 電子發燒友App
電子發燒友App


在本文中,我們將展示如何使用 TinyML 和 Edge Impulse 為 Arduino Nano BLE Sense 構建咳嗽檢測系統。
這篇文章主要講述如何使用Edge Impulse在 Arduino Nano BLE Sense 上進行機器學習,以檢測實時音頻中是否存在咳嗽。我們構建了咳嗽和背景噪聲樣本的數據集,并應用了高度優化的 TInyML 模型,構建了一個咳嗽檢測系統,該系統在 Nano BLE Sense 上 20 kB 的 RAM 中實時運行。同樣的方法適用于許多其他嵌入式音頻模式匹配應用,例如老年人護理、安全和機器監控。該項目和數據集最初由 Kartik Thakore 啟動,以幫助 COVID-19 工作。
前提
要想完成該項目,首先有以下要求:
對軟件開發和Arduino的基本了解
安裝 Arduino IDE 或 CLI
帶麥克風的Arduino Nano BLE Sense或等效 Cortex-M4+ 板(可選)
我們將使用 Edge Impulse,一個在邊緣設備上進行機器學習的在線開發平臺。你需要先注冊創建一個免費帳戶。登錄您的帳戶,并通過單擊標題為您的新項目命名。我們稱之為“Arduino Cough Tutorial”。
收集數據集
任何機器學習項目的第一步都是收集一個數據集,該數據集代表我們希望能夠在我們的 Arduino 設備上匹配的已知數據樣本。首先,我們創建了一個包含 10 分鐘音頻的小型數據集,分為“咳嗽”和“噪音”兩個類別。我們將展示如何將此數據集導入您的 Edge Impulse 項目,添加您自己的樣本,甚至從頭開始您自己的數據集。該數據集很小,并且具有有限數量的咳嗽和軟背景噪聲樣本。因此,該數據集僅適用于實驗,本教程中生成的模型只能區分安靜的背景噪音和小范圍的咳嗽。我們鼓勵您使用更廣泛的咳嗽、背景噪音和其他類別(如人類語音)來擴展數據集,以提高性能。
注意:強迫自己咳嗽對聲帶的傷害很大,收集數據和測試時要小心!
首先下載我們的咳嗽數據集并在您的 PC 上您選擇的位置提取文件:https ://cdn.edgeimpulse.com/datasets/cough.zip
您可以使用Edge Impulse CLI Uploader將此數據集導入您的 Edge Impulse 項目。按照這些安裝說明安裝 Edge Impulse CLI。
打開終端或命令提示符,然后導航到您提取文件的文件夾。
運行:
$ edge-impulse-uploader --clean
$ edge-impulse-uploader --category training training/*
$ edge-impulse-uploader --category testing testing/*
系統將提示您輸入 Edge Impulse 用戶名、密碼和要添加數據集的項目。數據集樣本現在將在數據采集頁面上可見。通過單擊示例,我們可以看到示例的外觀,并通過單擊每個圖表下方的播放按鈕來收聽音頻。
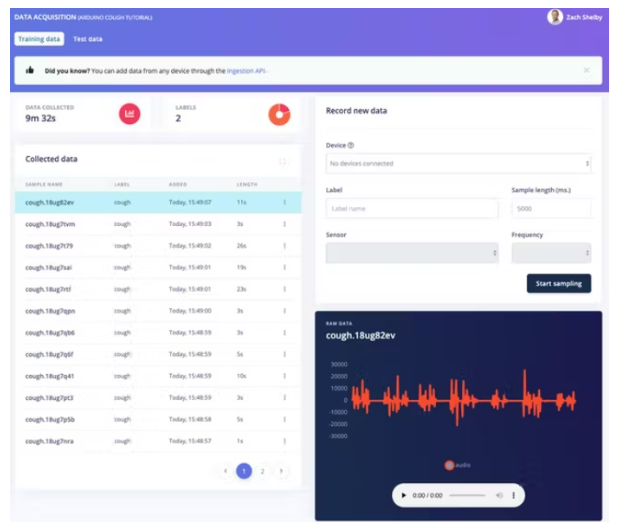
10 分鐘的咳嗽和噪音數據樣本足以開始。您可以選擇使用自己的咳嗽和背景噪聲樣本擴展數據集。我們可以從數據采集頁面直接從設備收集新的數據樣本。WAV 格式的音頻樣本也可以使用Edge Impulse CLI Uploader 上傳。
重要提示:現實世界應用程序中使用的模型應使用盡可能多樣化的數據集進行訓練和測試。這個初始數據集相對較小,因此當暴露于不同類型的背景噪音或來自不同人的咳嗽時,模型的表現會不一致。
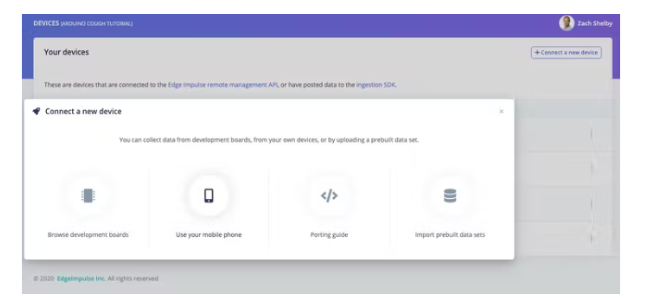
最簡單的入門方法是使用手機收集音頻數據。轉到“設備”頁面,然后單擊右上角的“+ 連接新設備”按鈕。選擇“使用您的手機”。這將生成一個唯一的 QR 碼,以在您的手機瀏覽器上打開一個 Web 應用程序。對二維碼拍照,然后選擇打開鏈接。
Web 應用程序將連接到您的 Edge Impulse 項目,應該如下所示:
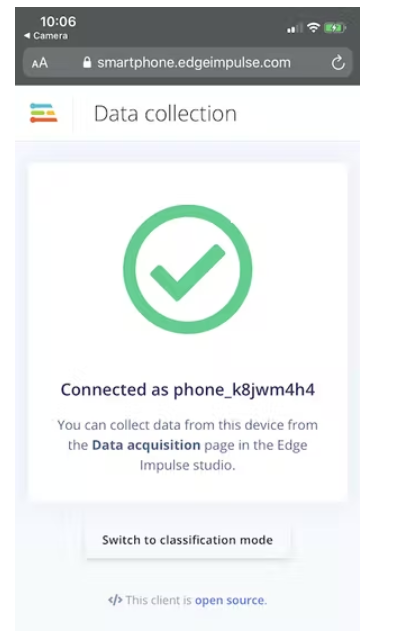
我們現在可以從Edge Impulse的數據采集頁面直接從手機中收集音頻數據樣本。在“記錄新數據”部分,輸入“咳嗽”或“噪音”標簽,確保選擇“麥克風”作為傳感器,然后單擊“開始采樣”。您的手機現在將收集音頻樣本,并將其添加到您的數據集中。

