 電子發燒友App
電子發燒友App


我想起了我剛工作的時候,第一次接觸RPC協議,當時就很懵,我HTTP協議用的好好的,為什么還要用RPC協議?
于是就到網上去搜。
不少解釋顯得非常官方,我相信大家在各種平臺上也都看到過,解釋了又好像沒解釋,都在用一個我們不認識的概念去解釋另外一個我們不認識的概念,懂的人不需要看,不懂的人看了還是不懂。
這種看了,又好像沒看的感覺,云里霧里的很難受,我懂。
為了避免大家有強烈的審丑疲勞,今天我們來嘗試重新換個方式講一講。
從TCP聊起
作為一個程序員,假設我們需要在A電腦的進程發一段數據到B電腦的進程,我們一般會在代碼里使用socket進行編程。
這時候,我們可選項一般也就TCP和UDP二選一。TCP可靠,UDP不可靠。除非是馬總這種神級程序員(早期QQ大量使用UDP),否則,只要稍微對可靠性有些要求,普通人一般無腦選TCP就對了。
類似下面這樣。
fd?=?socket(AF_INET,SOCK_STREAM,0);
其中SOCK_STREAM,是指使用字節流傳輸數據,說白了就是TCP協議。
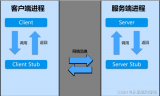
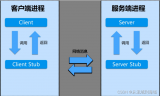
