(chǎn)網(wǎng)絡中的實際部署。
第三,通過讓Edge Fabric沿著幾條BGP的可選路徑(不只是BGP的最優(yōu)路徑)對每個目的地前綴進行持續(xù)的性能監(jiān)測。Edge Fabric將一小部分流量切換到這幾條備選路徑上來測試、收集這些路徑的性能數(shù)據(jù)。通過對4個PoP節(jié)點的的測量數(shù)據(jù)顯示:有5%的地址前綴通過選擇非最優(yōu)的BGP路徑,可以看到其延遲平均減少了20毫秒。 ?
設計的考量
PoP節(jié)點
為了減少到最終用戶的延遲,F(xiàn)acebook在全球數(shù)十個地點部署了PoP節(jié)點。PoP節(jié)點的整體架構參見圖1:服務器通過架內(nèi)交換機RSW和聚合交換機ASW的BGP連接最終匯聚連接到多個出口互聯(lián)路由器PR(Peering Router)。 ?
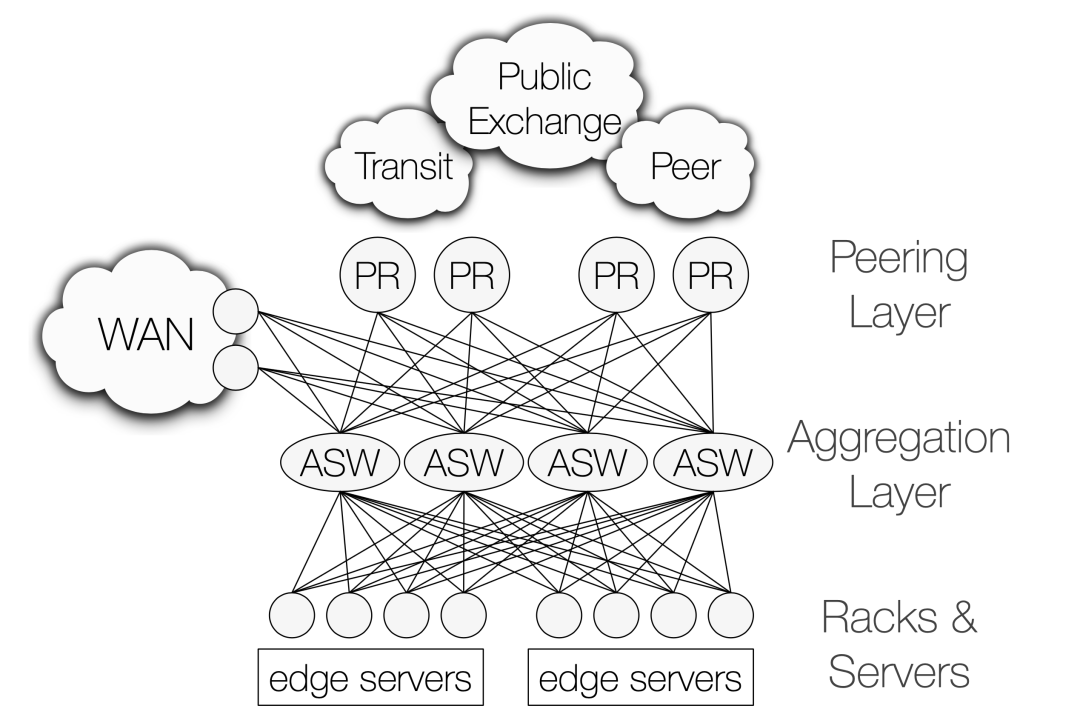
圖1:Facebook PoP節(jié)點架構圖 ? 通過分布在全球的多個地點的PoP節(jié)點,可以有效的降低到最終用戶的延遲:1)就近本地的緩存可以直接給最終用戶提供內(nèi)容;2)用戶的TCP連接直接在就近的PoP節(jié)點終結。
Facebook的更細一些路由只會由一個PoP節(jié)點宣告出來,這意味著,去往這個地址前綴進入哪個PoP節(jié)點數(shù)據(jù)中心是明確的、獨一無二的。至于如何選擇使用哪一個PoP節(jié)點取決于通過基于DNS的全球負載均衡系統(tǒng)(根據(jù)客戶端請求DNS的源地址來回應不同的PoP節(jié)點的地址)來實現(xiàn)的。在PoP節(jié)點之間實現(xiàn)的負載均衡系統(tǒng)是通過捕獲鄰居PoP點給用戶提供服務的性能來監(jiān)控,從而優(yōu)化后續(xù)的決定(選擇最優(yōu)的PoP節(jié)點)。PoP節(jié)點的選擇不在本文描述范圍。Edge Fabric實現(xiàn)的是同一個PoP節(jié)點內(nèi)部不同的BGP出口之間的流量調(diào)度(前提是流量的進、出都是同一個PoP節(jié)點),這個和Google的Espresso的調(diào)度范圍有區(qū)別(Espresso可以實現(xiàn)全球調(diào)度,即流量從一個PoP節(jié)點進,另一個PoP節(jié)點出)。
從路由、流量的角度來分析一下。圖2把Facebook前20個PoP節(jié)點的流量相對情況展示了出來。其中整體95%的流量來自于大約65000個地址前綴。參見圖3展示了這20個PoP節(jié)點各自承載了95%流量的地址前綴的數(shù)量,可以看到很多PoP節(jié)點承載了大部分的流量的地址前綴數(shù)量很少,大多數(shù)都是在幾千條以下,有16個PoP節(jié)點的地址前綴數(shù)量少于6500條。 ?
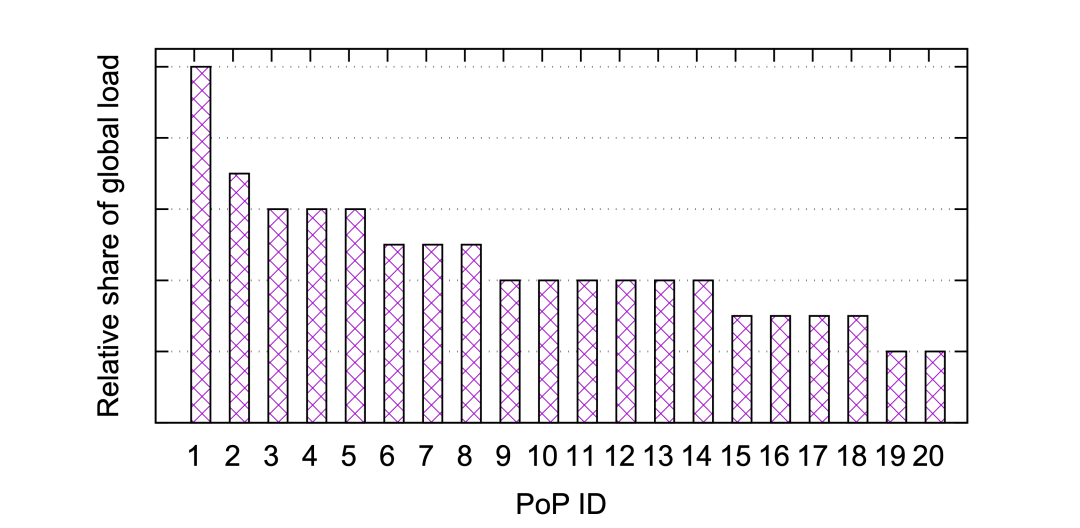
圖2:前20個PoP節(jié)點流量對比 ?
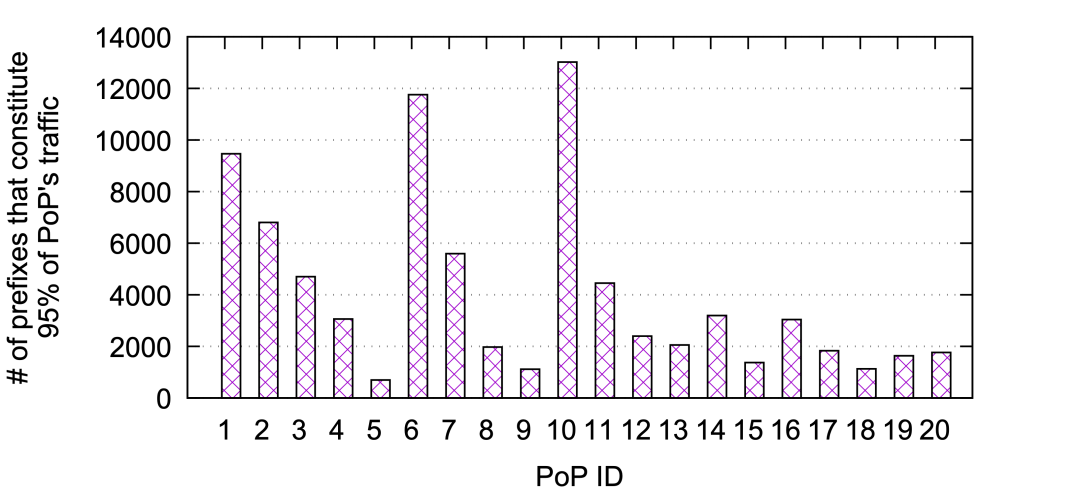
圖3:20個 PoP節(jié)點95%流量來自的地址前綴數(shù)量 ? 進一步查看每一個PoP節(jié)點中貢獻其95%流量的地址前綴條目的組成,參見圖4:大比例都是低于10條路由,所以少量路由的更改就能影響很大的流量變動。 ?
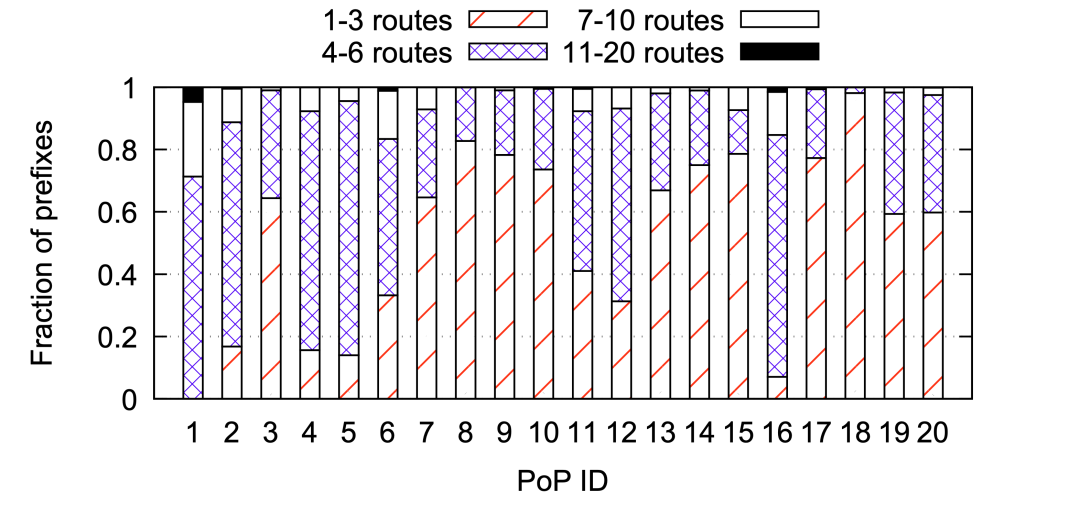
圖4:20個PoP節(jié)點中95%的流量路由占比 ?
