 電子發燒友App
電子發燒友App


一、整體思路
現在進入正題,今天的分享從三個方面進行:
匹配域相關的各個模塊簡單分析。
安裝檢驗和調試
演示結果。
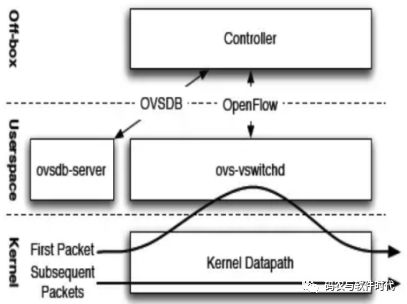
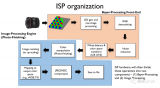
相比在ovs源碼中添加自定義action,自定義匹配域顯得關系更為復雜凌亂一些。為了讓和匹配域相關的模塊條理更加清楚明了,我盡量將要提到的相關模塊關系化,防止漏掉和匹配域相關的部分。這里先給出總體架構圖:

架構圖中包含了將要分析的8大模塊,每一個里面都有和匹配相關的內容,接下來會按照這個思路逐一分析。其實大家發現,這和流表從控制器下發后,數據包進入交換機的處理流程非常吻合,想必大家多多少少有一些認識。
二、各個模塊分析
下來進入分享的重點。按照圖中給出的思路,各個模塊講解順序依次為:
1、匹配域定義
2、flowmod解析
3、用戶層表項插入
4、內核層packet解析和匹配處理
5、Upcall接收和分類
6、用戶層查找匹配處理
7、表項和packet的下發操作
8、內核層flow插入和packet執行
9、其他
1、匹配域定義
Ovs匹配域是基于OpenFlow協議的,因此,如果要添加一個新的匹配域,需要延續OF協議定義一個匹配域的邏輯,這樣拓展出的新匹配才能較為容易的和其他OF已經定義的匹配域兼容起來,同時保障OVS的匹配處理邏輯不發生改變。
1)目前OF支持兩種定義匹配域的格式,用的較多的是OXM格式,即TLV格式(類型,長度和值)。我們之后的講解以TLV格式為基礎進行。那么要想實現一個新的匹配域,代表類型的T和長度的L比不少,他們定義在枚舉類型和宏定義中。
首先看枚舉類型,目前OF在1.3協議中已經定義了40種匹配字段,它們枚舉值定義在include\\openflow\\Openflow-1.2.h中,部分截圖如下:
每一個匹配域有相應ENUM值,從in_port的0到IPV6_EXTHDR的39,因此對于新的匹配域,需要以這種格式進行添加即可,但ENUM值必須是目前還沒有定義過的值。
2)除了要添加枚舉值外,還需要添加一個TLV相關的宏定義。TLV頭部如下(TL部分,相當于綁定了一個匹配字段的類型和長度):

對于一個新匹配域,只需要按照上面格式進行添加即可,注意4或是8指的是TLV中的L數值,表示匹配域值的長度。如對于inport則是4字節。之后OVS對flowmod中匹配域解析就全依賴這個枚舉值和宏定義了,此外提一句,如果是在控制端也做匹配域添加,需要和這個枚舉值和TL格式對應起來。
2、FlowMod消息解析
完成之前的新字段的TLV定義還遠遠不夠,即將等待我們的是,OVS如何能夠從Flowmod消息中準確提取出匹配域,并且能無排斥的插入原生的OVS流表中。接下來分析一下flowmod消息解析模塊。
先上圖:

圖體現了大體思路: Flowmod消息的匹配域部分,最終是要按照TLV格式逐一解析出來,然后經過一系列依賴性和重復性檢測等,最后才能將匹配域部分完整的解析放置在match結構體中。
Match是什么?是用來裝載從flowmod消息中解析出來的匹配域。先來看看match結構體:

Match包含了flow和wc,前者裝載字段值,后者標記字段掩碼(深入會發現wc也是用flow結構體存儲掩碼)。Flow結構體包含了匹配域所有字段類型,因此對于新的字段,需要在此結構體中添加。