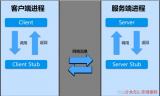
在定義了socket之后,我們就可以愉快的對這個socket進行操作,比如用bind()綁定IP端口,用connect()發起建連。
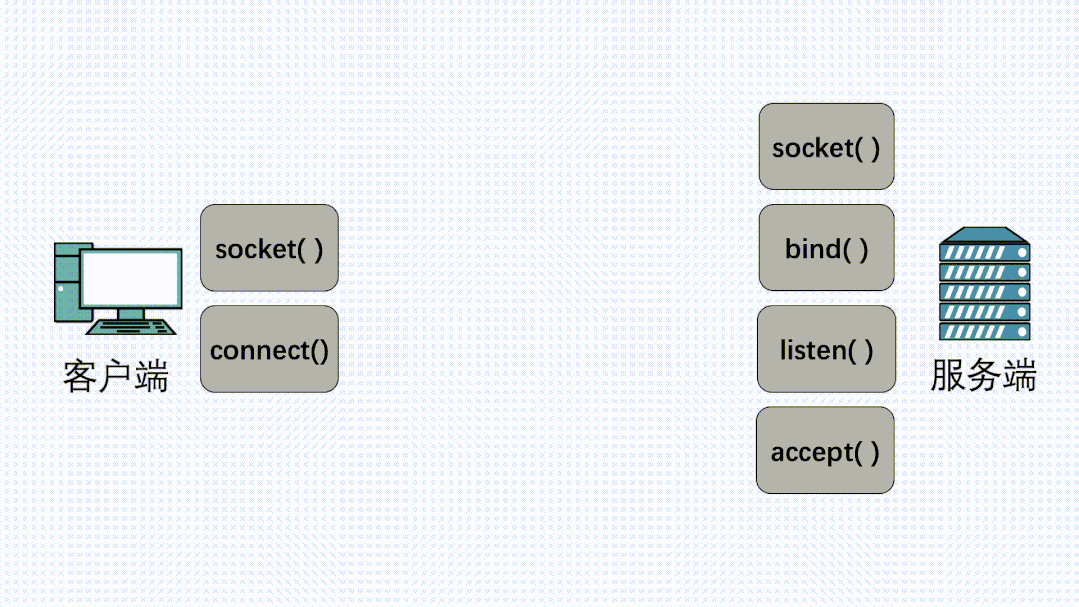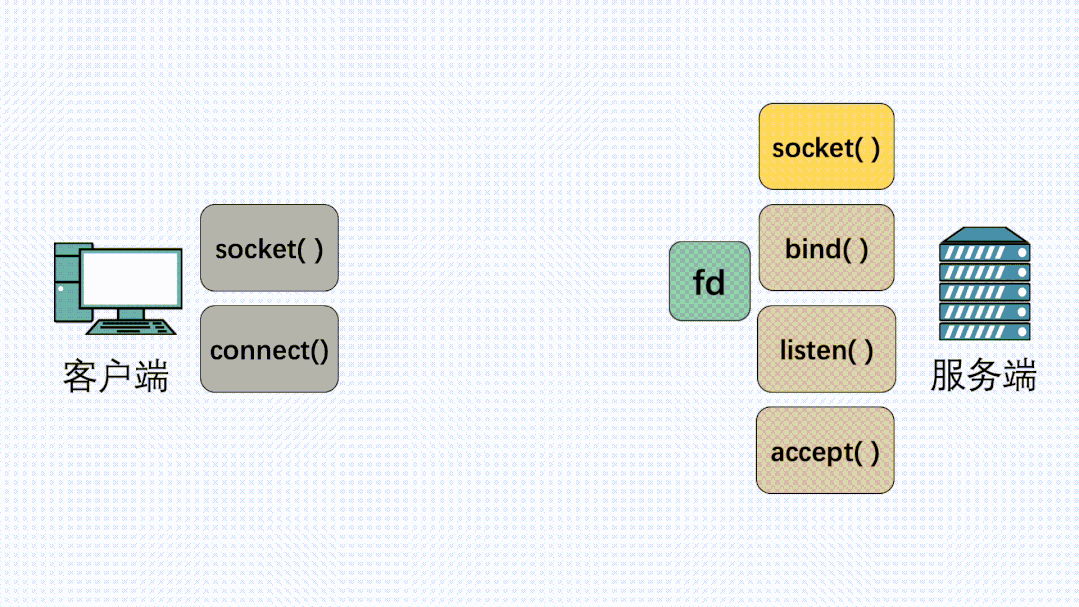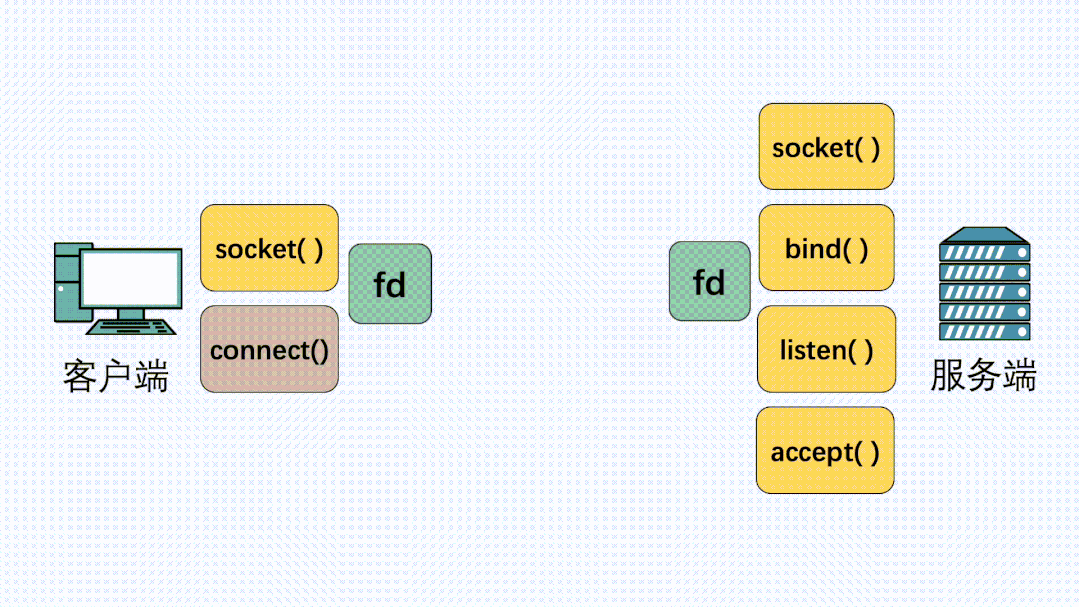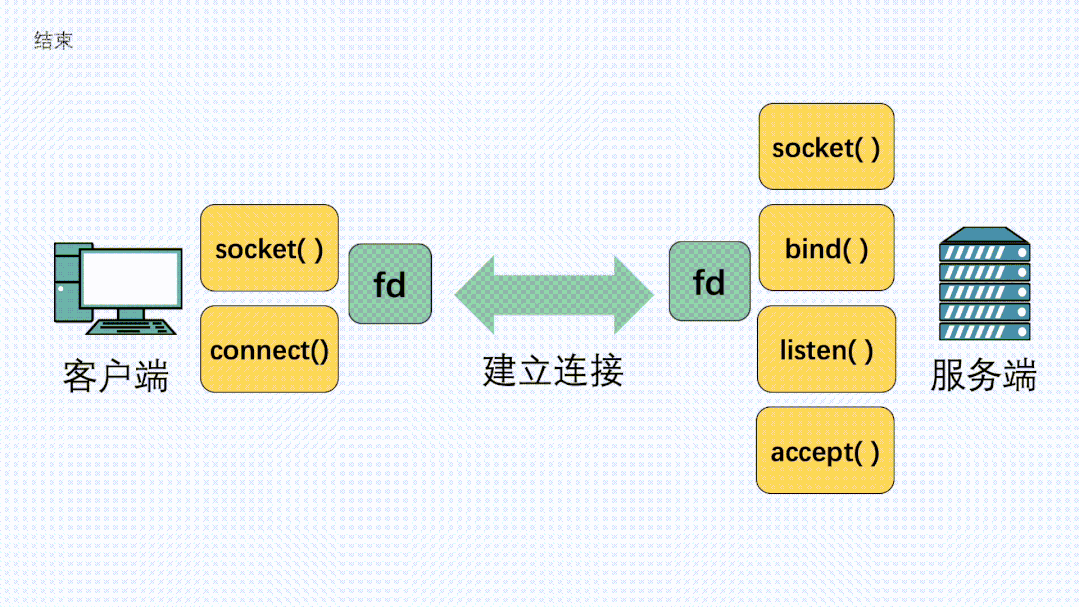
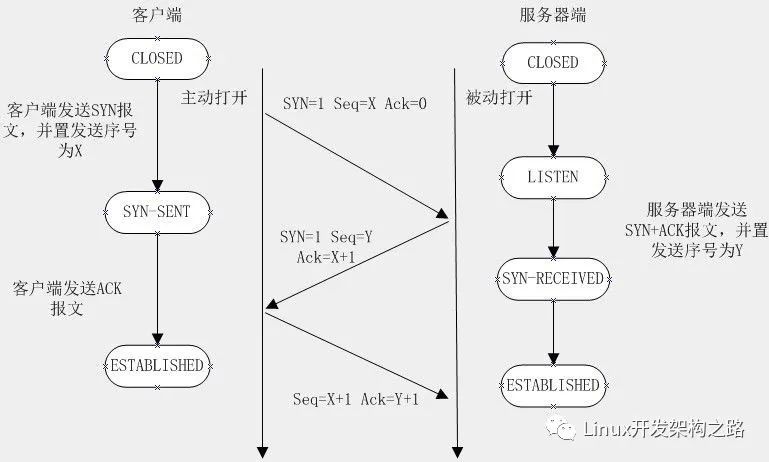
握手建立連接流程
在連接建立之后,我們就可以使用send()發送數據,recv()接收數據。
光這樣一個純裸的TCP連接,就可以做到收發數據了,那是不是就夠了?
不行,這么用會有問題。
使用純裸TCP會有什么問題
八股文常背,TCP是有三個特點,面向連接、可靠、基于字節流。
TCP是什么
這三個特點真的概括的非常精辟,這個八股文我們沒白背。
每個特點展開都能聊一篇文章,而今天我們需要關注的是基于字節流這一點。