AS域間連接
PoP節(jié)點通過PR(Peering Router)來連接其他AS域,這些BGP出口可分為:
1)穿透連接(Transit Providers):通常是電信運營商提供給Facebook一個PNI(私有網(wǎng)絡連接),可以訪問全球所有網(wǎng)段; 2)對等互聯(lián)(Peers):提供對等連接到運營商以及其下聯(lián)的用戶;對等互聯(lián)還可以按照連接當時再分為:
私有對等互聯(lián):通過專用的出口線路進行私有網(wǎng)絡連接;
公有對等互聯(lián):通過公共的互聯(lián)網(wǎng)交換中心互聯(lián)(IXP);
路由服務器互聯(lián):通過IXP的路由服務器(非直連方式)接收路由、發(fā)送流量;
通常PoP節(jié)點內(nèi)對同一個AS域存在多個BGP連接,例如:既有私有的對等互聯(lián),也有通過IXP的公有對等互聯(lián)。為了避免單點故障,通常PoP節(jié)點會和超過2個提供穿透服務的電信運營商互聯(lián),每個運營商的BGP連接會分布在2個或者多個PR路由器上。雖然PR路由器上連接的出口數(shù)量或者帶寬可能有不同,但盡可能的會讓每個PR具備有相同的出口帶寬總容量。
在PR上不同類型的出口互聯(lián)中,優(yōu)選對等互聯(lián)出口,然后才是穿透連接出口 (通過BGP的Local Preference屬性控制), AS-Path路徑長度作為隨后的BGP選路的條件。當有多條可選路徑時,PR選路的優(yōu)先順序按照BGP路由的來源區(qū)分:私有對等互聯(lián) > 公共對等互聯(lián) >?路由服務器互聯(lián)。在設計中,將出口互聯(lián)的類型通過數(shù)字編碼體現(xiàn)在MED屬性里(抹去對端發(fā)送過來的MED值,設置成Facebook自己設計的值)。對比穿透連接出口和對等互聯(lián)出口,會優(yōu)選對等互聯(lián),因為通過觀察發(fā)現(xiàn)對等互聯(lián)出口通常在后半程的路徑上更少出現(xiàn)擁塞(提供穿透連接的通常是一個大型運營商,通過其各種外部互聯(lián)再轉發(fā)到最終目的地所在的AS域,而對等連接屬于同一個運營商控制的網(wǎng)絡、通常有更好的內(nèi)部互聯(lián)質(zhì)量)。相對公共對等互聯(lián)(IXP),F(xiàn)acebook更優(yōu)選具備專屬帶寬的私有對等互聯(lián)出口,這樣可以避免了出口交叉擁塞的可能性(IXP的互聯(lián)帶寬是多家互聯(lián)機構共享的)。
PoP點內(nèi)部的PR和ASW之間是啟用了BGP多路徑功能。PR或者ASW會使用ECMP在多路徑上發(fā)送流量。
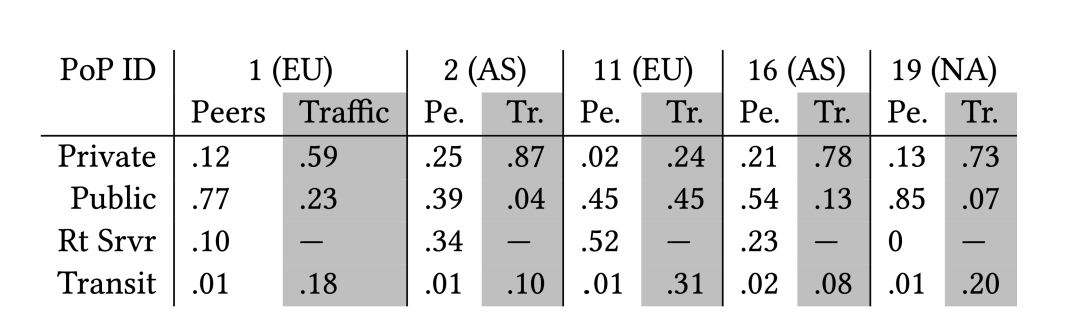
表1:五個PoP節(jié)點的各種出口帶寬和流量比例 ? 總的來說,F(xiàn)acebook整網(wǎng)擁有上千個BGP出口。參見表1顯示了5個PoP節(jié)點的每種類型的BGP出口所占的比例。表中顯示的每個PoP都有數(shù)百個BGP出口,從而具備有豐富多樣的連接性。該表還顯示了每個PoP節(jié)點按照BGP出口類型區(qū)分的流量比例(假設所有流量都按照BGP缺省優(yōu)選路徑,不考慮出口實際容量)。盡管私有對等互聯(lián)的數(shù)量在任何PoP節(jié)點中最多占四分之一(數(shù)量占比12%~25%,歐洲比較特殊,只有2%),但它們接收的流量卻占比極大,除了歐洲PoP-11節(jié)點(歐洲的互聯(lián)中心IXP發(fā)展一直位于全球前列,其自身技術能力、IXP互聯(lián)能力和質(zhì)量都非常出色,所以IXP成在歐洲互聯(lián)的首選,PoP-11通過IXP互聯(lián)的流量占比45%)。除了PoP-11節(jié)點之外,80%以上的出口流量都到分布在私有對等、公共對等和路由服務器互聯(lián)出口上,而不是通過穿透連接出口,這也是如今大型內(nèi)容服務商實現(xiàn)“扁平化”的一個例子。然而,BGP出口類型的分布在不同的PoP節(jié)點中因數(shù)量和流量而有很大的不同。 ?
BGP協(xié)議的挑戰(zhàn)
隨著用戶需求的增加和Facebook迅速擴展其PoP節(jié)點以及基礎設施和出口,F(xiàn)acebook遇到了由于BGP自身的限制而帶來的挑戰(zhàn),這促使誕生了Edge Fabric:通過BGP來實現(xiàn)路由的動態(tài)調(diào)整的SDN方案。任何靜態(tài)的域間路由策略都有可能面臨類似的挑戰(zhàn)(也就是說任何運行BGP的具有足夠大規(guī)模的服務商都會面臨這個痛點)。 ? 互聯(lián)出口帶寬是有限的,但BGP無法感知容量 ? 盡管Facebook建立了很多PoP節(jié)點,擴大了出口容量,并優(yōu)選了私有對等互聯(lián),但一個出口鏈路的容量不足以容納想要發(fā)送的所有流量。需求的快速增長會迅速導致現(xiàn)有的出口容量不足,在某些情況下,沒法進行出口擴容或者可能需要幾個月的時間。需求的短期激增(可能因為某些事件或者節(jié)假日到來)或由于故障導致的出口容量減少,都會導致需求和可用的出口容量之間的波動。此外,PoP節(jié)點就近服務周邊的用戶,因此,就近地區(qū)用戶的作息會導致每天的需求是同步的,按每天都會有同步的峰值,可能在短時間內(nèi)超過其出口容量。此外,特定的某個BGP Peer的出口帶寬可能沒有均勻地分布在相應的PR路由器上面,然而ASW通過ECMP將均擔的流量平均的送到這些PR上,也會導致某些PR會有擁塞(ASW對出口帶寬信息不可見,因為BGP沒法感知容量)。通常,給出口分配超量的流量會導致?lián)砣舆t和丟包,而且還會因為數(shù)據(jù)包重傳導致服務器的負荷也增加。
本文描述了如何實現(xiàn)建立在BGP之上還能感知容量的出口決策系統(tǒng)。為了更好的理解Facebook面臨的問題,通過對2天實際流量的數(shù)據(jù)(每個PR出口上的每個地址前綴流量,按分鐘取均值)進行分析。
圖5展示了沒有使用Edge Fabric來進行優(yōu)化控制的情況,所有PoP節(jié)點的80%的地址段都經(jīng)歷了擁塞。 ?
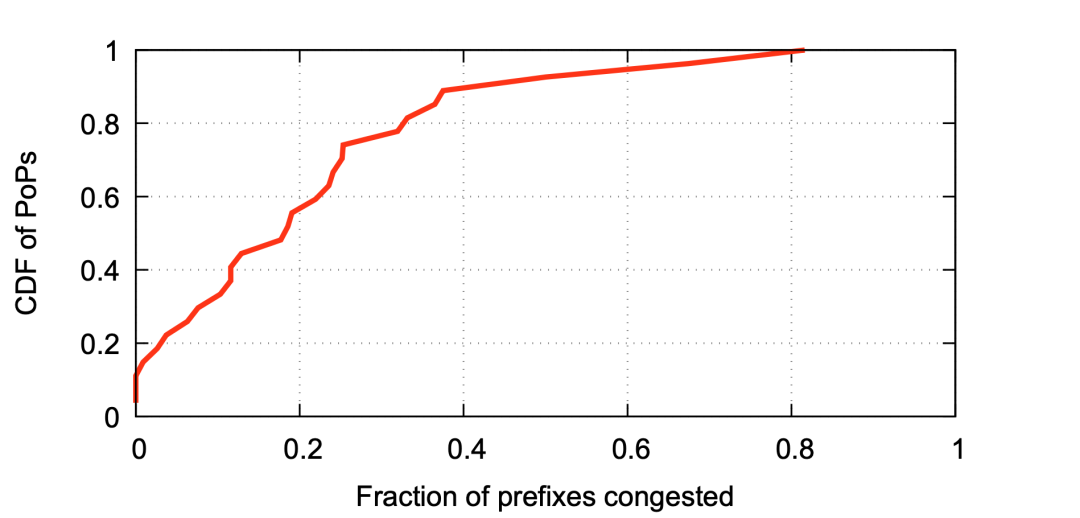
圖5:PoP節(jié)點中擁塞的路由的百分比 ? 圖6展示了沒有使用Edge Fabric的情況,分配到出口上的流量和實際端口帶寬的倍數(shù)關系。有10%的端口會因為BGP策略的問題導致分配到的流量是實際端口容量的2倍(靠上部的藍圈),在中線50%的端口會經(jīng)歷分配大約1.19倍的端口帶寬的流量(超量19%,中部的藍圈)。就是在類似的這些情況下,F(xiàn)acebook發(fā)現(xiàn)自己無法獲得足夠的出口容量,這促使Facebook設計了Edge Fabric,以克服BGP無法獨自處理的這種情況。 ?
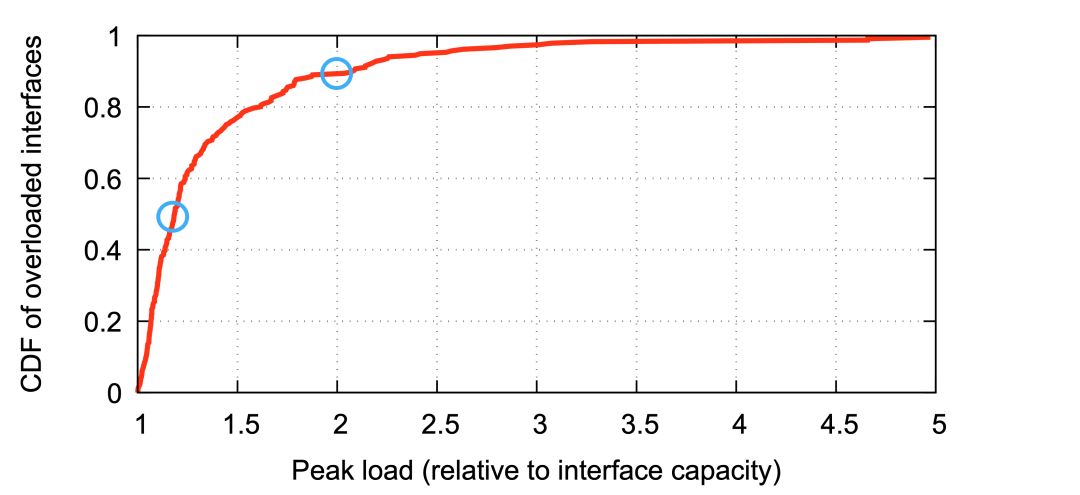
圖6:端口分配的流量對比實際帶寬 ? BGP的選路可能會損害性能 ? Facebook的BGP路由策略傾向于選擇那些有可能優(yōu)化流量性能的路徑。該路由策略在有對等互聯(lián)出口路由的情況下避免中轉路由,BGP選路會優(yōu)選更短的AS路徑(通常延遲更低),同時會優(yōu)先使用具有私有對等互聯(lián)的出口,而不是可能遭遇擁塞的公共對等互聯(lián)出口。然而,BGP本身并不能感知性能,因此這個策略依賴于一些屬性:比如AS-Path的長度,這些屬性的為后期設計的實現(xiàn)了拋磚引玉的效果。 ?