還支持直接從 Nano BLE Sense 板收集音頻數據。按照這些說明安裝 Edge Impulse 固件和守護程序。一旦設備連接到 Edge Impulse,您就可以像上面的手機一樣收集數據樣本。

創造你的脈沖
接下來,我們將在創建脈沖頁面上選擇信號處理和機器學習模塊。脈沖將從空白開始,帶有原始數據和輸出特征塊。保留 1000 ms 窗口大小和 500 ms 窗口增加的默認設置。這意味著我們的音頻數據將一次處理 1 秒,每 0.5 秒開始。使用小窗口可以節省嵌入式設備上的內存,但這意味著我們需要在兩次咳嗽之間沒有大間隔的咳嗽數據樣本。
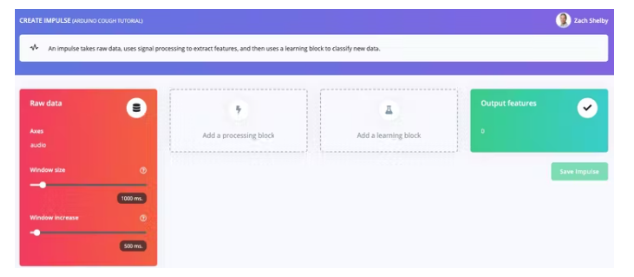
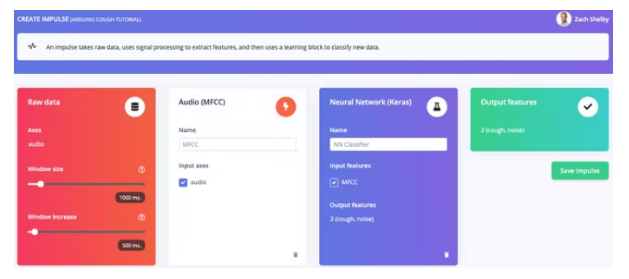
單擊“添加處理塊”并選擇音頻 (MFCC)塊。接下來單擊“添加學習塊”并選擇神經網絡 (Keras)塊。點擊“保存沖動”。音頻塊將為每個音頻窗口提取頻譜圖,神經網絡塊將被訓練以根據我們的訓練數據集將頻譜圖分類為“咳嗽”或“噪音”。您產生的脈沖將如下所示:
接下來,我們將從MFCC頁面上的訓練數據集生成特征。此頁面顯示從任何數據集樣本中提取的每 1 秒窗口的頻譜圖的樣子。我們可以將參數保留為默認值。
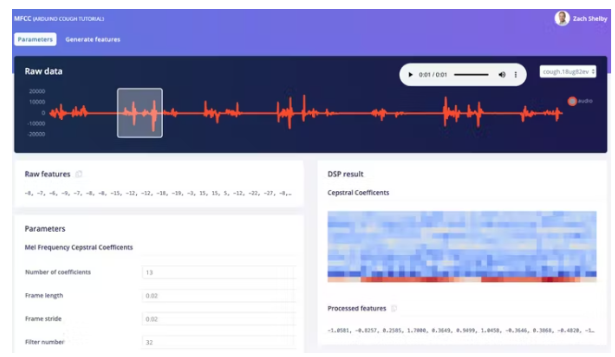
接下來單擊“生成特征”按鈕,然后使用此處理塊處理整個訓練數據集。這將創建完整的特征集,用于在下一步訓練我們的神經網絡。按“生成特征”按鈕開始處理,這需要幾分鐘才能完成。