字節流可以理解為一個雙向的通道里流淌的數據,這個數據其實就是我們常說的二進制數據,簡單來說就是一大堆 01 串。純裸TCP收發的這些 01 串之間是沒有任何邊界的,你根本不知道到哪個地方才算一條完整消息。
01二進制字節流
正因為這個沒有任何邊界的特點,所以當我們選擇使用TCP發送"夏洛"和"特煩惱"的時候,接收端收到的就是"夏洛特煩惱",這時候接收端沒發區分你是想要表達"夏洛"+"特煩惱"還是"夏洛特"+"煩惱"。
消息對比
這就是所謂的粘包問題,之前也寫過一篇專門的文章聊過這個問題。
說這個的目的是為了告訴大家,純裸TCP是不能直接拿來用的,你需要在這個基礎上加入一些自定義的規則,用于區分消息邊界。
于是我們會把每條要發送的數據都包裝一下,比如加入消息頭,消息頭里寫清楚一個完整的包長度是多少,根據這個長度可以繼續接收數據,截取出來后它們就是我們真正要傳輸的消息體。
消息邊界長度標志
而這里頭提到的消息頭,還可以放各種東西,比如消息體是否被壓縮過和消息體格式之類的,只要上下游都約定好了,互相都認就可以了,這就是所謂的協議。
每個使用TCP的項目都可能會定義一套類似這樣的協議解析標準,他們可能有區別,但原理都類似。
于是基于TCP,就衍生了非常多的協議,比如HTTP和RPC。
HTTP和RPC
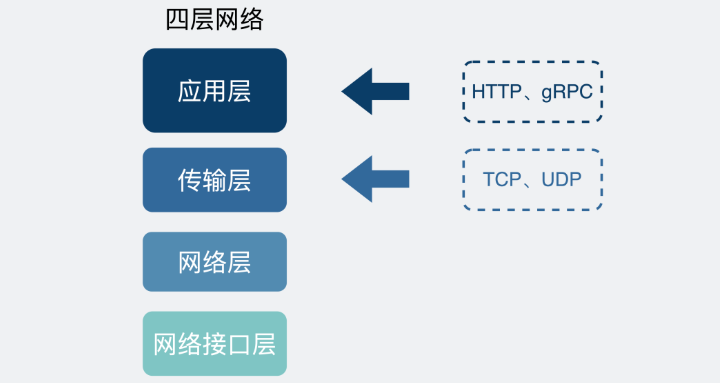