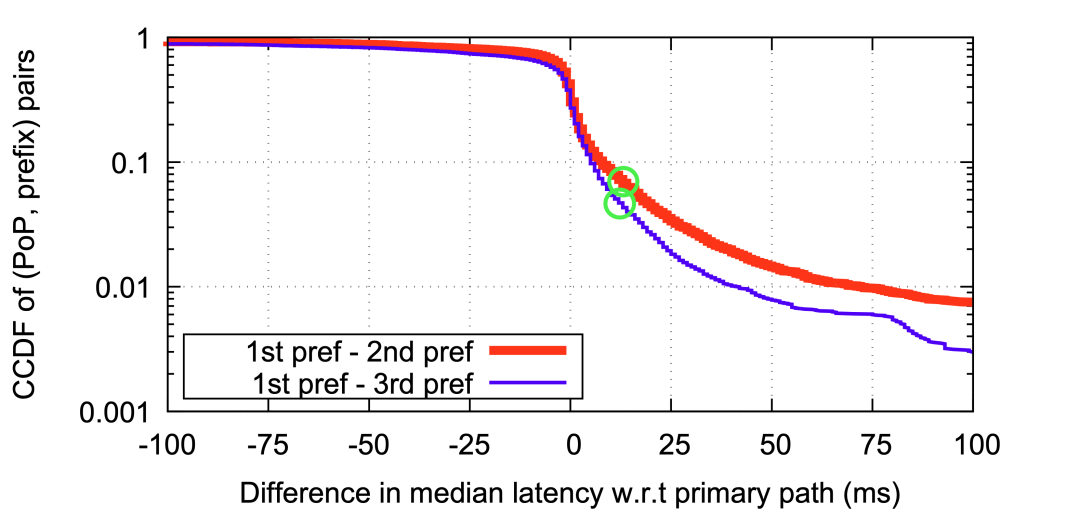
圖7:BGP最優(yōu)路徑和次優(yōu)、第三路徑的時延對比 ? 為了理解這個問題的嚴重性,我們比較了四個不同PoP節(jié)點的不同路徑的性能,一個在北美(PoP-19),一個是歐洲(PoP-11),兩個在亞太(PoP-2和PoP-16)。測試中將所有IP地址網(wǎng)段中的一小部分實際用戶流量遷移到BGP的次優(yōu)和第三優(yōu)選路徑上。在后面是章節(jié)會詳細的描述如何進行這些測量。圖7描述了BGP的首選路徑和非首選路徑之間的流量往返的總體延遲的差異。從圖中可以看出,如果將對從BGP的首選路徑切換到第二首選路徑, 5%的
設計目標和設計決策
互聯(lián)出口帶寬是有限的,但BGP無法感知容量 ? 出口流量調(diào)度的整體設計目標是為了克服BGP的限制以及使得Facebook能夠使用域間互聯(lián)來優(yōu)化性能:
·?對于給定的有限容量的出口和受擁塞影響的性能,路由決策系統(tǒng)必須能感知容量、鏈路利用率和流量需求及其變化; ·?路由決策系統(tǒng)需要能考量性能信息及其變化,同時利用BGP的路由策略;
為了完成這個目標,F(xiàn)acebook從2013年起開始開發(fā)Edge Fabric系統(tǒng),這是一個能控制PoP節(jié)點出口流量的流量工程系統(tǒng)。下一章將描述Edge Fabric如何動態(tài)的遷移流量避免擁塞。再后面將會描述隨著時間的推移,由于不斷變化的需求和運營經(jīng)驗,如何提高了Edge Fabric的穩(wěn)定性和對抗擁塞的能力。此外,F(xiàn)acebook還研究了如何使用測量技術來提高出口路由性能,如何開始將其度量納入路由的決策中去。
對于Edge Fabric的整體設計,關于面臨的一些選擇上面進行了以下的決策:
基于單個PoP節(jié)點調(diào)度流量 ? 全局負載均衡系統(tǒng)將用戶請求映射到某個特定PoP節(jié)點,而Edge Fabric將對于用戶請求的出流量分配到出口路徑上,流量從進入的同一個PoP節(jié)點流出,進出流量是對稱的。因此,Edge Fabric只需要在每個PoP節(jié)點的顆粒度上做操作,它不用協(xié)調(diào)全球出口流量。這種設計允許在PoP節(jié)點的組件設計中,減少了對遠端相應系統(tǒng)的依賴,降低了決策過程的控制范圍和實現(xiàn)復雜性。然后,可以在一個PoP節(jié)點上單獨重啟或重新配置Edge Fabric,而不會影響其他PoP節(jié)點。 ? 通過SDN來實現(xiàn)集中控制 ? 設計的最終選擇是一種基于SDN的實現(xiàn),PoP節(jié)點的集中控制器接收PoP節(jié)點網(wǎng)絡內(nèi)的相關狀態(tài),然后再確定形成網(wǎng)絡路由的決策。這種實現(xiàn)方法具備了SDN的優(yōu)點:與分布式方法相比,它更容易開發(fā)、測試和迭代。因為Facebook是通過BGP連接到各種對等互聯(lián)出口,所以PoP節(jié)點接收到的這些BGP路由也成為了網(wǎng)絡狀態(tài)中的一部分,這些信息會源源不斷的傳入SDN控制器,形成最終的路由決策。 ? 將實時流量的性能指標納入決策 ? 控制器每分鐘會接收多次容量和需求測量值數(shù)據(jù),使得Edge Fabric在出口不超載的情況下最大化的利用優(yōu)選路徑。Facebook在服務器端監(jiān)控了客戶流量的性能數(shù)據(jù)。通過在PR路由器上使用備選路徑的路由表(獨立與主路由表之外的),將隨機選擇的部分生產(chǎn)流量遷移到備選路徑上,從而增加了并行測量多條不同路徑的能力。這種方法保證了測量方式可以捕獲真實反映用戶感知的性能指標。Edge Fabric可以讓BGP選擇非BGP缺省的最佳路由,這奠定了基于性能感知路由決策系統(tǒng)的基石。 ? 使用BGP同時進行路由和控制 ? 盡管有集中控制器,但缺省情況下每個PR路由器在本地自行進行BGP路由決策和交換路由,只有當控制器想要改變某些地址前綴的BGP缺省選路時,才會進行干預。為了更改一個BGP選路決策,Edge Fabric將備選路由設置更高的Local_Preference,并通過BGP進程宣告給PR路由器,PR基于Local_Preference來選擇更改的優(yōu)選路由。在已經(jīng)建立的BGP路由架構之上來構建Edge Fabric可以簡化系統(tǒng)的整體部署,即使整個系統(tǒng)失效也可以讓網(wǎng)絡回到BGP自行的缺省路由策略,同時可以利用現(xiàn)有的運營團隊以及他們在BGP領域的專業(yè)能力和網(wǎng)絡監(jiān)控基礎設施。 ? 有效利用現(xiàn)有商用的軟硬件技術 ? 通過使用經(jīng)歷實戰(zhàn)考驗的商用設備和行業(yè)標準,避免了硬件的定制化和軟件的全新設計。Edge Fabric使用了BGP、IPFIX、sFlow、ISIS-SR、eBPF和BMP來實現(xiàn)整體功能。
總體而言,Edge Fabric的設計重視簡單性和與Facebook現(xiàn)有基礎設施、系統(tǒng)和實踐的兼容性。它滿足主要目標 — 避免出口過載擁塞?— 不需要對服務器或客戶端應用程序進行任何更改,只在路由器和控制器之間增加BGP進程。第二目標:性能感知路由系統(tǒng)的實現(xiàn)需要依賴于服務器上簡單的監(jiān)控軟件改造和在路由器上添加備選路徑路由表,這都是現(xiàn)有設備具備的基礎功能。 ?
避免邊緣擁塞
Edge Fabric由松耦合的微服務組成。參見圖8。缺省情況下,Allocator(路由分配器)每30秒從其他服務組件接收網(wǎng)絡當前的路由(BMP Collector)和流量狀態(tài)(Traffic Collector),預測計算出口的利用率,并生成一組更改的路由前綴來進行出口流量的路徑遷移,對于每個地址前綴,通過遷移到次優(yōu)或者第三路徑上去來避免BGP缺省優(yōu)選路徑的擁塞。另一個服務進程(BGP Injector)通過BGP向路由器注入定制的BGP路由來實現(xiàn)對BGP缺省路由的更改。30秒的時間間隔可以使得更容易地分析控制器的行為,但如果需要的話,可以降低30秒這個間隔,比如:流量的變化周期更短。
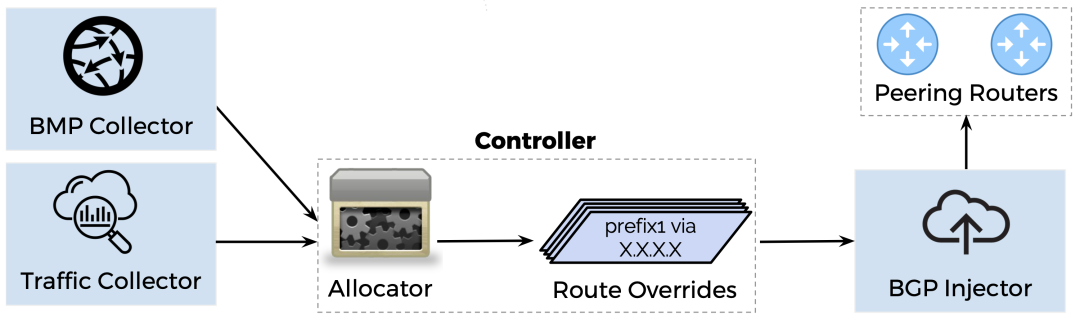
圖8:Edge Fabric整體架構 ?
