 電子發(fā)燒友App
電子發(fā)燒友App


丁香醫(yī)生的評(píng)論區(qū)和后臺(tái),每天都會(huì)收到成千上萬條關(guān)于健康的問題。為了幫助用戶解決各種健康疑問,丁香醫(yī)生提供了多種不同形式的服務(wù)。對(duì)于高頻、有共性的問題,通過數(shù)百位醫(yī)生、專家收集整理資料,編寫成專業(yè)易懂、FAQ問答形式的「健康百科」。此外,還有大量「專家科普」深度長文,解釋每個(gè)醫(yī)療知識(shí)背后的來龍去脈。
這兩類內(nèi)容都具備良好的結(jié)構(gòu)化,有相對(duì)工整的標(biāo)題,有歸屬的科室,同時(shí)或以醫(yī)療實(shí)體分類,或以健康topic分類等。用戶通過搜索的方式即可方便地觸達(dá)到內(nèi)容。不過,醫(yī)學(xué)畢竟是個(gè)復(fù)雜的話題,很多病癥在不同人身上個(gè)體差異也特別大,參照最近大家陽了的情況:
得新冠就像小馬過河,小馬問松鼠,水深嗎?松鼠說:“太深了!我朋友過河被淹死了!”小馬又問小狗,小狗說:“挺深的,我好不容易才游過去的。”小馬又去問黃牛。
黃牛笑著說:“要布洛芬嗎?”
主動(dòng)的科普做不到事無巨細(xì)地把所有細(xì)節(jié)、可能性都寫出來。用戶有個(gè)性化的問題,在科普文章中找不到答案,可以選擇使用付費(fèi)線上問診服務(wù),直接找個(gè)醫(yī)生問。當(dāng)問診結(jié)束后,問診記錄會(huì)默認(rèn)保持保密狀態(tài)。此時(shí),如果你愿意,幫助那些遇到類似問題的人,可以將問題設(shè)置為公開。本次問診記錄將會(huì)隱去所有敏感信息后,進(jìn)入搜索索引。通過用戶檢索,數(shù)據(jù)將展示在「公開問題」欄目。
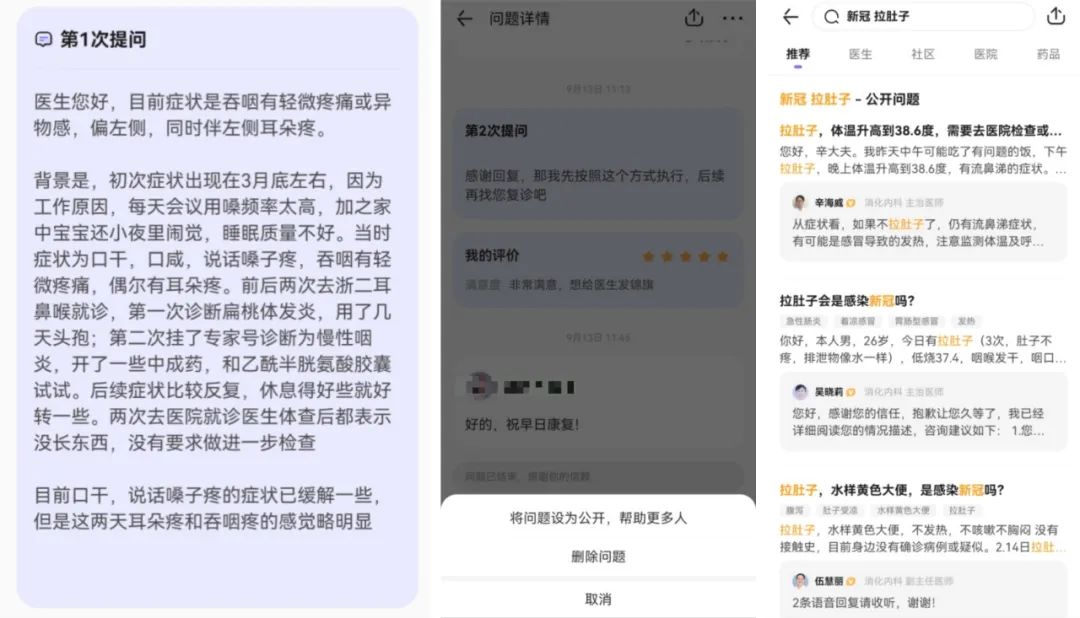
接觸過信息檢索的同學(xué)一定都有體會(huì),要提升搜索效果,一方面要在語義匹配上下功夫,另一方面也要盡可能提升原始數(shù)據(jù)的結(jié)構(gòu)化程度。眼尖的同學(xué)肯定發(fā)現(xiàn)了,被公開的問診記錄已經(jīng)被自動(dòng)帶上了標(biāo)題。對(duì)于長文本檢索來說,標(biāo)題是個(gè)非常重要的索引字段,它包含了全文的核心主旨,不僅有利于文檔與Query的語義匹配,同時(shí)對(duì)于用戶閱讀體驗(yàn)也更好。通常,文章標(biāo)題都是由編輯同學(xué)起的,人有高度抽象的思維能力,可以做到復(fù)雜事物的總結(jié)歸納,理清楚最主要的脈絡(luò)邏輯。在當(dāng)前的場(chǎng)景中,我們希望模型也能具備類似的能力,即提煉出用戶問診主訴,并生成一個(gè)流暢通順的問句。