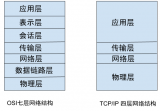
我們回過頭來看網絡的分層圖。
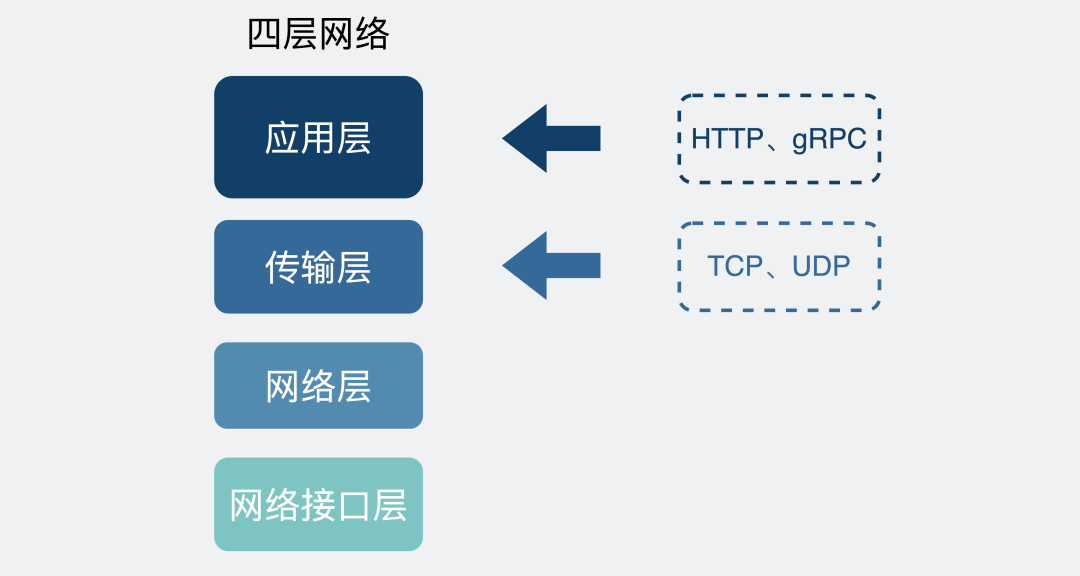
四層網絡協議
TCP是傳輸層的協議,而基于TCP造出來的HTTP和各類RPC協議,它們都只是定義了不同消息格式的應用層協議而已。
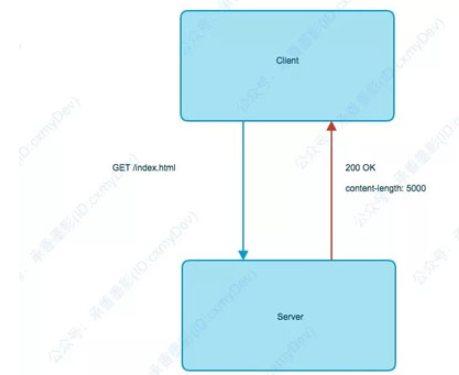
HTTP協議(Hyper Text Transfer Protocol),又叫做超文本傳輸協議。我們用的比較多,平時上網在瀏覽器上敲個網址就能訪問網頁,這里用到的就是HTTP協議。
HTTP調用
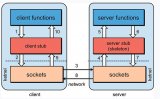
而RPC(Remote Procedure Call),又叫做遠程過程調用。它本身并不是一個具體的協議,而是一種調用方式。
舉個例子,我們平時調用一個本地方法就像下面這樣。
res?=?localFunc(req)
如果現在這不是個本地方法,而是個遠端服務器暴露出來的一個方法remoteFunc,如果我們還能像調用本地方法那樣去調用它,這樣就可以屏蔽掉一些網絡細節,用起來更方便,豈不美哉?