獲取網(wǎng)絡狀態(tài)(輸入)
Edge Fabric需要知道從該PoP節(jié)點到目的地的所有可用的BGP路由,以及其缺省的優(yōu)選路徑。此外,還需要知道PoP節(jié)點中去往每個目的地的流量大小和PoP節(jié)點出口端口的帶寬容量。 ? BGP路由信息 ? 1)每個地址前綴的所有可用路由 ? BGP監(jiān)控協(xié)議BMP(BGP Monitoring Protocol)允許路由器共享其從其他BGP鄰居接收到的所有BGP路由的信息快照(在RIB中的所有BGP路由),并將后續(xù)更新也發(fā)送給訂閱方。BMP Collector(BMP采集器)維護所有BGP路由器的BMP訂閱,為Edge Fabric提供每個PR路由器的實時RIB視圖。相比之下的另一個方案:讓Edge Fabric與每臺BGP路由器保持BGP會話,但這種方式只能看到每臺路由器BGP的最佳路徑,其他非優(yōu)選的BGP路由就無法看到了。所在最終選擇了BMP方式。 ? 2)地址前綴的優(yōu)選路由 ? BMP Collector只是搜集路由,并不知道BGP如何選路,即使路由器使用ECMP在多條等價路徑上分割流量,BGP路由器也只共享一條路徑出來。控制器還需要知道在沒有Edge Fabric改動的情況下,BGP優(yōu)選的是哪條路徑。因此,控制器需要自己實現(xiàn)BGP選路的模擬算法,用來為每個目的地模擬BGP最佳路徑的選擇計算(利用BMP收到的多條BGP路徑信息,忽略Edge Fabric的路由改動)。(當然,F(xiàn)acebook在自研FBOSS上的積累可以復用在這里了。) ? 流量信息 ? 1)每個地址前綴當前的流量 ? Traffic Collector(流量采集器)通過對PoP節(jié)點內(nèi)所有設備進行流量(IPFIX或sFlow,取決于路由器的支持程度)采樣,并根據(jù)BGP的路由網(wǎng)段進行的最長匹配來做聚合,最終計算出來每條BGP路由前綴在兩分鐘內(nèi)的平均流量速率。所有的流量都是實時采集的數(shù)據(jù)而不是讀取歷史記錄,因為如果不能做到分鐘級別的實時性,有可能全球負載均衡系統(tǒng)已經(jīng)將流量從一個PoP節(jié)點切換到另一個去了,那么PoP節(jié)點內(nèi)的流量工程已經(jīng)就沒有意義了,甚至會出現(xiàn)錯誤的預測計算。
當某個目的地網(wǎng)段前綴的匯聚速率超過了配置的閾值(例如:250Mbps)時,Edge Fabric系統(tǒng)將該地址網(wǎng)段前綴進行細分拆解(例如:將一個/20的網(wǎng)段拆分為兩個/21的網(wǎng)段,這個過程不會有流量丟失),直到所有目的地網(wǎng)段的匯聚速率低于配置的那個閾值。對于大網(wǎng)段前綴的拆分可以讓Allocator做出更細顆粒度的決策,并將由于出口過載而必須進行繞道的流量降低到最少。 ? 2)出口端口信息 ? Allocator從集中的網(wǎng)絡管控平臺(Robotron)中獲得每個PR路由器上的BGP出口端口列表,并每6秒通過SNMP查詢PR路由器相應接口的容量,使Allocator能夠快速響應由于故障或配置導致的出口容量變化。 ? 3)預測的端口利用率 ? Allocator利用前面采集到的路由信息、流量信息來進行預測計算:按照不進行任何路徑改動的情況下:BGP路由按照各自的缺省最優(yōu)路徑,目的地前綴的流量疊加在路徑和出口上(對于出現(xiàn)ECMP的情況,按照理論上的流量平均分配來計算),最終計算出每個BGP出口上的利用率。
Edge Fabric使用的是預測計算的結果而非實際采集的利用率來做決策,這么做的最重要的原因是:保證整個過程是無狀態(tài)的,不需要依賴Edge Fabric的歷史數(shù)據(jù)和狀態(tài)。無狀態(tài)的實現(xiàn)帶來最大的好處是極大的簡化了整體設計:Allocator在一個計算周期內(nèi)就能實現(xiàn)其最優(yōu)決策,完全不用依賴之前的狀態(tài),這對于整體系統(tǒng)的冗余、切換等等都帶來了極大的便捷。在后面的章節(jié)會更細致的描述為什么選用了無狀態(tài)設計。
根據(jù)預測計算的出口利用率,如果不進行操控改變BGP缺省選路的情況下,Allocator能確定出哪些出口將出現(xiàn)過載。如果端口利用率接近95%,F(xiàn)acebook會認為開始過載了,95%的利用率是在處理端口效率和留出的緩沖空間之間做出的平衡。 ?
產(chǎn)生更改(決策)
Allocator根據(jù)會出現(xiàn)的出口過載來進行流量的遷移。對于每個過載的出口,Allocator能識別需要流出到該接口的所有目的地前綴網(wǎng)段、及其相應的流量需求、以及每個前綴可用的其他BGP路徑。然后,Allocator通過 <前綴,備選路由> 列表,按照下面的處理過程來將其從該出口遷移到其他出口上去:
1. 相對IPv6,優(yōu)先選擇IPv4。
2. 優(yōu)選一個對等互聯(lián)出口,其本身也優(yōu)選Facebook作為它的優(yōu)選備用路徑的。這是通過和對端BGP傳遞的路由中攜帶的Community屬性來識別的,這些屬性值含有Facebook預定的路徑優(yōu)選信息。
3. 對于給定目的地前綴的備選路徑可能有多條,在這些備選路徑的BGP路由中,優(yōu)選具有最長網(wǎng)段匹配的路由(例如:/22網(wǎng)段優(yōu)先于/21網(wǎng)段)。
4. 優(yōu)選本身就是BGP的最優(yōu)路徑的。參見前面描述的對等互聯(lián)出口會比穿透連接出口更優(yōu)選的整體策略,如果Allocator決定將一個目的地前綴從現(xiàn)在的公共互聯(lián)出口(IXP)遷移到穿透連接出口上,面臨多個穿透出口的選擇,如果在某個穿透連接上的路由本身就是最優(yōu)路徑,那么就優(yōu)選這個出口。
5. 剩下的選路原則沿用BGP標準的策略,如果存在多條備選路徑,那么Allocator會使用前后一致的方式進行排序,這樣會增加流量的均衡性。 ? 當一對 <前綴,備選路由> 被選中以后,Allocator會記錄這個決定然后更新整個流量預測:將這個地址段的流量從之前的路徑、出口遷移到新的路徑、出口上。當然,前面提及的超過設置的流量(例如:250Mbps)值會將地址網(wǎng)段進行拆分。
Allocator會繼續(xù)選擇地址前綴網(wǎng)段來進行以上操作,直到出口不會再有過載的情況,或者是所有前綴網(wǎng)段的BGP路由都沒有可用的次優(yōu)路由存在。
因為整個處理過程是無狀態(tài)的,不需要參考之前的狀態(tài),系統(tǒng)每30秒將接收到的信息(路由和流量)進行一次計算,做出新的流量切換決策。為了減少對流量的攪動,F(xiàn)acebook設計了一套優(yōu)選機制,使用一致的考量順序來綜合端口、地址前綴、繞道的路徑等因素,這種一致的考量使得Allocator在前后的計算中會盡量得出相同的計算結果。其他的流量操控行為常常是因為流量速率和可用路由的變化而導致的。
對于某些持續(xù)增長的流量,出口剩余的可用帶寬(大約5%)空間可以留作Allocator在兩次計算間隔內(nèi)的緩沖,用以預防Allocator還沒來的急操作出口就開始擁塞了的情況。如果流量切換到次優(yōu)路徑,但其BGP路由被撤銷了,那么控制器也會撤銷、停用這條次優(yōu)路由,避免流量黑洞。 ?
使用Allocator控制(輸出)
在每一輪計算操控中,Allocator生成一組新的BGP路由更新來覆蓋原有的BGP缺省選路,實現(xiàn)的方式是給每個BGP更新的路由分配一個足夠高的Local_Preference。Allocator將BGP更新的路由信息傳遞給BGP Injector服務,該注入服務與PoP節(jié)點中的每一臺PR路由器建立了BGP連接,并通過向目標PR路由器宣告BGP更新路由來實現(xiàn)對原有BGP缺省選路決策的更改。由于注入的BGP更新路由具有更高的Local_Preference(在標準的BGP選路判斷中,對可用路由來說這是最高優(yōu)先級)值,并且通過iBGP在PR和AWS之間傳播,所以PoP節(jié)點網(wǎng)絡內(nèi)的所有路由器會優(yōu)選這個注入的BGP路由。BGP Injector會同時撤銷當前失效的更改路由(上一輪的注入路由,本輪計算后失效了)。
從全局角度來看,雖然Edge Fabric和全局負載均衡系統(tǒng)有各自的獨立決策流程,但兩者的處理結果需要協(xié)調(diào)一致、而不能相互沖突。首先,我們需要防止Edge Fabric決策和全局負載均衡系統(tǒng)的決策以會導致振蕩的方式相互影響。在選擇用哪一個PoP節(jié)點來響應用戶的請求時,全球負載均衡系統(tǒng)會根據(jù)PoP節(jié)點的性能、Facebook的整體BGP策略,通過可配的設置,在這個時候的決策不會參考Edge Fabric更改以后的BGP路由。考量另一個可能性,如果全球負載均衡系統(tǒng)也同時參考BGP Injector產(chǎn)生的更改以后的路由,那么在全局的第一級導流決策中,這個最終用戶的流量會被分配到其他PoP節(jié)點去,那么之前那個PoP節(jié)點的預測計算就會發(fā)生錯誤,流量已經(jīng)不存在了,那么預測的出口擁塞也不準確了,這更容易讓Edge Fabric和全局負載均衡系統(tǒng)之間發(fā)生振蕩。其次,全局負載均衡系統(tǒng)從全網(wǎng)的角度來監(jiān)控用戶網(wǎng)段流量和出口端口的利用率,這方便在全局PoP節(jié)點之間來流量調(diào)度。所以Edge Fabric就能夠?qū)W⒂赑oP節(jié)點內(nèi)的所有出口過載情況,再進行流量操控避免擁塞。 ?
部署、測試、監(jiān)控
Edge Fabric軟件的迭代、部署通常每周都會進行,在這個過程中使用多級發(fā)布流程來降低整體風險。首先,因為整個設計是模塊化和無狀態(tài)的,所以在測試方面,可以為Edge Fabric和其依賴的每個獨立組件進行全面和完整的自動化測試。其次,由于控制器是無狀態(tài)的,同時使用的是預測計算而非實際利用率,這樣被測試的“影子”控制器可以運行在沙箱里,通過測試環(huán)境獲取的網(wǎng)絡狀態(tài)信息和生產(chǎn)網(wǎng)絡里面控制器獲取的信息是一樣的,按照這種方式來進行測試,不需要去獲取生產(chǎn)網(wǎng)絡在線控制器的狀態(tài),也不需要獲得之前控制器的決策狀態(tài),使得測試更加易于實現(xiàn)。不斷的從版本庫中創(chuàng)建最新版本的影子控制器實例,在測試環(huán)境中運行、預測判斷,再與生產(chǎn)網(wǎng)絡中運行的控制器的決策結果去做對比,在這個過程中不斷的優(yōu)化、解決問題。在部署新版本之前,需要仔細評估對比這些測試結果。第三,由于Facebook是按照PoP節(jié)點為單位來部署Edge Fabric和其依賴組件,對于新版本的部署可以實現(xiàn)逐個PoP節(jié)點部署的灰度上線方式,當然灰度部署也是基于自動化實現(xiàn)的。當Edge Fabric控制器更新版本后,BGP Injector繼續(xù)執(zhí)行上一輪的命令(發(fā)送BGP更新路由),直到收到新的控制器產(chǎn)生的指令(通常在5分鐘以內(nèi))。如果需要更新BGP Injector服務,PR路由器會保持現(xiàn)有注入的路由直到新的BGP Injtector服務重啟完成(這是得益于BGP GR,Graceful Restart)。
雖然無狀態(tài)控制器易于進行自動化測試,但它也特別容易受到BGP路由或流量速率數(shù)據(jù)錯誤的影響,這些數(shù)據(jù)是控制器進行預測計算的基礎,其準確度會直接導致預測的出口利用率不正確。為了追蹤這種錯誤的預測,F(xiàn)acebook使用監(jiān)控系統(tǒng)來對比預測計算的結果和出口實際的利用率,在配置的時間間隔內(nèi)出現(xiàn)超過5%的偏差會觸發(fā)告警。通過這個流程,可以捕捉、識別、糾正可能存在的路由策略中的Bug以及PR路由器通過IPFIX和sFlow導出采集流量中的問題。控制器的預測計算是將流量均分到所有的ECMP路徑上。同樣,監(jiān)控系統(tǒng)可以監(jiān)控到由于ECMP實現(xiàn)不完美導致的流量不均衡的情況,這個時候可以通過Edge Fabric注入路由使用單個PR出口路由器來避免ECMP多路徑不均衡的情況。
整個Edge Fabric是建立在分布式BGP路由決策系統(tǒng)之上的,也就是說,每個路由器還是獨立進行選路判斷,這有利于復用現(xiàn)有的整體網(wǎng)絡架構,但BGP本身的復雜性也可能造成運維中的故障。例如在某個場景中,由于配置錯誤導致Edge Fabric注入的路由沒有被PoP節(jié)點內(nèi)所有的路由器收到,這造成了導致之前出口過載的流量被遷移到另一個并非預期的出口上,結果導致那個出口出現(xiàn)了擁塞。為了檢測這種錯誤配置,F(xiàn)acebook構建了一個審計系統(tǒng),定期比較Edge Fabric的輸出結果與當前的網(wǎng)絡狀態(tài)和流量模式。 ?
