 電子發(fā)燒友App
電子發(fā)燒友App


動機(jī)
出于學(xué)習(xí)-總結(jié)的目的,在我從什么是智能座艙、智能座艙的發(fā)展驅(qū)動因素、智能座艙的構(gòu)成要素三個方面梳理我對智能座艙的基礎(chǔ)認(rèn)識之后,為了加深“智能座艙產(chǎn)品入門”課程中語音交互部分知識的理解,我從什么是語音交互、語音交互的底層技術(shù)、智能座艙的語音交互等方面,對智能座艙語音交互系統(tǒng)相關(guān)的知識進(jìn)行了梳理與總結(jié)。
一.什么是語音交互
語音交互:語音是方式,交互的對象是任何的智能設(shè)備,顧名思義,即通過語音的方式完成人與機(jī)的交互。
在現(xiàn)今的各種智能化場景中,語音交互已成為一種非常關(guān)鍵的人機(jī)交互方式。從用戶的角度來看,語音交互的核心價值主要體現(xiàn)在釋放用戶的雙手,使得人與機(jī)之間的交互變的更高效便捷。
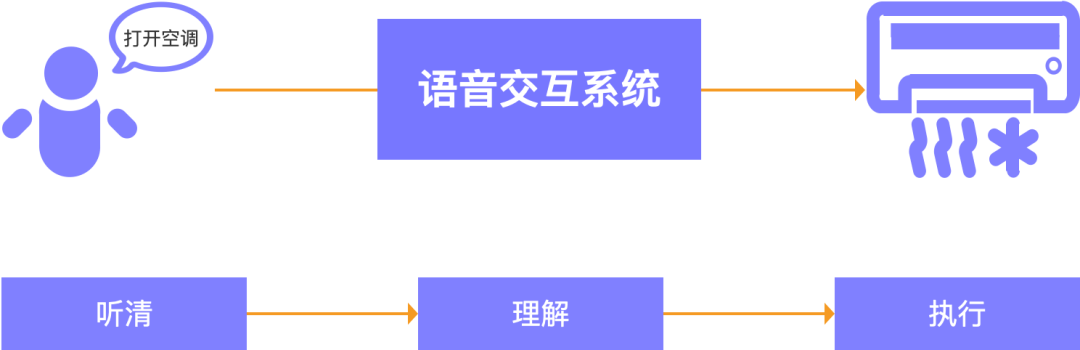
然而,從用戶發(fā)出語音指令到實(shí)現(xiàn)與智能設(shè)備的交互,其過程并不像其名詞描述的那么簡單,要實(shí)現(xiàn)通過語音來完成人機(jī)交互,要解決解決三個關(guān)鍵問題,如何讓機(jī)器聽清用戶的語音內(nèi)容?如何機(jī)器理解用戶的意圖?如何讓機(jī)器執(zhí)行用戶的意圖?,解決這些問題的的過程是復(fù)雜的,其背后涉及到多個復(fù)雜的技術(shù)環(huán)節(jié),如語音識別、自然語言理解、對話管理、自然語言生成、語音合成等。
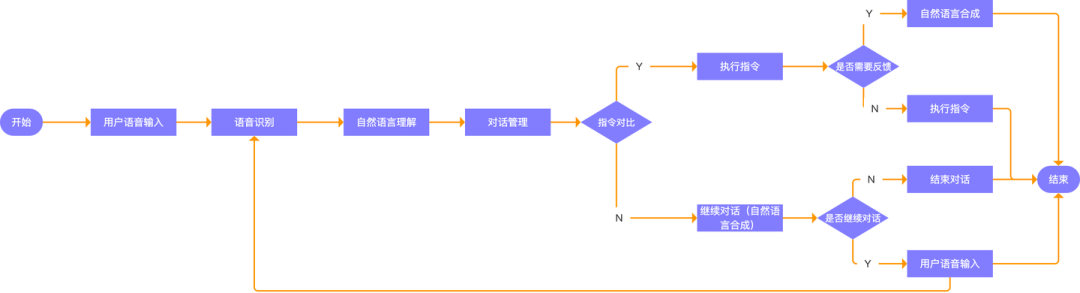
二.語音交互的底層技術(shù)
(一).語音識別
在語音交互系統(tǒng)中,用戶的語音信號需要經(jīng)過多個處理階段才能得出正確的結(jié)果,而語音識別是實(shí)現(xiàn)語音交互的第一步,其在語音交互系統(tǒng)中負(fù)責(zé)對用戶的語音信號進(jìn)行前置處理,通過對用戶語音信息的預(yù)處理、解碼等關(guān)鍵任務(wù),最終得到語音信號對應(yīng)的文本內(nèi)容,從而實(shí)現(xiàn)機(jī)器聽清的用戶的語音內(nèi)容。
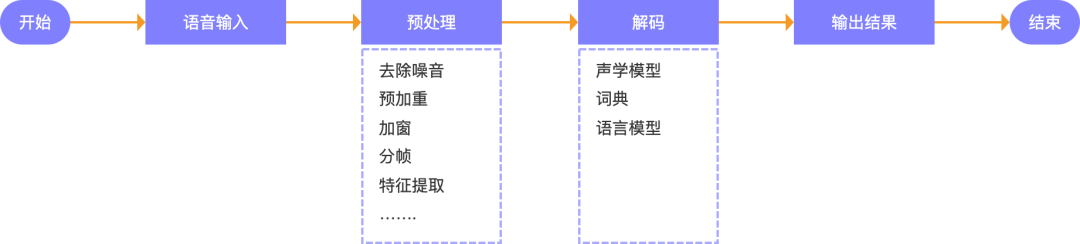
1.語音輸入:用戶通過麥克風(fēng)輸入內(nèi)容語音,例如:打開空調(diào)