res?=?remoteFunc(req)
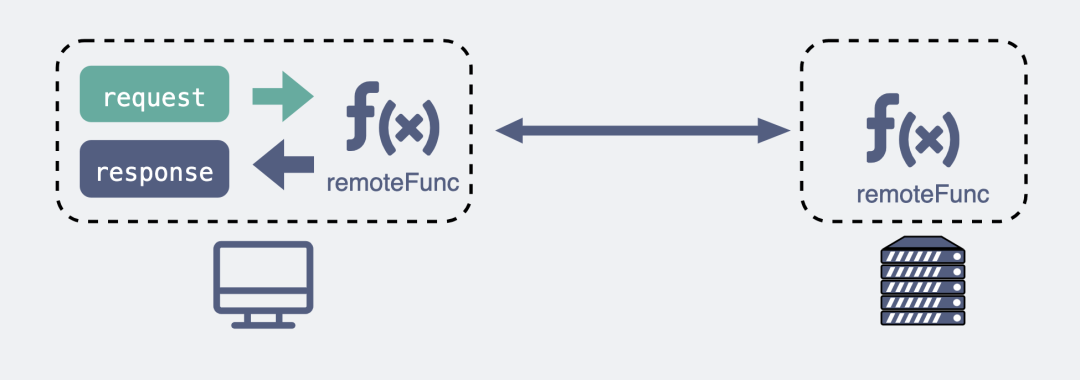
RPC可以像調用本地方法那樣調用遠端方法
基于這個思路,大佬們造出了非常多款式的RPC協議,比如比較有名的gRPC,thrift。
值得注意的是,雖然大部分RPC協議底層使用TCP,但實際上它們不一定非得使用TCP,改用UDP或者HTTP,其實也可以做到類似的功能。
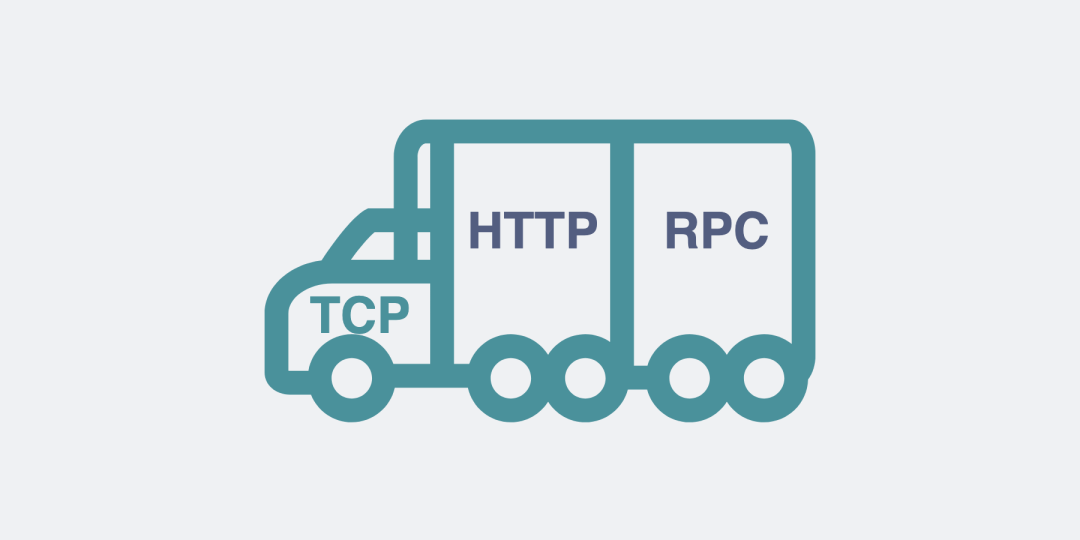
基于TCP協議的HTTP和RPC協議
到這里,我們回到文章標題的問題。
既然有HTTP協議,為什么還要有RPC?
其實,TCP是70年代出來的協議,而HTTP是90年代才開始流行的。而直接使用裸TCP會有問題,可想而知,這中間這么多年有多少自定義的協議,而這里面就有80年代出來的RPC。
所以我們該問的不是既然有HTTP協議為什么要有RPC,而是為什么有RPC還要有HTTP協議。
那既然有RPC了,為什么還要有HTTP呢?
現在電腦上裝的各種聯網軟件,比如xx管家,xx衛士,它們都作為客戶端(client)需要跟服務端(server)建立連接收發消息,此時都會用到應用層協議,在這種client/server (c/s)架構下,它們可以使用自家造的RPC協議,因為它只管連自己公司的服務器就ok了。
但有個軟件不同,瀏覽器(browser),不管是chrome還是IE,它們不僅要能訪問自家公司的服務器(server),還需要訪問其他公司的網站服務器,因此它們需要有個統一的標準,不然大家沒法交流。于是,HTTP就是那個時代用于統一 browser/server (b/s) 的協議。
也就是說在多年以前,HTTP主要用于b/s架構,而RPC更多用于c/s架構。但現在其實已經沒分那么清了,b/s和c/s在慢慢融合。很多軟件同時支持多端,比如某度云盤,既要支持網頁版,還要支持手機端和pc端,如果通信協議都用HTTP的話,那服務器只用同一套就夠了。而RPC就開始退居幕后,一般用于公司內部集群里,各個微服務之間的通訊。
那這么說的話,都用HTTP得了,還用什么RPC?