BGP邁向性能感知
Edge Fabric能夠避免由于網(wǎng)絡邊緣的鏈路擁塞而導致的性能問題。然而,由于BGP本身選路機制的限制,F(xiàn)acebook最終用戶的性能任然可能不是處于最優(yōu)的狀態(tài)。想讓BGP選路一直走在最優(yōu)的性能路徑上是頗為困難的事情:缺省的選路未必是最優(yōu)性能的路徑,選擇的次優(yōu)路徑也不一定是,即使在所有情況下都是最優(yōu)的,但遷移路徑的時候還是可能出現(xiàn)性能降低甚至比不上之前的缺省選擇。
此外,雖然Facebook直接連接到了許多邊緣網(wǎng)絡(類似其他大型內(nèi)容服務商一樣,前面描述的互聯(lián)網(wǎng)“扁平化”),但其他邊緣網(wǎng)絡(Facebook通過IXP或穿透連接)的性能可能會受到其下游網(wǎng)絡擁塞的影響,這是Edge Fabric無法進行優(yōu)化處理的。即使Facebook直連邊緣網(wǎng)絡的情況下,其下游網(wǎng)絡的擁塞仍然會導致端到端的性能降低。由于瞬態(tài)故障和流量波動,每條路徑的最優(yōu)性能可能會隨著時間的變化而變化,因此基于性能的決策需要對變化做出及時的響應。但BGP既不能提供性能的可見性,也不能提供基于性能的顯式?jīng)Q策能力。
為了使路由決策能夠結合性能指標,需要并行地、連續(xù)地測量到達目的地的多條可用路徑。此外,為了使Edge Fabric能夠最好地利用可用出口帶寬,需要能夠?qū)μ囟愋偷牧髁窟M行優(yōu)先級排序(例如:預測出口會出現(xiàn)過載時,對實時視頻流優(yōu)先級排序),但由于BGP只支持基于目的地的路由,僅靠BGP無法實現(xiàn)上述目標。
下面的小節(jié)描述了如何將特定的流量導向特定的路徑,然后在下一個小節(jié)描述了如何能監(jiān)測到同一個目的地前綴的多個可用BGP路徑的各自的性能。這兩種機制已經(jīng)應用到Edge Fabric的生產(chǎn)網(wǎng)絡中。本章的最后一小節(jié)討論未來的用例,這些用例將測量特定引導的流量,以來啟用能感知性能的路由系統(tǒng)。 ?
將流量遷移到備選路徑
為了克服BGP只能支持基于目的地的路由的限制,通過建立一種機制來優(yōu)化:允許為特定的流量選擇其流經(jīng)的路徑。該機制只需要在:1)服務器上做軟件上的小改動;2)PR路由器上進行小量的配置修改即可;并且不需要服務器和其他網(wǎng)絡設備互動(包括PR):服務器可以在不知道PR路由器的網(wǎng)絡狀態(tài)的情況下,為每個流量做出其決策。
·?服務器選擇并標記需要特殊處理的流量。具體來說,服務器將所選流量的IP報文中的DSCP字段設置為一個預定義的值。不同的DSCP值代表最終會選擇不同的出口、路徑,例如:缺省BGP優(yōu)選、次優(yōu)路徑、第三選擇路徑等。在實際應用中,服務器可以將一個數(shù)據(jù)流基于其最終目的標記為不同的DSCP值,比如:用于測量備選路徑的性能;或者將該流量引導到需要實時、性能敏感的路徑上去。
· PR路由器上的路由策略。PR路由器按照預先設定好的DSCP值,將不同的DSCP值的流量導入不同的路由表進行轉發(fā)(路由器上有主路由表,同時PR上面創(chuàng)建了很多不同的路由表,里面搭配不同的BGP路徑,用此來實現(xiàn)不同的路徑優(yōu)選)。為每個DSCP值的流量配備一個單獨的路由表(每個路由表中同一目的地的BGP優(yōu)選路由會不一樣,從而實現(xiàn)選擇不同的出口)。
·?控制器注入路由。控制器將路由注入到PR路由器的備選路徑路由表中,用以控制流量的出口選擇。如果控制器沒有為特定的目的地注入路由,則該流量將根據(jù)PR的主路由表進行路由,就是BGP的缺省優(yōu)選路徑。 ? 這種實現(xiàn)方法不需要在服務器、路由器和控制器之間持續(xù)同步狀態(tài)。服務器在為其流量設置DSCP標記值的時候可以完全不知道網(wǎng)絡設備的狀態(tài),控制器也可以根據(jù)需要將路由注入到備選路由表中來控制相應DSCP標記報文的路徑。
此外,PoP節(jié)點內(nèi)ASW層不需要知道分配給流量的DSCP值的含義,它只是根據(jù)BGP的缺省優(yōu)選路徑轉發(fā)IP流量。在這種情況下,流量不一定會發(fā)送到正確的PR上去,因為控制器計算出來的出口可能位于某個PR,但ASW卻基于缺省最優(yōu)路徑將流量發(fā)送給了另一個PR。對于這種情況,控制器會在缺少對應出口的PR路由器上注入BGP備選路由,并將該路由的下一跳設置為正確的PR路由器。這個時候,流量將從一個PR路由器轉發(fā)到另一個PR路由器,這通常會引起路由環(huán),因為ASW只是根據(jù)BGP的最優(yōu)目的地路由來轉發(fā)流量。為了避免這種情況,將PR之間使用IS-IS SR來實現(xiàn)流量的遷移,而遷移路徑中間的ASW是基于SR的MPLS標簽進行轉發(fā)的,IP信息對它不可見,所以可以避免路由環(huán)。 ?
監(jiān)測備選路徑的性能
最終用戶的TCP連接終結在PoP節(jié)點內(nèi)的前端服務器上,前端服務器將HTTP請求代理到后端服務器。通過上面描述的機制來隨機的選擇一些流量,并通過次優(yōu)路徑來轉發(fā)。這使得Facebook可以通過現(xiàn)有的基礎設施收集測量實際流量的數(shù)據(jù)指標,記錄前端服務器觀察到的客戶端連接的性能。 ?
隨機選擇的用戶流量
? 通過一個部署在前端服務器上運行的程序,可以隨機選擇數(shù)據(jù)流,并標記讓其沿著次優(yōu)路徑轉發(fā),這個程序的核心組件是使用eBPF(Extended Berkeley Packet Filter)。eBPF允許將其加載到內(nèi)核中,以便有效地處理、記錄從服務器發(fā)出的所有數(shù)據(jù)包。使用這種方式,不需要對現(xiàn)有的客戶端或服務器端的應用程序進行任何更改。 ? 通過設置預定義的DSCP值,eBPF程序隨機選擇部分數(shù)據(jù)流(比例可配置)引導到次優(yōu)路徑上進行路徑性能監(jiān)測。這個eBPF程序的配置可以動態(tài)更改,包含最重要的參數(shù)是:多少百分比的流量需要標記成哪個DSCP值。例如,要測量每個地址前綴的兩條備選路徑,配置可以將數(shù)據(jù)流的0.75%分配為DSCP值12,將數(shù)據(jù)流的0.25%分配為DSCP值24,流量到達PR路由器,會因為DSCP的12、24而分配不同的出口。考慮到Facebook的體量,這一小部分比例的仍然會產(chǎn)生大量的測量結果。
這是方式稱作被動監(jiān)測。設計之初在主動監(jiān)測(主動Ping或者各種TCP進程的模擬)和被動監(jiān)測之間的選擇上,F(xiàn)acebook選擇了被動監(jiān)測,因為主動測量不能代表真實用戶感知到的性能,這當中會有很大的偏差,而Facebook的eBPF的實現(xiàn)方式完全獲得了最終用戶最準確的各種性能數(shù)據(jù)。 ? 注入路由 ? Edge Fabric使用了AltPath Controller(備選路徑控制器)來將路由注入到專門的備選路由表。控制器生成備選路徑的時候只是考量過去10分鐘內(nèi)流量信息,這種實現(xiàn)大大減少了備選路由表的大小。
每隔30秒,AltPath Controller使用從BMP Collector服務進程獲取的BGP路由信息來決定為每個目的地前綴選擇的備選路徑,然后服務器為相應的流量標記相應的DSCP值。然后控制器使用BGP Injector將每個DSCP值對于的BGP備選路由注入到相應的PR路由器的備選路由表中。
AltPath Controller還可以對一些目的地AS號進行屏蔽備選路徑測量的功能,簡單輸入一組目標AS號即可。流量工程團隊根據(jù)之前的實操經(jīng)驗將一些可能會引起極差用戶體驗的備選路徑的AS號添加進去,避免選中了這些備選路徑降低了最終用戶的性能。 ?
監(jiān)測性能
當客戶端TCP連接終結時,前端服務器會將該路徑的性能評測指標記錄下來。這些服務器使用一個單獨的eBPF來捕捉需要采用的TCP連接,通常典型的采樣比為1:1000。采集的性能數(shù)據(jù)包括:重傳速率、RTO(Retransmission Timeout重傳超時時間)、SRTT(Smoothed Round-Trip Times平滑往返時間)和發(fā)送/接收的數(shù)據(jù)包分段數(shù)量。此外,服務器還對HTTP事務進程進行采樣,并對每個響應的客戶請求的下載吞吐量也進行測量。服務器也會記錄eBPF程序分配給相應數(shù)據(jù)流的DSCP值。采集器將樣本與出口路由信息關聯(lián)起來,這樣分散的采樣樣本可以按照出口路由網(wǎng)段來匯聚,最后疊加計算出按照每條路由這個顆粒度的匯聚流量信息。 ?
性能感知路由的未來用例
前面兩個小節(jié)描述的機制使得可以將流量遷移到備選路徑上去,同時也能測量備選路徑的性能。 ?
使用BGP來更改路徑
如今,Edge Fabric改變了BGP的缺省選路過程,以緩解Facebook網(wǎng)絡邊緣的擁塞。展望未來,可以通過合并AltPath的測量來優(yōu)化Edge Fabric。首先,Edge Fabric可以使用這些測量數(shù)據(jù)來確定在哪些情況下,即使出口沒有擁塞,也可以通過改寫B(tài)GP的缺省選路來提高性能。在當前路徑的性能下降時,AltPath測量可以確定是否可以通過更改路徑來規(guī)避這種問題,或者性能問題存在于所有可選路徑上(前面提及的用戶側網(wǎng)絡/下游網(wǎng)絡的擁塞導致問題不可避免)。其次,Edge Fabric可以測量備選路徑,以確保在出現(xiàn)擁塞時,將流量切換到性能最佳的備選路徑上。最后,備選路徑測量可以幫助運維團隊識別繞道流量的性能影響,這可以為網(wǎng)絡規(guī)劃團隊做決策時提供數(shù)據(jù)。 ?
優(yōu)化有限的出口容量
當出口帶寬容量有限時,Edge Fabric可能被迫將流量切換到性能相對較差一些的路徑上。Edge Fabric可以通過將一些不太可能受到影響的流量切換到其他備選路徑上,以便更好地利用主路徑上的有限容量。首先,Edge Fabric可以修改其選路決策標準,以更傾向于遷移在備選路徑上性能幾乎不會下降的地址前綴的流量。其次,更高優(yōu)先級的流量可以通過受約束的路徑路由來調(diào)整。前端服務器可以為優(yōu)先級較高的流量(比如實時視頻流)設置預定義的DSCP值。然后,當Edge Fabric通過注入路由將流量從過載的接口上遷移出去時,它同時將更改的路由注入到PR的備選路由表中,可以使DSCP優(yōu)先級高的流量在性能更好的路徑上傳送。Traffic Collector收集的IPFIX和sFlow采樣都包含有DSCP字段,因此Edge Fabric可以確定相應DSCP值的流量速率,并在每一輪的預測中對此進行計算。 ?