需要注意的是,匹配字段在flow中添加的前后位置要固定,因為后面添加相應源碼時需要和這個位置一致。
2)說完了match,那如何從flowmod的匹配域中逐一解析出每一個字段呢?(其主要思想體現在函數nx_pull_raw()中)
大體是這樣的,匹配域由多個TLV組成,每一個TLV是一個匹配字段。則OVS先會從flowmod匹配域中按照TLV中的L將每個OXM(TLV格式)切割出來。這樣是不是就解析完了呢,顯然不是,因為切割后的合法性無法保障(如長度是否符合定義,各個字段依賴是否正確等)。
這里就需要后面的工作了,通過分割出來的OXM的header(即TL部分),在匹配域哈希表mf_field(Hmap)中做哈希查找,然后查找到這個TL應該對應的mf_field結構體。mf_field是OVS已經聲明定義好的匹配域信息集合,包含依賴性,名字,長度等信息,這些可以對分割出來的該字段進行檢驗。Ok,清楚了這些,下面給出匹配域字段解析的示意圖:

剛才提到字段信息的集合mf_field,其以數組形式定義在mf_fields中,我們需要在此處寫入新字段的信息:

如上面這個是inport字段信息集合,可以看到它包含了名字,字段長度和最開始提到的匹配域定義的enum OXM_OF_IN_PORT。這里注意,包含的第一個屬性是mf_field的id號,一個mf_field有一個id,其定義在mf_field_id枚舉類型中(對于新字段也需要在這里添加一個id,注意相對位置)。這個id號算是OVS自身識別匹配域類型的方式,之后匹配域合法性檢測會都會用到這個id號。
3)接下來,會根據字段mf_field信息對分割的每個字段做依賴性檢測、重復性檢測和匹配域值的有效性檢測等。
A、依賴性檢測:如當設置ipv4匹配字段時,會檢測match->flow的“二層協議匹配字段”是否已經是ip協議。如果新添加匹配字段有依賴性限制,則需要在函數mf_are_prereqs_ok中添加case進行檢測。
B、重復性檢測:因為匹配域字段是逐個解析的,為了防止當前字段類型已經在之前存在過,則需要進行重復性檢測,對于新的字段,需要在函數mf_is_all_wild()添加代碼進行檢測。
C、匹配域值的有效性檢測:對于一些匹配字段值是有規定的,如inport號是否大于最大范圍等,對于新字段也需要在函數mf_is_value_valid()中完成檢測。
檢測完就可以安安心心的將解析的每個字段值賦給match結構體了,賦值時會分有掩碼和無掩碼情況,也需要添加相應新字段源碼。
其實,令人欣慰的是,對于一個新字段需要在各處添加源碼,看似繁雜,也基本就是照別的字段源碼格式多寫一個case的事情,照貓畫虎也算是是個好方法。
3、流表項插入
完成flowmod的匹配域解析,那么剩下的就是依照flowmod要求進行流表項刪除、添加等操作,這里對于一個新字段無需源碼改動。
OVS有很多保障性能的方法,這里就有一處,簡答提一下:Ovs定義了一個重要結構體cls_rule,其與匹配域信息、priority信息等相關,且cls_rule關聯一個相應的流表項。當ovs向流表中插入新表項時,不是以表項全部內容進行重復性檢測,而是通過cls_rule在分類器cls_calssifier中進行查找,這種對流表項分類查找方法可以大大提高工作效率,完成新表項的添加或是更新。
4、內核層packet解析和匹配處理
用戶層表項解析與插入告一段落,下來就是當數據包進入交換機時,如何完成packet解析與匹配處理。(核心代碼位于datapath文件夾下,數據包頭解析和匹配旅程從ovs_vport_receive()開始)
我們知道,ovs為了提高效率,數據包會先在內核層datapath進行流表項匹配處理,對于匹配失敗,或者是匹配到表項的action為發向用戶層時,才會去用戶層繼續查找匹配。對于在用戶層匹配成功的數據包會按照表項action相應處理,并向內核層下發一條匹配到的表項,方便以后類似數據包直接在內核層完成匹配轉發。

這個過程將是要一一解釋的關鍵點,無不和匹配域息息相關。先來說說數據包進入ovs內核層的處理過程。
1)當一個OVS端口接收到一個數據包,不是將整個數據包在內核層的流表中匹配查找,這樣效率低下,而是需要對此數據包頭字段進行解析,將解析出來的各個匹配字段值和端口號一起構造成查詢key,然后用key在流表中進行匹配查找。
查詢key,它是一個sw_flow_key結構體,如下,包含了各個匹配字段的類型,對于新字段也需要在這里進行添加。