?2.預(yù)處理:預(yù)處理是語音識別過程中的一個基礎(chǔ)性步驟,它的意義在于對錄音文件進(jìn)行分幀、去除噪音、語音增強(qiáng)、加窗等預(yù)處理,提取出有效的聲音特征,用于后續(xù)的語音內(nèi)容分析處理。
去除噪音:由于用戶環(huán)境因素影響,MIC設(shè)備錄制的聲音,除了人聲,可能還會包各種噪音,那么為了語音識別的準(zhǔn)確性,在識別前就需要先處理掉原始音頻中的噪音部分。去除噪音的實(shí)現(xiàn)過程大體可以理解為:首先提取原始音頻中聲音的頻率、時域、能量等特征,通過對這些特征的對比分析區(qū)分原始音頻中的人聲和其他聲音,然后通過濾波、降噪算法(基于頻域的傅里葉變換、小波變換,或者基于時域的信號平滑法)等手段,實(shí)現(xiàn)去除噪聲的目標(biāo)。
預(yù)加重:在語音輸入的過程中,由于環(huán)境和距離等影響因素,MIC錄制聲音可能會出現(xiàn)高頻衰減和低頻增益等失真現(xiàn)象,這將會影響后續(xù)語音識別的結(jié)果。?
例如:用戶的語音內(nèi)容為“apple”,由于高頻信號被衰減掉,錄制的聲音中可能只留下了“p”和“l(fā)”的較強(qiáng)信號,這將導(dǎo)致語音識別系統(tǒng)誤認(rèn)為說的是“pl”而不是“apple”。?針對這種現(xiàn)象,預(yù)加重通過加強(qiáng)高頻成分的能量和減少低頻成分的能量,讓不同頻率的音頻信號能夠在信號處理過程中均衡化,從而提高語音識別的準(zhǔn)確性。
為了更形象的理解“預(yù)加重”,可以將其類比于在圖像中的“銳化”,使得邊緣更為清晰。
分幀:原始語音信號是一個連續(xù)的波形,是一種時間和頻率上都變化較快的信號,在語音識別的過程中,如直接對連續(xù)且長的語音進(jìn)行計算處理,會增加計算的難度降低識別的準(zhǔn)確性。因此,為了提高語言識別結(jié)果的準(zhǔn)備性,需要將連續(xù)且長的語音信號分為若干個固定長度的幀,分幀后每幀內(nèi)的信號的頻譜變化就會較為緩慢、穩(wěn)定。
例如:以“打開空調(diào)”為例,假設(shè)錄制的語音時長為2秒,采樣率為16000Hz,那么原始語音信號就是一個長度為32000的一維向量,如果直接對這個聲音信息進(jìn)行語音識別,計算量會非常大,而且由于語音信號的頻率和幅度變化非常快,很難進(jìn)行有效的特征提取。
特征提取:完成去噪、預(yù)加重、分幀等前端處理后的語音信號,不能直接用于識別,還需要將其變換到頻域,然后利用線性預(yù)測倒譜系數(shù)(LPCC)和 Mel 倒譜系數(shù)(MFCC)等方法,從語音信號中提取用來描述語音信號的各種特征,以便識別模型能夠更好地對其進(jìn)行分析和區(qū)分,這些特征包括:幀能量、音調(diào)(調(diào)子、語氣等)、基音頻率、音周期、共振峰、諧波結(jié)構(gòu)、聲道特性等。