實際運行效果
部署狀態(tài)和評估數(shù)據(jù)集
Edge Fabric部署在全球的生產(chǎn)網(wǎng)絡中,在所有的PoP節(jié)點中通過備選路徑來避免出口擁塞。下一小節(jié)描述了對2017年1月的其中兩天的數(shù)據(jù)進行的研究,當時并沒有使用無狀態(tài)的控制器。這個研究使用了早期的有狀態(tài)的控制器,該控制器沒有使用自動分割大流量地址前綴的功能。雖然沒有進行正式的評估,但Facebook相信其無狀態(tài)控制器比有狀態(tài)控制器獲得了更好的出口利用率。
現(xiàn)在在PoP節(jié)點中部署了AltPath,在“性能感知評估”小節(jié)展示的效果是從2016年最先開始部署的4個PoP節(jié)點,在一定程度上選擇這4個PoP節(jié)點是因為它們有豐富的出口連接:一個在北美(PoP-19),一個在歐洲(PoP-11),和兩個在亞太地區(qū)(PoP-2和PoP-16)。這4個PoP節(jié)點加起來的流量約占20個PoP節(jié)點總量的18%。當前,沒有使用AltPath自動測量來通知生產(chǎn)網(wǎng)絡并形成路由決策,但是后面會介紹將其集成到路由決策中的影響和挑戰(zhàn)的試驗結果。
在每個路由器上創(chuàng)建了兩個備選路由表(缺省主路由表之外的),將所有路由前綴的BGP的次優(yōu)和BGP第三優(yōu)選路徑分別放置到兩個創(chuàng)建的路由表中。在2016年的測量實現(xiàn)中還沒有使用基于DSCP的方法,而是根據(jù)流量的目的端口將流量分配給對應的路由表。對于每個備選路由表,生成了一組獨有與之對應的端口,它們大約匹配總流量的0.5%,然后在PR上配置規(guī)則,將匹配這些端口的流量遷移到其中的一個路由表中,再做選路。為了增加備選路徑的測量次數(shù),當數(shù)據(jù)連接命中AltPath的端口集時就對現(xiàn)有的測量采樣比擴大100。通過這個方式,每個備選路徑接收到的0.5%的流量,會檢測其在主路徑的大約50%的流量。 ?
評估容量感知路由的效果
Edge Fabric是否實現(xiàn)了它的主要目標,即在實現(xiàn)提高出口利用率的同時避免出口擁塞?Edge Fabric通過使備選路徑來防止擁塞。在研究過程中,有空閑帶寬的備選路徑始終存在,這為Edge Fabric實現(xiàn)避免過載提供了可能性。尤其是,提供穿透連接的運營商可以將流量送到任何目的地,在研究期間,任何單個PoP節(jié)點(每分鐘采樣)觀察到的最大瞬時利用率是55%。Edge Fabric成功地防止了出口流量過載,當Edge Fabric選用優(yōu)選路徑時,出口上沒有丟包,且使用備選路徑的99.9%的時間內(nèi)也沒有丟包。
Edge Fabric遷移了多少流量到備選路徑上?圖9顯示了Edge Fabric從每個出口啟用遷移的時間分布。在評估期間,Edge Fabric至少在18%的端口上啟用過一次備選路徑流量切換,并且在一半的時間內(nèi),至少5%的出口進行過流量遷移(圖中藍色圓圈)。 ?
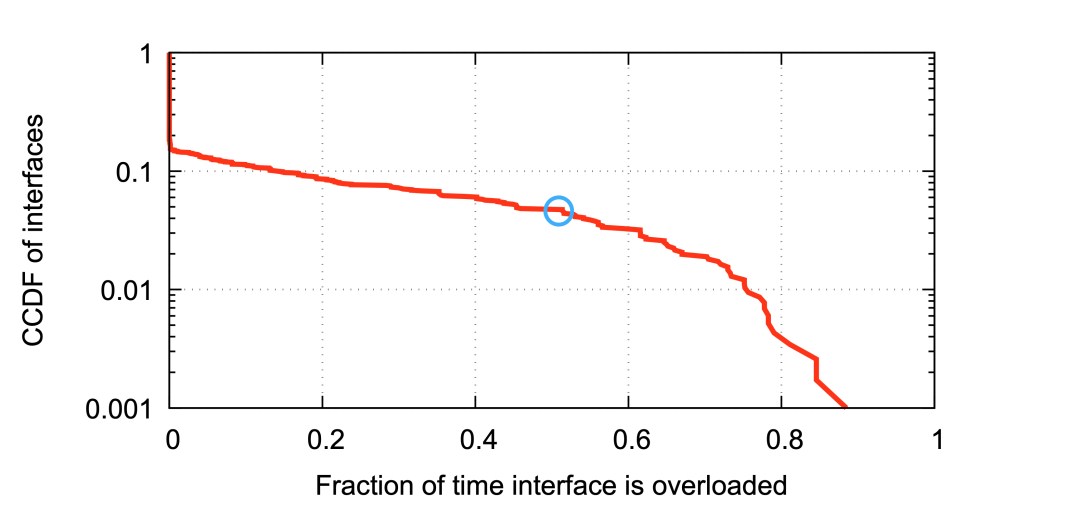
圖9:Edge Fabric切換流量的時長和間隔 ? 圖10顯示了每個流量遷移的持續(xù)的時間,以及給定(PoP,目的地前綴)的兩次遷移之間的間隔時間。平均流量遷移的時間為22分鐘,10%的遷移時間持續(xù)了超過6小時。有趣的是,流量遷移中位數(shù)的時間更短 — 只有14分鐘 — 但尾部更長,36%的流量遷移中有超過3小時的間隔,相當大一部分的間隔足夠長,這表明流量遷移發(fā)生在一個較短的每天的高峰期內(nèi)。 ?
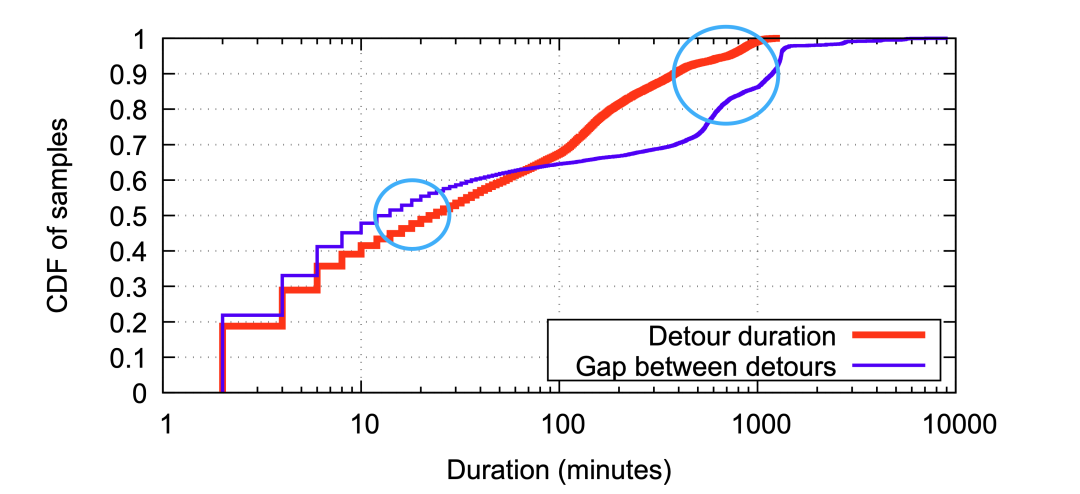
圖10:Edge Fabric遷移的流量占比 ? 圖11顯示了在一周的時間內(nèi),20個PoP節(jié)點進行遷移的流量所占的比例(紅色曲線),以及其中一個遷移流量占比最高的PoP節(jié)點(在這20個PoP中)的遷移流量所占的比例(藍色曲線)。全局和PoP節(jié)點流量遷移的模式顯示了每天流量變化的規(guī)律,遷移流量的占比只是總流量的一小部分,正如前面提及的PoP節(jié)點通常具備45%(瞬時最大55%的利用率)的富裕帶寬,這些閑置的容量足以吸收遷移的流量。Edge Fabric使得PoP節(jié)點能夠利用節(jié)點內(nèi)的其他可用出口的閑置的帶寬,動態(tài)地從過載端口遷移流量,否則那些端口會變得異常擁塞。 ?
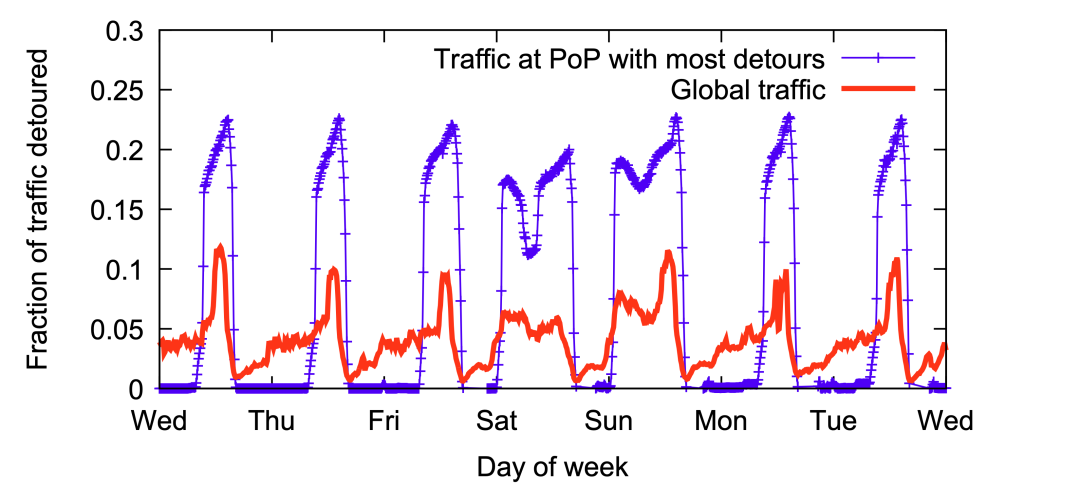
圖11:一周的每天進行流量遷移的比例 ?
評估性能感知的路由的效果
本節(jié)將研究相同目的地前綴的不同路徑之間的性能差異,以及系統(tǒng)是否可以使用這些信息來選擇優(yōu)于BGP缺省優(yōu)選路徑的其他備選路徑。通過在4個部署了備選路徑測量系統(tǒng)的PoP節(jié)點,監(jiān)測了7天的生產(chǎn)網(wǎng)絡流量,包括測量了:每個目的地前綴的備選路徑,一共有超過3.5億條備選路徑、終點到2萬個AS域,平均每個 <備用路徑,目的地前綴> 進行了8000次測量。
通過測量備選路徑做出更好的決策對性能有多大影響?使用這些測量的數(shù)據(jù)來改寫PoP-2節(jié)點上用戶實際生產(chǎn)流量的優(yōu)選路徑,AltPath識別出400個目的地前綴,并測量出這些目的地前綴的備選路徑的中位數(shù)時延至少比缺省情況要快20毫秒(丟包率沒有增加)。Edge Fabric獲得了這些信息,并在PoP節(jié)點上通過注入路由改變?nèi)笔〉膬?yōu)選路徑,將這些目的地前綴的生產(chǎn)流量遷移到備選路徑上。這些注入持續(xù)了24小時。 ?