我們現在可以在 NN 分類器頁面上繼續設置和訓練我們的神經網絡。默認神經網絡適用于流水等連續聲音。咳嗽檢測更復雜,因此我們將在每個窗口的頻譜圖上使用 2D 卷積配置更豐富的網絡。2D 卷積以與圖像分類類似的方式處理音頻頻譜圖。按“神經網絡設置”部分的右上角,然后選擇“切換到 Keras(專家)模式”。

將“神經網絡架構”定義替換為以下代碼,并將“最小置信度”設置為“0.70”。然后繼續單擊“開始培訓”按鈕。訓練將需要幾秒鐘。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, InputLayer, Dropout, Flatten, Reshape, BatchNormalization, Conv2D, MaxPooling2D, AveragePooling2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.constraints import MaxNorm
# model architecture
model = Sequential()
model.add(InputLayer(input_shape=(X_train.shape[1], ), name='x_input'))
model.add(Reshape((int(X_train.shape[1] / 13), 13, 1), input_shape=(X_train.shape[1], )))
model.add(Conv2D(10, kernel_size=5, activation='relu', padding='same', kernel_constraint=MaxNorm(3)))
model.add(AveragePooling2D(pool_size=2, padding='same'))
model.add(Conv2D(5, kernel_size=5, activation='relu', padding='same', kernel_constraint=MaxNorm(3)))
model.add(AveragePooling2D(pool_size=2, padding='same'))
model.add(Flatten())
model.add(Dense(classes, activation='softmax', name='y_pred', kernel_constraint=MaxNorm(3)))
# this controls the learning rate
opt = Adam(lr=0.005, beta_1=0.9, beta_2=0.999)
# train the neural network
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=32, epochs=9, validation_data=(X_test, Y_test), verbose=2)
該頁面將顯示訓練性能和設備上的性能,根據您的數據集應如下所示:

我們的咳嗽檢測算法現在可以試用了!
測試
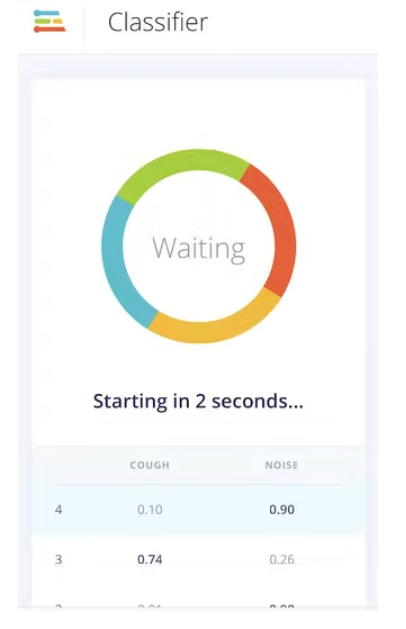
實時分類頁面允許我們使用數據集附帶的現有測試數據或通過手機或 Arduino 設備中的流式音頻數據來測試算法。我們可以從一個簡單的測試開始,選擇任何測試樣本,然后按“加載樣本”。這將對測試樣本進行分類并顯示結果:
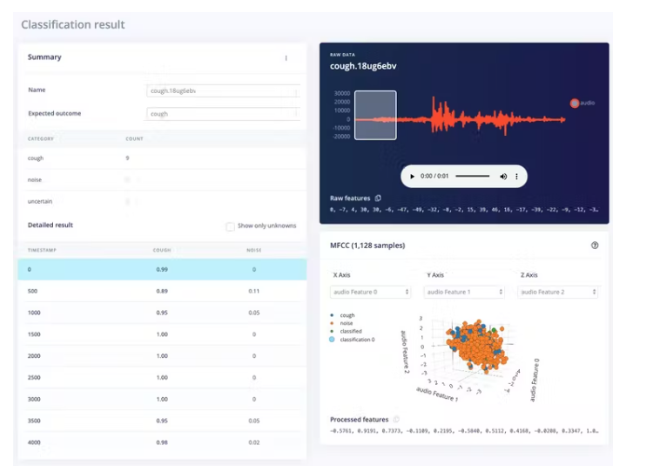
我們還可以使用實時數據測試算法。通過刷新我們之前打開的手機上的瀏覽器頁面,從您的手機開始。然后在“分類新數據”部分中選擇您的設備,然后按“開始采樣”。當通過 edge-impulse-daemon 連接到項目時,您可以類似地從 Nano BLE Sense 流式傳輸音頻樣本,就像在數據收集步驟中一樣。
部署
我們可以輕松地將我們的咳嗽檢測算法部署到手機上。轉到手機上的瀏覽器窗口并刷新,然后按“切換到分類模式”按鈕。這將自動將項目構建到 WebAssembly 包中并在您的手機上連續執行(之后無需云,甚至進入飛行模式!)
接下來,我們可以通過轉到部署頁面將算法部署到 Nano BLE Sense。在“構建固件”下選擇“Arduino Nano 33 BLE Sense”,然后單擊“構建”。
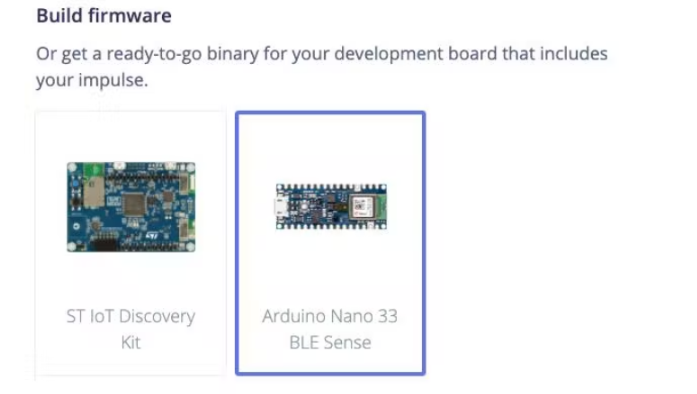
這將為 Nano BLE Sense 構建一個完整的固件,包括您的最新算法。按照屏幕上的說明使用二進制文件刷新您的 Arduino 板。

刷新 Arduino 后,我們可以在設備以 115、200 波特插入 USB 時打開設備的串行端口。串口打開后,按回車鍵得到提示,然后:
> AT+RUNIMPULSE
Inferencing settings:
? ? Interval: 0.06 ms.
? ? Frame size: 16000
? ? Sample length: 1000 ms.
? ? No. of classes: 2
Starting inferencing, press 'b' to break
Recording...
Recording done
Predictions (DSP: 495 ms., Classification: 84 ms., Anomaly: 0 ms.):?
? ? cough: 0.01562
? ? noise: 0.98438
Starting inferencing in 2 seconds...
Recording...
Recording done
Predictions (DSP: 495 ms., Classification: 84 ms., Anomaly: 0 ms.):
? ? cough: 0.01562
? ? noise: 0.98438
Starting inferencing in 2 seconds...
Recording...
Recording done
Predictions (DSP: 495 ms., Classification: 84 ms., Anomaly: 0 ms.):
? ? cough: 0.86719
? ? noise: 0.13281
Starting inferencing in 2 seconds...
Recording...
Recording done
Predictions (DSP: 495 ms., Classification: 84 ms., Anomaly: 0 ms.):
? ? cough: 0.01562
? ? noise: 0.98438
未來可能的拓展
使用您自己的咳嗽和背景聲音擴展默認數據集,記得定期重新訓練和測試。您可以在測試頁面下設置單元測試,以確保模型在擴展時仍然有效。
為不咳嗽的人類聲音添加一個新類和數據,例如背景語音、打哈欠等。
從一個新數據集開始,收集音頻樣本以檢測新事物。
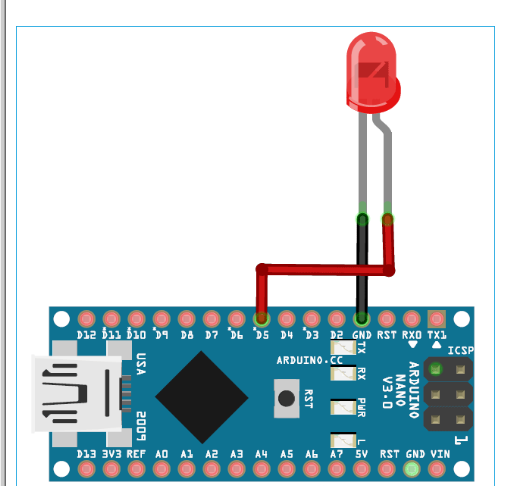
根據這些說明部署到 Arduino 庫,作為 Arduino Sketch 的一部分,以使用 LED 或顯示器顯示咳嗽檢測











 工商網監
工商網監
評論