在還是RNN-Seq2seq為主流架構(gòu)的3年前,團(tuán)隊(duì)也在摘要生成方面做了不少嘗試,當(dāng)時(shí)的技術(shù)背景下,我們大多探索的方向是在如何在結(jié)構(gòu)上加些trick,提升長文的編碼能力。或是各種結(jié)合copy機(jī)制,來提升關(guān)鍵信息的識(shí)別,引入外部知識(shí)實(shí)體數(shù)據(jù)等方向。但是,由于受限于主體encoder的編碼能力,最終結(jié)果總是差強(qiáng)人意,雖然偶有讓人眼前一亮的case,但是當(dāng)時(shí)模型輸出的穩(wěn)定性還是不足以應(yīng)用在實(shí)際場(chǎng)景中。
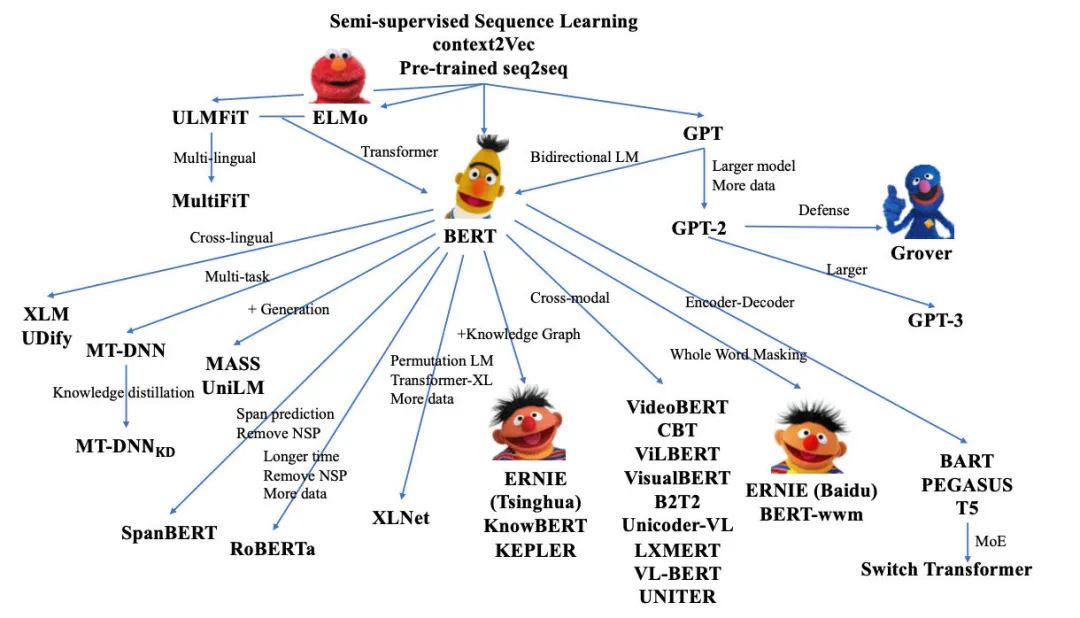
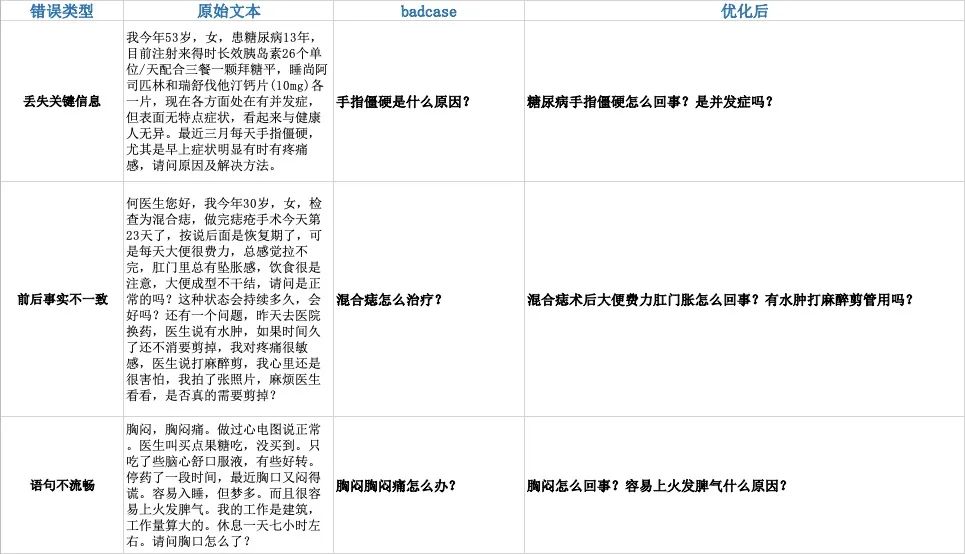
然而在隨后的3年里,預(yù)訓(xùn)練模型迎來了爆發(fā),在大模型的加持下,NLG的效果迅速提升至一個(gè)十分可觀的水平。結(jié)合我們的任務(wù),Google發(fā)布的T5成為了我們的基礎(chǔ)框架。在經(jīng)過幾輪標(biāo)注數(shù)據(jù)調(diào)教后,baseline版本已基本達(dá)到可讀狀態(tài)。但是在落地之前,還有幾個(gè)問題需要解決,比如由于生成低資源導(dǎo)致的語句不流暢、生成句子前后事實(shí)不一致、輸入文本過長等。
近幾年,摘要生成也是NLP領(lǐng)域比較火熱的一個(gè)方向,本文結(jié)合學(xué)界的幾項(xiàng)工作,談?wù)勅绾尉徑馍鲜鰡栴}的一些思路。
一、摘要生成與多任務(wù) or 多目標(biāo)相結(jié)合
從預(yù)訓(xùn)練模型興起時(shí),多任務(wù)就成了很多工作的解決方案,摘要領(lǐng)域也同樣如此,比如提事實(shí)一致性可以增加一個(gè)事實(shí)一致性的任務(wù),提升流暢性可以增加一個(gè)提升流暢度的任務(wù),摘要領(lǐng)域最具影響的多任務(wù)來自2019年Google的Pegasus。
《PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization》
該篇文章開創(chuàng)性的引入一個(gè)新的預(yù)訓(xùn)練任務(wù)gap sentences generation(GSG),并借此在12個(gè)數(shù)據(jù)集上取得了SOTA,將預(yù)訓(xùn)練模型摘要的效果提升了一個(gè)臺(tái)階。對(duì)于一個(gè)文本段落,GSG任務(wù)訓(xùn)練方式是:選擇在encoder階段mask掉一段文本中的部分句子,并將這部分句子作為decoder的target進(jìn)行訓(xùn)練。
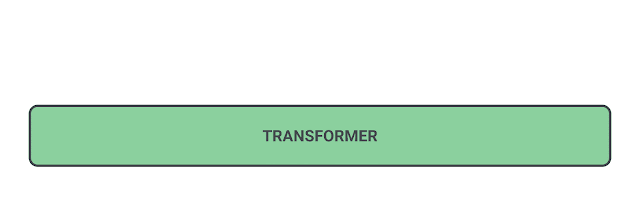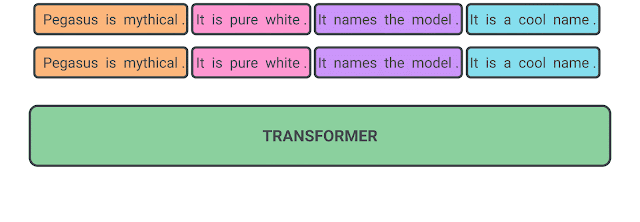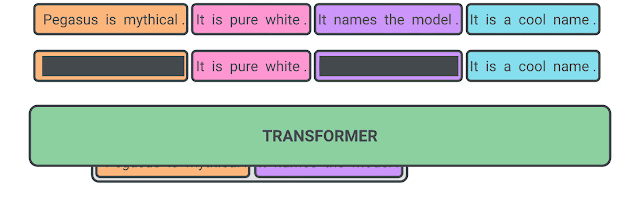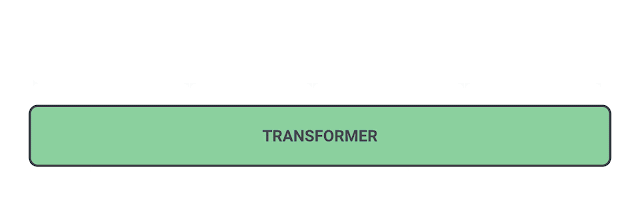