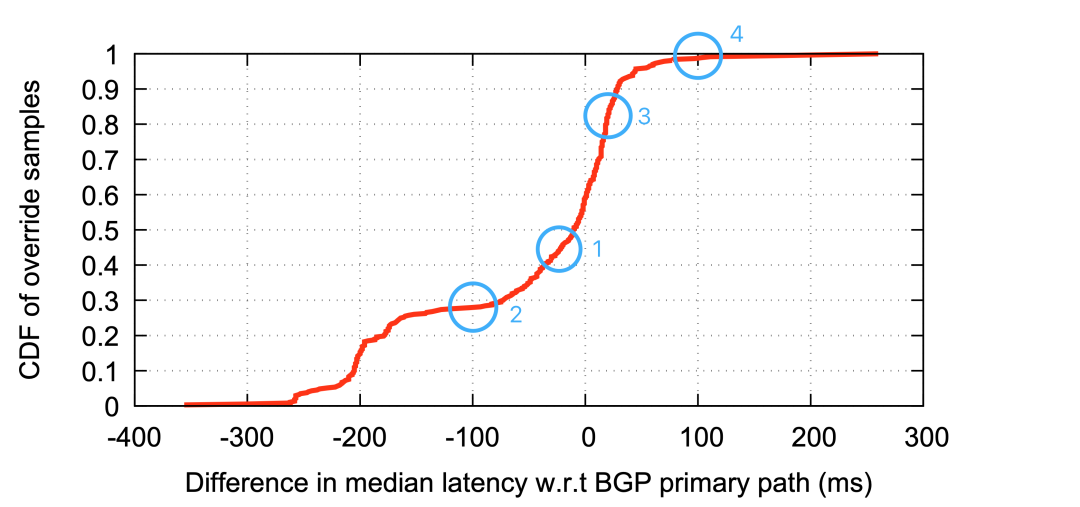
圖12:BGP備選路徑對比優(yōu)選路徑的性能變化(負數(shù)為優(yōu)化了) ? 圖12展示了備選路徑的性能和BGP缺省優(yōu)選路徑的對比,:AltPath指定的路徑(目前承載大部分流量)和BGP缺省的首選路徑的性能的對比。對于這些前綴,45%的前綴實現(xiàn)了至少20ms的中值延遲(藍圈1),28%的前綴至少提高了100ms(藍圈2)。在另一方面,有些備選路徑的改寫沒有獲得預期的效果:例如,有17%的前綴的延遲的中位值反而比缺省路徑多了20毫秒(藍圈3),還有1%的前綴的延遲至少比缺省路徑慢了100毫秒(藍圈4)。如果系統(tǒng)動態(tài)調(diào)整路由(而非這種一次性靜態(tài)改動),這些結果表明可能出現(xiàn)振蕩。這些情況中的絕大多數(shù)是因為目的地前綴從對等互聯(lián)出口遷移到了穿透連接出口上去了。
當更改路徑后導致結果出現(xiàn)更差的性能時,推測這種異常可能是來源于兩個因素的結合:1)路徑的性能和加載在上面的流量是某種函數(shù)關系;2)路徑的性能是隨著時間的推移而改變的。在未來的工作中,F(xiàn)acebook打算通過對流量進行更細粒度的遷移來研究這些問題,這樣就可以了解放置在特定路徑上的流量負載如何影響其性能。此外,這一挑戰(zhàn)還需要一個健壯和快速反應的控制系統(tǒng)來決定是否進行遷移,不僅基于單個前綴的測量,還取決于相同路徑上其他的流量是否被遷移進來或者遷移出去,同時還要考量歷史數(shù)據(jù)等其他的影響因素。要實現(xiàn)這個目標,需要進一步的提高AltPath的測量采樣率,這樣控制器就能夠有足夠的樣本來評估更短時間內(nèi)的性能。
AltPath還識別出有700個目的地前綴的BGP路由的第三優(yōu)選路徑要優(yōu)于其次優(yōu)路徑,因此將Edge Fabric配置為可以使用第三優(yōu)選路徑來做流量遷移的備選路徑。然而,在的實驗中,只有不到5%的這些前綴被Edge Fabric選中進行流量遷移。在這些遷移路徑中,通過比較選中的遷移路徑和BGP的次優(yōu)路徑兩者的AltPath測量性能,發(fā)現(xiàn)除了2個前綴外,所有遷移的流量都獲得了更好的性能。這一結果表明,AltPath能夠有效的幫助Edge Fabric使用遷移路徑來解決擁塞問題。
AltPath能準確地捕獲端到端性能嗎?利用BGP對等測試床進行了對照實驗。測試床直接在AMS- IX(位于阿姆斯特丹的互聯(lián)網(wǎng)交換中心)上的公共樞紐與Facebook對等互聯(lián),而對等網(wǎng)絡的宣告也通過對等網(wǎng)絡的穿透互聯(lián)運營商到達了Facebook的網(wǎng)絡。模擬客戶端的IP地址通過穿透運營商和與Facebook直接連接都進行了BGP宣告。客戶端持續(xù)使用HTTP從Facebook獲取515KB和30KB的文件,保持客戶端CPU和帶寬利用率低于20%。隨著時間的推移,使用Linux的流量控制框架來引入40毫秒的延遲,這個延遲疊加在:與Facebook直連的路徑、穿透路徑或兩者同時疊加。使用AltPath來測量5分鐘內(nèi)直連路徑和穿透路徑的性能差異。在持續(xù)的18個小時的實驗中,AltPath在所有測量結果中的測試誤差都在2.2毫秒以內(nèi),平均誤差為0.6毫秒。這種精準度足以滿足Edge Fabric在做流量遷移決策時所需的要求。 ?
運維經(jīng)驗
Edge Fabric經(jīng)過多年的發(fā)展,以響應PoP節(jié)點的增長和運營經(jīng)驗的實現(xiàn)。目前Edge Fabric的設計專注于提供需要的靈活性來處理不同出口路由的場景,但在任何可能的情況下,整體設計都傾向于使用易于理解的技術和協(xié)議,而不是更復雜的方式。 ?
Edge Fabric控制層的演進
當PoP節(jié)點數(shù)量和其規(guī)模不斷的增長時,F(xiàn)acebook更是追尋簡單、可擴展的設計架構。這些期望的特性需要對設計的組件進行持續(xù)的評估和改進,并仔細考慮這些設計決策將產(chǎn)生什么樣的長期影響。 ?
從有狀態(tài)到無狀態(tài)控制
當前Edge Fabric的實現(xiàn)是無狀態(tài)的,這意味著它在每30秒的周期中從零開始進行計算、分配和更改決策,而不需要知道它之前的遷移決定。由于設計簡單,這種方法有許多優(yōu)點。例如,因為無狀態(tài)Allocator通過收集到所有它需要的信息(路由和流量)就可以開始每個運行周期,并在控制器沒有干預的情況下預測計算出口的利用率,所以測試、重啟或發(fā)生故障時遷移控制器是很簡單的。給定輸入和預測,控制器只需要計算出應該遷移哪些流量,測試也可以非常簡單的通過提供輸入場景、檢查決策結果來完成。
相比之下,之前的有狀態(tài)的實現(xiàn)需要在每一輪計算之后在本地和遠端記錄Allocator的狀態(tài)。如果控制器由于升級或失敗而重新啟動,它必須從遠端記錄中恢復之前的決策,這增加了復雜性。此外,有狀態(tài)控制器的決策過程更加復雜,因為控制器不僅要決定當出口過載時哪些目的地前綴要遷移,而且還要決定在給定的當前出口負載下,要刪除哪些現(xiàn)有的遷移決策。因為有狀態(tài)控制器在出口利用率降到閾值以下時才會考慮刪除遷移決策,所以當出口利用率持續(xù)增加時,它無法回溯,而且它的下一步?jīng)Q策選項會受到之前操作結果的影響。在某些情況下,控制器會將一個目的地前綴遷移到一個備選路徑上,但在下一個計算周期中,再次遷移該流量。維護這些狀態(tài)和決策的記錄使得實現(xiàn)和測試變得異常復雜,因為程序邏輯實現(xiàn)和測試工作必須要注入相關聯(lián)的一系列狀態(tài)和決策,這些復雜性最終成為了設計無狀態(tài)實現(xiàn)方式的驅(qū)動因素。 ? 從基于主機的路由到基于邊緣的路由 ? 目前的Edge Fabric的實現(xiàn)使用BGP來完成路由更改,并且只要求主機對需要特殊處理的流量設置相應的DSCP值即可,例如前面提及的用于備選路徑測量的流量。相比之下,以前的Edge Fabric實現(xiàn)依賴于基于主機的路由來實現(xiàn)更改。在主機路由模型中,控制器需要在PoP節(jié)點內(nèi)的每臺服務器上安裝其流量規(guī)則。這些規(guī)則將用于標記到達不同目的地的流量。然后在對應的PR路由器上使用相應的規(guī)則來匹配這些流量標記,最后通過繞過標準IP路由(策略路由)將數(shù)據(jù)報文從指定的出口送出去。
在基于主機的路由時代,Edge Fabric先后在生產(chǎn)網(wǎng)絡中實現(xiàn)過三種不同的標記機制:MPLS、DSCP和GRE(基于MPLS的實現(xiàn)比目前的Edge Fabric更進一步,它根據(jù)主機的決策來路由所有出口流量,有效地將所有IP路由決策從我們的PR中轉移出去)。MPLS和DSCP與早期的PoP架構是兼容的,在這個架構中, 跨PR的對等互聯(lián)和穿透連接出口是平衡的,任何需要遷移的流量都被發(fā)送到穿透連接的出口上去了。由于流量受ECMP約束,所有PR對所有出口有相同的規(guī)則(例如,DSCP值12將使流量在所有PR路由器上轉發(fā)到穿透運營商X,這需要所有的PR都具備到X的出口)。然而,隨著的PoP架構的發(fā)展,PR之間的對等互聯(lián)和穿透出口的容量越來越不平衡,并且想要具體控制某個PR出口的流量,在那個設計中使用GRE隧道在服務器和PR路由器之間轉發(fā)流量。
從使用過的這些機制的經(jīng)驗來看,F(xiàn)acebook發(fā)現(xiàn)要同時獲得軟硬件供應商對隧道協(xié)議的快速、強有力的支持是非常重要的。讓終端主機擔負路由流量到指定出口的責任,使得調(diào)試和審計網(wǎng)絡的行為變得更加困難,因為必須在多個層面上進行配置檢查。此外,當出口發(fā)生故障或路由撤回時,終端主機必須迅速做出反應,以避免黑洞流量,這使得終端主機、PR路由器和控制器之間的信息同步至關重要。
相比之下,目前版本的Edge Fabric不需要主機知道網(wǎng)絡狀態(tài),通過在PR注入更改的BGP路由實現(xiàn),降低了同步的復雜性。此外,這種方式使PR能夠應對控制器的某條決策失效的情況,以防止流量黑洞,例如:因出口故障導致PR接收到的備選路徑不可用了,那么PR路由器還是可以使用BGP選路機制找到下一個優(yōu)選路由。
基于邊緣路由實現(xiàn)方式比基于主機路由具備更多的優(yōu)點,同時還更簡單。雖然基于主機路由能讓主機對數(shù)據(jù)包的路由方式有更多的控制能力,但由于以下的種種原因,這種額外靈活性帶來的優(yōu)點并不足以抵消實現(xiàn)的復雜性帶來的難度。首先,測量結果表明,大多數(shù)流量還是使用的BGP缺省優(yōu)選路徑(參見圖12,遷移的流量平均峰值在10%左右),Edge Fabric僅覆蓋了一小部分流量用以避免擁塞或提高性能。其次,改變基于目的地路徑的實現(xiàn)方法可以允許服務器標記選擇的流量(設置數(shù)據(jù)包的DSCP值)以期望進行特殊處理,并允許控制器決定這些流量的路徑是否應該被更改。雖然這種解耦方式限制了服務器的控制力度,但是整個系統(tǒng)的設計更為簡單、故障排錯也更容易,并且對于實際場景來講具備了足夠的靈活性。第三,因為Facebook選擇的全局流量均衡模式是流量在一個PoP節(jié)點進出對稱(同一個PoP節(jié)點進,同一個節(jié)點出),所以對于出口的選擇來說相對有限,決定發(fā)送到那個PR路由器即可。如果全局負載均衡系統(tǒng)探測到另一個PoP節(jié)點可以提供更好的性能,那么全局負載均衡系統(tǒng)直接將用戶切換到那個PoP即可。 ?