為了更加形象的理解“特征提取”,可以將其類比為制作抖音電影解說短視頻,在制作的過程中,你需要從完整的電影中篩選出最精彩、最有代表性的片段,需要對整部電影進(jìn)行剪輯,然后把這些片段組成一部短視頻,以便于快速地展現(xiàn)電影的精華和主題。
其他:原始音頻的預(yù)處理,除了去除噪音、預(yù)加重、分幀,還有加窗、語音信號能量歸一化、頻率濾波、動態(tài)特征等,具體可以參考專業(yè)資料。
3.解碼:在完成原始音頻信號的預(yù)處理與特征提取之后,需要將提取到的特征輸入語音識別模型中通過聲學(xué)模型、詞典、語音模型的協(xié)同計算來得到最終的識別結(jié)果。
聲學(xué)模型:聲學(xué)模型負(fù)責(zé)對語音信號進(jìn)行特征提取和處理,生成一系列特征向量,然后使用這些特征向量來計算每個可能的音素的得分,并根據(jù)得分選出最可能的音素序列。
詞典:在生活中,我們有認(rèn)識的字的時候,可能會通過網(wǎng)絡(luò)搜索或查字典的方式去尋找答案。在語音識別系統(tǒng)中,也有需要一個詞典,用于識別音素對應(yīng)的漢字(詞)或者單詞。語音識別系統(tǒng)中的詞典包括了一系列的詞語和它們對應(yīng)的音素序列,這些音素序列反映了詞語在語音信號中的語音學(xué)特征和發(fā)音方式,通過將語音信號的實(shí)際發(fā)音與詞典中存儲的發(fā)音進(jìn)行匹配,語音識別系統(tǒng)可以推算出說話人所說的詞語。
語言模型:在通過聲學(xué)模型與詞典,得到一組候選詞語或句子的情況下,最后需要通過語言模型得到符合用戶表達(dá)內(nèi)容的結(jié)果。語音模型的作用就是通過統(tǒng)計文本中詞與詞之間的關(guān)系和概率,預(yù)測一個詞語或句子出現(xiàn)的概率大小,從而對識別出的多個文本候選結(jié)果進(jìn)行打分、排序和篩選,最終,得分最高的結(jié)果就是系統(tǒng)認(rèn)為最符合用戶表達(dá)內(nèi)容的結(jié)果。
舉個例子,如果用戶說的是“我想要一杯咖啡”,在語音識別的過程中,可能會產(chǎn)生如下多個候選句子:我向要一杯咖啡我想要一輩咖啡我想要一杯可菲我向要一杯咖啡色菲語言模型通過預(yù)測每個識別候選結(jié)果的概率大小,就可以計算出每個候選結(jié)果的得分,從而篩選出最符合用戶表達(dá)內(nèi)容的最終結(jié)果,“我想要一杯咖啡”。?
