 電子發燒友App
電子發燒友App


將TestMatrixMultiply.c內容改為:[cpp]?
?
#include?
typedef?int?data_type;??
#define?N?5
const?data_type?MatrixA[]?=?{??
#include?"A.h"??
};??
const?data_type?Vector_b[]?=?{??
#include?"b.h"??
};??
const?data_type?MatlabResult_c[]?=?{??
#include?"c.h"??
};
data_type?HLS_Result_c[N]?=?{0};??
void?CheckResult(data_type?*?matlab_result,data_type?*?your_result);??
int?main(void)??
{??
?printf("Checking?Results: ");??
?MatrixMultiply(MatrixA,Vector_b,HLS_Result_c);??
?CheckResult(MatlabResult_c,HLS_Result_c);??
?return?0;??
}??
void?CheckResult(data_type?*?matlab_result,data_type?*?your_result)??
{??
?int?i;??
?for(i?=?0;i
?{??
??printf("Idx?%d:?Error?=?%d?
",i,matlab_result[i]-your_result[i]);??
?}??
}??
?
首先進行C語言仿真驗證,點這個按鈕:
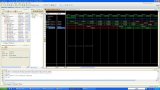
結果如下:
從C仿真輸出看到,仿真結果與matlab計算結果一致,說明我們編寫的C程序MatrixMultiply是正確的。接下來進行綜合,按C仿真后面那個三角形按鈕,得到結果如下:
注意到,計算延遲為186個時鐘周期。這是未經過優化的版本,記為版本1。為了提高FPGA并行計算性能,我們接下來對它進行優化。打開MatrixMultiply.c,點Directives頁面,可以看到我們可以優化的對象。
注意到矩陣和向量相乘是雙層for循環結構。我們先展開最內層for循環,步驟如下:右鍵點擊最內側循環,右鍵,然后Insert Directive...
彈出對話框如下,Directives選擇UNROLL,OK即可,后面所有都保持默認。
再次綜合后,結果如下
可見效果非常明顯,延遲縮短到51個時鐘周期。用同樣方法,展開外層循環,綜合后結果如下:
計算延遲又降低了1/3!!!可是代價呢?細心的你可能發現占用資源情況發生了較大變化,DSP48E1由最初的4個變為8個后來又成為76個!!!FPGA設計中,延遲的降低,即速度提高,必然會導致面積的增大!循環展開是優化的一個角度,另一個角度是從資源出發進行優化。我們打開Analysis視圖,如下所示:
從分析視圖可以看出各個模塊的運行順序,從而為優化提供更為明確的指引。我們發現AA_load導致了延遲,如果所有AA的值都能一次性并行取出,勢必會加快計算效率!回到Synthetic視圖,為AA增加Directives:
選擇Resources,再點Cores后面的方框,進入Vivado HLS core選擇對話框
按上圖進行選擇。使用ROM是因為在計算矩陣和向量相乘時,AA為常數。確認。仍然選擇AA,增加Directives,如下圖:
選擇數組分解,mode選擇完全complete,綜合后結果如下圖:
延遲進一步降低,已經降到11個時鐘周期了!!!是否已經達到極限了呢???答案是否定的。我們進入Analysis視圖,看一下還有哪些地方可以優化的。經過對比發現bb也需要分解,于是按照上面的方法對bb進行資源優化,也用ROM-2P類型,也做全分解,再次綜合,結果如下:
發現延遲進一步降低到8個時鐘周期了!!!老師,能不能再給力點?可以的!!!!我們進入分析視圖,發現cc這個回寫的步驟阻塞了整體流程,于是我們將cc也進行上述資源優化,只不過資源類型要變為RAM_2P,因為它是需要寫入的。綜合結果:
整體延遲已經降低到6個clk周期了!!!再看Analysis視圖:
延遲已經被壓縮到極限了。。。。老師,還能再給力點嘛?答案是可以的!!!!我們前面的所有運算都是基于整形數int,如果將數值精度降低,將大大節省資源。注意現在DSP48E1需要100個!看我們如何將資源再降下來。這就需要借助“任意精度”數據類型了。HLS中除了C中定義的char,shrot,int,long,long long 之外,還有任意bit長度的int類型。我們將代碼開頭的data_type定義改為:[cpp]?
?
#include?
typedef?uint15?data_type; ?
?








 工商網監
工商網監
評論