從全局到單一PoP節(jié)點
以前,F(xiàn)acebook網(wǎng)內(nèi)的PoP節(jié)點之間是運行iBGP來傳播來外部的eBGP路由。這種情況下,用戶的流量從一個PoP節(jié)點流入,但可以通過另一個PoP節(jié)點流出。在某些情況下,通過內(nèi)部的廣域網(wǎng)將流量從一個遠端的PoP節(jié)點的出口送出可以提高性能,但必須有相應的機制來防止它引起振蕩。例如,過載的出口上的一些流量可能已經(jīng)通過遠端PoP進入。如果Edge Fabric在出口PoP節(jié)點內(nèi)改寫路由以避免擁塞,更新路由將傳播到另一個入口PoP節(jié)點。如果通過改寫B(tài)GP路由讓入口PoP節(jié)點停止優(yōu)選出口PoP節(jié)點,那么這個預測流量就不會計入本地的出口流量中,本地出口的無過載狀態(tài)可能會讓Edge Fabric去掉之前的BGP路徑改寫行為,這會導致本地出口又出現(xiàn)擁塞,流量再次遷移到遠端PoP節(jié)點,流量在兩個PoP節(jié)點之間不斷震蕩。為了防止這種“入口PoP優(yōu)選出口PoP節(jié)點”的情況,控制器將改寫的BGP路由屬性設置成與原始路由相同。但控制器在操控BGP屬性上會混淆路由信息,給運維團隊理解和調(diào)試出向路由帶來了困難。在提高了全局負載均衡系統(tǒng)映射的準確性和顆粒度以后,F(xiàn)acebook就去掉了PoP節(jié)點之間的路由互傳(去掉了iBGP進程),現(xiàn)在流量的進出都在同一個PoP節(jié)點上。由于全局負載均衡系統(tǒng)控制流量進入的PoP節(jié)點,它可以將客戶的流量負載分擔到它認為等價的幾個PoP節(jié)點上,這樣可以同時利用多個PoP節(jié)點的出口容量。這使得Facebook可以避免使用內(nèi)部骨干網(wǎng)在PoP節(jié)點之間來傳遞最終用戶的流量,并簡化了Edge Fabric的設計。 ?
從平衡到非平衡容量
隨著的PoP節(jié)點的不斷增長, PoP節(jié)點的設計也需要隨之優(yōu)化來處理很多邊緣場景。當增加PoP節(jié)點的數(shù)量和規(guī)模時,PR路由器上面開始有更多不平均的出口互聯(lián)帶寬,部分原因是互聯(lián)出口的連接的不均衡增長,但也可能是由于發(fā)生故障和長時間的修復時間(海纜差不多2個月就會斷一次,平均7個小時來修復)。這些因素都造成了PR上出口帶寬不均衡的問題,現(xiàn)有設計中ASW使用的是ECMP將流量發(fā)送給多個PR,但ASW對于PR的不均衡出口并不知道,所以會導致均衡的流量進入PR但出口容量不均衡導致的問題。對于這個問題,可以考慮使用WCMP來解決,而不用在Edge Fabric上實現(xiàn)。
然而,由于種種原因,最終選擇了擴展Edge Fabric的功能來處理這些容量失衡的情況。首先,雖然有許多路由和交換芯片支持WCMP,但與ECMP相比,供應商對WCMP的采用和支持要少得多,這使得采用WCMP方案的風險更大。即使使用vanilla-ECMP算法,也能觀察到不均衡的流量分布和其他問題以及意想不到的行為。其次,由于供應商使用的WCMP實現(xiàn)是私有的,所以無法預測WCMP將如何運行,這使得預測計算和工程流量更加困難,并可能增加Edge Fabric的復雜性。最后,WCMP實現(xiàn)需要對路由器的整個路由表進行操作,路由表在發(fā)生變化以后可能需要分鐘級別的時間來收斂,在此期間可能沒法有效的進行正確的均衡流量。相比之下,Edge Fabric可以識別出流量的目的地網(wǎng)段的子集及其流量,并在幾秒鐘內(nèi)進行更改路由注入,從而緩解故障。 ?
IXP的挑戰(zhàn)
互聯(lián)網(wǎng)交換中心(IXP)一直是學術界關注的焦點,同時也對Facebook這種規(guī)模的內(nèi)容服務商提出了挑戰(zhàn)。與PNI(專用的私有連接)相比,內(nèi)容服務商無法知道 Peer的端口到底有多少可用容量,因為在IXP的其他Peer網(wǎng)絡可能也在向它發(fā)送數(shù)據(jù)(IXP的典型拓撲是通過交換機實現(xiàn)Hub-Spoke式互聯(lián))。這種有限的可見性使得避免擁塞的同時期望最大限度地利用接口容量變得更加困難。Edge Fabric通過設置每一個Peer出口的速率限制,來實現(xiàn)對Peer出口容量的可見性,以避免阻塞。在這種場景中,直接聯(lián)系IXP的各個Peer來獲得、設置其容量限制是更有效的方式。這種方式類似和具備PNI的出口一樣,只是會對利用率進行限制。 ?
相關工作
CDN流量工程
隨著CDN流量的增長,研究者和工程師們提出了新的流量工程解決方案。在CDN流量工程中,Edge Fabric也采用了一種常見的方法,即集中SDN的方式來控制,將網(wǎng)絡和流量信息結合起來配置網(wǎng)絡設備。
研究人員已經(jīng)研究了多種客戶端請求流量的處理方法,包括使用Anycast和DNS擴展作為將客戶端請求流量引導到“就近”的服務器上的機制。這些解決方案針對的是與前文中所描述的不一樣的挑戰(zhàn),這些方案也是Edge Fabric的有效補充。Facebook采用了這些解決方案來選擇客戶端流量去往那個PoP節(jié)點,但在PoP內(nèi)仍然需要Edge Fabric來選擇合適的出口回送去往客戶端的流量。
與Edge Fabric更相關的是Footprint(微軟的流量調(diào)度系統(tǒng))、PECAN、Entact和Espresso(Google的B2廣域網(wǎng)流量調(diào)度),它們選擇PoP節(jié)點或者路徑的時候是考量的路徑的性能。Footprint專注于在PoP節(jié)點之間遷移長連接有狀態(tài)的會話負載,以避免擁塞;PECAN專注于度量性能和選擇入口路由(入向流量),Edge Fabric設計用于在備選出口(出向流量)之間遷移流量,以避免擁塞。這三個設計方案是互補的:Edge Fabric的技術可以應用于Footprint和PECAN,反之亦然。
Entact和Espresso是最相似的。Entact通過一種精心設計的方法,平衡了BGP的性能、負載和成本,通過仿真來評估BGP的缺省選路策略。與AltPath類似,Entact將一些流量導向備選路徑,以測量其性能。Facebook以這個想法為基礎,按照自身用戶流量的特點做了相應改進,然后在生產(chǎn)環(huán)境中大規(guī)模部署。例如,Entact測量目的地網(wǎng)段前綴內(nèi)的單個IP地址的備選路徑性能,而AltPath則是在地址空間內(nèi)隨機選擇流量,以防不同地址具有不同性能的情況,并允許在將來基于應用區(qū)分的路由也可以使用這個機制。Entact使用主動測量(Ping)來測量路徑性能,但無法在許多前綴中找到響應地址,因此只能對26%的MSN流量做出決策。對響應地址的需求也限制了Entact可以并行測量的備選路徑的數(shù)量,并使得它沒法實現(xiàn)通過分割聚合地址前綴來增加決策顆粒度。這些原子分配的方式對于Entact的最佳流量分配來講,可能不是一個很好的近似值估算,因為它前提條件是:需要能夠在多個路徑上任意地將地址前綴的流量分割并測量。Edge Fabric采用了類似于Entact的方法,但不同的是基于生產(chǎn)流量的被動測量方式,它使用Facebook現(xiàn)有的服務器端的測量基礎設施來采集能夠代表整個用戶群流量的數(shù)據(jù),并且能夠分割地址前綴以增加決策顆粒度。并且可以使用現(xiàn)有PR路由器所能支持的盡可能多的并行路徑。
Espresso是谷歌的SDN流量調(diào)度系統(tǒng),用于控制出口路由。Espresso和Edge Fabric都是由大型內(nèi)容服務商設計的,在面對PoP節(jié)點和流量的快速增長的同時,它們需要克服BGP協(xié)議自身和BGP路由器的挑戰(zhàn)。它們的高階設計實現(xiàn)方式都類似:集中控制路由,同時保留BGP作為和對端互聯(lián)的接口。然而,這兩個系統(tǒng)在許多其他重要的設計決策上對其決策因素有不同的優(yōu)先級排序,這些優(yōu)先級的排序也最終影響了設計的結果。Espresso使用定制的架構來消除對支持互聯(lián)網(wǎng)全球路由表的的需求(Google的OpenFlow的硬件無法支持全球路由表),而Edge Fabric則依賴于BGP和供應商的BGP路由器來構建(商業(yè)路由器可以輕松支持全球路由表)。Edge Fabric通過隔離PoP節(jié)點來限制它的多個路由表的大小,這樣每個PoP節(jié)點承載用戶流量的地址前綴數(shù)量就很低(圖3)。而Facebook通過隔離地址前綴宣告、入口策略、出口策略和對單個PoP節(jié)點的控制來實現(xiàn)了簡單性(都是基于BGP協(xié)議的標準通用屬性),Espresso使用集中的全局控制器,可以將流量通過廣域網(wǎng)路由到遠端的PoP節(jié)點出口,提供了靈活性。Edge Fabric的控制器只在PoP節(jié)點內(nèi)決定出口,并將其推送給本節(jié)點內(nèi)的PR路由器,可以讓主機和網(wǎng)絡狀態(tài)之間解耦。另一方面,Espresso將路由決策推給主機,使其靈活性最大化,但需要更復雜的控制器架構和主機上的路由狀態(tài)保持實時同步,這樣才能防止流量黑洞。前面描述了這些權衡以及最后的選擇,這都是基于Facebook過去在PoP節(jié)點和基于主機路由之間流量控制的經(jīng)驗(早期的Edge Fabric設計更類似于Espresso)。當然,Espresso也有自己的一些方法來應對本節(jié)所描述的挑戰(zhàn)。
B4(Google的數(shù)據(jù)中心網(wǎng)絡)和SWAN(微軟的集中控制器,處理網(wǎng)絡擁塞)的集中控制是跨數(shù)據(jù)中心網(wǎng)絡的,在不影響高優(yōu)先級流量性能的情況下最大化利用率。Edge Fabric也有類似的目標,它也使用集中控制。然而,背景的不同帶來了新的挑戰(zhàn)。特別是B4和SWAN是在一個封閉的環(huán)境中運行的,所有的主機和網(wǎng)絡設備都是統(tǒng)一管理的,大部分的流量都可以容忍時延和損失(東西流量,低優(yōu)先級的用戶數(shù)據(jù)同步的流量為主)。相反,Edge Fabric控制網(wǎng)絡和用戶的出口流量。此外,大部分是自適應速率的視頻流量(南北流量,最終用戶的直接流量),其延遲要求遠遠超過數(shù)據(jù)中心間廣域網(wǎng)的彈性流量。Fibbing集中控制傳統(tǒng)的OSPF網(wǎng)絡,注入路由信息讓域內(nèi)路由器優(yōu)選特定路由。Edge Fabric的控制器類似地注入路由,但注入的BGP路由對于全網(wǎng)的可見性和控制要少得多(只在PR路由器生效)。 ?
性能監(jiān)控
對于CDN流量工程,現(xiàn)有的技術通過向網(wǎng)絡注入測量流量(主動測量)或被動地監(jiān)控正在運行的流量來測量路徑性能(被動測量)。主動測量技術需要通過專屬工具產(chǎn)生、收集測量數(shù)據(jù)或者部署專用測量點。被動測量技術通常需要網(wǎng)絡設備的監(jiān)控功能(一般很貴)。Edge Fabric在Facebook的服務器上采用的是被動測量技術,它允許:1)在不需要測量上百萬用戶的情況下監(jiān)控所有路徑和服務,2)與并入路徑的專用測量設備相比,可以收集更豐富的指標(如SRTT)。 ? 有意了解更多Tier-1 OTT技術趨勢,可以添加微信共同討論: ? ? ? 參考文獻:Engineering egress with edge fabric - Steering oceans of content to the world ? ? ?
編輯:黃飛
?


















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論