此外,需要調用函數key_extract()依次從包頭中提取各個字段放入key中。如果你構造了一個數據包新協議字段,就需要在這個函數中提取相應包頭字段賦值給key即可,包頭提取都是對linux的結構體操作,很方便快捷。
2)有了key,那就是內核層流表項匹配查找的事情了。由于此次分享圍繞匹配域展開,內核中流表匹配查找階段,不涉及具體的匹配字段,也無需做修改添加,因此不具體分析匹配查找流表項的具體過程。
查找結果無非兩種,查找成功和查找失敗。查找失敗則構造upcall上交用戶層繼續查找處理,但這里需要注意,即使查找到也可能面臨上交處理。因為有一些action無法在內核層執行,這種action在下發到內核層時已經標記為OVS_ACTION_ATTR_USERSPACE類型,此時也需要上交用戶層進一步匹配處理。
上交用戶層時(主要體現在queue_userspace_packet函數中),會構造上交的數據包user_skb(skb_buf結構體),然后通過generic netlink通信機制上交給用戶層。
結構體skb_buf可以簡單理解為這樣的結構:Netlink頭部+Attr+Attr+...,Attr是type+len+data結構。Attr主要分為三個類型信息:
?key:即由包頭等構造的查詢key,必不可少,數據類型type為OVS_PACKET_ATTR_KEY
?userdata:用于匹配成功卻仍要走slow-path的數據包,標記了action參數(如原因),數據類型type為OVS_PACKET_ATTR_USERDATA
?packet:顧名思義,原始數據包。類型type為OVS_PACKET_ATTR_PACKET。
注意,在這里,有兩部分內容和匹配域相關,添加新匹配域時候就需要在此處修改源碼:
?A是對于待上交key中含有的各個字段計算總長度(key_attr_size())
?B上傳數據user_skb中的key包含很多匹配字段。因此新字段也要從key中提取出來加入到待傳輸到用戶層的數據體中(函數ovs_nla_put_flow()),提取時會用到各個匹配域數據的類型(enum ovs_key_attr枚舉類型中定義)。
5、Upcall接收和分類
到這里,已經完成和匹配域相關的多大半內容,思路已經比較清晰,后面將加快進度。
上面說到,內核層會封裝含有key、packet和action參數等內容的upcall消息上交用戶層。那么用戶層接收到upcall之后直接匹配表項即可,為什么還要分類呢?(其主要體現在函數read_upcalls()(ofproto-dpif-upcalls.c))。
先給一張圖:

可以看到,用戶層的upcall結構體有dupcall和miss兩個成員,這就和ovs性能提升密切相關了。OVS將具有相同key的upcall歸為一類,管理映射到同一個miss中。這樣就完成了相似packet的分類工作,便于后期統一匹配處理,提高效率。
在上面這個過程中,需要從key提取出flow進行哈希查找和分類。Flow就是前面講解到的用戶層用于表示匹配域的結構體,OVS調用函數flow_extract()函數從packet與md(metadata元數據)中解析并構造flow賦值給miss->flow,在這里別忘了添加相應解析函數。
其實,分類還包括了對slow path原因的分類處理,因和匹配域無關,就不詳述了
6、用戶層查找匹配處理
完成upcall前期接收和分類工作,下來就是匹配處理了(主要體現在函數handle_upcalls()(ofproto-dpif-upcall.c))。
這里只有一處和新匹配域添加相關(odp_flow_key_from_flow__()函數),因此主要強調其工作原理。OVS會先分批(之前提到的,劃分為同一個miss的數據包)完成用戶層流表匹配查找,然后得到流表項action,并將用戶層action翻譯為內核層odp_action,并對屬于slow_path的action數據包做特殊標記處理(miss.xout->slow),尤其對部分slow_path中slow_action的做help標記。之后就可以下發查找到的表項到內核層了,并將數據包發到內核層去執行流表項的action。
這個過程很合情合理,但標記做什么用呢?因為數據包匹配到的流表項,其action執行只能通過慢通道處理(最典型的就是Controller action,甚至是因為action過多或是數據量太大),因此標記后,就會將這些含有slow_path action的表項和packet 直接在用戶層完成特殊處理,這基本和內核層關系就不大了,效率自然也不會高。
7、表項和Packet的下發操作
接下來的工作,就是將表項下發到內核層,并將packet通過netlink機制下發到內核層去執行action(主要體現在函數dpif_operate()中)。
由于之前提到的slow-path原因,OVS會采用兩種形式下發,一種是和slow-path無關的統一處理下發,一種是和slow-path相關的單獨特殊處理。
1)統一下發處理較為簡單,就是批量以廣播形式通過netlink機制下發到內核層,完成流表項在內核層的安裝和packet在內核層action的執行。這里需要注意的是,如果自定義的新匹配域屬于metadata類型,如inport這種,那么需要在odp_key_from_pkt_metadata()函數中,實現將元數據內容的取出放入request緩存后等待下發的功能。
2)特殊處理:對于一個需要slow-path處理的packet,其所有動作actions本應在用戶層執行(即在odp_execute_actions__()函數),但是執行到OVS_ACTION_ATTR_OUTPUT類型action時,不言而喻其最后需要發送到內核層完成轉發。那么這種含有slow_path的流表項是否需要下發到內核層?還記得之前的action翻譯嗎,這種表項會將action翻譯為OVS_ACTION_ATTR_USERSPACE下發到內核層中。如下,用戶層表項到內核層表項:

請注意,特殊處理中如果牽扯到set_field action,就需要在odp_execute_set_actio()添加新匹配域的set函數。
8、內核層flow插入和packet執行
轉了一圈,又回到了內核層。在內核層完成flow的插入和packet action執行工作基本就大功告成了。這里面的原理比較簡單,因此只提及在表項插入過程中與匹配域相關的地方。
OVS主要在用戶層下發的表項數據中,對含有的匹配字段值進行解析和字段有效性檢驗,完成表項插入。匹配字段解析中包含字段長度解析(ovs_key_lens()函數)和字段掩碼解析(ovs_key_from_nlattrs()函數),有效性檢驗(match_validate()函數)主要完成了匹配字段是否全初始化檢驗、掩碼和值的一致性檢驗等,對于新匹配域,以上幾個函數需要修改。
9、其他
圍繞著OVS匹配域有關的處理流程,終于分析完了從表項解析、插入、匹配,執行等一系列過程。當然,新的匹配域可能還不能很好的運作,因為還差打印顯示和手動插入等功能。這部分比較獨立,簡單提及函數即可。
打印密切相關:
miniflow_extract()
flow_format()
odp_flow_key_attr_len()
ovs_key_attr_to_string()
format_odp_key_attr()
其他一些:
mf_set_flow_value()(lib/meta-flow.c)
mf_get_value()(lib/meta-flow.c)
nx_put_raw()(nx-match.c)
parse_odp_key_mask_attr函數()(lib\\odp-util.c)
序號數FLOW_WC_SEQ
二、安裝檢驗和調試
對于添加一個自定義匹配域,源碼修改就算完成了,雖然比較繁瑣,但是每一處改動不大,基本照貓畫虎即可。安裝過程簡單,采用常規安裝OVS的方法即可。
如果安裝后,采用ovs-ofctl命令可以正常添加一條帶有自定義匹配域的流表項,并且數據包可以成功如愿以償的匹配到這條表項,那基本就大功告成了。
如果安裝失敗或是匹配不能按照預想的效果,需要進行調試。調試一般采用兩種方法,查看log信息和gdb工具調試:
1)log信息:匹配域的添加涉及用戶層和內核層,ovs在用戶層提供了相應log函數VLOG_WARN、VLOG_INFO、VLOG_DBG等,直接使用即可,用戶層log信息一般位于/usr/local/var/log/openvswitch/ovs-vswitchd.log中查看;
內核層可以使用printk等函數添加log,并在/var/log/kern.log中查看即可。
2)采用dbg方式,比較準確高級的。
三、演示結果
說了這么多,沒有實驗結果都是不可靠的。因此,我下發了一條流表項,包含了一個新的匹配域,并且成功匹配到了數據包,達到預期效果。可以用ofctl查看用戶層表項,用dpctl查看內核層表項。

為了能夠正確添加自定義匹配域,上文對于ovs匹配字段的執行流程和基本原理做了分析說明
審核編輯:郭婷















 工商網監
工商網監
評論