4.輸出結(jié)果:指最終輸出識別結(jié)果,即轉(zhuǎn)換后的文本或指令等形式的結(jié)果。
(二)自然語言處理
1.自然語言理解
在完成用于語音內(nèi)容的識別之后,要讓設(shè)備能順利執(zhí)行用戶的意圖,還需要自然語言處理(NLP)算法模型對計算機(jī)可識別的文本進(jìn)行分析和處理,以理解用戶語言的含義和意圖,并根據(jù)需要進(jìn)行相應(yīng)的回答或操作,一般情況下,NLP算法模型對文本的處理過程包括 包括詞法分析、句法分析、語義分析等多個環(huán)節(jié)。

預(yù)處理:為了降低文本處理的復(fù)雜度,提高算法的精度和效率,文本本輸入自然語言理解模型前,需要先進(jìn)行預(yù)處理,如去掉句子中的特殊字符、停用詞、將所有字母變成小寫等。?
例如:停用詞是指一些在自然語言中使用比較頻繁但實(shí)際上并不具有實(shí)際含義,對于句子的語義理解貢獻(xiàn)較小的一些詞語,比如一些代詞、介詞、連詞等等(如“的”、“和”、“就”、“在”、“用”等),這些停用詞雖然常常出現(xiàn)在文本中,但是對于計算機(jī)理解句子的真實(shí)含義并沒有太大幫助,只會增加文本處理的復(fù)雜度,降低算法的精度和效率。
分詞:自然語言理解模型,在理解在自然語言文本時,不是整句直接分析的,而時通過對自然語言文本的每個組成部分(如單詞、短語等)的含義進(jìn)行深入的分析和理解,進(jìn)而確定整個文本的含義。因此,在對文本進(jìn)行預(yù)處理之后,需要對文本進(jìn)行分詞操作,將文本按照一定的規(guī)則切分成一個個詞語,它的目的是將文本轉(zhuǎn)化為計算機(jī)可以處理的離散的詞語序列。舉個例子:以“導(dǎo)航去寶安機(jī)場”為例,通過分詞,可以得到以下詞語序列:導(dǎo)航 / 去 / 寶安機(jī)場。
詞性標(biāo)注:對每個詞語進(jìn)行詞性標(biāo)注,即確定每個詞語在句子中的詞性,通過對每個詞語進(jìn)行詞性標(biāo)注,可以確定詞在句子中的語法角色和含義,從而更準(zhǔn)確地進(jìn)行語義分析、句法分析等任務(wù)。常見的詞性包括名詞、動詞、形容詞、副詞、介詞、連詞、代詞、數(shù)詞、量詞、助詞、嘆詞等。?
?舉個例子:以”導(dǎo)航去寶安機(jī)場“為例,”導(dǎo)航”:名詞、“去”:動詞,“寶安”:名詞,“機(jī)場”:名詞,通過這樣的詞性標(biāo)注,可以分析出“導(dǎo)航”為主語,“去”為動詞,表示導(dǎo)航的動作,“寶安”、“機(jī)場”由于都是名詞,可以確定它們是導(dǎo)航的目的地。
實(shí)體識別:指從文本中識別特定實(shí)體,例如如人名、地名、組織機(jī)構(gòu)名等,通過實(shí)體識別,計算機(jī)可以更準(zhǔn)確地理解文本中的內(nèi)容。
?舉個例子:以”導(dǎo)航去寶安機(jī)場“為例,實(shí)體識別可以識別出“寶安機(jī)場”是一個地名實(shí)體,通過這一步得到的結(jié)果,計算機(jī)可以更好地理解用戶的意圖。