整個(gè)任務(wù)形式非常簡單,效果卻異常出彩。而對(duì)于如何選擇被mask的句子,為了使得被mask的句子內(nèi)容上更加接近一個(gè)"摘要",文章給的思路是通過計(jì)算句子與其余句子的Rouge,選擇top-N進(jìn)行mask。這里Rouge可以替換為其他分值,比如Fact PEGASUS就在選擇的分值上增加了FACTCC,用于提升生成摘要的事實(shí)一致性。
《BRIO: Bringing Order to Abstractive Summarization》
本文是筆者認(rèn)為今年較好的文章,一度在幾個(gè)數(shù)據(jù)集benchmark榜上占據(jù)第一的位置。這篇文章通過多任務(wù)緩解了自回歸模型的兩個(gè)缺點(diǎn):
(1)自回歸模型在生成過程中通常會(huì)受到bias帶來的影響;
(2)生成式摘要的訓(xùn)練數(shù)據(jù)通常為一篇文章對(duì)應(yīng)一句摘要,模型在學(xué)習(xí)的是一個(gè)點(diǎn)到點(diǎn)的分布,這并不是很好的形式;
文章中將摘要抽取的訓(xùn)練分兩個(gè)階段,第一階段首先訓(xùn)練MLE的loss,第二階段模型采用多任務(wù)訓(xùn)練排序loss+MLE loss訓(xùn)練,整個(gè)訓(xùn)練過程重復(fù)這兩個(gè)階段直到收斂。
排序任務(wù)通過beam-search生成若干句子,對(duì)原文計(jì)算Rouge對(duì)生成句子進(jìn)行排序。排序loss由句子生成概率和排序的位置決定,其目的是希望模型生成質(zhì)量高(Rouge分值高)句子的概率高于質(zhì)量差的概率。
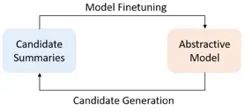
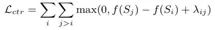
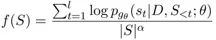
這里第二階段的loss公式可以解釋如下,?L_xent為MLE loss,L_ctr為排序loss,S_i,S_j為模型通過beam-search采樣得到的句子,其中i,j即為排序順序,f(s_i)為模型生成句子長度規(guī)劃后的log概率。對(duì)比 MLE loss,排序loss學(xué)習(xí)到的并非是一個(gè)點(diǎn)的分布,另外該loss中兩個(gè)句子生成概率相減,巧妙規(guī)避了詞頻帶來的bias。
《Calibrating Sequence likelihood Improves Conditional Language Generation》
來自PEGASUS同組的工作,當(dāng)前的SOTA模型,其思想和BRIO非常相似,在模型Fine-tune之后,引入了Calibration階段,two-stages的多任務(wù)訓(xùn)練(這里并不像BRIO重復(fù)訓(xùn)練),同樣的配方同樣的味道。
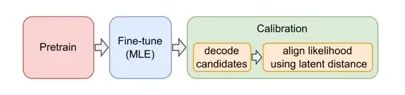