仿佛又回到了文章開頭的樣子,那這就要從它們之間的區別開始說起。
HTTP和RPC有什么區別
我們來看看RPC和HTTP區別比較明顯的幾個點。
服務發現
首先要向某個服務器發起請求,你得先建立連接,而建立連接的前提是,你得知道IP地址和端口。這個找到服務對應的IP端口的過程,其實就是服務發現。
在HTTP中,你知道服務的域名,就可以通過DNS服務去解析得到它背后的IP地址,默認80端口。
而RPC的話,就有些區別,一般會有專門的中間服務去保存服務名和IP信息,比如consul或者etcd,甚至是redis。想要訪問某個服務,就去這些中間服務去獲得IP和端口信息。由于dns也是服務發現的一種,所以也有基于dns去做服務發現的組件,比如CoreDNS。
可以看出服務發現這一塊,兩者是有些區別,但不太能分高低。
底層連接形式
以主流的HTTP1.1協議為例,其默認在建立底層TCP連接之后會一直保持這個連接(keep alive),之后的請求和響應都會復用這條連接。
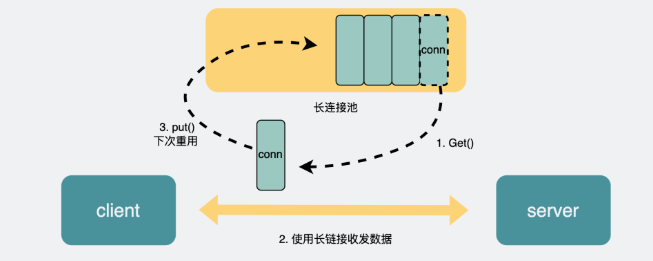
而RPC協議,也跟HTTP類似,也是通過建立TCP長鏈接進行數據交互,但不同的地方在于,RPC協議一般還會再建個連接池,在請求量大的時候,建立多條連接放在池內,要發數據的時候就從池里取一條連接出來,用完放回去,下次再復用,可以說非常環保。
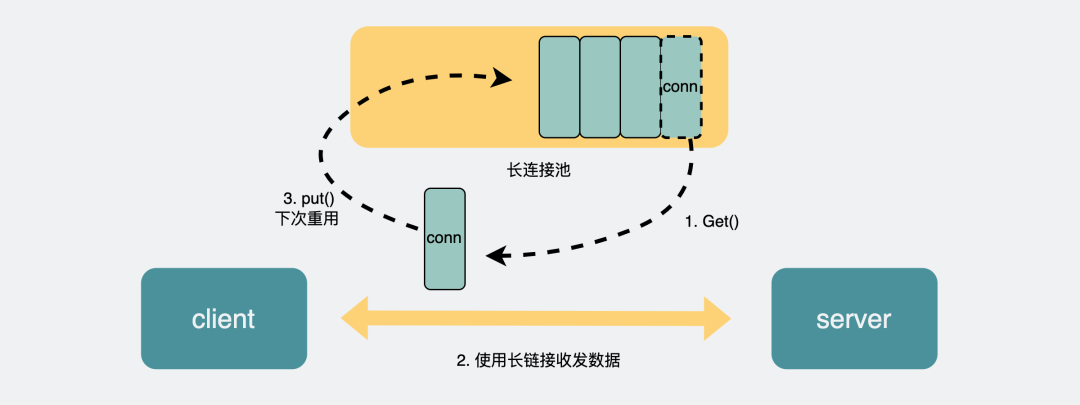
connection_pool
由于連接池有利于提升網絡請求性能,所以不少編程語言的網絡庫里都會給HTTP加個連接池,比如go就是這么干的。
可以看出這一塊兩者也沒太大區別,所以也不是關鍵。
傳輸的內容
基于TCP傳輸的消息,說到底,無非都是消息頭header和消息體body。
header是用于標記一些特殊信息,其中最重要的是消息體長度。