句法分析:對句子的語法結(jié)構(gòu)進(jìn)行分析,確定句子中各個詞語之間的關(guān)系,其意義在于理清句子中的語法結(jié)構(gòu)和詞語關(guān)系以便于計算機(jī)進(jìn)一步理解語音交互中的用戶意圖。舉個例子:以“導(dǎo)航去寶安機(jī)場”為例,句法分析可以將這個句子分析為“導(dǎo)航 去 寶安機(jī)場”,從中獲取到“導(dǎo)航”是動作, “去”是一個方向,“寶安機(jī)場”是具體的地點(diǎn)信息,這些信息對于計算機(jī)進(jìn)行后續(xù)處理是非常重要的。
語義分析:在完成預(yù)處理、分詞、詞性標(biāo)注、實(shí)體識別、句法分析等前置任務(wù)之后,接下來就需要進(jìn)行最后的語義分析,例如:情感分析、主體提取、語義聯(lián)想、語義角色標(biāo)注、槽位信息等,其主要意義是更全面地理解用戶輸入的意圖,幫助計算機(jī)能夠更好地理解用戶輸入的內(nèi)容,從而根據(jù)用戶意圖執(zhí)行相應(yīng)的操作。
舉個例子:以“導(dǎo)航去寶安機(jī)場”為例,經(jīng)過語義分析后,計算機(jī)可以清晰地理解用戶的意圖,即需要進(jìn)行導(dǎo)航操作,并且目的地是寶安機(jī)場。
結(jié)果輸出:將經(jīng)過預(yù)處理、分詞、詞性標(biāo)注、實(shí)體識別、句法分析、語義分析處理后的結(jié)果,按結(jié)構(gòu)輸出給自然語言處理中的對話管理模塊,進(jìn)行進(jìn)一步處理。舉個例子:以“導(dǎo)航去寶安機(jī)場”為例,自然語言理解最終輸出的結(jié)果為“動作-導(dǎo)航,目的地-寶安機(jī)場,起點(diǎn)-當(dāng)前位置。”
2.對話管理
在自然語言理解對語音識別的文本進(jìn)行分析處理之后,需要對話管理系統(tǒng)進(jìn)行意圖識別,確定用戶想要做什么,并且根據(jù)所處的對話狀態(tài)進(jìn)行狀態(tài)跟蹤,決定下一步需要執(zhí)行的操作或回復(fù)用戶的方式,這個過程包括根據(jù)用戶輸入的信息選擇相應(yīng)的策略、控制多輪對話流程、解決歧義等。對話管理系統(tǒng)是基于一個預(yù)先定義好的對話模型工作,對話模型中定義了對話流程、對話狀態(tài)、對話策略等,在對話管理過程中,系統(tǒng)會使用這個對話模型來處理用戶的請求。
意圖識別:在通過自然語言理解對文本的分析處理,得到用戶意圖的關(guān)鍵詞之后,對話管理系統(tǒng)負(fù)責(zé)將用戶意圖的關(guān)鍵詞與預(yù)設(shè)的意圖庫(或指令庫)進(jìn)行對比來確定用戶的意圖,并進(jìn)一步?jīng)Q定下一步的操作。舉個例子:以“打開空調(diào)”為例,語音助手接收到語音信號后,會先進(jìn)行語音識別,將語音信號轉(zhuǎn)化為文本,然后,自然語言理解系統(tǒng)會對轉(zhuǎn)化后的文本進(jìn)行解析,提取其中的關(guān)鍵詞和語義信息,比如“打開空調(diào)”,理解用戶的意圖,接下來,對話管理系統(tǒng)會根據(jù)用戶的意圖進(jìn)行響應(yīng)。
?
對話狀態(tài)跟蹤:指的是記錄和維護(hù)整個對話過程中的各個狀態(tài)信息,以便在后續(xù)的對話中進(jìn)行參考、分析和處理,狀態(tài)信息包括上下文、用戶意圖、技能選擇等等。