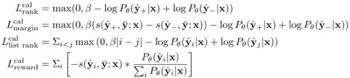
這篇文章做了非常多的實(shí)驗(yàn),對(duì)多種loss和訓(xùn)練方式進(jìn)行測(cè)試,這里簡單歸納下實(shí)驗(yàn)結(jié)論:
(1)多任務(wù)的loss選擇上:最簡單的rankloss取得了最好的效果。
(2)生成句子的排序指標(biāo)上:采用BertScore/decoder的結(jié)果/Rouge等幾種方法都差不多。
(3)生成數(shù)據(jù)的方式:Beam-search 好于Diverse Beam Search和Nucleus Sampling。
(4)多任務(wù)的另一個(gè)loss選擇kl-divergence和cross entropy表現(xiàn)差不多。
(5)進(jìn)入第二個(gè)訓(xùn)練階段的指標(biāo):采用困惑度取最好。
文章還證實(shí)了多任務(wù)結(jié)合two-stages的訓(xùn)練可以減少預(yù)測(cè)過程對(duì)beam-search等trick的依賴。
《FRSUM: Towards Faithful Abstractive Summarization via Enhancing Factual Robustness》
這篇文章來自Baidu的EMNLP2022的工作,在多任務(wù)基礎(chǔ)上通過引入對(duì)抗攻擊的思路來提升摘要的事實(shí)一致性。
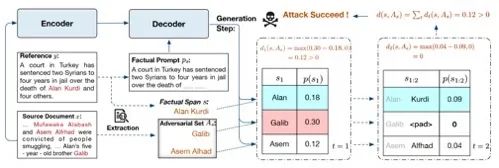
文章構(gòu)造了一個(gè)對(duì)抗攻擊任務(wù),文本信息通過encoder進(jìn)入deocder前會(huì)被加上一個(gè)擾動(dòng)h,另外希望模型在有擾動(dòng)的情況下,在factual span輸出的真實(shí)結(jié)果概率高于對(duì)抗集中其他可能實(shí)體的概率。這里選擇的factual span則是事先確定模型最可能出現(xiàn)的一些錯(cuò)誤類型,針對(duì)factual span構(gòu)造對(duì)抗集來自輸入文本。從消融實(shí)驗(yàn)可以看出擾動(dòng)和對(duì)抗任務(wù)都帶來一定程度的事實(shí)一致性的提升。
二、長文本摘要策略
長文本摘要目前主流的工作是兩個(gè)方向,一個(gè)利用BigBird、LongFromer之類的稀疏attention結(jié)構(gòu)增加模型可接受的輸入長度;另一個(gè)則是通過截?cái)唷⒇澙凡呗詠頊p少輸入長度。
《How Far are We from Robust Long Abstractive Summarization?》
文章來自2022EMNLP,對(duì)于長文本的摘要生成,該篇文章首先做個(gè)了比較有趣的信息量實(shí)驗(yàn)。對(duì)于平均為6k個(gè)token的英文文章,信息量最多的位置在1k-2k區(qū)間,0-1k區(qū)間信息量排第二,因此對(duì)于長文本的處理如果簡單取top 512長度輸入很有可能只得到一個(gè)次優(yōu)解。