body則是放我們真正需要傳輸的內容,而這些內容只能是二進制01串,畢竟計算機只認識這玩意。所以TCP傳字符串和數字都問題不大,因為字符串可以轉成編碼再變成01串,而數字本身也能直接轉為二進制。但結構體呢,我們得想個辦法將它也轉為二進制01串,這樣的方案現在也有很多現成的,比如json,protobuf。
這個將結構體轉為二進制數組的過程就叫序列化,反過來將二進制數組復原成結構體的過程叫反序列化。
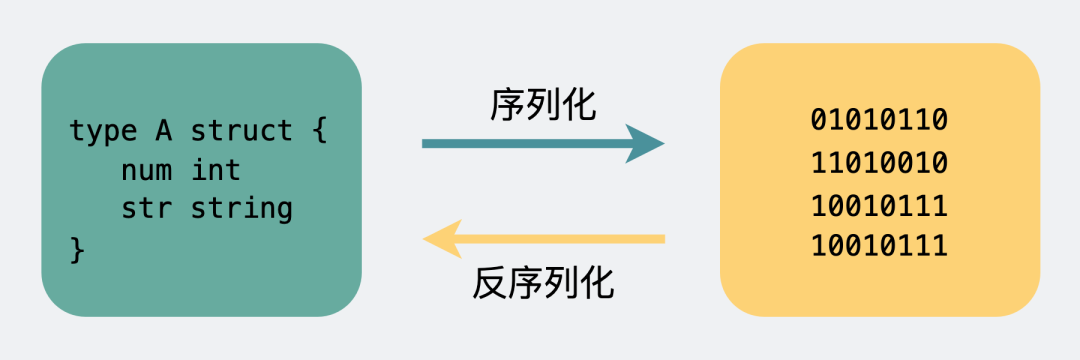
序列化和反序列化
對于主流的HTTP1.1,雖然它現在叫超文本協議,支持音頻視頻,但HTTP設計初是用于做網頁文本展示的,所以它傳的內容以字符串為主。header和body都是如此。在body這塊,它使用json來序列化結構體數據。
我們可以隨便截個圖直觀看下。
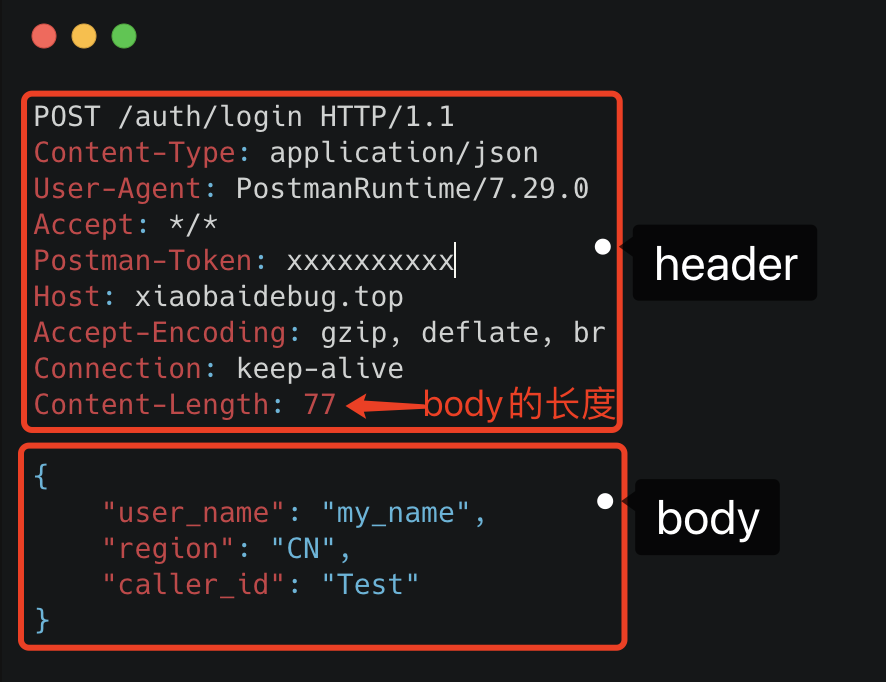
HTTP報文
可以看到這里面的內容非常多的冗余,顯得非常啰嗦。最明顯的,像header里的那些信息,其實如果我們約定好頭部的第幾位是content-type,就不需要每次都真的把"content-type"這個字段都傳過來,類似的情況其實在body的json結構里也特別明顯。
而RPC,因為它定制化程度更高,可以采用體積更小的protobuf或其他序列化協議去保存結構體數據,同時也不需要像HTTP那樣考慮各種瀏覽器行為,比如302重定向跳轉啥的。因此性能也會更好一些,這也是在公司內部微服務中拋棄HTTP,選擇使用RPC的最主要原因。
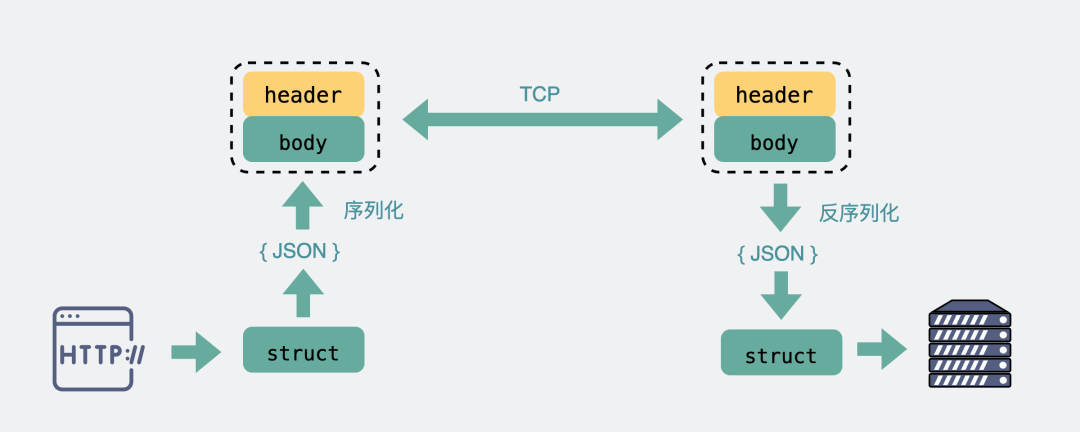
HTTP原理
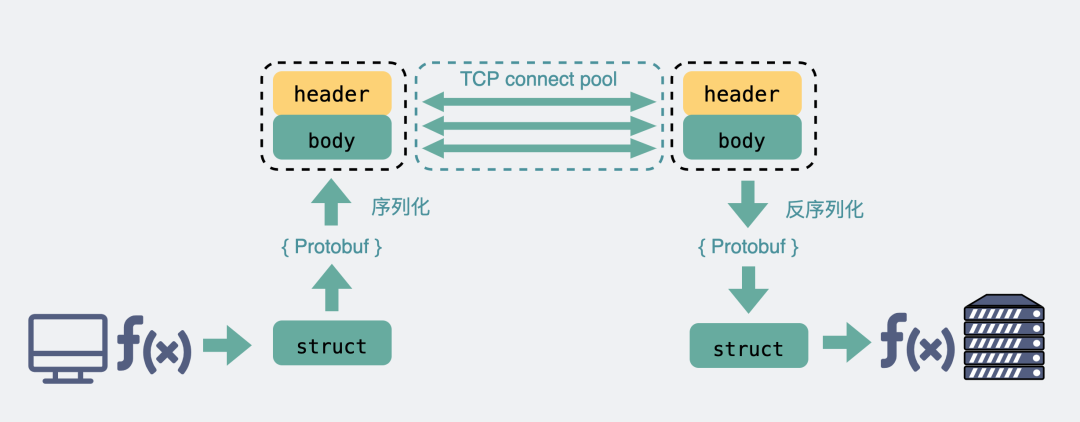
RPC原理