舉個例子:當(dāng)用戶詢問“今天下雨嗎?”,對話管理系統(tǒng)可以通過狀態(tài)跟蹤,結(jié)合當(dāng)前的用戶意圖和上下文信息,快速準(zhǔn)確地回答用戶問題。
3.自然語言生成
在語音交互系統(tǒng)中,當(dāng)對話管理系統(tǒng)確定要繼續(xù)與用戶對話或反饋執(zhí)行結(jié)果的時候,此時需要自然語言生成模塊根據(jù)對話管理系統(tǒng)的指令,從相關(guān)的知識庫或語料庫中提取信息,以及根據(jù)語境和上下文信息,將結(jié)構(gòu)化數(shù)據(jù)轉(zhuǎn)化為自然、邏輯連貫的文本,以人類語言回答用戶的問題、提供建議或執(zhí)行任務(wù),其生成自然語言的過程一般包括:句法分析、語義分析、語法分析、信息抽取、輸出文本等步驟。
舉個例子,當(dāng)用戶詢問“明天的天氣如何?”時,自然語言生成模塊可能會根據(jù)當(dāng)前的時間和位置信息,生成類似于“明天的天氣為晴天,最高氣溫27℃,最低氣溫18℃”的文本回復(fù)內(nèi)容。
(三).語音合成
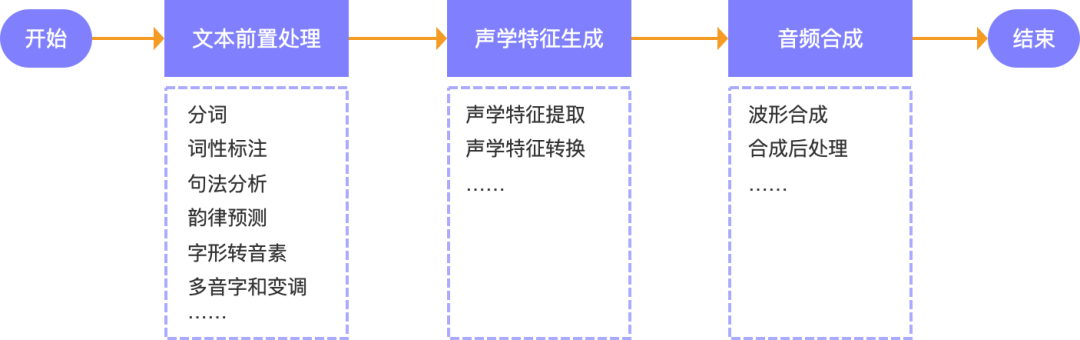
在通過語音識別、自然語言理解、對話管理、自然語言生成對用戶的語音信息進(jìn)行分析處理之后,最后想要機(jī)器開口與人交流,則需要語音合成系統(tǒng)將自然語言文本轉(zhuǎn)化為語音并通過輸出設(shè)備輸出給用戶。
語音合成系統(tǒng)既是語音交互的終點(diǎn)也是起點(diǎn),是語音交互系統(tǒng)的的重要底層技術(shù)之一,它基于語言模型、聲學(xué)模型、音頻處理等技術(shù),通過文本前置處理、聲學(xué)特征生成和音頻合成等關(guān)鍵步驟,將自然語言文本合成為高質(zhì)量、自然流暢的人類語音。
1.文本前置處理:在計算機(jī)獲得一段文本之后,要讓計算機(jī)像人類一樣開口講這段文本講出來,首先需要讓機(jī)器知道文本中字、詞如何發(fā)音和文本要表達(dá)的意思與文本里蘊(yùn)含的情緒。因此,在語音合成系統(tǒng)中,第一個關(guān)鍵任務(wù)對文本的前置處理,具體包括:分詞、詞性標(biāo)注、句法分析、韻律預(yù)測、字形轉(zhuǎn)音素、對音字與變調(diào)分析等。舉個例子:舉個例子,比如輸入一段文本:“明天下雨,出門記得帶傘。”在文本前置處理的過程中,可能需要經(jīng)過分詞、音素標(biāo)注和添加天氣標(biāo)簽的處理,變成:“明天/t 下雨/v ,出門/v 記得/v 帶/v 傘/n ,天氣/t 標(biāo)簽/rainy。”
2.聲學(xué)特征生成:要想讓機(jī)器像人類一樣將自然語言文本內(nèi)容有韻律、頓挫、情感地說出來,就需要讓機(jī)器知道自然語言文本中每個音素的聲學(xué)特征,包括基頻、時長、頻譜形態(tài)等,這些聲學(xué)特征是語音信號的特征,用于描述和控制語音信號的音色、音高、節(jié)奏等方面。因此,在完成文本預(yù)處理后,要將自然語言文本內(nèi)容合成為最近人類表達(dá)的語音內(nèi)容,就需要先將自然語言文本轉(zhuǎn)換成發(fā)音單元(音素),然后利用特定的算法將音素序列轉(zhuǎn)化為對應(yīng)的聲學(xué)特征。