文章實(shí)驗(yàn)了兩種方式,方式一是不限制輸入長度采用sparse-attention(Longformer的local-attention);方式二是限制輸入長度,輸入文本通過貪婪方式篩選(reduce-then-summ,根據(jù)Rouge貪婪選擇若干句子)。
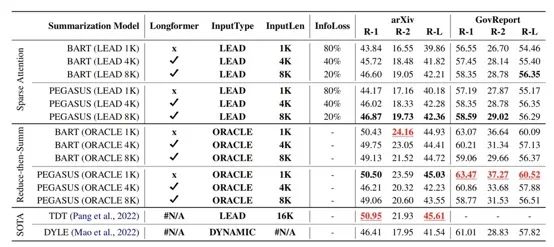
在文本長度限制為1k,4k,8k的輸出結(jié)果上,對(duì)于方式一,增加輸入長度能帶來輕微的提升,即便是由full attention變成sparse-attention。對(duì)于方式二,1k的長度限制結(jié)合full attention取得了最佳,增加長度和稀疏attention并沒有在方式二中帶來提升。采用1k長度結(jié)合篩選再輸入無疑是最貼近模型的預(yù)訓(xùn)練的方式,限制在1k長度也避免了對(duì)attention和position embedding的改造,除去了冗余信息也減少生成模型跑偏的風(fēng)險(xiǎn)。
《Investigating Efficiently Extending Transformers for Long Input Summarization》
另一篇采用sparse attention解決長文本的是Google的Pegasus-X,支持最大token長度長達(dá)16k,可在huggingface下載。該篇文章引入了staggered block-local Transformer。這種transformer不同層采用了不同的local-attention范圍,這種堆疊的思想類似于CNN感受野,最上層的transformer通過錯(cuò)位attention可以達(dá)到非常長的感受野。
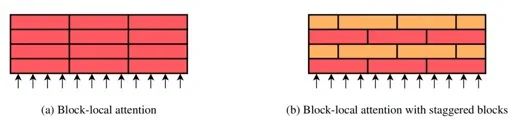
文章通過實(shí)驗(yàn)證明了staggered block-local Transformer即使在有全局的global attention的情況下也能帶來一定的提升。
《A Multi-Stage Summarization Framework for Long Input Dialogues and Documents》
這篇文章來自微軟今年的ACL的工作,相比前兩篇文章多了一些工業(yè)風(fēng)。
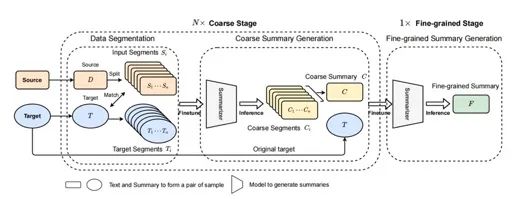
文章采用了split-then-summarize的形式來應(yīng)對(duì)長文本摘要問題,在一些長文本訓(xùn)練集上取得了sota的效果。將長文本摘要生成過程分成N個(gè)粗摘要過程和一個(gè)精摘要過程,每個(gè)過程對(duì)應(yīng)都有不同的模型來適配,一共有N+1個(gè)模型。文章特別提及到了多個(gè)過程共用模型會(huì)帶來性能下降。