當然上面說的HTTP,其實特指的是現在主流使用的HTTP1.1,HTTP2在前者的基礎上做了很多改進,所以性能可能比很多RPC協議還要好,甚至連gRPC底層都直接用的HTTP2。
那么問題又來了。
為什么既然有了HTTP2,還要有RPC協議?
這個是由于HTTP2是2015年出來的。那時候很多公司內部的RPC協議都已經跑了好些年了,基于歷史原因,一般也沒必要去換了。
總結
純裸TCP是能收發數據,但它是個無邊界的數據流,上層需要定義消息格式用于定義消息邊界。于是就有了各種協議,HTTP和各類RPC協議就是在TCP之上定義的應用層協議。
RPC本質上不算是協議,而是一種調用方式,而像gRPC和thrift這樣的具體實現,才是協議,它們是實現了RPC調用的協議。目的是希望程序員能像調用本地方法那樣去調用遠端的服務方法。同時RPC有很多種實現方式,不一定非得基于TCP協議。
從發展歷史來說,HTTP主要用于b/s架構,而RPC更多用于c/s架構。但現在其實已經沒分那么清了,b/s和c/s在慢慢融合。很多軟件同時支持多端,所以對外一般用HTTP協議,而內部集群的微服務之間則采用RPC協議進行通訊。
RPC其實比HTTP出現的要早,且比目前主流的HTTP1.1性能要更好,所以大部分公司內部都還在使用RPC。
HTTP2.0在HTTP1.1的基礎上做了優化,性能可能比很多RPC協議都要好,但由于是這幾年才出來的,所以也不太可能取代掉RPC。
最后留個問題吧,大家有沒有發現,不管是HTTP還是RPC,它們都有個特點,那就是消息都是客戶端請求,服務端響應。客戶端沒問,服務端肯定就不答,這就有點僵了,但現實中肯定有需要下游主動發送消息給上游的場景,比如打個網頁游戲,站在那啥也不操作,怪也會主動攻擊我,這種情況該怎么辦呢?
審核編輯:黃飛


















 工商網監
工商網監
評論