3.音頻合成:這一步是將前面處理好的聲學(xué)特征和文本信息進(jìn)行結(jié)合,最終合成音頻文件,作為語音合成系統(tǒng)的輸出。具體來說,關(guān)鍵任務(wù)包括:波形合成、合成后處理等。
小結(jié):以上我從產(chǎn)品的視角,基于課程內(nèi)容、專業(yè)資料結(jié)合自身的理解,梳理的我對語音交互系統(tǒng)底層關(guān)鍵技術(shù)的理解,目的不在于學(xué)習(xí)語言交互相關(guān)的具體技術(shù)知識,而是知其大概原理。如存在歧義,歡迎交流,并建議參考相關(guān)的專業(yè)書籍與資料。
三.智能座艙的語音交互
(一).語音交互對智能座艙的意義
在傳統(tǒng)的汽車座艙內(nèi),存在著大量的傳統(tǒng)機(jī)械和電子設(shè)備,駕乘人員在執(zhí)行駕駛?cè)蝿?wù)或使用汽車功能時,需要不斷地操作各種控制器和按鈕,以控制車輛的速度、方向、功能等,這些操作可能同時占用駕乘人員的雙手、手眼、雙腳,不僅繁瑣和復(fù)雜,還容易導(dǎo)致駕駛疲勞和注意力不集中,從而增加駕駛安全的風(fēng)險。
因此,為了提高汽車駕駛的安全性和舒適性,語音交互系統(tǒng)被應(yīng)用在汽車智能座艙中。語音交互系統(tǒng)通過語音交互的方式來代替部分駕駛操作,從而可以讓駕乘人員的雙手、手眼、雙腳更多地用于安全駕駛和應(yīng)急操作。例如,駕乘人員可以使用語音指令來操控空調(diào)、導(dǎo)航系統(tǒng)、音樂播放器等,而不需要手動操作控制面板,減少了駕駛員的分心和疲勞,在一定程度上提高了駕駛安全性和方便性。
從消費(fèi)者的角度來看,語音交互系統(tǒng)不僅可以通過被動的接收用戶的指令,幫用戶高效地完成人與車交互,而且可以為通過主動式的交互為用戶帶來更智能化、情感化的人車交互體驗(yàn)。在當(dāng)前“人機(jī)共駕”階段,語音交互是座艙內(nèi)最直接、最人性化、最完全的交互方式。
從廠商的角度來看,由于語音交互系統(tǒng)具備較大個性化、自定義空間,廠商可以基于結(jié)合品牌定位與用戶需求,為用戶打造具有差異化特征語言交互系統(tǒng),在品牌差異化發(fā)展中發(fā)揮著重要的作用。另外,基于用戶的個性化需求,在基礎(chǔ)語音服務(wù)的基礎(chǔ)上衍生除很多付費(fèi)服務(wù)場景,例如,在samrt精靈1號上,付費(fèi)的語音助手形象,付費(fèi)的音助手裝扮。
(二).智能座艙語音交互場景

基于用戶、場景、需求,以語音交互系統(tǒng)為起點(diǎn),我們可以將智能座艙語音交互的場景抽象的分為主動交互場景和被動交互場景。
1.被動交互場景:當(dāng)我們在討論“人機(jī)交互”時,大部分情況討論的是“被動式交互”,它的實(shí)現(xiàn)邏輯很簡單,即由人給機(jī)器發(fā)號施令,機(jī)器執(zhí)行并輸出結(jié)果反饋給人。如,傳統(tǒng)的被動式語音交互,是由用戶主動向機(jī)器輸入語音指令,然后由機(jī)器對用戶的音指令進(jìn)行分析、處里并執(zhí)行,以實(shí)現(xiàn)特定的功能,其能為用戶提供的最大價值僅僅是“君子動口不動手”。? ?