粗摘要過程的模型訓(xùn)練數(shù)據(jù),是將原始文章和目標(biāo)摘要進(jìn)行段落拆分進(jìn)行匹配得到。這個(gè)匹配策略是貪婪的最大化Rouge分值。最終輸入的精摘要模型的文章長度并沒有被壓縮在模型輸入最大長度K以內(nèi),而是在1K~2K之間。文章給的解釋是,壓縮到K的目標(biāo)長度更容易產(chǎn)生過短粗摘要,這些過短的摘要拼接后會(huì)帶來一些噪聲。
三、利用圖結(jié)構(gòu)
文章中通常存在一些結(jié)構(gòu)信息,比如句子是否同屬于一個(gè)段落,句子間一些指代關(guān)系,句子是否包含關(guān)鍵詞等,這些信息通常可以與圖結(jié)構(gòu)相結(jié)合提升摘要的效果。
《HEGEL: Hypergraph Transformer for Long Document Summarization》
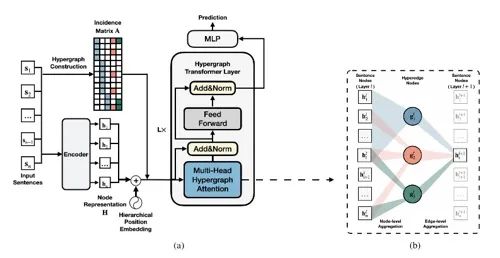
該篇文章通過文章結(jié)構(gòu)信息提升抽取式摘要結(jié)果,雖然是抽取式摘要但其將構(gòu)造圖結(jié)構(gòu)信息的方式仍然值得借鑒。該篇文章將句子、句子所屬段落、topic、keyword作為圖中節(jié)點(diǎn)構(gòu)造圖結(jié)構(gòu),topic和keyword都是通過抽取的方式得到。句子經(jīng)過sentence encoder之后在經(jīng)過兩層Hypregraph attention匯聚點(diǎn)和邊的信息獲得更好的句子表示,再進(jìn)行抽取任務(wù)。
《Abstractive Summarization Guided by Latent Hierarchical Document Structure》
該篇文章同樣來自今年的EMNLP,該篇文章提出了HierGNN結(jié)構(gòu)希望能通過圖結(jié)構(gòu)學(xué)到文章中句子之間的依賴關(guān)系,來提升摘要生成效果。從最終的實(shí)驗(yàn)結(jié)果上看預(yù)訓(xùn)練和非預(yù)訓(xùn)練模型均有一定的提升。
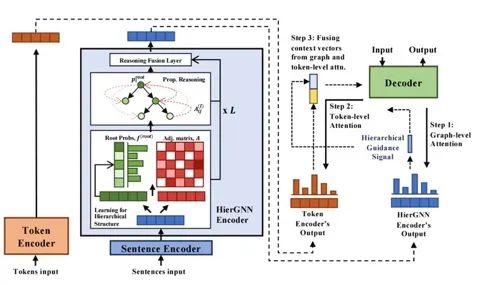
和上篇文章類似,這里將句子看作圖中節(jié)點(diǎn),邊則是兩個(gè)句子間的依賴關(guān)系f,文章對(duì)于一個(gè)節(jié)點(diǎn)s分別給了p(parent),c(child)兩種的表示。
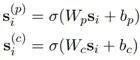
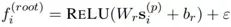
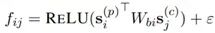
圖中的節(jié)點(diǎn)經(jīng)過HierGNN的reasoning結(jié)構(gòu)節(jié)點(diǎn)匯聚周圍節(jié)點(diǎn)的信息,兩層網(wǎng)絡(luò)更新過程中有類似遺忘門的gate結(jié)構(gòu)。
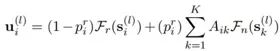