在人與車的交互場景中,被動式的語音交互,僅能實(shí)現(xiàn)的是“不動手”地去實(shí)現(xiàn)車身功能、信息娛樂的功能的控制。這種被動式的交互,在某些情況下還是會分散用戶的注意力,從而造成安全隱患,例如:用戶在發(fā)起語言指令的時候,視線和注意力可能會從駕駛?cè)蝿?wù)上轉(zhuǎn)移。
2.主動交互場景:不同于被動式交互,主動式交互以機(jī)器為起點(diǎn),機(jī)器可以自己主動地輸入信息,主動輸出執(zhí)行結(jié)果或建議給用戶。
在人與車的交互場景中,語音交互系統(tǒng)可以與其他模態(tài)交互融合,基于人、車狀態(tài)和內(nèi)外部環(huán)境,通過傳感器、攝像頭等設(shè)備主動輸入信息進(jìn)行決策判斷,為用戶提供主動的服務(wù),例如:主動關(guān)懷服務(wù)、提醒服務(wù)、推薦服務(wù)等,主動式的語音交互,在一步提高人車交互效率的同時,還可以為用戶提供更加智能化、情感化的人交互體驗(yàn)。
(三).智能座艙語音交互系統(tǒng)基礎(chǔ)框架

智能座艙的語音交互系統(tǒng)是一個高度復(fù)雜的綜合系統(tǒng),它不僅需要精密的硬件與軟件協(xié)同配合,同時需要專業(yè)的運(yùn)營管理來保障其可靠性和穩(wěn)定性。總的來看,整個系統(tǒng)可以分為硬件層、服務(wù)層、應(yīng)用層和運(yùn)營管理平臺四個組成部分。
1.硬件層:在語音交互系統(tǒng)中,硬件層是智能座艙語音交互系統(tǒng)的物理基礎(chǔ),關(guān)鍵的硬件設(shè)備包括輸入/輸出設(shè)備和音頻處理芯片,其中輸入/輸出設(shè)備負(fù)責(zé)采集用戶的語音指令和反饋信息,主要包括:麥克風(fēng)陣列、揚(yáng)聲器、攝像頭、傳感器、燈光等,芯片部分主要負(fù)責(zé)音頻信號的處理與分析,主要包括數(shù)字信號處理器(DSP)、音頻解碼器、音頻放大器等。
2.服務(wù)層:服務(wù)層是智能座艙語音交互系統(tǒng)的核心,它承擔(dān)著語音、圖像等信息的處理和解析,并提供必要反饋和響應(yīng)的重要任務(wù)。主要包括自然語言處理(NLP)引擎、語音識別引擎、語音合成引擎、聲紋識別、云端服務(wù)、API服務(wù)、業(yè)務(wù)邏輯處理服務(wù)等模塊。
3.應(yīng)用層:應(yīng)用層是指基于服務(wù)層提供的核心能力與用戶的實(shí)際需求相結(jié)合,為用戶提供的具體應(yīng)用程序,以幫助用戶通過語音交互實(shí)現(xiàn)具體的功能控制。例如,車身控制模塊中的空調(diào)控制、座椅控制、車窗控制等應(yīng)用,以及信息娛樂模塊中娛樂、通訊、導(dǎo)航等應(yīng)用。
4.運(yùn)營管理平臺:用戶在使用語音交互系統(tǒng)的過程中,會產(chǎn)生大量的用戶行為數(shù)據(jù)與音頻、文本、圖像數(shù)據(jù),運(yùn)營管理平臺通過對這些數(shù)據(jù)的統(tǒng)計分析,為語音交互系統(tǒng)與各種AI模型的持續(xù)優(yōu)化提供數(shù)據(jù)支持。從業(yè)務(wù)角度分類,運(yùn)營管理平臺主要分為兩大核心模塊:用戶數(shù)據(jù)統(tǒng)計分析和模型數(shù)據(jù)運(yùn)營。
用戶數(shù)據(jù)統(tǒng)計分析模塊,可以對實(shí)車用戶使用語音交互系統(tǒng)的行為數(shù)據(jù)進(jìn)行統(tǒng)計和分析,從而生成不同維度、不同粒度的分析報表。這些報表可以幫助我們深入了解用戶使用習(xí)慣和偏好,及時發(fā)現(xiàn)并解決系統(tǒng)存在的問題,為語音交互系統(tǒng)的優(yōu)化提供數(shù)據(jù)依據(jù)。
模型數(shù)據(jù)運(yùn)營模塊,可以通過對用戶在使用語音交互系統(tǒng)過程中產(chǎn)生的大量音頻、文本、圖像數(shù)據(jù)的定期回收與采集、標(biāo)注,生產(chǎn)出各個AI模型需要的數(shù)據(jù),為模型訓(xùn)練提供數(shù)據(jù)支持。
編輯:黃飛
?


















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論