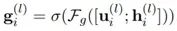
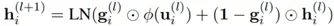
最終每個(gè)節(jié)點(diǎn)的表示會(huì)和decoder t時(shí)刻的輸出進(jìn)行g(shù)raph attention加權(quán)求和獲得圖表示,再和decoder輸出經(jīng)過token attention,softmax獲得對(duì)應(yīng)vocab的分值。
總結(jié)
雖然預(yù)訓(xùn)練模型對(duì)摘要抽取帶來許多便利,但是實(shí)際應(yīng)用中仍會(huì)遇到語句不流暢、前后事實(shí)不一致等問題,然而這些問題在嚴(yán)肅醫(yī)療科普中的容錯(cuò)率是比較低的。除了通過上述所提到的工作,改善摘要的生成過程。同時(shí)我們也建議在生成之后完善后續(xù)評(píng)估環(huán)節(jié),比如針對(duì)生成結(jié)果的流暢性評(píng)估過濾環(huán)節(jié)。我們?cè)谠摥h(huán)節(jié)除了包含一些業(yè)務(wù)規(guī)則之外,還會(huì)從困惑度、Rouge、Domain分類結(jié)果、摘要包含的實(shí)體個(gè)數(shù)等維度進(jìn)行二次打分。
引用
[1]《Pegasus: Pre-training with extracted gap-sentences for abstractive summarization》
[2]《FactPEGASUS: Factuality-Aware Pre-training and Fine-tuning for Abstractive Summarization》
[3]《BRIO: Bringing Order to Abstractive Summarization》
[4]《Calibrating Sequence likelihood Improves Conditional Language Generation》
[5]《How Far are We from Robust Long Abstractive Summarization》
[6]《Investigating Efficiently Extending Transformers for Long Input Summarization》
[7]《A Multi-Stage Summarization Framework for Long Input Dialogues and Documents》
[8]《HEGEL: Hypergraph Transformer for Long Document Summarization》
[9]《Abstractive Summarization Guided by Latent Hierarchical Document Structure》
編輯:黃飛
?

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論